このガイドでは、Cloud Deployment Manager を使用して、SAP HANA ホストの自動フェイルオーバー障害復旧ソリューションが組み込まれた SAP HANA スケールアウト システムをデプロイする方法について説明します。Deployment Manager を使用すると、SAP のサポート要件を満たすシステムをデプロイし、SAP と Compute Engine 両方のベスト プラクティスを遵守できます。
作成された SAP HANA システムでは、1 つのマスターホスト、最大 15 までのワーカーホスト、最大 3 つまでのスタンバイ ホストを、1 つの Compute Engine ゾーン内に作成できます。
また、システムには、SAP HANA スタンバイ ノード用のGoogle Cloud ストレージ マネージャー(SAP HANA 用のストレージ マネージャー)も含まれ、フェイルオーバーの間、ストレージ デバイスのスタンバイ ノードへの転送を管理します。SAP HANA のストレージ マネージャーは、SAP HANA /shared ボリュームにインストールされます。SAP HANA 用ストレージ マネージャーと必要な IAM 権限については、SAP HANA 用ストレージ マネージャーをご覧ください。
Linux 高可用性クラスタに SAP HANA をデプロイする必要がある場合は、次のいずれかのガイドを使用してください。
- Deployment Manager: SAP HANA HA クラスタ構成ガイド
- RHEL 上の SAP HANA の HA クラスタ構成ガイド
- SLES 上の SAP HANA の HA クラスタ構成ガイド
このガイドは、高可用性のためのスタンバイ ホストおよびネットワーク ファイル システムを含む SAP のスケールアウト構成に精通した SAP HANA の上級ユーザーを対象としています。
前提条件
SAP HANA 高可用性スケールアウト システムを作成する前に、以下の要件を確認してください。
- SAP HANA プランニング ガイドと SAP HANA 高可用性プランニング ガイドを読んでいる。
- 個人または組織の Google Cloud アカウントがあり、SAP HANA をデプロイするためのプロジェクトが作成済み。Google Cloud アカウントとプロジェクトの作成については、SAP HANA デプロイガイドの Google アカウントの設定をご覧ください。
- データ所在地、アクセス制御、サポート担当者、規制要件に準拠しながら SAP ワークロードを実行する必要がある場合は、必要な Assured Workloads フォルダを作成する必要があります。詳細については、 Google Cloudでの SAP のコンプライアンスと主権管理をご覧ください。
- SAP HANA のインストール メディアが、ユーザーのデプロイ プロジェクトおよびリージョンで利用可能な Cloud Storage バケットに格納されている。SAP HANA インストール メディアを Cloud Storage バケットにアップロードする方法については、SAP HANA デプロイガイドの Cloud Storage バケットの作成をご覧ください。
- スケールアウトした SAP HANA システムのホスト間で SAP HANA の
/hana/sharedボリュームと/hanabackupボリュームを共有するために、マネージド Filestore ソリューションなどの NFS ソリューションが用意されている。Deployment Manager の構成ファイルで NFS サーバーのマウント ポイントを指定してから、システムをデプロイします。Filestore NFS サーバーをデプロイするには、インスタンスの作成をご覧ください。 SAP HANA スケールアウト ノードをホストする SAP HANA サブネットワーク内のすべての VM 間の通信が許可されている。
プロジェクト メタデータで OS Login が有効になっている場合は、デプロイが完了するまで一時的に OS Login を無効にする必要があります。デプロイのために、次の手順によりインスタンス メタデータで SSH 認証鍵を構成します。OS Login が有効になっている場合、メタデータ ベースの SSH 認証鍵構成は無効になり、このデプロイは失敗します。デプロイが完了したら、再度 OS Login を有効にできます。
詳細については、以下をご覧ください。
ネットワークの作成
セキュリティ上の理由から、新しいネットワークを作成します。アクセスできるユーザーを制御するには、ファイアウォール ルールを追加するか、別のアクセス制御方法を使用します。
プロジェクトにデフォルトの VPC ネットワークがある場合、デフォルトは使用せず、明示的に作成したファイアウォール ルールが唯一の有効なルールとなるように、独自の VPC ネットワークを作成してください。
デプロイ中、Compute Engine インスタンスは通常、 Google Cloudの SAP 用エージェントをダウンロードするためにインターネットにアクセスする必要があります。 Google Cloudから入手できる SAP 認定の Linux イメージのいずれかを使用している場合も、ライセンスを登録して OS ベンダーのリポジトリにアクセスするために、コンピューティング インスタンスからインターネットにアクセスする必要があります。このアクセスをサポートするために、NAT ゲートウェイを配置し、VM ネットワーク タグを使用して構成します。ターゲットのコンピューティング インスタンスに外部 IP がない場合でもこの構成が可能です。
ネットワークを設定するには:
コンソール
- Google Cloud コンソールで、[VPC ネットワーク] ページに移動します。
- [VPC ネットワークを作成] をクリックします。
- ネットワークの名前を入力します。
命名規則に従って名前を付けてください。VPC ネットワークは、Compute Engine の命名規則を使用します。
- [サブネット作成モード] で [カスタム] をクリックします。
- [新しいサブネット] セクションで、サブネットに次の構成パラメータを指定します。
- サブネットの名前を入力します。
- [リージョン] で、サブネットを作成する Compute Engine のリージョンを選択します。
- [IP スタックタイプ] で [IPv4(シングルスタック)] を選択し、CIDR 形式で IP アドレス範囲を入力します。(
10.1.0.0/24など)これはサブネットのプライマリ IPv4 範囲です。複数のサブネットワークを追加する場合は、ネットワーク内の各サブネットワークに重複しない CIDR IP 範囲を割り当ててください。各サブネットワークとその内部 IP 範囲は、単一のリージョンにマッピングされることに注意してください。
- [完了] をクリックします。
- さらにサブネットを追加するには、[サブネットを追加] をクリックして前の手順を繰り返します。ネットワークを作成した後で、ネットワークにさらにサブネットを追加できます。
- [作成] をクリックします。
gcloud
- Cloud Shell に移動します。
- カスタム サブネットワーク モードで新しいネットワークを作成するには、次のコマンドを実行します。
gcloud compute networks create NETWORK_NAME --subnet-mode custom
NETWORK_NAMEは、新しいネットワークの名前に置き換えます。命名規則に従って名前を付けてください。VPC ネットワークは、Compute Engine の命名規則を使用します。デフォルトの自動モードでは、各 Compute Engine リージョンにサブネットが自動的に作成されます。この自動モードを使用しないようにするには、
