Panduan ini berisi ringkasan tentang opsi, rekomendasi, dan konsep umum yang perlu Anda ketahui sebelum men-deploy sistem SAP HANA ketersediaan tinggi (HA) di Google Cloud.
Panduan ini mengasumsikan bahwa Anda telah memahami konsep dan praktik yang secara umum diperlukan untuk menerapkan sistem ketersediaan tinggi SAP HANA. Oleh karena itu, panduan ini terutama berfokus pada hal yang perlu Anda ketahui untuk menerapkan sistem tersebut di Google Cloud.
Jika Anda perlu mengetahui lebih lanjut tentang konsep dan praktik umum yang diperlukan untuk menerapkan sistem SAP HANA HA, lihat:
- Dokumen praktik terbaik SAP Membangun Ketersediaan Tinggi untuk SAP NetWeaver dan SAP HANA di Linux
- Dokumentasi SAP HANA
Panduan perencanaan ini hanya berfokus pada HA untuk SAP HANA dan tidak mencakup HA untuk sistem aplikasi. Untuk mengetahui informasi tentang HA untuk SAP NetWeaver, lihat Panduan perencanaan ketersediaan tinggi untuk SAP NetWeaver di Google Cloud.
Panduan ini tidak menggantikan dokumentasi apa pun yang disediakan oleh SAP.
Opsi ketersediaan tinggi untuk SAP HANA di Google Cloud
Anda dapat menggunakan kombinasi fitur Google Cloud dan SAP dalam desain konfigurasi ketersediaan tinggi untuk SAP HANA yang dapat menangani kegagalan di tingkat infrastruktur atau software. Tabel berikut menjelaskan fitur SAP dan Google Cloud yang digunakan untuk menyediakan ketersediaan tinggi.
| Fitur | Deskripsi |
|---|---|
| Migrasi langsung Compute Engine |
Compute Engine memantau status infrastruktur dasar dan otomatis memigrasikan instance Anda dari peristiwa pemeliharaan infrastruktur. Tidak memerlukan intervensi pengguna. Compute Engine membuat instance Anda tetap berjalan selama migrasi jika memungkinkan. Dalam kasus pemadaman layanan yang signifikan, mungkin akan ada sedikit penundaan antara saat instance berhenti berfungsi dan saat tersedia. Dalam sistem multi-host, volume bersama, seperti volume `/hana/shared` yang digunakan dalam panduan deployment, merupakan persistent disk yang dipasang ke VM yang menghosting master host, dan terpasang di NFS ke worker host. Volume NFS tidak dapat diakses hingga beberapa detik jika terjadi migrasi langsung master host. Saat host master dimulai ulang, volume NFS akan berfungsi lagi pada semua host, dan operasi normal akan dilanjutkan secara otomatis. Instance yang dipulihkan sama persis dengan instance asli, termasuk ID instance, alamat IP pribadi, serta semua metadata dan penyimpanan instance. Secara default, instance standar disetel ke migrasi langsung. Sebaiknya jangan ubah setelan ini. Untuk mengetahui informasi selengkapnya, lihat Migrasi langsung. |
| Mulai ulang otomatis Compute Engine |
Jika instance Anda ditetapkan untuk berhenti saat ada peristiwa pemeliharaan, atau jika instance Anda error karena masalah hardware yang mendasar, Anda dapat menyiapkan Compute Engine untuk memulai ulang instance secara otomatis. Secara default, instance disetel untuk memulai ulang secara otomatis. Sebaiknya jangan ubah setelan ini. |
| Mulai Ulang Otomatis Layanan SAP HANA |
Mulai Ulang Otomatis Layanan SAP HANA adalah solusi pemulihan kesalahan yang disediakan oleh SAP. SAP HANA memiliki banyak layanan terkonfigurasi yang berjalan sepanjang waktu untuk berbagai aktivitas. Jika salah satu layanan ini dinonaktifkan karena kegagalan software atau error manusia, fungsi pengawas mulai ulang otomatis layanan SAP HANA akan memulai ulang secara otomatis. Saat dimulai ulang, layanan akan memuat semua data yang diperlukan kembali ke dalam memori dan melanjutkan operasinya. |
| Cadangan SAP HANA |
Pencadangan SAP HANA membuat salinan data dari database Anda yang dapat digunakan untuk merekonstruksi database ke suatu titik waktu. Untuk informasi selengkapnya tentang cara menggunakan cadangan SAP HANA di Google Cloud, lihat panduan operasi SAP HANA. |
| Replikasi Penyimpanan SAP HANA |
Replikasi penyimpanan SAP HANA menyediakan dukungan pemulihan dari bencana (disaster recovery) tingkat penyimpanan melalui partner hardware tertentu. Replikasi penyimpanan SAP HANA tidak didukung di Google Cloud. Sebagai gantinya, Anda dapat mempertimbangkan untuk menggunakan snapshot persistent disk Compute Engine. Untuk informasi selengkapnya tentang penggunaan snapshot disk persisten untuk mencadangkan sistem SAP HANA di Google Cloud, lihat panduan operasi SAP HANA. |
| Failover Otomatis Host SAP HANA |
Failover otomatis host SAP HANA adalah solusi pemulihan kesalahan lokal yang memerlukan satu atau beberapa host SAP HANA standby dalam sistem penyebaran skala. Jika salah satu host utama gagal, failover otomatis host akan otomatis mengaktifkan host standby dan memulai ulang host yang gagal sebagai host standby. Untuk informasi selengkapnya, lihat: |
| Replikasi Sistem SAP HANA |
Dengan replikasi sistem SAP HANA, Anda dapat mengonfigurasi satu atau beberapa sistem untuk mengambil alih sistem utama Anda dalam skenario ketersediaan tinggi atau pemulihan dari bencana (disaster recovery). Anda dapat menyesuaikan replikasi untuk memenuhi kebutuhan Anda dalam hal performa dan waktu failover. |
| Opsi Mulai Ulang Cepat SAP HANA (Direkomendasikan) |
Mulai Ulang Cepat SAP HANA mengurangi waktu mulai ulang jika SAP HANA
dihentikan, tetapi sistem operasi tetap berjalan. SAP HANA akan mengurangi
waktu mulai ulang dengan memanfaatkan fungsi memori persisten SAP HANA
untuk mempertahankan fragmen data MAIN tabel penyimpanan kolom
di DRAM yang dipetakan ke sistem file Untuk mengetahui informasi selengkapnya tentang penggunaan opsi Mulai Ulang Cepat SAP HANA, lihat panduan deployment ketersediaan tinggi: |
| Hook penyedia SAP HANA HA/DR (Direkomendasikan) |
Dengan hook penyedia SAP HANA HA/DR, SAP HANA dapat mengirimkan notifikasi
untuk peristiwa tertentu ke cluster Pacemaker, sehingga meningkatkan
deteksi kegagalan. Hook penyedia SAP HANA HA/DR memerlukan
Untuk informasi lebih lanjut tentang penggunaan hook penyedia SAP HANA HA/DR, lihat panduan deployment ketersediaan tinggi: |
Cluster HA native OS untuk SAP HANA di Google Cloud
Pengelompokan sistem operasi Linux memberikan kesadaran aplikasi dan tamu untuk status aplikasi Anda dan mengotomatiskan tindakan pemulihan jika terjadi kegagalan.
