Google Cloud fournit une infrastructure certifiée SAP rentable, fiable, sécurisée et hautes performances pour l'exécution de SAP S/4HANA sur SAP HANA. Pour obtenir la liste complète des solutions SAP compatibles avec Google Cloud, consultez la page SAP sur Google Cloud.
Architecture
Les schémas suivants présentent une vue d'ensemble de trois modèles de déploiement courants pour SAP S/4HANA : centralisé, distribué et distribués avec une haute disponibilité.
Déploiement centralisé
Dans un déploiement centralisé, vous pouvez installer S/4HANA et la base de données SAP HANA sur la même instance de VM Compute Engine. Nous recommandons cette approche pour les environnements hors production tels que les environnements de bac à sable et de développement.
Le schéma suivant illustre une architecture de référence pour SAP S/4HANA sur SAP HANA dans un déploiement centralisé. Notez que SAP ASCS, PAS, WD et la base de données SAP HANA sont tous installés sur la même instance de VM.
Déploiement distribué
Dans un déploiement distribué, vous pouvez installer les différents composants sur différentes instances Compute Engine. Nous recommandons cette approche pour les environnements de production ou les environnements qui nécessitent une grande puissance de calcul pour gérer des charges de transaction élevées.
Le schéma suivant montre une architecture de référence pour SAP S/4HANA dans un modèle de déploiement distribué. Notez que SAP ASCS, PAS, WD et HANA sont tous installés sur des instances de VM différentes.
Déploiement distribué à haute disponibilité
Dans un déploiement distribué à haute disponibilité, les clusters Linux sont configurés sur plusieurs zones pour éviter les défaillances de composants dans une région donnée. Vous pouvez déployer un cluster Linux sur plusieurs zones à l'aide d'une configuration en mode actif/passif ou d'une configuration en mode actif/actif. Dans les deux cas, vous commencez par configurer deux instances de VM Compute Engine dans des zones distinctes pour une redondance maximale, chacune avec sa propre base de données SAP HANA. Le schéma suivant illustre une architecture SAP S/4HANA qui utilise un cluster Linux pour obtenir une haute disponibilité du côté de l'application et de la base de données SAP HANA : Les schémas suivants illustrent une base de données SAP HANA hautement disponible lors d'une opération normale et lors d'une opération de reprise :
Les schémas suivants illustrent une base de données SAP HANA hautement disponible lors d'une opération normale et lors d'une opération de reprise :
Fonctionnement normal :

Opération de prise de relais :

Pour combiner la haute disponibilité et la reprise après sinistre de la base de données, vous pouvez utiliser la réplication du système SAP HANA. Le schéma suivant montre une combinaison des deux pour atteindre une disponibilité maximale et une tolérance aux pannes :

Le cluster qui gère la haute disponibilité inclut les fonctions et fonctionnalités suivantes :
- Deux VM hôtes, chacune avec une instance de SAP HANA.
- La réplication du système SAP HANA synchrone
- Le gestionnaire de ressources de cluster à haute disponibilité Pacemaker
- Un mécanisme de cloisonnement qui protège le nœud défaillant.
- Le redémarrage automatique de l'instance ayant échoué en tant que nouvelle instance secondaire
L'architecture côté application est similaire. Dans ce cas, le cluster gère les services centraux SAP (ASCS) ABAP, ainsi que le serveur de réplication de mise en file d'attente ou le service de réplication de mise en file d'attente (ERS, Enqueue Replication Server) qui sont utilisés pour fournir au système SAP S/4HANA une haute disponibilité au cas où quelque chose arrive à l'une des instances ASCS et ERS.
Selon la version de SAP S/4HANA que vous utilisez, le serveur de mise en file d'attente et le serveur de réplication de mise en file d'attente / réplicateur de mise en file d'attente s'exécutent sur une version différente:
- S/4HANA 1709 et versions antérieures : ENSA1 et ERS
- S/4HANA 1809 ou version ultérieure : ENSA2 et ERS2
Le schéma suivant illustre un système SAP S/4HANA utilisant un cluster Pacemaker pour limiter les points de défaillance uniques du serveur de messages et du serveur de mise en file d'attente :

Les détails concernant le déploiement du système à haute disponibilité et le clustering Linux sur plusieurs zones sont traités plus loin dans ce document.
Remarque sur l'équilibrage de charge
Dans un environnement SAP S/4HANA distribué, l'équilibrage de charge est requis. Vous pouvez configurer l'équilibrage de charge de l'application à l'aide d'une combinaison de la couche d'application SAP et des équilibreurs de charge réseau. Pour en savoir plus, consultez la section Implémentations d'une IPV pour l'équilibreur de charge réseau passthrough interne du guide de planification de la haute disponibilité pour SAP NetWeaver surGoogle Cloud.
Composants de déploiement
SAP S/4HANA comprend les composants techniques suivants :
- Base de données SAP HANA
- ASCS : Services centraux SAP ABAP
- Contient le serveur de messagerie et le serveur de file d'attente, requis dans tout système SAP ABAP.
- Ils sont déployés sur leur propre instance de VM dans des déploiements à haute disponibilité ou déployés sur l'instance de VM hébergeant le PAS.
- Dans les déploiements à haute disponibilité, les ressources ASCS sont gérées par un gestionnaire de ressources de cluster Linux tel que Pacemaker.
- ERS : serveur de réplication de mise en file d'attente ou réplication de mise en file d'attente
- Déployé dans des déploiements à haute disponibilité pour conserver une instance dupliquée de la table de verrouillage en cas d'événement au niveau de l'instance ASCS.
- Géré par un gestionnaire de ressources de cluster Linux, tel que Pacemaker.
- PAS : serveur d'applications principal
- Le premier ou le seul serveur d'applications pour le système SAP.
- AAS : serveur d'applications supplémentaire
- Généralement déployé pour l'équilibrage de charge au niveau de l'application. Vous pouvez installer plusieurs instances AAS pour obtenir une disponibilité plus élevée du point de vue de la couche d'application. Si l'un des serveurs d'applications tombe en panne, toutes les sessions utilisateur connectées à ce serveur d'applications sont arrêtées, mais les utilisateurs peuvent se reconnecter à l'autre serveur AAS de l'environnement.
- Passerelle SAP NetWeaver
- Déployée en tant que système autonome ou dans le cadre du système SAP S/4HANA.
- Permet au système de connecter des appareils, des environnements et des plates-formes aux systèmes SAP à l'aide du protocole Open Data (Open Data Protocol).
- Serveur SAP Fiori Front-End
- Déployée en tant que système autonome ou dans le cadre du système SAP S/4HANA.
- Le système SAP Netweaver ABAP est utilisé pour héberger les applications SAP Fiori.
- WD : coordinateur Web (facultatif)
- Équilibreur de charge logiciel intelligent qui répartit les requêtes HTTP et HTTPS, en fonction du type d'application, sur PAS et AAS.
