Ce guide explique comment automatiser le déploiement de SAP HANA dans un cluster à haute disponibilité Red Hat Enterprise Linux (RHEL) ou SUSE Linux Enterprise Server (SLES) utilisant l'équilibreur de charge réseau passthrough interne pour gérer l'adresse IP virtuelle.
Ce guide utilise Terraform pour déployer deux machines virtuelles (VM) Compute Engine, deux systèmes à évolutivité verticale SAP HANA, une adresse IP virtuelle avec implémentation d'un équilibreur de charge réseau passthrough interne et un cluster à haute disponibilité basé sur un système d'exploitation, le tout conformément aux bonnes pratiques de Google Cloud, de SAP et du fournisseur du système d'exploitation.
L'un des systèmes SAP HANA fonctionne en tant que système principal, actif, et l'autre en tant que système secondaire, de secours. Vous déployez les deux systèmes SAP HANA dans la même région, de préférence dans différentes zones.

Le cluster déployé inclut les fonctions et fonctionnalités suivantes :
- Le gestionnaire de ressources de cluster à haute disponibilité Pacemaker
- Un mécanisme de cloisonnement Google Cloud
- Une adresse IP virtuelle (VIP) avec mise en œuvre d'un équilibreur de charge interne TCP de niveau 4, y compris :
- Une réservation de l'adresse IP que vous choisissez comme adresse IP virtuelle
- Deux groupes d'instances Compute Engine
- Un équilibreur de charge interne TCP
- Une vérification de l'état Compute Engine
- Dans les clusters RHEL à haute disponibilité :
- Le modèle à haute disponibilité Red Hat
- Packages d'agent de ressources et de cloisonnement Red Hat
- Dans les clusters SLES à haute disponibilité :
- Le modèle à haute disponibilité SUSE
- Pour SLES pour SAP 15 SP6 ou version ultérieure, le package d'agent de ressources
SAPHanaSR-angiSUSE Pour les versions antérieures de SLES, le package d'agent de ressources SUSESAPHanaSR
- La réplication de système synchrone
- La précharge de mémoire
- Le redémarrage automatique de l'instance ayant échoué en tant que nouvelle instance secondaire
Si vous avez besoin d'un système à évolutivité horizontale avec des hôtes de secours pour le basculement automatique de l'hôte SAP HANA, vous devez consulter :Terraform: Guide de déploiement du système SAP HANA à scaling horizontal avec basculement automatique des hôtes.
Pour déployer un système SAP HANA sans cluster Linux à haute disponibilité ni hôtes de secours, consultez la page Terraform : Guide de déploiement de SAP HANA.
Ce guide est destiné aux utilisateurs avancés de SAP HANA qui connaissent bien les configurations Linux à haute disponibilité pour SAP HANA.
Prérequis
Avant de créer le cluster à haute disponibilité SAP HANA, assurez-vous que les conditions préalables suivantes sont remplies :
- Vous avez lu le guide de planification SAP HANA et le guide de planification de la haute disponibilité pour SAP HANA.
- Vous ou votre organisation disposez d'un compte Google Cloud et vous avez créé un projet pour le déploiement de SAP HANA. Pour en savoir plus sur la création de comptes et de projetsGoogle Cloud , consultez la section Configurer votre compte Google.
- Si vous souhaitez que votre charge de travail SAP s'exécute conformément aux exigences liées à la résidence des données, au contrôle des accès, au personnel d'assistance ou à la réglementation, vous devez créer le dossier Assured Workloads requis. Pour en savoir plus, consultez la page Contrôles de conformité et de souveraineté pour SAP sur Google Cloud.
Le support d'installation de SAP HANA se trouve dans un bucket Cloud Storage disponible dans votre projet et votre région de déploiement. Pour savoir comment importer le support d'installation de SAP HANA dans un bucket Cloud Storage, consultez la section Créer un bucket Cloud Storage pour les fichiers d'installation de SAP HANA.
Si OS Login est activé dans les métadonnées de votre projet, vous devrez le désactiver temporairement jusqu'à la fin du déploiement. Pour le déploiement, cette procédure configure les clés SSH dans les métadonnées d'instance. Lorsque OS Login est activé, les configurations de clé SSH basées sur les métadonnées sont désactivées et le déploiement échoue. Une fois le déploiement terminé, vous pouvez réactiver OS Login.
Pour en savoir plus, consultez les pages suivantes :
Si vous utilisez un DNS interne de VPC, la valeur de la variable
vmDnsSettingdans les métadonnées de votre projet doit êtreGlobalOnlyouZonalPreferredafin de permettre la résolution des noms de nœuds entre zones. La valeur par défaut devmDnsSettingestZonalOnly. Pour en savoir plus, consultez les pages suivantes :
Créer un réseau
Pour des raisons de sécurité, vous devez créer un réseau. Vous pourrez contrôler les accès en ajoutant des règles de pare-feu ou en utilisant une autre méthode.
Si votre projet dispose d'un réseau VPC par défaut, ne l'utilisez pas. À la place, créez votre propre réseau VPC afin que les seules règles de pare-feu appliquées soient celles que vous créez explicitement.
Lors du déploiement, les instances Compute Engine nécessitent généralement un accès à Internet pour télécharger l'agent Google Cloudpour SAP. Si vous utilisez l'une des images Linux certifiées SAP disponibles dans Google Cloud, l'instance de calcul nécessite également l'accès à Internet pour enregistrer la licence et accéder aux dépôts des fournisseurs d'OS. Une configuration comprenant une passerelle NAT et des tags réseau de VM permet aux instances de calcul cibles d'accéder à Internet même si elles ne possèdent pas d'adresses IP externes.
Pour créer un réseau VPC pour votre projet, procédez comme suit :
-
Créez un réseau en mode personnalisé. Pour plus d'informations, consultez la section Créer un réseau en mode personnalisé.
-
Créez un sous-réseau, puis spécifiez la région et la plage d'adresses IP. Pour plus d'informations, consultez la section Ajouter des sous-réseaux.
Configurer une passerelle NAT
Si vous devez créer une ou plusieurs VM sans adresse IP publique, vous devez utiliser la traduction d'adresse réseau (NAT) pour permettre aux VM d'accéder à Internet. Utilisez Cloud NAT, un service Google Cloud géré distribué et défini par logiciel qui permet aux VM d'envoyer des paquets sortants vers Internet et de recevoir tous les paquets de réponses entrants établis correspondants. Vous pouvez également configurer une VM distincte en tant que passerelle NAT.
Pour créer une instance Cloud NAT pour votre projet, consultez la page Utiliser Cloud NAT.
Une fois que vous avez configuré Cloud NAT pour votre projet, vos instances de VM peuvent accéder en toute sécurité à Internet sans adresse IP publique.
Ajouter des règles de pare-feu
Par défaut, une règle de pare-feu implicite bloque les connexions entrantes provenant de l'extérieur de votre réseau VPC (Virtual Private Cloud, cloud privé virtuel). Pour autoriser les connexions entrantes, configurez une règle de pare-feu pour votre VM. Une fois qu'une connexion entrante est établie avec une VM, le trafic est autorisé dans les deux sens via cette connexion.
Les clusters à haute disponibilité pour SAP HANA nécessitent au moins deux règles de pare-feu, une permettant la vérification de l'état des nœuds du cluster et une autre permettant aux nœuds du cluster de communiquer entre eux.Si vous n'utilisez pas de réseau VPC partagé, vous devez créer la règle de pare-feu destinée à la communication entre les nœuds, et non aux vérifications de l'état. Le fichier de configuration Terraform crée la règle de pare-feu destinée aux vérifications de l'état, que vous pouvez modifier une fois le déploiement terminé, si nécessaire.
Si vous utilisez un réseau VPC partagé, un administrateur réseau doit créer les deux règles de pare-feu dans le projet hôte.