--subnet-mode customを指定します。詳しくは、サブネット作成モードをご覧ください。 - サブネットワークを作成し、リージョンと IP 範囲を指定します。
gcloud compute networks subnets create SUBNETWORK_NAME \ --network NETWORK_NAME --region REGION --range RANGE次のように置き換えます。
SUBNETWORK_NAME: 新しいサブネットワークの名前NETWORK_NAME: 前の手順で作成したサービスの名前REGION: サブネットワークを配置するリージョンRANGE: CIDR 形式で指定された IP アドレス範囲(例:10.1.0.0/24)。複数のサブネットワークを追加する場合は、ネットワーク内の各サブネットワークに重複しない CIDR IP 範囲を割り当ててください。各サブネットワークとその内部 IP 範囲は、単一のリージョンにマッピングされることに注意してください。
- 必要に応じて前の手順を繰り返し、サブネットワークを追加します。
NAT ゲートウェイの設定
パブリック IP アドレスなしで 1 台以上の VM を作成する必要がある場合は、ネットワーク アドレス変換(NAT)を使用して、VM がインターネットにアクセスできるようにする必要があります。Cloud NAT は Google Cloud の分散ソフトウェア定義マネージド サービスであり、VM からインターネットへのアウトバウンド パケットの送信と、それに対応するインバウンド レスポンス パケットの受信を可能にします。また、別個の VM を NAT ゲートウェイとして設定することもできます。
プロジェクトに Cloud NAT インスタンスを作成する方法については、Cloud NAT の使用をご覧ください。
プロジェクトに Cloud NAT を構成すると、VM インスタンスはパブリック IP アドレスなしでインターネットに安全にアクセスできるようになります。
ファイアウォール ルールの追加
デフォルトでは、暗黙のファイアウォール ルールにより、Virtual Private Cloud(VPC)ネットワークの外部からの受信接続がブロックされます。受信側の接続を許可するには、VM にファイアウォール ルールを設定します。VM との受信接続が確立されると、トラフィックはその接続を介して双方向に許可されます。
特定のポートへの外部アクセスを許可するファイアウォール ルールや、同じネットワーク上の VM 間のアクセスを制限するファイアウォール ルールも作成できます。VPC ネットワーク タイプとして default が使用されている場合は、default-allow-internal ルールなどの追加のデフォルト ルールも適用されます。追加のデフォルト ルールは、同じネットワークであれば、すべてのポートで VM 間の接続を許可します。
ご使用の環境に適用可能な IT ポリシーによっては、データベース ホストへの接続を分離するか制限しなければならない場合があります。これを行うには、ファイアウォール ルールを作成します。
目的のシナリオに応じて、次の対象にアクセスを許可するファイアウォール ルールを作成できます。
- すべての SAP プロダクトの TCP/IP にリストされているデフォルトの SAP ポート。
- パソコンまたは企業のネットワーク環境から Compute Engine VM インスタンスへの接続。使用すべき IP アドレスがわからない場合は、社内のネットワーク管理者に確認してください。
- SAP HANA サブネットワークの VM 間の通信(SAP HANA スケールアウト システムのノード間の通信や、3 層アーキテクチャのデータベース サーバーとアプリケーション サーバー間の通信など)。VM 間の通信を有効にするには、サブネットワーク内から発信されるトラフィックを許可するファイアウォール ルールを作成する必要があります。
ファイアウォール ルールを作成するには:
コンソール
Google Cloud コンソールで、VPC ネットワークの [ファイアウォール] ページに移動します。
ページ上部の [ファイアウォール ルールを作成] をクリックします。
- [ネットワーク] フィールドで、VM が配置されているネットワークを選択します。
- [ターゲット] フィールドで、ルールが適用される Google Cloud上のリソースを指定します。たとえば、[ネットワーク上のすべてのインスタンス] を指定します。 Google Cloud上の特定のインスタンスにルールを制限するには、[指定されたターゲットタグ] にタグを入力してください。
- [ソースフィルタ] フィールドで、次のいずれかを選択します。
- 特定の IP アドレスからの受信トラフィックを許可する場合は、[IP 範囲] を選択します。[ソース IP の範囲] フィールドで IP アドレスの範囲を指定します。
- サブネット: 特定のサブネットワークからの受信トラフィックを許可する場合に使用します。次の [サブネット] フィールドにサブネットワーク名を指定します。このオプションを使用すると、3 層構成またはスケールアウト構成で VM 間のアクセスを許可できます。
- [プロトコルとポート] セクションで、[指定したプロトコルとポート] を選択して
tcp:PORT_NUMBERを指定します。
[作成] をクリックしてファイアウォール ルールを作成します。
gcloud
次のコマンドを使用してファイアウォール ルールを作成します。
$ gcloud compute firewall-rules create FIREWALL_NAME
--direction=INGRESS --priority=1000 \
--network=NETWORK_NAME --action=ALLOW --rules=PROTOCOL:PORT \
--source-ranges IP_RANGE --target-tags=NETWORK_TAGSスタンバイ ホストがある SAP HANA スケールアウト システムの作成
次の手順では、以下の作業を実行します。
- 作成済みの構成ファイルのテンプレートを使用して Deployment Manager を呼び出し、SAP HANA システムを作成します。
- デプロイを確認します。
- ホストエラーをシミュレーションして、スタンバイ ホストをテストします。
以降の手順の一部では、gcloud コマンドを入力するために Cloud Shell を使用します。最新バージョンの Google Cloud CLI がインストールされている場合は、ローカル ターミナルからも gcloud コマンドを入力できます。
SAP HANA システムの定義と作成
次の手順では、Deployment Manager の構成ファイル テンプレートをダウンロードして完成させ、Deployment Manager を呼び出します。これにより、VM、永続ディスク、SAP HANA インスタンスがデプロイされます。
永続ディスクや CPU などプロジェクトのリソースの現在の割り当てが、インストールしようとしている SAP HANA システムに対して十分であることを確認します。割り当てが不足していると、デプロイは失敗します。SAP HANA の割り当て要件については、SAP HANA の料金と割り当てに関する考慮事項をご覧ください。
Cloud Shell を開きます。
SAP HANA 高可用性スケールアウト システムの
template.yaml構成ファイル テンプレートを作業ディレクトリにダウンロードします。wget https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/latest/dm-templates/sap_hana_scaleout/template.yaml
必要に応じて
