Accelerate AI Inference with Google Cloud TPUs and GPUs

Alex Spiridonov
Group Product Manager, AI Infrastructure
In the rapidly evolving landscape of artificial intelligence, the demand for high-performance, cost-efficient AI inference (serving) has never been greater. This week we announced two new open source software offerings: JetStream and MaxDiffusion.
JetStream is a new inference engine for XLA devices, starting with Cloud TPUs. JetStream is specifically designed for large language models (LLMs) and represents a significant leap forward in both performance and cost efficiency, offering up to 3x more inferences per dollar for LLMs than previous Cloud TPU inference engines. JetStream supports PyTorch models through PyTorch/XLA, and JAX models through MaxText – our highly scalable, high-performance reference implementation for LLMs that customers can fork to accelerate their development.
MaxDiffusion is the analog of MaxText for latent diffusion models, and makes it easier to train and serve diffusion models optimized for high performance on XLA devices, starting with Cloud TPUs.
In addition, we are proud to share the latest performance results from MLPerf™ Inference v4.0, showcasing the power and versatility of Google Cloud’s A3 virtual machines (VMs) powered by NVIDIA H100 GPUs.
JetStream: High-performance, cost-efficient LLM inference
LLMs are at the forefront of the AI revolution, powering a wide range of applications such as natural language understanding, text generation, and language translation. To reduce our customers’ LLM inference costs, we built JetStream: an inference engine that provides up to 3x more inferences per dollar than previous Cloud TPU inference engines.
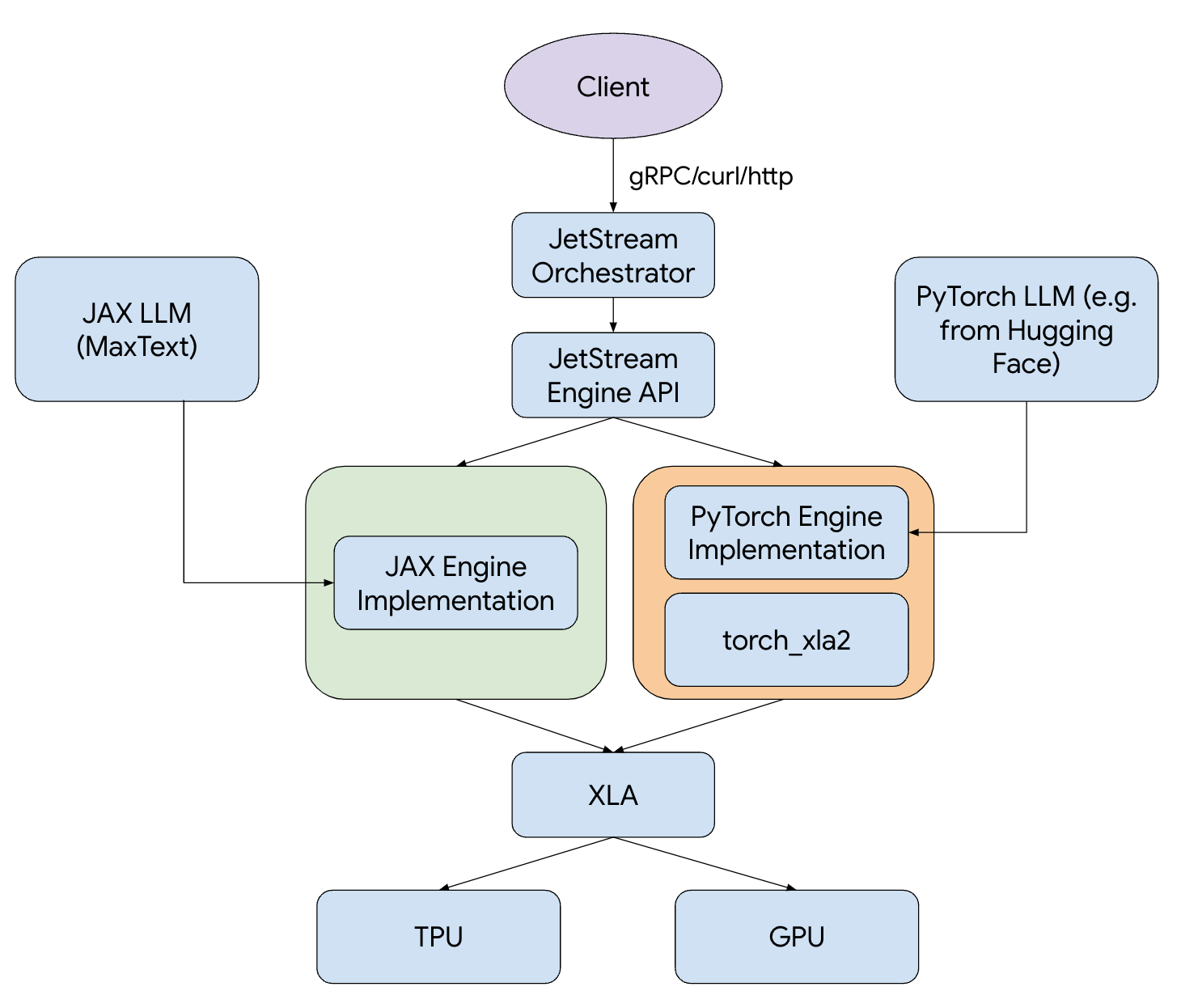
Figure 1: The JetStream stack.