Vous pouvez également créer une règle de pare-feu pour autoriser l'accès externe à des ports spécifiés ou pour limiter l'accès entre plusieurs VM d'un même réseau. Si le type de réseau VPC default est utilisé, d'autres règles par défaut s'appliquent également, telles que la règle default-allow-internal, qui permet la connectivité entre les VM d'un même réseau sur tous les ports.
En fonction de la stratégie informatique applicable à votre environnement, vous devrez peut-être isoler votre hôte de base de données, ou en restreindre la connectivité, en créant des règles de pare-feu.
Selon votre scénario, vous pouvez créer des règles de pare-feu afin d'autoriser l'accès pour ce qui suit :
- Ports SAP par défaut répertoriés dans le tableau listant les ports TCP/IP de tous les produits SAP.
- Connexions à partir de votre ordinateur ou de votre environnement de réseau d'entreprise à votre instance de VM Compute Engine. Si vous ne savez pas quelle adresse IP utiliser, contactez l'administrateur réseau de votre entreprise.
- Connexions SSH à votre instance de VM, y compris les connexions SSH-in-browser.
- Connexion à votre VM à l'aide d'un outil tiers sous Linux. Créez une règle autorisant l'accès de l'outil via votre pare-feu.
Consultez la section Créer des règles de pare-feu pour créer les règles de pare-feu de votre projet.
Créer un cluster Linux à haute disponibilité avec SAP HANA installé
Les instructions suivantes utilisent le fichier de configuration Terraform pour créer un cluster RHEL ou SLES avec deux systèmes SAP HANA : un système SAP HANA principal, à un seul hôte, sur une instance de VM, et un système SAP HANA de secours sur une autre instance de VM de la même région Compute Engine. Les systèmes SAP HANA utilisent la réplication de système synchrone, et le système de secours précharge les données répliquées.
Vous définissez les options de configuration du cluster à haute disponibilité SAP HANA dans un fichier de configuration Terraform.
Vérifiez que vos quotas actuels pour les ressources, telles que les disques persistants et les processeurs, sont suffisants pour les systèmes SAP HANA que vous allez installer. Si les quotas sont insuffisants, le déploiement échoue.
Pour connaître les exigences de quotas de SAP HANA, consultez la section Remarques concernant les tarifs et les quotas applicables à SAP HANA.
Ouvrez Cloud Shell.
Téléchargez dans votre répertoire de travail le fichier de configuration
sap_hana_ha.tfdu cluster à haute disponibilité SAP HANA :$wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/terraform/sap_hana_ha.tfOuvrez le fichier
sap_hana_ha.tfdans l'éditeur de code Cloud Shell.Pour ce faire, cliquez sur l'icône en forme de crayon située dans l'angle supérieur droit de la fenêtre du terminal Cloud Shell.
Dans le fichier
sap_hana_ha.tf, mettez à jour les valeurs d'argument en remplaçant le contenu entre guillemets doubles par les valeurs de votre installation. Les arguments sont décrits dans le tableau suivant.Argument Type de données Description sourceChaîne Spécifie l'emplacement et la version du module Terraform à utiliser lors du déploiement.
Le fichier de configuration
sap_hana_ha.tfcomprend deux instances de l'argumentsource: l'une active et l'autre incluse en tant que commentaire. L'argumentsourceactif par défaut spécifielatestcomme version de module. La deuxième instance de l'argumentsource, qui est désactivée par défaut par un caractère#de début, spécifie un horodatage qui identifie une version de module.Si vous avez besoin que tous vos déploiements utilisent la même version de module, supprimez le caractère
#de début de l'argumentsourcequi spécifie l'horodatage de la version, puis ajoutez-le à l'argumentsourcespécifiantlatest.project_idChaîne Spécifiez l'ID de votre projet Google Cloud dans lequel vous déployez ce système. Exemple : my-project-xmachine_typeChaîne Spécifiez le type de machine virtuelle (VM) Compute Engine sur lequel vous devez exécuter votre système SAP. Si vous avez besoin d'un type de VM personnalisé, spécifiez un type de VM prédéfini avec un nombre de processeurs virtuels le plus proche possible de la quantité dont vous avez besoin tout en étant légèrement supérieur. Une fois le déploiement terminé, modifiez le nombre de processeurs virtuels et la quantité de mémoire. Par exemple,
n1-highmem-32.sole_tenant_deploymentBooléen Facultatif. Si vous souhaitez provisionner un nœud propriétaire pour votre déploiement SAP HANA, spécifiez la valeur
true.La valeur par défaut est
false.Cet argument est disponible dans la version
1.3.704310921, ou ultérieure, desap_hana_ha.sole_tenant_name_prefixChaîne Facultatif. Si vous provisionnez un nœud propriétaire unique pour votre déploiement SAP HANA, vous pouvez utiliser cet argument pour spécifier un préfixe que Terraform définit pour les noms du modèle et du groupe propriétaire unique correspondants.
La valeur par défaut est
st-SID_LC.Pour en savoir plus sur les modèles et les groupes à locataire unique, consultez la section Présentation de la location unique.
Cet argument est disponible dans la version
1.3.704310921, ou ultérieure, desap_hana_ha.sole_tenant_node_typeChaîne Facultatif.Si vous souhaitez provisionner un nœud propriétaire unique pour votre déploiement SAP HANA, spécifiez le type de nœud que vous souhaitez définir pour le modèle de nœud correspondant.
Cet argument est disponible dans la version
1.3.704310921, ou ultérieure, desap_hana_ha.networkChaîne Indiquez le nom du réseau dans lequel vous devez créer l'équilibreur de charge qui gère l'adresse IP virtuelle. Si vous utilisez un réseau VPC partagé, vous devez ajouter l'ID du projet hôte en guise de répertoire parent du nom de réseau. Par exemple :
HOST_PROJECT_ID/NETWORK_NAME.subnetworkChaîne Spécifiez le nom du sous-réseau que vous avez créé à une étape précédente. Si vous procédez au déploiement sur un VPC partagé, spécifiez cette valeur en tant que SHARED_VPC_PROJECT_ID/SUBNETWORK. Exemple :myproject/network1.linux_imageChaîne Indiquez le nom de l'image du système d'exploitation Linux sur laquelle vous souhaitez déployer votre système SAP. Par exemple, rhel-9-2-sap-haousles-15-sp5-sap. Pour obtenir la liste des images de système d'exploitation disponibles, consultez la page Images dans la console Google Cloud .linux_image_projectChaîne Spécifiez le projet Google Cloud qui contient l'image que vous avez spécifiée pour l'argument linux_image. Il peut s'agir de votre propre projet ou d'un projet d'image Google Cloud . Pour une image Compute Engine, spécifiezrhel-sap-cloudoususe-sap-cloud. Pour trouver le projet d'image correspondant à votre système d'exploitation, consultez la page Détails des systèmes d'exploitation.primary_instance_nameChaîne Spécifiez le nom de l'instance de VM pour le système SAP HANA principal. Le nom peut contenir des lettres minuscules, des chiffres et des traits d'union. primary_zoneChaîne Spécifiez la zone dans laquelle le système SAP HANA principal est déployé. Les zones principale et secondaire doivent être dans la même région. Par exemple : us-east1-csecondary_instance_nameChaîne Spécifiez le nom de l'instance de VM pour le système SAP HANA secondaire. Le nom peut contenir des lettres minuscules, des chiffres et des traits d'union. secondary_zoneChaîne Spécifiez la zone dans laquelle le système SAP HANA secondaire est déployé. Les zones principale et secondaire doivent être dans la même région. Par exemple : us-east1-bsap_hana_deployment_bucketChaîne Pour installer automatiquement SAP HANA sur les VM déployées, spécifiez le chemin du bucket Cloud Storage contenant les fichiers d'installation de SAP HANA. N'incluez pas gs://dans le chemin. Incluez uniquement le nom du bucket et celui des dossiers. Exemple :my-bucket-name/my-folder.Le bucket Cloud Storage doit exister dans le projet Google Cloud que vous spécifiez pour l'argument
project_id.sap_hana_sidChaîne Pour installer automatiquement SAP HANA sur les VM déployées, spécifiez l'ID système SAP HANA. L'ID doit comporter trois caractères alphanumériques et commencer par une lettre. Toutes les lettres doivent être en majuscules. Par exemple, ED1.sap_hana_instance_numberEntier Facultatif. Spécifiez le numéro d'instance (0 à 99) du système SAP HANA. La valeur par défaut est 0.sap_hana_sidadm_passwordChaîne Pour installer automatiquement SAP HANA sur les VM déployées, spécifiez un mot de passe SIDadmtemporaire pour les scripts d'installation à utiliser lors du déploiement. Le mot de passe doit contenir au moins huit caractères et inclure au moins une lettre majuscule, une lettre minuscule et un chiffre.Au lieu de spécifier le mot de passe en texte brut, nous vous recommandons d'utiliser un secret. Pour en savoir plus, consultez la section Gestion des mots de passe.
