Questa guida mostra come utilizzare Terraform per eseguire il deployment di un sistema SAP HANA scalabile orizzontalmente che include la soluzione di recupero dei guasti con failover automatico dell'host SAP HANA. Utilizzando Terraform, puoi eseguire il deployment di un sistema che soddisfi i requisiti di assistenza SAP e sia conforme alle best practice di SAP e Compute Engine.
Il sistema SAP HANA risultante include un host master, fino a 15 host worker e fino a 3 host di riserva, tutti all'interno di un'unica zona Compute Engine.
Il sistema include anche il
Google Cloud gestore dello spazio di archiviazione per i nodi di standby SAP HANA (Gestione archiviazione per SAP HANA), che
gestisce il trasferimento dei dispositivi di archiviazione al nodo di standby durante un failover.
Il Gestione archiviazione per SAP HANA è installato nel volume SAP HANA /shared.
Per informazioni sul gestore dello spazio di archiviazione per SAP HANA e sulle autorizzazioni IAM richieste, consulta Il Gestione archiviazione per SAP HANA.
Per ulteriori informazioni di SAP sulla soluzione di failover automatico dell'host, consulta Failover automatico dell'host
Non utilizzare questa guida se non hai bisogno della funzionalità di failover automatico dell'host. Utilizza invece la guida al deployment di Terraform: SAP HANA.
Se devi eseguire il deployment di SAP HANA in un cluster ad alta disponibilità Linux, utilizza una delle seguenti guide:
- Terraform: guida alla configurazione del cluster SAP HANA HA
- La guida alla configurazione del cluster ad alta disponibilità per SAP HANA su RHEL
- La guida alla configurazione del cluster ad alta disponibilità per SAP HANA su SLES
Questa guida è rivolta agli utenti avanzati di SAP HANA che hanno familiarità con le configurazioni di scalabilità orizzontale di SAP che includono host di riserva per l'alta disponibilità, nonché file system di rete.
Prerequisiti
Prima di creare il sistema SAP HANA scalabile orizzontalmente ad alta disponibilità, assicurati che siano soddisfatti i seguenti prerequisiti:
- Hai letto la guida alla pianificazione di SAP HANA e la guida alla pianificazione dell'alta disponibilità di SAP HANA.
- Tu o la tua organizzazione avete un Google Cloud account e avete creato un progetto per il deployment di SAP HANA. Per informazioni sulla creazione diGoogle Cloud account e progetti, consulta Configurare l'Account Google nella Guida all'implementazione di SAP HANA.
- Se vuoi che il tuo carico di lavoro SAP venga eseguito in conformità con la residenza dei dati, controllo dell'accesso, il personale di assistenza o i requisiti normativi, devi creare la cartella Assured Workloads richiesta. Per ulteriori informazioni, consulta Controlli di conformità e sovranità per SAP su Google Cloud.
- I media di installazione di SAP HANA sono archiviati in un bucket Cloud Storage disponibile nel progetto e nella regione di deployment. Per informazioni su come caricare i media di installazione di SAP HANA in un bucket Cloud Storage, consulta Creazione di un bucket Cloud Storage nella Guida all'implementazione di SAP HANA.
- Disponi di una soluzione NFS, come la soluzione Filestore gestita, per condividere i volumi SAP HANA
/hana/sharede/hanabackuptra gli host nel sistema SAP HANA scalabile orizzontalmente. Prima di poter eseguire il deployment del sistema, devi specificare i punti di montaggio per i server NFS nel file di configurazione Terraform. Per eseguire il deployment dei server NFS Filestore, consulta la sezione Creare istanze. La comunicazione deve essere consentita tra tutte le VM nella sottorete SAP HANA che ospitano un nodo SAP HANA scalabile orizzontalmente.
Se OS Login è abilitato nei metadati del progetto, devi disattivarlo temporaneamente fino al completamento del deployment. Ai fini del deployment, questa procedura configura le chiavi SSH nei metadati dell'istanza. Quando l'accesso al sistema operativo è abilitato, le configurazioni delle chiavi SSH basate su metadati vengono disabilitate e questo deployment non va a buon fine. Al termine del deployment, puoi riattivare l'accesso al sistema operativo.
Per ulteriori informazioni, vedi:
Creare una rete
Per motivi di sicurezza, crea una nuova rete. Puoi controllare chi ha accesso aggiungendo regole firewall o utilizzando un altro metodo di controllo dell'accesso.
Se il progetto ha una rete VPC predefinita, non utilizzarla. Crea invece una tua rete VPC in modo che le uniche regole firewall in vigore siano quelle che crei esplicitamente.
Durante il deployment, le istanze Compute Engine in genere richiedono l'accesso a internet per scaricare l'agente per SAP di Google Cloud. Se utilizzi una delle immagini Linux certificate da SAP disponibili su Google Cloud, l'istanza di calcolo richiede anche l'accesso a internet per registrare la licenza e accedere ai repository del fornitore del sistema operativo. Una configurazione con un gateway NAT e con tag di rete VM supporta questo accesso, anche se le istanze di calcolo di destinazione non hanno IP esterni.
Per creare una rete VPC per il tuo progetto, completa i seguenti passaggi:
-
Crea una rete in modalità personalizzata. Per saperne di più, consulta Creare una rete in modalità personalizzata.
-
Crea una subnet e specifica la regione e l'intervallo IP. Per ulteriori informazioni, consulta la sezione Aggiunta di subnet.
Configurazione di un gateway NAT
Se devi creare una o più VM senza indirizzi IP pubblici, devi utilizzare la Network Address Translation (NAT) per consentire alle VM di accedere a internet. Utilizza Cloud NAT, un Google Cloud servizio gestito software-defined distribuito che consente alle VM di inviare pacchetti in uscita a internet e di ricevere eventuali pacchetti di risposta in entrata stabiliti corrispondenti. In alternativa, puoi configurare una VM separata come gateway NAT.
Per creare un'istanza Cloud NAT per il tuo progetto, consulta Utilizzo di Cloud NAT.
Dopo aver configurato Cloud NAT per il progetto, le istanze VM possono accedere in sicurezza a internet senza un indirizzo IP pubblico.
aggiungi regole firewall
Per impostazione predefinita, una regola del firewall implicita blocca le connessioni in entrata dall'esterno della tua rete Virtual Private Cloud (VPC). Per consentire le connessioni in entrata, configura una regola firewall per la tua VM. Dopo aver stabilito una connessione in entrata con una VM, il traffico è consentito in entrambe le direzioni tramite la connessione.
Puoi anche creare una regola firewall per consentire l'accesso esterno a porte specifiche o per limitare l'accesso tra le VM sulla stessa rete. Se viene utilizzato il tipo di rete VPC default, vengono applicate anche alcune regole predefinite aggiuntive, come la regola default-allow-internal, che consente la connettività tra le VM sulla stessa rete su tutte le porte.
A seconda dei criteri IT applicabili al tuo ambiente, potresti dover isolare o limitare in altro modo la connettività all'host del database, cosa che puoi fare creando regole firewall.
A seconda dello scenario, puoi creare regole firewall per consentire l'accesso per:
- Le porte SAP predefinite elencate in TCP/IP di tutti i prodotti SAP.
- Connessioni dal tuo computer o dall'ambiente di rete aziendale all'istanza VM Compute Engine. Se hai dubbi su quale indirizzo IP utilizzare, rivolgiti all'amministratore di rete della tua azienda.