Meskipun prinsip cluster ketersediaan tinggi yang berlaku di lingkungan non-cloud umumnya berlaku di Google Cloud, ada perbedaan dalam penerapan beberapa hal, seperti pagar dan IP virtual.
Anda dapat menggunakan distribusi Linux ketersediaan tinggi Red Hat atau SUSE untuk cluster HA untuk SAP HANA di Google Cloud.
Untuk mendapatkan petunjuk tentang cara men-deploy dan mengonfigurasi cluster HA secara manual diGoogle Cloud untuk SAP HANA, lihat:
- Konfigurasi cluster peningkatan skala HA manual di RHEL
- Konfigurasi cluster HA manual di SLES:
Untuk mengetahui opsi deployment otomatis yang disediakan oleh Google Cloud, lihat Opsi deployment otomatis untuk konfigurasi ketersediaan tinggi SAP HANA.
Agen resource cluster
Red Hat dan SUSE menyediakan agen resource untuk Google Cloud dengan implementasi software cluster Pacemaker yang memiliki ketersediaan tinggi. Agen resource untuk Google Cloud mengelola pagar, VIP yang diimplementasikan dengan rute atau IP alias, dan tindakan penyimpanan.
Untuk mengirimkan update yang belum disertakan dalam agen resource OS dasar, Google Cloud secara berkala menyediakan agen resource pendamping untuk cluster HA bagi SAP. Jika agen resource pendamping ini diperlukan, prosedur deploymentGoogle Cloud akan menyertakan langkah untuk mendownloadnya.
Agen pemagaran
Pemagaran, dalam konteks Google Cloud pengelompokan OS Compute Engine, mengambil bentuk STONITH, yang memberi setiap anggota dalam cluster dua node kemampuan untuk memulai ulang node lainnya.
Google Cloud menyediakan dua agen pemagaran untuk digunakan dengan SAP di sistem operasi Linux, agen fence_gce yang disertakan dalam distribusi Red Hat dan SUSE Linux
yang tersertifikasi, serta agen gcpstonith lama, yang juga dapat didownload untuk digunakan dengan distribusi Linux yang tidak menyertakan
agen fence_gce. Sebaiknya gunakan agen fence_gce, jika
tersedia.
Izin IAM yang diperlukan untuk agen pemagaran
Agen pemagaran memulai ulang VM dengan melakukan panggilan reset ke Compute Engine API. Untuk autentikasi dan otorisasi guna mengakses API, agen pagar menggunakan akun layanan VM. Akun layanan yang digunakan oleh agen pagar harus diberi peran yang mencakup izin berikut:
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
Peran Compute Instance Admin bawaan berisi semua izin yang diperlukan.
Untuk membatasi cakupan izin mulai ulang agen ke node target, Anda dapat mengonfigurasi akses berbasis resource. Untuk informasi selengkapnya, lihat Mengonfigurasi akses berbasis resource.
Alamat IP virtual
Cluster ketersediaan tinggi untuk SAP di Google Cloud menggunakan alamat IP (VIP) virtual atau mengambang untuk mengalihkan traffic jaringan dari satu host ke host lain jika terjadi failover.
Deployment non-cloud biasa menggunakan permintaan Address Resolution Protocol (ARP) serampangan untuk mengumumkan perpindahan dan alokasi ulang VIP ke alamat MAC baru.
Di Google Cloud, daripada menggunakan permintaan ARP yang serampangan, Anda dapat menggunakan salah satu dari beberapa metode berbeda untuk memindahkan dan mengalokasikan ulang VIP dalam cluster HA. Metode yang direkomendasikan adalah menggunakan load balancer TCP/UDP internal. Namun, bergantung pada kebutuhan, Anda juga dapat menggunakan implementasi VIP berbasis rute atau implementasi VIP berbasis IP alias.
Untuk mengetahui informasi selengkapnya tentang implementasi VIP di Google Cloud, lihat Implementasi IP virtual di Google Cloud.
Penyimpanan dan replikasi
Konfigurasi cluster SAP HANA HA menggunakan Replikasi Sistem SAP HANA sinkron untuk menjaga database SAP HANA utama dan sekunder tetap sinkron. Agen resource standar yang disediakan OS untuk SAP HANA mengelola Replikasi Sistem selama failover, memulai dan menghentikan replikasi, serta mengganti instance yang berfungsi sebagai instance aktif dan standby dalam proses replikasi.
Jika Anda memerlukan penyimpanan file bersama, filer berbasis NFS atau SMB dapat menyediakan fungsi yang diperlukan.
Untuk solusi penyimpanan bersama dengan ketersediaan tinggi, Anda dapat menggunakan Filestore, tingkat layanan Premium atau Extreme dari Google Cloud NetApp Volumes, atau solusi berbagi file pihak ketiga. Tingkat layanan Regional (sebelumnya Enterprise) Filestore dapat digunakan untuk deployment multi-zona, dan paket Dasar Filestore dapat digunakan untuk deployment zona tunggal.
Persistent disk regional Compute Engine menawarkan block storage yang direplikasi secara sinkron di seluruh zona. Meskipun persistent disk regional tidak didukung untuk penyimpanan database dalam sistem SAP HA, Anda dapat menggunakannya dengan server file NFS.
Untuk mengetahui informasi selengkapnya tentang opsi penyimpanan di Google Cloud, lihat:
Setelan konfigurasi untuk cluster HA di Google Cloud
Google Cloud merekomendasikan untuk mengubah nilai default parameter konfigurasi cluster tertentu ke nilai yang lebih cocok untuk sistem SAP di lingkungan Google Cloud . Jika Anda menggunakan skrip otomatisasi yang disediakan oleh Google Cloud, nilai yang direkomendasikan akan ditetapkan untuk Anda.
Pertimbangkan nilai yang direkomendasikan sebagai titik awal untuk menyesuaikan setelan Corosync di cluster HA Anda. Anda perlu mengonfirmasi bahwa sensitivitas deteksi kegagalan dan pemicu failover sudah sesuai untuk sistem dan workload Anda di lingkungan Google Cloud .