template.yamlのファイル名を変更し、このファイルで定義する構成がわかるようにします。たとえば、hana2sp3rev30-scaleout.yamlのようなファイル名を使用できます。template.yamlファイルを Cloud Shell コードエディタで開きます。Cloud Shell コードエディタを開くには、Cloud Shell ターミナル ウィンドウの右上にある鉛筆アイコンをクリックします。
template.yamlファイルで、以下のプロパティ値のかっことその内容をご使用のインストール環境の値に置き換えて更新します。たとえば、[ZONE] を「us-central1-f」に置き換えます。プロパティ データ型 説明 type 文字列 デプロイ中に使用する Deployment Manager テンプレートの場所、タイプ、バージョンを指定します。
YAML ファイルには 2 つの
type仕様が含まれており、そのうちの 1 つがコメントアウトされています。デフォルトで有効なtype仕様では、テンプレート バージョンをlatestとして指定します。コメントアウトされているtype仕様では、タイムスタンプを使用して特定のテンプレート バージョンを指定します。すべてのデプロイで同じテンプレート バージョンを使用する必要がある場合は、タイムスタンプを含む
type仕様を使用します。instanceName文字列 SAP HANA マスターホストの VM インスタンスの名前。名前の指定に使用できるのは、小文字、数字、ハイフンのみです。ワーカーホストとスタンバイ ホストの VM インスタンスの名前は同じになり、「w」とホスト番号が追加された名前を用います。 instanceType文字列 SAP HANA を実行する Compute Engine 仮想マシンのタイプ。カスタム VM タイプが必要な場合は、必要な数に最も近く、かつ必要数以上の vCPU 数を持つ事前定義された VM タイプを指定します。デプロイが完了したら、vCPU 数とメモリ量を変更してください。 zone文字列 SAP HANA システムをデプロイして実行するゾーン。サブネットに選択したリージョン内である必要があります。 subnetwork文字列 前のステップで作成したサブネットワークの名前。共有 VPC にデプロイする場合は、この値を [SHAREDVPC_PROJECT]/[SUBNETWORK]の形式で指定します。例:myproject/network1linuxImage文字列 SAP HANA で使用する Linux オペレーティング システム イメージまたはイメージ ファミリーの名前。イメージ ファミリーを指定するには、ファミリー名に接頭辞 family/を追加します。たとえば、family/rhel-8-1-sap-haやfamily/sles-15-sp2-sapです。特定のイメージを指定するには、イメージ名のみを指定します。利用可能なイメージ ファミリーの一覧については、 Google Cloud コンソールの [イメージ] ページをご覧ください。linuxImageProject文字列 使用するイメージを含む Google Cloud プロジェクト。このプロジェクトは独自のプロジェクトか、 Google Cloud イメージ プロジェクトです。Compute Engine イメージの場合は、 rhel-sap-cloudかsuse-sap-cloudを指定します。ご利用のオペレーティング システムのイメージ プロジェクトを確認するには、オペレーティング システムの詳細をご覧ください。sap_hana_deployment_bucket文字列 前のステップでアップロードした SAP HANA インストール ファイルを含む、プロジェクト内の Cloud Storage バケットの名前。 sap_hana_sid文字列 SAP HANA システム ID。ID は英数字 3 文字で、最初の文字はアルファベットにする必要があります。文字は大文字のみ使用できます。 sap_hana_instance_number整数 SAP HANA システムのインスタンス番号(0~99)。デフォルトは 0 です。 sap_hana_sidadm_password文字列 デプロイ時に使用されるオペレーティング システム管理者向けの仮のパスワード。パスワードは 8 文字以上で設定し、少なくとも英大文字、英小文字、数字をそれぞれ 1 文字以上含める必要があります。 sap_hana_system_password文字列 デプロイ時に使用されるデータベースのスーパー ユーザーの一時パスワード。パスワードは 8 文字以上で設定し、少なくとも英大文字、英小文字、数字をそれぞれ 1 文字以上含める必要があります。 sap_hana_worker_nodes整数 追加で必要な SAP HANA ワーカーホストの数。1~15 のワーカーホスト数を指定できます。デフォルトの値は 1 です。 sap_hana_standby_nodes整数 追加で必要な SAP HANA スタンバイ ホストの数。1~3 のスタンバイ ホスト数を指定できます。デフォルト値は 1 です。 sap_hana_shared_nfs文字列 /hana/sharedボリュームの NFS マウント ポイント。例:10.151.91.122:/hana_shared_nfssap_hana_backup_nfs文字列 /hanabackupボリュームの NFS マウント ポイント。例:10.216.41.122:/hana_backup_nfsnetworkTag文字列 省略可。ファイアウォールまたはルーティングの目的で使用される、VM インスタンスを表すネットワーク タグ。カンマ区切りで複数指定できます。 publicIP: Noを指定していて、ネットワーク タグを指定しない場合は、インターネットへの別のアクセス手段を必ず指定してください。nic_typeString 省略可。ただし、ターゲット マシンと OS バージョンに適用可能な場合は推奨します。VM インスタンスで使用するネットワーク インターフェースを指定します。値には GVNICまたはVIRTIO_NETを指定できます。Google Virtual NIC(gVNIC)を使用するには、linuxImageプロパティの値として gVNIC をサポートする OS イメージを指定する必要があります。OS イメージの一覧については、オペレーティング システムの詳細をご覧ください。このプロパティの値を指定しなかった場合は、
この引数は、Deployment Manager テンプレート バージョンinstanceTypeプロパティに指定したマシンタイプに基づいて、ネットワーク インターフェースが自動的に選択されます。202302060649以降で使用できます。publicIPブール値 省略可。パブリック IP アドレスを VM インスタンスに追加するかどうかを指定します。デフォルトは Yesです。sap_hana_double_volume_size整数 省略可。HANA のボリューム サイズを 2 倍にします。複数の SAP HANA インスタンスや障害復旧用の SAP HANA インスタンスを同じ VM にデプロイする場合に役立ちます。デフォルトでは、SAP の認定とサポート要件を満たしつつ、ボリューム サイズがメモリ フットプリントに必要な最小サイズとして自動的に計算されます。 sap_hana_sidadm_uid整数 省略可。 SID_LCadmユーザー ID のデフォルト値をオーバーライドします。デフォルト値は 900 です。SAP ランドスケープ内での整合性を保つために、別の値に変更できます。sap_hana_sapsys_gid整数 省略可。sapsys のデフォルトのグループ ID をオーバーライドします。デフォルト値は 79 です。 sap_deployment_debugブール値 省略可。