Questa guida mostra come automatizzare il deployment di SAP HANA in un cluster di alta disponibilità (HA) Red Hat Enterprise Linux (RHEL) o SUSE Linux Enterprise Server (SLES) che utilizza un bilanciatore del carico di rete passthrough interno per gestire l'indirizzo IP virtuale (VIP).
La guida utilizza Terraform per eseguire il deployment di due macchine virtuali (VM) Compute Engine, due sistemi SAP HANA scalabili, un indirizzo IP virtuale (VIP) con un'implementazione di bilanciatore del carico di rete passthrough interno e un cluster HA basato sul sistema operativo, il tutto in base alle best practice di Google Cloud, SAP e del fornitore del sistema operativo.
Uno dei sistemi SAP HANA funziona come sistema principale attivo e l'altro come sistema secondario in standby. Esegui il deployment di entrambi i sistemi SAP HANA all'interno della stessa regione, idealmente in zone diverse.

Il cluster di cui è stato eseguito il deployment include le seguenti funzioni e funzionalità:
- Il gestore delle risorse del cluster ad alta disponibilità Pacemaker.
- Un meccanismo di recinzione di Google Cloud.
- Un indirizzo IP virtuale (VIP) che utilizza un'implementazione di bilanciatore del carico TCP interno di livello 4, tra cui:
- Una prenotazione dell'indirizzo IP selezionato per il VIP.
- Due gruppi di istanze Compute Engine.
- Un bilanciatore del carico interno TCP.
- Un controllo di integrità Compute Engine.
- Nei cluster RHEL ad alta disponibilità:
- Il pattern di alta disponibilità di Red Hat.
- L'agente delle risorse Red Hat e i pacchetti di recinzione.
- Nei cluster ad alta disponibilità SLES:
- Il pattern di alta disponibilità di SUSE.
- Il pacchetto dell'agente di risorse SUSE SAPHanaSR.
- Replica sincrona del sistema.
- Precaricamento della memoria.
- Riavvio automatico dell'istanza non riuscita come nuova istanza secondaria.
Se hai bisogno di un sistema scalabile orizzontalmente con host di riserva per il failover automatico dell'host SAP HANA, consulta la guida al deployment di Terraform: sistema SAP HANA scalabile orizzontalmente con failover automatico dell'host.
Per eseguire il deployment di un sistema SAP HANA senza un cluster ad alta disponibilità Linux o host di standby, consulta la guida al deployment di Terraform: SAP HANA.
Questa guida è rivolta agli utenti SAP HANA esperti che hanno familiarità con le configurazioni ad alta disponibilità di Linux per SAP HANA.
Prerequisiti
Prima di creare il cluster SAP HANA ad alta disponibilità, assicurati che siano soddisfatti i seguenti prerequisiti:
- Hai letto la guida alla pianificazione di SAP HANA e la guida alla pianificazione dell'alta disponibilità di SAP HANA.
- Tu o la tua organizzazione disponete di un account Google Cloud e avete creato un progetto per il deployment di SAP HANA. Per informazioni sulla creazione di account e progetti Google Cloud, consulta Configurare l'Account Google.
- Se vuoi che il tuo carico di lavoro SAP venga eseguito in conformità con la residenza dei dati, controllo dell'accesso, il personale di assistenza o i requisiti normativi, devi creare la cartella Assured Workloads richiesta. Per ulteriori informazioni, consulta Controlli di conformità e sovranità per SAP su Google Cloud.
I media di installazione di SAP HANA sono archiviati in un bucket Cloud Storage disponibile nel progetto e nella regione di deployment. Per informazioni su come caricare i media di installazione di SAP HANA in un bucket Cloud Storage, consulta Creare un bucket Cloud Storage per i file di installazione di SAP HANA.
Se OS Login è abilitato nei metadati del progetto, devi disattivarlo temporaneamente fino al completamento del deployment. Ai fini del deployment, questa procedura configura le chiavi SSH nei metadati dell'istanza. Quando l'accesso al sistema operativo è abilitato, le configurazioni delle chiavi SSH basate su metadati vengono disabilitate e questo deployment non va a buon fine. Al termine del deployment, puoi riattivare l'accesso al sistema operativo.
Per ulteriori informazioni, vedi:
Se utilizzi il DNS interno della VPC, il valore della variabile
vmDnsSettingnei metadati del progetto deve essereGlobalOnlyoZonalPreferredper abilitare la risoluzione dei nomi dei nodi nelle varie zone. L'impostazione predefinita divmDnsSettingèZonalOnly. Per ulteriori informazioni, consulta:
Creare una rete
Per motivi di sicurezza, crea una nuova rete. Puoi controllare chi ha accesso aggiungendo regole firewall o utilizzando un altro metodo di controllo dell'accesso.
Se il progetto ha una rete VPC predefinita, non utilizzarla. Crea invece una tua rete VPC in modo che le uniche regole firewall in vigore siano quelle che crei esplicitamente.
Durante il deployment, le istanze VM in genere richiedono l'accesso a internet per scaricare l'agente di Google Cloud per SAP. Se utilizzi una delle immagini Linux certificate da SAP disponibili su Google Cloud, l'istanza VM richiede anche l'accesso a internet per registrare la licenza e accedere ai repository del fornitore del sistema operativo. Una configurazione con un gateway NAT e con i tag di rete VM supporta questo accesso, anche se le VM di destinazione non hanno IP esterni.
Per creare una rete VPC per il tuo progetto, completa i seguenti passaggi:
-
Crea una rete in modalità personalizzata. Per saperne di più, consulta Creare una rete in modalità personalizzata.
-
Crea una subnet e specifica la regione e l'intervallo IP. Per ulteriori informazioni, consulta la sezione Aggiunta di subnet.
Configurazione di un gateway NAT
Se devi creare una o più VM senza indirizzi IP pubblici, devi utilizzare la Network Address Translation (NAT) per consentire alle VM di accedere a internet. Utilizza Cloud NAT, un servizio gestito software-defined distribuito di Google Cloud che consente alle VM di inviare pacchetti in uscita a internet e di ricevere eventuali pacchetti di risposta in entrata stabiliti corrispondenti. In alternativa, puoi configurare una VM separata come gateway NAT.
Per creare un'istanza Cloud NAT per il tuo progetto, consulta Utilizzo di Cloud NAT.
Dopo aver configurato Cloud NAT per il progetto, le istanze VM possono accedere in sicurezza a internet senza un indirizzo IP pubblico.
aggiungi regole firewall
Per impostazione predefinita, una regola firewall implicita blocca le connessioni in entrata dall'esterno della rete Virtual Private Cloud (VPC). Per consentire le connessioni in entrata, configura una regola firewall per la tua VM. Dopo aver stabilito una connessione in entrata con una VM, il traffico è consentito in entrambe le direzioni tramite la connessione.
I cluster ad alta disponibilità per SAP HANA richiedono almeno due regole firewall, una che consente al controllo di integrità di Compute Engine di verificare l'integrità dei nodi del cluster e un'altra che consente ai nodi del cluster di comunicare tra loro.Se non utilizzi una rete VPC condivisa, devi creare la regola del firewall per la comunicazione tra i nodi, ma non per i controlli di integrità. Il file di configurazione Terraform crea la regola firewall per i controlli di integrità, che puoi modificare al termine del deployment, se necessario.