Nilai parameter konfigurasi Corosync
Dalam panduan konfigurasi cluster HA untuk SAP HANA, Google Cloud
merekomendasikan nilai untuk beberapa parameter
di bagian totem file konfigurasi corosync.conf yang berbeda
dengan nilai default yang ditetapkan oleh Corosync atau distributor
Linux Anda.
totem yang direkomendasikan nilainya oleh Google Cloud, beserta dampak perubahan nilai tersebut. Untuk nilai default
parameter ini, yang dapat berbeda di antara distribusi Linux, lihat dokumentasi
untuk distribusi Linux Anda.
| Parameter | Nilai yang direkomendasikan | Dampak perubahan nilai |
|---|---|---|
secauth |
off |
Menonaktifkan autentikasi dan enkripsi semua pesan totem. |
join |
60 (md) | Meningkatkan durasi tunggu node untuk pesan join
dalam protokol keanggotaan. |
max_messages |
20 | Meningkatkan jumlah maksimum pesan yang mungkin dikirim oleh node setelah menerima token. |
token |
20000 (md) |
Meningkatkan durasi tunggu node untuk token protokol
Meningkatkan nilai parameter
Nilai parameter |
consensus |
T/A | Menentukan, dalam milidetik, durasi tunggu konsensus yang akan dicapai sebelum memulai putaran baru konfigurasi keanggotaan.
Sebaiknya hapus parameter ini. Jika parameter consensus secara eksplisit,
pastikan nilainya adalah 24000 atau
1.2*token, mana saja yang lebih besar.
|
token_retransmits_before_loss_const |
10 | Meningkatkan jumlah token yang ditransmisikan ulang oleh node sebelum menyimpulkan bahwa node penerima gagal dan mengambil tindakan. |
transport |
|
Menentukan mekanisme transpor yang digunakan oleh corosync. |
Untuk informasi selengkapnya tentang cara mengonfigurasi file corosync.conf, lihat
panduan konfigurasi untuk distribusi Linux Anda:
Setelan waktu habis dan interval untuk resource cluster
Saat menentukan resource cluster, Anda dapat menetapkan nilai interval
dan timeout, dalam detik, untuk berbagai operasi resource (op).
Misalnya:
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
Nilai timeout memengaruhi setiap operasi resource secara berbeda, seperti
yang dijelaskan dalam tabel berikut.
| Resource operation | Tindakan waktu tunggu |
|---|---|
monitor |
Jika waktu tunggu habis, status pemantauan biasanya akan dilaporkan sebagai gagal, dan resource yang terkait akan dianggap dalam status gagal. Cluster mencoba opsi pemulihan, yang dapat mencakup failover. Cluster tidak mencoba kembali operasi pemantauan yang gagal. |
start |
Jika resource gagal dimulai sebelum waktu tunggunya tercapai, cluster akan mencoba memulai ulang resource. Perilaku ini ditentukan oleh tindakan saat gagal yang terkait dengan resource. |
stop |
Jika resource tidak merespons operasi penghentian sebelum waktu tunggu habis, hal ini akan memicu peristiwa pemagaran. |
Bersama dengan setelan konfigurasi cluster lainnya, setelan interval dan timeout
resource cluster memengaruhi seberapa cepat software cluster
mendeteksi kegagalan dan memicu failover.
Nilai timeout dan interval yang disarankan oleh Google Cloud dalam
panduan konfigurasi cluster untuk akun SAP HANA untuk peristiwa pemeliharaan
Migrasi Langsung Compute Engine.
Terlepas dari nilai timeout dan interval yang digunakan, Anda harus
mengevaluasi nilai saat menguji cluster, terutama selama pengujian
migrasi langsung, karena durasi peristiwa migrasi langsung dapat sedikit berbeda
tergantung pada jenis mesin yang Anda gunakan dan faktor lainnya, seperti pemanfaatan
sistem.
Setelan resource pagar
Dalam panduan konfigurasi cluster HA untuk SAP HANA, Google Cloud merekomendasikan beberapa parameter saat mengonfigurasi resource pagar cluster HA. Nilai yang direkomendasikan berbeda dengan nilai default yang ditetapkan oleh Corosync atau distributor Linux Anda.
Tabel berikut menunjukkan parameter pagar yang direkomendasikan Google Cloud beserta nilai yang direkomendasikan dan detail parameter. Untuk nilai default parameter, yang dapat berbeda di antara distribusi Linux, lihat dokumentasi untuk distribusi Linux Anda.
| Parameter | Nilai yang direkomendasikan | Detail |
|---|---|---|
pcmk_reboot_timeout |
300 (detik) | Menentukan nilai waktu tunggu yang akan digunakan untuk tindakan mulai ulang.
Nilai
|
pcmk_monitor_retries |
4 | Menentukan frekuensi maksimum untuk mencoba ulang
perintah monitor dalam periode waktu tunggu. |
pcmk_delay_max |
30 (detik) | Menentukan penundaan acak untuk tindakan pagar guna mencegah node cluster membatasi satu sama lain secara bersamaan. Untuk menghindari race pagar dengan memastikan hanya satu instance yang diberi penundaan acak, parameter ini hanya boleh diaktifkan pada salah satu resource pagar di dua cluster HANA HA node (peningkatan skala). Pada cluster HANA HA dengan penyebaran skala, parameter ini harus diaktifkan pada semua node yang merupakan bagian dari situs (baik primer maupun sekunder) |
Menguji cluster HA di Google Cloud
Setelah cluster dikonfigurasi dan sistem cluster dan SAP HANA di-deploy di lingkungan pengujian, Anda perlu menguji cluster tersebut untuk mengonfirmasi bahwa sistem HA telah dikonfigurasi dengan benar dan berfungsi seperti yang diharapkan.
Untuk mengonfirmasi failover berfungsi seperti yang diharapkan, simulasikan berbagai skenario kegagalan dengan tindakan berikut:
- Matikan VM
- Buat kernel panik
- Nonaktifkan aplikasi
- Putus jaringan antara instance
Selain itu, simulasikan peristiwa migrasi langsung Compute Engine pada host utama
untuk mengonfirmasi bahwa peristiwa tersebut tidak memicu failover. Anda dapat menyimulasikan
peristiwa pemeliharaan menggunakan perintah Google Cloud CLI gcloud compute instances
simulate-maintenance-event.
Logging dan pemantauan
Agen resource dapat mencakup kemampuan logging yang menyebarkan log ke Google Cloud Observability untuk analisis. Setiap agen resource menyertakan informasi
konfigurasi yang mengidentifikasi setiap opsi logging. Untuk implementasi
bash, opsi logging adalah gcloud logging.
Anda juga dapat menginstal agen Cloud Logging untuk mengambil output log dari proses sistem operasi dan menghubungkan penggunaan resource dengan peristiwa sistem. Agen Logging mengambil log sistem default, yang mencakup data log dari Pacemaker dan layanan pengelompokan. Untuk mengetahui informasi selengkapnya, lihat Tentang agen Logging.