この値が Yesに設定されている場合、デプロイの際に詳細なログが生成されます。Google のサポート エンジニアからデバッグを有効にするように求められない限り、この設定はオンにしないでください。post_deployment_scriptブール値 省略可。デプロイが完了した後に実行するスクリプトの URL または保存場所。スクリプトは、ウェブサーバーか Cloud Storage バケットでホストする必要があります。値は、http://、https://、gs:// のいずれかで始めます。このスクリプトは、テンプレートで作成されたすべての VM で実行されることに注意してください。マスター インスタンスでのみ実行したい場合は、スクリプトの先頭にチェックを追加する必要があります。 以下は、us-central1-f ゾーンに 3 つのワーカーホストと 1 つのスタンバイ ホストを設定して、SAP HANA スケールアウト システムをデプロイする構成ファイルの例です。各ホストは、Compute Engine の公開イメージで提供される Linux オペレーティング システムが実行されている n2-highmem-32 VM にインストールされます。NFS ボリュームは Filestore によって提供されます。仮のパスワードは、デプロイと構成の処理時にのみ使用されます。指定したカスタム サービス アカウントが、デプロイされた VM のサービス アカウントになります。
resources: - name: sap_hana_ha_scaleout type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/latest/dm-templates/sap_hana_scaleout/sap_hana_scaleout.py # # By default, this configuration file uses the latest release of the deployment # scripts for SAP on Google Cloud. To fix your deployments to a specific release # of the scripts, comment out the type property above and uncomment the type property below. # # type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/YYYYMMDDHHMM/dm-templates/sap_hana_scaleout/sap_hana_scaleout.py # properties: instanceName: hana-scaleout-w-failover instanceType: n2-highmem-32 zone: us-central1-f subnetwork: example-sub-network-sap linuxImage: family/sles-15-sp2-sap linuxImageProject: suse-sap-cloud sap_hana_deployment_bucket: hana2-sp5-rev53 sap_hana_sid: HF0 sap_hana_instance_number: 00 sap_hana_sidadm_password: TempPa55word sap_hana_system_password: TempPa55word sap_hana_worker_nodes: 3 sap_hana_standby_nodes: 1 sap_hana_shared_nfs: 10.74.146.58:/hana_shr sap_hana_backup_nfs: 10.188.249.170:/hana_bup serviceAccount: sap-deploy-example@example-project-123456.次のコマンドを実行して、インスタンスを作成します。
gcloud deployment-manager deployments create [DEPLOYMENT_NAME] --config [TEMPLATE_NAME].yaml上記のコマンドによって Deployment Manager が起動します。これにより、 Google Cloud インフラストラクチャが設定され、別のスクリプトが呼び出されてオペレーティング システムの構成と SAP HANA のインストールが行われます。
Deployment Manager により制御が行われる間、ステータス メッセージは Cloud Shell に書き込まれます。スクリプトが呼び出されると、Logging のログの確認で説明されているように、ステータス メッセージが Logging に書き込まれ、 Google Cloud コンソールで表示できるようになります。
完了までの時間は一定ではありませんが、通常 30 分未満でプロセス全体が完了します。
デプロイの確認
デプロイを確認するには、Cloud Logging でデプロイログを確認、プライマリ ホストとワーカーホストの VM 上のディスクとサービスを確認して、SAP HANA Studio でシステムを表示し、スタンバイ ホストによる引き継ぎをテストします。
ログを調べる
Google Cloud コンソールで Cloud Logging を開いて、インストールの進行状況をモニタリングし、エラーがないか確認します。
ログをフィルタします。
ログ エクスプローラ
[ログ エクスプローラ] ページで、[クエリ] ペインに移動します。
[リソース] プルダウン メニューから [グローバル] を選択し、[追加] をクリックします。
[グローバル] オプションが表示されない場合は、クエリエディタに次のクエリを入力します。
resource.type="global" "Deployment"[クエリを実行] をクリックします。
以前のログビューア
- [以前のログビューア] ページの基本的なセレクタ メニューから、ロギング リソースとして [グローバル] を選択します。
フィルタされたログを分析します。
"--- Finished"が表示されている場合、デプロイメントは完了しています。次の手順に進んでください。割り当てエラーが発生した場合:
[IAM と管理] の [割り当て] ページで、SAP HANA プランニング ガイドに記載されている SAP HANA の要件を満たしていない割り当てを増やします。
Deployment Manager の [デプロイ] ページでデプロイメントを削除し、失敗したインストールから VM と永続ディスクをクリーンアップします。
デプロイを再実行します。
VM に接続してディスクと SAP HANA サービスを確認する
デプロイが完了したら、マスターホストといずれか 1 つのワーカーホストのディスクとサービスの状態をみて、ディスクと SAP HANA サービスが正しくデプロイされていることを確認します。
Compute Engine VM インスタンスのページで、2 つの VM インスタンスそれぞれの行に表示された [SSH] ボタンをクリックして、マスターホストの VM といずれか 1 つのワーカーホストの VM に接続します。
ワーカーホストに接続するときは、スタンバイ ホストに接続していないことを確認してください。スタンバイ ホストはワーカーホストと同じ命名規則を使用しますが、最初のテイクオーバーが行われるまでは、最も大きな数字のサフィックスをもつワーカーがスタンバイ ホストになります。たとえば、3 つのワーカーホストと 1 つのスタンバイ ホストがある場合、最初のテイクオーバーまでは、スタンバイ ホストのサフィックスは「w4」になります。
各ターミナル ウィンドウで、root ユーザーに切り替えます。
sudo su -
