Cette page fait référence au paramètre
typequi fait partie d'une mesure.
typepeut également être utilisé dans une dimension ou un filtre, décrit sur la page de documentation Dimension, filtre et types de paramètres.
typepeut également être utilisé dans un groupe de dimensions, comme décrit sur la page de documentation sur les paramètresdimension_group.
Utilisation
measure: champ_nom {
type: measure_field_type
}
}
|
Hiérarchie
type |
Types de champs possibles
MesurerAcceptation
Un type de mesure |
Cette page contient des informations sur les différents types pouvant être attribués à une mesure. Une mesure ne peut comporter qu'un seul type, et la valeur par défaut est string si aucun type n'est spécifié.
Certains types de mesures sont associés à des paramètres qui sont décrits dans la section appropriée.
Mesurer des catégories de types
Chaque type de mesure appartient à l'une des catégories suivantes. Ces catégories déterminent si le type de mesure effectue des agrégations, le type de champs que le type de mesure peut référencer et si vous pouvez filtrer le type de mesure à l'aide du paramètre filters:
- Mesures agrégées: les mesures agrégées effectuent des agrégations, telles que
sumetaverage. Les mesures agrégées ne peuvent faire référence qu'aux dimensions, et non à d'autres mesures. Il s'agit du seul type de mesure compatible avec le paramètrefilters. - Mesures non agrégées: comme leur nom l'indique, les mesures non globales sont des types qui n'effectuent pas d'agrégation, tels que
numberetyesno. Ces types de mesure effectuent des transformations simples et, comme ils n'effectuent pas d'agrégations, ne peuvent référencer que des mesures agrégées ou des dimensions précédemment agrégées. Vous ne pouvez pas utiliser le paramètrefiltersavec ces types de mesures. - Mesures post-SQL : les mesures post-SQL sont des types de mesure spéciaux qui effectuent des calculs spécifiques après que Looker a généré les requêtes SQL. Ils ne peuvent faire référence qu'à des mesures ou dimensions numériques. Vous ne pouvez pas utiliser le paramètre
filtersavec ces types de mesures.
Liste des définitions de types
| Type | Catégorie | Description |
|---|---|---|
average |
Agrégation | Génère une moyenne (moyenne) des valeurs dans une colonne |
average_distinct |
Agrégation | Lorsqu'elle utilise des données dénormalisées, elle génère correctement (moyennement) des valeurs. Pour une description complète, consultez la définition ci-dessous. |
count |
Agrégation | Génère un nombre de lignes |
count_distinct |
Agrégation | Génère un nombre de valeurs uniques dans une colonne |
date |
Non agrégés | Pour les mesures contenant des dates |
list |
Agrégation | Génère une liste des valeurs uniques dans une colonne |
max |
Agrégation | Génère la valeur maximale d'une colonne |
median |
Agrégation | Génère la médiane (valeur du point médian) des valeurs d'une colonne |
median_distinct |
Agrégation | Générer correctement une médiane (valeur de point médian) des valeurs lorsqu'une jointure provoque une distribution ramifiée. Pour une description complète, consultez la définition ci-dessous. |
min |
Agrégation | Génère la valeur minimale dans une colonne |
number |
Non agrégés | Pour les mesures contenant des chiffres |
percent_of_previous |
Post-SQL | Génère la différence en pourcentage entre les lignes affichées |
percent_of_total |
Post-SQL | Génère le pourcentage du total pour chaque ligne affichée |
percentile |
Agrégation | Génère la valeur au centile spécifié dans une colonne |
percentile_distinct |
Agrégation | Lorsqu'une jointure provoque une distribution ramifiée, la valeur est correctement générée au centile spécifié. Pour une description complète, consultez la définition ci-dessous. |
running_total |
Post-SQL | Génère le total cumulé pour chaque ligne affichée |
string |
Non agrégés | Pour les mesures contenant des lettres ou des caractères spéciaux (comme avec la fonction GROUP_CONCAT de MySQL) : |
sum |
Agrégation | Génère une somme de valeurs dans une colonne |
sum_distinct |
Agrégation | Lorsqu'elle utilise des données dénormalisées, elle génère une somme de valeurs appropriée. Consultez la définition ci-dessous pour obtenir une description complète. |
yesno |
Non agrégés | Pour les champs qui s'affichent si une information est vraie ou fausse |
int |
Non agrégés |
REMOVED 5.4
Remplacer par type: number |
average
type: average calcule la moyenne des valeurs d'un champ donné. Elle est semblable à la fonction AVG de SQL. Toutefois, contrairement à l'écriture en SQL brut, Looker calcule correctement les moyennes, même si les jointures de votre requête contiennent des distributions ramifiées.
Le paramètre sql pour les mesures type: average peut prendre n'importe quelle expression SQL valide générant une colonne de tableau numérique, une dimension LookML ou une combinaison de dimensions LookML.
Vous pouvez mettre en forme les champs type: average à l'aide des paramètres value_format ou value_format_name.