- Comunicazione tra le VM nella sottorete SAP HANA, inclusa la comunicazione tra i nodi di un sistema SAP HANA scalabile o tra il server di database e i server delle applicazioni in un'architettura a tre livelli. Puoi attivare la comunicazione tra le VM creando una regola firewall per consentire il traffico proveniente dalla sottorete.
Per creare le regole firewall per il progetto, consulta la sezione Creare regole firewall.
Creazione di un sistema SAP HANA scalabile orizzontalmente con host di riserva
Nelle istruzioni riportate di seguito, completa le seguenti azioni:
- Crea il sistema SAP HANA richiamando Terraform con un file di configurazione che completi.
- Verifica il deployment.
- Testa gli host di riserva simulando un errore dell'host.
Alcuni passaggi delle istruzioni riportate di seguito utilizzano Cloud Shell per inserire i comandi gcloud. Se hai installato la versione più recente di Google Cloud SDK, puoi inserire i comandi gcloud da un terminale locale.
Definisci e crea il sistema SAP HANA
Nei passaggi che seguono, scarichi e completi un file di configurazione Terraform, utilizzi i comandi Terraform standard per inizializzare la directory di lavoro corrente e scaricare i file del plug-in e del modulo del provider Terraform per Google Cloud, quindi applichi la configurazione, che esegue il deployment delle VM, dei dischi permanenti e delle istanze SAP HANA.
Verifica che le quote attuali per le risorse del progetto, come CPU e dischi permanenti, siano sufficienti per il sistema SAP HANA che stai per installare. Se le quote non sono sufficienti, il deployment non riesce. Per i requisiti relativi alle quote di SAP HANA, consulta Considerazioni su prezzi e quote per SAP HANA.
Apri Cloud Shell.
Scarica il file di configurazione
sap_hana_scaleout.tfper il sistema scalabile orizzontalmente di SAP HANA con alta disponibilità nella tua directory di lavoro:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_scaleout/terraform/sap_hana_scaleout.tf
Apri il file
sap_hana_scaleout.tfnell'editor di codice di Cloud Shell.Per aprire l'editor di codice di Cloud Shell, fai clic sull'icona a forma di matita nell'angolo in alto a destra della finestra del terminale di Cloud Shell.
Nel file
sap_hana_scaleout.tf, aggiorna i seguenti valori dell'argomento sostituendo i contenuti all'interno delle virgolette doppie con i valori per la tua installazione. Ad esempio, puoi sostituire "ZONE" con "us-central1-f".Argomento Tipo di dati Descrizione sourceStringa Specifica la posizione e la versione del modulo Terraform da utilizzare durante il deployment.
Il file di configurazione
sap_hana_scaleout.tfinclude due istanze dell'argomentosource: una attiva e una inclusa come commento. L'argomentosourceattivo per impostazione predefinita specificalatestcome versione del modulo. La seconda istanza dell'argomentosource, che per impostazione predefinita è disattivata da un carattere#iniziale, specifica un timestamp che identifica una versione del modulo.Se vuoi che tutti i tuoi deployment utilizzino la stessa versione del modulo, rimuovi il carattere
#iniziale dall'argomentosourceche specifica il timestamp della versione e aggiungilo all'argomentosourceche specificalatest.project_idStringa Specifica l'ID del Google Cloud progetto in cui stai eseguendo il deployment di questo sistema. Ad esempio, my-project-x.zoneStringa Specifica la zona in cui stai eseguendo il deployment del sistema SAP. La zona deve trovarsi nella stessa regione selezionata per la subnet.
Ad esempio, se la subnet è di cui è stato eseguito il deployment nella regione
us-central1, puoi specificare una zona comeus-central1-a.machine_typeStringa Specifica il tipo di macchina virtuale (VM) Compute Engine su cui devi eseguire il sistema SAP. Se hai bisogno di un tipo di VM personalizzata, specifica un tipo di VM predefinito con un numero di vCPU più vicino a quello di cui hai bisogno, pur essendo più grande. Al termine del deployment, modifica il numero di vCPU e la quantità di memoria. Ad esempio,
n1-highmem-32.subnetworkStringa Specifica il nome della sottorete creata in un passaggio precedente. Se effettui il deployment in una VPC condivisa, specifica questo valore come SHARED_VPC_PROJECT_ID/SUBNETWORK. Ad esempiomyproject/network1.linux_imageStringa Specifica il nome dell'immagine del sistema operativo Linux su cui vuoi eseguire il deployment del sistema SAP. Ad esempio, rhel-9-2-sap-haosles-15-sp5-sap. Per l'elenco delle immagini del sistema operativo disponibili, consulta la pagina Immagini nella console Google Cloud .linux_image_projectStringa Specifica il Google Cloud progetto contenente l'immagine che hai specificato per l'argomento linux_image. Può trattarsi del tuo progetto o di un Google Cloud progetto di immagini. Per un'immagine Compute Engine, specificarhel-sap-cloudosuse-sap-cloud. Per trovare il progetto immagine per il tuo sistema operativo, consulta Dettagli del sistema operativo.instance_nameStringa Specifica un nome per l'istanza VM host. Il nome può contenere lettere minuscole, numeri e trattini. Le istanze VM per gli host worker e di riserva utilizzano lo stesso nome con un we il numero dell'host aggiunto al nome.sap_hana_shared_nfsStringa Specifica il punto di montaggio NFS per il volume /hana/shared. Ad esempio,10.151.91.122:/hana_shared_nfs.sap_hana_backup_nfsStringa Specifica il punto di montaggio NFS per il volume /hanabackup. Ad esempio,10.216.41.122:/hana_backup_nfs.sap_hana_deployment_bucketStringa Per installare automaticamente SAP HANA sulle VM di cui è stato eseguito il deployment, specifica il percorso del bucket Cloud Storage contenente i file di installazione di SAP HANA. Non includere gs://nel percorso; includi solo il nome del bucket e i nomi di eventuali cartelle. Ad esempio,my-bucket-name/my-folder.Il bucket Cloud Storage deve esistere nel progetto Google Cloud specificato per l'argomento
project_id.sap_hana_sidStringa Per installare automaticamente SAP HANA sulle VM di cui è stato eseguito il deployment, specifica l'ID sistema SAP HANA. L'ID deve essere composto da tre caratteri alfanumerici e deve iniziare con una lettera. Tutte le lettere devono essere in maiuscolo. Ad esempio, ED1.sap_hana_instance_numberNumero intero Facoltativo. Specifica il numero di istanza, da 0 a 99, del sistema SAP HANA. Il valore predefinito è 0.sap_hana_sidadm_passwordStringa Per installare automaticamente SAP HANA sulle VM di cui è stato eseguito il deployment, specifica una password SIDadmtemporanea da utilizzare per gli script di installazione durante il deployment. La password deve contenere almeno 8 caratteri e includere almeno una lettera maiuscola, una lettera minuscola e un numero.Anziché specificare la password in testo normale, ti consigliamo di utilizzare un secret. Per saperne di più, consulta Gestione delle password.
sap_hana_sidadm_password_secretStringa Facoltativo. Se utilizzi Secret Manager per archiviare la password SIDadm, specifica il nome del segreto corrispondente a questa password.In Secret Manager, assicurati che il valore della chiave, ovvero la password, contenga almeno 8 caratteri e includa almeno una lettera maiuscola, una lettera minuscola e un numero.