各ターミナル ウィンドウで、ディスク ファイル システムを表示します。
df -h
マスターホストでは、出力は次のようになります。
hana-scaleout-w-failover:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 0 189G 0% /dev/shm tmpfs 126G 18M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 45G 5.6G 40G 13% / /dev/sda2 20M 2.9M 18M 15% /boot/efi 10.135.35.138:/hana_shr 1007G 50G 906G 6% /hana/shared tmpfs 26G 0 26G 0% /run/user/473 10.197.239.138:/hana_bup 1007G 0 956G 0% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 /dev/mapper/vg_hana-data 709G 7.7G 702G 2% /hana/data/HF0/mnt00001 /dev/mapper/vg_hana-log 125G 5.3G 120G 5% /hana/log/HF0/mnt00001 tmpfs 26G 0 26G 0% /run/user/1003
ワーカーホストで、
/hana/dataディレクトリと/hana/logディレクトリは、マウントが異なることに注意してください。hana-scaleout-w-failoverw2:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 0 189G 0% /dev/shm tmpfs 126G 9.2M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 45G 5.6G 40G 13% / /dev/sda2 20M 2.9M 18M 15% /boot/efi tmpfs 26G 0 26G 0% /run/user/0 10.135.35.138:/hana_shr 1007G 50G 906G 6% /hana/shared 10.197.239.138:/hana_bup 1007G 0 956G 0% /hanabackup /dev/mapper/vg_hana-data 709G 821M 708G 1% /hana/data/HF0/mnt00003 /dev/mapper/vg_hana-log 125G 2.2G 123G 2% /hana/log/HF0/mnt00003 tmpfs 26G 0 26G 0% /run/user/1003
障害が発生したホストからテイクオーバーされるまでは、スタンバイ ホストにデータ ディレクトリとログ ディレクトリはマウントされません。
hana-scaleout-w-failoverw4:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 0 189G 0% /dev/shm tmpfs 126G 18M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 45G 5.6G 40G 13% / /dev/sda2 20M 2.9M 18M 15% /boot/efi tmpfs 26G 0 26G 0% /run/user/0 10.135.35.138:/hana_shr 1007G 50G 906G 6% /hana/shared 10.197.239.138:/hana_bup 1007G 0 956G 0% /hanabackup tmpfs 26G 0 26G 0% /run/user/1003
各ターミナル ウィンドウで、SAP HANA オペレーティング システムのユーザーに切り替えます。
su - SID_LCadm
SID_LCは、構成ファイルのテンプレートで指定した SID 値に置き換えます。すべて小文字を使用します。各ターミナル ウィンドウで、
hdbnameserver、hdbindexserverなどの SAP HANA サービスがインスタンスで実行されていることを確認します。HDB info
マスターホストでは、次の簡略化された出力例に似た出力が表示されます。
hf0adm@hana-scaleout-w-failover:/usr/sap/HF0/HDB00> HDB info USER PID PPID %CPU VSZ RSS COMMAND hf0adm 5936 5935 0.7 18540 6776 -sh hf0adm 6011 5936 0.0 14128 3856 \_ /bin/sh /usr/sap/HF0/HDB00/HDB info hf0adm 6043 6011 0.0 34956 3568 \_ ps fx -U hf0adm -o user:8,pid:8,ppid:8,pcpu:5,vsz:10 hf0adm 17950 1 0.0 23052 3168 sapstart pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout hf0adm 17957 17950 0.0 457332 70956 \_ /usr/sap/HF0/HDB00/hana-scaleout-w-failover/trace/hdb.sa hf0adm 17975 17957 1.8 9176656 3432456 \_ hdbnameserver hf0adm 18334 17957 0.4 4672036 229204 \_ hdbcompileserver hf0adm 18337 17957 0.4 4941180 257348 \_ hdbpreprocessor hf0adm 18385 17957 4.5 9854464 4955636 \_ hdbindexserver -port 30003 hf0adm 18388 17957 1.2 7658520 1424708 \_ hdbxsengine -port 30007 hf0adm 18865 17957 0.4 6640732 526104 \_ hdbwebdispatcher hf0adm 14230 1 0.0 568176 32100 /usr/sap/HF0/HDB00/exe/sapstartsrv pf=/hana/shared/HF0/profi hf0adm 10920 1 0.0 710684 51560 hdbrsutil --start --port 30003 --volume 3 --volumesuffix mn hf0adm 10575 1 0.0 710680 51104 hdbrsutil --start --port 30001 --volume 1 --volumesuffix mn hf0adm 10217 1 0.0 72140 7752 /usr/lib/systemd/systemd --user hf0adm 10218 10217 0.0 117084 2624 \_ (sd-pam)
ワーカーホストでは、次の簡略化された出力例に似た出力が表示されます。
