このガイドでは、 Google Cloud上の Compute Engine 仮想マシン(VM)で実行されている SAP LT Replication Server にバージョン 2.0 または 2.1 の BigQuery Connector for SAP をインストールして構成する方法について説明します。
このガイドでは、BigQuery、SAP Landscape Transformation Replication Server(SAP LT Replication Server)、BigQuery Connector for SAP を準備し、SAP アプリケーションから SAP データをリアルタイムで直接かつ安全に BigQuery にレプリケートする方法を説明します。
このガイドは、SAP 管理者、 Google Cloud管理者、その他の SAP と Google Cloud のセキュリティおよびデータの専門家を対象としています。
前提条件
BigQuery Connector for SAP をインストールする前に、次の前提条件を満たしていることを確認してください。
- BigQuery Connector for SAP のプランニング ガイドを確認している。このプランニング ガイドでは、BigQuery Connector for SAP のオプション、パフォーマンスに関する考慮事項、フィールド マッピングなど、BigQuery Connector for SAP の最適な構成に必要な情報について説明します。
Google Cloud プロジェクトが存在しない場合は作成します。
プロジェクトで課金が有効になっている。プロジェクトで課金が有効になっていることを確認してください。BigQuery ストリーミング API と BigQuery を使用する場合と、BigQuery Connector for SAP をダウンロードする場合は、請求先アカウントが必要です。
SAP のプロダクトの可用性マトリックスで説明されているように、インストールされている SAP ソフトウェアのメンテナンスは最新状態であり、すべての SAP ソフトウェアのバージョン間に互換性がある。
ソフトウェアの要件に記載されているとおり、使用している SAP ソフトウェアのバージョンが BigQuery Connector for SAP でサポートされている。
SAP LT Replication Server SDK を使用して任意のターゲットにデータを複製するには、正しい SAP ライセンスが必要です。SAP ライセンスの詳細については、SAP Note 2707835 をご覧ください。
SAP LT Replication Server がインストールされている。SAP LT Replication Server のインストールの詳細については、SAP のドキュメントをご覧ください。
SAP LT Replication Server とソースシステムの間の RFC 接続またはデータベース接続が構成されている。必要に応じて、SAP トランザクション
SM59を使用し、RFC 接続をテストしてください。データベース接続は、SAP トランザクションDBACOCKPITを使用して、テストしてください。
インストールと構成のプロセスの概要
次の表に、このガイドで説明する手順と、対象の手順を行うロールを示します。
| 手順 | ロール |
|---|---|
| 必要に応じて、SAP から適切なライセンスをすべて検証したら、SAP の手順に沿って SAP Landscape Transformation Replication Server をインストールします。 | SAP 管理者。 |
| 必要に応じて、SAP NetWeaver のユーザー インターフェース(UI)アドオンをインストールします。詳細については、SAP ソフトウェア バージョンの要件をご覧ください。 | SAP 管理者。 |
| 必要な Google Cloud API を有効にします。 | Google Cloud 管理者。 |
| 必要に応じて、SAP LT Replication Server ホストに gcloud CLI をインストールします。 | SAP 管理者。 |
| BigQuery データセットを作成します。 | Google Cloud の管理者またはデータ エンジニア。 |
| Google Cloud の認証と認可を設定します。 | Google Cloud セキュリティ管理者。 |
| BigQuery Connector for SAP インストール パッケージをダウンロードします。 | Google Cloud 請求先アカウント所有者。 |
| BigQuery Connector for SAP をインストールします。 | SAP 管理者。 |
| BigQuery Connector for SAP の SAP ロールと権限を作成します。 | SAP 管理者。 |
| レプリケーションを構成します。 | データ エンジニアまたは管理者。 |
| レプリケーションをテストします。 | データ エンジニアまたは管理者。 |
| レプリケーションを検証します。 | データ エンジニアまたは管理者。 |
必要な Google Cloud API を有効にする
BigQuery Connector for SAP が BigQuery にアクセスするには、次の Google Cloud API を有効にする必要があります。
- BigQuery API
- IAM Service Account Credentials API
Google Cloud API を有効にする方法については、API の有効化をご覧ください。
gcloud CLI をインストールする
BigQuery へのレプリケーションには、sidadm ユーザー アカウントに SAP LT Replication Server ホストの Google Cloud CLI(gcloud CLI)へのアクセス権が必要です。
gcloud
components list を発行します。コマンドが認識されない場合は、gcloud CLI をインストールする必要があります。gcloud CLI は、SAP 管理者がインストールできます。
gcloud CLI をインストールするには、次の手順を行います。
gcloud CLI のインストール手順を行います。
sidadmユーザー アカウントが gcloud CLI インストール ディレクトリにアクセスすることを許可します。必要に応じて
sidadmとして、gcloud CLI のデフォルト プロジェクトを設定します。gcloud config set project PROJECT_ID
PROJECT_IDは、BigQuery データセットを含むプロジェクトの ID に置き換えます。例:example-project-123456gcloud CLI のデフォルト プロジェクトを設定していない場合は、発行する各
gcloudコマンドで--projectプロパティを指定する必要があります。
gcloud CLI に対する BigQuery Connector for SAP の要件の詳細については、gcloud CLI の要件をご覧ください。
BigQuery データセットを作成する
BigQuery の Google Cloud 認証と認可をテストするか、ターゲット BigQuery テーブルを作成するには、まずユーザーまたはデータ エンジニア、あるいは管理者が BigQuery データセットを作成する必要があります。
BigQuery データセットを作成するには、ユーザー アカウントに、BigQuery に対する適切な IAM 権限が必要です。詳細については、必要な権限をご覧ください。
Google Cloud コンソールで、[BigQuery] ページに移動します。
プロジェクト ID の横にある [アクションを表示] アイコン()をクリックし、[データセットを作成] をクリックします。
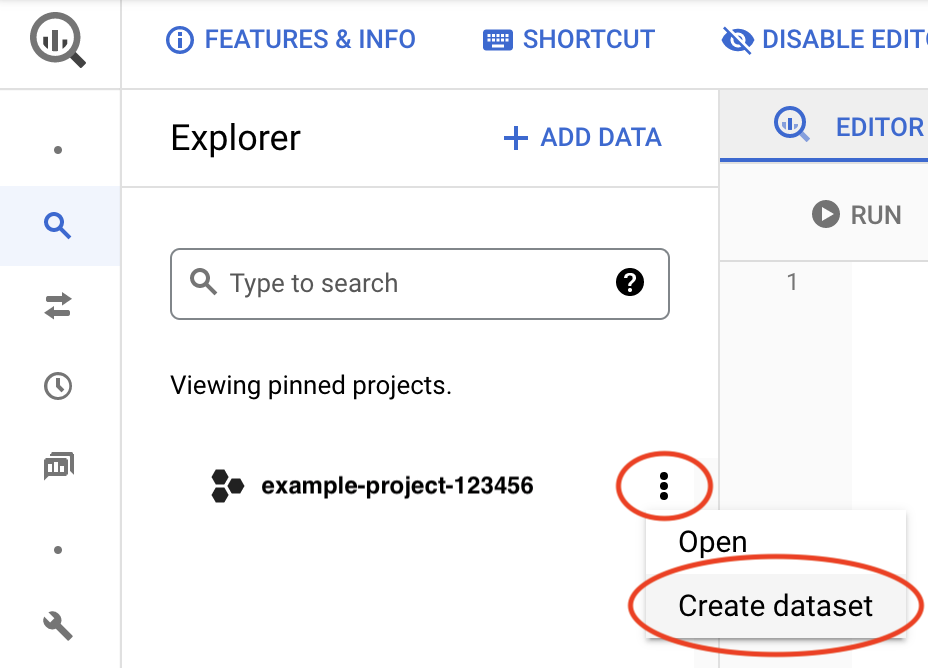
