Ce guide présente les options, les recommandations et les concepts généraux à connaître avant de déployer un système SAP HANA à haute disponibilité (HA) sur Google Cloud.
Dans ce guide, nous supposons que vous avez assimilé les concepts et les pratiques généralement nécessaires à la mise en œuvre d'un système SAP HANA à haute disponibilité. Par conséquent, il traitera principalement des informations à connaître pour mettre en œuvre un système de ce type sur Google Cloud.
Pour en savoir plus sur les concepts et les pratiques générales requis pour mettre en œuvre un système SAP HANA à haute disponibilité, consultez les pages suivantes :
- Le document sur les bonnes pratiques relatives à SAP : Générer la haute disponibilité pour SAP NetWeaver et SAP HANA sous Linux
- Documentation SAP HANA
Ce guide de planification se concentre uniquement sur la haute disponibilité pour SAP HANA et ne couvre pas la haute disponibilité pour les systèmes d'application. Pour en savoir plus sur la haute disponibilité pour SAP NetWeaver, consultez le guide de planification de la haute disponibilité pour SAP NetWeaver sur Google Cloud.
Ce guide ne remplace aucune documentation fournie par SAP.
Options de haute disponibilité pour SAP HANA sur Google Cloud
Vous pouvez utiliser une combinaison de fonctionnalités Google Cloud et SAP dans la conception d'une configuration à haute disponibilité pour SAP HANA capable de gérer les défaillances au niveau de l'infrastructure ou du logiciel. Le tableau suivant décrit les fonctionnalités SAP et Google Cloud permettant d'assurer une haute disponibilité.
| Fonctionnalité | Description |
|---|---|
| Migration à chaud de Compute Engine |
Compute Engine surveille l'état de l'infrastructure sous-jacente et migre automatiquement votre instance hors d'un événement de maintenance de l'infrastructure. Aucune intervention n'est requise de la part de l'utilisateur. Si possible, Compute Engine maintient votre instance en cours d'exécution pendant la migration. En cas de pannes majeures, il peut s'écouler quelques instants entre le moment de défaillance de l'instance et sa disponibilité. Dans les systèmes à hôtes multiples, les volumes partagés, tels que le volume "/hana/shared" utilisé dans le guide de déploiement, sont des disques persistants associés à la VM hébergeant l'hôte maître et installés sur NFS directement sur les hôtes de calcul. Le volume NFS est inaccessible pendant quelques secondes en cas de migration à chaud de l'hôte maître. Une fois que l'hôte maître a redémarré, le volume NFS fonctionne à nouveau sur tous les hôtes, et l'exécution normale reprend automatiquement. Une instance récupérée est identique à l'instance d'origine et conserve les éléments associés suivants : ID d'instance, adresse IP privée, métadonnées et stockage. Par défaut, les instances standards sont configurées pour une migration à chaud. Nous vous recommandons de ne pas modifier ce paramètre. Pour en savoir plus, consultez la section Migrer à chaud. |
| Redémarrage automatique de Compute Engine |
Si l'instance est configurée de manière à s'arrêter en cas d'événement de maintenance ou de plantage lié à un problème matériel sous-jacent, vous pouvez configurer Compute Engine pour qu'il la redémarre automatiquement. Par défaut, les instances sont configurées pour redémarrer automatiquement. Nous vous recommandons de ne pas modifier ce paramètre. |
| Redémarrage automatique du service SAP HANA |
Le redémarrage automatique du service SAP HANA est une solution de reprise après sinistre fournie par SAP. SAP HANA dispose de nombreux services configurés fonctionnant en permanence pour diverses activités. Lorsque l'un de ces services est désactivé en raison d'une défaillance logicielle ou d'une erreur humaine, la fonction de surveillance du redémarrage automatique du service SAP HANA le redémarre automatiquement. Une fois le service redémarré, il recharge toutes les données nécessaires dans la mémoire et reprend son fonctionnement. |
| Sauvegardes SAP HANA |
Les sauvegardes SAP HANA créent des copies des données de votre base de données qui peuvent servirent à reconstruire cette dernière à un moment précis. Pour en savoir plus sur l'utilisation des sauvegardes SAP HANA sur Google Cloud, consultez le guide d'utilisation de SAP HANA. |
| Réplication du stockage SAP HANA |
La réplication du stockage SAP HANA permet la reprise après sinistre au niveau du stockage par le biais de certains partenaires matériels. La réplication du stockage SAP HANA n'est pas disponible sur Google Cloud. À la place, vous pouvez utiliser des instantanés de disque persistant Compute Engine. Pour en savoir plus sur l'utilisation d'instantanés de disque persistant pour sauvegarder les systèmes SAP HANA sur Google Cloud, consultez le guide d'utilisation de SAP HANA. |
| Basculement automatique des hôtes SAP HANA |
Le basculement automatique des hôtes SAP HANA est une solution de reprise après sinistre locale qui nécessite un ou plusieurs hôtes SAP HANA de secours dans un système à scaling horizontal. En cas de défaillance de l'un des hôtes principaux, le basculement automatique des hôtes met automatiquement en ligne l'hôte de secours et redémarre l'hôte défaillant en tant qu'hôte de secours. Pour en savoir plus, consultez les pages suivantes : |
| Réplication du système SAP HANA |
La réplication du système SAP HANA vous permet de configurer un ou plusieurs systèmes pour prendre le relais de votre système principal dans des scénarios de haute disponibilité ou de reprise après sinistre. Vous pouvez adapter la réplication de façon à répondre à vos besoins en matière de performances et de temps de basculement. |
| Option de redémarrage rapide de SAP HANA (recommandée) |
Le redémarrage rapide de SAP HANA réduit le temps de redémarrage en cas d'arrêt de SAP HANA, mais le système d'exploitation reste en cours d'exécution. SAP HANA réduit le temps de redémarrage en exploitant la fonctionnalité de mémoire persistante SAP HANA afin de conserver les fragments de données MAIN des tables de magasin de colonnes dans la mémoire DRAM mappée au système de fichiers Pour en savoir plus sur l'utilisation de l'option Fast Restart pour SAP HANA, consultez les guides de déploiement à haute disponibilité : |
| Hooks de fournisseur HA/DR SAP HANA (recommandé) |
Les hooks de fournisseur HA/DR (haute disponibilité/reprise après sinistre) SAP HANA permettent à SAP HANA d'envoyer des notifications pour certains événements au cluster Pacemaker, améliorant ainsi la détection des défaillances. Les hooks de fournisseur de haute disponibilité/reprise après sinistre (HA/DR, High Availability/Disaster Recovery) SAP HANA nécessitent Pour plus d'informations sur l'utilisation des hooks de fournisseur HA/DR SAP HANA, consultez les guides de déploiement à haute disponibilité : |
Clusters à haute disponibilité natifs du système d'exploitation pour SAP HANA sur Google Cloud
Le clustering du système d'exploitation Linux permet de détecter l'état des applications et des invités, et automatise les actions de récupération en cas de défaillance.