Les services Google Cloud suivants sont utilisés dans le déploiement de SAP S/4HANA:
| Service | Description |
|---|---|
| Mise en réseau VPC |
Connectez vos instances de VM les unes aux autres et à Internet. Chaque instance de VM est membre d'un ancien réseau avec une plage d'adresses IP globale unique ou d'un réseau de sous-réseaux recommandé, où l'instance de VM appartient à un seul sous-réseau membre d'un réseau plus grand. Notez qu'un réseau cloud privé virtuel (VPC) ne peut pas s'étendre sur plusieurs projets Google Cloud , mais qu'un projet Google Cloud peut englober plusieurs réseaux VPC. Pour connecter des ressources provenant de différents projets à un réseau VPC commun, vous pouvez utiliser un VPC partagé. Cela permet aux ressources de communiquer entre elles de manière sécurisée et efficace à l'aide d'adresses IP internes de ce réseau. Pour en savoir plus sur le provisionnement d'un VPC partagé, y compris sur les conditions requises, les étapes de configuration et l'utilisation, consultez la page Provisionner un VPC partagé. |
| Compute Engine | Créez et gérez des VM avec le système d'exploitation et la pile logicielle de votre choix. |
| Persistent Disk et Hyperdisk |
Vous pouvez utiliser Persistent Disk et Google Cloud Hyperdisk :
|
| Google Cloud console |
Outil basé sur un navigateur pour gérer les ressources de Compute Engine. Utilisez un modèle pour décrire toutes les ressources et instances de Compute Engine dont vous avez besoin. Il n'est pas nécessaire de créer et de configurer individuellement les ressources, ni de déterminer les dépendances : la console Google Cloud s'en charge pour vous. |
| Cloud Storage | Vous pouvez stocker vos sauvegardes de base de données SAP dans Cloud Storage pour plus de durabilité et de fiabilité, grâce à la réplication. |
| Cloud Monitoring |
Ce service offre une visibilité sur le déploiement, les performances, le temps d'activité et la santé de Compute Engine, du réseau et des disques de stockage persistant. Monitoring collecte des métriques, des événements et des métadonnées à partir de Google Cloud , et les utilise pour générer des insights via des tableaux de bord, des graphiques et des alertes. Vous pouvez surveiller les métriques de calcul gratuitement grâce à Monitoring. |
| IAM |
Fournit un contrôle unifié des autorisations pour les ressources Google Cloud . IAM vous permet de contrôler qui peut effectuer des opérations du plan de contrôle sur vos VM, y compris la création, la modification et la suppression de VM et de disques de stockage persistant, ainsi que la création et la modification de réseaux. |
| Filestore |
Stockage de fichiers NFS entièrement géré hautes performances depuis Google Cloud. Pour les déploiements multizones à haute disponibilité, nous vous recommandons d'utiliser Filestore Regional (anciennement Filestore Enterprise) avec une garantie de disponibilité de 99,99% dans le contrat de niveau de service. Pour en savoir plus sur les niveaux de service Filestore, consultez la section Niveaux de service. |
| NetApp Cloud Volumes ONTAP |
Une solution de stockage intelligente et complète que vous déployez et gérez vous-même sur une instance de VM Compute Engine. Pour en savoir plus sur NetApp Cloud Volumes ONTAP, consultez la page Présentation de Cloud Volumes ONTAP. |
| Google Cloud NetApp Volumes |
Solution de stockage de fichiers NFS et SMB entièrement gérée de Google Cloud, basée sur NetApp Cloud Volumes ONTAP. Selon la région, vous pouvez sélectionner plusieurs niveaux de service. Pour en savoir plus, consultez la section Niveaux de service. |
Considérations de conception
Cette section fournit des conseils pour vous aider à utiliser cette architecture de référence afin de développer une architecture répondant à vos exigences spécifiques en termes de sécurité, de fiabilité, d'efficacité opérationnelle, de coût et de performances.
Mise en réseau
Il existe plusieurs façons de déployer un système SAP S/4HANA du point de vue de la mise en réseau. La manière dont vous déployez votre réseau a un impact significatif sur sa disponibilité, sa résilience et ses performances. Comme indiqué précédemment, un cloud privé virtuel (VPC) est un réseau privé sécurisé et isolé, hébergé dansGoogle Cloud. Les VPC sont mondiaux dans Google Cloud. Un seul VPC peut donc s'étendre sur plusieurs régions sans communiquer sur Internet.
Un déploiement SAP standard place les instances de systèmes à haute disponibilité dans différentes zones de la même région pour garantir la résilience tout en offrant une faible latence. Les sous-réseaux peuvent s'étendre sur plusieurs zones en raison des fonctionnalités de Google Cloud . Ces fonctionnalités simplifient également le clustering SAP, car l'adresse IP virtuelle (VIP) du cluster peut se trouver dans la même plage que les instances des systèmes à haute disponibilité. Cette configuration protège l'adresse IP flottante à l'aide d'un équilibreur de charge d'application interne et s'applique au clustering à haute disponibilité de la couche d'application (ASCS et ERS) et de la couche de base de données SAP HANA (principale et secondaire SAP HANA).
Il existe plusieurs façons de créer votre réseau et de connecter votre système SAP S/4HANA à votre infrastructure :
L'appairage de réseaux VPC connecte deux réseaux VPC afin que les ressources de chaque réseau puissent communiquer entre elles. Les réseaux VPC peuvent être hébergés dans le même Google Cloud projet, dans différents projets de la même organisation ou même dans différents projets de plusieurs organisations. L'appairage de réseaux VPC établit une connexion directe entre deux réseaux VPC, chacun utilisant ses propres sous-réseaux, ce qui permet une communication privée entre les ressources des VPC appairés.
Le VPC partagé est une fonctionnalité de Google Cloudqui permet à une organisation de connecter des ressources provenant de différents projets à un réseau VPC commun. Les systèmes utilisant un VPC partagé peuvent communiquer efficacement et en toute sécurité à l'aide d'adresses IP internes. Vous pouvez gérer de manière centralisée les ressources réseau (telles que les sous-réseaux, les routes et les pare-feu) au sein d'un projet hôte, tout en déléguant les responsabilités administratives liées à la création et à la gestion de ressources individuelles aux projets de service. Cette séparation des tâches simplifie l'administration du réseau et garantit la cohérence des règles de sécurité dans votre organisation.
Pour les systèmes SAP, il est généralement recommandé de regrouper les ressources par type d'environnement. Par exemple, les environnements de production ne doivent pas partager de ressources de calcul avec des environnements hors production afin de fournir une isolation adéquate, mais vous pouvez utiliser un VPC partagé pour une couche de connectivité commune entre vos projets. Vous pouvez également utiliser des VPC indépendants et l'appairage de réseaux VPC pour connecter des projets.
Lors de la conception de votre réseau, commencez avec un projet hôte contenant un ou plusieurs réseaux VPC partagés. Vous pouvez associer des projets de service supplémentaires à un projet hôte, ce qui permet aux projets de service de participer au VPC partagé. Selon vos besoins, vous pouvez déployer SAP S/4HANA sur un seul VPC partagé ou sur plusieurs VPC partagés. Les deux scénarios diffèrent en termes de contrôle du réseau, d'isolation de l'environnement SAP et d'inspection du réseau :
- Scénario 1 : Déploiement de SAP S/4HANA sur un seul VPC partagé. Cela simplifie le déploiement et réduit les frais généraux, au détriment de l'isolation entre les réseaux.
- Scénario 2 : Déploiement de SAP S/4HANA sur plusieurs VPC partagés Cela renforce l'isolation du réseau et la sécurité, engendrant de la complexité et des coûts administratifs.
Il est également possible d'utiliser une approche hybride. Par exemple, vous pouvez utiliser un VPC partagé pour l'environnement de production et un VPC partagé pour tous les systèmes hors production. Pour en savoir plus, consultez la section "Mise en réseau" de la checklist générale pour SAP sur Google Cloud.
Points de défaillance uniques
Un système SAP S/4HANA présente des points de défaillance uniques communs susceptibles d'affecter sa disponibilité :
- Services centraux SAP tels que le serveur de messagerie et le serveur de file d'attente
- Serveur d'applications SAP
- Base de données SAP HANA
- SAP Web Dispatcher, s'il est utilisé comme interface pour l'accès HTTP/HTTPS au système
- Stockage partagé tel que NFS
Il existe plusieurs options permettant de réduire l'impact de ces points de défaillance uniques. Ces options impliquent le déploiement du système à l'aide de solutions à haute disponibilité, de services de réplication ou d'autres fonctionnalités qui protègent le système contre les défaillances. Lors de la planification de votre système SAP S/4HANA, nous vous recommandons d'étudier ces points de défaillance uniques et de planifier en conséquence. Pour obtenir une présentation des autres solutions que vous pouvez utiliser pour gérer des points de défaillance uniques, consultez les sections suivantes de ce guide :
- Disponibilité et continuité
- Architecture de déploiement pour SAP HANA
- Architecture de déploiement pour SAP S/4HANA
Disponibilité et continuité
Au cours de la phase de planification d'une mise en œuvre de SAP S/4HANA, vous devez spécifier les points de données suivants afin de définir la disponibilité et la continuité du système :
- Objectifs de niveau de service (SLO) : valeur ou plage de valeurs cible pour un niveau de service mesuré par un indicateur de niveau de service (SLI) Exemples : performances, disponibilité et fiabilité.