Se utilizzi una rete VPC condivisa, un amministratore di rete deve creare entrambe le regole del firewall nel progetto host.
Puoi anche creare una regola firewall per consentire l'accesso esterno a porte specifiche o per limitare l'accesso tra le VM sulla stessa rete. Se viene utilizzato il tipo di rete VPC default, vengono applicate anche alcune regole predefinite aggiuntive, come la regola default-allow-internal, che consente la connettività tra le VM sulla stessa rete su tutte le porte.
A seconda dei criteri IT applicabili al tuo ambiente, potresti dover isolare o limitare in altro modo la connettività all'host del database, cosa che puoi fare creando regole firewall.
A seconda dello scenario, puoi creare regole firewall per consentire l'accesso per:
- Le porte SAP predefinite elencate in TCP/IP di tutti i prodotti SAP.
- Connessioni dal tuo computer o dall'ambiente di rete aziendale all'istanza VM Compute Engine. Se hai dubbi su quale indirizzo IP utilizzare, rivolgiti all'amministratore di rete della tua azienda.
- Connessioni SSH all'istanza VM, incluso SSH nel browser.
- Connessione alla VM utilizzando uno strumento di terze parti in Linux. Crea una regola per consentire l'accesso dello strumento tramite il firewall.
Per creare le regole firewall per il progetto, consulta la sezione Creare regole firewall.
Creazione di un cluster Linux ad alta disponibilità con SAP HANA installato
Le istruzioni riportate di seguito utilizzano il file di configurazione Terraform per creare un cluster RHEL o SLES con due sistemi SAP HANA, un sistema SAP HANA a singolo host primario su un'istanza VM e un sistema SAP HANA di riserva su un'altra istanza VM nella stessa regione Compute Engine. I sistemi SAP HANA utilizzano la replica di sistema sincrona e il sistema di standby precarica i dati replicati.
Definisci le opzioni di configurazione per il cluster ad alta disponibilità SAP HANA in un file di configurazione Terraform.
Verifica che le quote attuali per risorse come i dischi permanenti e le CPU siano sufficienti per i sistemi SAP HANA che stai per installare. Se le quote non sono sufficienti, il deployment non riesce.
Per i requisiti delle quote SAP HANA, consulta Considerazioni su prezzi e quote per SAP HANA.
Apri Cloud Shell.
Scarica il file di configurazione
sap_hana_ha.tfper il cluster di alta disponibilità SAP HANA nella tua directory di lavoro:$wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/terraform/sap_hana_ha.tfApri il file
sap_hana_ha.tfnell'editor di codice di Cloud Shell.Per aprire l'editor di codice di Cloud Shell, fai clic sull'icona a forma di matita nell'angolo in alto a destra della finestra del terminale di Cloud Shell.
Nel file
sap_hana_ha.tf, aggiorna i valori degli argomenti sostituendo i contenuti tra virgolette doppie con i valori per l'installazione. Gli argomenti sono descritti nella tabella seguente.Argomento Tipo di dati Descrizione sourceStringa Specifica la posizione e la versione del modulo Terraform da utilizzare durante il deployment.
Il file di configurazione
sap_hana_ha.tfinclude due istanze dell'argomentosource: una attiva e una inclusa come commento. L'argomentosourceattivo per impostazione predefinita specificalatestcome versione del modulo. La seconda istanza dell'argomentosource, che per impostazione predefinita è disattivata da un carattere#iniziale, specifica un timestamp che identifica una versione del modulo.Se vuoi che tutti i tuoi deployment utilizzino la stessa versione del modulo, rimuovi il carattere
#iniziale dall'argomentosourceche specifica il timestamp della versione e aggiungilo all'argomentosourceche specificalatest.project_idStringa Specifica l'ID del progetto Google Cloud in cui esegui il deployment di questo sistema. Ad esempio, my-project-x.machine_typeStringa Specifica il tipo di macchina virtuale (VM) Compute Engine su cui devi eseguire il sistema SAP. Se hai bisogno di un tipo di VM personalizzata, specifica un tipo di VM predefinito con un numero di vCPU più vicino a quello di cui hai bisogno, pur essendo più grande. Al termine del deployment, modifica il numero di vCPU e la quantità di memoria. Ad esempio,
n1-highmem-32.networkStringa Specifica il nome della rete in cui devi creare il bilanciatore del carico che gestisce il VIP. Se utilizzi una rete VPC condivisa, devi aggiungere l'ID del progetto host come directory principale del nome della rete. Ad esempio,
HOST_PROJECT_ID/NETWORK_NAME.subnetworkStringa Specifica il nome della sottorete creata in un passaggio precedente. Se effettui il deployment in un VPC condiviso, specifica questo valore come SHARED_VPC_PROJECT_ID/SUBNETWORK. Ad esempio,myproject/network1.linux_imageStringa Specifica il nome dell'immagine del sistema operativo Linux su cui vuoi eseguire il deployment del sistema SAP. Ad esempio, rhel-9-2-sap-haosles-15-sp5-sap. Per l'elenco delle immagini del sistema operativo disponibili, consulta la pagina Immagini nella console Google Cloud.linux_image_projectStringa Specifica il progetto Google Cloud che contiene l'immagine che hai specificato per l'argomento linux_image. Questo progetto potrebbe essere il tuo progetto o un progetto di immagini Google Cloud. Per un'immagine Compute Engine, specificarhel-sap-cloudosuse-sap-cloud. Per trovare il progetto immagine per il tuo sistema operativo, consulta Dettagli del sistema operativo.primary_instance_nameStringa Specifica un nome per l'istanza VM del sistema SAP HANA principale. Il nome può contenere lettere minuscole, numeri o trattini. primary_zoneStringa Specifica una zona in cui è dipiegato il sistema SAP HANA principale. Le zone primaria e secondaria devono trovarsi nella stessa regione. Ad esempio, us-east1-c.secondary_instance_nameStringa Specifica un nome per l'istanza VM del sistema SAP HANA secondario. Il nome può contenere lettere minuscole, numeri o trattini. secondary_zoneStringa Specifica una zona in cui è dipiegato il sistema SAP HANA secondario. Le zone principali e secondarie devono trovarsi nella stessa regione. Ad esempio, us-east1-b.sap_hana_deployment_bucketStringa Per installare automaticamente SAP HANA sulle VM di cui è stato eseguito il deployment, specifica il percorso del bucket Cloud Storage contenente i file di installazione di SAP HANA. Non includere gs://nel percorso; includi solo il nome del bucket e i nomi di eventuali cartelle. Ad esempio,my-bucket-name/my-folder.Il bucket Cloud Storage deve esistere nel progetto Google Cloud specificato per l'argomento
project_id.sap_hana_sidStringa Per installare automaticamente SAP HANA sulle VM di cui è stato eseguito il deployment, specifica l'ID sistema SAP HANA. L'ID deve essere composto da tre caratteri alfanumerici e deve iniziare con una lettera. Tutte le lettere devono essere in maiuscolo. Ad esempio, ED1.sap_hana_instance_numberNumero intero Facoltativo. Specifica il numero di istanza, da 0 a 99, del sistema SAP HANA. Il valore predefinito è 0.sap_hana_sidadm_passwordStringa Per installare automaticamente SAP HANA sulle VM di cui è stato eseguito il deployment, specifica una password SIDadmtemporanea da utilizzare per gli script di installazione durante il deployment. La password deve contenere almeno 8 caratteri e includere almeno una lettera maiuscola, una lettera minuscola e un numero.Anziché specificare la password in testo normale, ti consigliamo di utilizzare un secret. Per saperne di più, consulta Gestione delle password.
sap_hana_sidadm_password_secretStringa Facoltativo. Se utilizzi Secret Manager per archiviare la password SIDadm, specifica il nome del segreto corrispondente a questa password.In Secret Manager, assicurati che il valore della chiave, ovvero la password, contenga almeno 8 caratteri e includa almeno una lettera maiuscola, una lettera minuscola e un numero.