hf0adm@hana-scaleout-w-failoverw2:/usr/sap/HF0/HDB00> HDB info USER PID PPID %CPU VSZ RSS COMMAND hf0adm 22136 22135 0.3 18540 6804 -sh hf0adm 22197 22136 0.0 14128 3892 \_ /bin/sh /usr/sap/HF0/HDB00/HDB info hf0adm 22228 22197 100 34956 3528 \_ ps fx -U hf0adm -o user:8,pid:8,ppid:8,pcpu:5,vsz:10 hf0adm 9138 1 0.0 23052 3064 sapstart pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout hf0adm 9145 9138 0.0 457360 70900 \_ /usr/sap/HF0/HDB00/hana-scaleout-w-failoverw2/trace/hdb. hf0adm 9163 9145 0.7 7326228 755772 \_ hdbnameserver hf0adm 9336 9145 0.5 4670756 226972 \_ hdbcompileserver hf0adm 9339 9145 0.6 4942460 259724 \_ hdbpreprocessor hf0adm 9385 9145 2.0 7977460 1666792 \_ hdbindexserver -port 30003 hf0adm 9584 9145 0.5 6642012 528840 \_ hdbwebdispatcher hf0adm 8226 1 0.0 516532 52676 hdbrsutil --start --port 30003 --volume 5 --volumesuffix mn hf0adm 7756 1 0.0 567520 31316 /hana/shared/HF0/HDB00/exe/sapstartsrv pf=/hana/shared/HF0/p
スタンバイ ホストでは、次の簡略化された出力例に似た出力が表示されます。
hana-scaleout-w-failoverw4:~ # su - hf0adm hf0adm@hana-scaleout-w-failoverw4:/usr/sap/HF0/HDB00> HDB info USER PID PPID %CPU VSZ RSS COMMAND hf0adm 19926 19925 0.2 18540 6748 -sh hf0adm 19987 19926 0.0 14128 3864 \_ /bin/sh /usr/sap/HF0/HDB00/HDB info hf0adm 20019 19987 0.0 34956 3640 \_ ps fx -U hf0adm -o user:8,pid:8,ppid:8,pcpu:5,vsz:10 hf0adm 8120 1 0.0 23052 3232 sapstart pf=/hana/shared/HF0/profile/HF0_HDB00_hana-scaleout hf0adm 8127 8120 0.0 457348 71348 \_ /usr/sap/HF0/HDB00/hana-scaleout-w-failoverw4/trace/hdb. hf0adm 8145 8127 0.6 7328784 708284 \_ hdbnameserver hf0adm 8280 8127 0.4 4666916 223892 \_ hdbcompileserver hf0adm 8283 8127 0.4 4939904 256740 \_ hdbpreprocessor hf0adm 8328 8127 0.4 6644572 534044 \_ hdbwebdispatcher hf0adm 7374 1 0.0 633568 31520 /hana/shared/HF0/HDB00/exe/sapstartsrv pf=/hana/shared/HF0/p
RHEL for SAP 9.0 以降を使用する場合は、パッケージ
chkconfigとcompat-openssl11が VM インスタンスにインストールされていることを確認してください。SAP の詳細については、SAP Note 3108316 - Red Hat Enterprise Linux 9.x: Installation and Configuration をご覧ください。
SAP HANA Studio を接続する
SAP HANA Studio から、SAP HANA のマスターホストに接続します。
接続は、 Google Cloud 外の SAP HANA Studio のインスタンス、または Google Cloudのインスタンスから行えます。ターゲット VM と SAP HANA Studio の間のネットワーク アクセスを有効にする必要がある場合があります。
Google Cloud で SAP HANA Studio を使用して SAP HANA システムへのアクセスを有効にする方法については、Compute Engine Windows VM への SAP HANA Studio のインストールをご覧ください。
SAP HANA Studio で、デフォルトのシステム管理パネルの [Landscape] タブをクリックすると、次のように表示されます。
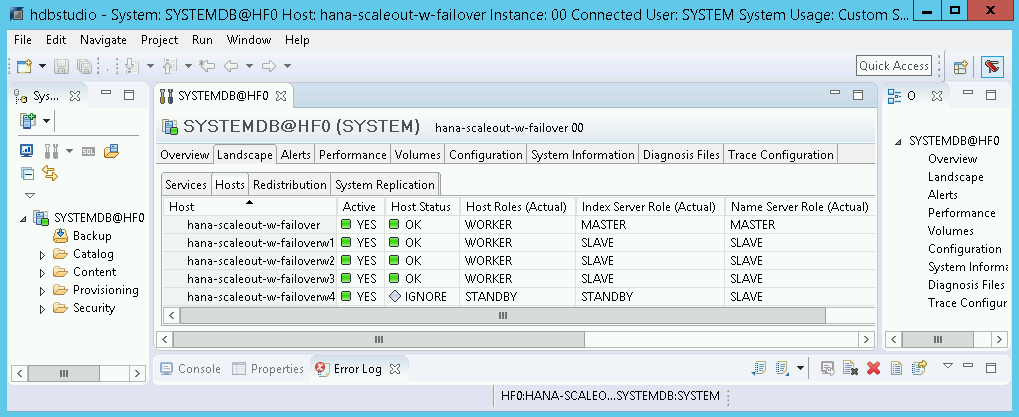
確認ステップの途中でインストールに失敗したことが示された場合、次の手順を行います。
- エラーを修正します。
- [デプロイ] ページで、デプロイメントを削除します。
- デプロイを再実行します。
フェイルオーバー テストを実行する
SAP HANA システムが正常にデプロイされたことを確認したら、フェイルオーバー機能をテストします。
次の手順では、SAP HANA オペレーティング システム ユーザーに切り替えて、HDB stop コマンドを入力することで、フェイルオーバーを作動させます。HDB stop コマンドは、SAP HANA の正常なシャットダウンを開始してホストからディスクを切断します。このため、比較的迅速なフェイルオーバーが可能です。
フェイルオーバーを行うには:
SSH を使用して、ワーカーホストの VM に接続します。各 VM インスタンスの [SSH] ボタンをクリックして、Compute Engine VM インスタンス ページから接続するか、任意の SSH メソッドを使用できます。
SAP HANA オペレーティング システムのユーザーに切り替えます。次の例では、
SID_LCをシステム用に定義した SID に置き換えます。su - SID_LCadm
SAP HANA を停止して、障害をシミュレートします。
HDB stop
HDB stopコマンドにより、SAP HANA のシャットダウンが開始し、フェイルオーバーがトリガーされます。フェイルオーバー時に、ディスクは障害が発生したホストから切断され、スタンバイ ホストに再アタッチされます。障害が発生したホストは、再起動してスタンバイ ホストになります。テイクオーバーの完了を待って、障害が発生したホストを引き継いだホストに、SSH を使用して再接続します。
root ユーザーに切り替えます。
sudo su -
マスターホストとワーカーホスト用の VM のディスク ファイル システムを表示します。
df -h
出力は次のようになります。障害が発生したホストの
/hana/dataディレクトリと/hana/logディレクトリが、テイクオーバーしたホストにマウントされています。hana-scaleout-w-failoverw4:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 0 189G 0% /dev/shm tmpfs 126G 9.2M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 45G 5.6G 40G 13% / /dev/sda2 20M 2.9M 18M 15% /boot/efi tmpfs 26G 0 26G 0% /run/user/0 10.74.146.58:/hana_shr 1007G 50G 906G 6% /hana/shared 10.188.249.170:/hana_bup 1007G 0 956G 0% /hanabackup /dev/mapper/vg_hana-data 709G 821M 708G 1% /hana/data/HF0/mnt00003 /dev/mapper/vg_hana-log 125G 2.2G 123G 2% /hana/log/HF0/mnt00003 tmpfs 26G 0 26G 0% /run/user/1003