- Indicateurs de niveau de service (SLI) : métriques, telles que la latence, qui aident à mesurer les performances d'un service. Il s'agit d'une mesure quantitative soigneusement définie d'un aspect du niveau de service fourni.
- Contrat de niveau de service (SLA) : contrat de service entre deux parties (fournisseur, client) qui définit un contrat concernant le service fourni en termes mesurables appelés objectifs de niveau de service (SLO).
- Objectif de temps de récupération (RTO) : durée maximale tolérable entre un incident de perte de données et son atténuation.
- Objectif de point de récupération (RPO) : l'objectif de point de récupération (RPO) correspond à la quantité maximale de données pouvant être perdues, mesurée en temps, sans causer de préjudice important. En pratique, cela se traduit par un moment où l'état des données affectées doit être récupéré après un événement de perte de données.
En fonction des points de données et des valeurs convenues entre toutes les parties prenantes, le système SAP S/4HANA s'appuie sur des fonctionnalités telles que la haute disponibilité ou la reprise après sinistre :
- Haute disponibilité : capacité d'un système compatible avec l'objectif de continuité des activités tout en garantissant que les données et les services sont disponibles pour les utilisateurs en cas de besoin. Le moyen habituel d'y parvenir consiste à activer la redondance, y compris la redondance matérielle, la redondance du réseau et la redondance des centres de données.
- Reprise après sinistre : capacité d'un système à être protégé contre les interruptions non planifiées via des méthodes de récupération fiables et prévisibles sur un matériel et/ou un emplacement physique différents.
La haute disponibilité et la reprise après sinistre sont toutes deux compatibles, mais elles couvrent des cas et des situations différents. Par exemple, une solution à haute disponibilité vous permet de poursuivre vos opérations si l'un des éléments du système subit une panne ou un temps d'arrêt imprévus, sans engendrer d'interruption pour vos utilisateurs. Il en va de même pour une solution de reprise après sinistre, à l'exception de l'interruption entre le moment où la panne se produit et le moment où la solution de reprise après sinistre démarre les éléments défectueux du système dans un autre emplacement.
Les sections suivantes présentent les différentes options disponibles pour planifier et déployer votre système SAP S/4HANA sur Google Cloud.
Types de machines compatibles avec SAP S/4HANA
Google Cloud propose des types d'instances de VM Compute Engine certifiés par SAP pour répondre aux exigences de dimensionnement lors du déploiement de SAP S/4HANA. Pour en savoir plus sur le dimensionnement sur Google Cloud et les types de machines compatibles, consultez les documents suivants:
- Types de machines compatibles avec SAP HANA sur Google Cloud
- Types de machines compatibles avec SAP NetWeaver sur Google Cloud
Les types de machines personnalisés pour SAP HANA sur Google Cloud sont également certifiés par SAP. Vous pouvez exécuter des instances SAP HANA avec moins de 64 processeurs virtuels tant que vous conservez un ratio processeur virtuel/mémoire d'au moins 1:6,5.
Pour afficher les valeurs SAPS des machines virtuelles Compute Engine certifiées pour les applications SAP, consultez la note SAP 2456432 - Applications SAP sur Google Cloud: produits compatibles et Google Cloud types de machines.
SAP fournit également une liste certifiée des Google Cloud configurations pour SAP HANA sur son site Web. Pour en savoir plus, consultez le Répertoire matériel SAP HANA certifié et compatible.
Planifier les régions et les zones
Lorsque vous déployez une instance Compute Engine, vous devez choisir une région et une zone. Une région est un emplacement géographique spécifique où vous pouvez exécuter vos ressources et correspond à un ou plusieurs emplacements de centre de données relativement proches les uns des autres. Chaque région possède une ou plusieurs zones avec une connectivité, une alimentation et un refroidissement redondants.
Les ressources globales, telles que les images de disque préconfigurées et les instantanés de disque, sont accessibles dans toutes les régions et les zones. Les ressources régionales, telles que les adresses IP externes statiques régionales, ne sont accessibles qu'aux ressources situées dans la même région. Les ressources zonales, telles que les instances de calcul et les disques, ne sont accessibles qu'aux ressources situées dans la même zone. Pour en savoir plus, consultez la page Ressources globales, régionales et zonales.

Lorsque vous choisissez une région et une zone pour vos instances de calcul, tenez compte des points suivants:
- L'emplacement de vos utilisateurs et de vos ressources internes, telles que votre centre de données ou votre réseau d'entreprise. Pour réduire la latence, sélectionnez un emplacement situé à proximité de vos utilisateurs et de vos ressources.
- Les plates-formes de processeur disponibles pour cette région et cette zone. Par exemple, les processeurs Intel Broadwell, Haswell, Skylake et Ice Lake sont compatibles avec les charges de travail SAP NetWeaver sur Google Cloud.
- Pour en savoir plus, consultez la note SAP 2456432 - Applications SAP sur Google Cloud: produits et types de machines Google Cloud compatibles.
- Pour en savoir plus sur les régions dans lesquelles les processeurs Haswell, Broadwell, Skylake et Ice Lake peuvent être utilisés avec Compute Engine, consultez la section Régions et zones disponibles.
- Assurez-vous que votre serveur d'applications SAP et votre base de données se trouvent dans la même région.
Options de stockage pour SAP S/4HANA
Voici les options de stockage proposées par Google Cloud et certifiées par SAP pour une utilisation avec SAP S/4HANA et SAP HANA.
Pour obtenir des informations générales sur les options de stockage dans Google Cloud, consultez la section Options de stockage.
Persistent Disk
- Disque persistant standard (
pd-standard) : stockage de blocs efficace et économique sauvegardé par des disques durs standards (HDD) pour gérer les opérations de lecture/écriture séquentielles, mais pas optimisé pour gérer des taux élevés d'opérations d'entrée/sortie aléatoires par seconde (IOPS). - Disque persistant SSD (
pd-ssd) : fournit un stockage de blocs fiable, à hautes performances et sauvegardé par des disques durs SSD. - Disque persistant avec équilibrage (
pd-balanced) : fournit un stockage de blocs économique et fiable basé sur SSD. - Disque persistant extrême (
pd-extreme) : basé sur SSD, fournit des options d'IOPS et de débit maximales supérieures à celles despd-ssdpour les types de machines Compute Engine plus volumineux. Pour en savoir plus, consultez la page Disques persistants extrêmes.
Hyperdisk
Les volumes Hyperdisk Extreme (
hyperdisk-extreme) offrent des options d'IOPS et de débit maximales plus élevés que les volumes Persistent Disk basés sur SSD. Vous sélectionnez les performances requises en provisionnant les IOPS, qui déterminent le débit. Il est préférable d'y héberger les répertoires/hana/dataet/hana/log. Pour en savoir plus, consultez la page À propos de Google Cloud Hyperdisk Extreme.Hyperdisk avec équilibrage (
hyperdisk-balanced) : la meilleure option pour la plupart des charges de travail. Nous recommandons cette option pour l'utilisation avec les bases de données ne nécessitant pas les performances Hyperdisk Extreme. Vous sélectionnez les performances dont vous avez besoin en provisionnant les IOPS et le débit. Vous pouvez utiliser des volumes Hyperdisk avec équilibrage pour héberger les répertoires/hana/dataet/hana/log. Pour en savoir plus, consultez la page À propos de Google Cloud Hyperdisk équilibré.