Per saperne di più, consulta Gestione delle password.
sap_hana_system_passwordStringa Per installare automaticamente SAP HANA sulle VM di cui è stato eseguito il deployment, specifica una password temporanea per il superutente del database da utilizzare dagli script di installazione durante il deployment. La password deve contenere almeno 8 caratteri e includere almeno una lettera maiuscola, una lettera minuscola e un numero. Anziché specificare la password in testo normale, ti consigliamo di utilizzare un secret. Per saperne di più, consulta Gestione delle password.
sap_hana_system_password_secretStringa Facoltativo. Se utilizzi Secret Manager per archiviare la password del superutente del database, specifica il nome del segreto corrispondente a questa password. In Secret Manager, assicurati che il valore della chiave, ovvero la password, contenga almeno 8 caratteri e includa almeno una lettera maiuscola, una lettera minuscola e un numero.
Per saperne di più, consulta Gestione delle password.
sap_hana_double_volume_sizeBooleano Facoltativo. Per raddoppiare le dimensioni del volume HANA, specifica true. Questo argomento è utile quando vuoi eseguire il deployment di più istanze SAP HANA o di un'istanza SAP HANA di ripristino di emergenza sulla stessa VM. Per impostazione predefinita, le dimensioni del volume vengono calcolate automaticamente in base alle dimensioni minime richieste per la VM, soddisfacendo al contempo i requisiti di certificazione e assistenza SAP. Il valore predefinito èfalse.sap_hana_backup_sizeNumero intero Facoltativo. Specifica le dimensioni del volume /hanabackupin GB. Se non specifichi questo argomento o lo imposti su0, lo script di installazione esegue il provisioning dell'istanza Compute Engine con un volume di backup HANA pari al doppio della memoria totale.sap_hana_sidadm_uidNumero intero Facoltativo. Specifica un valore per sostituire il valore predefinito dell'SID_LCID utente amministratore. Il valore predefinito è 900. Puoi impostare un valore diverso per garantire la coerenza all'interno del tuo panorama SAP.sap_hana_sapsys_gidNumero intero Facoltativo. Sostituisce l'ID gruppo predefinito per sapsys. Il valore predefinito è79.sap_vipStringa Specifica l'indirizzo IP che utilizzerai per il VIP. L' indirizzo IP deve rientrare nell'intervallo di indirizzi IP assegnati alla subnet. Il file di configurazione Terraform riserva questo indirizzo IP per te. primary_instance_group_nameStringa Facoltativo. Specifica il nome del gruppo di istanze non gestite per il nodo principale. Il nome predefinito è ig-PRIMARY_INSTANCE_NAME.secondary_instance_group_nameStringa Facoltativo. Specifica il nome del gruppo di istanze non gestite per il nodo secondario. Il nome predefinito è ig-SECONDARY_INSTANCE_NAME.loadbalancer_nameStringa Facoltativo. Specifica il nome del bilanciatore del carico di rete passthrough interno. Il nome predefinito è lb-SAP_HANA_SID-ilb.network_tagsStringa Facoltativo. Specifica uno o più tag di rete separati da virgola da associare alle tue istanze VM a fini di firewall o routing. Un tag di rete per i componenti ILB viene aggiunto automaticamente ai tag di rete della VM.
nic_typeStringa Facoltativo. Specifica l'interfaccia di rete da utilizzare con l'istanza VM. Puoi specificare il valore GVNICoVIRTIO_NET. Per utilizzare una scheda di rete virtuale Google (gVNIC), devi specificare un'immagine del sistema operativo che supporti gVNIC come valore per l'argomentolinux_image. Per l'elenco delle immagini del sistema operativo, consulta Dettagli del sistema operativo.Se non specifichi un valore per questo argomento, l'interfaccia di rete viene selezionata automaticamente in base al tipo di macchina specificato per l'argomento
Questo argomento è disponibile nella versione del modulomachine_type.sap_hana202302060649o successive.disk_typeStringa Facoltativo. Specifica il tipo predefinito di volume Hyperdisk o Persistent Disk che vuoi implementare per i volumi di dati e log SAP nel tuo deployment. Per informazioni sul deployment predefinito del disco eseguito dalle configurazioni Terraform fornite da Google Cloud, consulta Deployment del disco da parte di Terraform. Di seguito sono riportati i valori validi per questo argomento:
pd-ssd,pd-balanced,hyperdisk-extreme,hyperdisk-balanced, epd-extreme. Nei deployment di SAP HANA con scalabilità verticale, viene disegnato anche un disco permanente bilanciato separato per la directory/hana/shared.Puoi eseguire l'override di questo tipo di disco predefinito, della dimensione del disco predefinita e delle IOPS predefinite associate utilizzando alcuni argomenti avanzati. Per ulteriori informazioni, vai alla tua directory di lavoro, quindi esegui il comando
terraform inite consulta il file/.terraform/modules/sap_hana_ha/variables.tf. Prima di utilizzare questi argomenti in produzione, assicurati di testarli in un ambiente non di produzione.use_single_shared_data_log_diskBooleano Facoltativo. Il valore predefinito è false, che indica a Terraform di eseguire il deployment di un disco permanente o Hyperdisk separato per ciascuno dei seguenti volumi SAP:/hana/data,/hana/log,/hana/sharede/usr/sap. Per montare questi volumi SAP sullo stesso disco permanente o Hyperdisk, specificatrue.enable_data_stripingBooleano Facoltativo. Questo argomento ti consente di eseguire il deployment del volume /hana/datasu due dischi. Il valore predefinito èfalse, che indica a Terraform di eseguire il deployment di un singolo disco per l'hosting del volume/hana/data.Questo argomento è disponibile nella versione
1.3.674800406o successive del modulosap_hana_ha.include_backup_diskBooleano Facoltativo. Questo argomento è applicabile ai deployment di SAP HANA scalabili verticalmente. Il valore predefinito è true, che indica a Terraform di eseguire il deployment di un disco separato per ospitare la directory/hanabackup.Il tipo di disco è determinato dall'argomento
backup_disk_type. Le dimensioni di questo disco sono determinate dall'argomentosap_hana_backup_size.Se imposti il valore di
include_backup_disksufalse, non viene disegnato alcun disco per la directory/hanabackup.backup_disk_typeStringa Facoltativo. Per i deployment di scalabilità in aumento, specifica il tipo di Persistent Disk o Hyperdisk che vuoi implementare per il volume /hanabackup. Per informazioni sul deployment predefinito del disco eseguito dalle configurazioni Terraform fornite da Google Cloud, consulta Deployment del disco da parte di Terraform.Di seguito sono riportati i valori validi per questo argomento:
pd-ssd,pd-balanced,pd-standard,hyperdisk-extreme,hyperdisk-balanced, epd-extreme.Questo argomento è disponibile nella versione
202307061058o successive del modulosap_hana_ha.enable_fast_restartBooleano Facoltativo. Questo parametro determina se l'opzione di riavvio rapido SAP HANA è attivata o meno per il deployment. Il valore predefinito è true. Google Cloud consiglia vivamente di attivare l'opzione Riavvio rapido SAP HANA.Questo argomento è disponibile nella versione
sap_hana_hao successive del modulo.202309280828public_ipBooleano Facoltativo. Determina se un indirizzo IP pubblico viene aggiunto o meno all'istanza VM. Il valore predefinito è true.service_accountStringa Facoltativo. Specifica l'indirizzo email di un account di servizio gestito dall'utente da utilizzare dalle VM host e dai programmi in esecuzione sulle VM host. Ad esempio, svc-acct-name@project-id.iam.gserviceaccount.com.Se specifichi questo argomento senza un valore o lo ometti, lo script di installazione utilizza l'account di servizio predefinito di Compute Engine. Per ulteriori informazioni, consulta Gestione di identità e accessi per i programmi SAP su Google Cloud.