Par exemple, le modèle LookML suivant crée un champ appelé avg_order en faisant la moyenne de la dimension sales_price, puis l'affiche au format monétaire (1 234,56 $):
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct est destiné aux ensembles de données dénormalisés. Il calcule la moyenne des valeurs non répétées d'un champ donné, en fonction des valeurs uniques définies par le paramètre sql_distinct_key.
Ce concept avancé peut être expliqué plus clairement à l'aide d'un exemple. Prenons l'exemple d'une table dénormalisée comme celle-ci:
| ID de l'élément de campagne | ID de commande | Expédition commande |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20 |
| 4 | 2 | 20 |
| 5 | 2 | 20 |
Dans ce cas, vous pouvez voir qu'il y a plusieurs lignes pour chaque commande. Par conséquent, si vous ajoutez une mesure type: average simple pour la colonne order_shipping, vous obtenez une valeur de 16,00, même si la moyenne réelle est de 15,00.
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
Pour obtenir un résultat précis, vous pouvez expliquer à Looker comment identifier chaque entité unique (dans ce cas, chaque ordre unique) à l'aide du paramètre sql_distinct_key. Cela calcule le montant correct de 15 €:
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Notez que chaque valeur unique de sql_distinct_key ne doit avoir qu'une seule valeur correspondante dans sql. En d'autres termes, l'exemple ci-dessus fonctionne parce que chaque ligne avec un order_id de 1 a le même order_shipping de 10.00, chaque ligne avec un order_id de 2 a le même order_shipping de 20.00, etc.
Vous pouvez mettre en forme les champs type: average_distinct à l'aide des paramètres value_format ou value_format_name.
count
type: count effectue un décompte de table, semblable à la fonction COUNT de SQL. Toutefois, contrairement à l'écriture en SQL brut, Looker calcule correctement les nombres même si les jointures de votre requête contiennent des distributions ramifiées.
Les mesures type: count ne sont pas compatibles avec le paramètre sql, car une mesure type: count effectue le nombre de tables en fonction de la clé primaire de la table. Si vous souhaitez effectuer un nombre de tables sur un champ autre que la clé primaire de la table, utilisez une mesure type: count_distinct.
Par exemple, le LookML suivant crée un champ number_of_products:
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
Il est très courant de fournir un paramètre drill_fields (pour les champs) lorsque vous définissez une mesure type: count afin que les utilisateurs puissent voir les enregistrements individuels qui sont comptabilisés lorsqu'ils cliquent dessus.
Lorsque vous utilisez une mesure de
type: countdans une exploration, la visualisation libelle les valeurs obtenues avec le nom de la vue plutôt que le mot "Nombre". Pour éviter toute confusion, nous vous recommandons de donner un nom à votre vue au pluriel, de sélectionner Afficher le nom complet du champ sous Série dans les paramètres de visualisation ou d'utiliser un nom de versionview_labelavec une version au pluriel.
Si vous souhaitez effectuer une opération COUNT (et non une opération COUNT_DISTINCT) sur un champ qui n'est pas la clé primaire, vous pouvez utiliser une mesure de type: number. Pour en savoir plus, consultez l'article du centre d'aide Différence entre les types de mesure count et count_distinct.
Vous pouvez ajouter un filtre à une mesure de type: count à l'aide du paramètre filters.
count_distinct
type: count_distinct calcule le nombre de valeurs distinctes dans un champ donné. Il utilise la fonction COUNT DISTINCT de SQL.
Le paramètre sql pour les mesures type: count_distinct peut utiliser n'importe quelle expression SQL valide ayant pour résultat une colonne de tableau, une dimension LookML ou une combinaison de dimensions LookML.
Par exemple, l'élément LookML suivant crée un champ number_of_unique_customers, qui comptabilise le nombre de numéros client uniques:
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
Vous pouvez ajouter un filtre à une mesure de type: count_distinct à l'aide du paramètre filters.
date
type: date est utilisé avec des champs contenant des dates.
Le paramètre sql pour les mesures type: date peut utiliser n'importe quelle expression SQL valide renvoyant une date. En pratique, ce type est rarement utilisé, car la plupart des fonctions d'agrégation SQL ne renvoient pas de dates. Les MIN ou les MAX sont des exceptions courantes pour les dimensions de date.
Créer une mesure de date maximale ou minimale avec type: date
Si vous souhaitez créer une mesure d'une date maximale ou minimale, vous pourriez commencer par penser à utiliser une mesure de type: max ou de type: min. Toutefois, ces types de mesures ne sont compatibles qu'avec les champs numériques. À la place, vous pouvez capturer une date maximale ou minimale en définissant une mesure de type: date et en encapsulant le champ de date référencé dans le paramètre sql dans une fonction MIN() ou MAX().