Persistent Disk et Hyperdisk sont conçus pour offrir une grande durabilité. Ils stockent les données de manière redondante afin de garantir leur intégrité. Chaque disque persistant peut stocker jusqu'à 64 To, ce qui vous permet de créer des volumes logiques volumineux sans gérer de groupes de disques. Selon le type d'espace de stockage que vous utilisez, les volumes Hyperdisk permettent également jusqu'à 64 To d'espace de stockage. L'une des principales caractéristiques des volumes Persistent Disk et Hyperdisk est qu'ils sont automatiquement chiffrés pour protéger les données.
Lors de sa création, une instance de VM Compute Engine attribue par défaut un seul disque Persistent Disk ou Hyperdisk contenant le système d'exploitation. Vous pouvez ajouter d'autres options de stockage à l'instance de VM si nécessaire.
Pour les implémentations SAP, examinez les options de stockage recommandées dans Structure de répertoires SAP et options de stockage.
Solutions de partage de fichiers
Plusieurs solutions de partage de fichiers sont disponibles sur Google Cloud, parmi lesquelles:
- Filestore: Google Cloud stockage de fichiers NFS entièrement géré et à hautes performances de Google Cloud avec une disponibilité régionale.
- Google Cloud NetApp Volumes: solution de stockage de fichiers NFS ou SMB entièrement gérée parGoogle Cloud.
- NetApp Cloud Volumes ONTAP : solution de stockage intelligente et complète que vous déployez et gérez vous-même sur une VM Compute Engine.
Pour en savoir plus sur les solutions de partage de fichiers pour SAP S/4HANA surGoogle Cloud, consultez la page Solutions de partage de fichiers pour SAP sur Google Cloud.
Cloud Storage pour le stockage d'objets
Cloud Storage est un store d'objets pour des fichiers de n'importe quel type et n'importe quel format. Il propose un espace de stockage quasiment illimité, ce qui signifie que vous n'avez pas à vous soucier de son provisionnement ni de l'ajout de capacité. Un objet Cloud Storage contient des données de fichier et les métadonnées qui y sont associées, et sa taille peut atteindre 5 téraoctets. Un bucket Cloud Storage peut stocker un nombre illimité d'objets.
Il est courant de stocker des fichiers dans Cloud Storage pour tout type d'usage. Par exemple, Cloud Storage constitue un excellent emplacement de stockage pour les sauvegardes de base de données SAP HANA. Pour en savoir plus sur la planification de la sauvegarde de base de données, consultez la page Sauvegarde et récupération de base de données. Vous pouvez également utiliser Cloud Storage dans le cadre d'un processus de migration.
De plus, vous pouvez utiliser le service de sauvegarde et de reprise après sinistre en tant que solution centralisée pour les opérations de sauvegarde et de reprise après sinistre. Ce service est compatible avec un large éventail de bases de données, y compris SAP HANA. Pour en savoir plus, consultez la page Solutions de sauvegarde et de reprise après sinistre avec Google Cloud.
Choisissez votre option Cloud Storage en fonction de la fréquence à laquelle vous devez accéder aux données. Pour un accès fréquent, par exemple plusieurs fois par mois, sélectionnez la classe de stockage standard. Si seul un accès peu fréquent est requis, sélectionnez le stockage Nearline ou Coldline. Pour les données archivées, auxquelles vous ne pensez pas avoir à accéder, sélectionnez le stockage Archive.
Structure de répertoires SAP et options de stockage
Les tableaux suivants décrivent les structures de répertoires Linux pour les bases de données SAP HANA et les instances SAP ABAP sur Google Cloud.
Options de stockage recommandées pour la structure de répertoires Linux sur SAP HANA :
Répertoire SAP HANA Option de stockage recommandée dans Google Cloud /usr/sapDisque persistant avec équilibrage /hana/dataPersistent Disk ou Hyperdisk basé sur SSD /hana/logPersistent Disk ou Hyperdisk basé sur SSD /hana/shared*Disque persistant avec équilibrage /hanabackup*Disque persistant avec équilibrage Dans les déploiements distribués,
/hana/sharedet/hanabackuppeuvent également être montés en tant que systèmes de fichiers réseau à l'aide d'une solution NFS, telle que Filestore.Pour en savoir plus sur le stockage sur disque persistant certifié par SAP pour une utilisation avec SAP HANA, consultez la section Stockage sur disque persistant pour SAP HANA.
Options de stockage recommandées pour la structure de répertoires Linux sur l'instance SAP ABAP :
Annuaire Option de stockage recommandée dans Google Cloud /sapmnt†Disque persistant avec équilibrage /usr/sapDisque persistant avec équilibrage Dans les déploiements distribués,
/sapmntpeut également être monté en tant que système de fichiers réseau à l'aide d'une solution NFS, telle que Filestore.Pour plus d'informations sur le stockage sur disque persistant certifié par SAP pour une utilisation avec les instances SAP ABAP, consultez la section Stockage sur disque persistant pour les applications SAP.
Compatibilité des systèmes d'exploitation pour SAP S/4HANA
Lorsque vous choisissez un système d'exploitation (OS) pour SAP NetWeaver sur Google Cloud, vous devez non seulement vérifier que la version d'OS est certifiée par SAP, mais aussi confirmer que les trois sociétés (SAP, le fournisseur du système d'exploitation et Google Cloud) assurent toujours la compatibilité de cette version d'OS.
Votre décision doit également tenir compte des éléments suivants :
- Si une version d'OS donnée est disponible depuis Google Cloud. Les images d'OS fournies par Compute Engine sont configurées pour fonctionner avec Google Cloud. Si un système d'exploitation n'est pas proposé parGoogle Cloud, vous pouvez apporter votre propre image d'OS (BYOI) et votre propre licence (BYOL). Dans Compute Engine, les images d'OS BYOI sont appelées des images personnalisées.
- Les options d'attribution de licences disponibles pour une version d'OS donnée. Vérifiez si la version du système d'exploitation dispose d'une option d'attribution de licences à la demande ou si vous devez souscrire un abonnement BYOS (Bring Your Own Subscription) acquis auprès du fournisseur du système d'exploitation.
- Indique si les fonctionnalités intégrées de haute disponibilité d'une version d'OS donnée sont activées pour Google Cloud.
- L'option de remise sur engagement d'utilisation pour les images SLES pour SAP et RHEL pour SAP.
Les systèmes d'exploitation suivants sont certifiés par SAP pour une utilisation avec SAP NetWeaver sur Google Cloud:
Vous trouverez plus d'informations sur les versions de système d'exploitation spécifiques et leur compatibilité avec SAP S/4HANA et SAP HANA dans les guides suivants :
- Compatibilité des systèmes d'exploitation pour SAP NetWeaver sur Google Cloud
- Compatibilité des systèmes d'exploitation pour SAP HANA sur Google Cloud
Option de Fast Restart de SAP HANA
Pour SAP HANA 2.0 SP04 et versions ultérieures, Google recommande fortement l'option Fast Restart de SAP HANA.
Cette option est automatiquement activée lorsque vous déployez SAP HANA à l'aide des modules Terraform suivants fournis par Google Cloud: module sap_hana ou sap_hana_ha, version 202309280828 ou ultérieure. Pour en savoir plus sur l'activation manuelle du redémarrage rapide de SAP HANA, consultez la section Activer le redémarrage rapide de SAP HANA.
Le redémarrage rapide de SAP HANA réduit le temps de redémarrage en cas d'arrêt de SAP HANA, mais le système d'exploitation reste en cours d'exécution. Pour réduire le délai de redémarrage, SAP HANA utilise la fonctionnalité de mémoire persistante SAP HANA afin de conserver les fragments de données MAIN des tables de magasin de colonnes dans la mémoire DRAM mappée au système de fichiers tmpfs.
De plus, sur les VM des familles M2 et M3 des types de machines Compute Engine à mémoire optimisée, le redémarrage rapide de SAP HANA améliore la durée de récupération si des erreurs irréparables se produisent en mémoire. Pour en savoir plus, consultez la section Option Fast Restart pour SAP HANA.