sap_deployment_debugBooleano Facoltativo. Solo quando lassistenza clienti Google Cloud ti chiede di attivare il debug per il tuo deployment, specifica true, che consente al deployment di generare log dettagliati. Il valore predefinito èfalse.primary_reservation_nameStringa Facoltativo. Per utilizzare una prenotazione VM Compute Engine specifica per il provisioning dell'istanza VM che ospita l'istanza SAP HANA principale del tuo cluster HA, specifica il nome della prenotazione. Per impostazione predefinita, lo script di installazione seleziona qualsiasi prenotazione Compute Engine disponibile in base alle seguenti condizioni. Affinché una prenotazione sia utilizzabile, indipendentemente dal fatto che tu specifichi un nome o che lo script di installazione la selezioni automaticamente, la prenotazione deve essere impostata con quanto segue:
-
L'opzione
specificReservationRequiredè impostata sutrueo, nella console Google Cloud, è selezionata l'opzione Seleziona una prenotazione specifica. -
Alcuni tipi di macchine Compute Engine supportano piattaforme CPU non coperte dalla certificazione SAP del tipo di macchina. Se la prenotazione di destinazione riguarda uno dei seguenti tipi di macchine, deve specificare le piattaforme CPU minime come indicato:
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Le piattaforme CPU minime per tutti gli altri tipi di macchine certificate da SAP per l'utilizzo su Google Cloud sono conformi al requisito minimo della CPU di SAP.
secondary_reservation_nameStringa Facoltativo. Per utilizzare una prenotazione VM Compute Engine specifica per il provisioning dell'istanza VM che ospita l'istanza SAP HANA secondaria del tuo cluster HA, specifica il nome della prenotazione. Per impostazione predefinita, lo script di installazione seleziona qualsiasi prenotazione Compute Engine disponibile in base alle seguenti condizioni. Affinché una prenotazione sia utilizzabile, indipendentemente dal fatto che tu specifichi un nome o che lo script di installazione la selezioni automaticamente, la prenotazione deve essere impostata con quanto segue:
-
L'opzione
specificReservationRequiredè impostata sutrueo, nella console Google Cloud, è selezionata l'opzione Seleziona una prenotazione specifica. -
Alcuni tipi di macchine Compute Engine supportano piattaforme CPU non coperte dalla certificazione SAP del tipo di macchina. Se la prenotazione di destinazione riguarda uno dei seguenti tipi di macchine, deve specificare le piattaforme CPU minime come indicato:
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Le piattaforme CPU minime per tutti gli altri tipi di macchine certificate da SAP per l'utilizzo su Google Cloud sono conformi al requisito minimo della CPU di SAP.
primary_static_ipStringa Facoltativo. Specifica un indirizzo IP statico valido per l'istanza VM principale nel tuo cluster ad alta disponibilità. Se non ne specifichi uno, verrà generato automaticamente un indirizzo IP per l'istanza VM. Ad esempio, 128.10.10.10.Questo argomento è disponibile nella versione
sap_hana_hadel modulo202306120959o successive.secondary_static_ipStringa Facoltativo. Specifica un indirizzo IP statico valido per l'istanza VM secondaria nel cluster ad alta disponibilità. Se non ne specifichi uno, verrà generato automaticamente un indirizzo IP per l'istanza VM. Ad esempio, 128.11.11.11.Questo argomento è disponibile nella versione
sap_hana_hadel modulo202306120959o successive.can_ip_forwardBooleano Specifica se è consentito l'invio e la ricezione di pacchetti con IP di origine o di destinazione non corrispondenti, in modo che una VM possa comportarsi come un router. Il valore predefinito è
true.Se intendi utilizzare i bilanciatori del carico interni di Google solo per gestire gli IP virtuali per le VM di cui è stato eseguito il deployment, imposta il valore su
false. Un bilanciatore del carico interno viene disegnato automaticamente come parte dei modelli di alta disponibilità.Gli esempi seguenti mostrano il file di configurazione completato che definisce un cluster ad alta disponibilità per SAP HANA. Il cluster utilizza un bilanciatore del carico di rete passthrough interno per gestire l'IP virtuale.
Terraform esegue il deployment delle risorse Google Cloud definite nel file di configurazione, dopodiché gli script prendono il controllo per configurare il sistema operativo, installare SAP HANA, configurare la replica e configurare il cluster Linux HA.
Fai clic su
RHELoSLESper visualizzare l'esempio specifico per il tuo sistema operativo. Per chiarezza, i commenti nel file di configurazione vengono omessi negli esempi.RHEL
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "rhel-8-4-sap-ha" linux_image_project = "rhel-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456.iam.gserviceaccount.com" primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }SLES
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "sles-15-sp3-sap" linux_image_project = "suse-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456.iam.gserviceaccount.com" primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }-
L'opzione
Inizializza la directory di lavoro corrente e scarica i file del plug-in e del modulo del provider Terraform per Google Cloud:
terraform init
Il comando
terraform initprepara la directory di lavoro per altri comandi Terraform.Per forzare l'aggiornamento del plug-in del provider e dei file di configurazione nella directory di lavoro, specifica il flag
--upgrade. Se il flag--upgradeviene omesso e non apporti modifiche alla directory di lavoro, Terraform utilizza le copie memorizzate nella cache locale, anche selatestè specificato nell'URLsource.terraform init --upgrade
Se vuoi, crea il piano di esecuzione Terraform:
terraform plan
Il comando
terraform planmostra le modifiche richieste dalla configurazione attuale. Se salti questo passaggio, il comandoterraform applycrea automaticamente un nuovo piano e ti chiede di approvarlo.Applica il piano di esecuzione:
terraform apply
Quando ti viene chiesto di approvare le azioni, inserisci
yes.Il comando
terraform applyconfigura l'infrastruttura Google Cloud e poi passa il controllo a uno script che configura il cluster HA e installa SAP HANA in base agli argomenti definiti nel file di configurazione Terraform.Mentre Terraform ha il controllo, i messaggi di stato vengono scritti in Cloud Shell. Dopo l'attivazione degli script, i messaggi di stato vengono scritti in Logging e sono visualizzabili nella console Google Cloud, come descritto in Controllare i log.