Bien que les principes des clusters à haute disponibilité qui s'appliquent à des environnements non-cloud s'appliquent généralement sur Google Cloud, il existe des différences dans la mise en œuvre de certains éléments, tels que le cloisonnement et les adresses IP virtuelles.
Vous pouvez utiliser les distributions Linux à haute disponibilité Red Hat ou SUSE pour votre cluster HA pour SAP HANA sur Google Cloud.
Pour obtenir des instructions sur le déploiement et la configuration manuelle d'un cluster à haute disponibilité surGoogle Cloud pour SAP HANA, consultez les pages suivantes:
- Configuration manuelle d'un scaling à la hausse sur un cluster à haute disponibilité sur RHEL
- Configuration manuelle d'un cluster à haute disponibilité sur SLES :
Pour connaître les options de déploiement automatisé fournies par Google Cloud, consultez la section Options de déploiement automatisé pour les configurations SAP HANA à haute disponibilité.
Agents de ressource de cluster
Red Hat et SUSE fournissent des agents de ressources pour Google Cloud avec leurs implémentations haute disponibilité du logiciel de cluster Pacemaker. Les agents de ressources de Google Cloud gèrent le cloisonnement, les adresses IP virtuelles implémentées avec des routes ou des adresses IP d'alias, ainsi que des actions de stockage.
Afin de fournir des mises à jour qui ne sont pas encore incluses dans les agents de ressource de base du système d'exploitation,Google Cloud fournit périodiquement des agents associés aux ressources HA pour les clusters haute disponibilité pour SAP. Lorsque ces agents de ressources compagnons sont requis, les procédures de déploiement deGoogle Cloud incluent une étape de téléchargement.
Agents de cloisonnement
Dans le contexte du clustering de l'OS Google Cloud Compute Engine, le cloisonnement prend la forme de STONITH, qui fournit à chaque membre d'un cluster à deux nœuds la possibilité de redémarrer l'autre nœud.
Google Cloud fournit deux agents de cloisonnement à utiliser avec SAP sur les systèmes d'exploitation Linux, l'agent fence_gce inclus dans les distributions Linux Red Hat et SUSE Linux, et l'ancien agent gcpstonith, que vous pouvez également télécharger pour une utilisation avec des distributions Linux qui n'incluent pas l'agent fence_gce. Nous vous recommandons d'utiliser l'agent fence_gce, le cas échéant.
Autorisations IAM requises pour les agents de cloisonnement
Les agents de cloisonnement redémarrent les VM en envoyant un appel de réinitialisation à l'API Compute Engine. Pour l'authentification et l'autorisation d'accès à l'API, les agents de cloisonnement utilisent le compte de service de la VM. Le compte de service utilisé par un agent de cloisonnement doit disposer d'un rôle comprenant les autorisations suivantes :
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
Le rôle prédéfini d'administrateur d'instances Compute contient toutes les autorisations requises.
Pour limiter le champ d'application de l'autorisation de redémarrage de l'agent au nœud cible, vous pouvez configurer un accès basé sur les ressources. Pour en savoir plus, consultez la section Configurer un accès basé sur les ressources.
Adresse IP virtuelle
Les clusters à haute disponibilité pour SAP sur Google Cloud utilisent une adresse IP virtuelle (VIP) pour rediriger le trafic réseau d'un hôte à un autre en cas de basculement.
Les déploiements classiques hors cloud utilisent une requête ARP (Address Resolution Protocol) gratuite pour annoncer le déplacement et la réaffectation d'une adresse IP virtuelle vers une nouvelle adresse MAC.
Sur Google Cloud, au lieu d'utiliser des requêtes ARP gratuites, vous utilisez l'une des différentes méthodes pour déplacer et réaffecter une adresse IP virtuelle dans un cluster à haute disponibilité. La méthode recommandée consiste à utiliser un équilibreur de charge TCP/UDP interne, mais, selon vos besoins, vous pouvez également utiliser une mise en œuvre IPV basée sur les routes ou une mise en œuvre IPV basée sur l'adresse IP d'alias.
Pour en savoir plus sur l'implémentation des adresses IP virtuelles sur Google Cloud, consultez la page Mise en œuvre des adresses IP virtuelles sur Google Cloud.
Stockage et réplication
Une configuration de cluster SAP HANA à haute disponibilité utilise la réplication du système SAP HANA synchrone pour synchroniser les bases de données SAP HANA principale et secondaire. Les agents de ressources standards fournis par le système d'exploitation pour SAP HANA gèrent la réplication du système lors d'un basculement, en démarrant et en arrêtant la réplication, et en changeant les instances actives et les instances de secours du processus de réplication.
Si vous avez besoin d'un espace de stockage partagé, les fichiers NFS ou SMB peuvent fournir les fonctionnalités requises.
Pour une solution de stockage partagé à haute disponibilité, vous pouvez utiliser Filestore, le niveau de service Premium ou Extreme de Google Cloud NetApp Volumes ou une solution tierce de partage de fichiers. Le niveau de service régional (anciennement Enterprise) de Filestore peut être utilisé pour les déploiements multizones et le niveau de base de Filestore peut être utilisé pour les déploiements sur zones uniques.
Les disques persistants régionaux Compute Engine offrent un stockage de blocs répliqué de manière synchrone sur plusieurs zones. Bien que les disques persistants régionaux ne soient pas compatibles avec le stockage de base de données dans les systèmes SAP HA, vous pouvez les utiliser avec les serveurs de fichiers NFS.
Pour en savoir plus sur les options de stockage sur Google Cloud, consultez les ressources suivantes:
Paramètres de configuration des clusters à haute disponibilité sur Google Cloud
Google Cloud recommande de remplacer les valeurs par défaut de certains paramètres de configuration du cluster par des valeurs plus adaptées aux systèmes SAP dans l'environnement Google Cloud . Si vous utilisez les scripts d'automatisation fournis par Google Cloud, les valeurs recommandées sont définies automatiquement.
Considérez les valeurs recommandées comme un point de départ pour ajuster les paramètres Corosync dans votre cluster à haute disponibilité. Vous devez vérifier que la sensibilité de la détection des défaillances et le déclenchement du basculement sont adaptés à vos systèmes et charges de travail dans l'environnement Google Cloud .