Per saperne di più, consulta Gestione delle password.
sap_hana_system_passwordStringa Per installare automaticamente SAP HANA sulle VM di cui è stato eseguito il deployment, specifica una password temporanea del superutente del database da utilizzare per gli script di installazione durante il deployment. La password deve contenere almeno 8 caratteri e includere almeno una lettera maiuscola, una lettera minuscola e un numero. Anziché specificare la password in testo normale, ti consigliamo di utilizzare un secret. Per saperne di più, consulta Gestione delle password.
sap_hana_system_password_secretStringa Facoltativo. Se utilizzi Secret Manager per archiviare la password del superutente del database, specifica il nome del segreto corrispondente a questa password. In Secret Manager, assicurati che il valore della chiave, ovvero la password, contenga almeno 8 caratteri e includa almeno una lettera maiuscola, una lettera minuscola e un numero.
Per saperne di più, consulta Gestione delle password.
sap_hana_double_volume_sizeBooleano Facoltativo. Per raddoppiare le dimensioni del volume HANA, specifica true. Questo argomento è utile quando vuoi eseguire il deployment di più istanze SAP HANA o di un'istanza SAP HANA di ripristino di emergenza sulla stessa VM. Per impostazione predefinita, le dimensioni del volume vengono calcolate automaticamente in base alle dimensioni minime richieste per la VM, soddisfacendo al contempo i requisiti di certificazione e assistenza SAP. Il valore predefinito èfalse.sap_hana_sidadm_uidNumero intero Facoltativo. Specifica un valore per sostituire il valore predefinito dell'SID_LCID utente amministratore. Il valore predefinito è 900. Puoi impostare un valore diverso per garantire la coerenza all'interno del tuo panorama SAP.sap_hana_sapsys_gidNumero intero Facoltativo. Sostituisce l'ID gruppo predefinito per sapsys. Il valore predefinito è79.sap_hana_worker_nodesNumero intero Specifica il numero di host worker SAP HANA aggiuntivi di cui hai bisogno. Puoi specificare da 1 a 15 host worker. Non utilizzare le virgolette con il valore. Il valore predefinito è 1. sap_hana_standby_nodesNumero intero Specifica il numero di host SAP HANA standby aggiuntivi di cui hai bisogno. Puoi specificare da 1 a 3 host di riserva. Non utilizzare le virgolette con il valore. Il valore predefinito è 1. network_tagsStringa Facoltativo. Specifica uno o più tag di rete separati da virgola da associare alle istanze VM per finalità di firewall o routing. Se specifichi
public_ip = falsee non specifichi un tag di rete, assicurati di fornire un altro mezzo di accesso a internet.nic_typeStringa Facoltativo. Specifica l'interfaccia di rete da utilizzare con l'istanza VM. Puoi specificare il valore GVNICoVIRTIO_NET. Per utilizzare una scheda di rete virtuale Google (gVNIC), devi specificare un'immagine del sistema operativo che supporti gVNIC come valore per l'argomentolinux_image. Per l'elenco delle immagini del sistema operativo, consulta Dettagli del sistema operativo.Se non specifichi un valore per questo argomento, l'interfaccia di rete viene selezionata automaticamente in base al tipo di macchina specificato per l'argomento
Questo argomento è disponibile nella versione del modulomachine_type.sap_hana202302060649o successive.disk_typeStringa Facoltativo. Specifica il tipo predefinito di volume del Persistent Disk o Hyperdisk da eseguire per i dati SAP e i volumi dei log nel deployment. Per informazioni sul deployment predefinito del disco eseguito dalle configurazioni Terraform fornite da Google Cloud, consulta Deployment del disco da parte di Terraform. Di seguito sono riportati i valori validi per questo argomento:
pd-ssd,pd-balanced,hyperdisk-extreme,hyperdisk-balanced, epd-extreme.Puoi eseguire l'override di questo tipo di disco predefinito, della dimensione del disco predefinita e delle IOPS predefinite utilizzando alcuni argomenti avanzati. Per ulteriori informazioni, vai alla tua directory di lavoro, quindi esegui il comando
terraform inite consulta il file/.terraform/modules/sap_hana_scaleout/variables.tf. Prima di utilizzare questi argomenti in produzione, assicurati di testarli in un ambiente non di produzione.Se vuoi utilizzare SAP HANA Native Storage Extension (NSE), devi eseguire il provisioning di dischi più grandi utilizzando gli argomenti avanzati.
use_single_shared_data_log_diskBooleano Facoltativo. Il valore predefinito è false, che indica a Terraform di eseguire il deployment di un disco permanente o Hyperdisk separato per ciascuno dei seguenti volumi SAP:/hana/data,/hana/log,/hana/sharede/usr/sap. Per montare questi volumi SAP sullo stesso disco permanente o Hyperdisk, specificatrue.public_ipBooleano Facoltativo. Determina se un indirizzo IP pubblico viene aggiunto o meno all'istanza VM. Il valore predefinito è true.service_accountStringa Facoltativo. Specifica l'indirizzo email di un account di servizio gestito dall'utente da utilizzare dalle VM host e dai programmi in esecuzione sulle VM host. Ad esempio svc-acct-name@project-id..Se specifichi questo argomento senza un valore o lo ometti, lo script di installazione utilizza l'account di servizio predefinito di Compute Engine. Per ulteriori informazioni, consulta Gestione di identità e accessi per i programmi SAP su Google Cloud.
sap_deployment_debugBooleano Facoltativo. Solo quando lassistenza clienti Google Cloud ti chiede di attivare il debug per il tuo deployment, specifica true, in modo che il deployment generi log dettagliati. Il valore predefinito èfalse.reservation_nameStringa Facoltativo. Per utilizzare una prenotazione VM Compute Engine specifica per questo dispiegamento, specifica il nome della prenotazione. Per impostazione predefinita, lo script di installazione seleziona qualsiasi prenotazione Compute Engine disponibile in base alle seguenti condizioni. Affinché una prenotazione sia utilizzabile, indipendentemente dal fatto che tu specifichi un nome o che lo script di installazione la selezioni automaticamente, la prenotazione deve essere impostata con quanto segue:
-
L'opzione
specificReservationRequiredè impostata sutrueo, nella Google Cloud console, è selezionata l'opzione Seleziona una prenotazione specifica. -
Alcuni tipi di macchine Compute Engine supportano piattaforme CPU non coperte dalla certificazione SAP del tipo di macchina. Se la prenotazione di destinazione riguarda uno dei seguenti tipi di macchine, deve specificare le piattaforme CPU minime come indicato:
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
Le piattaforme CPU minime per tutti gli altri tipi di macchine certificate da SAP per l'utilizzo su Google Cloud sono conformi al requisito minimo della CPU SAP.