Verifica del deployment del sistema HANA HA
La verifica di un cluster SAP HANA HA prevede diverse procedure:
- Controllo del logging
- Controllo della configurazione della VM e dell'installazione di SAP HANA
- Controllo della configurazione del cluster
- Controllare il bilanciatore del carico e l'integrità dei gruppi di istanze
- Controllo del sistema SAP HANA utilizzando SAP HANA Studio
- Eseguire un test di failover
Controlla i log
Nella console Google Cloud, apri Cloud Logging per monitorare l'avanzamento dell'installazione e verificare la presenza di errori.
Filtra i log:
Esplora log
Nella pagina Esplora log, vai al riquadro Query.
Nel menu a discesa Risorsa, seleziona Globale e poi fai clic su Aggiungi.
Se non vedi l'opzione Globale, nell'editor di query inserisci la seguente query:
resource.type="global" "Deployment"Fai clic su Esegui query.
Visualizzatore log legacy
- Nella pagina Visualizzatore log legacy, seleziona Globale come risorsa di registrazione nel menu del selettore di base.
Analizza i log filtrati:
- Se viene visualizzato
"--- Finished", significa che l'elaborazione del deployment è completata e puoi procedere al passaggio successivo. Se viene visualizzato un errore relativo alla quota:
Nella pagina IAM e amministrazione Quote, aumenta le quote che non soddisfano i requisiti di SAP HANA elencati nella guida alla pianificazione di SAP HANA.
Apri Cloud Shell.
Vai alla tua directory di lavoro ed elimina il deployment per ripulire le VM e i dischi permanenti dall'installazione non riuscita:
terraform destroy
Quando ti viene chiesto di approvare l'azione, inserisci
yes.Esegui di nuovo il deployment.
- Se viene visualizzato
Controlla la configurazione della VM e dell'installazione di SAP HANA
Dopo aver eseguito il deployment del sistema SAP HANA senza errori, connettiti a ogni VM utilizzando SSH. Nella pagina Istanze VM di Compute Engine, puoi fare clic sul pulsante SSH per ogni istanza VM oppure utilizzare il metodo SSH che preferisci.

Passa all'utente root.
sudo su -
Al prompt dei comandi, inserisci
df -h. Assicurati di visualizzare un output che includa le directory/hana, ad esempio/hana/data.RHEL
[root@example-ha-vm1 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 0 126G 0% /dev tmpfs 126G 54M 126G 1% /dev/shm tmpfs 126G 25M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda2 30G 5.4G 25G 18% / /dev/sda1 200M 6.9M 193M 4% /boot/efi /dev/mapper/vg_hana-shared 251G 52G 200G 21% /hana/shared /dev/mapper/vg_hana-sap 32G 477M 32G 2% /usr/sap /dev/mapper/vg_hana-data 426G 9.8G 417G 3% /hana/data /dev/mapper/vg_hana-log 125G 7.0G 118G 6% /hana/log /dev/mapper/vg_hanabackup-backup 512G 9.3G 503G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/899 tmpfs 26G 0 26G 0% /run/user/1003
SLES
example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 54M 189G 1% /dev/shm tmpfs 126G 34M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 30G 5.4G 25G 18% / /dev/sda2 20M 2.9M 18M 15% /boot/efi /dev/mapper/vg_hana-shared 251G 50G 202G 20% /hana/shared /dev/mapper/vg_hana-sap 32G 281M 32G 1% /usr/sap /dev/mapper/vg_hana-data 426G 8.0G 418G 2% /hana/data /dev/mapper/vg_hana-log 125G 4.3G 121G 4% /hana/log /dev/mapper/vg_hanabackup-backup 512G 6.4G 506G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/473 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1003
Controlla lo stato del nuovo cluster inserendo il comando status specifico per il tuo sistema operativo:
RHEL
pcs statusSLES
crm statusL'output è simile al seguente esempio, in cui entrambe le istanze VM sono avviate e
example-ha-vm1è l'istanza principale attiva:RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.4-4b1f869f0f) - partition with quorum * Last updated: Wed Jul 7 23:05:11 2021 * Last change: Wed Jul 7 23:04:43 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ] Failed Resource Actions: * rsc_healthcheck_HA1_start_0 on example-ha-vm1 'error' (1): call=29, status='complete', exitreason='', last-rc-change='2021-07-07 21:07:35Z', queued=0ms, exec=2097ms * SAPHana_HA1_00_monitor_61000 on example-ha-vm1 'not running' (7): call=44, status='complete', exitreason='', last-rc-change='2021-07-07 21:09:49Z', queued=0ms, exec=0ms Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledSLES for SAP 15 SP5 o versioni precedenti
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Wed Jul 7 22:57:59 2021 * Last change: Wed Jul 7 22:57:03 2021 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]SLES for SAP 15 SP6 o versioni successive
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Mon Oct 7 22:57:59 2024 * Last change: Mon Oct 7 22:57:03 2024 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]Passa all'utente amministratore SAP sostituendo SID_LC nel seguente comando con il valore
sap_hana_sidspecificato nel filesap_hana_ha.tf. Il valore SID_LC deve essere in minuscolo.su - SID_LCadmAssicurati che i servizi SAP HANA, come
hdbnameserver,hdbindexservere altri, siano in esecuzione nell'istanza inserendo il seguente comando:HDB infoSe utilizzi RHEL per SAP 9.0 o versioni successive, assicurati che i pacchetti
chkconfigecompat-openssl11siano installati nell'istanza VM.Per ulteriori informazioni di SAP, consulta Nota SAP 3108316 - Red Hat Enterprise Linux 9.x: installazione e configurazione .
Controlla la configurazione del cluster
Controlla le impostazioni dei parametri del cluster. Controlla sia le impostazioni visualizzate dal software del cluster sia le impostazioni dei parametri nel file di configurazione del cluster. Confronta le tue impostazioni con quelle degli esempi riportati di seguito, che sono state create dagli script di automazione utilizzati in questa guida.
Fai clic sulla scheda del tuo sistema operativo.
RHEL
Visualizza le configurazioni delle risorse del cluster:
pcs config show
L'esempio seguente mostra le configurazioni delle risorse create dagli script di automazione su RHEL 8.1 e versioni successive.