Valeurs des paramètres de configuration Corosync
Dans les guides de configuration des clusters à haute disponibilité pour SAP HANA, Google Cloud recommande des valeurs pour plusieurs paramètres dans la section totem du fichier de configuration corosync.conf, qui sont différentes de celles définies par défaut par Corosync ou votre distributeur Linux. Google Cloud
totem pour lesquels Google Cloudrecommande des valeurs, ainsi que l'impact de la modification de ces valeurs. Pour connaître les valeurs par défaut de ces paramètres, qui peuvent différer entre les distributions Linux, consultez la documentation de votre distribution Linux.
| Paramètre | Valeur recommandée | Impact de la modification de la valeur |
|---|---|---|
secauth |
off |
Désactive l'authentification et le chiffrement de tous les messages totem. |
join |
60 (ms) | Augmente la durée pendant laquelle le nœud attend des messages join dans le protocole de souscription. |
max_messages |
20 | Augmente le nombre maximal de messages pouvant être envoyés par le nœud après réception du jeton. |
token |
20 000 (ms) | Augmente la durée pendant laquelle le nœud attend un jeton de protocole
L'augmentation de la valeur du paramètre La valeur du paramètre |
consensus |
N/A | Indique en millisecondes le délai d'attente avant d'obtenir un consensus avant de lancer une nouvelle série de configurations d'abonnements.
Nous vous recommandons d'omettre ce paramètre. Lorsque le paramètre consensus, assurez-vous que cette valeur est 24000 ou 1.2*token, selon la valeur la plus élevée.
|
token_retransmits_before_loss_const |
10 | Augmente le nombre de retransmissions de jetons effectuées par le nœud avant de conclure que le nœud destinataire a échoué et prend les mesures nécessaires. |
transport |
|
Spécifie le mécanisme de transport utilisé par Corosync. |
Pour en savoir plus sur la configuration du fichier corosync.conf, consultez le guide de configuration de votre distribution Linux :
- RHEL : Modifier les paramètres par défaut du fichier corosync.conf
- SLES : Créer les fichiers de configuration Corosync
Paramètres de délai d'expiration et d'intervalle pour les ressources de cluster
Lorsque vous définissez une ressource de cluster, vous définissez des valeurs interval et timeout, exprimées en secondes, pour différentes opérations de ressources (op). Exemple :
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
Les valeurs timeout affectent chacune des opérations de ressources différemment, comme expliqué dans le tableau suivant.
| Opération de ressource | Action en cas d'expiration |
|---|---|
monitor |
Si le délai avant expiration est dépassé, l'état de surveillance indique généralement un échec, et la ressource associée est considérée comme ayant échoué. Le cluster applique des options de récupération, qui peuvent inclure un basculement. Le cluster ne tente pas de relancer une opération de surveillance ayant échoué. |
start |
Si le lancement d'une ressource échoue avant qu'elle atteigne le délai avant expiration, le cluster tente de redémarrer la ressource. Le comportement est déterminé par l'action en échec associée à une ressource. |
stop |
Si une ressource ne répond pas à une opération d'arrêt avant que le délai avant expiration soit atteint, cela déclenche un événement de cloisonnement. |
En plus des autres paramètres de configuration du cluster, les paramètres interval et timeout des ressources du cluster affectent la vitesse à laquelle le logiciel du cluster détecte une défaillance et déclenche un basculement.
Les valeurs timeout et interval sont suggérées par Google Cloud dans les guides de configuration des clusters pour les événements de maintenance de migration à chaud des comptes SAP HANA pour Compute Engine.
Quelles que soient les valeurs timeout et interval utilisées, vous devez évaluer les valeurs lorsque vous testez votre cluster, en particulier lors des tests de migration à chaud, car la durée des événements de migration à chaud peut légèrement varier selon le type de machine dont vous vous servez et d'autres facteurs, tels que l'utilisation du système.
Paramètres des ressources de cloisonnement
Dans les guides de configuration des clusters à haute disponibilité pour SAP HANA, Google Cloudrecommande plusieurs paramètres lors de la configuration des ressources de cloisonnement du cluster à haute disponibilité. Les valeurs recommandées sont différentes de celles définies par défaut par Corosync ou votre distributeur Linux.
Le tableau suivant présente les paramètres de clôture que Google Cloudrecommande, ainsi que les valeurs recommandées et les détails des paramètres. Pour connaître les valeurs par défaut des paramètres, qui peuvent différer entre les distributions Linux, consultez la documentation de votre distribution Linux.
| Paramètre | Valeur recommandée | Détails |
|---|---|---|
pcmk_reboot_timeout |
300 secondes | Spécifie la valeur du délai avant expiration à utiliser pour les actions de redémarrage.
La valeur
|
pcmk_monitor_retries |
4 | Spécifie le nombre maximal de nouvelles tentatives à effectuer pour la commande monitor pendant le délai avant expiration. |
pcmk_delay_max |
30 secondes | Spécifie un délai aléatoire pour les actions de clôture afin d'éviter que les nœuds du cluster ne se clôturent simultanément. Pour éviter une concurrence de cloisonnement en vous assurant qu'une seule instance se voit attribuer un délai aléatoire, ce paramètre ne doit être activé que sur l'une des ressources de cloisonnement d'un cluster à haute disponibilité pour HANA (scaling à la hausse). Sur un cluster à haute disponibilité et à scaling horizontal pour HANA, ce paramètre doit être activé sur tous les nœuds faisant partie d'un site (principal ou secondaire). |
Tester votre cluster à haute disponibilité sur Google Cloud
Une fois le cluster configuré et déployé avec les systèmes SAP HANA dans votre environnement de test, vous devez tester le cluster pour vérifier que le système à haute disponibilité est configuré correctement et fonctionne comme prévu.
Pour vérifier que le basculement fonctionne comme prévu, simulez différents scénarios d'échec en effectuant les opérations suivantes :
- Arrêter la VM
- Créer une panique du noyau
- Fermer l'application
- Interrompre le réseau entre les instances
Simulez également un événement de migration à chaud de Compute Engine sur l'hôte principal pour confirmer qu'il ne déclenche pas de basculement. Vous pouvez simuler un événement de maintenance à l'aide de la commande gcloud compute instances
simulate-maintenance-event de Google Cloud CLI.
Journalisation et surveillance
Les agents de ressources peuvent inclure des fonctionnalités de journalisation qui propagent les journaux vers Google Cloud Observability pour analyse. Chaque agent de ressource inclut des informations de configuration qui identifient les options de journalisation. Dans le cas des mises en œuvre bash, l'option de journalisation est gcloud logging.
Vous pouvez également installer l'agent Cloud Logging pour capturer la sortie du journal des processus du système d'exploitation et corréler l'utilisation des ressources avec les événements système. L'agent Logging capture les journaux système par défaut, qui incluent les données de journal de Pacemaker et les services de clustering. Pour en savoir plus, consultez la section À propos de l'agent Logging.
Pour en savoir plus sur l'utilisation de Cloud Monitoring pour configurer des tests de service qui surveillent la disponibilité des points de terminaison de service, consultez la page Gérer les tests de disponibilité.