Architecture de déploiement pour SAP HANA
SAP HANA est un composant clé de tout système SAP S/4HANA, car il sert de base de données pour le système. Vous pouvez utiliser deux architectures lors du déploiement de la base de données SAP HANA : scaling à la hausse et scaling horizontal.
Architecture de scaling vertical
Le schéma suivant illustre une architecture de scaling à la hausse pour SAP HANA surGoogle Cloud. Dans le diagramme, notez à la fois le déploiement surGoogle Cloud et l'organisation du disque. Vous pouvez utiliser Cloud Storage pour sauvegarder vos sauvegardes locales disponibles dans /hanabackup. La taille de cette installation doit être supérieure ou égale à celle de l'installation de données.

Architecture de scaling horizontal
L'architecture de scaling horizontal pour SAP HANA se compose d'un hôte maître, d'un certain nombre d'hôtes de calcul et, éventuellement, d'un ou plusieurs hôtes de secours. Les hôtes sont interconnectés via un réseau compatible avec l'envoi de données entre les hôtes à des débits pouvant atteindre 32 Gbit/s ou 100 Gbit/s sur les types de machines sélectionnés à l'aide de la mise en réseau à haut débit.
À mesure que la demande associée aux charges de travail augmente, en particulier lors de l'utilisation du traitement analytique en ligne (OLAP), une architecture à hôtes multiples et à évolutivité horizontale peut répartir la charge sur tous les hôtes.
Le schéma suivant illustre une architecture à évolutivité horizontale pour SAP HANA sur Google Cloud:

Architecture de déploiement pour SAP S/4HANA
Comme indiqué dans la section Architecture, vous pouvez utiliser plusieurs architectures de déploiement pour déployer SAP S/4HANA sur Google Cloud.
Architecture à deux niveaux
Cette architecture est présentée dans la section Déploiement centralisé. Le schéma suivant montre quelques informations propres à une architecture à deux niveaux pour SAP S/4HANA exécutée sur une VM Compute Engine :

Architecture à trois niveaux
Cette architecture est présentée dans la section Déploiement distribué. Vous pouvez utiliser cette architecture pour déployer des systèmes SAP S/4HANA à haute disponibilité. Le schéma suivant montre quelques informations propres à une architecture à trois niveaux pour SAP S/4HANA exécutée sur des VM Compute Engine :

Dans cette architecture, le système SAP S/4HANA répartit le travail entre plusieurs serveurs d'applications NetWeaver, chacun étant hébergé sur une VM distincte. Tous les nœuds des serveurs d'application de NetWeaver partagent la même base de données, qui est hébergée sur une VM distincte. Tous les nœuds des serveurs d'application de NetWeaver ont accès à un système de fichiers partagé sur lequel ils sont installés et qui héberge les profils SAP NetWeaver. Ce système de fichiers partagé est hébergé sur un volume de disque persistant partagé entre tous les nœuds ou sur une solution de partage de fichiers compatible.
Sécurité, confidentialité et conformité
Cette section fournit des informations sur la sécurité, la confidentialité et la conformité pour l'exécution de SAP S/4HANA sur Google Cloud.
Contrôles de conformité et de souveraineté
Si vous souhaitez que votre charge de travail SAP s'exécute conformément aux exigences liées à la résidence des données, au contrôle des accès, au personnel d'assistance ou à la réglementation, vous devez planifier l'utilisation d'Assured Workloads, un service qui vous permet d'exécuter des charges de travail sécurisées et conformes sans compromettre la qualité de votre expérience cloud. Google Cloud Pour en savoir plus, consultez la page Contrôles de conformité et de souveraineté pour SAP sur Google Cloud.
Mise en réseau et sécurité réseau
Tenez compte des informations fournies dans les sections suivantes lorsque vous planifiez la mise en réseau et la sécurité réseau.
Modèle de privilège minimum
L'une de vos premières lignes de défense consiste à limiter le nombre de personnes pouvant accéder à votre réseau et à vos VM. Pour ce faire, utilisez des règles de pare-feu VPC. Par défaut, tout le trafic vers les VM, même celui provenant d'autres VM, est bloqué par le pare-feu, sauf si vous créez des règles pour autoriser l'accès. La seule exception est le réseau par défaut créé automatiquement avec chaque projet, et pour lequel des règles de pare-feu sont créées par défaut.
En créant des règles de pare-feu VPC, vous pouvez limiter tout le trafic sur un ensemble de ports donné à des adresses IP source spécifiques. Pour limiter l'accès aux adresses IP, protocoles et ports spécifiques qui nécessitent un accès, suivez le principe du moindre privilège. Par exemple, vous devez toujours configurer un hôte bastion et autoriser les connexions SSH dans votre système SAP NetWeaver uniquement à partir de cet hôte.
Réseaux personnalisés et règles de pare-feu
Vous pouvez utiliser un réseau pour définir une adresse IP de passerelle et la plage de réseau des VM connectées à ce réseau. Tous les réseaux Compute Engine utilisent le protocole IPv4. Chaque projetGoogle Cloud est fourni avec un réseau par défaut avec des configurations et des règles de pare-feu prédéfinies. Cependant, nous vous recommandons d'ajouter un sous-réseau personnalisé et d'ajouter des règles de pare-feu basées sur un modèle de privilège minimal. Par défaut, un réseau nouvellement créé n'a pas de règles de pare-feu et donc pas d'accès au réseau.
Vous pouvez ajouter plusieurs sous-réseaux si vous souhaitez isoler des parties de votre réseau ou répondre à d'autres exigences. Pour en savoir plus, consultez la section Réseaux et sous-réseaux.
Les règles de pare-feu s'appliquent à l'ensemble du réseau et à toutes les VM du réseau. Vous pouvez ajouter une règle de pare-feu qui autorise le trafic entre les VM du même réseau et pour tous les sous-réseaux. Vous pouvez également configurer des pare-feu à appliquer à des VM cibles spécifiques à l'aide de tags réseau.
SAP nécessite l'accès à certains ports. Par conséquent, vous devrez ajouter des règles de pare-feu pour permettre l'accès aux ports indiqués par SAP.
Routes
Les routes sont des ressources globales associées à un seul réseau. Les routes créées par l'utilisateur s'appliquent à toutes les VM d'un réseau. Cela signifie que vous pouvez ajouter une route qui transfère le trafic d'une VM à une autre au sein du même réseau et entre sous-réseaux sans requérir d'adresses IP externes.
Pour un accès externe aux ressources Internet, lancez une VM sans adresse IP externe et configurez une autre VM en tant que passerelle NAT. Cette configuration nécessite que vous ajoutiez votre passerelle NAT en tant que route pour votre instance SAP.
Hôtes bastion et passerelles NAT
Si votre stratégie de sécurité requiert des VM véritablement internes, vous devez configurer manuellement un proxy NAT sur votre réseau et une route correspondante afin que les VM puissent accéder à Internet. Il est important de noter que vous ne pouvez pas vous connecter directement à une instance de VM entièrement interne à l'aide de SSH.
Pour ce faire, vous devez configurer une instance bastion dotée d'une adresse IP externe et vous en servir comme tunnel. Lorsque les VM n'ont pas d'adresses IP externes, elles ne peuvent être accessibles que par d'autres VM du réseau ou via une passerelle VPN gérée. Vous pouvez provisionner des VM pour votre réseau pour qu’elles agissent en tant que relais de confiance pour les connexions entrantes, appelées hôtes bastions, ou pour les sorties réseau, appelées passerelles NAT. Pour une connectivité plus transparente sans configurer de telles connexions, vous pouvez utiliser une ressource de passerelle VPN gérée.
Hôtes bastion pour les connexions entrantes
Les hôtes bastion constituent un point d'entrée externe dans un réseau contenant des VM de réseau privé. Cet hôte peut fournir un seul point de renforcement ou d'audit et peut être démarré et arrêté pour activer ou désactiver la communication SSH entrante à partir d'Internet.