sap_hana_sidadm_password_secretChaîne Facultatif. Si vous utilisez Secret Manager pour stocker le mot de passe SIDadm, spécifiez le nom du secret correspondant à ce mot de passe.Dans Secret Manager, assurez-vous que la valeur du secret, qui correspond au mot de passe, contient au moins huit caractères et au moins une lettre majuscule, une lettre minuscule et un chiffre.
Pour en savoir plus, consultez la section Gestion des mots de passe.
sap_hana_system_passwordChaîne Pour installer automatiquement SAP HANA sur les VM déployées, spécifiez le mot de passe temporaire d'un super-utilisateur de base de données pour les scripts d'installation à utiliser lors du déploiement. Le mot de passe doit contenir au moins huit caractères et inclure au moins une lettre majuscule, une lettre minuscule et un chiffre. Au lieu de spécifier le mot de passe en texte brut, nous vous recommandons d'utiliser un secret. Pour en savoir plus, consultez la section Gestion des mots de passe.
sap_hana_system_password_secretChaîne Facultatif. Si vous utilisez Secret Manager pour stocker le mot de passe du super-utilisateur de la base de données, spécifiez le nom du secret correspondant à ce mot de passe. Dans Secret Manager, assurez-vous que la valeur du secret, qui correspond au mot de passe, contient au moins huit caractères et au moins une lettre majuscule, une lettre minuscule et un chiffre.
Pour en savoir plus, consultez la section Gestion des mots de passe.
sap_hana_double_volume_sizeBooléen Facultatif. Pour doubler la taille du volume HANA, spécifiez true. Cet argument est utile lorsque vous souhaitez déployer plusieurs instances SAP HANA ou une instance SAP HANA de reprise après sinistre sur la même VM. Par défaut, la taille du volume est calculée automatiquement pour correspondre à la taille minimale requise pour votre VM, tout en respectant les exigences de certification et de compatibilité SAP. La valeur par défaut estfalse.sap_hana_backup_sizeEntier Facultatif. Spécifiez la taille du volume /hanabackupen Go. Si vous ne spécifiez pas cet argument ou si vous le définissez sur0, le script d'installation provisionne l'instance Compute Engine avec un volume de sauvegarde HANA de deux fois la mémoire totale.sap_hana_sidadm_uidEntier Facultatif. Spécifiez une valeur pour remplacer la valeur par défaut de l'ID de l'utilisateur administrateur SID_LC. La valeur par défaut est 900. Vous pouvez la remplacer par une autre valeur pour garantir la cohérence dans votre environnement SAP.sap_hana_sapsys_gidEntier Facultatif. Remplace l'ID de groupe par défaut défini pour sapsys. La valeur par défaut est79.sap_vipChaîne Facultatif. Adresse IP utilisée en guise d'adresse IP virtuelle. L'adresse IP doit être comprise dans la plage d'adresses IP qui sont attribuées à votre sous-réseau. Le fichier de configuration Terraform réserve cette adresse IP pour vous.
À partir de la version
1.3.730053050du modulesap_hana_ha, l'argumentsap_vipest facultatif. Si vous ne le spécifiez pas, Terraform attribue automatiquement une adresse IP disponible à partir du sous-réseau que vous spécifiez pour l'argumentsubnetwork.primary_instance_group_nameChaîne Facultatif. Spécifiez le nom du groupe d'instances non géré pour le nœud principal. Le nom par défaut est ig-PRIMARY_INSTANCE_NAME.secondary_instance_group_nameChaîne Facultatif. Spécifiez le nom du groupe d'instances non géré pour le nœud secondaire. Le nom par défaut est ig-SECONDARY_INSTANCE_NAME.loadbalancer_nameChaîne Facultatif. Spécifiez le nom de l'équilibreur de charge réseau passthrough interne. Le nom par défaut est lb-SAP_HANA_SID-ilb.network_tagsChaîne Facultatif. Spécifiez un ou plusieurs tags réseau séparés par une virgule que vous souhaitez associer à vos instances de VM à des fins de routage ou de pare-feu. Un tag réseau pour les composants ILB est automatiquement ajouté aux tags réseau de la VM.
nic_typeChaîne Facultatif. Spécifie l'interface réseau à utiliser avec l'instance de VM. Vous pouvez spécifier la valeur GVNICouVIRTIO_NET. Pour utiliser une carte d'interface réseau virtuelle Google (gVNIC), vous devez spécifier une image de l'OS compatible avec gVNIC comme valeur de l'argumentlinux_image. Pour obtenir la liste des images de l'OS, consultez la section Détails des systèmes d'exploitation.Si vous ne spécifiez pas de valeur pour cet argument, l'interface réseau est automatiquement sélectionnée en fonction du type de machine que vous spécifiez pour l'argument
Cet argument est disponible dans la versionmachine_type.202302060649, ou ultérieure, du modulesap_hana.disk_typeChaîne Facultatif. Spécifiez le type de volume Persistent Disk ou Hyperdisk par défaut que vous souhaitez déployer pour les volumes de données et de journaux SAP de votre déploiement. Pour en savoir plus sur le déploiement de disque par défaut effectué par les configurations Terraform fournies par Google Cloud, consultez la section Déploiement de disque par Terraform. Voici des valeurs valides pour cet argument :
pd-ssd,pd-balanced,hyperdisk-extreme,hyperdisk-balancedetpd-extreme. Dans les déploiements SAP HANA avec scaling à la hausse, un disque persistant avec équilibrage distinct est également déployé pour le répertoire/hana/shared.Vous pouvez remplacer ce type de disque par défaut, ainsi que la taille de disque par défaut et les IOPS par défaut à l'aide de certains arguments avancés. Pour en savoir plus, accédez à votre répertoire de travail, exécutez la commande
terraform init, puis consultez le fichier/.terraform/modules/sap_hana_ha/variables.tf. Avant d'utiliser ces arguments en production, veillez à les tester dans un environnement hors production.Si vous souhaitez utiliser la Native Storage Extension (NSE) de SAP HANA, vous devez provisionner des disques plus volumineux à l'aide des arguments avancés.