vm_static_ipStringa Facoltativo. Specifica un indirizzo IP statico valido per l'istanza VM. Se non ne specifichi uno, verrà generato automaticamente un indirizzo IP per la tua istanza VM. Questo argomento è disponibile nella
sap_hana_scaleoutversione del modulo202306120959o successive.worker_static_ipsElenco(Stringa) Facoltativo. Specifica un array di indirizzi IP statici validi per le istanze worker nel sistema di scalabilità. Se non specifichi un valore per questo argomento, viene generato automaticamente un indirizzo IP per ogni istanza VM worker. Ad esempio, [ "1.0.0.1", "2.3.3.4" ].Gli indirizzi IP statici vengono assegnati nell'ordine di creazione delle istanze. Per esempio, se scegli di eseguire il deployment di 3 istanze di worker, ma specifichi solo 2 indirizzi IP per l'argomento
worker_static_ips, questi indirizzi IP vengono assegnati alle prime due istanze VM di cui viene eseguito il deployment dalla configurazione Terraform. Per la terza istanza VM worker, l'indirizzo IP viene generato automaticamente.Questo argomento è disponibile nella
sap_hana_scaleoutversione del modulo202306120959o successive.standby_static_ipsElenco(Stringa) Facoltativo. Specifica un array di indirizzi IP statici validi per le istanze di standby nel sistema di scalabilità. Se non specifichi un valore per questo argomento, viene generato automaticamente un indirizzo IP per ogni istanza VM di riserva. Ad esempio, [ "1.0.0.1", "2.3.3.4" ].Gli indirizzi IP statici vengono assegnati nell'ordine di creazione delle istanze. Ad esempio, se scegli di eseguire il deployment di 3 istanze di standby, ma specifichi solo 2 indirizzi IP per l'argomento
standby_static_ips, questi indirizzi IP vengono assegnati alle prime due istanze VM di cui viene eseguito il deployment dalla configurazione Terraform. Per la terza istanza VM di riserva, l'indirizzo IP viene generato automaticamente.Questo argomento è disponibile nella versione
sap_hana_scaleoutdel modulo202306120959o successive.L'esempio seguente mostra un file di configurazione completo che esegue il deployment di un sistema SAP HANA scalabile orizzontalmente con tre host worker e un host di riserva nella zona
us-central1-f. Ogni host è installato su una VMn2-highmem-32che esegue un sistema operativo Linux fornito da un'immagine pubblica di Compute Engine. I volumi NFS sono forniti da Filestore. Le password temporary vengono utilizzate solo durante l'elaborazione del deployment e della configurazione.Per chiarezza, i commenti nel file di configurazione sono omessi nell'esempio.
# ... module "hana_scaleout" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_scaleout/sap_hana_scaleout_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source property above and uncomment the source property below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_scaleout/sap_hana_scaleout_module.zip" # # ... # project_id = "example-project-123456" zone = "us-central1-f" machine_type = "n2-highmem-32" subnetwork = "example-sub-network-sap" linux_image = "sles-15-sp4-sap" linux_image_project = "suse-sap-cloud" instance_name = "hana-scaleout-w-failover" sap_hana_shared_nfs = "10.74.146.58:/hana_shr" sap_hana_backup_nfs = "10.188.249.170:/hana_bup" # ... sap_hana_deployment_bucket = "hana2-sp5-rev53" sap_hana_sid = "HF0" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_hana_worker_nodes = 3 sap_hana_standby_nodes = 1 vm_static_ip = "10.0.0.1" worker_static_ips = ["10.0.0.2", "10.0.0.3", "10.0.0.4"] standby_static_ips = ["10.0.0.5"] # ... }-
L'opzione
Inizializza la directory di lavoro corrente e scarica i file del plug-in e del modulo del provider Terraform per Google Cloud:
terraform init
Il comando
terraform initprepara la directory di lavoro per altri comandi Terraform.Per forzare l'aggiornamento del plug-in del provider e dei file di configurazione nella directory di lavoro, specifica il flag
--upgrade. Se il flag--upgradeviene omesso e non apporti modifiche alla directory di lavoro, Terraform utilizza le copie memorizzate nella cache locale, anche selatestè specificato nell'URLsource.Se vuoi, crea il piano di esecuzione Terraform:
terraform plan
Il comando
terraform planmostra le modifiche richieste dalla configurazione attuale. Se salti questo passaggio, il comandoterraform applycrea automaticamente un nuovo piano e ti chiede di approvarlo.Applica il piano di esecuzione:
terraform apply
Quando ti viene chiesto di approvare le azioni, inserisci
yes.Il comando
terraform applyconfigura l' Google Cloud infrastruttura. Quando la macchina Compute Engine si avvia, l' Google Cloud infrastruttura invoca gli script di avvio che configurano il sistema operativo e installano SAP HANA.Mentre Terraform ha il controllo, i messaggi di stato vengono scritti in Cloud Shell. Dopo l'attivazione degli script, i messaggi di stato vengono scritti in Logging e sono visualizzabili nella Google Cloud console, come descritto in Controllare i log di Logging.
Il tempo di completamento può variare, ma l'intera procedura richiede in genere da 45 minuti a un'ora.
Verifica del deployment
Per verificare il deployment, controlla i log di deployment in Cloud Logging, controlla i dischi e i servizi sulle VM degli host principali e di lavoro, visualizza il sistema in SAP HANA Studio e testa il rilevamento da parte di un host di riserva.
Controlla i log
Nella Google Cloud console, apri Cloud Logging per monitorare l'avanzamento dell'installazione e verificare la presenza di errori.
Filtra i log:
Esplora log
Nella pagina Esplora log, vai al riquadro Query.
Dal menu a discesa Risorsa, seleziona Globale e poi fai clic su Aggiungi.
Se non vedi l'opzione Globale, nell'editor di query inserisci la seguente query:
resource.type="global" "Deployment"Fai clic su Esegui query.
Visualizzatore log legacy
- Nella pagina Visualizzatore log legacy, seleziona Globale come risorsa di logging nel menu del selettore di base.
Analizza i log filtrati:
- Se viene visualizzato
"--- Finished", significa che l'elaborazione del deployment è completata e puoi procedere al passaggio successivo. Se viene visualizzato un errore relativo alla quota:
Nella pagina IAM e amministrazione Quote, aumenta le quote che non soddisfano i requisiti di SAP HANA elencati nella guida alla pianificazione di SAP HANA.
Apri Cloud Shell.
Vai alla tua directory di lavoro ed elimina il deployment per ripulire le VM e i dischi permanenti dall'installazione non riuscita:
terraform destroy
Quando ti viene chiesto di approvare l'azione, inserisci
yes.Esegui di nuovo il deployment.
- Se viene visualizzato
Connettiti alle VM per controllare i dischi e i servizi SAP HANA
Al termine del deployment, verifica che i dischi e i servizi SAP HANA siano stati implementati correttamente controllando i dischi e i servizi dell'host master e di un host worker.
Nella pagina delle istanze VM di Compute Engine, collegati all'istanza VM dell'host principale e all'istanza VM di un host worker facendo clic sul pulsante SSH nella riga di ciascuna delle due istanze VM.
Quando ti connetti all'host di lavoro, assicurati di non connetterti a un host di riserva. Gli host di riserva utilizzano la stessa convenzione di denominazione degli host worker, ma hanno il suffisso dell'host worker con il numero più alto prima del primo takeover. Ad esempio, se hai tre host worker e un host di riserva, prima del primo rilevamento l'host di riserva ha il suffisso "w4".