SAP HANA Studio で、SAP HANA システムの [Landscape] ビューを開き、フェイルオーバーが正常に完了したことを確認します。
- フェイルオーバーに関係したホストのステータスは、
INFOと表示されます。 - [Index Server Role(Actual)] 列に、障害が発生したホストが新しいスタンバイ ホストとして表示されます。
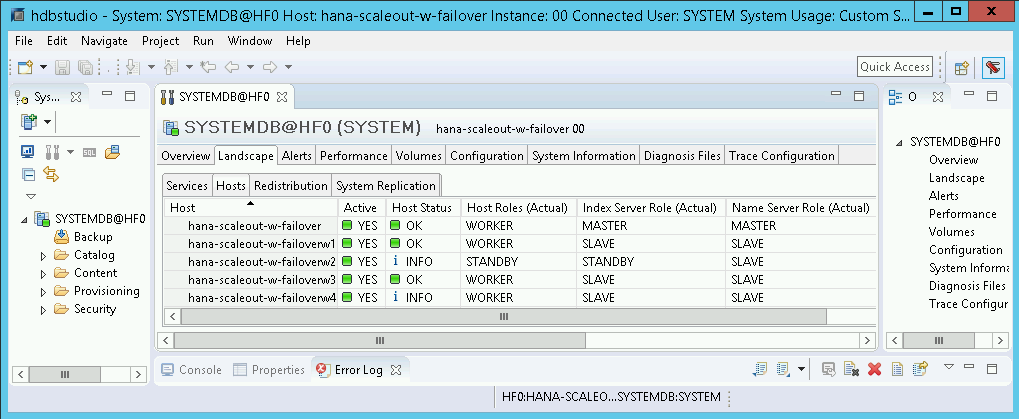
- フェイルオーバーに関係したホストのステータスは、
Google Cloudの SAP 用エージェントのインストールを検証する
VM をデプロイして SAP システムをインストールしたら、Google Cloudの SAP 用エージェントが正常に機能していることを確認します。
Google Cloudの SAP 用エージェントが実行されていることを確認する
エージェントの動作確認の手順は次のとおりです。
Compute Engine インスタンスと SSH 接続を確立します。
次のコマンドを実行します。
systemctl status google-cloud-sap-agent
エージェントが正常に機能している場合、出力には
active (running)が含まれます。次に例を示します。google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
エージェントが実行されていない場合は、エージェントを再起動します。
SAP Host Agent が指標を受信していることを確認する
Google Cloudの SAP 用エージェントによってインフラストラクチャの指標が収集され、SAP Host Agent に正しく送信されていることを確認するには、次の操作を行います。
- SAP システムで、トランザクションとして「
ST06」を入力します。 概要ウィンドウで可用性と以下のフィールドの内容を確認し、SAP と Google モニタリング インフラストラクチャのエンドツーエンドの設定が正しいか調べます。
- クラウド プロバイダ:
Google Cloud Platform - Enhanced Monitoring Access:
TRUE - Enhanced Monitoring Details:
ACTIVE
- クラウド プロバイダ:
SAP HANA のモニタリングを設定する
必要に応じて、Google Cloudの SAP 用エージェントを使用して SAP HANA インスタンスをモニタリングできます。バージョン 2.0 以降では、SAP HANA モニタリング指標を収集して Cloud Monitoring に送信するようにエージェントを構成できます。Cloud Monitoring を使用すると、これらの指標を可視化するダッシュボードを作成し、指標のしきい値などに基づくアラートを設定できます。
Google Cloudの SAP 用エージェントを使用した SAP HANA モニタリング指標の収集の詳細については、SAP HANA モニタリング指標の収集をご覧ください。
SAP HANA Fast Restart を有効にする
Google Cloud では、SAP HANA の各インスタンス(特に大規模なインスタンス)で SAP HANA Fast Restart を有効にすることを強くおすすめします。SAP HANA Fast Restart により、SAP HANA の終了後もオペレーティング システムが稼働し続けている場合の再起動時間が短縮されます。
Google Cloud が提供する自動化スクリプトによって構成されるように、オペレーティング システムとカーネルの設定は、すでに SAP HANA Fast Restart をサポートしています。tmpfs ファイル システムを定義し、SAP HANA を構成する必要があります。
tmpfs ファイル システムを定義して SAP HANA を構成するには、手動の手順を行うか、Google Cloud が提供する自動化スクリプトを使用して SAP HANA Fast Restart を有効にします。詳細については、次の情報をご覧ください。
SAP HANA Fast Restart の詳しい手順については、SAP HANA Fast Restart オプションのドキュメントをご覧ください。
手動で行う場合の手順
tmpfs ファイル システムを構成する
ホスト VM とベースとなる SAP HANA システムが正常にデプロイされたら、tmpfs ファイル システムで NUMA ノードのディレクトリを作成してマウントする必要があります。
VM の NUMA トポロジを表示する
必要な tmpfs ファイル システムをマッピングする前に、VM に含まれる NUMA ノードの数を確認する必要があります。Compute Engine VM で利用可能な NUMA ノードを表示するには、次のコマンドを入力します。
lscpu | grep NUMA
たとえば、m2-ultramem-208 VM タイプには、次の例に示すように、0~3 の番号が付いた 4 つの NUMA ノードがあります。
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
NUMA ノード ディレクトリを作成する
VM に NUMA ノードごとにディレクトリを作成し、権限を設定します。
たとえば、0~3 の番号が付いた 4 つの NUMA ノードの場合、次のようになります。
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDNUMA ノード ディレクトリを tmpfs にマウントする
tmpfs ファイル システム ディレクトリをマウントし、mpol=prefer を使用してそれぞれの NUMA ノードの優先順位を指定します。
SID: SID を大文字で指定します。
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
/etc/fstab の更新
オペレーティング システムの再起動後にマウント ポイントを使用できるようにするには、次のように、ファイル システム テーブル /etc/fstab にエントリを追加します。
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
省略可: メモリ使用量の上限を設定する
tmpfs ファイル システムは動的に拡張および縮小できます。
tmpfs ファイル システムで使用されるメモリを制限するには、size オプションを使用して NUMA ノード ボリュームのサイズ制限を設定します。次に例を示します。
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
また、global.ini ファイルの [memorymanager] セクションで persistent_memory_global_allocation_limit パラメータを設定して、特定の SAP HANA インスタンスと特定のサーバーノードにおけるすべての NUMA ノードについて、全体的な tmpfs メモリ使用量を制限できます。
Fast Restart 用の SAP HANA の構成
Fast Restart 用に SAP HANA を構成するには、global.ini ファイルを更新し、永続メモリに保存するテーブルを指定します。