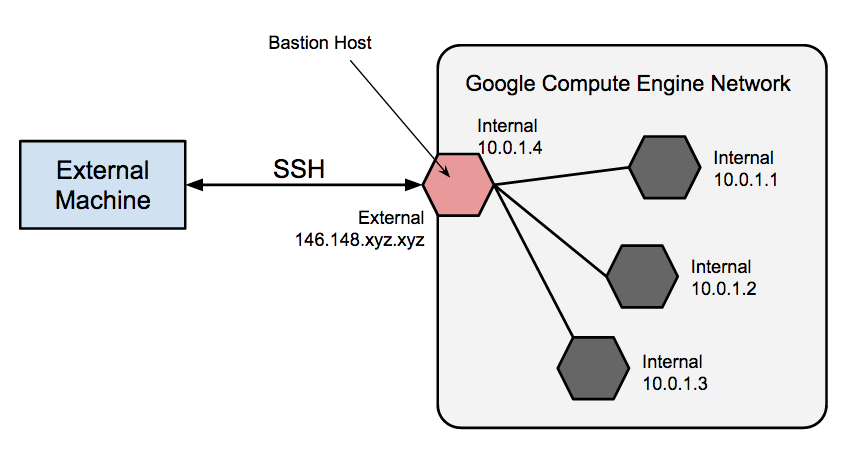
L'accès SSH aux VM n'ayant pas d'adresse IP externe peut être obtenu en vous connectant d'abord à un hôte bastion. Le renforcement complet d'un hôte bastion n'entre pas dans le cadre de ce document, mais vous pouvez effectuer les premières étapes suivantes :
- Limiter la plage CIDR d'adresses IP sources pouvant communiquer avec le bastion
- Configurer des règles de pare-feu qui autorisent uniquement le trafic SSH provenant de l'hôte bastion vers des VM privées
Par défaut, SSH sur les VM est configuré pour utiliser des clés privées pour l'authentification. Lorsque vous utilisez un hôte bastion, vous devez d'abord vous connecter à l'hôte bastion, puis à votre VM privée cible. En raison de cette connexion en deux étapes, nous vous recommandons d'utiliser le transfert d'agent SSH pour atteindre la VM cible au lieu de stocker la clé privée de la VM cible sur l'hôte bastion. Vous devez procéder ainsi même si vous utilisez la même paire clé/valeur pour les VM cibles et le bastion, car le bastion a un accès direct uniquement à la moitié publique de la paire de clés.
Passerelles NAT pour le transfert de données sortantes
Lorsqu'une VM n'a pas d'adresse IP externe attribuée, elle ne peut pas établir de connexions directes avec des services externes, y compris d'autres Google Cloud services. Pour permettre à ces VM d'accéder aux services sur Internet, vous pouvez mettre en place et configurer une passerelle NAT. La passerelle NAT est une VM pouvant acheminer le trafic pour le compte de toute autre VM du réseau. Utilisez une passerelle NAT par réseau. Une passerelle NAT à VM unique n'est pas hautement disponible et n'est pas en mesure d'accepter un débit élevé pour plusieurs VM. Pour en savoir plus sur la configuration d'une VM en tant que passerelle NAT, consultez le guide de déploiement correspondant à votre système d'exploitation :
Cloud VPN
Vous pouvez connecter de manière sécurisée votre réseau existant à Google Cloud via une connexion VPN avec IPsec en utilisant Cloud VPN. Le trafic échangé entre les deux réseaux est chiffré par une passerelle VPN, puis déchiffré par l'autre passerelle VPN, ce qui les protège lors des transferts via Internet. Vous pouvez contrôler de manière dynamique quelles sont les VM qui peuvent envoyer du trafic via le VPN à l'aide de tags d'instance sur les routes. Les tunnels Cloud VPN sont facturés à un tarif mensuel fixe, majoré des frais standards pour le transfert de données sortant. Notez que la connexion de deux réseaux d'un même projet entraîne toujours des frais standards pour le transfert de données sortant. Pour en savoir plus, consultez cette page :
Sécurité pour les buckets Cloud Storage
Si vous utilisez Cloud Storage pour héberger les sauvegardes de vos données et journaux, assurez-vous d'utiliser TLS (HTTPS) lors de l'envoi de données à Cloud Storage à partir de vos VM, afin de protéger les données en transit.
Bien que Cloud Storage chiffre automatiquement les données au repos, vous pouvez spécifier vos propres clés de chiffrement si vous disposez de votre propre système de gestion de clés.
Limites des notifications par e-mail
Pour protéger vos systèmes et Google contre les utilisations abusives, Google Cloud impose des limites concernant l'envoi d'e-mails depuis Compute Engine. Cela a des conséquences sur la transaction SCOT sur les systèmes ABAP SAP NetWeaver, car elle nécessite une configuration spécifique par rapport aux systèmes sur site.
Pour en savoir plus, y compris sur la configuration de SCOT, consultez la page Envoyer des e-mails depuis une instance.
Documents de sécurité associés
Pour en savoir plus sur les ressources de sécurité pour votre environnement SAP surGoogle Cloud, consultez les ressources suivantes:
- Se connecter en toute sécurité aux instances de VM
- Centre de sécurité
- Conformité dans Google Cloud
- Présentation de la sécurité Google
- PDF Présentation de la sécurité sur l'infrastructure de Google
Fiabilité
Cette section fournit des informations sur les aspects liés à la fiabilité pour l'exécution de SAP S/4HANA sur Google Cloud.
Haute disponibilité et reprise après sinistre
La haute disponibilité et la reprise après sinistre sont des ensembles de techniques, de pratiques d'ingénierie et de principes de conception qui permettent d'assurer la continuité des activités en cas d'échec. Ces approches fonctionnent en éliminant les points de défaillance isolés et en offrant la possibilité de reprendre rapidement les opérations après une panne du système ou des composants avec un minimum de perturbation des activités. La reprise après sinistre correspond au processus de récupération et de reprise des opérations après une panne due à un composant défaillant.
Par exemple, voici quelques outils de haute disponibilité et de reprise après sinistre que vous pouvez utiliser :
- Clustering Linux entre les zones: pour en savoir plus, consultez le Guide de planification de la haute disponibilité pour SAP NetWeaver sur Google Cloud et le Guide de planification de la haute disponibilité SAP HANA.
- Migration à chaud
- Stratégie de maintenance de l'hôte de VM
- Redémarrage automatique du service
- Sauvegardes
Clustering Linux sur plusieurs zones : la configuration de votre cluster Linux sur plusieurs zones permet d'éviter les défaillances de composants dans une région donnée.
Sur la couche d'application SAP NetWeaver, vous pouvez déployer un cluster Linux sur plusieurs zones afin de réduire l'impact d'une défaillance sur le système ASCS et de le rendre hautement disponible sur les deux nœuds dans différentes zones. Le cluster Linux déplace ensuite le serveur ASCS vers le nœud de secours en cas de problème avec le nœud principal ou si des opérations de maintenance sont en cours. Vous pouvez également utiliser un serveur de réplication de mise en file d'attente pour répliquer le contenu de la table de mise en file d'attente afin qu'il conserve le contenu de la table de mise en file d'attente sur le nœud de secours au cas où le processus passerait du nœud principal au nœud de secours.
Sur la couche de base de données SAP HANA, vous pouvez déployer un cluster Linux sur plusieurs zones à l'aide d'une configuration en mode actif/passif ou d'une configuration en mode actif/actif. Dans les deux cas, vous commencez par configurer deux instances Compute Engine dans des zones distinctes, chacune avec sa propre base de données SAP HANA.
- Configuration en mode actif/passif : configurez une instance en tant que nœud principal du cluster (actif) et l'autre en tant que nœud secondaire (passif). Utilisez la réplication du système SAP HANA pour configurer le nœud secondaire en tant qu'instance principale en cas de défaillance du nœud principal. Pour en savoir plus sur la configuration de la réplication du système HANA, consultez la page sur la réplication du système HANA.