Se utilizzi RHEL 7.7 o versioni precedenti, la definizione della risorsa
Clone: SAPHana_HA1_00-clonenon includeMeta Attrs: promotable=true.Cluster Name: hacluster Corosync Nodes: example-rha-vm1 example-rha-vm2 Pacemaker Nodes: example-rha-vm1 example-rha-vm2 Resources: Group: g-primary Resource: rsc_healthcheck_HA1 (class=service type=haproxy) Operations: monitor interval=10s timeout=20s (rsc_healthcheck_HA1-monitor-interval-10s) start interval=0s timeout=100 (rsc_healthcheck_HA1-start-interval-0s) stop interval=0s timeout=100 (rsc_healthcheck_HA1-stop-interval-0s) Resource: rsc_vip_HA1_00 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=32 ip=10.128.15.100 nic=eth0 Operations: monitor interval=3600s timeout=60s (rsc_vip_HA1_00-monitor-interval-3600s) start interval=0s timeout=20s (rsc_vip_HA1_00-start-interval-0s) stop interval=0s timeout=20s (rsc_vip_HA1_00-stop-interval-0s) Clone: SAPHanaTopology_HA1_00-clone Meta Attrs: clone-max=2 clone-node-max=1 interleave=true Resource: SAPHanaTopology_HA1_00 (class=ocf provider=heartbeat type=SAPHanaTopology) Attributes: InstanceNumber=00 SID=HA1 Operations: methods interval=0s timeout=5 (SAPHanaTopology_HA1_00-methods-interval-0s) monitor interval=10 timeout=600 (SAPHanaTopology_HA1_00-monitor-interval-10) reload interval=0s timeout=5 (SAPHanaTopology_HA1_00-reload-interval-0s) start interval=0s timeout=600 (SAPHanaTopology_HA1_00-start-interval-0s) stop interval=0s timeout=300 (SAPHanaTopology_HA1_00-stop-interval-0s) Clone: SAPHana_HA1_00-clone Meta Attrs: promotable=true Resource: SAPHana_HA1_00 (class=ocf provider=heartbeat type=SAPHana) Attributes: AUTOMATED_REGISTER=true DUPLICATE_PRIMARY_TIMEOUT=7200 InstanceNumber=00 PREFER_SITE_TAKEOVER=true SID=HA1 Meta Attrs: clone-max=2 clone-node-max=1 interleave=true notify=true Operations: demote interval=0s timeout=3600 (SAPHana_HA1_00-demote-interval-0s) methods interval=0s timeout=5 (SAPHana_HA1_00-methods-interval-0s) monitor interval=61 role=Slave timeout=700 (SAPHana_HA1_00-monitor-interval-61) monitor interval=59 role=Master timeout=700 (SAPHana_HA1_00-monitor-interval-59) promote interval=0s timeout=3600 (SAPHana_HA1_00-promote-interval-0s) reload interval=0s timeout=5 (SAPHana_HA1_00-reload-interval-0s) start interval=0s timeout=3600 (SAPHana_HA1_00-start-interval-0s) stop interval=0s timeout=3600 (SAPHana_HA1_00-stop-interval-0s) Stonith Devices: Resource: STONITH-example-rha-vm1 (class=stonith type=fence_gce) Attributes: pcmk_delay_max=30 pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm1 project=example-project-123456 zone=us-central1-a Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm1-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm1-start-interval-0) Resource: STONITH-example-rha-vm2 (class=stonith type=fence_gce) Attributes: pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm2 project=example-project-123456 zone=us-central1-c Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm2-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm2-start-interval-0) Fencing Levels: Location Constraints: Resource: STONITH-example-rha-vm1 Disabled on: example-rha-vm1 (score:-INFINITY) (id:location-STONITH-example-rha-vm1-example-rha-vm1--INFINITY) Resource: STONITH-example-rha-vm2 Disabled on: example-rha-vm2 (score:-INFINITY) (id:location-STONITH-example-rha-vm2-example-rha-vm2--INFINITY) Ordering Constraints: start SAPHanaTopology_HA1_00-clone then start SAPHana_HA1_00-clone (kind:Mandatory) (non-symmetrical) (id:order-SAPHanaTopology_HA1_00-clone-SAPHana_HA1_00-clone-mandatory) Colocation Constraints: g-primary with SAPHana_HA1_00-clone (score:4000) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-g-primary-SAPHana_HA1_00-clone-4000) Ticket Constraints: Alerts: No alerts defined Resources Defaults: migration-threshold=5000 resource-stickiness=1000 Operations Defaults: timeout=600s Cluster Properties: cluster-infrastructure: corosync cluster-name: hacluster dc-version: 2.0.2-3.el8_1.2-744a30d655 have-watchdog: false stonith-enabled: true stonith-timeout: 300s Quorum: Options:Visualizza il file di configurazione del cluster,
corosync.conf:cat /etc/corosync/corosync.conf
L'esempio seguente mostra i parametri impostati dagli script di automazione per RHEL 8.1 e versioni successive.
Se utilizzi RHEL 7.7 o versioni precedenti, il valore di
transport:èudpuinvece diknet:totem { version: 2 cluster_name: hacluster transport: knet join: 60 max_messages: 20 token: 20000 token_retransmits_before_loss_const: 10 crypto_cipher: aes256 crypto_hash: sha256 } nodelist { node { ring0_addr: example-rha-vm1 name: example-rha-vm1 nodeid: 1 } node { ring0_addr: example-rha-vm2 name: example-rha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum two_node: 1 } logging { to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes timestamp: on }
SLES for SAP 15 SP5 o versioni precedenti
Visualizza le configurazioni delle risorse del cluster:
crm config show
Gli script di automazione utilizzati da questa guida creano le configurazioni delle risorse mostrate nell'esempio seguente:
node 1: example-ha-vm1 \ attributes hana_ha1_op_mode=logreplay lpa_ha1_lpt=1635380335 hana_ha1_srmode=syncmem hana_ha1_vhost=example-ha-vm1 hana_ha1_remoteHost=example-ha-vm2 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes lpa_ha1_lpt=30 hana_ha1_op_mode=logreplay hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 hana_ha1_srmode=syncmem hana_ha1_remoteHost=example-ha-vm1 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHana \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta notify=true clone-max=2 clone-node-max=1 target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Visualizza il file di configurazione del cluster,
corosync.conf:cat /etc/corosync/corosync.conf
Gli script di automazione utilizzati da questa guida specificano le impostazioni dei parametri nel file
corosync.confcome mostrato nell'esempio seguente:totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
SLES for SAP 15 SP6 o versioni successive
Visualizza le configurazioni delle risorse del cluster:
crm config show
Gli script di automazione utilizzati da questa guida creano le configurazioni delle risorse mostrate nell'esempio seguente:
node 1: example-ha-vm1 \ attributes hana_ha1_vhost=example-ha-vm1 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHanaFileSystem_HA1_HDB00 ocf:suse:SAPHanaFilesystem \ operations $id=rsc_sap3_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHanaController \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Promoted timeout=700 \ op monitor interval=61 role=Unpromoted timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 clone mst_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta clone-node-max=1 promotable=true interleave=true clone cln_SAPHanaFileSystem_HA1_HDB00 rsc_SAPHanaFileSystem_HA1_HDB00 \ meta clone-node-max=1 interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started mst_SAPHana_HA1_HDB00:Promoted order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 mst_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Visualizza il file di configurazione del cluster,
corosync.conf:cat /etc/corosync/corosync.conf
Gli script di automazione utilizzati da questa guida specificano le impostazioni dei parametri nel file
corosync.confcome mostrato nell'esempio seguente:totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
Controlla il bilanciatore del carico e lo stato dei gruppi di istanze
Per verificare che il bilanciatore del carico e il controllo di integrità siano stati configurati correttamente, controlla il bilanciatore del carico e i gruppi di istanze nella console Google Cloud.