[データセット ID] フィールドに一意の名前を入力します。詳細については、データセットに名前を付けるをご覧ください。
Google Cloud の認証と認可を設定したら、このデータセットに関する情報を取得して、 Google Cloud へのアクセスをテストします。
BigQuery データセットの作成の詳細については、データセットの作成をご覧ください。
Google Cloud の認証と認可を設定する
BigQuery に対する Google Cloud の認証とアクセス許可を行うために、 Google Cloud セキュリティ管理者と SAP 管理者は以下のことを行う必要があります。
- BigQuery Connector for SAP のサービス アカウントを作成します。
- そのサービス アカウントに、BigQuery にアクセスするために必要な IAM ロールを付与します。
- BigQuery プロジェクトのプリンシパルとして BigQuery Connector for SAP サービス アカウントを追加します。
- SAP LT Replication Server ホストで Google Cloud のセキュリティ設定を構成します。
- アクセス トークンを取得する権限をホスト VM に付与します。
- 必要に応じて、ホスト VM の API アクセス スコープを変更します。
サービス アカウントを作成する
BigQuery Connector for SAP には、BigQuery にアクセスするための認証と認可のための IAM サービス アカウントが必要です。
このサービス アカウントは、BigQuery データセットを含む Google Cloud プロジェクトのプリンシパルでなければなりません。サービス アカウントを BigQuery データセットと同じプロジェクトで作成すると、そのサービス アカウントはプリンシパルとして自動的にプロジェクトに追加されます。
BigQuery データセットを含むプロジェクト以外のプロジェクトでサービス アカウントを作成する場合は、別のステップで BigQuery データセット プロジェクトにサービス アカウントを追加する必要があります。
サービス アカウントを作成するには、次の操作を行います。
Google Cloud コンソールで、[IAM と管理] の [サービス アカウント] ページに移動します。
プロンプトが表示されたら、 Google Cloud プロジェクトを選択します。
[サービス アカウントを作成] をクリックします。
サービス アカウントの名前を指定します。必要であれば、説明も入力します。
[作成して続行] をクリックします。
サービス アカウントを BigQuery データセットと同じプロジェクトで作成する場合は、[このサービス アカウントにプロジェクトへのアクセスを許可する] パネルで次のロールを選択します。
- BigQuery データ編集者
- BigQuery ジョブユーザー
サービス アカウントを BigQuery データセットとは異なるプロジェクトで作成する場合は、サービス アカウントにロールを付与しないでください。
[続行] をクリックします。
必要に応じて、他のユーザーにサービス アカウントへのアクセス権を付与します。
[完了] をクリックします。プロジェクトのサービス アカウントのリストにサービス アカウントが表示されます。
サービス アカウントを BigQuery データセットを含むプロジェクトとは別のプロジェクトで作成した場合は、サービス アカウントの名前をメモします。この名前は、BigQuery プロジェクトにサービス アカウントを追加するときに指定します。詳細については、サービス アカウントを BigQuery プロジェクトに追加するをご覧ください。
サービス アカウントは、サービス アカウントが作成された Google Cloud プロジェクトの [IAM 権限] ページにプリンシパルとして表示されます。
サービス アカウントを BigQuery プロジェクトに追加する
ターゲット BigQuery データセットを含むプロジェクト以外のプロジェクトで BigQuery Connector for SAP のサービス アカウントを作成した場合は、BigQuery データセット プロジェクトにサービス アカウントを追加する必要があります。
BigQuery データセットと同じプロジェクトでサービス アカウントを作成した場合は、このステップをスキップできます。
既存のサービス アカウントを BigQuery データセット プロジェクトに追加するには、次の操作を行います。
Google Cloud コンソールで IAM の [権限] ページに移動します。
ターゲット BigQuery データセットが含まれるプロジェクトの名前がページの上部付近に表示されていることを確認します。例:
プロジェクト「
PROJECT_NAME」の権限表示されていない場合は、プロジェクトを切り替えます。
[IAM] ページで、[追加] をクリックします。[「
PROJECT_NAME」にプリンシパルを追加します] ダイアログが開きます。[「
PROJECT_NAME」プロジェクトにプリンシパルを追加する] ダイアログで、次の手順を行います。- [新しいプリンシパル] フィールドに、サービス アカウントの名前を指定します。
- [ロールを選択] フィールドで [BigQuery データ編集者] を指定します。
- [別のロールを追加] をクリックします。[ロールを選択] フィールドが再び表示されます。
- [ロールを選択] フィールドで、[BigQuery ジョブユーザー] を指定します。
- [保存] をクリックします。サービス アカウントは、[IAM] ページのプロジェクト プリンシパルのリストに表示されます。
これで、サービス アカウントを使用して、このプロジェクト内の BigQuery データセットにアクセスできるようになりました。
ホスト VM でセキュリティを構成する
BigQuery Connector for SAP では、SAP LT Replication Server をホストしている Compute Engine VM が次のセキュリティ オプションを使用して構成されている必要があります。
- Cloud APIs への完全アクセス権を許可するように、ホスト VM のアクセス スコープを設定する必要があります。
- ホスト VM のサービス アカウントには、IAM サービス アカウント トークン作成者のロールが含まれている必要があります。
これらのオプションがホスト VM で構成されていない場合は、構成する必要があります。
VM のアクセス スコープを変更するには、VM を停止する必要があります。
ホスト VM の API アクセス スコープを確認する
SAP LT Replication Server ホスト VM の現在のアクセス スコープ設定を確認します。VM にすべての Cloud APIs に対する完全アクセス権がある場合は、アクセス スコープを変更する必要はありません。
ホスト VM のアクセス スコープを確認するには、次の手順を行います。
Google Cloud コンソール
Google Cloud コンソールで [VM インスタンス] ページを開きます。
必要に応じて、SAP LT Replication Server ホストを含む Google Cloud プロジェクトを選択します。
[VM インスタンス] ページで、ホスト VM の名前をクリックします。[VM の詳細] ページが開きます。
[ホスト VM の詳細] ページの [API と ID 管理] で、[Cloud API アクセス スコープ] の現在の設定を確認します。
- 設定が [すべての Cloud API に完全アクセス権を許可] の場合、この設定は正しいため、変更する必要はありません。
- [すべての Cloud API に完全アクセス権を許可] に設定されていない場合は、VM を停止して設定を変更する必要があります。手順については、次のセクションをご覧ください。