Comptes de service et clusters HD
Les actions que le logiciel du cluster peut effectuer dans l'environnement Google Cloudsont sécurisées par les autorisations accordées au compte de service de chaque VM hôte. Pour les environnements à sécurité élevée, vous pouvez limiter les autorisations des comptes de service de vos VM hôtes pour respecter le principe du moindre privilège.
Lorsque vous limitez les autorisations de compte de service, gardez à l'esprit que votre système peut interagir avec des services tels que Cloud Storage. Vous devrez donc peut-être inclure des autorisations pour ces interactions de service dans le compte de service de la VM hôte. Google Cloud
Pour les autorisations les plus restrictives, créez un rôle personnalisé avec les autorisations minimales requises. Pour en savoir plus sur les rôles personnalisés, consultez la page Créer et gérer les rôles personnalisés. Vous pouvez restreindre davantage les autorisations en les limitant à des instances spécifiques d'une ressource, telles que les instances de VM dans votre cluster HA, en ajoutant des conditions dans les liaisons de rôles d'une stratégie IAM d'une ressource.
Les autorisations minimales dont vos systèmes ont besoin dépendent des ressourcesGoogle Cloud auxquelles vos systèmes accèdent et des actions qu'ils exécutent. Par conséquent, pour déterminer les autorisations minimales requises pour les VM hôtes dans votre cluster à haute disponibilité, vous devrez peut-être rechercher précisément les ressources auxquelles les systèmes accèdent sur la VM hôte, ainsi que les actions que ces systèmes effectuent avec ces ressources.
Pour commencer, la liste suivante présente certaines ressources de cluster HA et les autorisations associées dont elles ont besoin :
- Cloisonnement
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- IPV mise en œuvre à l'aide d'une adresse IP d'alias
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- IPV mise en œuvre à l'aide de routes statiques
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- IPV mise en œuvre à l'aide d'un équilibreur de charge interne
- Aucune autorisation spécifique requise : l'équilibreur de charge fonctionne sur des états de vérification de l'état'état qui ne nécessitent pas d'interaction ou de modification des ressources dans Google Cloud
Mise en œuvre d'une adresse IP virtuelle sur Google Cloud
Un cluster à haute disponibilité utilise une adresse IP flottante ou virtuelle (IPV) pour déplacer sa charge de travail d'un nœud de cluster à un autre en cas de défaillance inattendue ou de maintenance planifiée. L'adresse IP de l'IPV ne changeant pas, les applications clientes ne savent pas que le travail est servi par un autre nœud.
Une adresse IP virtuelle est également appelée adresse IP flottante.
Sur Google Cloud, les adresses VIP sont implémentées légèrement différemment que dans les installations sur site. En effet, lorsqu'un basculement a lieu, les requêtes ARP gratuites ne peuvent pas être utilisées pour annoncer le changement. À la place, vous pouvez mettre en œuvre une adresse VIP pour un cluster SAP HA en utilisant l'une des méthodes suivantes :
- Équilibreur de charge réseau interne passthrough avec basculement (recommandé).
- Google Cloud routes statiques
- Google Cloud Adresses IP d'alias
Implémentations IPV pour équilibreur de charge réseau passthrough interne
Un équilibreur de charge répartit généralement le trafic utilisateur entre plusieurs instances de vos applications, à la fois pour répartir la charge de travail sur plusieurs systèmes actifs et pour vous protéger contre un ralentissement ou une défaillance du traitement sur une instance.
L'équilibreur de charge réseau passthrough interne fournit également une assistance de basculement que vous pouvez utiliser avec les vérifications d'état de Compute Engine pour détecter les défaillances, déclencher le basculement et rediriger le trafic vers un nouveau système SAP principal dans un cluster haute disponibilité natif au système d'exploitation.
La prise en charge du basculement est la mise en œuvre IPV recommandée pour diverses raisons, y compris :
- L'équilibrage de charge sur Compute Engine offre un SLA avec une disponibilité de 99,99 %.
- L'équilibrage de charge est compatible avec les clusters à haute disponibilité multizones, ce qui vous protège contre les défaillances de zone avec des temps de basculement interzone prévisibles.
- L'utilisation de l'équilibrage de charge réduit le temps nécessaire à la détection et au déclenchement d'un basculement, généralement quelques secondes après l'échec. Les temps de basculement globaux dépendent des temps de basculement de chacun des composants du système à haute disponibilité, qui peuvent inclure les hôtes, les systèmes de base de données, les systèmes d'application, etc.
- L'utilisation de l'équilibrage de charge simplifie la configuration du cluster et réduit les dépendances.
- Contrairement à une implémentation VIP utilisant des routes, avec l'équilibrage de charge, vous pouvez utiliser des plages d'adresses IP de votre propre réseau VPC, ce qui vous permet de les réserver et de les configurer selon vos besoins.
- L'équilibrage de charge peut facilement être utilisé pour réacheminer le trafic vers un système secondaire en cas d'interruption de maintenance planifiée.
Lorsque vous créez une vérification de l'état pour la mise en œuvre d'un équilibreur de charge d'une adresse IP virtuelle, vous spécifiez le port hôte que la vérification de l'état sonde pour déterminer l'état de l'hôte. Pour un cluster SAP HA, spécifiez un port hôte cible situé dans la plage privée (49152 à 65535) afin d'éviter toute interférence avec d'autres services. Sur la VM hôte, configurez le port cible avec un service d'assistance secondaire, tel que l'utilitaire Socat ou HAProxy.
Pour les clusters de base de données dans lesquels le système de secours secondaire reste en ligne, la vérification de l'état et le service d'aide permettent à l'équilibrage de charge de diriger le trafic vers le système en ligne qui sert actuellement de système principal dans le cluster.
À l'aide du service d'aide et de la redirection de port, vous pouvez déclencher un basculement pour une maintenance logicielle planifiée sur vos systèmes SAP.
Pour en savoir plus sur la compatibilité des basculements, consultez la page Configurer le basculement pour les équilibreurs de charge réseau passthrough internes.
Pour déployer un cluster à haute disponibilité avec une mise en œuvre d'une IPV par équilibreur de charge, consultez les pages suivantes :
- Terraform : Guide de configuration d'un cluster à haute disponibilité SAP HANA
- Guide de configuration d'un cluster à haute disponibilité pour SAP HANA sur RHEL
- Guide de configuration d'un cluster à haute disponibilité pour SAP HANA sur SLES
Mise en œuvre d'une IPV de routes statiques
La mise en œuvre de la route statique offre également une protection contre les défaillances de zone, mais vous oblige à utiliser une adresse IP virtuelle en dehors des plages d'adresses IP de vos sous-réseaux VPC existants. Par conséquent, vous devez également vous assurer que l'adresse IP virtuelle n'entre pas en conflit avec les adresses IP externes de votre réseau étendu.