use_single_shared_data_log_diskBooléen Facultatif. La valeur par défaut est false, qui indique à Terraform de déployer un disque persistant ou un hyperdisque distinct pour chacun des volumes SAP suivants :/hana/data,/hana/log,/hana/sharedet/usr/sap. Pour installer ces volumes SAP sur le même disque persistant ou hyperdisque, spécifieztrue.enable_data_stripingBooléen Facultatif. Cet argument vous permet de déployer le volume /hana/datasur deux disques. La valeur par défaut estfalse, ce qui indique à Terraform de déployer un seul disque pour héberger votre volume/hana/data.Cet argument est disponible dans la version
1.3.674800406, ou ultérieure, du modulesap_hana_ha.include_backup_diskBooléen Facultatif. Cet argument s'applique aux déploiements SAP HANA à scaling à la hausse. La valeur par défaut est true, ce qui indique à Terraform de déployer un disque distinct pour héberger le répertoire/hanabackup.Le type de disque est déterminé par l'argument
backup_disk_type. La taille de ce disque est déterminée par l'argumentsap_hana_backup_size.Si vous définissez la valeur de
include_backup_disksurfalse, aucun disque n'est déployé pour le répertoire/hanabackup.backup_disk_typeChaîne Facultatif. Pour les déploiements supposant un scaling vertical, spécifiez le type de disque persistant ou d'hyperdisque que vous souhaitez déployer pour le volume /hanabackup. Pour en savoir plus sur le déploiement de disque par défaut effectué par les configurations Terraform fournies par Google Cloud, consultez la section Déploiement de disque par Terraform.Voici des valeurs valides pour cet argument :
pd-ssd,pd-balanced,pd-standard,hyperdisk-extreme,hyperdisk-balancedetpd-extreme.Cet argument est disponible dans la version
202307061058, ou ultérieure, du modulesap_hana_ha.enable_fast_restartBooléen Facultatif. Cet argument détermine si l'option Fast Restart pour SAP HANA est activée ou non pour votre déploiement. La valeur par défaut est true. Google Cloud recommande vivement d'activer l'option Fast Restart pour SAP HANA.Cet argument est disponible dans la version
202309280828, ou ultérieure, du modulesap_hana_ha.public_ipBooléen Facultatif. Détermine si une adresse IP publique est ajoutée ou non à votre instance de VM. La valeur par défaut est true.service_accountChaîne Facultatif. Spécifiez l'adresse e-mail d'un compte de service géré par l'utilisateur qui sera utilisée par les VM hôtes et par les programmes qui s'exécutent sur celles-ci. Par exemple, svc-acct-name@project-id..Si vous spécifiez cet argument sans valeur ou si vous l'omettez, le script d'installation utilise le compte de service Compute Engine par défaut. Pour en savoir plus, consultez la page Gestion de l'authentification et des accès pour les programmes SAP sur Google Cloud.
sap_deployment_debugBooléen Facultatif. Lorsque Cloud Customer Care vous demande d'activer le débogage pour votre déploiement, spécifiez true, qui permet au déploiement de générer des journaux de déploiement détaillés. La valeur par défaut estfalse.primary_reservation_nameChaîne Facultatif. Si vous souhaitez utiliser une réservation de VM Compute Engine spécifique pour le provisionnement de l'instance de VM qui héberge l'instance SAP HANA principale de votre cluster à haute disponibilité, spécifiez le nom de la réservation. Par défaut, le script d'installation sélectionne toute réservation Compute Engine disponible en fonction des conditions suivantes. Que vous définissiez son nom ou que le script d'installation le sélectionne automatiquement, la réservation doit être définie comme suit pour être utilisable :
-
L'option
specificReservationRequiredest définie surtrueou, dans la console Google Cloud , l'option Sélectionner une réservation spécifique est sélectionnée. -
Certains types de machines Compute Engine sont compatibles avec les plates-formes de processeur qui ne sont pas couvertes par la certification SAP de ce type de machine. Si la réservation cible concerne l'un des types de machines suivants, la réservation doit spécifier les plates-formes de processeur minimales, comme indiqué :
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Les plates-formes de processeur minimales pour tous les autres types de machines certifiés par SAP pour une utilisation sur Google Cloud sont conformes à la configuration minimale requise de processeur SAP.
secondary_reservation_nameChaîne Facultatif. Si vous souhaitez utiliser une réservation de VM Compute Engine spécifique pour le provisionnement de l'instance de VM qui héberge l'instance SAP HANA secondaire de votre cluster à haute disponibilité, spécifiez le nom de la réservation. Par défaut, le script d'installation sélectionne toute réservation Compute Engine disponible en fonction des conditions suivantes. Que vous définissiez son nom ou que le script d'installation le sélectionne automatiquement, la réservation doit être définie comme suit pour être utilisable :
-
L'option
specificReservationRequiredest définie surtrueou, dans la console Google Cloud , l'option Sélectionner une réservation spécifique est sélectionnée. -
Certains types de machines Compute Engine sont compatibles avec les plates-formes de processeur qui ne sont pas couvertes par la certification SAP de ce type de machine. Si la réservation cible concerne l'un des types de machines suivants, la réservation doit spécifier les plates-formes de processeur minimales, comme indiqué :
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Les plates-formes de processeur minimales pour tous les autres types de machines certifiés par SAP pour une utilisation sur Google Cloud sont conformes à la configuration minimale requise de processeur SAP.
primary_static_ipChaîne Facultatif. Spécifiez une adresse IP statique valide pour l'instance de VM principale dans votre cluster à haute disponibilité. Si vous n'en spécifiez pas, une adresse IP est automatiquement générée pour votre instance de VM. Par exemple, 128.10.10.10.Cet argument est disponible dans la version
202306120959, ou ultérieure, du modulesap_hana_ha.secondary_static_ipChaîne Facultatif. Spécifiez une adresse IP statique valide pour l'instance de VM secondaire dans votre cluster à haute disponibilité. Si vous n'en spécifiez pas, une adresse IP est automatiquement générée pour votre instance de VM. Par exemple, 128.11.11.11.Cet argument est disponible dans la version
202306120959, ou ultérieure, du modulesap_hana_ha.can_ip_forwardBooléen Indiquez si l'envoi et la réception de paquets avec des adresses IP sources ou de destination qui ne correspondent pas sont autorisés, ce qui permet à une VM de fonctionner comme un routeur. La valeur par défaut est
true.Si vous souhaitez uniquement utiliser les équilibreurs de charge internes de Google pour gérer les adresses IP virtuelles des VM déployées, définissez la valeur sur
false. Un équilibreur de charge interne est automatiquement déployé dans le cadre des modèles haute disponibilité.Les exemples suivants montrent un fichier de configuration terminé qui définit un cluster à haute disponibilité pour SAP HANA. Le cluster gère les adresses IP virtuelles à l'aide d'un équilibreur de charge réseau passthrough interne.
Terraform déploie les ressources Google Clouddéfinies dans le fichier de configuration, puis les scripts prennent le relais pour configurer le système d'exploitation, installer SAP HANA, configurer la réplication et configurer le cluster Linux à haute disponibilité.
Cliquez sur
RHELouSLESpour afficher l'exemple spécifique à votre système d'exploitation. Pour plus de clarté, les commentaires du fichier de configuration sont omis dans les exemples.RHEL
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "rhel-8-4-sap-ha" linux_image_project = "rhel-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456." primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }SLES
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "sles-15-sp3-sap" linux_image_project = "suse-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456." primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }-
L'option
Initialisez votre répertoire de travail actuel et téléchargez le plug-in et les fichiers de modules du fournisseur Terraform pour Google Cloud:
terraform init
La commande
terraform initprépare votre répertoire de travail pour d'autres commandes Terraform.Pour forcer l'actualisation du plug-in du fournisseur et des fichiers de configuration dans votre répertoire de travail, spécifiez l'option
--upgrade. Si l'option--upgradeest omise et que vous n'apportez aucune modification à votre répertoire de travail, Terraform utilise les copies mises en cache localement, même silatestest spécifié dans l'URLsource.terraform init --upgrade
Vous pouvez également créer le plan d'exécution Terraform :
terraform plan
La commande
terraform planaffiche les modifications requises par votre configuration actuelle. Si vous ignorez cette étape, la commandeterraform applycrée automatiquement un plan et vous invite à l'approuver.Appliquez le plan d'exécution :
terraform apply
Lorsque vous êtes invité à approuver les actions, saisissez
yes.La commande
terraform applyconfigure l'infrastructure Google Cloud , puis donne le contrôle à un script qui configure le cluster HA et installe SAP HANA en fonction des arguments définis dans le fichier de configuration Terraform.Lorsque Terraform a le contrôle, les messages d'état sont écrits dans Cloud Shell. Une fois les scripts appelés, les messages d'état sont écrits dans Logging et peuvent être consultés dans la console Google Cloud , comme décrit dans la section Vérifier les journaux.