gcloud CLI
ホスト VM の現在のアクセス スコープを表示します。
gcloud compute instances describe VM_NAME --zone=VM_ZONE --format="yaml(serviceAccounts)"
アクセス スコープに
https://www.googleapis.com/auth/cloud-platformが含まれていない場合は、ホスト VM のアクセス スコープを変更する必要があります。たとえば、デフォルトの Compute Engine サービス アカウントで VM インスタンスを作成する場合は、次のデフォルトのアクセス スコープを変更する必要があります。serviceAccounts: - email: 600915385160-compute@ scopes: - https://www.googleapis.com/auth/devstorage.read_only - https://www.googleapis.com/auth/logging.write - https://www.googleapis.com/auth/monitoring.write - https://www.googleapis.com/auth/servicecontrol - https://www.googleapis.com/auth/service.management.readonly - https://www.googleapis.com/auth/trace.append
次の例に示すように、
scopesにあるスコープがhttps://www.googleapis.com/auth/cloud-platformのみの場合は、スコープを変更する必要はありません。serviceAccounts: - email: 600915385160-compute@ scopes: - https://www.googleapis.com/auth/cloud-platform
ホスト VM の API アクセス スコープを変更する
SAP LT Replication Server ホスト VM にGoogle Cloud APIs に対する完全アクセス権がない場合は、アクセス スコープを変更して、すべての Cloud APIs に対する完全アクセス権を付与します。
ホスト VM の Cloud APIs アクセス スコープの設定を変更するには、次の手順を行います。
Google Cloud コンソール
必要に応じて、ホスト VM のセキュリティ アカウントに付与されているロールを制限します。
セキュリティ アカウント名は、[ホスト VM の詳細] ページの [API と ID の管理] で確認できます。サービス アカウントに付与されているロールは、 Google Cloud コンソールの [IAM] ページの [プリンシパル] で変更できます。
必要に応じて、ホスト VM で実行されているワークロードを停止します。
Google Cloud コンソールで [VM インスタンス] ページを開きます。
[VM インスタンス] ページで、ホスト VM の名前をクリックして [VM の詳細] ページを開きます。
[ホスト VM の詳細] ページの上部で、[停止] をクリックしてホスト VM を停止します。
VM が停止したら、[編集] をクリックします。
[セキュリティとアクセス] > [アクセス スコープ] で、[すべての Cloud API に完全アクセス権を許可] を選択します。
[保存] をクリックします。
ホスト VM の詳細ページの上部にある [開始 / 再開] をクリックしてホスト VM を起動します。
必要に応じて、ホスト VM で停止しているワークロードを再起動します。
gcloud CLI
必要に応じて、ホスト VM から Google Cloudサービスへのアクセスが適切に制限されるように、VM サービス アカウントに付与されている IAM ロールを調整します。
サービス アカウントに付与されているロールの変更方法については、サービス アカウントの更新をご覧ください。
必要に応じて、ホスト VM で実行されている SAP ソフトウェアを停止します。
VM を停止します。
gcloud compute instances stop VM_NAME --zone=VM_ZONE
VM のアクセス スコープを変更します。
gcloud compute instances set-service-account VM_NAME --scopes=cloud-platform --zone=VM_ZONE
VM を起動します。
gcloud compute instances start VM_NAME --zone=VM_ZONE
必要に応じて、ホスト VM で実行されている SAP ソフトウェアを起動します。
ホスト VM がアクセス トークンを取得できるようする
BigQuery Connector for SAP が BigQuery にアクセスするために必要なアクセス トークンを取得するには、ホスト VM のサービス アカウントに権限を付与する必要があります。
アクセス トークンを作成する権限を付与するには、次の操作を行います。
Google Cloud コンソールで [VM インスタンス] ページを開きます。
[VM インスタンス] ページで、ホスト VM の名前をクリックして [VM の詳細] ページを開きます。
[VM の詳細] ページの [API と ID の管理] で、サービス アカウントの名前をメモします。次の例は、デフォルトの Compute Engine サービス アカウント用です。
SVC-ACCT-NUMBER-compute@
Google Cloud コンソールで、[IAM] ページに移動します。
プロジェクト プリンシパルのリストでサービス アカウント名を探して、[プリンシパルを編集します] をクリックします。[権限を編集] ダイアログが開きます。
[権限の編集] ペインで、[別のロールを追加] をクリックします。[ロールを選択] フィールドが表示されます。
[ロールを選択] フィールドで、[サービス アカウント トークン作成者] を指定します。
[保存] をクリックします。[IAM 権限] ページに戻ります。
これで、ホスト VM にアクセス トークンを作成する権限が付与されました。
SSL 証明書と HTTPS を設定する
BigQuery Connector for SAP と BigQuery API 間の通信は、SSL と HTTPS を使用して保護されます。
Google Trust Services リポジトリから、次の証明書をダウンロードします。
GTS Root R1GTS CA 1C3
SAP GUI で、
STRUSTトランザクションを使用して、ルート証明書と下位証明書の両方をSSL client SSL Client (Standard)PSE フォルダにインポートします。SAP の詳細については、SAP ヘルプ - PSE 認定資格のリストの保守をご覧ください。
SAP LT Replication Server ホストで、HTTPS ポートから BigQuery API への下り(外向き)トラフィックを許可するように、ファイアウォール ルールかプロキシが構成されていることを確認します。
具体的には、SAP LT Replication Server は、次のGoogle Cloud APIs にアクセスできる必要があります。
- https://bigquery.googleapis.com
- https://iamcredentials.googleapis.com
SSL の設定に関する SAP からの詳細情報については、SAP Note 510007 - Additional considerations for setting up SSL on Application Server ABAP をご覧ください。
Google Cloud の認証と認可をテストする