In ogni finestra del terminale, passa all'utente root.
sudo su -
In ogni finestra del terminale, viene visualizzato il file system del disco.
df -h
Nell'host principale, dovresti vedere un output simile al seguente:
hana-scaleout-w-failover:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 8.0K 4.0M 1% /dev tmpfs 189G 4.0K 189G 1% /dev/shm tmpfs 51G 18M 51G 1% /run tmpfs 4.0M 0 4.0M 0% /sys/fs/cgroup /dev/sdb3 45G 6.4G 39G 15% / /dev/sdb2 20M 3.0M 17M 15% /boot/efi 10.74.146.58:/hana_shr 2.5T 41G 2.3T 2% /hana/shared /dev/mapper/vg_hana_data-data 422G 12G 411G 3% /hana/data/HF0/mnt00001 /dev/mapper/vg_hana_log-log 128G 7.8G 121G 7% /hana/log/HF0/mnt00001 tmpfs 26G 0 26G 0% /run/user/174 10.188.249.170:/hana_bup 2.5T 0 2.4T 0% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/1000
Su un host di lavoro, tieni presente che le directory
/hana/datae/hana/loghanno montaggi diversi:hana-scaleout-w-failoverw1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 8.0K 4.0M 1% /dev tmpfs 189G 4.0K 189G 1% /dev/shm tmpfs 51G 9.4M 51G 1% /run tmpfs 4.0M 0 4.0M 0% /sys/fs/cgroup /dev/sda3 45G 6.4G 39G 15% / /dev/sda2 20M 3.0M 17M 15% /boot/efi tmpfs 26G 0 26G 0% /run/user/0 10.74.146.58:/hana_shr 2.5T 41G 2.3T 2% /hana/shared 10.188.249.170:/hana_bup 2.5T 0 2.4T 0% /hanabackup /dev/mapper/vg_hana_data-data 422G 593M 422G 1% /hana/data/HF0/mnt00002 /dev/mapper/vg_hana_log-log 128G 3.2G 125G 3% /hana/log/HF0/mnt00002 tmpfs 26G 0 26G 0% /run/user/1000
Su un host di riserva, le directory di dati e log non vengono montate fino a quando l'host di riserva non prende il controllo di un host non funzionante:
hana-scaleout-w-failoverw4:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 8.0K 4.0M 1% /dev tmpfs 189G 4.0K 189G 1% /dev/shm tmpfs 51G 9.4M 51G 1% /run tmpfs 4.0M 0 4.0M 0% /sys/fs/cgroup /dev/sda3 45G 6.4G 39G 15% / /dev/sda2 20M 3.0M 17M 15% /boot/efi tmpfs 26G 0 26G 0% /run/user/0 10.74.146.58:/hana_shr 2.5T 41G 2.3T 2% /hana/shared 10.188.249.170:/hana_bup 2.5T 0 2.4T 0% /hanabackup tmpfs 26G 0 26G 0% /run/user/1000
In ogni finestra del terminale, passa all'utente del sistema operativo SAP HANA. Sostituisci SID_LC con il valore
sap_hana_sidspecificato nel file di configurazione. Il valore SID_LC deve essere in minuscolo.su - SID_LCadm
In ogni finestra del terminale, assicurati che i servizi SAP HANA, come
hdbnameserver,hdbindexservere altri, siano in esecuzione nell'istanza.HDB info
Nell'host principale, dovresti vedere un output simile a quello riportato nel seguente esempio troncato:
hana-scaleout-w-failover:~ # su - hf0adm hf0adm@hana-scaleout-w-failover:/usr/sap/HF0/HDB00> HDB info USER PID PPID %CPU VSZ RSS COMMAND hf0adm 25987 25986 0.4 15248 6312 -sh hf0adm 26049 25987 0.0 10448 4036 \_ /bin/sh /usr/sap/HF0/HDB00/HDB info hf0adm 26084 26049 0.0 19892 3864 \_ ps fx -U hf0adm -o user:8,pid:8,ppid:8,pcpu:5,vsz:10,rss:10,args hf0adm 22386 22385 0.0 15248 6248 -sh hf0adm 19164 1 0.0 13604 3124 sapstart pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout-w-failover hf0adm 19171 19164 0.0 481188 84340 \_ /usr/sap/HF0/HDB00/hana-scaleout-w-failover/trace/hdb.sapHF0_HDB00 -d -nw -f /usr/sap/HF0/HDB00/hana-scaleout-w-failover/daemon.ini pf=/usr/sap/HF0/SYS/profile/HF0_HDB00_hana-scaleout-w-failover hf0adm 19193 19171 3.4 9616860 3970304 \_ hdbnameserver hf0adm 19583 19171 0.3 4636456 206500 \_ hdbcompileserver hf0adm 19586 19171 0.3 4883932 235764 \_ hdbpreprocessor hf0adm 19624 19171 5.9 9896896 4193620 \_ hdbindexserver -port 30003 hf0adm 19627 19171 1.2 7920208 1605448 \_ hdbxsengine -port 30007 hf0adm 20072 19171 0.5 6825984 531884 \_ hdbwebdispatcher hf0adm 15053 1 0.0 590628 33208 hdbrsutil --start --port 30003 --volume 3 --volumesuffix mnt00001/hdb00003.00003 --identifier 1689854702 hf0adm 14420 1 0.0 590560 33308 hdbrsutil --start --port 30001 --volume 1 --volumesuffix mnt00001/hdb00001 --identifier 1689854671 hf0adm 14155 1 0.1 554820 33320 /usr/sap/HF0/HDB00/exe/sapstartsrv pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout-w-failover -D -u hf0adm hf0adm 14030 1 0.0 57024 11060 /usr/lib/systemd/systemd --user hf0adm 14031 14030 0.0 243164 4036 \_ (sd-pam)
Su un host di lavoro, dovresti vedere un output simile a quello riportato nel seguente esempio troncato:
hana-scaleout-w-failoverw1:~ # su - hf0adm hf0adm@hana-scaleout-w-failoverw1:/usr/sap/HF0/HDB00> HDB info USER PID PPID %CPU VSZ RSS COMMAND hf0adm 16442 16441 0.0 15248 6276 -sh hf0adm 17317 16442 0.0 10448 4032 \_ /bin/sh /usr/sap/HF0/HDB00/HDB info hf0adm 17352 17317 0.0 19892 3816 \_ ps fx -U hf0adm -o user:8,pid:8,ppid:8,pcpu:5,vsz:10,rss:10,args hf0adm 11873 1 0.0 13604 3244 sapstart pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout-w-failoverw1 hf0adm 11880 11873 0.0 477076 84260 \_ /usr/sap/HF0/HDB00/hana-scaleout-w-failoverw1/trace/hdb.sapHF0_HDB00 -d -nw -f /usr/sap/HF0/HDB00/hana-scaleout-w-failoverw1/daemon.ini pf=/usr/sap/HF0/SYS/profile/HF0_HDB00_hana-scaleout-w-failoverw1 hf0adm 11902 11880 0.8 7738216 784912 \_ hdbnameserver hf0adm 12140 11880 0.4 4245828 199884 \_ hdbcompileserver hf0adm 12143 11880 0.4 4758024 235448 \_ hdbpreprocessor hf0adm 12176 11880 0.6 6046020 534448 \_ hdbwebdispatcher hf0adm 12210 11880 2.0 8363976 1743196 \_ hdbindexserver -port 30003 hf0adm 10452 1 0.0 525100 33640 hdbrsutil --start --port 30003 --volume 4 --volumesuffix mnt00002/hdb00004.00003 --identifier 1689855202 hf0adm 10014 1 0.1 554696 31992 /hana/shared/HF0/HDB00/exe/sapstartsrv pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout-w-failoverw1 -D -u hf0adm
Su un host di riserva, dovresti vedere un output simile a quello riportato nel seguente esempio troncato:
hana-scaleout-w-failoverw4:~ # su - hf0adm hf0adm@hana-scaleout-w-failoverw4:/usr/sap/HF0/HDB00> HDB info USER PID PPID %CPU VSZ RSS COMMAND hf0adm 15597 15596 0.5 15248 6272 -sh hf0adm 15659 15597 0.0 10448 4004 \_ /bin/sh /usr/sap/HF0/HDB00/HDB info hf0adm 15694 15659 0.0 19892 3860 \_ ps fx -U hf0adm -o user:8,pid:8,ppid:8,pcpu:5,vsz:10,rss:10,args hf0adm 10285 1 0.0 13604 3244 sapstart pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout-w-failoverw4 hf0adm 10292 10285 0.0 478076 84540 \_ /usr/sap/HF0/HDB00/hana-scaleout-w-failoverw4/trace/hdb.sapHF0_HDB00 -d -nw -f /usr/sap/HF0/HDB00/hana-scaleout-w-failoverw4/daemon.ini pf=/usr/sap/HF0/SYS/profile/HF0_HDB00_hana-scaleout-w-failoverw4 hf0adm 10314 10292 0.6 7468320 729308 \_ hdbnameserver hf0adm 10492 10292 0.3 3851320 191636 \_ hdbcompileserver hf0adm 10495 10292 0.3 4493296 227884 \_ hdbpreprocessor hf0adm 10528 10292 0.4 5381616 509368 \_ hdbwebdispatcher hf0adm 9750 1 0.0 620748 32796 /hana/shared/HF0/HDB00/exe/sapstartsrv pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout-w-failoverw4 -D -u hf0adm
Se utilizzi RHEL per SAP 9.0 o versioni successive, assicurati che i pacchetti
chkconfigecompat-openssl11siano installati nell'istanza VM.Per ulteriori informazioni di SAP, consulta Nota SAP 3108316 - Red Hat Enterprise Linux 9.x: installazione e configurazione .