Untuk mengetahui informasi tentang cara menggunakan Cloud Monitoring untuk mengonfigurasi pemeriksaan layanan yang memantau ketersediaan endpoint layanan, lihat Mengelola cek uptime.
Akun layanan dan cluster HA
Tindakan yang dapat dilakukan software cluster di lingkungan Google Cloud dilindungi dengan izin yang diberikan ke akun layanan setiap VM host. Untuk lingkungan dengan keamanan tinggi, Anda dapat membatasi izin di akun layanan VM host Anda agar sesuai dengan prinsip hak istimewa terendah.
Saat membatasi izin akun layanan, perlu diingat bahwa sistem Anda mungkin berinteraksi dengan layanan Google Cloud , seperti Cloud Storage, jadi Anda mungkin perlu menyertakan izin untuk interaksi layanan tersebut di akun layanan VM host.
Untuk izin yang paling ketat, buat peran khusus dengan izin minimum yang diperlukan. Untuk mengetahui informasi tentang peran khusus, lihat Membuat dan mengelola peran khusus. Anda dapat membatasi izin lebih lanjut dengan membatasinya hanya ke instance resource tertentu, seperti instance VM dalam cluster HA, dengan menambahkan kondisi dalam binding peran kebijakan IAM resource.
Izin minimum yang diperlukan sistem Anda bergantung pada resourceGoogle Cloud yang diakses sistem Anda dan tindakan yang dilakukan sistem Anda. Akibatnya, menentukan izin minimum yang diperlukan untuk VM host di cluster HA mungkin mengharuskan Anda menyelidiki secara tepat resource mana yang diakses oleh sistem pada VM host dan tindakan yang dilakukan sistem tersebut dengan sumber daya tersebut.
Sebagai titik awal, daftar berikut menunjukkan beberapa resource cluster dengan ketersediaan tinggi (HA) dan izin terkait yang diperlukannya:
- Pagar
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- VIP yang diimplementasikan dengan menggunakan IP alias
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- VIP yang diimplementasikan dengan menggunakan rute statis
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- VIP yang diimplementasikan dengan menggunakan load balancer internal
- Tidak ada izin khusus yang diperlukan - load balancer beroperasi dalam status health check yang tidak mengharuskan cluster untuk berinteraksi dengan atau mengubah resource di Google Cloud
Implementasi IP virtual di Google Cloud
Cluster ketersediaan tinggi menggunakan alamat IP (VIP) floating atau virtual untuk memindahkan workloadnya dari satu node cluster ke node cluster lain jika terjadi kerusakan tak terduga atau untuk pemeliharaan terjadwal. Alamat IP VIP tidak berubah, sehingga aplikasi klien tidak mengetahui bahwa pekerjaan sedang disajikan oleh node lain.
VIP juga disebut sebagai alamat IP mengambang.
Di Google Cloud, VIP diimplementasikan dengan sedikit berbeda dibandingkan dengan penginstalan di infrastruktur lokal, dalam hal ini saat failover terjadi, permintaan ARP yang tidak beralasan tidak dapat digunakan untuk mengumumkan perubahan tersebut. Sebagai gantinya, Anda dapat menerapkan alamat VIP untuk cluster SAP HA menggunakan salah satu metode berikut:
- Dukungan failover Network Load Balancer passthrough internal (direkomendasikan).
- Google Cloud Rute statis.
- AlamatGoogle Cloud IP alias.
Implementasi VIP Network Load Balancer passthrough internal
Load balancer biasanya mendistribusikan traffic pengguna ke beberapa instance aplikasi, baik untuk mendistribusikan workload di beberapa sistem aktif maupun untuk melindungi dari pelambatan atau kegagalan pemrosesan pada satu instance.
Network Load Balancer passthrough internal juga memberikan dukungan failover yang dapat Anda gunakan dengan health check Compute Engine untuk mendeteksi kegagalan, memicu failover, dan mengalihkan traffic ke sistem SAP utama baru di cluster HA berbasis OS.
Dukungan failover adalah penerapan VIP yang direkomendasikan karena berbagai alasan, termasuk:
- Load balancing di Compute Engine menawarkan SLA ketersediaan 99,99%.
- Load balancing mendukung cluster ketersediaan tinggi multi-zona, yang melindungi dari kegagalan zona dengan waktu failover lintas zona yang dapat diprediksi.
- Penggunaan load balancing akan mengurangi waktu yang diperlukan untuk mendeteksi dan memicu failover, biasanya dalam hitungan detik setelah kegagalan. Waktu failover keseluruhan bergantung pada waktu failover setiap komponen dalam sistem HA, yang dapat mencakup host, sistem database, sistem aplikasi, dan lainnya.
- Menggunakan load balancing akan menyederhanakan konfigurasi cluster dan mengurangi dependensi.
- Tidak seperti implementasi VIP yang menggunakan rute, dengan load balancing, Anda dapat menggunakan rentang IP dari jaringan VPC Anda sendiri, sehingga Anda dapat mencadangkan dan mengonfigurasinya sesuai kebutuhan.
- Load balancing dapat dengan mudah digunakan untuk mengalihkan traffic ke sistem sekunder untuk pemadaman pemeliharaan terencana.
Saat membuat health check untuk penerapan VIP load balancer, Anda menentukan port host yang diperiksa health check untuk menentukan kondisi host. Untuk cluster SAP HA, tentukan port host target yang berada dalam rentang pribadi, 49152-65535, untuk menghindari bentrok dengan layanan lain. Pada VM host, konfigurasikan port target dengan layanan bantuan sekunder, seperti utilitas socat atau HAProxy.
Untuk cluster database dengan sistem standby sekunder tetap online, health check dan layanan helper memungkinkan load balancing untuk mengarahkan traffic ke sistem online yang saat ini berfungsi sebagai sistem utama dalam cluster.
Dengan layanan bantuan dan pengalihan port, Anda dapat memicu failover untuk pemeliharaan software yang direncanakan pada sistem SAP.
Untuk mengetahui informasi selengkapnya tentang dukungan failover, lihat Mengonfigurasi failover untuk Network Load Balancers passthrough internal.
Untuk men-deploy cluster HA dengan implementasi VIP load balancing, lihat:
- Terraform: Panduan konfigurasi cluster ketersediaan tinggi SAP HANA
- Panduan konfigurasi cluster HA untuk SAP HANA di RHEL
- Panduan konfigurasi cluster HA untuk SAP HANA di SLES
Implementasi VIP rute statis
Implementasi rute statis juga memberikan perlindungan terhadap kegagalan zona, tetapi Anda harus menggunakan VIP di luar rentang IP subnet VPC yang ada di tempat VM berada. Dengan demikian, Anda juga perlu memastikan bahwa VIP tidak bentrok dengan alamat IP eksternal mana pun di jaringan yang diperluas.