Supposons que vous ayez un groupe de dimensions de type: time appelé updated :
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
Vous pouvez créer une mesure de type: date pour capturer la date maximale de ce groupe de dimensions comme suit:
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
Dans cet exemple, au lieu d'utiliser une mesure type: max pour créer la mesure last_updated_date, la fonction MAX() est appliquée au paramètre sql. Le paramètre convert_tz est également défini sur no pour la mesure last_updated_date afin d'éviter les doubles fuseaux horaires dans la mesure, car la conversion du fuseau horaire a déjà été définie dans le groupe de dimensions updated. Pour en savoir plus, consultez la documentation sur le paramètre convert_tz.
Dans l'exemple LookML pour la mesure last_updated_date, type: date peut être omis et la valeur traitée comme une chaîne, car string est la valeur par défaut pour type. Toutefois, si vous utilisez type: date, vous bénéficierez de meilleures fonctionnalités de filtrage pour les utilisateurs.
Notez également que la définition de la mesure last_updated_date fait référence à la période ${updated_raw} au lieu de la période ${updated_date}. La valeur renvoyée par ${updated_date} étant une chaîne, vous devez utiliser ${updated_raw} pour référencer la valeur de date réelle à la place.
Vous pouvez également utiliser le paramètre datatype avec type: date pour améliorer les performances des requêtes en spécifiant le type de données de date utilisées par votre table de base de données.
Créer une mesure maximale ou minimale pour une colonne date/heure
Le calcul du maximum pour une colonne type: datetime est légèrement différent. Dans ce cas, vous souhaitez créer une mesure sans déclarer le type suivant:
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list crée une liste des valeurs distinctes d'un champ donné. Elle est semblable à la fonction GROUP_CONCAT de MySQL.
Vous n'avez pas besoin d'inclure de paramètre sql pour les mesures type: list. Utilisez plutôt le paramètre list_field pour spécifier la dimension à partir de laquelle vous voulez créer des listes.
L'utilisation est la suivante:
measure: nom_champ {
type: list
list_field: my_field_name
}
}
Par exemple, le LookML suivant crée une mesure name_list basée sur la dimension name:
measure: name_list {
type: list
list_field: name
}
Notez les points suivants pour list:
- Le type de mesure
listn'est pas compatible avec le filtrage. Vous ne pouvez pas utiliser le paramètrefilterssur une mesuretype: list. - Le type de mesure
listne peut pas être référencé à l'aide de l'opérateur de substitution ($). Vous ne pouvez pas utiliser la syntaxe${}pour faire référence à une mesuretype: list.
Dialectes de base de données compatibles avec list
Pour que Looker soit compatible avec type: list dans votre projet Looker, le dialecte de votre base de données doit également être compatible. Le tableau suivant présente les dialectes compatibles avec type: list dans la dernière version de Looker:
max
type: max recherche la valeur la plus élevée dans un champ donné. Il utilise la fonction MAX de SQL.
Le paramètre sql pour les mesures de type: max peut utiliser n'importe quelle expression SQL valide générant une colonne de tableau numérique, une dimension LookML ou une combinaison de dimensions LookML.
Étant donné que les mesures de type: max ne sont compatibles qu'avec des champs numériques, vous ne pouvez pas utiliser une mesure de type: max pour trouver une date maximale. À la place, vous pouvez utiliser la fonction MAX() dans le paramètre sql d'une mesure de type: date pour capturer une date maximale, comme indiqué précédemment dans les exemples de la section date.
Vous pouvez mettre en forme les champs type: max à l'aide des paramètres value_format ou value_format_name.
Par exemple, le modèle LookML suivant crée un champ appelé largest_order en examinant la dimension sales_price, puis l'affiche au format monétaire (1 234,56 $):
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
Actuellement, vous ne pouvez pas utiliser de mesures type: max pour des chaînes ou des dates, mais vous pouvez ajouter manuellement la fonction MAX pour créer un champ de ce type:
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median renvoie la valeur du point médian des valeurs d'un champ donné. Cela est particulièrement utile lorsque les données comportent quelques anomalies de très grande taille ou de petite taille qui fausseraient une moyenne simple (moyenne).
Prenons l'exemple d'un tableau comme celui-ci:
ID d'article de commande | Coût | Point médian ? -------------:|--------------: 2 | 10,00 | 4 | 10,00 | 3 | 20,00 | Valeur du point médian 1 | 80,00 | 5 | 90,00
Pour faciliter la lecture, la table est triée par coût, mais cela n'affecte pas le résultat. Alors que le type average renvoie 42 (en ajoutant toutes les valeurs et en les divisant par 5), le type median renvoie la valeur du point intermédiaire: 20.
S'il existe un nombre pair de valeurs, la valeur médiane est calculée en prenant la moyenne des deux valeurs les plus proches du point médian. Prenons l'exemple d'une table comportant un nombre pair de lignes:
ID d'article de commande | Coût | Point médian ? -------------:|--------------: 2 | 10 | 3 | 20 | Plus proche avant le milieu 1 | 80 | Le plus proche après le milieu 4 | 9
La médiane, la valeur moyenne, est (20 + 80)/2 = 50.
La médiane est également égale à la valeur au 50e centile.