Connetti SAP HANA Studio
Connettiti all'host SAP HANA principale da SAP HANA Studio.
Puoi connetterti da un'istanza di SAP HANA Studio esterna Google Cloud o da un'istanza su Google Cloud. Potresti dover attivare l'accesso alla rete tra le VM di destinazione e SAP HANA Studio.
Per utilizzare SAP HANA Studio su Google Cloud e abilitare l'accesso al sistema SAP HANA, consulta Installazione di SAP HANA Studio su una VM Windows Compute Engine.
In SAP HANA Studio, fai clic sulla scheda Landscape (Panoramica) nel riquadro di amministrazione del sistema predefinito. Dovresti visualizzare una schermata simile all'esempio riportato di seguito.
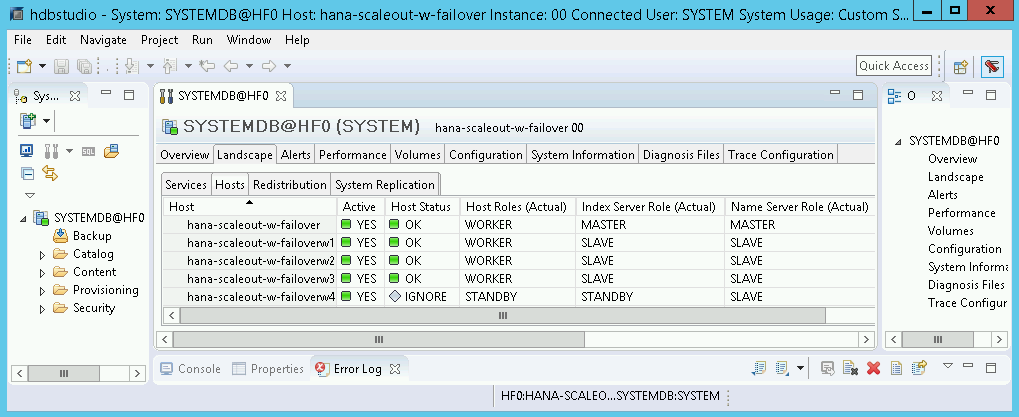
Ripulisci e riprova a eseguire il deployment
Se uno dei passaggi di verifica del deployment nelle sezioni precedenti indica che l'installazione non è andata a buon fine, devi annullare il deployment e riprovare completando i seguenti passaggi:
Risolvi eventuali errori per assicurarti che il deployment non fallisca di nuovo per lo stesso motivo. Per informazioni su come controllare i log o risolvere gli errori relativi alla quota, consulta Controllare i log.
Apri Cloud Shell o, se hai installato Google Cloud CLI sulla tua workstation locale, apri un terminale.
Vai alla directory contenente il file di configurazione Terraform utilizzato per questo deployment.
Elimina tutte le risorse che fanno parte del deployment eseguendo il seguente comando:
terraform destroy
Quando ti viene chiesto di approvare l'azione, inserisci
yes.Riprova il deployment come indicato in precedenza in questa guida.
Eseguire un test di failover
Dopo aver verificato che il sistema SAP HANA sia stato implementato correttamente, testa la funzione di failover.
Le istruzioni riportate di seguito attivano un failover passando all'utente del sistema operativo SAP HANA e inserendo il comando HDB stop. Il comando HDB stop
avvia un arresto di SAP HANA e scollega i dischi dall'host, il che consente un failover relativamente rapido.
Per eseguire un test di failover:
Connettiti alla VM di un host di lavoro tramite SSH. Puoi connetterti dalla pagina Istanze VM di Compute Engine facendo clic sul pulsante SSH per ogni istanza VM oppure puoi utilizzare il metodo SSH che preferisci.
Passa all'utente del sistema operativo SAP HANA. Nel comando seguente, sostituire SID_LC con il valore specificato per l'argomento
sap_hana_sidnel file di configurazione Terraform.su - SID_LCadm
Simula un errore arrestando SAP HANA:
HDB stop
Il comando
HDB stopavvia l'arresto di SAP HANA, che attiva un failover. Durante il failover, i dischi vengono scollegati dall'host in cui si è verificato l'errore e ricollegati all'host di riserva. L'host con errore viene riavviato e diventa un host di riserva.Dopo aver concesso il tempo necessario per il completamento del passaggio di proprietà, connettiti all'host che ha assunto il controllo dell'host non riuscito utilizzando SSH.
Passa all'utente root:
sudo su -
Visualizza le informazioni sul file system del disco:
df -h
Dovresti vedere un output simile al seguente. Tieni presente che le directory
/hana/datae/hana/logdell'host che ha avuto un errore ora sono montate sull'host che ha preso il controllo.hana-scaleout-w-failoverw4:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 8.0K 4.0M 1% /dev tmpfs 189G 4.0K 189G 1% /dev/shm tmpfs 51G 9.4M 51G 1% /run tmpfs 4.0M 0 4.0M 0% /sys/fs/cgroup /dev/sda3 45G 6.4G 39G 15% / /dev/sda2 20M 3.0M 17M 15% /boot/efi tmpfs 26G 0 26G 0% /run/user/0 10.74.146.58:/hana_shr 2.5T 41G 2.3T 2% /hana/shared 10.188.249.170:/hana_bup 2.5T 0 2.4T 0% /hanabackup tmpfs 26G 0 26G 0% /run/user/1000 /dev/mapper/vg_hana_data-data 422G 593M 422G 1% /hana/data/HF0/mnt00002 /dev/mapper/vg_hana_log-log 128G 3.2G 125G 3% /hana/log/HF0/mnt00002
In SAP HANA Studio, apri la visualizzazione Landscape del sistema SAP HANA per verificare che il failover sia andato a buon fine:
- Lo stato degli host coinvolti nel failover deve essere
INFO. - La colonna Ruolo del server di indicizzazione (effettivo) dovrebbe mostrare l'host con errori come il nuovo host di riserva.