Implementasi rute statis juga dapat menimbulkan kompleksitas saat digunakan dengan konfigurasi VPC bersama, yang dimaksudkan untuk memisahkan konfigurasi jaringan ke project host.
Jika Anda menggunakan penerapan rute statis untuk VIP, konsultasikan dengan administrator jaringan guna menentukan alamat IP yang sesuai untuk penerapan rute statis.
Implementasi VIP IP alias
Implementasi VIP IP alias tidak direkomendasikan untuk deployment HA multi-zona karena, jika sebuah zona gagal, realokasi IP alias ke node di zona yang berbeda dapat tertunda. Implementasikan VIP Anda dengan Network Load Balance passthrough internal dengan dukungan failover.
Jika Anda men-deploy semua node cluster SAP HA di zona yang sama, Anda dapat menggunakan IP alias untuk mengimplementasikan VIP untuk cluster HA.
Jika sudah memiliki cluster SAP HA multi-zona yang menggunakan penerapan IP alias untuk VIP, Anda dapat bermigrasi ke penerapan Network Load Balance passthrough internal tanpa mengubah alamat VIP Anda. Alamat IP alias dan Network Load Balancer passthrough internal menggunakan rentang IP dari jaringan VPC Anda.
Meskipun alamat IP alias tidak direkomendasikan untuk implementasi VIP di cluster HA multi-zona, alamat IP alias memiliki kasus penggunaan lain dalam deployment SAP. Misalnya, dapat digunakan untuk memberikan nama host dan penetapan IP yang logis untuk deployment SAP yang fleksibel, seperti yang dikelola oleh SAP Landscape Management.
Praktik terbaik umum untuk VIP di Google Cloud
Untuk mengetahui informasi selengkapnya tentang VIP di Google Cloud, lihat Praktik Terbaik untuk Alamat IP Mengambang.
Failover otomatis host SAP HANA di Google Cloud
Google Cloud mendukung failover otomatis host SAP HANA, yaitu solusi pemulihan error lokal yang disediakan oleh SAP HANA. Solusi failover otomatis host menggunakan satu atau beberapa host standby yang disimpan sebagai cadangan untuk mengambil alih pekerjaan dari master host atau worker host jika terjadi kegagalan host. Host standby tidak berisi data atau memproses tugas apa pun.
Setelah failover selesai, host yang gagal dimulai ulang sebagai host standby.
SAP mendukung hingga tiga host standby dalam sistem penyebaran skala di Google Cloud. Host standby tidak termasuk dalam jumlah maksimum 16 host aktif yang didukung SAP dalam sistem penyebaran skala di Google Cloud.
Untuk informasi selengkapnya dari SAP tentang solusi failover otomatis host, lihat Failover Otomatis Host.
Kapan harus menggunakan failover otomatis host SAP HANA di Google Cloud
Kegagalan otomatis host SAP HANA melindungi dari kegagalan yang memengaruhi satu node dalam sistem penyebaran skala SAP HANA, termasuk kegagalan:
- Instance SAP HANA
- Sistem operasi host
- VM host
Terkait kegagalan VM host, di Google Cloud, mulai ulang otomatis, yang biasanya memulihkan VM host SAP HANA lebih cepat daripada failover otomatis host, dan migrasi langsung secara bersamaan melindungi dari gangguan VM yang terencana dan tidak terencana. Jadi, untuk perlindungan VM, solusi failover otomatis host SAP HANA tidak diperlukan.
Failover otomatis host SAP HANA tidak memberikan perlindungan terhadap kegagalan zona, karena semua node sistem penyebaran skala SAP HANA di-deploy di satu zona.
Failover otomatis host SAP HANA tidak melakukan pramuat data SAP HANA ke dalam memori node standby, sehingga saat node standby mengambil alih, waktu pemulihan node secara keseluruhan terutama ditentukan oleh durasi pemuatan data ke dalam memori node standby.
Pertimbangkan untuk menggunakan failover otomatis host SAP HANA untuk skenario berikut:
- Kegagalan pada software atau sistem operasi host node SAP HANA yang mungkin tidak terdeteksi oleh Google Cloud.
- Migrasi Lift and shift, ketika Anda perlu mereproduksi konfigurasi SAP HANA lokal hingga Anda dapat mengoptimalkan SAP HANA untuk Google Cloud.
- Jika konfigurasi ketersediaan tinggi yang direplikasi sepenuhnya, lintas zona memiliki
biaya tinggi dan bisnis Anda dapat menoleransi:
- Waktu pemulihan node yang lebih lama karena perlunya memuat data SAP HANA ke dalam memori node standby.
- Risiko kegagalan zona.
Pengelola penyimpanan untuk SAP HANA
Volume /hana/data dan /hana/log hanya dipasang di master host dan worker host. Saat pengambilalihan terjadi, solusi failover otomatis host menggunakan SAP HANA Storage Connector API dan pengelola penyimpananGoogle Cloud untuk node standby SAP HANA guna memindahkan dudukan volume dari host yang gagal ke host standby.
Di Google Cloud, pengelola penyimpanan untuk SAP HANA diperlukan untuk sistem SAP HANA yang menggunakan failover otomatis host SAP HANA.
Versi pengelola penyimpanan yang didukung untuk SAP HANA
Pengelola penyimpanan versi 2.0 dan yang lebih baru untuk SAP HANA didukung. Semua versi sebelum 2.0 tidak digunakan lagi dan tidak didukung. Jika Anda menggunakan versi sebelumnya, update sistem SAP HANA untuk menggunakan pengelola penyimpanan versi terbaru untuk SAP HANA. Lihat Mengupdate pengelola penyimpanan untuk SAP HANA.
Untuk mengetahui apakah versi Anda tidak digunakan lagi, buka file gceStorageClient.py.
Direktori penginstalan default adalah /hana/shared/gceStorageClient.
Mulai dari versi 2.0, nomor versi tercantum dalam komentar di
bagian atas
file gceStorageClient.py, seperti ditunjukkan dalam contoh berikut. Jika
nomor versi tidak ada, Anda sedang melihat versi pengelola penyimpanan untuk SAP HANA
yang sudah tidak digunakan lagi.
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
Menginstal pengelola penyimpanan untuk SAP HANA
Metode yang disarankan untuk menginstal pengelola penyimpanan untuk SAP HANA adalah menggunakan metode deployment otomatis untuk men-deploy sistem SAP HANA penyebaran skala yang menyertakan pengelola penyimpanan terbaru untuk SAP HANA.