Le paramètre sql pour les mesures type: median peut prendre n'importe quelle expression SQL valide générant une colonne de tableau numérique, une dimension LookML ou une combinaison de dimensions LookML.
Vous pouvez mettre en forme les champs type: median à l'aide des paramètres value_format ou value_format_name.
Exemple
Par exemple, le modèle LookML suivant crée un champ appelé median_order en faisant la moyenne de la dimension sales_price, puis l'affiche au format monétaire (1 234,56 $):
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
Éléments à prendre en compte pour median
Si vous utilisez median pour un champ impliqué dans une distribution ramifiée, Looker essaie d'utiliser plutôt median_distinct. Cependant, medium_distinct n'est disponible que pour certains dialectes. Si median_distinct n'est pas disponible pour votre dialecte, Looker renvoie une erreur. Étant donné que la median peut être considérée comme le 50e centile, l'erreur indique que le dialecte n'accepte pas des centiles distincts.
Dialectes de base de données compatibles avec median
Pour que Looker accepte le type median dans votre projet Looker, le dialecte de votre base de données doit également être compatible. Le tableau suivant indique les dialectes compatibles avec le type median dans la dernière version de Looker:
Lorsqu'une requête est impliquée, Looker tente de convertir median en median_distinct. Cette opération ne fonctionne que dans les dialectes compatibles avec median_distinct.
median_distinct
Utilisez type: median_distinct lorsque votre jointure implique un fanout. Il calcule la moyenne des valeurs non répétées d'un champ donné, en fonction des valeurs uniques définies par le paramètre sql_distinct_key. Si la mesure ne comporte pas de paramètre sql_distinct_key, Looker tente d'utiliser le champ primary_key.
Considérons le résultat d'une requête associant les tables "Item" et "Order" :
| ID de l'élément de campagne | ID de commande | Expédition commande |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
Dans ce cas, vous pouvez voir qu'il y a plusieurs lignes pour chaque commande. Cette requête impliquait une distribution ramifiée, car chaque commande correspond à plusieurs articles. median_distinct prend cela en considération et trouve la médiane entre les valeurs distinctes 10, 20 et 50, vous obtenez donc une valeur de 20.
Pour obtenir un résultat précis, vous pouvez expliquer à Looker comment identifier chaque entité unique (dans ce cas, chaque ordre unique) à l'aide du paramètre sql_distinct_key. Le montant correct est calculé:
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Notez que chaque valeur unique de sql_distinct_key ne doit avoir qu'une seule valeur correspondante dans le paramètre sql de la mesure. En d'autres termes, l'exemple ci-dessus fonctionne parce que chaque ligne avec un order_id de 1 a le même order_shipping de 10, chaque ligne avec un order_id de 2 a le même order_shipping de 20, etc.
Vous pouvez mettre en forme les champs type: median_distinct à l'aide des paramètres value_format ou value_format_name.
Éléments à prendre en compte pour median_distinct
Le type de mesure medium_distinct n'est compatible qu'avec certains dialectes. Si median_distinct n'est pas disponible pour le dialecte, Looker renvoie une erreur. Étant donné que la median peut être considérée comme le 50e centile, l'erreur indique que le dialecte n'accepte pas des centiles distincts.
Dialectes de base de données compatibles avec median_distinct
Pour que Looker accepte le type median_distinct dans votre projet Looker, le dialecte de votre base de données doit également être compatible. Le tableau suivant indique les dialectes compatibles avec le type median_distinct dans la dernière version de Looker:
min
type: min recherche la plus petite valeur d'un champ donné. Il utilise la fonction MIN de SQL.
Le paramètre sql pour les mesures de type: min peut utiliser n'importe quelle expression SQL valide générant une colonne de tableau numérique, une dimension LookML ou une combinaison de dimensions LookML.
Étant donné que les mesures de type: min ne sont compatibles qu'avec des champs numériques, vous ne pouvez pas utiliser une mesure de type: min pour trouver une date minimale. À la place, vous pouvez utiliser la fonction MIN() dans le paramètre sql d'une mesure de type: date pour capturer un minimum, tout comme vous pouvez utiliser la fonction MAX() avec une mesure de type: date pour capturer une date maximale. Comme indiqué précédemment sur cette page de la section date, qui inclut des exemples d'utilisation de la fonction MAX() dans le paramètre sql pour rechercher une date maximale.
Vous pouvez mettre en forme les champs type: min à l'aide des paramètres value_format ou value_format_name.
Par exemple, le modèle LookML suivant crée un champ appelé smallest_order en examinant la dimension sales_price, puis l'affiche au format monétaire (1 234,56 $):
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
Actuellement, vous ne pouvez pas utiliser de mesures type: min pour des chaînes ou des dates, mais vous pouvez ajouter manuellement la fonction MIN pour créer un champ de ce type:
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number est utilisé avec des nombres ou des entiers. Une mesure de type: number n'effectue aucune agrégation et est destinée à effectuer des transformations simples sur d'autres mesures. Si vous définissez une mesure basée sur une autre mesure, la nouvelle mesure doit être type: number pour éviter les erreurs d'agrégation imbriquée.