- Configuration du mode actif/actif (activé en lecture) : configurez les deux instances pour qu'elles soient actives, mais le nœud secondaire en lecture seule. Cette configuration est basée sur la relecture continue du journal. L'adresse IP virtuelle (VIP) est configurée pour pointer vers le nœud de lecture/écriture actuel. Pour en savoir plus, consultez la page Active/Active (Read Enabled).
Il est également possible d'utiliser la réplication du système SAP HANA comme solution de reprise après sinistre. La base de données principale réplique son contenu dans la base de données de secours, qui peut être utilisée en cas de déconnexion de la base de données principale, ce qui permet au système SAP de continuer à fonctionner jusqu'à la restauration du service sur la base de données principale. Dans ce cas, la promotion du nœud secondaire ne s'effectue pas automatiquement ; elle doit être effectuée manuellement. Vous pouvez également combiner haute disponibilité et reprise après sinistre côté SAP HANA pour augmenter la résilience et la disponibilité. Pour en savoir plus, consultez cette page :
Migration à chaud : Compute Engine propose une migration à chaud pour que vos instances de VM s'exécutent même en cas d'événement du système hôte, tel qu'une mise à jour logicielle ou matérielle. Dans ce cas, Compute Engine effectue une migration à chaud de votre instance en cours d'exécution vers un autre hôte de la même zone, au lieu de nécessiter un redémarrage de votre instance en cours d'exécution. Ce mécanisme réplique l'état de la VM de l'instance d'origine. Ainsi, lorsque la nouvelle instance s'affiche, la mémoire de l'instance d'origine est déjà préchargée.
Dans les rares cas où la migration à chaud ne se produit pas, la machine virtuelle défaillante est automatiquement redémarrée sur le nouveau matériel dans la même zone. Pour en savoir plus, consultez la section Processus de migration à chaud lors des événements de maintenance.
Optimisation des coûts
Cette section fournit des informations sur les licences, les remises et l'estimation de la taille des charges de travail.
Licences
Si vous êtes client de SAP, vous pouvez utiliser votre licence existante pour déployer SAP S/4HANA sur Google Cloud dans le cadre d'un modèle BYOL (Bring Your Own License, utilisation de votre propre licence). Google Cloud accepte le modèle BYOL pour les cas d'utilisation de production et hors production. Les licences de système d'exploitation sont incluses dans les tarifs Compute Engine.
Vous pouvez également apporter votre propre image d'OS et vos propres licences. Pour en savoir plus, consultez la section Images d'OS personnalisées.
Remises
Avec le modèle de paiement à l'usage de Google Cloud, vous ne payez que pour les services que vous utilisez. Vous n'avez pas besoin de vous engager sur une taille ou un service particulier ; vous pouvez modifier ou arrêter votre utilisation si nécessaire. Pour les charges de travail prévisibles, Compute Engine propose des remises sur engagement d'utilisation (CUD) qui permettent de réduire le coût de votre infrastructure en souscrivant un contrat en échange de remises conséquentes sur l'utilisation des VM.
Google Cloud offre ces remises en échange de la souscription de contrats d'engagement d'utilisation, également appelés engagements. Lorsque vous souscrivez un engagement, vous vous engagez soit à une quantité minimale d'utilisation des ressources, soit à un montant minimal de dépenses pour une durée déterminée de un ou trois ans. Ces remises vous permettent de réduire votre facture mensuelle pour les ressources utilisées par votre système SAP S/4HANA. Pour en savoir plus, consultez la section Remises sur engagement d'utilisation.
Estimations de taille
Les ressources suivantes fournissent des informations sur la façon d'estimer la taille de vos systèmes SAP avant de les migrer vers Google Cloud:
- Examiner le dimensionnement des charges de travail SAP
- Estimer les coûts liés à l'infrastructure pour votre charge de travail SAP
Efficacité opérationnelle
Cette section fournit des informations sur la façon d'optimiser l'efficacité opérationnelle de SAP S/4HANA sur Google Cloud.
Sauvegarde et récupération
Créez régulièrement des sauvegardes de votre serveur d'applications et de votre base de données afin de pouvoir les récupérer en cas de panne du système, de corruption de données ou de tout autre problème.
Vous disposez de plusieurs options pour sauvegarder vos données SAP HANA sur Google Cloud, y compris les suivantes:
- Effectuez une sauvegarde à l'aide du service de sauvegarde et de reprise après sinistre de Google. Pour en savoir plus, consultez la section Sauvegarder une base de données SAP HANA découverte et ses journaux.
- Effectuez une sauvegarde directe sur Cloud Storage à l'aide de la fonctionnalité Backint de l'agent Google Cloudpour SAP certifiée SAP.
- Effectuez une sauvegarde sur un disque, puis importer les sauvegardes sur Cloud Storage.
- Sauvegardez des disques à l'aide d'instantanés.
Sauvegarder dans Cloud Storage
À partir de la version 3.0,l'agent Google Cloudpour SAP est compatible avec la fonctionnalité Backint, qui permet à SAP HANA de sauvegarder et de récupérer des sauvegardes de base de données directement à partir de Cloud Storage. Cette nouvelle fonctionnalité est disponible pour les instances SAP HANA exécutées sur des instances de VM Compute Engine, des serveurs de solution Bare Metal, des serveurs sur site ou d'autres plates-formes cloud pour que vous puissiez sauvegarder et récupérer directement depuis et vers Cloud Storage sans nécessiter de stockage sur disque persistant pour vos sauvegardes. Pour en savoir plus, consultez le guide d'utilisation de SAP HANA.
Pour en savoir plus sur la certification SAP de cette fonctionnalité de l'agent, consultez la note SAP 2031547 - Overview of SAP-certified 3rd party backup tools and associated support process.
Le schéma suivant illustre le déroulement des sauvegardes lorsque vous utilisez la fonctionnalité Backint de l'agent Google Cloudpour SAP:

Sauvegarder sur des disques
Vous pouvez utiliser la fonction de sauvegarde et de récupération SAP HANA native avec des volumes Persistent Disk et utiliser un bucket Cloud Storage pour le stockage à long terme des sauvegardes.
En cours de fonctionnement normal, SAP HANA enregistre automatiquement les données de la mémoire sur le disque à des points de sauvegarde réguliers. En outre, toutes les modifications de données sont enregistrées dans les entrées du journal de rétablissement. Une entrée de journal de rétablissement est écrite sur le disque après chaque transaction de base de données validée.
À partir de SAP HANA 2.0 et versions ultérieures, créez des sauvegardes SAP HANA à l'aide de SAP HANA Cockpit.
Le schéma suivant illustre le déroulement de la fonctionnalité de sauvegarde pour SAP HANA :

Sauvegarder des disques en utilisant des instantanés
Une autre option que vous pouvez ajouter à votre stratégie de sauvegarde consiste à réaliser des instantanés de disques entiers à l'aide de la fonctionnalité d'instantané de disque persistant de Compute Engine. Par exemple, vous pouvez réaliser des instantanés planifiés du disque hébergeant votre répertoire /hanabackup pour les utiliser dans des scénarios de reprise après sinistre. Vous pouvez également utiliser des instantanés de disque pour sauvegarder et récupérer votre volume de données SAP HANA. Pour assurer la cohérence des applications, réalisez des instantanés lorsqu'aucune modification n'est apportée au volume cible. Les instantanés sont réalisés au niveau du bloc.
Après le premier instantané, chaque instantané suivant est incrémentiel et ne stocke que les modifications de bloc incrémentielles, comme illustré dans le schéma suivant.
Lorsque vous utilisez la version 3.0 ou une version ultérieure de l'agent Google Cloudpour SAP, vous pouvez créer des sauvegardes et effectuer une récupération pour SAP HANA à l'aide de la fonctionnalité d'instantané de disque de l'agent. Pour en savoir plus, consultez la section Sauvegarde et récupération de SAP HANA à l'aide d'instantanés de disque.