Vérifier le déploiement de votre système à haute disponibilité HANA
La vérification d'un cluster à haute disponibilité SAP HANA implique plusieurs procédures différentes :
- Vérifier la journalisation
- Vérifier la configuration de la VM et l'installation de SAP HANA
- Vérifier la configuration du cluster
- Vérifier l'équilibreur de charge et l'état des groupes d'instances
- Vérifier le système SAP HANA à l'aide de SAP HANA Studio
- Effectuer un test de basculement
Vérifier les journaux
Dans la console Google Cloud , ouvrez Cloud Logging pour surveiller la progression de l'installation et rechercher les erreurs.
Filtrez les journaux :
Explorateur de journaux
Sur la page Explorateur de journaux, accédez au volet Requête.
Dans le menu déroulant Ressource, sélectionnez Global, puis cliquez sur Ajouter.
Si l'option Global n'apparaît pas, saisissez la requête suivante dans l'éditeur de requête :
resource.type="global" "Deployment"Cliquez sur Exécuter la requête.
Ancienne visionneuse de journaux
- Sur la page Ancienne visionneuse de journaux, dans le menu de sélection de base, sélectionnez Global comme ressource de journalisation.
Analysez les journaux filtrés :
- Si
"--- Finished"s'affiche, le traitement du déploiement est terminé, et vous pouvez passer à l'étape suivante. Si vous rencontrez une erreur de quota :
Sur la page Quotas de IAM & Admin, augmentez les quotas qui ne répondent pas aux exigences de SAP HANA décrites dans le guide de planification SAP HANA.
Ouvrez Cloud Shell.
Accédez à votre répertoire de travail et supprimez le déploiement pour nettoyer les VM et les disques persistants de l'installation ayant échoué :
terraform destroy
Lorsque vous êtes invité à approuver l'action, saisissez
yes.Réexécutez le déploiement.
- Si
Vérifier la configuration de la VM et l'installation de SAP HANA
Une fois le système SAP HANA déployé sans erreur, connectez-vous à chaque VM à l'aide du protocole SSH. Sur la page VM instances (Instances de VM) de Compute Engine, cliquez sur le bouton SSH de votre instance de VM ou utilisez la méthode SSH de votre choix.

Connectez-vous en tant qu'utilisateur racine.
sudo su -
À l'invite de commande, saisissez
df -h. Assurez-vous d'obtenir un résultat comprenant les répertoires/hana, par exemple/hana/data.RHEL
[root@example-ha-vm1 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 0 126G 0% /dev tmpfs 126G 54M 126G 1% /dev/shm tmpfs 126G 25M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda2 30G 5.4G 25G 18% / /dev/sda1 200M 6.9M 193M 4% /boot/efi /dev/mapper/vg_hana-shared 251G 52G 200G 21% /hana/shared /dev/mapper/vg_hana-sap 32G 477M 32G 2% /usr/sap /dev/mapper/vg_hana-data 426G 9.8G 417G 3% /hana/data /dev/mapper/vg_hana-log 125G 7.0G 118G 6% /hana/log /dev/mapper/vg_hanabackup-backup 512G 9.3G 503G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/899 tmpfs 26G 0 26G 0% /run/user/1003
SLES
example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 54M 189G 1% /dev/shm tmpfs 126G 34M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 30G 5.4G 25G 18% / /dev/sda2 20M 2.9M 18M 15% /boot/efi /dev/mapper/vg_hana-shared 251G 50G 202G 20% /hana/shared /dev/mapper/vg_hana-sap 32G 281M 32G 1% /usr/sap /dev/mapper/vg_hana-data 426G 8.0G 418G 2% /hana/data /dev/mapper/vg_hana-log 125G 4.3G 121G 4% /hana/log /dev/mapper/vg_hanabackup-backup 512G 6.4G 506G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/473 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1003
Vérifiez l'état du nouveau cluster en saisissant la commande d'état spécifique à votre système d'exploitation :
RHEL
pcs statusSLES
crm statusLe résultat ressemble à l'exemple suivant, dans lequel les deux instances de VM sont démarrées, et où
example-ha-vm1correspond à l'instance principale active:RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.4-4b1f869f0f) - partition with quorum * Last updated: Wed Jul 7 23:05:11 2021 * Last change: Wed Jul 7 23:04:43 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ] Failed Resource Actions: * rsc_healthcheck_HA1_start_0 on example-ha-vm1 'error' (1): call=29, status='complete', exitreason='', last-rc-change='2021-07-07 21:07:35Z', queued=0ms, exec=2097ms * SAPHana_HA1_00_monitor_61000 on example-ha-vm1 'not running' (7): call=44, status='complete', exitreason='', last-rc-change='2021-07-07 21:09:49Z', queued=0ms, exec=0ms Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledSLES pour SAP 15 SP5 ou version antérieure
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Wed Jul 7 22:57:59 2021 * Last change: Wed Jul 7 22:57:03 2021 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]SLES pour SAP 15 SP6 ou version ultérieure
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Mon Oct 7 22:57:59 2024 * Last change: Mon Oct 7 22:57:03 2024 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]Connectez-vous en tant qu'administrateur SAP en remplaçant SID_LC dans la commande suivante par la valeur
sap_hana_sidque vous avez spécifiée dans le fichiersap_hana_ha.tf. La valeur SID_LC doit être en minuscules.su - SID_LCadmAssurez-vous que les services SAP HANA, tels que
hdbnameserver,hdbindexserveret autres services, s'exécutent sur l'instance en saisissant la commande suivante :HDB infoSi vous utilisez RHEL pour SAP 9.0 ou une version ultérieure, assurez-vous que les packages
chkconfigetcompat-openssl11sont installés sur votre instance de VM.Pour en savoir plus, consultez la note SAP 3108316 – Red Hat Enterprise Linux 9.x : installation et configuration.
Vérifier la configuration du cluster
Vérifiez les paramètres du cluster. Vérifiez les paramètres affichés par le logiciel du cluster et les paramètres qui s'affichent dans le fichier de configuration du cluster. Comparez vos paramètres aux paramètres des exemples ci-dessous, qui ont été créés par les scripts d'automatisation utilisés dans ce guide.
Cliquez sur l'onglet correspondant à votre système d'exploitation.
RHEL
Affichez les configurations des ressources du cluster :
pcs config show
L'exemple suivant présente les configurations de ressources créées par les scripts d'automatisation sur RHEL 8.1 et versions ultérieures.