Le paramètre sql pour les mesures type: number peut prendre n'importe quelle expression SQL valide qui génère un nombre ou un entier.
Vous pouvez mettre en forme les champs type: number à l'aide des paramètres value_format ou value_format_name.
Par exemple, le LookML suivant crée une mesure appelée total_gross_margin_percentage basée sur les mesures agrégées total_sale_price et total_gross_margin, puis l'affiche au format de pourcentage avec deux décimales (12,34%):
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
L'exemple ci-dessus utilise également la fonction SQL NULLIF() pour éviter les erreurs de division par zéro.
Éléments à prendre en compte pour type: number
Voici quelques points importants à retenir lorsque vous utilisez des mesures type: number:
- Une mesure de
type: numberpeut effectuer des calculs arithmétiques uniquement sur d'autres mesures, et non sur d'autres dimensions. - Les agrégations symétriques de Looker ne protègent pas les fonctions d'agrégation en SQL d'une mesure
type: numberlorsqu'elles sont calculées via une jointure. - Le paramètre
filtersne peut pas être utilisé avec les mesurestype: number, mais la documentationfiltersexplique une solution de contournement. type: numbermesure ne fournira aucune suggestion aux utilisateurs.
percent_of_previous
type: percent_of_previous calcule le pourcentage de différence entre une cellule et la cellule précédente de la colonne.
Le paramètre sql pour type: percent_of_previous mesures doit référencer une autre mesure numérique.
Vous pouvez mettre en forme les champs type: percent_of_previous à l'aide des paramètres value_format ou value_format_name. Cependant, les formats de pourcentage du paramètre value_format_name ne fonctionnent pas avec les mesures type: percent_of_previous. Ces formats de pourcentage multiplient les valeurs par 100, ce qui fausse les résultats d'un pourcentage du calcul précédent.
Dans l'exemple suivant, ce LookML crée une mesure count_growth basée sur la mesure count:
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
Voici à quoi ressemblerait l'interface utilisateur Looker:
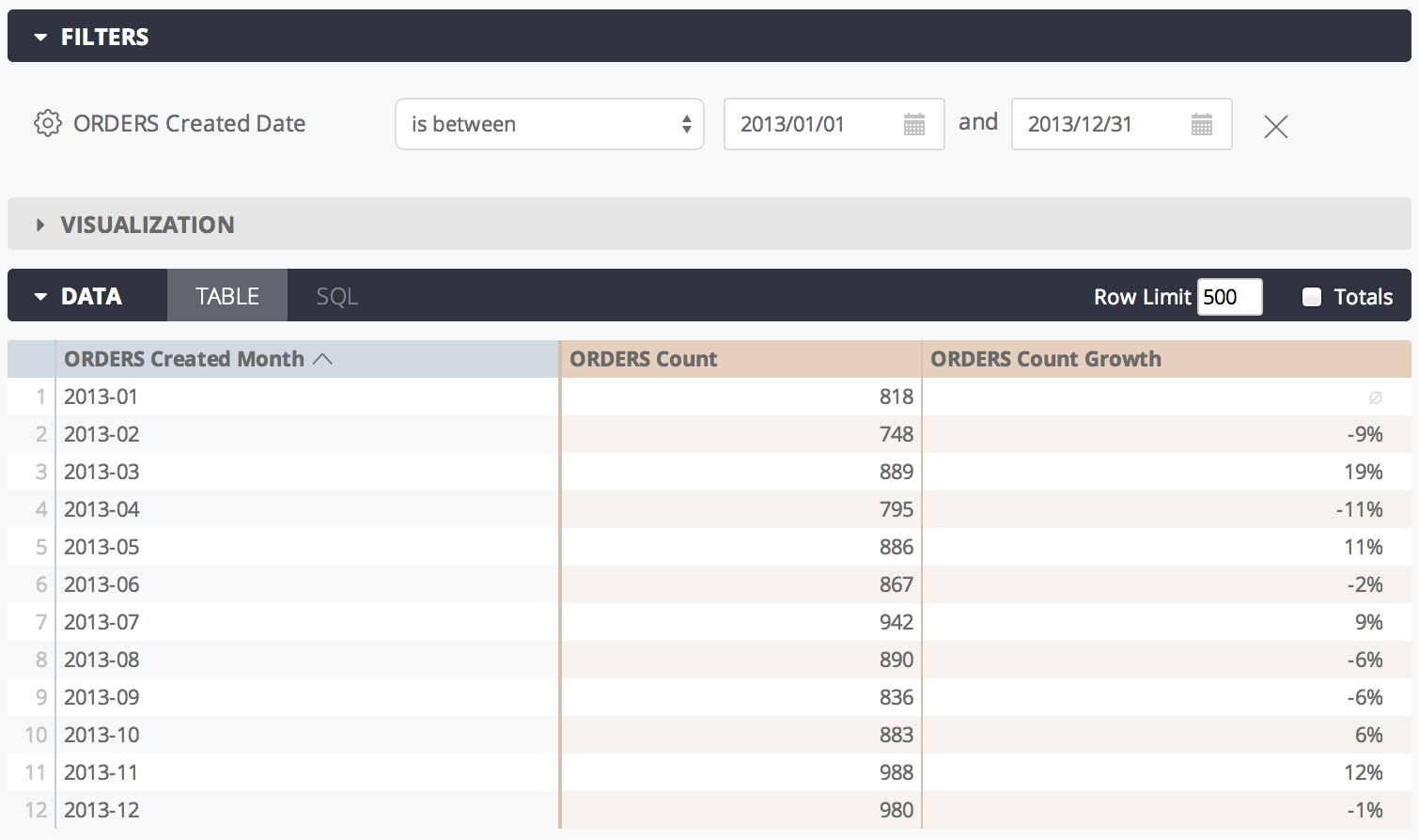
Notez que les valeurs percent_of_previous dépendent de l'ordre de tri. Si vous modifiez le tri, vous devez réexécuter la requête pour recalculer les valeurs percent_of_previous. Lorsqu'une requête est pivotée, percent_of_previous s'exécute sur la ligne au lieu de la colonne. Vous ne pouvez pas modifier ce comportement pour le moment.
