How we improved GKE volume attachments for stateful applications by up to 80%
Sneha Aradhey
Software Engineer
Brad Farr
Software Engineer
If you run stateful workloads on Google Kubernetes Engine (GKE), you may have noticed that your Cluster upgrades execute much faster as of late. You’re not imagining things. We recently introduced an enhancement to GKE and Google Compute Engine that significantly improves the speed at which Persistent Disks (PDs) are attached and detached. This means less latency, which benefits user workloads and interactions with persistent storage. This is most evident during cluster upgrades, which in the past were characterized by high attach and detach requests when moving disks to a new VM, slowing down the process.
Read on for background on this problem and our solution to it.
Kubernetes storage and GKE CSI driver
Back before most applications ran in containers on Kubernetes, a workload’s (and its storage’s) lifecycle was coupled to its underlying virtual machine (VM). That made migrating a workload to a new VM error-prone and time-consuming: you needed to decommission the VM, manually detach and reattach disks to the new VM, remount the disk paths, and restart the application. Disks were rarely detached from VMs and attached to new VMs, and when they were, it was often only at startup and shutdown, and at low traffic volume. This made it hard to recommend Kubernetes as a place to run stateful, IO-bound applications. We needed a storage-centric solution.
In Google Cloud, this solution took the form of the Google Compute Engine Persistent Disk (GCE PD) Container Storage Interface (CSI) Storage Plugin. This CSI driver is a foundational component within GKE that manages the lifecycle of Compute Engine PDs in a GKE cluster. It enables seamless storage access for Kubernetes workloads, facilitating operations like provisioning, attaching, detaching, and modifying filesystems. This allows workloads to move seamlessly across GKE nodes, enabling upgrades, scaling, and migrations.
There’s a problem, though. GKE provides flexibility for workload placement, at a high scale. Nodes can accommodate hundreds of pods, and workloads may utilize multiple Persistent Volumes. This translates to tens to hundreds of PDs attached to VMs that need to be tracked, managed and reconciled. In the case of a node upgrade, you need to reduce the amount of time needed to restart workload pods and move PDs to a new node in order to maintain workload availability and reduce cluster upgrade delays. This can introduce an order of magnitude higher number of attach/detach operations relative to the existing system that was designed for VMs — a unique challenge.
Stateful applications on GKE are growing exponentially, so we needed a CSI driver design that could handle these large-scale operations efficiently. To address this, we had to rethink the underlying architecture to optimize the PD attachment and detachment processes, to provide minimal downtime and smoother workload transitions. Here’s what we did.
Merging queued operations for volume attachments
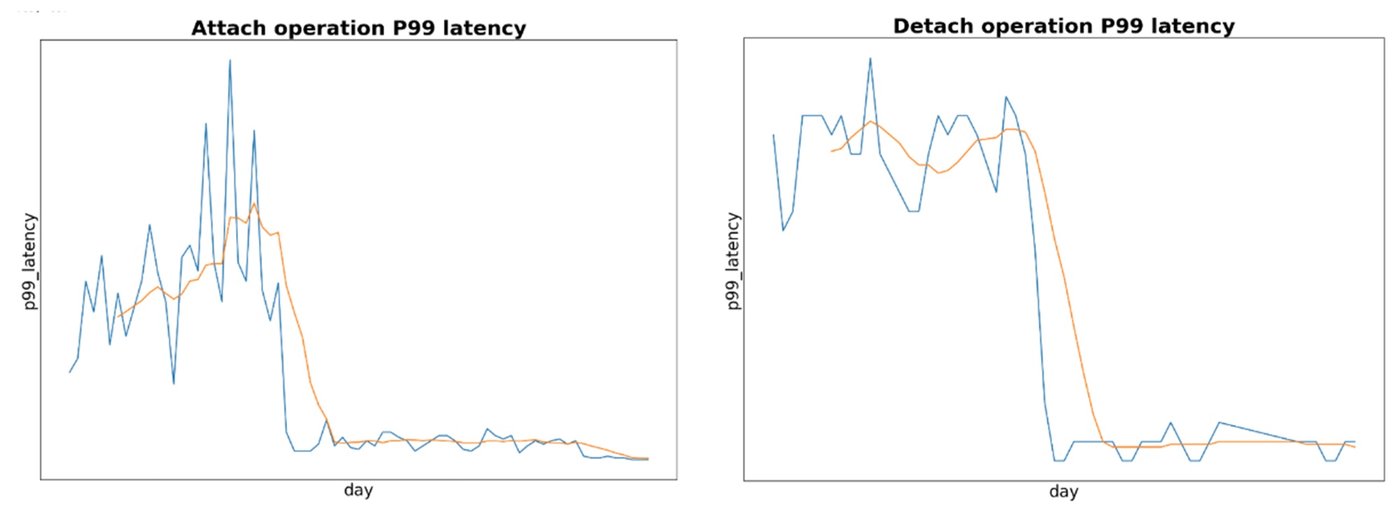
As explained above, GKE nodes with a large number of PD volumes (up to 128) were experiencing very high latency during software upgrades due to serialized volume detach and attach operations. Take a node with 64 attached PD volumes as an example. Prior to the recent optimization, the CSI driver would issue 64 requests to detach all of the disks from the original node and then 64 requests to attach all of the disks to the upgraded node. However, Compute Engine only allowed queuing of up to 32 of these requests at a time, and then processed the corresponding operations serially. Requests not admitted to the queue would have to be retried by the CSI driver until capacity became available. If each of the 128 detach and attach operations took 5 seconds, that contributed 10+ minutes of latency for the node upgrade. With the new optimization, this latency is reduced to just over one minute.