JetStream includes advanced performance optimizations such as continuous batching, sliding window attention, and int8 quantization for weights, activations, and key-value (KV) cache. And whether you're working with JAX or PyTorch, JetStream supports your preferred framework. To further streamline your LLM inference workflows, we provide MaxText and PyTorch/XLA implementations of popular open models such as Gemma and Llama, optimized for peak cost-efficiency and performance.
On Cloud TPU v5e-8, JetStream delivers up to 4783 tokens/second for open models including Gemma in MaxText and Llama 2 in PyTorch/XLA:
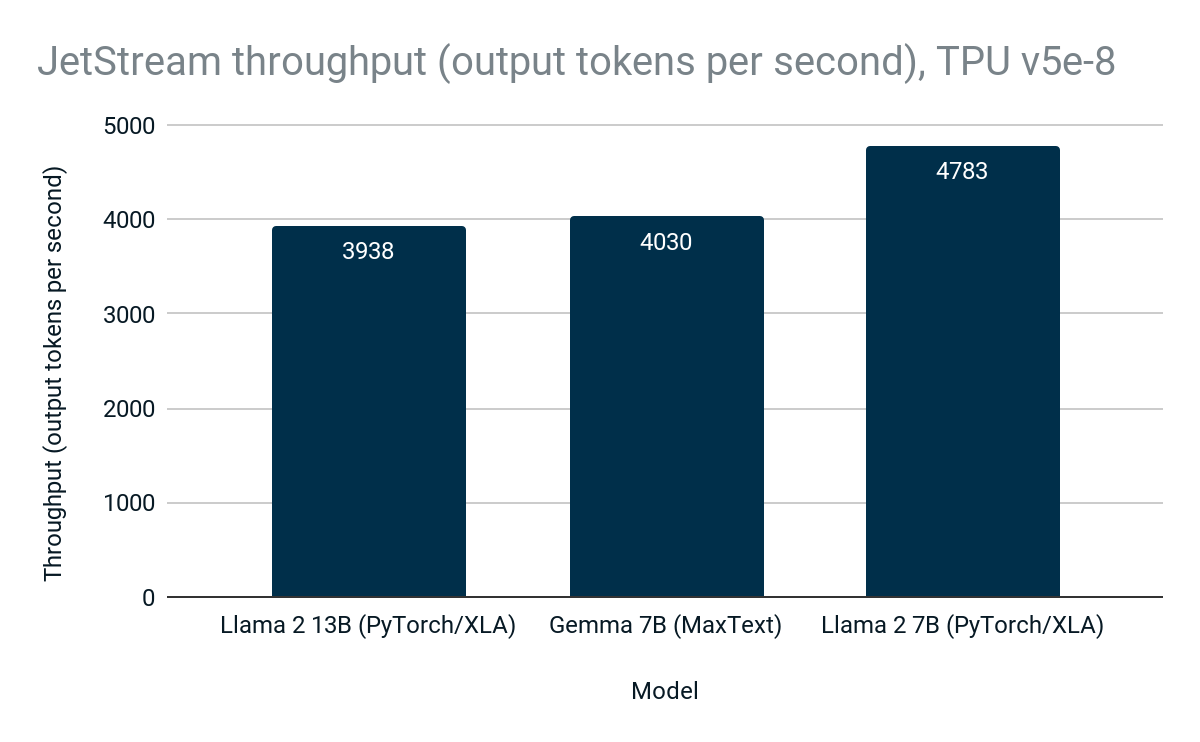
Figure 2: JetStream throughput (output tokens / second). Google internal data. Measured using Gemma 7B (MaxText), Llama 2 7B (PyTorch/XLA), and Llama 2 13B (PyTorch/XLA) on Cloud TPU v5e-8. Maximum input length: 1024, maximum output length: 1024. Continuous batching, int8 quantization for weights, activations, KV cache. PyTorch/XLA uses sliding window attention. As of April, 2024.