Google Cloud の認証が正しく構成されていることは、アクセス トークンをリクエストして BigQuery データセットに関する情報を取得することで確認します。
SAP LT Replication Server ホスト VM からの Google Cloudの認証と認可をテストするには、次の操作を行います。
SAP LT Replication Server ホスト VM で、コマンドライン シェルを開きます。
sidadmユーザーに切り替えます。ホスト VM のメタデータ サーバーから最初のアクセス トークンをリクエストします。
curl "http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token" -H "Metadata-Flavor: Google"
メタデータ サーバーは、次の例のようなアクセス トークンを返します。ACCESS_TOKEN_STRING_1 は、次のステップでコマンドにコピーするアクセス トークン文字列です。
{"access_token":"ACCESS_TOKEN_STRING_1", "expires_in":3599,"token_type":"Bearer"}プレースホルダ値を置き換え、以下のコマンドを実行して、IAM API に 2 つ目のアクセス トークンをリクエストします。
curl --request POST \ 'https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/SERVICE_ACCOUNT:generateAccessToken' \ --header 'Authorization: Bearer ACCESS_TOKEN_STRING_1' \ --header 'Accept: application/json' \ --header 'Content-Type: application/json' \ --data '{"scope":["https://www.googleapis.com/auth/bigquery"],"lifetime":"300s"}' \ --compressed次のように置き換えます。
SERVICE_ACCOUNT: 前の手順で BigQuery Connector for SAP 用に作成したサービス アカウント。ACCESS_TOKEN_STRING_1: 前のステップで取得した最初のアクセス トークン文字列
IAM API は、次の例に示すように 2 つ目のアクセス トークン ACCESS_TOKEN_STRING_2 を返します。次に、この 2 つ目のトークン文字列を BigQuery API へのリクエストにコピーします。
{"access_token":"ACCESS_TOKEN_STRING_2","expires_in":3599,"token_type":"Bearer"}プレースホルダの値を置き換えてから次のコマンドを発行して、BigQuery API から BigQuery データセットに関する情報を取得します。
curl "https://bigquery.googleapis.com/bigquery/v2/projects/PROJECT_ID/datasets/DATASET_NAME" \ -H "Accept: application/json" -H "Authorization: Bearer ACCESS_TOKEN_STRING_2"
次のように置き換えます。
PROJECT_ID: BigQuery データセットを含むプロジェクトの ID。DATASET_NAME: BigQuery で定義されているターゲット データセットの名前。ACCESS_TOKEN_STRING_2: 前の手順で IAM API によって返されたアクセス トークン文字列。
Google Cloud 認証が正しく構成されている場合は、データセットに関する情報が返されます。
正しく構成されていない場合は、BigQuery Connector for SAP のトラブルシューティングをご覧ください。
インストール パッケージをダウンロードする
BigQuery Connector for SAP のダウンロード ポータルから BigQuery Connector for SAP のインストール パッケージをダウンロードします。
ダウンロードを完了するには、Cloud Billing 請求番号が必要です。請求先アカウントについて詳しくは、Cloud Billing とお支払いプロファイルをご覧ください。
インストール パッケージには、SAP LT Replication Server の適切なトランスポート ディレクトリにコピーするトランスポート ファイルが含まれています。
BigQuery Connector for SAP をインストールする
BigQuery Connector for SAP トランスポート ファイルを含むインストール パッケージを受け取ったら、SAP 管理者は、トランスポート ファイルを SAP LT Replication Server にインポートすることで、BigQuery Connector for SAP をインストールできます。
BigQuery Connector for SAP 用の SAP トランスポートには、/GOOG/ 名前空間、DDIC オブジェクト、SLT SDK BADI の実装とクラスなど、BigQuery Connector for SAP に必要なすべてのオブジェクトが含まれています。
トランスポート ファイルを SAP LT Replication Server にインポートする前に、ソフトウェア要件に記載されているとおり、SAP LT Replication Server が BigQuery Connector for SAP でサポートされていることを確認します。
サポートされているバージョンの SAP LT Replication Server を使用していても、トランスポート ファイルをインポートする際に、エラー メッセージ Requests do not match the component version of the target system が表示される場合があります。このような場合は、トランスポート ファイルを SAP LT Replication Server に再インポートする必要があります。再インポート中は、[Import Transport Request] 画面 > [Options] タブで [Ignore Invalid Component Version] チェックボックスをオンにします。
次の手順は、おおまかな手順です。SAP システムはそれぞれ異なるため、SAP 管理者と連携して、SAP システムに必要な手順への変更点を確認してください。
BigQuery Connector for SAP トランスポート ファイルを、次の SAP LT Replication Server トランスポート インポート ディレクトリにコピーします。
/usr/sap/trans/cofiles/KXXXXXX.ED1/usr/sap/trans/data/RXXXXXX.ED1
上記の例で、
XXXXXXは、番号付きのファイル名を表します。SAP GUI で、トランザクション コード
STMS_IMPORTまたはSTMSを使用して、ファイルを SAP システムにインポートします。/GOOG/SLT_SDKパッケージのすべてのオブジェクトがアクティブで、整合性のある状態にします。- SAP インターフェースで、トランザクション コード
SE80を入力します。 - パッケージ セレクタで、
/GOOG/SLT_SDKを選択します。 [Object name] フィールドで、パッケージ
/GOOG/SLT_SDKを右クリックし、[Check] > [Package Check] > [Objects of Package] を選択します。[Result] 列の緑色のチェックは、すべてのオブジェクトがパッケージ チェックに合格したことを示します。