Les mises en œuvre de routes statiques peuvent également compliquer l'utilisation de configurations VPC partagées, destinées à séparer la configuration réseau d'un projet hôte.
Si vous utilisez une mise en œuvre de route statique pour votre adresse IP virtuelle, consultez votre administrateur réseau afin de déterminer une adresse IP appropriée pour une mise en œuvre de route statique.
Mise en œuvre d'une IPV des adresses IP d'alias
Les implémentations IPV d'adresses IP d'alias ne sont pas recommandées pour les déploiements multizones haute disponibilité, car en cas de défaillance d'une zone, l'emplacement réel de l'adresse IP d'alias sur un nœud situé dans une zone différente peut être retardé. Mettez en œuvre votre adresse IP virtuelle avec un équilibreur de charge réseau passthrough interne compatible avec le basculement.
Si vous déployez tous les nœuds de votre cluster SAP HA dans la même zone, vous pouvez utiliser une adresse IP d'alias afin de mettre en œuvre une adresse IP virtuelle pour le cluster.
Si vous possédez des clusters SAP HA multizones qui utilisent une mise en œuvre d'IP d'alias pour l'adresse IP virtuelle, vous pouvez migrer vers une implémentation d'équilibreur de charge réseau passthrough interne sans modifier votre adresse IP virtuelle. Les adresses IP d'alias et les équilibreurs de charge réseau passthrough interne utilisent des plages d'adresses IP de votre réseau VPC.
Bien que les adresses IP d'alias ne soient pas recommandées pour les implémentations d'adresses IP virtuelles dans les clusters multizones à haute disponibilité, elles ont d'autres cas d'utilisation dans les déploiements SAP. Par exemple, elles peuvent être utilisées pour fournir un nom d'hôte logique et des attributions d'adresses IP pour les déploiements SAP flexibles, tels que ceux gérés par SAP Landscape Management.
Bonnes pratiques générales pour les adresses IP virtuelles sur Google Cloud
Pour en savoir plus sur les adresses VIP sur Google Cloud, consultez les bonnes pratiques pour les adresses IP flottantes.
Basculement automatique des hôtes SAP HANA sur Google Cloud
Google Cloud est compatible avec le basculement automatique des hôtes SAP HANA, la solution de reprise après sinistre locale fournie par SAP HANA. Celle-ci utilise un ou plusieurs hôtes de secours gardés en réserve pour prendre le relais de l'hôte maître ou d'un hôte de calcul en cas de défaillance. Les hôtes de secours ne contiennent aucune donnée ni ne traitent aucune tâche.
Une fois le basculement terminé, l'hôte défaillant est redémarré en tant qu'hôte de secours.
SAP accepte jusqu'à trois hôtes de secours dans les systèmes à scaling horizontal sur Google Cloud. Les hôtes de secours ne sont pas comptabilisés dans le nombre maximal de 16 hôtes actifs acceptés par SAP dans ces systèmes.Google Cloud
Pour en savoir plus sur la solution de basculement automatique des hôtes, consultez la page Basculement automatique des hôtes.
Quand utiliser le basculement automatique des hôtes SAP HANA sur Google Cloud
Le basculement automatique des hôtes SAP HANA offre une protection contre les défaillances affectant un seul nœud dans un système SAP HANA à scaling horizontal, y compris les défaillances des éléments suivants :
- L'instance SAP HANA
- Le système d'exploitation hôte
- La VM hôte
En ce qui concerne les défaillances de la VM hôte, sur Google Cloud, le redémarrage automatique, qui permet généralement de restaurer la VM hôte SAP HANA plus rapidement que le basculement automatique des hôtes, et la migration à chaud assurent tous deux une protection contre les interruptions de VM planifiées et non planifiées. Par conséquent, pour la protection des VM, la solution de basculement automatique des hôtes SAP HANA n'est pas nécessaire.
Le basculement automatique des hôtes SAP HANA ne protège pas contre les défaillances de zone, car tous les nœuds d'un système à scaling horizontal SAP HANA sont déployés dans une seule zone.
Le basculement automatique des hôtes SAP HANA ne précharge pas les données SAP HANA dans la mémoire des nœuds de secours. Ainsi, lorsqu'un nœud de secours prend le relais, le temps de récupération du nœud global est déterminé principalement par la durée de chargement des données dans la mémoire du nœud de secours.
Envisagez d'utiliser le basculement automatique des hôtes SAP HANA dans les situations suivantes :
- Les défaillances dans le logiciel ou le système d'exploitation hôte d'un nœud SAP HANA pouvant ne pas être détectées par Google Cloud.
- Les migrations Lift and Shift, dans lesquelles vous devez reproduire votre configuration SAP HANA sur site jusqu'à ce que vous puissiez optimiser SAP HANA pourGoogle Cloud.
- Lorsqu'une configuration entièrement répliquée interrégionale et multizones est trop coûteuse, et que votre entreprise peut tolérer les éléments suivants :
- Un temps de récupération de nœud plus long, car vous avez besoin de charger des données SAP HANA dans la mémoire d'un nœud de secours.
- Un risque de défaillance de zone.
Gestionnaire d'espace de stockage pour SAP HANA
Les volumes /hana/data et /hana/log ne sont installés que sur l'hôte maître et sur les hôtes de calcul. En cas de prise de relais, la solution de basculement automatique des hôtes utilise l'API SAP HANA Storage Connector et le gestionnaire d'espace de stockageGoogle Cloud pour les nœuds de secours SAP HANA pour déplacer les installations de volume de l'hôte défaillant vers l'hôte de secours.
Sur Google Cloud, le gestionnaire d'espace de stockage pour SAP HANA est requis pour les systèmes SAP HANA qui utilisent le basculement automatique des hôtes SAP HANA.
Versions compatibles du gestionnaire d'espace de stockage pour SAP HANA
Les versions 2.0 et ultérieures du gestionnaire d'espace de stockage pour SAP HANA sont compatibles. Toutes les versions antérieures à la version 2.0 sont obsolètes et ne sont plus compatibles. Si vous utilisez une version antérieure, mettez à jour votre système SAP HANA pour utiliser la dernière version du gestionnaire d'espace de stockage pour SAP HANA. Consultez la section Mettre à jour le gestionnaire d'espace de stockage pour SAP HANA.
Pour déterminer si votre version est obsolète, ouvrez le fichier gceStorageClient.py.
Le répertoire d'installation par défaut est /hana/shared/gceStorageClient.
À partir de la version 2.0, le numéro de version est indiqué dans les commentaires en haut du fichier gceStorageClient.py, comme illustré dans l'exemple suivant. Si le numéro de version est manquant, vous consultez une version obsolète du gestionnaire d'espace de stockage pour SAP HANA.