De plus, les mesures percent_of_previous sont calculées après le renvoi de données de votre base de données. Cela signifie que vous ne devez pas référencer une mesure percent_of_previous dans une autre mesure. En effet, comme ils peuvent être calculés à des moments différents, vous risquez de ne pas obtenir de résultats précis. Cela signifie également que les mesures percent_of_previous ne peuvent pas être filtrées.
percent_of_total
type: percent_of_total calcule la partie d'une cellule par rapport au total de la colonne. Le pourcentage est calculé par rapport au nombre total de lignes renvoyées par votre requête, et non au nombre total de lignes possibles. Toutefois, si les données renvoyées par votre requête dépassent le nombre maximal de lignes, les valeurs du champ sont nulles, car il faut les résultats complets pour calculer le pourcentage du total.
Le paramètre sql pour type: percent_of_total mesures doit référencer une autre mesure numérique.
Vous pouvez mettre en forme les champs type: percent_of_total à l'aide des paramètres value_format ou value_format_name. Cependant, les formats de pourcentage du paramètre value_format_name ne fonctionnent pas avec les mesures type: percent_of_total. Ces formats de pourcentage multiplient les valeurs par 100, ce qui fausse les résultats du calcul percent_of_total.
Dans l'exemple suivant, ce LookML crée une mesure percent_of_total_gross_margin basée sur la mesure total_gross_margin:
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
Voici à quoi ressemblerait l'interface utilisateur Looker:

Lorsqu'une requête est pivotée, percent_of_total s'exécute sur la ligne au lieu de la colonne. Si vous ne le souhaitez pas, ajoutez direction: "column" à la définition de la mesure.
De plus, les mesures percent_of_total sont calculées après le renvoi de données de votre base de données. Cela signifie que vous ne devez pas référencer une mesure percent_of_total dans une autre mesure. En effet, comme ils peuvent être calculés à des moments différents, vous risquez de ne pas obtenir de résultats précis. Cela signifie également que les mesures percent_of_total ne peuvent pas être filtrées.
percentile
type: percentile renvoie la valeur au centile spécifié des valeurs d'un champ donné. Par exemple, si vous spécifiez le 75e centile, la valeur renvoyée est supérieure à 75% des autres valeurs de l'ensemble de données.
Pour identifier la valeur à renvoyer, Looker calcule le nombre total de valeurs de données et multiplie le centile spécifié par le nombre total de valeurs de données. Quelle que soit la façon dont les données sont triées, Looker identifie l'ordre relatif des valeurs de données dans l'augmentation de la valeur. La valeur de données renvoyée par Looker varie selon que le calcul génère un nombre entier ou non, comme indiqué ci-dessous.
Si la valeur calculée n'est pas un entier
Looker arrondit la valeur calculée et l'utilise pour identifier la valeur de données à renvoyer. Dans cet exemple de 19 scores de test, le 75e centile serait identifié par 19 * 0,75 = 14,25, ce qui signifie que 75% des valeurs se trouvent dans les 14 premières valeurs de données, soit en dessous de la 15e position. Ainsi, Looker renvoie la 15e valeur de données (87) comme étant supérieure à 75% des valeurs de données.

Si la valeur calculée est un entier
Dans ce cas légèrement plus complexe, Looker renvoie une moyenne de la valeur de données à cette position et la valeur de données suivante. Pour comprendre cela, prenons un ensemble de 20 scores de test. Le 75e centile serait identifié par 20 * 0, 75 = 15, ce qui signifie que la valeur de données en 15e position fait partie du 75e centile et que nous devons renvoyer une valeur supérieure à 75% des valeurs de données. En renvoyant la moyenne des valeurs à la 15e position (82) et à la 16e position (87), Looker s'assure que 75%. Cette moyenne (84,5) n'existe pas dans l'ensemble des valeurs de données, mais elle serait supérieure à 75% des valeurs de données.