Récupération
Les outils de récupération dans SAP HANA peuvent récupérer les données au dernier moment possible ou à un moment précis. Vous pouvez utiliser ces outils pour restaurer un nouveau système ou créer une copie de la base de données. Contrairement aux sauvegardes que vous pouvez exécuter lorsque la base de données est opérationnelle, vous ne pouvez utiliser les outils de récupération que lorsque la base de données est fermée. Vous pouvez choisir l'une des options suivantes :
- Restauration des données vers l'état le plus récent à l'aide de l'une des ressources suivantes :
- Sauvegarde complète ou instantané
- Sauvegardes de journaux
- Entrées du journal de rétablissement encore disponibles
- Restauration des données vers un moment donné dans le passé
- Restauration des données vers une sauvegarde complète spécifiée
Surveillance
Pour surveiller et fournir une assistance pour les charges de travail SAP exécutées sur des instances de VM Compute Engine et des serveurs de solution Bare Metal,Google Cloud fournit l'agent pour SAP.
Conformément à la demande de SAP, vous devez installer l'agentGoogle Cloudpour SAP sur toutes les instances de VM Compute Engine et tous les serveurs de solution Bare Metal qui exécutent un système SAP afin de bénéficier de l'assistance de SAP et de permettre à SAP de respecter ses contrats de niveau de service. Pour en savoir plus sur les conditions préalables à l'assistance, consultez la note SAP 2456406 - SAP on Google Cloud Platform: Support Prerequisites .
En plus de la collecte obligatoire des métriques de l'agent hôte SAP, sous Linux, l'agentGoogle Cloudpour SAP inclut des fonctionnalités facultatives telles que la collecte des métriques de surveillance des processus et les métriques d'évaluation du gestionnaire de charges de travail. Vous pouvez activer ces fonctionnalités pour activer des produits et des services, tels que la gestion des charges de travail, pour vos charges de travail SAP.
Optimisation des performances
Cette section fournit des informations sur l'optimisation des performances des charges de travail SAP S/4HANA via le dimensionnement et la configuration du réseau.
Dimensionnement
Plusieurs options de dimensionnement sont disponibles en fonction du type d'implémentation. Pour les implémentations de type Greenfield, nous vous recommandons d'utiliser l'outil SAP Quick Sizer. Pour plus d'informations, accédez à la page Sizing du site Web de SAP. SAP fournit également des guides de type "tailles de tee-shirt" pour des solutions spécifiques et des outils permettant la migration des solutions sur site actuelles vers Google Cloud. Par exemple, consultez le répertoire matériel SAP HANA certifié et compatible et la note SAP 2456432 - Applications SAP sur Google Cloud: produits et types de machines Google Cloud compatibles. SAP et Google Cloud utilisent des unités différentes pour mesurer les IOPS (opérations d'entrée/de sortie par seconde). Consultez votre partenaire intégrateur de systèmes pour convertir les exigences de dimensionnement SAP en une infrastructure Google Cloud de taille appropriée.
Avant de migrer des systèmes existants de SAP ECC vers S/4HANA, SAP vous recommande d'exécuter le rapport/SDF/HDB_SIZING, comme décrit dans la note SAP 1872170 - Rapport de dimensionnement ABAP sur HANA (S/4HANA, Suite sur HANA...).
Ce rapport de dimensionnement analyse les besoins actuels en mémoire et en traitement de votre système source, et fournit des informations sur les conditions requises pour passer à S/4HANA.
Configuration du réseau
Les fonctionnalités réseau de votre VM Compute Engine sont déterminées par sa famille de machines, et non par son interface réseau (NIC) ou son adresse IP.
En fonction de son type de machine, votre instance de VM accepte un débit réseau de 2 à 32 Gbit/s. Certains types de machines acceptent également des débits jusqu'à 100 Gbit/s, qui nécessitent l'utilisation du type d'interface NIC (Virtual Virtual NIC) de Google avec une configuration réseau de niveau 1. La capacité à atteindre ces débits dépend davantage du sens du trafic et du type d'adresse IP de destination.
Les interfaces réseau de VM Compute Engine s'appuient sur une infrastructure réseau redondante et résiliente à l'aide de composants réseau physiques et définis par logiciel. Ces interfaces héritent de la redondance et de la résilience de la plate-forme sous-jacente. Vous pouvez utiliser plusieurs cartes d'interface réseau virtuelles pour séparer le trafic, mais cela n'offre aucun avantage supplémentaire en termes de résilience ou de performances.
Une carte d'interface réseau unique fournit les performances nécessaires pour les déploiements SAP HANA sur Compute Engine. Votre cas d'utilisation, vos exigences de sécurité ou vos préférences spécifiques peuvent également nécessiter des interfaces supplémentaires pour séparer le trafic, tel que le trafic Internet, le trafic interne de réplication du système SAP HANA ou d'autres flux pouvant tirer avantage de règles de stratégie de réseau spécifiques. Pour limiter l'accès, nous vous recommandons d'utiliser le chiffrement du trafic proposé par l'application et de sécuriser l'accès réseau en suivant une stratégie de pare-feu selon le principe du moindre privilège.
Tenez compte de la nécessité de séparer le trafic dès le début de la conception de votre réseau et d'allouer des cartes d'interface réseau supplémentaires lorsque vous déployez des VM. Vous devez associer chaque interface réseau à un réseau VPC différent. Le choix du nombre d'interfaces réseau dépend du niveau d'isolation requis, avec jusqu'à huit interfaces autorisées pour les VM comportant au moins huit processeurs virtuels.
Par exemple, vous pouvez définir un réseau VPC pour vos clients d'applications SQL SAP HANA, tels que des serveurs d'applications SAP NetWeaver et des applications personnalisées, ainsi qu'un réseau VPC distinct pour le trafic interserveur, tel que la réplication du système SAP HANA. Notez qu'un trop grand nombre de segments peut compliquer la gestion et le dépannage des problèmes de réseau. Si vous changez d'avis ultérieurement, vous pouvez utiliser des images système Compute Engine pour recréer votre instance de VM tout en conservant toutes les configurations, métadonnées et données associées.Pour en savoir plus, consultez cette page :
Déploiement
Cette section fournit des informations sur le déploiement de SAP S/4HANA sur Google Cloud.
Notes SAP importantes concernant le prédéploiement
Avant de commencer à déployer un système SAP S/4HANA sur Google Cloud, lisez les notes SAP suivantes. De plus, avant de commencer toute implémentation de SAP, consultez SAP Marketplace pour obtenir des notes et des guides d'installation du produit mis à jour.
- Note SAP 2456432 - Applications SAP sur Google Cloud: produits et types de machines Google Cloud compatibles
- 2446441 - Linux on Google Cloud (IaaS): Adaption of your SAP License
- 2456953 - Windows sur Google Cloud (IaaS): adaptation de votre licence SAP
- 1380654 - Assistance SAP dans des environnements cloud public
- Note SAP 2456406 – SAP sur Google Cloud Platform: prérequis pour l'assistance
Automatisation des déploiements
Pour installer SAP S/4HANA sur Google Cloud, vous pouvez utiliser les options de déploiement suivantes:- Pour automatiser le déploiement d'un système distribué ou distribué avec une haute disponibilité, vous pouvez utiliser l'outil Automatisation guidée du déploiement dans le gestionnaire de charges de travail. Cet outil vous permet de configurer et de déployer des charges de travail SAP compatibles directement à partir de la console Google Cloud , ou de générer et de télécharger le code Terraform et Ansible équivalent. Pour en savoir plus, consultez la page À propos de l'automatisation guidée du déploiement.
- Pour automatiser le déploiement d'un système SAP HANA centralisé ou distribué, vous pouvez utiliser les configurations Terraform fournies par Google Cloud. Pour en savoir plus, consultez le guide de déploiement correspondant à votre scénario SAP HANA.
Étape suivante
- En savoir plus sur les Google Cloud services utilisés dans ce guide :
- Pour découvrir d'autres architectures de référence, guides de conception et bonnes pratiques, consultez le Cloud Architecture Center.