It was important to us to introduce this optimization transparently without breaking clients. The CSI driver tracks and retries attach and detach operations at a per-volume level. But because CSI drivers are not designed for bulk operations, we couldn’t simply update the OSS community specs. Our solution was to provide transparent operation merging in Compute Engine instead, whereby the Compute Engine control merges the incoming attach and detach requests into a single workflow, while also maintaining per-operation error handling and rollback.
This newly introduced operation merging in Compute Engine transparently parallelizes detach and attach operations. Additionally, increased queue capacity now allows for up to 128 pending requests per node. The CSI driver continues to work as before, managing individual detach and attach requests without any changes to take advantage of the Compute Engine optimization, which opportunistically merges the queued operations. By the time the initially running detach and attach operation has completed, Compute Engine has calculated the resulting state of the node-volume attachments and begins reconciling this state with downstream systems. For 64 concurrent attach operations, the effect of this merging is that the first attachment begins running immediately, while the remaining 63 operations are merged and queued for execution immediately after completion of the initial operation. This resulted in staggering end-to-end latency improvements for GKE. The best part of these improvements is no customer action is needed and they automatically benefit:
-
~80% improvement in p99 latency for attach workloads
-
~60% improvement in P99 latency for detach workloads
This custom solution introduces a tiered approach for workflow execution. It decouples incoming requests from the actual execution of volume attachments and detachments by introducing two additional workflows that oversee the core business-logic workflow.
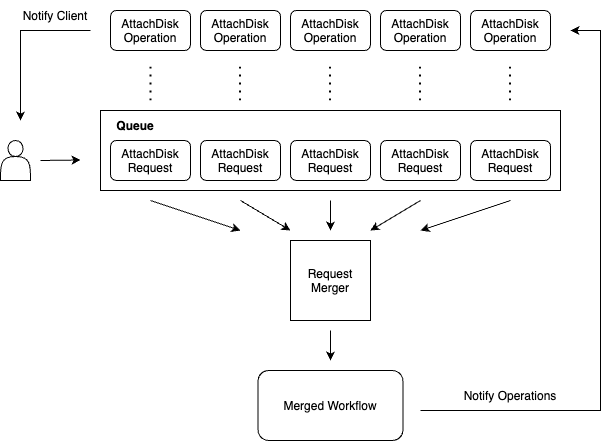
When the Compute Engine API receives a request to attach a disk, it now creates up to three workflows instead of one:
-
The first workflow is bound directly to the attachDisk operation but does not drive the actual execution. Rather, it simply polls for completion and sets any observed errors on the user-facing operation.
-
You can think of the second workflow that gets created as a watchdog for pending attachDisk or detachDisk operations. There is only ever one watchdog flow per Compute Engine instance resource. It terminates when all pending operations have been marked completed and is created on demand as part of the initial request to attach/detach a disk, only if there is no existing watchdog flow.
-
Finally, a watchdog flow ensures the existence of the third workflow, which does the actual attachDisk/detachDisk processing. This business-logic workflow directly notifies the operation-polling workflows of the success or failure of each individual attachDisk or detachDisk operation.
Additionally, to help provide optimal HTTP latency and to minimize database contention, incoming attachDisk/detachDisk requests aren’t directly queued within the same database row as the target Compute Engine instance entity. Rather, the request data is created as a sub-resource row of the instance entity and monitored by the watchdog flow to be picked up and executed in first-in first-ou (FIFO) order (for GKE).
And there you have it — a new and improved method technique for large scale attach and detach disk operations, allowing you to run large-scale stateful applications seamlessly on GKE clusters. You can learn more about deploying stateful applications on GKE from these resources.