Si vous exécutez RHEL 7.7 ou une version antérieure, la définition de la ressource
Clone: SAPHana_HA1_00-clonen'inclut pasMeta Attrs: promotable=true.Cluster Name: hacluster Corosync Nodes: example-rha-vm1 example-rha-vm2 Pacemaker Nodes: example-rha-vm1 example-rha-vm2 Resources: Group: g-primary Resource: rsc_healthcheck_HA1 (class=service type=haproxy) Operations: monitor interval=10s timeout=20s (rsc_healthcheck_HA1-monitor-interval-10s) start interval=0s timeout=100 (rsc_healthcheck_HA1-start-interval-0s) stop interval=0s timeout=100 (rsc_healthcheck_HA1-stop-interval-0s) Resource: rsc_vip_HA1_00 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=32 ip=10.128.15.100 nic=eth0 Operations: monitor interval=3600s timeout=60s (rsc_vip_HA1_00-monitor-interval-3600s) start interval=0s timeout=20s (rsc_vip_HA1_00-start-interval-0s) stop interval=0s timeout=20s (rsc_vip_HA1_00-stop-interval-0s) Clone: SAPHanaTopology_HA1_00-clone Meta Attrs: clone-max=2 clone-node-max=1 interleave=true Resource: SAPHanaTopology_HA1_00 (class=ocf provider=heartbeat type=SAPHanaTopology) Attributes: InstanceNumber=00 SID=HA1 Operations: methods interval=0s timeout=5 (SAPHanaTopology_HA1_00-methods-interval-0s) monitor interval=10 timeout=600 (SAPHanaTopology_HA1_00-monitor-interval-10) reload interval=0s timeout=5 (SAPHanaTopology_HA1_00-reload-interval-0s) start interval=0s timeout=600 (SAPHanaTopology_HA1_00-start-interval-0s) stop interval=0s timeout=300 (SAPHanaTopology_HA1_00-stop-interval-0s) Clone: SAPHana_HA1_00-clone Meta Attrs: promotable=true Resource: SAPHana_HA1_00 (class=ocf provider=heartbeat type=SAPHana) Attributes: AUTOMATED_REGISTER=true DUPLICATE_PRIMARY_TIMEOUT=7200 InstanceNumber=00 PREFER_SITE_TAKEOVER=true SID=HA1 Meta Attrs: clone-max=2 clone-node-max=1 interleave=true notify=true Operations: demote interval=0s timeout=3600 (SAPHana_HA1_00-demote-interval-0s) methods interval=0s timeout=5 (SAPHana_HA1_00-methods-interval-0s) monitor interval=61 role=Slave timeout=700 (SAPHana_HA1_00-monitor-interval-61) monitor interval=59 role=Master timeout=700 (SAPHana_HA1_00-monitor-interval-59) promote interval=0s timeout=3600 (SAPHana_HA1_00-promote-interval-0s) reload interval=0s timeout=5 (SAPHana_HA1_00-reload-interval-0s) start interval=0s timeout=3600 (SAPHana_HA1_00-start-interval-0s) stop interval=0s timeout=3600 (SAPHana_HA1_00-stop-interval-0s) Stonith Devices: Resource: STONITH-example-rha-vm1 (class=stonith type=fence_gce) Attributes: pcmk_delay_max=30 pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm1 project=example-project-123456 zone=us-central1-a Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm1-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm1-start-interval-0) Resource: STONITH-example-rha-vm2 (class=stonith type=fence_gce) Attributes: pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm2 project=example-project-123456 zone=us-central1-c Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm2-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm2-start-interval-0) Fencing Levels: Location Constraints: Resource: STONITH-example-rha-vm1 Disabled on: example-rha-vm1 (score:-INFINITY) (id:location-STONITH-example-rha-vm1-example-rha-vm1--INFINITY) Resource: STONITH-example-rha-vm2 Disabled on: example-rha-vm2 (score:-INFINITY) (id:location-STONITH-example-rha-vm2-example-rha-vm2--INFINITY) Ordering Constraints: start SAPHanaTopology_HA1_00-clone then start SAPHana_HA1_00-clone (kind:Mandatory) (non-symmetrical) (id:order-SAPHanaTopology_HA1_00-clone-SAPHana_HA1_00-clone-mandatory) Colocation Constraints: g-primary with SAPHana_HA1_00-clone (score:4000) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-g-primary-SAPHana_HA1_00-clone-4000) Ticket Constraints: Alerts: No alerts defined Resources Defaults: migration-threshold=5000 resource-stickiness=1000 Operations Defaults: timeout=600s Cluster Properties: cluster-infrastructure: corosync cluster-name: hacluster dc-version: 2.0.2-3.el8_1.2-744a30d655 have-watchdog: false stonith-enabled: true stonith-timeout: 300s Quorum: Options:Affichez le fichier de configuration de votre cluster,
corosync.conf:cat /etc/corosync/corosync.conf
L'exemple suivant présente les paramètres définis par les scripts d'automatisation pour RHEL 8.1 et versions ultérieures.
Si vous utilisez RHEL 7.7 ou une version antérieure, la valeur de
transport:estudpuau lieu deknet:totem { version: 2 cluster_name: hacluster transport: knet join: 60 max_messages: 20 token: 20000 token_retransmits_before_loss_const: 10 crypto_cipher: aes256 crypto_hash: sha256 } nodelist { node { ring0_addr: example-rha-vm1 name: example-rha-vm1 nodeid: 1 } node { ring0_addr: example-rha-vm2 name: example-rha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum two_node: 1 } logging { to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes timestamp: on }
SLES pour SAP 15 SP5 ou version antérieure
Affichez les configurations des ressources du cluster :
crm config show
Les scripts d'automatisation utilisés par ce guide créent les configurations de ressources présentées dans l'exemple suivant :
node 1: example-ha-vm1 \ attributes hana_ha1_op_mode=logreplay lpa_ha1_lpt=1635380335 hana_ha1_srmode=syncmem hana_ha1_vhost=example-ha-vm1 hana_ha1_remoteHost=example-ha-vm2 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes lpa_ha1_lpt=30 hana_ha1_op_mode=logreplay hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 hana_ha1_srmode=syncmem hana_ha1_remoteHost=example-ha-vm1 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHana \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta notify=true clone-max=2 clone-node-max=1 target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Affichez le fichier de configuration de votre cluster,