JetStream’s high performance and efficiency mean lower inference costs for Google Cloud customers, making LLM inference more accessible and affordable:
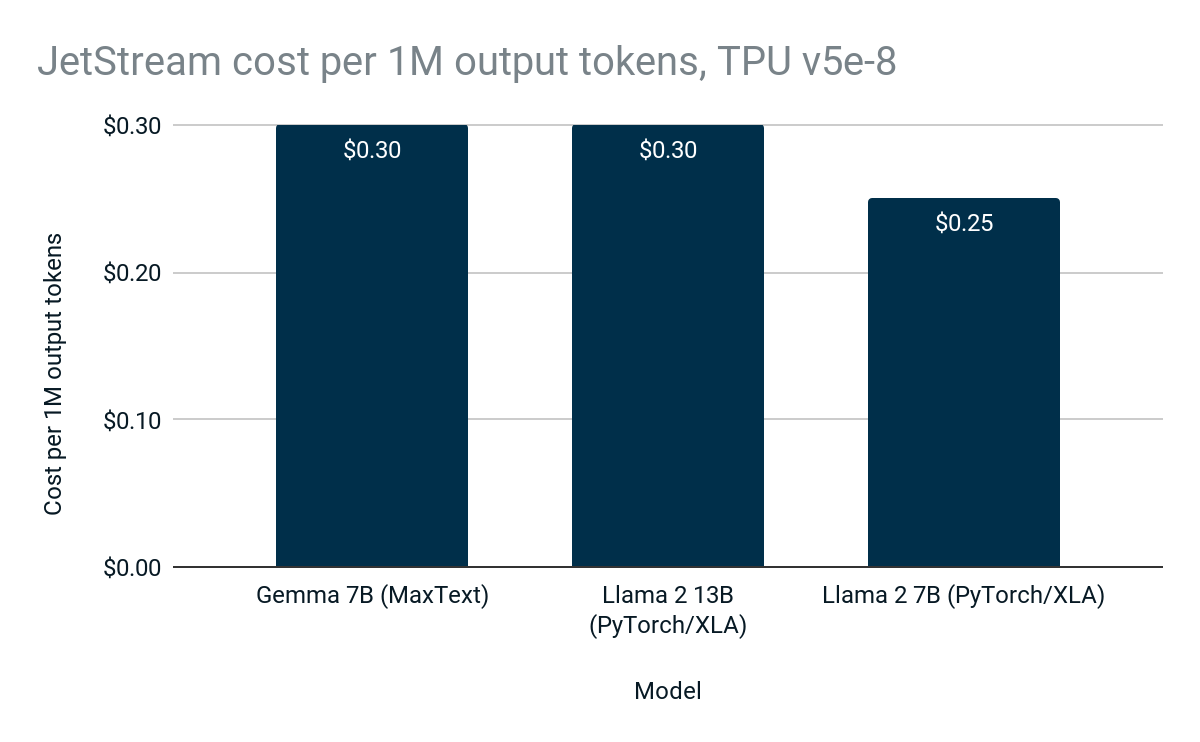
Figure 3: JetStream cost to generate 1 million output tokens. Google internal data. Measured using Gemma 7B (MaxText), Llama 2 7B (PyTorch/XLA), and Llama 2 13B (PyTorch/XLA) on Cloud TPU v5e-8. Maximum input length: 1024, maximum output length: 1024. Continuous batching, int8 quantization for weights, activations, KV cache. PyTorch/XLA uses sliding window attention. JetStream ($0.30 per 1M tokens) achieves up to 3x more inferences per dollar on Gemma 7B compared to the previous Cloud TPU LLM inference stack ($1.10 per 1M tokens). Cost is based on the 3Y CUD price for Cloud TPU v5e-8 in the US. As of April, 2024.