global.ini ファイルの [persistence] セクションを更新する
tmpfs の場所を参照するように、SAP HANA の global.ini ファイルの [persistence] セクションを構成します。各 tmpfs の場所をセミコロンで区切ります。
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
上記の例では、4 つの NUMA ノードに 4 つのメモリ ボリュームを指定しています。これは、m2-ultramem-208 に対応しています。m2-ultramem-416 で実行している場合は、8 つのメモリ ボリューム(0~7)を構成する必要があります。
global.ini ファイルを変更したら、SAP HANA を再起動します。
SAP HANA では、tmpfs の場所を永続メモリ領域として使用できるようになりました。
永続メモリに保存するテーブルを指定する
永続メモリに保存する特定の列テーブルまたはパーティションを指定します。
たとえば、既存のテーブルの永続メモリを有効にするには、SQL クエリを実行します。
ALTER TABLE exampletable persistent memory ON immediate CASCADE
新しいテーブルのデフォルトを変更するには、indexserver.ini ファイルにパラメータ table_default を追加します。次に例を示します。
[persistent_memory] table_default = ON
列、テーブルのコントロール方法の詳細や、どのモニタリング ビューが詳細情報を提供するかは、SAP HANA 永続メモリをご確認ください。
自動で行う場合の手順
SAP HANA Fast Restart を有効にするために Google Cloud が提供する自動化スクリプトは、ディレクトリ /hana/tmpfs*、ファイル /etc/fstab、SAP HANA の構成を変更します。スクリプトを実行する際に、これが SAP HANA システムの初期デプロイか、マシンを別の NUMA サイズに変更するかによって、追加の手順が必要になる場合があります。
SAP HANA システムの初期デプロイや、NUMA ノードの数を増やすためにマシンのサイズを変更する場合は、 Google Cloud提供の自動化スクリプトで SAP HANA Fast Restart を有効にするときに、SAP HANA が稼働している必要があります。
NUMA ノードの数を減らすためにマシンサイズを変更する場合は、SAP HANA Fast Restart を有効にするために Google Cloud が提供する自動化スクリプトの実行中に SAP HANA が停止していることを確認してください。スクリプトの実行後、SAP HANA の構成を手動で更新し、SAP HANA Fast Restart の設定を完了する必要があります。詳細については、Fast Restart 用の SAP HANA の構成をご覧ください。
SAP HANA Fast Restart を有効にするには、次の手順を行います。
ホスト VM との SSH 接続を確立します。
root に切り替えます。
sudo su -
sap_lib_hdbfr.shスクリプトをダウンロードします。wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
ファイルを実行可能にします。
chmod +x sap_lib_hdbfr.sh
スクリプトにエラーがないことを確認します。
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
コマンドからエラーが返された場合は、Cloud カスタマーケアにお問い合わせください。カスタマーケアへのお問い合わせ方法については、 Google Cloudでの SAP に関するサポートを利用するをご覧ください。
スクリプトを実行する前に、SAP HANA のシステム ID(SID)とパスワードを SAP HANA データベースの SYSTEM ユーザーのものと置き換えてください。パスワードを安全に提供するには、Secret Manager でシークレットを使用することをおすすめします。
Secret Manager で、シークレットの名前を使用してスクリプトを実行します。このシークレットは、ホスト VM インスタンスを含む Google Cloud プロジェクトに存在している必要があります。
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
次のように置き換えます。
SID: SID を大文字で指定します。例:AHASECRET_NAME: SAP HANA データベースの SYSTEM ユーザーのパスワードに対応するシークレットの名前を指定します。このシークレットは、ホスト VM インスタンスを含む Google Cloud プロジェクトに存在している必要があります。
書式なしテキストのパスワードを使用してスクリプトを実行することもできます。SAP HANA Fast Restart を有効にした後、パスワードを変更します。パスワードは VM のコマンドライン履歴に記録されるため、書式なしテキストのパスワードの使用はおすすめしません。
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
次のように置き換えます。
SID: SID を大文字で指定します。例:AHAPASSWORD: SAP HANA データベースの SYSTEM ユーザーのパスワードを指定します。
初期実行に成功すると、次のような出力が表示されます。
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
SAP HANA へ接続する
この手順では SAP HANA に外部 IP を使用しないため、SAP HANA インスタンスに接続できるのは、SSH を使用して踏み台インスタンスを経由するか、SAP HANA Studio を使用して Windows サーバーを経由する場合だけになることに注意してください。
踏み台インスタンスを介して SAP HANA に接続するには、踏み台インスタンスに接続してから、任意の SSH クライアントを使用して SAP HANA インスタンスに接続します。
SAP HANA Studio を経由して SAP HANA データベースに接続するには、リモート デスクトップ クライアントを使用して、Windows Server インスタンスに接続します。接続後、手動で SAP HANA Studio をインストールし、SAP HANA データベースにアクセスします。
デプロイ後のタスクの実行
SAP HANA インスタンスを使用する前に、次のデプロイ後の手順を実行することをおすすめします。詳しくは、SAP HANA のインストールおよび更新ガイドをご覧ください。
SAP HANA システム管理者とデータベースのスーパーユーザーの仮のパスワードを変更します。
SAP HANA ソフトウェアを、最新のパッチで更新します。
アプリケーション機能ライブラリ(AFL)またはスマートデータ アクセス(SDA)などの、追加コンポーネントがあればインストールします。
既存の SAP HANA システムをアップグレードする場合は、標準のバックアップと復元手順か、SAP HANA システム レプリケーションを使用して、既存のシステムからデータを読み込みます。
新しい SAP HANA データベースを構成し、バックアップします。詳細については、SAP HANA オペレーション ガイドをご覧ください。
次のステップ
- VM の管理とモニタリングの詳細については、SAP HANA 運用ガイドをご覧ください。