corosync.conf:cat /etc/corosync/corosync.conf
Les scripts d'automatisation utilisés par ce guide spécifient les paramètres dans le fichier
corosync.conf, comme indiqué dans l'exemple suivant :totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
SLES pour SAP 15 SP6 ou version ultérieure
Affichez les configurations des ressources du cluster :
crm config show
Les scripts d'automatisation utilisés par ce guide créent les configurations de ressources présentées dans l'exemple suivant :
node 1: example-ha-vm1 \ attributes hana_ha1_vhost=example-ha-vm1 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHanaFileSystem_HA1_HDB00 ocf:suse:SAPHanaFilesystem \ operations $id=rsc_sap3_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHanaController \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Promoted timeout=700 \ op monitor interval=61 role=Unpromoted timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 clone mst_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta clone-node-max=1 promotable=true interleave=true clone cln_SAPHanaFileSystem_HA1_HDB00 rsc_SAPHanaFileSystem_HA1_HDB00 \ meta clone-node-max=1 interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started mst_SAPHana_HA1_HDB00:Promoted order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 mst_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Affichez le fichier de configuration de votre cluster,
corosync.conf:cat /etc/corosync/corosync.conf
Les scripts d'automatisation utilisés par ce guide spécifient les paramètres dans le fichier
corosync.conf, comme indiqué dans l'exemple suivant :totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
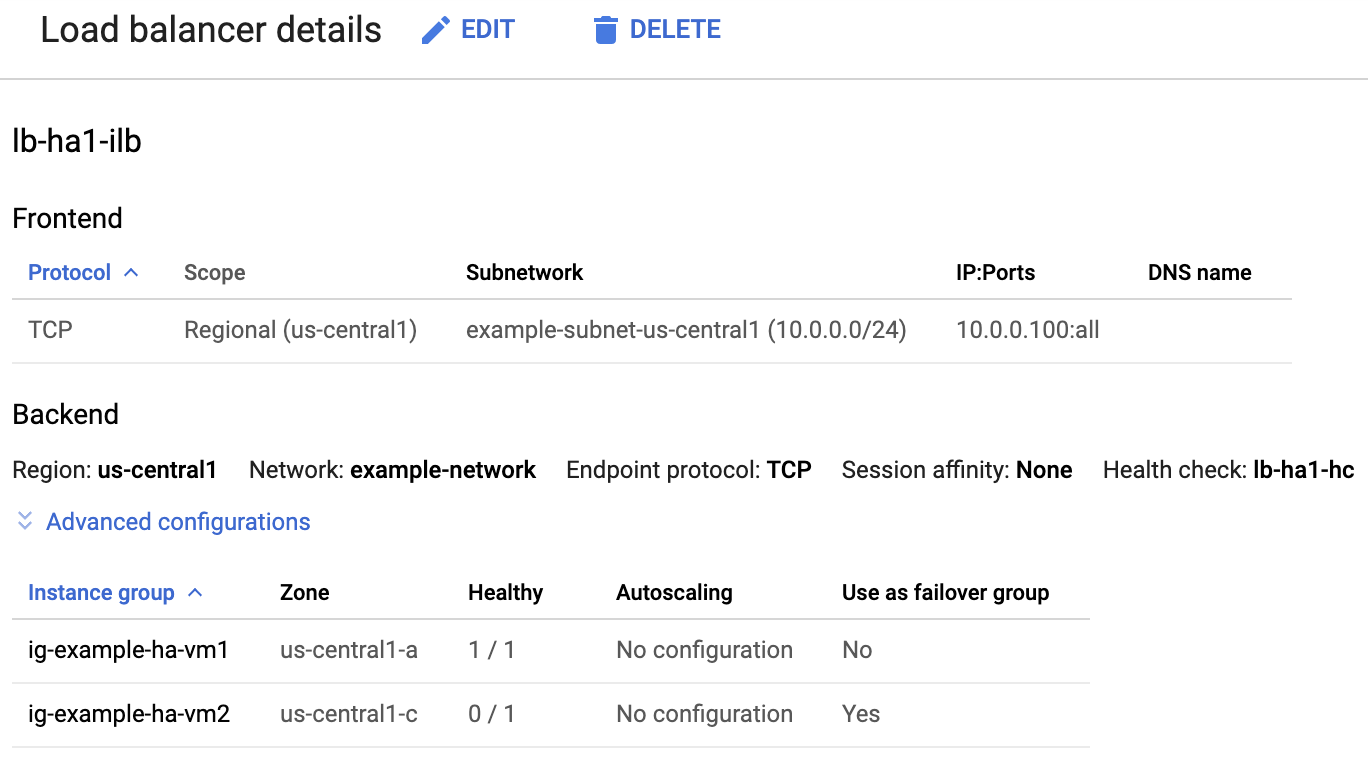
Vérifier l'équilibreur de charge et l'état des groupes d'instances
Pour vérifier que l'équilibreur de charge et la vérification de l'état ont été correctement configurés, vérifiez l'équilibreur de charge et les groupes d'instances dans la console Google Cloud .
Ouvrez la page Équilibrage de charge dans la console Google Cloud :
Dans la liste des équilibreurs de charge, vérifiez qu'un équilibreur de charge a été créé pour votre cluster à haute disponibilité.
Sur la page d'Informations sur l'équilibreur de charge, dans la colonne Opérationnel sous Groupe d'instances, dans la section Backend, confirmez que l'un des groupes d'instances indique "1/1" et l'autre "0/1". Après un failover, l'indicateur opérationnel "1/1" bascule sur le nouveau groupe d'instances actif.
Vérifier le système SAP HANA à l'aide de SAP HANA Studio
Vous pouvez utiliser SAP HANA Cockpit ou SAP HANA Studio pour surveiller et gérer vos systèmes SAP HANA dans un cluster à haute disponibilité.
Connectez-vous au système HANA à l'aide de SAP HANA Studio. Lors de la définition de la connexion, spécifiez les valeurs suivantes :
- Dans le volet "Specify System" (Spécifier le système), spécifiez l'adresse IP flottante comme nom d'hôte.
- Dans le panneau "Propriétés de connexion", pour l'authentification de l'utilisateur de la base de données, spécifiez le nom de super-utilisateur de la base de données, ainsi que le mot de passe que vous avez spécifié pour l'argument
sap_hana_system_passworddans le fichiersap_hana_ha.tf.
Pour en savoir plus sur l'installation de SAP HANA Studio, consultez sur le site de SAP le Guide d'installation et de mise à jour de SAP HANA Studio.
Une fois SAP HANA Studio connecté à votre système à haute disponibilité HANA, affichez la vue d'ensemble du système en double-cliquant sur le nom du système dans le volet de navigation situé sur la gauche de la fenêtre.
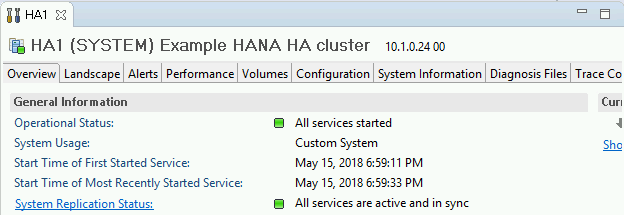
Dans l'onglet "Overview" (Aperçu), sous "General Information" (Informations générales), vérifiez les éléments suivants :
- L'élément "Operational Status" (État opérationnel) indique "All services started" (Tous les services sont démarrés).
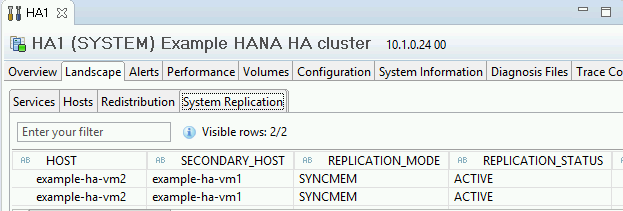
- L'élément "System Replication Status" (État de la réplication du système) indique "All services are active and in sync" (Tous les services sont actifs et synchronisés).
Confirmez le mode de réplication en cliquant sur le lien System Replication Status (État de la réplication du système) sous "General Information" (Informations générales). La réplication synchrone est indiquée par
SYNCMEMdans la colonne REPLICATION_MODE (Mode de réplication) de l'onglet "System Replication" (Réplication système).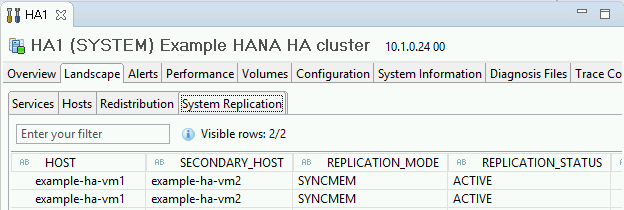
Nettoyer et réessayer le déploiement
Si l'une des étapes de vérification du déploiement des sections précédentes indique que l'installation a échoué, vous devez annuler votre déploiement et réessayer en procédant comme suit :
Corrigez les erreurs pour vous assurer que votre déploiement n'échouera pas à nouveau pour la même raison. Pour en savoir plus sur la vérification des journaux ou la résolution des erreurs liées aux quotas, consultez la section Vérifier les journaux.
Ouvrez Cloud Shell ou, si vous avez installé Google Cloud CLI sur votre poste de travail local, ouvrez un terminal.
Accédez au répertoire contenant le fichier de configuration Terraform que vous avez utilisé pour ce déploiement.
Supprimez toutes les ressources faisant partie de votre déploiement en exécutant la commande suivante :
terraform destroy
Lorsque vous êtes invité à approuver l'action, saisissez
yes.Relancez le déploiement comme indiqué précédemment dans ce guide.
Effectuer un test de basculement
Pour effectuer un test de basculement, procédez comme suit :
Connectez-vous à la VM principale à l'aide de SSH. Vous pouvez vous connecter à partir de la page Instances de VM de Compute Engine en cliquant sur le bouton "SSH" de chaque instance de VM. Vous avez également la possibilité d'utiliser la méthode SSH de votre choix.