Jika Anda perlu menambahkan failover otomatis host SAP HANA ke sistem penyebaran skala SAP HANA yang ada di Google Cloud, pendekatan yang direkomendasikan adalah serupa: gunakan file konfigurasi Terraform yang disediakan oleh Google Cloud untuk men-deploy sistem SAP HANA penyebaran skala baru, lalu muat data ke dalam sistem baru dari sistem yang ada. Untuk memuat data, Anda dapat menggunakan prosedur pencadangan dan pemulihan SAP HANA standar atau replikasi sistem SAP HANA, yang dapat membatasi periode nonaktif. Untuk mengetahui informasi selengkapnya tentang replikasi sistem, lihat SAP Note 2473002 - Menggunakan replikasi sistem HANA untuk memigrasikan sistem penyebaran skala.
Jika Anda tidak dapat menggunakan metode deployment otomatis, pertimbangkan untuk menghubungi konsultan solusi SAP, seperti yang dapat ditemukan melalui Google Cloud layanan Konsultasi, untuk mendapatkan bantuan dalam menginstal pengelola penyimpanan secara manual untuk SAP HANA.
Penginstalan manual pengelola penyimpanan untuk SAP HANA ke dalam sistem SAP HANA penyebaran skala yang ada atau yang baru saat ini tidak didokumentasikan.
Untuk informasi selengkapnya tentang opsi deployment otomatis untuk failover otomatis host SAP HANA, lihat Deployment otomatis sistem penyebaran skala host SAP HANA dengan failover otomatis host SAP HANA.
Memperbarui pengelola penyimpanan untuk SAP HANA
Anda mengupdate pengelola penyimpanan untuk SAP HANA dengan mendownload paket penginstalan
terlebih dahulu, lalu menjalankan skrip penginstalan, yang mengupdate
pengelola penyimpanan untuk SAP HANA yang dapat dieksekusi di drive SAP HANA /shared.
Prosedur berikut hanya untuk pengelola penyimpanan versi 2 untuk SAP HANA. Jika Anda menggunakan versi pengelola penyimpanan untuk SAP HANA yang telah didownload sebelum 1 Februari 2021, instal versi 2 sebelum mencoba mengupdate pengelola penyimpanan untuk SAP HANA.
Untuk mengupdate pengelola penyimpanan SAP HANA:
Periksa versi pengelola penyimpanan saat ini untuk SAP HANA:
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
Jika ada update, instal update tersebut:
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
Pengelola penyimpanan yang diupdate untuk SAP HANA diinstal di
/usr/sap/google-sapgcestorageclient/gceStorageClient.py.Ganti
gceStorageClient.pyyang ada dengan filegceStorageClient.pyyang diupdate:Jika file
gceStorageClient.pyyang ada berada di/hana/shared/gceStorageClient, yang merupakan lokasi penginstalan default, gunakan skrip penginstalan untuk mengupdate file:sudo /usr/sap/google-sapgcestorageclient/install.sh
Jika file
gceStorageClient.pyyang sudah ada tidak ada di/hana/shared/gceStorageClient, salin file yang telah diupdate ke lokasi yang sama dengan file yang ada, sehingga file tersebut akan diganti.
Parameter konfigurasi di file global.ini
Parameter konfigurasi tertentu untuk pengelola penyimpanan untuk SAP HANA,
termasuk apakah pagar diaktifkan atau dinonaktifkan, disimpan di
bagian penyimpanan file global.ini SAP HANA. Saat Anda menggunakan file konfigurasi Terraform yang disediakan oleh Google Cloud untuk men-deploy sistem SAP HANA dengan fungsi failover otomatis host, proses deployment akan menambahkan parameter konfigurasi ke file global.ini untuk Anda.
Contoh berikut menampilkan konten global.ini yang dibuat
untuk pengelola penyimpanan untuk SAP HANA:
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_*__gcloudAccount = svc-acct-name@project-id. # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
Akses sudo untuk pengelola penyimpanan untuk SAP HANA
Untuk mengelola layanan dan penyimpanan SAP HANA,
pengelola penyimpanan untuk SAP HANA akan menggunakan akun pengguna SID_LCadm
dan memerlukan akses sudo ke biner sistem tertentu.
Jika Anda menggunakan skrip otomatisasi yang disediakan Google Cloud untuk men-deploy SAP HANA dengan failover otomatis host, akses sudo yang diperlukan akan dikonfigurasi untuk Anda.
Jika Anda menginstal pengelola penyimpanan untuk SAP HANA secara manual, gunakan
perintah visudo untuk mengedit file /etc/sudoers guna memberi
akun pengguna SID_LCadm akses sudo ke hal berikut
yang diperlukan biner.
Klik tab untuk sistem operasi Anda:
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
Contoh berikut menunjukkan entri dalam file /etc/sudoers. Dalam
contoh, ID sistem untuk sistem SAP HANA yang terkait diganti dengan
SID_LC. Contoh entri dibuat oleh
konfigurasi Terraform yang disediakan oleh Google Cloud untuk penyebaran skala SAP HANA
dengan failover otomatis host.
Entri yang dibuat oleh konfigurasi Terraform
menyertakan biner yang tidak lagi diperlukan, tetapi dipertahankan untuk
kompatibilitas mundur. Anda hanya perlu menyertakan biner yang
muncul dalam daftar sebelumnya.
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
Mengonfigurasi akun layanan untuk pengelola penyimpanan untuk SAP HANA
Untuk mengaktifkan failover otomatis host untuk sistem penyebaran skala SAP HANA di Google Cloud, pengelola penyimpanan untuk SAP HANA memerlukan akun layanan. Anda dapat membuat akun layanan khusus dan memberikan izin yang diperlukan untuk melakukan tindakan pada VM SAP HANA, seperti melepaskan dan memasang disk selama failover. Untuk mengetahui informasi tentang cara membuat akun layanan, lihat Membuat akun layanan.
Izin IAM yang diperlukan
Untuk akun layanan yang digunakan oleh pengelola penyimpanan untuk SAP HANA, Anda harus memberikan peran yang menyertakan izin IAM berikut:
Untuk mereset instance VM menggunakan perintah
gcloud compute instances reset, berikan izincompute.instances.reset.Untuk mendapatkan informasi tentang volume Persistent Disk atau Hyperdisk menggunakan perintah
gcloud compute disks describe, berikan izincompute.disks.get.Untuk memasang disk ke instance VM menggunakan perintah
gcloud compute instances attach-disk, beri izincompute.instances.attachDisk.Untuk melepaskan disk dari instance VM menggunakan perintah
gcloud compute instances detach-disk, beri izincompute.instances.detachDisk.Untuk mencantumkan instance VM menggunakan perintah
gcloud compute instances list, beri izincompute.instances.list.Untuk mencantumkan volume Persistent Disk atau Hyperdisk menggunakan perintah
gcloud compute disks list, beri izincompute.disks.list.
Anda dapat memberikan izin yang diperlukan melalui peran kustom atau peran bawaan lainnya.
Selain itu, tetapkan cakupan akses VM ke cloud-platform sehingga izin IAM VM sepenuhnya ditentukan oleh peran IAM yang Anda berikan ke akun layanan.