Apri la pagina Bilanciamento del carico nella console Google Cloud:
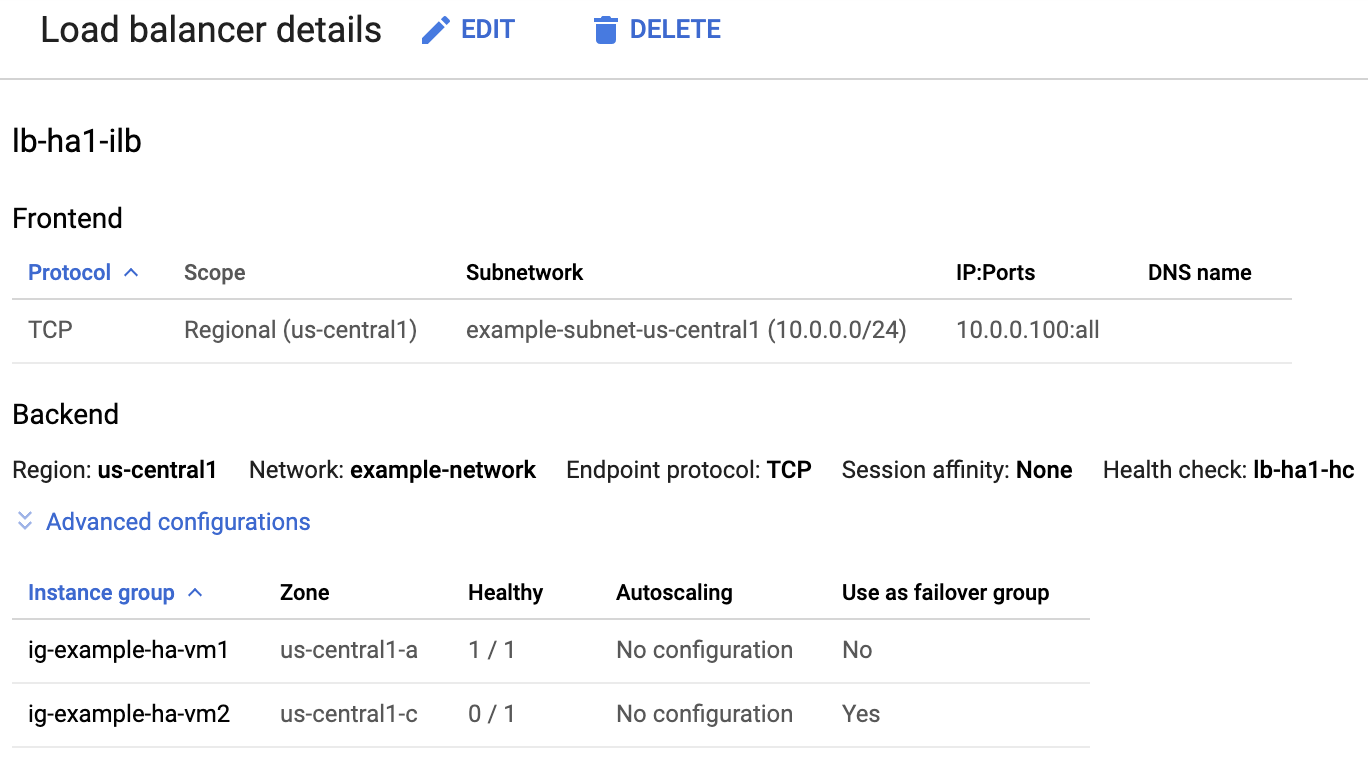
Nell'elenco dei bilanciatori del carico, verifica che sia stato creato un bilanciatore del carico per il cluster HA.
Nella pagina Dettagli del bilanciatore del carico, nella colonna Integro in Gruppo di istanze nella sezione Backend, verifica che uno dei gruppi di istanze mostri "1/1" e l'altro "0/1". Dopo un failover, l'indicatore di stato "1/1" passa al nuovo gruppo di istanze attive.
Controllare il sistema SAP HANA utilizzando SAP HANA Studio
Puoi utilizzare SAP HANA Cockpit o SAP HANA Studio per monitorare e gestire i sistemi SAP HANA in un cluster ad alta disponibilità.
Connettiti al sistema HANA utilizzando SAP HANA Studio. Quando definisci la connessione, specifica i seguenti valori:
- Nel riquadro Specifica il sistema, specifica l'indirizzo IP dinamico come Nome host.
- Nel riquadro Proprietà connessione, per l'autenticazione utente del database,
specifica il nome del superutente del database e la password specificata
per l'argomento
sap_hana_system_passwordnel filesap_hana_ha.tf.
Per informazioni di SAP sull'installazione di SAP HANA Studio, consulta la Guida all'installazione e all'aggiornamento di SAP HANA Studio.
Dopo aver collegato SAP HANA Studio al sistema HANA HA, visualizza la panoramica del sistema facendo doppio clic sul nome del sistema nel riquadro di navigazione sul lato sinistro della finestra.
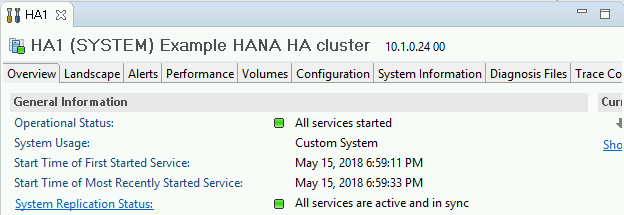
Nella sezione Informazioni generali della scheda Panoramica, verifica che:
- Lo stato di operatività mostra "Tutti i servizi avviati".
- Lo stato della replica di sistema mostra "Tutti i servizi sono attivi e sincronizzati".
Conferma la modalità di replica facendo clic sul link Stato della replica di sistema nella sezione Informazioni generali. La replica sincrona è indicata da
SYNCMEMnella colonna REPLICATION_MODE della scheda Replica di sistema.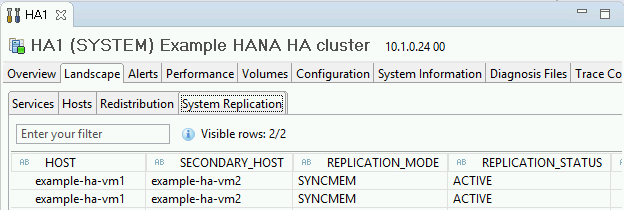
Ripulisci e riprova a eseguire il deployment
Se uno dei passaggi di verifica del deployment nelle sezioni precedenti indica che l'installazione non è andata a buon fine, devi annullare il deployment e riprovare completando i seguenti passaggi:
Risolvi eventuali errori per assicurarti che il deployment non fallisca di nuovo per lo stesso motivo. Per informazioni su come controllare i log o risolvere gli errori relativi alla quota, consulta Controllare i log.
Apri Cloud Shell o, se hai installato Google Cloud CLI sulla tua workstation locale, apri un terminale.
Vai alla directory contenente il file di configurazione Terraform utilizzato per questo deployment.
Elimina tutte le risorse che fanno parte del deployment eseguendo il seguente comando:
terraform destroy
Quando ti viene chiesto di approvare l'azione, inserisci
yes.Riprova il deployment come indicato in precedenza in questa guida.
Esegui un test di failover
Per eseguire un test di failover:
Connettiti alla VM principale tramite SSH. Puoi connetterti dalla pagina delle istanze VM di Compute Engine facendo clic sul pulsante SSH per ogni istanza VM oppure puoi utilizzare il metodo SSH che preferisci.
Al prompt dei comandi, inserisci il seguente comando:
sudo ip link set eth0 down
Il comando
ip link set eth0 downattiva un failover interrompendo le comunicazioni con l'host principale.Riconnettiti a uno degli host utilizzando SSH e passa all'utente root.