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
Installer le gestionnaire d'espace de stockage pour SAP HANA
La méthode recommandée pour installer le gestionnaire de stockage pour SAP HANA consiste à utiliser une méthode de déploiement automatisé pour déployer un système SAP HANA à scaling horizontal qui inclut le dernier gestionnaire de stockage pour SAP HANA.
Si vous devez ajouter le basculement automatique des hôtes SAP HANA à un système SAP HANA à évolutivité horizontale existant sur Google Cloud, l'approche recommandée est similaire: utilisez le fichier de configuration Terraform fourni par Google Cloud pour déployer un nouveau système SAP HANA à évolutivité horizontale, puis chargez les données dans le nouveau système à partir du système existant. Pour charger les données, vous pouvez utiliser soit des procédures standards de sauvegarde et de restauration SAP HANA, soit la réplication du système SAP HANA, ce qui peut limiter le temps d'arrêt. Pour en savoir plus sur la réplication du système, consultez la note SAP 2473002 : Utiliser la réplication du système HANA pour migrer le système effectuer un scaling horizontal horizontal.
Si vous ne pouvez pas utiliser de méthode de déploiement automatisé, envisagez de contacter un consultant en solution SAP, disponible via les services de conseilGoogle Cloud , afin d'obtenir une assistance pour installer manuellement le gestionnaire d'espace de stockage pour SAP HANA.
L'installation manuelle du gestionnaire d'espace de stockage pour SAP HANA dans un système SAP HANA à scaling horizontal existant ou nouveau n'est actuellement pas documentée.
Pour plus d'informations sur les options de déploiement automatisé pour le basculement automatique des hôtes SAP HANA, consultez la section Déploiement automatisé des systèmes à scaling horizontal SAP HANA avec basculement automatique des hôtes SAP HANA.
Mettre à jour le gestionnaire d'espace de stockage pour SAP HANA
Pour mettre à jour le gestionnaire d'espace de stockage pour SAP HANA, commencez par télécharger le package d'installation, puis exécutez un script d'installation qui met à jour le gestionnaire d'espace de stockage pour l'exécutable SAP HANA dans le lecteur /shared de SAP HANA.
La procédure suivante ne s'applique qu'à la version 2 du gestionnaire d'espace de stockage pour SAP HANA. Si vous utilisez une version du gestionnaire de stockage pour SAP HANA téléchargée avant le 1er février 2021, installez la version 2 avant de mettre à jour le gestionnaire de stockage pour SAP HANA.
Pour mettre à jour le gestionnaire d'espace de stockage pour SAP HANA, procédez comme suit :
Vérifiez la version actuelle de votre gestionnaire d'espace de stockage pour SAP HANA :
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
Si une mise à jour existe, installez-la :
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
Le gestionnaire d'espace de stockage pour SAP HANA mis à jour est installé dans
/usr/sap/google-sapgcestorageclient/gceStorageClient.py.Remplacez le fichier
gceStorageClient.pyexistant par le fichiergceStorageClient.pymis à jour :Si votre fichier
gceStorageClient.pyexistant se trouve dans/hana/shared/gceStorageClient, l'emplacement d'installation par défaut, mettez à jour le fichier à l'aide du script d'installation :sudo /usr/sap/google-sapgcestorageclient/install.sh
Si votre fichier
gceStorageClient.pyexistant ne se trouve pas dans/hana/shared/gceStorageClient, copiez le fichier mis à jour dans le même emplacement que votre fichier existant, en remplaçant le fichier existant.
Paramètres de configuration dans le fichier global.ini
Certains paramètres de configuration du gestionnaire d'espace de stockage pour SAP HANA, y compris l'activation ou la désactivation du cloisonnement, sont stockés dans la section de stockage du fichier SAP HANA global.ini. Lorsque vous utilisez le fichier de configuration Terraform fourni par Google Cloud pour déployer un système SAP HANA avec la fonction de basculement automatique des hôtes, le processus de déploiement ajoute automatiquement les paramètres de configuration au fichier global.ini.
L'exemple suivant montre le contenu d'un fichier global.ini créé pour le gestionnaire d'espace de stockage pour SAP HANA :
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_*__gcloudAccount = svc-acct-name@project-id. # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
Accès sudo du gestionnaire d'espace de stockage pour SAP HANA
Pour gérer les services et l'espace de stockage SAP HANA, le gestionnaire de stockage de SAP HANA utilise le compte utilisateur SID_LCadm et nécessite un accès sudo à certains binaires du système.
Si vous utilisez les scripts d'automatisation fournis par Google Cloud pour déployer SAP HANA avec basculement automatique des hôtes, l'accès sudo requis est configuré pour vous.
Si vous installez manuellement le gestionnaire de stockage pour SAP HANA, exécutez la commande visudo pour modifier le fichier /etc/sudoers afin d'accorder au compte utilisateur SID_LCadm un accès sudo aux binaires suivants.
Cliquez sur l'onglet correspondant à votre système d'exploitation :
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
L'exemple suivant montre une entrée du fichier /etc/sudoers. Dans l'exemple, l'ID système du système SAP HANA associé est remplacé par SID_LC. L'exemple d'entrée a été créé par la configuration Terraform fournie par Google Cloud pour le scaling horizontal de SAP HANA avec basculement automatique des hôtes.
L'entrée créée par la configuration Terraform inclut des binaires qui ne sont plus nécessaires, mais qui sont conservés pour des raisons de rétrocompatibilité. Vous ne devez inclure que les fichiers binaires qui apparaissent dans la liste précédente.
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
Configurer le compte de service pour le gestionnaire d'espace de stockage pour SAP HANA
Pour activer le basculement automatique des hôtes pour votre système SAP HANA à scaling horizontal sur Google Cloud, le gestionnaire de stockage pour SAP HANA nécessite un compte de service. Vous pouvez créer un compte de service dédié et lui accorder les autorisations requises pour effectuer des actions sur vos VM SAP HANA, telles que la dissociation et l'association de disques lors d'un basculement. Pour savoir comment créer un compte de service, consultez la section Créer un compte de service.
Autorisations IAM requises
Pour le compte de service utilisé par le gestionnaire de stockage pour SAP HANA, vous devez accorder un rôle qui inclut les autorisations IAM suivantes:
Pour réinitialiser une instance de VM à l'aide de la commande
gcloud compute instances reset, accordez l'autorisationcompute.instances.reset.Pour obtenir des informations sur un volume Persistent Disk ou Hyperdisk à l'aide de la commande
gcloud compute disks describe, accordez l'autorisationcompute.disks.get.Pour associer un disque à une instance de VM à l'aide de la commande
gcloud compute instances attach-disk, accordez l'autorisationcompute.instances.attachDisk.Pour dissocier un disque d'une instance de VM à l'aide de la commande
gcloud compute instances detach-disk, accordez l'autorisationcompute.instances.detachDisk.Pour lister les instances de VM à l'aide de la commande
gcloud compute instances list, accordez l'autorisationcompute.instances.list.Pour lister les volumes Persistent Disk ou Hyperdisk à l'aide de la commande
gcloud compute disks list, accordez l'autorisationcompute.disks.list.