- SAP インターフェースで、トランザクション コード
BigQuery Connector for SAP が構成できることを確認する
トランスポート ファイルが正しくインポートされ、BigQuery Connector for SAP を構成する準備ができていることを確認するには、BigQuery Connector for SAP Business Add-In(BAdI)の実装が有効で、BigQuery Connector for SAP レプリケーション アプリケーションには、IUUC_REPL_APPL テーブルのエントリがあります。
- BAdI の実装を確認します。
- トランザクション SE80 を使用して移動し、
/GOOG/EI_IUUC_REPL_RUNTIME_BQ拡張オブジェクト フォルダを選択します。 - ページの右側にある [Enh. Implementation Elements] をクリックします。
- [Runtime Behavior] で、[Implementation is active] がオンになっていることを確認します。
- トランザクション SE80 を使用して移動し、
- レプリケーション アプリケーションを確認します。
- SAP データブラウザかトランザクション
SE16を使用して、IUUC_REPL_APPLテーブルを表示します。 - 次のアプリケーションが
IUUC_REPL_APPLテーブルに表示されていることを確認します。/GOOG/SLT_BQZGOOG_SLT_BQ:/GOOG/名前空間が登録されていないときに使用します。
- SAP データブラウザかトランザクション
BigQuery Connector for SAP のロールと認可を作成する
BigQuery Connector for SAP を使用するには、標準の SAP LT Replication Server 承認に加えて、BigQuery Connector for SAP に付属のカスタム トランザクション /GOOG/SLT_SETTINGS と /GOOG/REPLIC_VALID です。
デフォルトでは、カスタム トランザクションにアクセスできるユーザーがどの構成の設定も変更できるため、必要に応じて特定の構成へのアクセスを制限できます。
BigQuery Connector for SAP トランスポート ファイルには、BigQuery Connector for SAP に固有の承認用の Google BigQuery
Settings Authorization オブジェクト ZGOOG_MTID が含まれています。
カスタム トランザクションへのアクセス権を付与し、特定の構成へのアクセスを制限するには:
SAP トランザクション コード
PFCGを使用して、BigQuery Connector for SAP のロールを定義します。そのロールに、カスタム トランザクション
/GOOG/SLT_SETTINGSと/GOOG/REPLIC_VALIDへのアクセス権を付与します。ロールのアクセスを制限するには、
ZGOOG_MTID認可オブジェクトを使用してロールがアクセスできる各構成の認可グループを指定します。例:- BigQuery Connector for SAP(
ZGOOG_MTID)の認可オブジェクト:Activity 01Authorization Group AUTH_GROUP_1,AUTH_GROUP_N
AUTH_GROUP_01とAUTH_GROUP_Nは、SAP LT Replication Server 構成で定義されている値です。ZGOOG_MTIDに指定された認可グループは、SAPS_DMIS_SLT認可オブジェクト内のロールに指定された認可グループと一致する必要があります。- BigQuery Connector for SAP(
レプリケーションの構成
レプリケーションを構成するには、BigQuery Connector for SAP と SAP LT Replication Server の両方の設定を指定します。
/GOOG/CLIENT_KEY にアクセス設定を指定する
トランザクション SM30 を使用して、BigQuery へのアクセス用の設定を指定します。BigQuery Connector for SAP は、/GOOG/CLIENT_KEY カスタム構成テーブルにレコードとして設定を保存します。
アクセス設定を指定するには:
SAP GUI で、トランザクション コード
SM30を入力します。/GOOG/CLIENT_KEY構成テーブルを選択します。次のテーブル フィールドに値を入力します。
フィールド データ型 説明 名前 文字列 CLIENT_KEY構成のわかりやすい名前を指定します(例:ABAP_SDK_CKEY)。クライアント キー名は、BigQuery Connector for SAP が BigQuery へのアクセス構成を識別するために使用する固有識別子です。
サービス アカウント名 文字列 サービス アカウントを作成するで BigQuery Connector for SAP 用に作成したサービス アカウントの名前(メールアドレス形式)。例:
sap-example-svc-acct@example-project-123456.。範囲 文字列 Compute Engine の推奨事項に従って、
https://www.googleapis.com/auth/cloud-platformAPI アクセス スコープを指定します。このアクセス スコープは、ホスト VM の設定Allow full access to all Cloud APIsに対応します。詳細については、ホスト VM のアクセス スコープを設定するをご覧ください。プロジェクト ID 文字列 対象とする BigQuery データセットを含むプロジェクトの ID。 コマンド名 文字列 このフィールドは空白のままにしておきます。
認可クラス 文字列 レプリケーションに使用する認可クラス。 /GOOG/CL_GCP_AUTH_GOOGLEを指定します。認可フィールド 該当なし このフィールドは空白のままにしておきます。 トークンの更新期限(秒) 整数 アクセス トークンの有効期限が切れ、更新が必要になるまでの時間を秒単位で指定します。デフォルトは
3600(1 時間)です。1値を3599に指定すると、デフォルトの有効期限の3600秒がオーバーライドされます。0を指定した場合、BigQuery Connector for SAP ではデフォルト値の3600が使用されます。
SAP LT Replication Server レプリケーション構成を作成する
SAP トランザクション LTRC を使用して、SAP LT Replication Server レプリケーション構成を作成します。
SAP LT Replication Server がソース SAP システムとは異なるサーバーで稼働している場合は、レプリケーション構成を作成する前に、2 つのシステム間に RFC 接続があることを確認します。
レプリケーション構成の一部の設定がパフォーマンスに影響を与えます。インストールに適した設定値については、SAP ヘルプポータルで、ご使用の SAP LT Replication Server バージョンのパフォーマンス最適化ガイドをご覧ください。
SAP LT Replication Server のインターフェースと構成オプションは、使用しているバージョンによって若干異なる場合があります。
レプリケーションを構成するには、SAP LT Replication Server のバージョンに応じた手順を使用します。
DMIS 2011 SP17、DMIS 2018 SP02 以降でレプリケーションを構成する
次の手順では、新しいバージョンの SAP LT Replication Server でレプリケーションを構成します。以前のバージョンを使用している場合は、DMIS 2011 SP16、DMIS 2018 SP01 以前でレプリケーションを構成するをご覧ください。