Verifica che l'host principale sia ora attivo sulla VM che in precedenza conteneva l'host secondario. Il riavvio automatico è abilitato nel cluster, quindi l'host arrestato si riavvierà e assumerà il ruolo di host secondario.
RHEL
pcs statusSLES
crm statusGli esempi riportati di seguito mostrano che i ruoli su ciascun host sono stati scambiati.
RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.3-4b1f869f0f) - partition with quorum * Last updated: Fri Mar 19 21:22:07 2021 * Last change: Fri Mar 19 21:21:28 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES for SAP 15 SP5 o versioni precedenti
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Thu Jul 8 17:33:44 2021 * Last change: Thu Jul 8 17:33:07 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES for SAP 15 SP6 o versioni successive
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Tue Oct 8 21:47:19 2024 * Last change: Tue Oct 8 21:47:13 2024 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]Nella pagina Dettagli del bilanciatore del carico della console, verifica che la nuova istanza principale attiva mostri "1/1" nella colonna Intatto. Aggiorna la pagina, se necessario.
Ad esempio:

In SAP HANA Studio, verifica di essere ancora connesso al sistema facendo clic due volte sulla voce del sistema nel riquadro di navigazione per aggiornare le informazioni del sistema.
Fai clic sul link Stato della replica di sistema per verificare che gli host principali e secondari abbiano eseguito il passaggio e siano attivi.
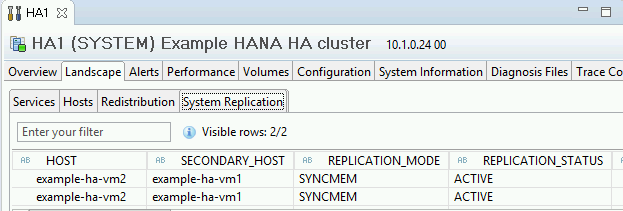
Convalida l'installazione dell'agente di Google Cloud per SAP
Dopo aver eseguito il deployment di una VM e installato il sistema SAP, verifica che l'agente di Google Cloud per SAP funzioni correttamente.
Verificare che l'agente di Google Cloud per SAP sia in esecuzione
Per verificare che l'agente sia in esecuzione:
Stabilisci una connessione SSH con la tua istanza Compute Engine.
Esegui questo comando:
systemctl status google-cloud-sap-agent
Se l'agente funziona correttamente, l'output contiene
active (running). Ad esempio:google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
Se l'agente non è in esecuzione, riavvialo.
Verificare che l'agente host SAP riceva le metriche
Per verificare che le metriche dell'infrastruttura vengano raccolte dall'agente di Google Cloud per SAP e inviate correttamente all'agente host SAP, segui questi passaggi:
- Nel sistema SAP, inserisci la transazione
ST06. Nel riquadro di panoramica, controlla la disponibilità e i contenuti dei seguenti campi per la configurazione end-to-end corretta dell'infrastruttura di monitoraggio di SAP e Google:
- Fornitore cloud:
Google Cloud Platform - Accesso al monitoraggio avanzato:
TRUE - Dettagli sul monitoraggio avanzato:
ACTIVE
- Fornitore cloud:
Configurare il monitoraggio per SAP HANA
Se vuoi, puoi monitorare le tue istanze SAP HANA utilizzando l'agente di Google Cloud per SAP. Dalla versione 2.0, puoi configurare l'agente per raccogliere le metriche di monitoraggio di SAP HANA e inviarle a Cloud Monitoring. Cloud Monitoring ti consente di creare dashboard per visualizzare queste metriche, configurare avvisi in base alle soglie delle metriche e altro ancora.
Per monitorare un cluster HA utilizzando l'agente per SAP di Google Cloud, assicurati di seguire le indicazioni riportate in Configurazione ad alta disponibilità per l'agente.Per ulteriori informazioni sulla raccolta delle metriche di monitoraggio di SAP HANA utilizzando l'agente di Google Cloud per SAP, consulta la raccolta delle metriche di monitoraggio di SAP HANA.
Connettiti a SAP HANA
Tieni presente che, poiché queste istruzioni non utilizzano un indirizzo IP esterno per SAP HANA, puoi connetterti alle istanze SAP HANA solo tramite l'istanza bastione utilizzando SSH o tramite il server Windows tramite SAP HANA Studio.
Per connetterti a SAP HANA tramite l'istanza bastion, connettiti all'host bastion e poi alle istanze SAP HANA utilizzando un client SSH di tua scelta.
Per connetterti al database SAP HANA tramite SAP HANA Studio, utilizza un client desktop remoto per connetterti all'istanza Windows Server. Dopo la connessione, installa manualmente SAP HANA Studio e accedi al tuo database SAP HANA.
Configura HANA Active/Active (lettura abilitata)
A partire da SAP HANA 2.0 SPS1, puoi configurare HANA Active/Active (Read Enabled) in un cluster Pacemaker. Per istruzioni, vedi:
- Configurare HANA Active/Active (lettura abilitata) in un cluster SUSE Pacemaker
- Configurare HANA Active/Active (lettura abilitata) in un cluster Red Hat Pacemaker
Eseguire le attività di post-deployment
Prima di utilizzare l'istanza SAP HANA, ti consigliamo di eseguire i seguenti passaggi di post-deployment. Per ulteriori informazioni, consulta la Guida all'installazione e all'aggiornamento di SAP HANA.
Modifica le password temporanee per l'amministratore di sistema SAP HANA e per il superutente del database.
Aggiorna il software SAP HANA con le patch più recenti.
Se il sistema SAP HANA è dipiegato su un'interfaccia di rete VirtIO, ti consigliamo di assicurarti che il valore del parametro TCP
/proc/sys/net/ipv4/tcp_limit_output_bytessia impostato su1048576. Questa modifica contribuisce a migliorare la velocità effettiva complessiva della rete sull'interfaccia di rete VirtIO senza influire sulla latenza della rete.Installa eventuali componenti aggiuntivi come le librerie di funzioni per le applicazioni (AFL) o l'accesso ai dati intelligenti (SDA).
Configura e esegui il backup del nuovo database SAP HANA. Per ulteriori informazioni, consulta la guida alle operazioni di SAP HANA.
Valuta il tuo workload SAP HANA
Per automatizzare i controlli di convalida continua per i carichi di lavoro SAP HANA ad alta disponibilità in esecuzione su Google Cloud, puoi utilizzare Workload Manager.
Workload Manager ti consente di eseguire automaticamente la scansione e la valutazione dei carichi di lavoro SAP HANA ad alta disponibilità in base alle best practice di SAP, Google Cloud e dei fornitori di sistemi operativi. In questo modo puoi migliorare la qualità, le prestazioni e l'affidabilità dei tuoi carichi di lavoro.
Per informazioni sulle best practice supportate da Workload Manager per la valutazione dei carichi di lavoro SAP HANA ad alta disponibilità in esecuzione su Google Cloud, consulta le best practice di Workload Manager per SAP. Per informazioni sulla creazione e sull'esecuzione di una valutazione utilizzando Workload Manager, consulta Creare ed eseguire una valutazione.
Passaggi successivi
- Per ulteriori informazioni sull'amministrazione e sul monitoraggio delle VM, consulta la Guida alle operazioni di SAP HANA.