Customers such as Osmos are using JetStream to accelerate their LLM inference workloads:
“At Osmos, we've developed an AI-powered data transformation engine to help companies scale their business relationships through the automation of data processing. The incoming data from customers and business partners is often messy and non-standard, and needs intelligence applied to every row of data to map, validate, and transform it into good, usable data. To achieve this we need high-performance, scalable, cost-efficient AI infrastructure for training, fine-tuning, and inference. That’s why we chose Cloud TPU v5e with MaxText, JAX, and JetStream for our end-to-end AI workflows. With Google Cloud, we were able to quickly and easily fine-tune Google’s latest Gemma open model on billions of tokens using MaxText and deploy it for inference using JetStream, all on Cloud TPU v5e. Google’s optimized AI hardware and software stack enabled us to achieve results within hours, not days.” – Kirat Pandya, CEO, Osmos
By providing researchers and developers with a powerful, cost-efficient, open-source foundation for LLM inference, we're powering the next generation of AI applications. Whether you're a seasoned AI practitioner or just getting started with LLMs, JetStream is here to accelerate your journey and unlock new possibilities in natural language processing.
Experience the future of LLM inference with JetStream today. Visit our GitHub repository to learn more about JetStream and get started on your next LLM project. We are committed to developing and supporting JetStream over the long term on GitHub and through Google Cloud Customer Care. We are inviting the community to build with us and contribute improvements to further advance the state of the art.
MaxDiffusion: High-performance diffusion model inference
Just as LLMs have revolutionized natural language processing, diffusion models are transforming the field of computer vision. To reduce our customers’ costs of deploying these models, we created MaxDiffusion: a collection of open-source diffusion-model reference implementations. These implementations are written in JAX and are highly performant, scalable, and customizable – think MaxText for computer vision.
MaxDiffusion provides high-performance implementations of core components of diffusion models such as cross attention, convolutions, and high-throughput image data loading. MaxDiffusion is designed to be highly adaptable and customizable: whether you're a researcher pushing the boundaries of image generation or a developer seeking to integrate cutting-edge gen AI capabilities into your applications, MaxDiffusion provides the foundation you need to succeed.
The MaxDiffusion implementation of the new SDXL-Lightning model achieves 6 images/s on Cloud TPU v5e-4, and throughput scales linearly to 12 images/s on Cloud TPU v5e-8, taking full advantage of the high performance and scalability of Cloud TPUs
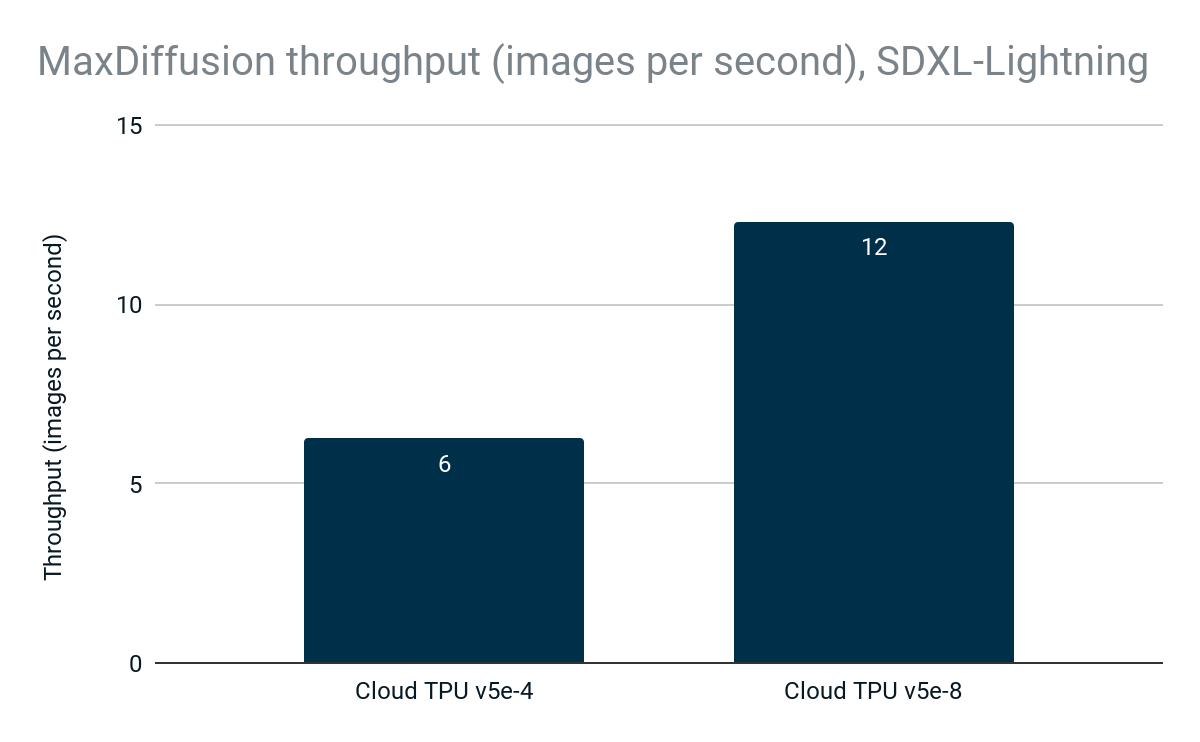
Figure 4: MaxDiffusion throughput (images per second). Google internal data. Measured using the SDXL-Lightning model on Cloud TPU v5e-4 and Cloud TPU v5e-8. Resolution: 1024x1024, batch size per device: 2, decode steps: 4. As of April, 2024.