SAP GUI で、トランザクション コード
LTRCを入力します。[Create configuration] アイコンをクリックします。[Create configuration] ウィザードが開きます。
[Configuration Name] フィールドと [Description] フィールドに、構成の名前と説明を入力し、[Next] をクリックします。
認可グループを指定して、特定の認可グループへのアクセスを制限できます。これは後で指定するもできます。
[Source System Connection Details] パネルで次の操作を行います。
- [RFC Connection] ラジオボタンをオンにします。
- [RFC Destination] フィールドに、ソースシステムへの RFC 接続の名前を指定します。
- 必要に応じて、[Allow Multiple Usage] と [Read from Single Client] のチェックボックスをオンにします。詳細については、SAP LT Replication Server のドキュメントをご覧ください。
- [Next] をクリックします。
上記の手順は RFC 接続の場合ですが、ソースがデータベースで、トランザクション
DBACOCKPITを使用してすでに接続を定義している場合は、[DB Connection] を選択できます。[Target System Connection Details] パネルで次の操作を行います。
- [Other] のラジオボタンを選択します。
- [Scenario] フィールドで、プルダウン メニューから [SLT SDK] を選択します。
- [Next] をクリックします。
[Specify Transfer Settings] パネルで、次の操作を行います。
[Data Transfer Settings] セクションの [Application] フィールドに、「
/GOOG/SLT_BQ」または「ZGOOG_SLT_BQ」と入力します。[Job options] セクションで、次の各フィールドに初期値を入力します。
- Number of Data Transfer Jobs
- Number of Initial Load Jobs
- Number of Calculation Jobs
[Replication Options] セクションで、[Real Time] ラジオボタンを選択します。
[Next] をクリックします。
構成を確認したら、[Save] をクリックします。
[Mass Transfer] 列の 3 桁の ID をメモします。この値は、後のステップで使用します。
詳細については、SAP Note 2652704 に付属の PDF(Replicating Data Using SLT SDK - DMIS 2011 SP17, DMIS 2018 SP02.pdf)をご覧ください。
DMIS 2011 SP16、DMIS 2018 SP01 以前でレプリケーションを構成する
次の手順では、以前のバージョンの SAP LT Replication Server でレプリケーションを構成します。これよりも後のバージョンを使用している場合は、DMIS 2011 SP17、DMIS 2018 SP02 以降でレプリケーションを構成するをご覧ください。
- SAP GUI で、トランザクション コード
LTRCを入力します。 - [New] をクリックします。新しい構成を指定するためのダイアログが開きます。
- [Specify Source System] で次の操作を行います。
- 接続タイプとして [RFC Connection] を選択します。
- RFC 接続名を入力します。
- [Allow Multiple Usage] が選択されていることを確認します。
- [Specify Target System] ステップで、次の操作を行います。
- ターゲット システムへの接続データを入力します。
- 接続タイプとして [RFC Connection] を選択します。
- [Scenario for RFC Communication] フィールドで、プルダウン リストから [Write Data to Target Using BAdI] という値を選択します。RFC 接続は自動的に [NONE] に設定されます。
- [Specify Transfer Settings] の手順で、[F4 Help] を押します。以前に定義したアプリケーションが [Application] フィールドに表示されます。
- [Mass Transfer] 列の 3 桁の ID をメモします。この値は、後のステップで使用します。
詳細については、SAP Note 2652704 に付属の PDF(Replicating Data Using SLT SDK - DMIS 2011 SP15, SP16, DMIS 2018 SP00, SP01.pdf)をご覧ください。
BigQuery への大量転送構成を作成する
カスタム /GOOG/SLT_SETTINGS トランザクションを使用して、BigQuery の一括転送を構成し、テーブルとフィールドのマッピングを指定します。
初期の一括転送オプションを選択する
/GOOG/SLT_SETTINGS トランザクションを初めて入力するときに、BigQuery の一括転送構成で編集が必要な部分を選択します。
一括転送構成の部分を選択するには:
SAP GUI で、
/nで始まる/GOOG/SLT_SETTINGSトランザクションを入力します。/n/GOOG/SLT_SETTINGS/GOOG/SLT_SETTINGSトランザクションの起動画面の [Settings Table] プルダウン メニューから [Mass Transfers] を選択します。新しい転送構成の場合は、[Mass Transfer Key] フィールドを空白のままにします。
[Execute] アイコンをクリックします。[BigQuery Settings Maintenance - Mass Transfers] 画面が表示されます。
テーブル作成とその他の一般的な属性を指定する
BigQuery の一括転送構成の最初のセクションで、一括転送構成を特定し、関連するクライアント キーと、ターゲット BigQuery テーブルの作成に関連する特定のプロパティを指定します。
SAP LT Replication Server が一括転送設定をレコードとして /GOOG/BQ_MASTR カスタム構成テーブルに保存します。
次の手順で指定するフィールドは必須になります。
[BigQuery Settings Maintenance - Mass Transfers] 画面で、[Append Row] アイコンをクリックします。
表示された行で、次の設定を指定します。
- [Mass Transfer Key] フィールドで、この転送の名前を定義します。この名前が一括転送の主キーになります。
- [Mass Transfer ID] フィールドに、対応する SAP LT Replication Server レプリケーション構成の作成時に生成された 3 桁の ID を入力します。
- BigQuery でターゲット フィールドの名前としてソース フィールドのラベルまたは簡単な説明を使用するには、[Use Custom Names Flag] チェックボックスをオンにします。フィールド名の詳細については、フィールドのデフォルトの命名オプションをご覧ください。
挿入をトリガーした変更の種類を保存し、ソーステーブル、SAP LT Replication Server 統計情報、BigQuery テーブル間のレコード数の検証を有効にするには、[Extra Fields Flag] チェックボックスをオンにします。
このフラグを設定すると、BigQuery Connector for SAP は BigQuery テーブル スキーマに列を追加します。詳しくは、レコード変更とカウントクエリ用の追加フィールドをご覧ください。