Paramètres obligatoires et facultatifs
Utilisez le mot clé percentile: pour spécifier la valeur fractionnelle, qui correspond au pourcentage de données qui doit être inférieur à la valeur renvoyée. Par exemple, utilisez percentile: 75 pour spécifier la valeur au 75e centile de l'ordre des données, ou percentile: 10 pour la renvoyer au 10e centile. Si vous souhaitez trouver la valeur au 50e centile, vous pouvez spécifier percentile: 50 ou simplement utiliser le type médiane.
Le paramètre sql pour les mesures type: percentile peut prendre n'importe quelle expression SQL valide générant une colonne de tableau numérique, une dimension LookML ou une combinaison de dimensions LookML.
Vous pouvez mettre en forme les champs type: percentile à l'aide des paramètres value_format ou value_format_name.
Exemple
Par exemple, le LookML suivant crée un champ appelé test_scores_75th_percentile qui renvoie la valeur au 75e centile dans la dimension test_scores:
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
Éléments à prendre en compte pour percentile
Si vous utilisez percentile pour un champ impliqué dans un fanout, Looker essaie d'utiliser plutôt percentile_distinct. Si percentile_distinct n'est pas disponible pour le dialecte, Looker renvoie une erreur. Pour en savoir plus, consultez les dialectes compatibles avec percentile_distinct.
Dialectes de base de données compatibles avec percentile
Pour que Looker accepte le type percentile dans votre projet Looker, le dialecte de votre base de données doit également être compatible. Le tableau suivant indique les dialectes compatibles avec le type percentile dans la dernière version de Looker:
percentile_distinct
La type: percentile_distinct est une forme de centile spécialisée qui doit être utilisée lorsque votre jointure implique un fanout. Elle utilise les valeurs non répétées d'un champ donné, en fonction des valeurs uniques définies par le paramètre sql_distinct_key. Si la mesure ne comporte pas de paramètre sql_distinct_key, Looker tente d'utiliser le champ primary_key.
Considérons le résultat d'une requête associant les tables "Item" et "Order" :
| ID de l'élément de campagne | ID de commande | Expédition commande |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
Dans ce cas, vous pouvez voir qu'il y a plusieurs lignes pour chaque commande. Cette requête impliquait une distribution ramifiée, car chaque commande correspond à plusieurs articles. percentile_distinct prend cela en considération et trouve la valeur de centile à l'aide des valeurs distinctes 10, 20, 50, 70 et 110. Le 25e centile renverra la deuxième valeur distincte, ou 20, tandis que le 80e centile renverra la moyenne des quatrième et cinquième valeurs distinctes, ou 90.
Paramètres obligatoires et facultatifs
Utilisez le mot clé percentile: pour spécifier la valeur fractionnelle. Par exemple, utilisez percentile: 75 pour spécifier la valeur au 75e centile de l'ordre des données, ou percentile: 10 pour la renvoyer au 10e centile. Si vous essayez de trouver la valeur au 50e centile, vous pouvez utiliser le type median_distinct.
Pour obtenir un résultat précis, spécifiez comment Looker doit identifier chaque entité unique (dans ce cas, chaque ordre unique) à l'aide du paramètre sql_distinct_key.
Voici un exemple d'utilisation de percentile_distinct pour renvoyer la valeur au 90e centile:
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Notez que chaque valeur unique de sql_distinct_key ne doit avoir qu'une seule valeur correspondante dans le paramètre sql de la mesure. En d'autres termes, l'exemple ci-dessus fonctionne parce que chaque ligne avec order_id de 1 a le même order_shipping de 10, chaque ligne avec un order_id de 2 a le même order_shipping de 20, etc.
Vous pouvez mettre en forme les champs type: percentile_distinct à l'aide des paramètres value_format ou value_format_name.
Éléments à prendre en compte pour percentile_distinct
Si percentile_distinct n'est pas disponible pour le dialecte, Looker renvoie une erreur. Pour en savoir plus, consultez les dialectes compatibles avec percentile_distinct.
Dialectes de base de données compatibles avec percentile_distinct
Pour que Looker accepte le type percentile_distinct dans votre projet Looker, le dialecte de votre base de données doit également être compatible. Le tableau suivant indique les dialectes compatibles avec le type percentile_distinct dans la dernière version de Looker:
running_total
type: running_total calcule la somme cumulée des cellules d'une colonne. Il ne permet pas de calculer des sommes le long d'une ligne, sauf si cette dernière a été générée par un pivot.
Le paramètre sql pour type: running_total mesures doit référencer une autre mesure numérique.
Vous pouvez mettre en forme les champs type: running_total à l'aide des paramètres value_format ou value_format_name.