À l'invite, saisissez la commande suivante :
sudo ip link set eth0 down
La commande
ip link set eth0 downdéclenche un basculement en coupant les communications avec l'hôte principal.Reconnectez-vous à l'un des hôtes à l'aide de SSH, puis connectez-vous en tant qu'utilisateur racine.
Confirmez que l'hôte principal est désormais actif sur la VM qui contenait l'hôte secondaire. Le redémarrage automatique est activé dans le cluster. Par conséquent, l'hôte arrêté redémarre et prend le rôle d'hôte secondaire.
RHEL
pcs statusSLES
crm statusLes exemples suivants montrent que les rôles de chaque hôte ont été inversés.
RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.3-4b1f869f0f) - partition with quorum * Last updated: Fri Mar 19 21:22:07 2021 * Last change: Fri Mar 19 21:21:28 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES pour SAP 15 SP5 ou version antérieure
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Thu Jul 8 17:33:44 2021 * Last change: Thu Jul 8 17:33:07 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES pour SAP 15 SP6 ou version ultérieure
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Tue Oct 8 21:47:19 2024 * Last change: Tue Oct 8 21:47:13 2024 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]Sur la page d'informations sur l'équilibreur de charge de la console, confirmez que la nouvelle instance principale active affiche "1/1" dans la colonne Opérationnel. Rechargez la page si nécessaire.
Accéder à Cloud Load Balancing
Exemple :

Dans SAP HANA Studio, confirmez que vous êtes toujours connecté au système en double-cliquant sur l'entrée du système dans le volet de navigation afin d'actualiser les informations système.
Cliquez sur le lien System Replication Status (État de la réplication du système) pour confirmer que les hôtes principal et secondaire ont changé de VM et sont actifs.
Vérifier l'installation de l'agent Google Cloudpour SAP
Après avoir déployé une VM et installé le système SAP, vérifiez que l'agentGoogle Cloudpour SAP fonctionne correctement.
Vérifier que l'agent pour SAP de Google Cloudest en cours d'exécution
Pour vérifier que l'agent est en cours d'exécution, procédez comme suit :
Établissez une connexion SSH avec votre instance Compute Engine.
Exécutez la commande suivante :
systemctl status google-cloud-sap-agent
Si l'agent fonctionne correctement, la sortie contient
active (running). Exemple :google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
Si l'agent n'est pas en cours d'exécution, redémarrez-le.
Vérifier que l'agent hôte SAP reçoit les métriques
Pour vérifier que les métriques d'infrastructure sont collectées par l'agentGoogle Cloudpour SAP et envoyées correctement à l'agent hôte SAP, procédez comme suit:
- Dans votre système SAP, saisissez la transaction
ST06. Dans le volet de synthèse, vérifiez la disponibilité et le contenu des champs suivants pour vous assurer de la configuration de façon correcte et complète de l'infrastructure de surveillance SAP et Google :
- Fournisseur cloud :
Google Cloud Platform - Accès à la surveillance améliorée :
TRUE - Détails de la surveillance améliorée :
ACTIVE
- Fournisseur cloud :
Configurer la surveillance pour SAP HANA
Vous pouvez éventuellement surveiller vos instances SAP HANA à l'aide de l'agentGoogle Cloudpour SAP. À partir de la version 2.0, vous pouvez configurer l'agent de sorte qu'il collecte les métriques de surveillance SAP HANA et les envoie à Cloud Monitoring. Cloud Monitoring vous permet de créer des tableaux de bord pour visualiser ces métriques, de configurer des alertes en fonction de seuils de métriques, etc.
Pour surveiller un cluster à haute disponibilité à l'aide de l'agent Google Cloudpour SAP, veillez à suivre les instructions fournies sur la page Configuration de la haute disponibilité pour l'agent.Pour en savoir plus sur la collecte des métriques de surveillance SAP HANA à l'aide de l'agentGoogle Cloudpour SAP, consultez Collecte des métriques de surveillance SAP HANA.
Se connecter à SAP HANA
Étant donné qu'aucune adresse IP externe n'est utilisée pour SAP HANA dans ces instructions, vous ne pouvez vous connecter aux instances SAP HANA que via l'instance bastion à l'aide de SSH ou via le serveur Windows à l'aide de SAP HANA Studio.
Pour vous connecter à SAP HANA via l'instance bastion, connectez-vous à l'hôte bastion, puis aux instances SAP HANA à l'aide du client SSH de votre choix.
Pour vous connecter à la base de données SAP HANA via SAP HANA Studio, utilisez un client Bureau à distance pour vous connecter à l'instance Windows Server. Une fois la connexion établie, installez SAP HANA Studio manuellement, puis accédez à votre base de données SAP HANA.
Configurer HANA actif/actif (lecture activée)
À partir de SAP HANA 2.0 SPS1, vous pouvez configurer HANA actif/actif (lecture activée) dans un cluster Pacemaker. Pour savoir comment procéder, consultez les articles suivants :
- Configurer HANA actif/actif (lecture activée) dans un cluster SUSE Pacemaker
- Configurer HANA actif/actif (lecture activée) dans un cluster Red Hat Pacemaker
Effectuer des tâches post-déploiement
Avant d'utiliser votre instance SAP HANA, nous vous recommandons de suivre la procédure post-déploiement ci-dessous. Pour en savoir plus, consultez le Guide d'installation et de mise à jour de SAP HANA.
Modifiez les mots de passe temporaires de l'administrateur système et du super-utilisateur du système SAP HANA.
Mettez à jour le logiciel SAP HANA avec les derniers correctifs.
Si votre système SAP HANA est déployé sur une interface réseau VirtIO, nous vous recommandons de vous assurer que la valeur du paramètre TCP
/proc/sys/net/ipv4/tcp_limit_output_bytesest définie sur1048576. Cette modification permet d'améliorer le débit réseau global sur l'interface réseau VirtIO sans affecter la latence du réseau.Installez des composants supplémentaires tels que les bibliothèques Application Function Library (AFL) ou Smart Data Access (SDA).
Configurez et sauvegardez votre nouvelle base de données SAP HANA. Pour en savoir plus, consultez le Guide d'utilisation de SAP HANA.
Évaluer votre charge de travail SAP HANA
Pour automatiser les vérifications de validation continues pour vos charges de travail à haute disponibilité SAP HANA exécutées sur Google Cloud, vous pouvez utiliser le gestionnaire de charges de travail.
Le gestionnaire de charges de travail vous permet d'analyser et d'évaluer automatiquement vos charges de travail SAP HANA à haute disponibilité par rapport aux bonnes pratiques des fournisseurs SAP, Google Cloudet de système d'exploitation. Cela permet d'améliorer la qualité, les performances et la fiabilité de vos charges de travail.
Pour en savoir plus sur les bonnes pratiques compatibles avec le gestionnaire de charges de travail pour évaluer les charges de travail SAP HANA à haute disponibilité exécutées sur Google Cloud, consultez la page Bonnes pratiques pour le gestionnaire de charges de travail SAP. Pour en savoir plus sur la création et l'exécution d'une évaluation à l'aide du gestionnaire de charges de travail, consultez la page Créer et exécuter une évaluation.
Étape suivante
-
Si vous utilisez SLES pour SAP 15 SP4 ou SP5, consultez Mettre à niveau
SAPHanaSRversSAPHanaSR-angidans un cluster HA à évolutivité verticale sur SLES pour savoir comment passer à l'agent de ressources SUSESAPHanaSR-angidans votre cluster HA. - Si vous devez utiliser des Google Cloud NetApp Volumes au lieu de disques persistants ou de volumes Hyperdisk pour héberger des répertoires SAP HANA tels que
/hana/sharedou/hanabackup, consultez les informations de déploiement des NetApp Volumes dans le guide de planification SAP HANA. - Pour en savoir plus sur l'administration et la surveillance des VM, consultez le Guide d'utilisation de SAP HANA.