データエラーのあるレコードが発生したときにデータの送信を停止するには、[Break at First Error Flag] チェックボックスをオンにします。また、そうすることが推奨されます。詳細については、BREAK フラグをご覧ください。
データエラーのあるレコードが検出されたときに、レコードをスキップして BigQuery テーブルにレコードを挿入し続けるには、[Skip Invalid Records Flag] チェックボックスをオンにします。これは、オフのままにすることをおすすめします。詳細については、SKIP フラグをご覧ください。
[Google Cloud Key Name] フィールドに、対応する
/GOOG/CLIENT_KEY構成の名前を入力します。BigQuery Connector for SAP は、
/GOOG/CLIENT_KEY構成から自動的に Google Cloud プロジェクト ID を取得します。[BigQuery Dataset] フィールドに、前の手順で作成したターゲット BigQuery データセットの名前を入力します。
[Is Setting Active Flag] フィールドで、チェックボックスをオンにして一括転送構成を有効にします。
[Save] をクリックします。
一括転送レコードは
/GOOG/BQ_MASTRテーブルに追加され、[Changed By]、[Changed On]、[Changed At] フィールドに自動的に値が挿入されます。[Display Table] をクリックします。
新しい一括転送レコードが表示され、その後にテーブル属性のエントリパネルが表示されます。
テーブル属性を指定する
/GOOG/SLT_SETTINGS トランザクションの 2 番目のセクションで、テーブル名やテーブルのパーティショニングなどのテーブル属性や、各転送に含めるレコード数や BigQuery に送信されるチャンクを指定できます。
指定した設定は、レコードとして /GOOG/BQ_TABLE 構成テーブルに保存されます。
これらの設定は任意です。
テーブル属性を指定するには:
行を追加アイコンをクリックします。
[SAP Table Name] フィールドに、ソース SAP テーブルの名前を入力します。
[External Table Name] フィールドに、ターゲット BigQuery テーブルの名前を入力します。ターゲット テーブルが存在しない場合、BigQuery Connector for SAP は、この名前のテーブルを作成します。BigQuery のテーブル命名規則については、テーブルの命名をご覧ください。
[Send Uncompressed Flag] フィールドで、レコードの圧縮を無効にします。BigQuery Connector for SAP がソーステーブルで初期化された値を使用してソースレコードの空のフィールドを複製する必要がある場合にのみ、このフラグを指定します。パフォーマンスを向上させるには、このフラグを指定しないでください。詳細については、レコードの圧縮をご覧ください。
必要に応じて、[Chunk Size] フィールドに、BigQuery に送信される各チャンクに含めるレコードの最大数を指定します。可能であれば、BigQuery Connector for SAP で許可されている最大チャンクサイズ(現在は 10,000 レコード)とデフォルト値を使用します。ソースレコードに多くのフィールドがある場合、フィールド数によってはチャンクの全体的なバイトサイズが増加し、チャンクエラーが発生することがあります。この場合は、チャンクサイズを小さくしてバイトサイズを減らしてみてください。詳細については、BigQuery Connector for SAP のチャンクサイズをご覧ください。
必要に応じて、[Partition Type] フィールドで、パーティショニングに使用する時間の増分を指定します。有効な値は
HOUR、DAY、MONTH、またはYEARです。詳細については、テーブル パーティショニングをご覧ください。必要に応じて、[Partition Field] フィールドに、ターゲット BigQuery テーブルでパーティショニングに使用するタイムスタンプを含むフィールド名を指定します。[Partition Field] を指定する場合は、[Partition Type] も指定する必要があります。詳細については、テーブル パーティショニングをご覧ください。
[Is Setting Active Flag] フィールドで、チェックボックスをクリックしてテーブル属性を有効にします。[Is Setting Active Flag] ボックスがオンでない場合、BigQuery Connector for SAP は、SAP ソーステーブルの名前とデフォルトのチャンクサイズを使用して、パーティショニングは行わずに BigQuery テーブルを作成します。
[Save] をクリックします。
属性はレコードとして
/GOOG/BQ_TABLE構成テーブルに保存され、[Changed By]、[Changed On]、[Changed At] の各フィールドに自動的に挿入されます。[Display Fields] をクリックします。
新しいテーブル属性レコードが表示され、その後にフィールド マッピングのエントリパネルが表示されます。
デフォルトのフィールド マッピングをカスタマイズする
ソース SAP テーブルにタイムスタンプ フィールドやブール値が含まれている場合は、ターゲット BigQuery テーブルのデータタイプを正確に反映するように、デフォルトのデータ型マッピングを変更します。
他のデータ型やターゲット フィールドの名前を変更することもできます。
デフォルトのマッピングは SAP GUI で直接編集できます。他のユーザーが SAP LT Replication Server にアクセスせずに値を編集できるように、デフォルトのマッピングをスプレッドシートまたはテキスト ファイルにエクスポートすることもできます。
デフォルトのフィールド マッピングと実施できる変更の詳細については、フィールド マッピングをご覧ください。
ターゲット BigQuery フィールドのデフォルト マッピングをカスタマイズするには:
トランザクション
/GOOG/SLT_SETTINGSの [BigQuery Settings Maintenance - Fields] ページで、現在構成している一括転送のデフォルト フィールド マッピングを表示します。必要に応じて、[External Data Element] 列でデフォルトのターゲット データ型を編集します。特に、以下のデータ型のターゲット データ型を変更します。
- タイムスタンプ 。デフォルトのターゲット データ型を、
NUMERICからTIMESTAMPまたはTIMESTAMP (LONG)に変更します。 - ブール値。デフォルトのターゲット データ型を
STRINGからBOOLEANに変更します。 - 16 進数。デフォルトのターゲット データ型を
STRINGからBYTESに変更します。
デフォルトのデータ型マッピングを編集するには:
- 編集が必要なフィールドの行で、[External Data Element] フィールドをクリックします。
- データ型のダイアログで、必要な BigQuery データ型を選択します。
- 変更内容を確認し、[Save] をクリックします。
- タイムスタンプ 。デフォルトのターゲット データ型を、
[BigQuery Settings Maintenance] ページで [Custom Names] フラグを指定した場合は、必要に応じて [Temporary Field Name] 列のデフォルトのターゲット フィールド名を編集します。
指定した値は、[External Field Name] 列に表示されるデフォルトの名前をオーバーライドします。
必要に応じて、[Field Description] 列のデフォルトのターゲット フィールドの説明を編集します。