And like MaxText and JetStream, MaxDiffusion is cost-efficient: generating 1000 images on Cloud TPU v5e-4 or Cloud TPU v5e-8 costs just $0.10.

Figure 5: MaxDiffusion cost to generate 1000 images. Google internal data. Measured using the SDXL-Lightning model on Cloud TPU v5e-4 and Cloud TPU v5e-8. Resolution: 1024x1024, batch size per device: 2, decode steps: 4. Cost is based on the 3Y CUD prices for Cloud TPU v5e-4 and Cloud TPU v5e-8 in the US. As of April, 2024.
Customers such as Codeway are using Google Cloud to maximize cost-efficiency for diffusion model inference at scale:
“At Codeway, we create chart-topping apps and games used by more than 115 million people in 160 countries around the world. "Wonder," for example, is an AI-powered app that turns words into digital artworks, while "Facedance" makes faces dance with a range of fun animations. Putting AI in the hands of millions of users requires a highly scalable and cost-efficient inference infrastructure. With Cloud TPU v5e, we achieved 45% faster serving time for serving diffusion models compared to other inference solutions, and can serve 3.6 times more requests per hour. At our scale, this translates into significant infrastructure cost savings, and makes it possible for us to bring AI-powered applications to even more users in a cost-efficient manner.” – Uğur Arpacı, Head of DevOps, Codeway
MaxDiffusion provides a high-performance, scalable, flexible foundation for image generation. Whether you're a seasoned computer vision expert or just dipping your toes into the world of image generation, MaxDiffusion is here to support you on your journey.
Visit our GitHub repository to learn more about MaxDiffusion and start building your next creative project today.
A3 VMs: Strong results in MLPerf™ 4.0 Inference
In August 2023 we announced the general availability of A3 VMs. Powered by 8 NVIDIA H100 Tensor Core GPUs in a single VM, A3s are purpose-built to train and serve demanding gen AI workloads and LLMs. A3 Mega, powered by NVIDIA H100 GPUs, will be generally available next month and offers double the GPU-to-GPU networking bandwidth of A3.
For the MLPerf™ Inference v4.0 benchmark testing, Google submitted 20 results across seven models, including the new Stable Diffusion XL and Llama 2 (70B) benchmarks, using A3 VMs:
-
RetinaNet (Server and Offline)
-
3D U-Net: 99% and 99.9% accuracy (Offline)
-
BERT: 99 and 99% accuracy (Server and Offline)
-
DLRM v2: 99.9% accuracy (Server and Offline)
-
GPT-J: 99% and 99% accuracy (Server and Offline)
-
Stable Diffusion XL (Server and Offline)
-
Llama 2: 99% and 99% accuracy (Server and Offline)
All results were within 0-5% of the peak performance demonstrated by NVIDIA’s submissions. These results are a testament to Google Cloud’s close partnership with NVIDIA to build workload-optimized end-to-end solutions specifically for LLMs and gen AI.
Powering the future of AI with Google Cloud TPUs and NVIDIA GPUs
Google's innovation in AI inference, powered by hardware advancements in Google Cloud TPUs and NVIDIA GPUs, plus software innovations such as JetStream, MaxText, and MaxDiffusion, empower our customers to build and scale AI applications. With JetStream, developers can achieve new levels of performance and cost efficiency in LLM inference, unlocking new opportunities for natural language processing applications. MaxDiffusion provides a foundation that empowers researchers and developers to explore the full potential of diffusion models to accelerate image generation. Our robust MLPerf™ 4.0 inference results on A3 VMs powered by NVIDIA H100 Tensor Core GPUs showcase the power and versatility of Cloud GPUs.
Visit our website to learn more and get started with Google Cloud TPU and GPU inference today.