Vous pouvez accorder les autorisations requises via des rôles personnalisés ou d'autres rôles prédéfinis.
Définissez également le champ d'application de la VM sur cloud-platform afin que les autorisations IAM de la VM soient entièrement déterminées par les rôles IAM que vous avez accordés au compte de service.
Par défaut, le gestionnaire de stockage de SAP HANA utilise le compte de service ou le compte utilisateur actif que gcloud CLI est autorisée à utiliser sur les hôtes du système SAP HANA évolutif.
Pour vérifier le compte actif utilisé par le gestionnaire d'espace de stockage pour SAP HANA, exécutez la commande suivante:
gcloud auth list
Pour en savoir plus sur cette commande, consultez gcloud auth list.
Pour modifier le compte utilisé par le gestionnaire de stockage pour SAP HANA, procédez comme suit:
Assurez-vous que le compte de service est disponible sur chacun des hôtes du système SAP HANA à évolutivité horizontale:
gcloud auth listDans le fichier
global.ini, mettez à jour la section[storage]avec le compte de service:[storage] ha_provider = gceStorageClient ... partition_*_*__gcloudAccount = SERVICE_ACCOUNTRemplacez
SERVICE_ACCOUNTpar le nom du compte de service, au format d'adresse e-mail, utilisé par le gestionnaire de stockage de SAP HANA. Ce compte de service est utilisé lors de l'émission de commandesgcloudà partir du gestionnaire de stockage pour SAP HANA.
Espace de stockage NFS pour le basculement automatique des hôtes SAP HANA
Un système SAP HANA à scaling horizontal avec basculement automatique des hôtes requiert une solution NFS, telle que Filestore, pour partager les volumes /hana/shared et /hanabackup entre tous les hôtes. Vous devez configurer vous-même la solution NFS.
Lorsque vous utilisez une méthode de déploiement automatisé, vous fournissez des informations sur le serveur NFS dans le fichier de déploiement, pour installer les répertoires NFS lors du déploiement.
Le volume NFS que vous utilisez doit être vide. Tous les fichiers existants peuvent entrer en conflit avec le processus de déploiement, en particulier si les fichiers ou les dossiers font référence à l'ID système SAP (SID, SAP system ID). Le processus de déploiement ne peut pas déterminer si les fichiers peuvent ou non être écrasés.
Le processus de déploiement stocke les volumes /hana/shared et /hanabackup sur le serveur NFS et installe le serveur NFS sur tous les hôtes, y compris les hôtes de secours. L'hôte maître gère ensuite le serveur NFS.
Si vous mettez en œuvre une solution de sauvegarde, telle que l'agent Backint de Cloud Storage pour SAP HANA, vous pouvez supprimer le volume /hanabackup du serveur NFS une fois le déploiement terminé.
Pour en savoir plus sur les solutions de fichiers partagés disponibles sur Google Cloud, consultez la page Solutions de partage de fichiers pour SAP sur Google Cloud.
Systèmes d'exploitation compatibles
Google Cloud n'est compatible avec le basculement automatique des hôtes SAP HANA que sur les systèmes d'exploitation suivants:
- RHEL pour SAP 7.7 ou version ultérieure
- RHEL pour SAP 8.1 ou version ultérieure
- RHEL pour SAP 9.0 ou version ultérieure
-
Avant d'installer un logiciel SAP sur RHEL pour SAP 9.x, vous devez installer des packages supplémentaires sur vos machines hôtes, en particulier
chkconfigetcompat-openssl11. Si vous utilisez une image fournie par Compute Engine, ces packages sont automatiquement installés pour vous. Pour en savoir plus, consultez la note SAP 3108316 – Red Hat Enterprise Linux 9.x : installation et configuration.
-
Avant d'installer un logiciel SAP sur RHEL pour SAP 9.x, vous devez installer des packages supplémentaires sur vos machines hôtes, en particulier
- SLES for SAP 12 SP5
- SLES pour SAP 15 SP1 ou version ultérieure
Pour savoir quelles images publiques sont disponibles avec Compute Engine, consultez la page Images.
Architecture d'un système SAP HANA avec basculement automatique des hôtes
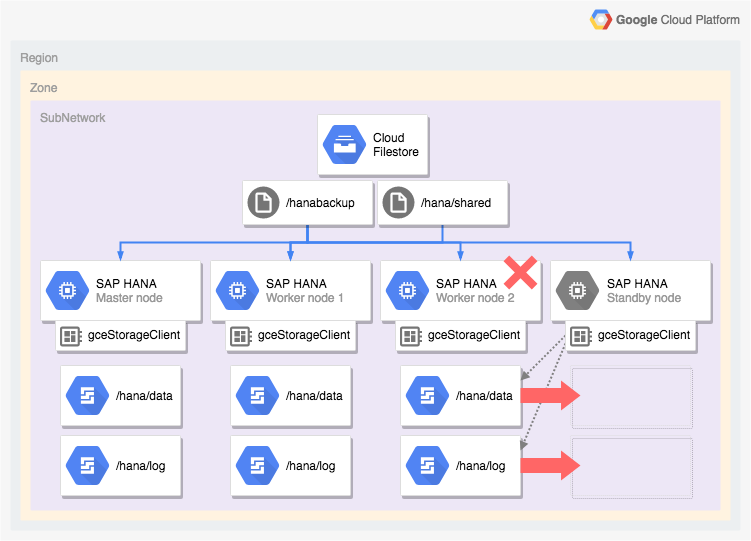
Le schéma suivant illustre une architecture à scaling horizontal sur Google Cloud qui inclut la fonctionnalité de basculement automatique des hôtes SAP HANA. Dans le schéma, le gestionnaire d'espace de stockage pour SAP HANA est représenté par le nom de son exécutable gceStorageClient.
Le schéma montre l'échec du nœud de calcul 2 et le nœud de secours qui prend le relais.
Le gestionnaire d'espace de stockage pour SAP HANA fonctionne avec l'API SAP Storage Connector (non illustrée) pour dissocier les disques contenant les volumes /hana/data et /hana/logs du nœud de calcul défaillant et les réinstaller sur le nœud de secours, qui devient ensuite le nœud de calcul 2 alors que le nœud défaillant devient le nœud de secours.
Options de déploiement automatisées pour les configurations de haute disponibilité SAP HANA
Google Cloud fournit des configurations Terraform que vous pouvez utiliser pour automatiser le déploiement de systèmes SAP HANA à haute disponibilité, ou vous pouvez déployer et configurer vos systèmes SAP HANA à haute disponibilité manuellement.