必要に応じて、外部編集用にフィールド マップをエクスポートします。手順については、CSV ファイルで BigQuery のフィールド マップを編集するをご覧ください。
すべての変更が完了し、外部で編集された値がアップロードされたら、[Is Setting Active Flag] チェックボックスがオンになっていることを確認します。[Is Setting Active Flag] がオンになっていない場合、BigQuery Connector for SAP によってターゲット テーブルがデフォルト値で作成されます。
[Save] をクリックします。
変更は、
/GOOG/BQ_FIELD構成テーブルに保存され、[Changed By]、[Changed On]、[Changed At] フィールドに自動的に挿入されます。
レプリケーションをテストする
レプリケーションの構成をテストするには、データ プロビジョニングを開始します。
SAP GUI で、SAP LT Replication Server Cockpit(トランザクション
LTRC)を開きます。テストしているテーブル レプリケーションの一括転送構成をクリックします。
[Data Provisioning] をクリックします。
[Data Provisioning] パネルで、データ プロビジョニングを開始します。
- ソーステーブルの名前を入力します。
- テストするデータ プロビジョニングの種類のラジオボタンをオンにします([Start Load] など)。
[Execute] アイコンをクリックします。データ転送が開始され、[Participating objects] 画面に進行状況が表示されます。
テーブルが BigQuery に存在しない場合、BigQuery Connector for SAP は、以前に
/GOOG/SLT_SETTINGSトランザクションで定義したテーブルとフィールド属性から構築するスキーマからテーブルを作成します。テーブルの初期読み込みにかかる時間は、テーブルのサイズとレコード数によって異なります。
メッセージは、SAP LT Replication Server でトランザクション
LTRCの [Application Logs] セクションに書き込まれます。
レプリケーションを検証する
レプリケーションは、次の方法を使用して検証できます。
- SAP LT Replication Server の場合:
- [Data Provisioning] 画面でレプリケーションをモニタリングします。
- [Application Logs] 画面でエラー メッセージを確認します。
- BigQuery のテーブル情報タブ:
- [スキーマ] タブで、スキーマが正しく表示されることを確認します。
- [プレビュー] タブで、挿入された行のプレビュー表示を確認します。
- [詳細] タブで、挿入された行数、テーブルサイズ、その他の情報を確認します。
- BigQuery テーブルの構成時に [Extra Fields Flag] チェックボックスがオンになっている場合は、
/GOOG/REPLIC_VALIDカスタム トランザクションを入力して、レプリケーション検証ツールを実行します。
SAP LT Replication Server のレプリケーションを確認する
トランザクション LTRC を使用して、初期読み込みまたはレプリケーション ジョブの開始後に進行状況を確認し、エラー メッセージをチェックします。
SAP LT Replication Server の [Load Statistics] タブで読み込みのステータスを確認し、[Data Transfer Monitor] タブでジョブの進行状況を確認します。
トランザクション LTRC の [Application Logs] 画面には、BigQuery、BigQuery Connector for SAP、SAP LT Replication Server によって返されるすべてのメッセージが表示されます。
SAP LT Replication Server の BigQuery Connector for SAP コードによって発行されたメッセージの先頭には、接頭辞 /GOOG/SLT が付いています。BigQuery API から返されるメッセージの先頭には、接頭辞 /GOOG/MSG が付いています。
SAP LT Replication Server によって返されるメッセージの先頭には、/GOOG/ 接頭辞は付きません。
BigQuery でレプリケーションを確認する
Google Cloud コンソールで、テーブルが作成されて BigQuery によってデータが挿入されていることを確認します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] セクションの検索フィールドに、ターゲット BigQuery テーブルの名前を入力し、
Enterを押します。ページの右側にあるコンテンツ ペインのタブの下に、テーブル情報が表示されます。
テーブル情報セクションで、次の見出しをクリックして、テーブルと行の挿入を確認します。
- プレビュー: BigQuery テーブルに挿入された行とフィールドを表示します。
- スキーマ: フィールド名とデータ型を表示します。
- 詳細: テーブルサイズ、行の合計数などの詳細を表示します。
Replication Validation ツールを実行する
BigQuery テーブルの構成時に [Extra Fields Flag] が選択されている場合は、Replication Validation ツールを使用して、BigQuery テーブルのレコード数と SAP LT Replication Server 統計またはソーステーブルのレコード数を比較するレポートを生成できます。
Replication Validation ツールを実行するには:
SAP GUI で、
/nで始まる/GOOG/REPLIC_VALIDトランザクションを入力します。/n/GOOG/REPLIC_VALID
[Processing Options] セクションで、[Execute Validation] ラジオボタンをクリックします。
[Selection Options] セクションで、次の仕様を入力します。
- [GCP Partner Identifier] フィールドのプルダウン メニューから、[BigQuery] を選択します。
- [Check Type] フィールドのプルダウン メニューから、生成するレポートの種類を選択します。
- 初期読み込み数
- レプリケーション数
- 現在のカウント
- [Check Date] フィールドが表示されている場合は、カウントが必要な日付を指定します。
- [Mass Transfer Key] フィールドに、一括転送構成名を入力します。
[Execute] アイコンをクリックして、Replication Validation ツールを実行します。
検証チェックが完了したら、[Processing Options] セクションで [Display Report] ラジオボタンをクリックし、[Execute] アイコンをクリックしてレポートを表示します。
詳細については、Replication Validation ツールをご覧ください。
トラブルシューティング
BigQuery Connector for SAP を使用して SAP と BigQuery との間で読み込みまたはレプリケーションを構成して実行する場合に発生する可能性のある問題の診断と解決については、BigQuery Connector for SAP トラブルシューティング ガイドをご覧ください。
サポートを受ける
レプリケーションと BigQuery Connector for SAP の問題を解決する必要がある場合は、入手可能な診断情報をすべて収集し、Cloud カスタマーケアにお問い合わせください。カスタマーケアへのお問い合わせ方法については、 Google Cloudでの SAP に関するサポートを利用するをご覧ください。