Par exemple, le LookML suivant crée une mesure cumulative_total_revenue basée sur la mesure total_sale_price:
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
Voici à quoi ressemblerait l'interface utilisateur Looker:

Notez que les valeurs running_total dépendent de l'ordre de tri. Si vous modifiez le tri, vous devez réexécuter la requête pour recalculer les valeurs running_total. Lorsqu'une requête est pivotée, running_total s'exécute sur la ligne au lieu de la colonne. Si vous ne le souhaitez pas, ajoutez direction: "column" à la définition de la mesure.
De plus, les mesures running_total sont calculées après le renvoi de données de votre base de données. Cela signifie que vous ne devez pas référencer une mesure running_total dans une autre mesure. En effet, comme ils peuvent être calculés à des moments différents, vous risquez de ne pas obtenir de résultats précis. Cela signifie également que les mesures running_total ne peuvent pas être filtrées.
string
type: string est utilisé avec des champs contenant des lettres ou des caractères spéciaux.
Le paramètre sql pour les mesures type: string peut utiliser n'importe quelle expression SQL valide générant une chaîne. En pratique, ce type est rarement utilisé, car la plupart des fonctions d'agrégation SQL ne renvoient pas de chaînes. La fonction GROUP_CONCAT de MySQL est une exception courante, même si Looker fournit type: list pour ce cas d'utilisation.
Par exemple, le LookML suivant crée un champ category_list en combinant les valeurs uniques d'un champ appelé category:
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
Dans cet exemple, type: string peut être omis, car string est la valeur par défaut pour type.
sum
type: sum additionne les valeurs d'un champ donné. Elle est semblable à la fonction SUM de SQL. Toutefois, contrairement à l'écriture en SQL brut, Looker calcule correctement les sommes, même si les jointures de votre requête contiennent des distributions ramifiées.
Le paramètre sql pour les mesures type: sum peut prendre n'importe quelle expression SQL valide générant une colonne de tableau numérique, une dimension LookML ou une combinaison de dimensions LookML.
Vous pouvez mettre en forme les champs type: sum à l'aide des paramètres value_format ou value_format_name.
Par exemple, le modèle LookML suivant crée un champ appelé total_revenue en ajoutant la dimension sales_price, puis l'affiche au format monétaire (1 234,56 $):
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct est destiné aux ensembles de données dénormalisés. Il additionne les valeurs non répétées d'un champ donné, en fonction des valeurs uniques définies par le paramètre sql_distinct_key.
Ce concept avancé peut être expliqué plus clairement à l'aide d'un exemple. Prenons l'exemple d'une table dénormalisée comme celle-ci:
| ID de l'élément de campagne | ID de commande | Expédition commande |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20 |
| 4 | 2 | 20 |
| 5 | 2 | 20 |
Dans ce cas, vous pouvez voir qu'il y a plusieurs lignes pour chaque commande. Par conséquent, si vous ajoutez une mesure type: sum simple pour la colonne order_shipping, vous obtiendrez un total de 80,00 $, même si le total des frais de port collectés est de 30,00.
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
Pour obtenir un résultat précis, vous pouvez expliquer à Looker comment identifier chaque entité unique (dans ce cas, chaque ordre unique) à l'aide du paramètre sql_distinct_key. Cela calcule le montant correct de 30 €:
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Notez que chaque valeur unique de sql_distinct_key ne doit avoir qu'une seule valeur correspondante dans sql. En d'autres termes, l'exemple ci-dessus fonctionne parce que chaque ligne avec un order_id de 1 a le même order_shipping de 10.00, chaque ligne avec un order_id de 2 a le même order_shipping de 20.00, etc.
Vous pouvez mettre en forme les champs type: sum_distinct à l'aide des paramètres value_format ou value_format_name.
yesno
type: yesno crée un champ qui indique si une information est vraie ou fausse. Les valeurs Yes et No s'affichent dans l'interface utilisateur Explorer.
Le paramètre sql d'une mesure type: yesno utilise une expression SQL valide qui renvoie TRUE ou FALSE. Si la condition renvoie TRUE, Yes s'affiche pour l'utilisateur, sinon No s'affiche.
L'expression SQL pour les mesures type: yesno ne doit inclure que des agrégations SQL, c'est-à-dire des agrégations SQL ou des références à des mesures LookML. Si vous souhaitez créer un champ yesno qui inclut une référence à une dimension LookML ou une expression SQL qui n'est pas une agrégation, utilisez une dimension avec type: yesno, et non une mesure.
À l'instar des mesures avec type: number, une mesure avec type: yesno n'effectue aucune agrégation ; elle fait simplement référence à d'autres agrégations.
Par exemple, la mesure total_sale_price ci-dessous correspond à la somme du prix soldé total des articles d'une commande. La deuxième mesure appelée is_large_total est type: yesno. La mesure is_large_total comporte un paramètre sql qui détermine si la valeur total_sale_price est supérieure à 1 000 $.
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
Si vous souhaitez référencer un champ type: yesno dans un autre champ, vous devez traiter le champ type: yesno comme booléen (en d'autres termes, comme s'il s'agissait déjà d'une valeur vraie ou fausse). Exemple :
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
}
# This is correct
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}