Google Cloud fournit des fichiers de configuration Terraform spécifiques au déploiement que vous effectuez. Vous utilisez les commandes Terraform standards pour initialiser votre répertoire de travail actuel et télécharger le plug-in et les fichiers de modules du fournisseur Terraform pour Google Cloud, puis appliquez la configuration pour déployer un système SAP HANA.
Cette méthode de déploiement automatisé déploie pour vous un système SAP HANA entièrement compatible avec SAP et conforme aux bonnes pratiques de SAP et deGoogle Cloud.
Déploiement automatisé de clusters Linux à haute disponibilité pour SAP HANA
Pour SAP HANA, la méthode de déploiement automatisé déploie un cluster Linux à haute disponibilité et aux performances optimisées, qui comprend les éléments suivants:
- Le basculement automatique
- Le redémarrage automatique
- Une réservation de l'adresse IP virtuelle (VIP) que vous spécifiez
- La compatibilité de basculement à l'aide de l'équilibrage de charge TCP/UDP interne, qui gère le routage depuis l'adresse IP virtuelle (VIP) vers les nœuds du cluster à haute disponibilité
- Une règle de pare-feu qui permet aux vérifications de l'état de Compute Engine de surveiller les instances de VM du cluster.
- Le gestionnaire de ressources de cluster à haute disponibilité Pacemaker
- Un mécanisme de cloisonnement Google Cloud
- Une VM dotée des disques persistants requis pour chaque instance SAP HANA
- Éventuellement, un nœud à locataire unique
- Des instances SAP HANA configurées pour la réplication synchrone et le préchargement de la mémoire
Pour automatiser le déploiement d'un cluster à haute disponibilité pour SAP HANA à l'aide de Terraform, consultez les pages suivantes:
- Terraform: Guide de configuration d'un cluster à haute disponibilité et à scaling à la hausse SAP HANA
- Terraform: Guide de configuration d'un cluster à haute disponibilité et à scaling horizontal SAP HANA
Déploiement automatisé de systèmes à évolutivité horizontale SAP HANA avec basculement automatique des hôtes SAP HANA
Vous pouvez utiliser Terraform pour automatiser le déploiement d'un système à scaling horizontal avec des hôtes de secours. Pour en savoir plus, consultez le guide de déploiement du système SAP HANA à évolutivité horizontale avec basculement automatique des hôtes.
Pour un système SAP HANA à scaling horizontal qui inclut la fonctionnalité de basculement automatique des hôtes SAP HANA, la configuration Terraform fournie par Google Cloud déploie les éléments suivants:
- une instance SAP HANA maître ;
- entre 1 et 15 hôtes de calcul ;
- entre 1 et 3 hôtes de secours ;
- une VM pour chaque hôte SAP HANA ;
- Des volumes Persistent Disk ou Hyperdisk, basés sur SSD, pour l'hôte maître et les hôtes de calcul
- Gestionnaire de stockage Google Cloud pour les nœuds de secours SAP HANA
Un système SAP HANA à scaling horizontal avec basculement automatique des hôtes requiert une solution NFS, telle que Filestore, pour partager les volumes /hana/shared et /hanabackup entre tous les hôtes. Pour que Terraform puisse installer les répertoires NFS lors du déploiement, vous devez configurer vous-même la solution NFS avant de déployer le système SAP HANA.
Pour configurer rapidement des instances de serveur NFS Filestore, suivez les instructions figurant sur la page Créer des instances.
Option active/active (lecture activée) pour SAP HANA
À partir de SAP HANA 2.0 SPS1, SAP fournit la configuration Active/Active (lecture activée) pour les scénarios SAP HANA System Replication. Dans un système de réplication configuré pour actif/actif (activé en lecture), les ports SQL du système secondaire sont ouverts pour un accès en lecture. Cela vous permet d'utiliser le système secondaire pour les tâches en lecture intensive et d'obtenir un meilleur équilibre des charges de travail entre les ressources de calcul, améliorant ainsi les performances globales de votre base de données SAP HANA. Pour en savoir plus sur la fonctionnalité active/active (lecture activée), consultez le guide d'administration de SAP HANA spécifique à votre version SAP HANA et la note SAP 1999880.
Pour configurer une réplication du système qui active l'accès en lecture sur votre système secondaire, vous devez utiliser le mode d'opération logreplay_readaccess. Toutefois, pour utiliser ce mode d'opération, vos systèmes principal et secondaire doivent exécuter la même version de SAP HANA. Par conséquent, il n'est pas possible d'accéder en lecture seule au système secondaire pendant une mise à niveau progressive tant que les deux systèmes n'exécutent pas la même version de SAP HANA.
Pour vous connecter à un système secondaire actif/actif (activé en lecture), SAP accepte les options suivantes :
- Connectez-vous directement en ouvrant une connexion explicite au système secondaire.
- Connectez-vous indirectement en exécutant une instruction SQL sur le système principal avec une optimisation, qui, lors de l'évaluation, redirige la requête vers le système secondaire.
Le schéma suivant illustre la première option, dans laquelle les applications accèdent directement au système secondaire dans un cluster Pacemaker déployé dans Google Cloud. Une adresse flottante ou IP virtuelle (VIP) supplémentaire est utilisée pour cibler l'instance de VM qui sert de système secondaire avec le cluster SAP HANA Pacemaker. L'adresse IP virtuelle suit le système secondaire et peut déplacer sa charge de travail de lecture d'un nœud de cluster à un autre en cas de défaillance inattendue ou de maintenance planifiée. Pour en savoir plus sur les méthodes de mise en œuvre des adresses IP virtuelles disponibles, consultez la page Mise en œuvre des adresses IP virtuelles sur Google Cloud.

Pour configurer la réplication du système SAP HANA avec Active/Active (lecture activée), dans un cluster Pacemaker :
- Configurer HANA actif/actif (lecture activée) dans un cluster SUSE Pacemaker
- Configurer HANA actif/actif (lecture activée) dans un cluster Red Hat Pacemaker
Étapes suivantes
Google Cloud et SAP fournissent tous deux plus d'informations sur la haute disponibilité.
En savoir plus sur la haute disponibilité de Google Cloud
Pour en savoir plus sur la haute disponibilité pour SAP HANA sur Google Cloud, consultez le guide d'utilisation de SAP HANA.
Pour obtenir des informations générales sur la protection des systèmes sur Google Cloudcontre divers scénarios de défaillance, consultez la page Concevoir des systèmes robustes.
En savoir plus sur les fonctionnalités de haute disponibilité de SAP HANA fournies par SAP
Pour en savoir plus sur les fonctionnalités de haute disponibilité de SAP HANA, reportez-vous aux documents SAP suivants :
- Haute disponibilité pour SAP HANA
- Note SAP 2057595 - Questions fréquentes: haute disponibilité SAP HANA
- How To Perform System Replication for SAP HANA 2.0
- Network Recommendations for SAP HANA System Replication