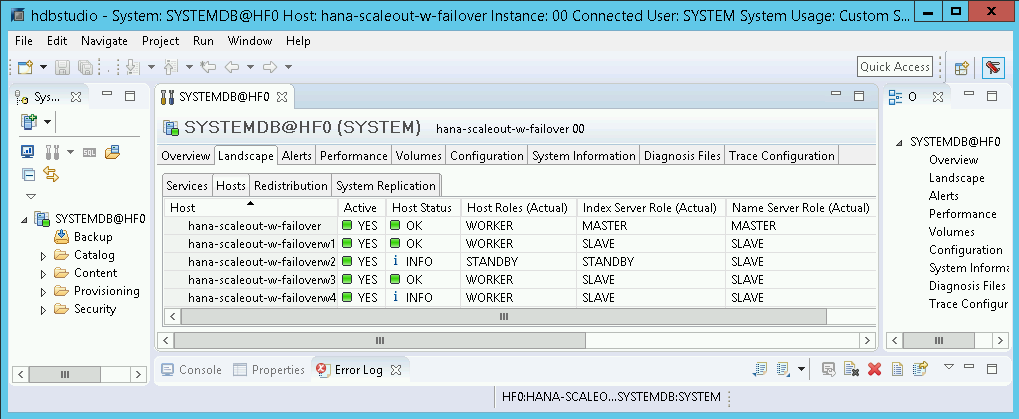
- Lo stato degli host coinvolti nel failover deve essere
Convalida l'installazione dell'agente per SAP di Google Cloud
Dopo aver disegnato una VM e installato il sistema SAP, verifica che Agent per SAP diGoogle Cloudfunzioni correttamente.
Verifica che l'agente per SAP di Google Cloudsia in esecuzione
Per verificare che l'agente sia in esecuzione:
Stabilisci una connessione SSH con la tua istanza Compute Engine.
Esegui questo comando:
systemctl status google-cloud-sap-agent
Se l'agente funziona correttamente, l'output contiene
active (running). Ad esempio:google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
Se l'agente non è in esecuzione, riavvialo.
Verificare che l'agente host SAP riceva le metriche
Per verificare che le metriche dell'infrastruttura vengano raccolte dall'agente diGoogle Cloudper SAP e inviate correttamente all'agente host SAP, segui questi passaggi:
- Nel sistema SAP, inserisci la transazione
ST06. Nel riquadro di panoramica, controlla la disponibilità e i contenuti dei seguenti campi per la configurazione end-to-end corretta dell'infrastruttura di monitoraggio di SAP e Google:
- Fornitore di servizi cloud:
Google Cloud Platform - Accesso al monitoraggio avanzato:
TRUE - Dettagli sul monitoraggio migliorati:
ACTIVE
- Fornitore di servizi cloud:
Configurare il monitoraggio per SAP HANA
Se vuoi, puoi monitorare le tue istanze SAP HANA utilizzando Agente per SAP diGoogle Cloud. Dalla versione 2.0, puoi configurare l'agente per raccogliere le metriche di monitoraggio di SAP HANA e inviarle a Cloud Monitoring. Cloud Monitoring ti consente di creare dashboard per visualizzare queste metriche, configurare avvisi in base alle soglie delle metriche e altro ancora.
Per ulteriori informazioni sulla raccolta delle metriche di monitoraggio di SAP HANA utilizzando Agente per SAP diGoogle Cloud, consulta la raccolta delle metriche di monitoraggio di SAP HANA.
Attivare il riavvio rapido di SAP HANA
Google Cloud Consiglia vivamente di attivare il riavvio rapido di SAP HANA per ogni istanza di SAP HANA, in particolare per le istanze più grandi. Il riavvio rapido di SAP HANA riduce il tempo di riavvio nel caso in cui SAP HANA si arresti, ma il sistema operativo rimanga in esecuzione.
Come configurato dagli script di automazione forniti,
le impostazioni del sistema operativo e del kernel supportano già il riavvio rapido di SAP HANA. Google Cloud
Devi definire il file system tmpfs e configurare SAP HANA.
Per definire il file system tmpfs e configurare SAP HANA, puoi seguire i passaggi manuali o utilizzare lo script di automazione fornito daGoogle Cloud per attivare il riavvio rapido di SAP HANA. Per ulteriori informazioni, consulta:
- Passaggi manuali: attivare il riavvio rapido di SAP HANA
- Passaggi automatici: attiva Fast Restart di SAP HANA
Per istruzioni autorevoli complete su SAP HANA Fast Restart, consulta la documentazione dell'opzione SAP HANA Fast Restart.
Procedura manuale
Configura il file system tmpfs
Dopo aver eseguito il deployment delle VM host e dei sistemi SAP HANA di base,
devi creare e montare le directory per i nodi NUMA nel file system tmpfs.
Mostra la topologia NUMA della VM
Prima di poter mappare il file system tmpfs richiesto, devi sapere quanti nodi NUMA sono presenti nella tua VM. Per visualizzare i nodi NUMA disponibili su una VM Compute Engine, inserisci il seguente comando:
lscpu | grep NUMA
Ad esempio, un tipo di VM m2-ultramem-208 ha quattro nodi NUMA,
numerati da 0 a 3, come mostrato nell'esempio seguente:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
Crea le directory dei nodi NUMA
Crea una directory per ogni nodo NUMA nella VM e imposta le autorizzazioni.
Ad esempio, per quattro nodi NUMA numerati da 0 a 3:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDMonta le directory dei nodi NUMA su tmpfs
Monta le directory del file system tmpfs e specifica
una preferenza per il nodo NUMA per ciascuna con mpol=prefer:
SID specifica il SID con lettere maiuscole.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
Aggiorna /etc/fstab
Per assicurarti che i punti di montaggio siano disponibili dopo il riavvio del sistema operativo, aggiungi voci alla tabella del file system, /etc/fstab:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
(Facoltativo) Imposta limiti all'utilizzo della memoria
Il file system tmpfs può aumentare e diminuire dinamicamente.
Per limitare la memoria utilizzata dal file system tmpfs, puoi impostare un limite di dimensioni per un volume del nodo NUMA con l'opzione size.
Ad esempio:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
Puoi anche limitare l'utilizzo complessivo della memoria tmpfs per tutti i nodi NUMA per
una determinata istanza SAP HANA e un determinato nodo del server impostando il
parametro persistent_memory_global_allocation_limit nella sezione [memorymanager]
del file global.ini.
Configurazione di SAP HANA per il riavvio rapido
Per configurare SAP HANA per il riavvio rapido, aggiorna il file global.ini
e specifica le tabelle da archiviare nella memoria persistente.