Secara default, pengelola penyimpanan untuk SAP HANA menggunakan akun layanan aktif atau akun pengguna yang diberi otorisasi oleh gcloud CLI untuk digunakan di host dalam sistem SAP HANA yang diskalakan.
Untuk memeriksa akun aktif yang digunakan oleh pengelola penyimpanan untuk SAP HANA, gunakan perintah berikut:
gcloud auth list
Untuk informasi tentang perintah ini, lihat gcloud auth list.
Untuk mengubah akun yang digunakan oleh pengelola penyimpanan untuk SAP HANA, lakukan langkah-langkah berikut:
Pastikan akun layanan tersedia di setiap host dalam sistem SAP HANA yang di-scale-out:
gcloud auth listDi file
global.ini, perbarui bagian[storage]dengan akun layanan:[storage] ha_provider = gceStorageClient ... partition_*_*__gcloudAccount = SERVICE_ACCOUNTGanti
SERVICE_ACCOUNTdengan nama akun layanan, dalam format alamat email, yang digunakan oleh pengelola penyimpanan untuk SAP HANA. Akun layanan ini digunakan saat mengeluarkan perintahgclouddari pengelola penyimpanan untuk SAP HANA.
Penyimpanan NFS untuk failover otomatis host SAP HANA
Sistem penyebaran skala SAP HANA dengan failover otomatis host memerlukan solusi NFS,
seperti Filestore, untuk berbagi volume /hana/shared dan /hanabackup
di antara semua host. Anda harus menyiapkan solusi NFS sendiri.
Saat menggunakan metode deployment otomatis, berikan informasi tentang server NFS dalam file deployment, untuk memasang direktori NFS selama deployment.
Volume NFS yang Anda gunakan harus kosong. Semua file yang ada dapat mengalami konflik dengan proses deployment, terutama jika file atau folder tersebut merujuk ke ID sistem SAP (SID). Proses deployment tidak dapat menentukan apakah file dapat ditimpa.
Proses deployment menyimpan volume /hana/shared dan /hanabackup
di server NFS dan memasang server NFS di semua host, termasuk
host standby. Master host kemudian mengelola server NFS.
Jika Anda mengimplementasikan solusi pencadangan, seperti agen Backint Cloud Storage untuk SAP HANA, Anda dapat
menghapus volume /hanabackup dari server NFS setelah deployment selesai.
Untuk mengetahui informasi selengkapnya tentang solusi file bersama yang tersedia di Google Cloud, lihat Solusi berbagi file untuk SAP di Google Cloud.
Dukungan sistem operasi
Google Cloud hanya mendukung failover otomatis host SAP HANA pada sistem operasi berikut:
- RHEL untuk SAP 7.7 atau yang lebih baru
- RHEL untuk SAP 8.1 atau yang lebih baru
- RHEL untuk SAP 9.0 atau yang lebih baru
-
Sebelum Anda menginstal software SAP apa pun di RHEL untuk SAP 9.x, paket tambahan harus diinstal di
mesin host Anda, terutama
chkconfigdancompat-openssl11. Jika Anda menggunakan image yang disediakan oleh Compute Engine, paket ini akan otomatis diinstal untuk Anda. Untuk mengetahui informasi selengkapnya dari SAP, lihat Catatan SAP 3108316 - Red Hat Enterprise Linux 9.x: Penginstalan dan Konfigurasi .
-
Sebelum Anda menginstal software SAP apa pun di RHEL untuk SAP 9.x, paket tambahan harus diinstal di
mesin host Anda, terutama
- SLES untuk SAP 12 SP5
- SLES untuk SAP 15 SP1 atau yang lebih baru
Untuk melihat image publik yang tersedia dari Compute Engine, lihat Gambar.
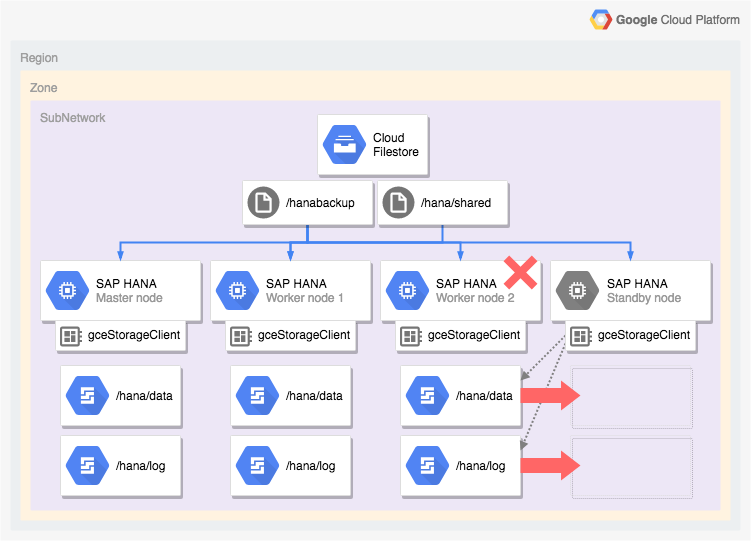
Arsitektur sistem SAP HANA dengan failover otomatis host
Diagram berikut menunjukkan arsitektur penyebaran skala di Google Cloud yang
menyertakan fitur failover otomatis host SAP HANA. Dalam diagram,
pengelola penyimpanan untuk SAP HANA direpresentasikan oleh nama
file yang dapat dieksekusi, gceStorageClient.
Diagram menunjukkan worker node 2 yang gagal dan node standby mengambil alih.
Pengelola penyimpanan untuk SAP HANA bekerja dengan SAP Storage Connector
API (tidak ditampilkan) untuk melepaskan disk
yang berisi volume /hana/data dan /hana/logs dari worker node yang gagal
dan untuk memasangnya kembali pada node standby, yang kemudian menjadi worker
node 2 sementara node yang gagal menjadi node standby.
Opsi deployment otomatis untuk konfigurasi ketersediaan tinggi SAP HANA
Google Cloud menyediakan konfigurasi Terraform yang dapat Anda gunakan untuk mengotomatiskan deployment sistem HA SAP HANA atau Anda dapat men-deploy dan mengonfigurasi sistem HA SAP HANA secara manual.
Google Cloud menyediakan file konfigurasi Terraform khusus deployment yang Anda selesaikan. Gunakan perintah Terraform standar untuk menginisialisasi direktori kerja saat ini dan mendownload file plugin dan modul penyedia Terraform untuk Google Cloud, serta menerapkan konfigurasi untuk men-deploy sistem SAP HANA.
Metode deployment otomatis ini men-deploy sistem SAP HANA untuk Anda yang sepenuhnya didukung oleh SAP dan mematuhi praktik terbaik dari SAP dan Google Cloud.