Aggiorna la sezione [persistence] nel file global.ini
Configura la sezione [persistence] nel file global.ini di SAP HANA
per fare riferimento alle località tmpfs. Separa ogni località tmpfs con un punto e virgola:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
L'esempio precedente specifica quattro volumi di memoria per quattro nodi NUMA,
che corrispondono a m2-ultramem-208. Se esegui la tua esecuzione su m2-ultramem-416, devi configurare otto volumi di memoria (0-7).
Riavvia SAP HANA dopo aver modificato il file global.ini.
Ora SAP HANA può utilizzare la posizione tmpfs come spazio di memoria permanente.
Specifica le tabelle da archiviare nella memoria persistente
Specifica tabelle o partizioni di colonne specifiche da archiviare nella memoria persistente.
Ad esempio, per attivare la memoria persistente per una tabella esistente, esegui la query SQL:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Per modificare il valore predefinito per le nuove tabelle, aggiungi il parametro
table_default nel file indexserver.ini. Ad esempio:
[persistent_memory] table_default = ON
Per ulteriori informazioni su come controllare le colonne, le tabelle e le visualizzazioni di monitoraggio che forniscono informazioni dettagliate, consulta Memoria persistente SAP HANA.
Passaggi automatici
Lo script di automazione fornito Google Cloud per attivare il riavvio rapido di SAP HANA apporta modifiche alle directory /hana/tmpfs*, al file /etc/fstab e alla configurazione di SAP HANA. Quando esegui lo script, potresti dover eseguire passaggi aggiuntivi a seconda che si tratti del deployment iniziale del sistema SAP HANA o se stai ridimensionando la macchina a una dimensione NUMA diversa.
Per il deployment iniziale del sistema SAP HANA o per il ridimensionamento della macchina al fine di aumentare il numero di nodi NUMA, assicurati che SAP HANA sia in esecuzione durante l'esecuzione dello script di automazione fornito per attivare il riavvio rapido di SAP HANA. Google Cloud
Quando redimensioni la macchina per ridurre il numero di nodi NUMA, assicurati che SAP HANA sia interrotta durante l'esecuzione dello script di automazione che consente di attivare il riavvio rapido di SAP HANA. Google Cloud Dopo l'esecuzione dello script, devi aggiornare manualmente la configurazione di SAP HANA per completare la configurazione del riavvio rapido di SAP HANA. Per ulteriori informazioni, consulta la configurazione di SAP HANA per il riavvio rapido.
Per attivare il riavvio rapido di SAP HANA, segui questi passaggi:
Stabilisci una connessione SSH con la VM host.
Passa al root:
sudo su -
Scarica lo script
sap_lib_hdbfr.sh:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Rendi eseguibile il file:
chmod +x sap_lib_hdbfr.sh
Verifica che lo script non contenga errori:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Se il comando restituisce un errore, contatta l'assistenza clienti Google Cloud. Per ulteriori informazioni su come contattare l'assistenza clienti, consulta Ricevere assistenza per SAP su Google Cloud.
Esegui lo script dopo aver sostituito l'ID sistema (SID) e la password di SAP HANA per l'utente SYSTEM del database SAP HANA. Per fornire la password in modo sicuro, ti consigliamo di utilizzare un secret in Secret Manager.
Esegui lo script utilizzando il nome di un secret in Secret Manager. Questo segreto deve esistere nel Google Cloud progetto che contiene l'istanza VM host.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Sostituisci quanto segue:
SID: specifica l'SID con lettere maiuscole. Ad esempio,AHA.SECRET_NAME: specifica il nome del segreto corrispondente alla password per l'utente SYSTEM del database SAP HANA. Questo segreto deve esistere nel Google Cloud progetto che contiene l'istanza VM host.
In alternativa, puoi eseguire lo script utilizzando una password in testo normale. Dopo aver attivato il riavvio rapido di SAP HANA, assicurati di cambiare la password. L'utilizzo di una password in testo normale non è consigliato perché la password verrà registrata nella cronologia della riga di comando della VM.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Sostituisci quanto segue:
SID: specifica l'SID con lettere maiuscole. Ad esempio,AHA.PASSWORD: specifica la password per l'utente SYSTEM del database SAP HANA.
Se l'esecuzione iniziale è andata a buon fine, dovresti visualizzare un output simile al seguente:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
Connessione a SAP HANA
Tieni presente che, poiché queste istruzioni non utilizzano un IP esterno per SAP HANA, puoi collegarti alle istanze SAP HANA solo tramite l'istanza bastion utilizzando SSH o tramite il server Windows utilizzando SAP HANA Studio.
Per connetterti a SAP HANA tramite l'istanza bastion, connettiti all'bastion host e poi alle istanze SAP HANA utilizzando un client SSH di tua scelta.
Per connetterti al database SAP HANA tramite SAP HANA Studio, utilizza un client desktop remoto per connetterti all'istanza Windows Server. Dopo la connessione, installa manualmente SAP HANA Studio e accedi al tuo database SAP HANA.
Eseguire le attività di post-deployment
Prima di utilizzare l'istanza SAP HANA, ti consigliamo di eseguire i seguenti passaggi di post-deployment. Per ulteriori informazioni, consulta la Guida all'installazione e all'aggiornamento di SAP HANA.
Modifica le password temporanee per l'amministratore di sistema SAP HANA e per il superutente del database.
Aggiorna il software SAP HANA con le patch più recenti.
Se il sistema SAP HANA è dipiegato su un'interfaccia di rete VirtIO, ti consigliamo di assicurarti che il valore del parametro TCP
/proc/sys/net/ipv4/tcp_limit_output_bytessia impostato su1048576. Questa modifica contribuisce a migliorare la velocità effettiva complessiva della rete sull'interfaccia di rete VirtIO senza influire sulla latenza della rete.Installa eventuali componenti aggiuntivi come le librerie di funzioni per le applicazioni (AFL) o l'accesso ai dati intelligenti (SDA).
Se esegui l'upgrade di un sistema SAP HANA esistente, carica i dati dal sistema esistente utilizzando procedure di backup e ripristino standard o la replica del sistema SAP HANA.
Configura e esegui il backup del nuovo database SAP HANA. Per ulteriori informazioni, consulta la guida alle operazioni di SAP HANA.
Valuta il tuo workload SAP HANA
Per automatizzare i controlli di convalida continua per i carichi di lavoro SAP HANA in esecuzione su Google Cloud, puoi utilizzare Workload Manager.
Workload Manager ti consente di eseguire automaticamente la scansione e la valutazione dei carichi di lavoro SAP HANA in base alle best practice di SAP Google Cloude dei fornitori di sistemi operativi. In questo modo, puoi migliorare la qualità, le prestazioni e l'affidabilità dei tuoi carichi di lavoro.
Per informazioni sulle best practice supportate da Workload Manager per la valutazione dei carichi di lavoro SAP HANA in esecuzione su Google Cloud, consulta Best practice di Workload Manager per SAP. Per informazioni sulla creazione e sull'esecuzione di una valutazione utilizzando Workload Manager, consulta Creare ed eseguire una valutazione.
Passaggi successivi
- Se devi utilizzare Google Cloud NetApp Volumes anziché i volumi Persistent Disk o Hyperdisk per ospitare directory SAP HANA come
/hana/sharedo/hanabackup, consulta le informazioni di implementazione dei NetApp Volumes nella guida alla pianificazione di SAP HANA. - Per ulteriori informazioni sull'amministrazione e sul monitoraggio delle VM, consulta la Guida alle operazioni di SAP HANA.