Deployment otomatis cluster ketersediaan tinggi Linux untuk SAP HANA
Untuk SAP HANA, metode deployment otomatis men-deploy cluster Linux ketersediaan tinggi yang dioptimalkan performa yang mencakup:
- Failover otomatis.
- Mulai ulang otomatis.
- Pencadangan alamat IP virtual (VIP) yang Anda tentukan.
- Dukungan failover disediakan oleh load balancing TCP/UDP internal, yang mengelola pemilihan rute dari alamat IP virtual (VIP) ke node cluster HA.
- Aturan firewall yang mengizinkan health check Compute Engine untuk memantau instance VM di cluster.
- Pengelola resource cluster ketersediaan tinggi Pacemaker.
- Mekanisme pagar Google Cloud .
- VM dengan persistent disk yang diperlukan untuk setiap instance SAP HANA.
- Atau, node tenant tunggal.
- Instance SAP HANA yang dikonfigurasi untuk replikasi sinkron dan pramuat memori.
Agar dapat menggunakan Terraform untuk mengotomatiskan deployment cluster ketersediaan tinggi untuk SAP HANA, lihat:
- Terraform: Panduan konfigurasi cluster ketersediaan tinggi untuk peningkatan skala SAP HANA.
- Terraform: Panduan konfigurasi cluster ketersediaan tinggi untuk penyebaran skala SAP HANA.
Deployment otomatis sistem penyebaran skala SAP HANA dengan failover otomatis host SAP HANA
Anda dapat menggunakan Terraform untuk mengotomatiskan deployment sistem penyebaran skala dengan host standby. Untuk informasi selengkapnya, lihat Terraform: Panduan deployment sistem penyebaran skala SAP HANA dengan failover otomatis host.
Untuk sistem penyebaran skala SAP HANA yang menyertakan fitur failover otomatis host SAP HANA, konfigurasi Terraform yang disediakan oleh Google Cloud akan men-deploy hal berikut:
- Satu instance SAP HANA master
- 1 hingga 15 worker host
- 1 hingga 3 standby host
- VM untuk setiap host SAP HANA
- Volume Persistent Disk atau Hyperdisk berbasis SSD untuk master host dan worker host
- Pengelola penyimpanan Google Cloud untuk node standby SAP HANA
Sistem penyebaran skala SAP HANA dengan failover otomatis host memerlukan solusi NFS,
seperti Filestore, untuk berbagi volume
/hana/shared dan /hanabackup di antara semua host. Agar Terraform
dapat memasang direktori NFS selama deployment, Anda harus menyiapkan solusi NFS sendiri sebelum men-deploy sistem SAP
HANA.
Anda dapat menyiapkan instance server Filestore NFS dengan cepat dengan mengikuti petunjuk di Membuat Instance.
Opsi Aktif/Aktif (yang Dapat Dibaca) untuk SAP HANA
Dimulai dengan SAP HANA 2.0 SPS1, SAP menyediakan penyiapan Aktif/Aktif (yang Dapat Dibaca) untuk skenario Replikasi Sistem SAP HANA. Dalam sistem replikasi yang dikonfigurasi untuk Aktif/Aktif (yang Dapat Dibaca), port SQL di sistem sekunder terbuka untuk akses baca. Hal ini memungkinkan Anda menggunakan sistem sekunder untuk tugas yang intensif dibaca dan memiliki keseimbangan yang lebih baik antara workload di seluruh resource compute, sehingga meningkatkan performa keseluruhan database SAP HANA Anda. Untuk informasi selengkapnya tentang fitur Aktif/Aktif (yang Dapat Dibaca), lihat Panduan Administrasi SAP HANA yang khusus untuk versi SAP HANA dan SAP Note 1999880.
Untuk mengonfigurasi replikasi sistem yang memungkinkan akses baca di sistem sekunder, Anda harus menggunakan mode operasi logreplay_readaccess. Namun, untuk menggunakan mode operasi ini, sistem utama dan sekunder Anda harus menjalankan versi SAP HANA yang sama. Akibatnya, akses hanya baca ke sistem sekunder tidak dapat dilakukan selama upgrade berkelanjutan hingga kedua sistem menjalankan versi SAP HANA yang sama.
Untuk terhubung ke sistem sekunder Aktif/Aktif (yang Dapat Dibaca), SAP mendukung opsi berikut:
- Terhubung langsung dengan membuka koneksi eksplisit ke sistem sekunder.
- Menghubungkan secara tidak langsung dengan mengeksekusi pernyataan SQL di sistem utama dengan petunjuk, yang pada evaluasi akan mengalihkan kueri ke sistem sekunder.
Diagram berikut menunjukkan opsi pertama, ketika aplikasi mengakses sistem sekunder secara langsung di cluster Pacemaker yang di-deploy di Google Cloud. Alamat floating atau IP virtual (VIP) tambahan digunakan untuk menargetkan instance VM yang berfungsi sebagai sistem sekunder sebagai bagian dari cluster SAP HANA Pacemaker. VIP mengikuti sistem sekunder dan dapat memindahkan workloada bacanya dari satu node cluster ke node cluster lainnya jika terjadi kegagalan tak terduga atau untuk pemeliharaan terjadwal. Untuk informasi tentang metode implementasi VIP yang tersedia, lihat Implementasi IP virtual di Google Cloud.

Untuk mendapatkan petunjuk tentang cara mengonfigurasi replikasi sistem SAP HANA dengan Aktif/Aktif (yang Dapat Dibaca) di cluster Pacemaker:
- Mengonfigurasi HANA Aktif/Aktif (yang Dapat Dibaca) di cluster SUSE Pacemaker
- Mengonfigurasi HANA Aktif/Aktif (yang dapat dibaca) di cluster Red Hat Pacemaker
Langkah berikutnya
Google Cloud dan SAP memberikan informasi lebih lanjut tentang ketersediaan tinggi.
Informasi selengkapnya dari Google Cloud tentang ketersediaan tinggi
Untuk mengetahui informasi selengkapnya tentang ketersediaan tinggi untuk SAP HANA di Google Cloud, lihat Panduan Operasi SAP HANA.
Untuk mengetahui informasi umum tentang cara melindungi sistem di Google Cloud terhadap berbagai skenario kegagalan, lihat Mendesain sistem yang tangguh.
Informasi selengkapnya dari SAP tentang fitur ketersediaan tinggi SAP HANA
Untuk mengetahui informasi selengkapnya dari SAP tentang fitur ketersediaan tinggi SAP HANA, lihat dokumen berikut:
- Ketersediaan Tinggi untuk SAP HANA
- Catatan SAP 2057595 - FAQ: Ketersediaan Tinggi SAP HANA
- Cara Melakukan Replikasi Sistem untuk SAP HANA 2.0
- Rekomendasi Jaringan untuk Replikasi Sistem SAP HANA