Après avoir sécurisé et configuré votre base de données, vous êtes prêt à connecter votre base de données à Looker.
Création d'une nouvelle connexion de base de données
Sélectionnez Connexions dans la section Base de données du panneau Administration. Sur la page Connections (Connexions), cliquez sur le bouton Add Connection (Ajouter une connexion). Looker affiche la page Paramètres de connexion. Les champs de la page Paramètres de connexion dépendent du dialecte sélectionné.
Pour en savoir plus sur l'application d'attributs utilisateur aux paramètres de connexion, consultez la section Connexions de la page de documentation Attributs utilisateur.
Pour savoir comment configurer des identifiants de connexion distincts pour les processus PDT à l'aide de la colonne Remplacements PDT, consultez la section Configurer des identifiants de connexion distincts pour les processus PDT.
Par exemple, les options suivantes sont disponibles pour la configuration lorsque vous connectez Looker à Amazon Redshift.
Nom
Le nom de la connexion tel que vous souhaitez y faire référence. Vous ne devez pas utiliser le nom d'un dossier. Cette valeur ne doit pas nécessairement correspondre à un élément de votre base de données ; il s'agit simplement d'attribuer une étiquette. Vous l'utiliserez dans le paramètre connection de votre modèle LookML.
Dialecte
Dialecte SQL correspondant à votre connexion. Il est important de choisir la bonne valeur afin que les options de connexion appropriées vous soient proposées et que Looker puisse traduire correctement votre LookML en SQL.
Serveur SSH
L'option Serveur SSH est disponible si l'instance est déployée sur l'infrastructure Kubernetes et uniquement si la possibilité d'ajouter des informations de configuration du serveur SSH à votre instance Looker a été activée. Si cette option n'est pas activée sur votre instance Looker et que vous souhaitez l'activer, contactez votre responsable de compte Looker ou ouvrez une demande d'assistance dans le Centre d'aide de Looker.
Le serveur SSH choisit automatiquement le port localhost pour vous et il est actuellement impossible de spécifier le port localhost. Si vous devez créer une connexion SSH nécessitant un port localhost, contactez votre responsable de compte Looker ou ouvrez une demande d'assistance dans le Centre d'aide de Looker.
Pour vous connecter à votre base de données à l'aide d'un tunnel SSH, activez l'option et sélectionnez Configuration du serveur SSH dans la liste déroulante.
Remote Host:Port
Le nom d'hôte de votre base de données et le port que Looker doit utiliser pour se connecter à l'hôte de votre base de données.
Si vous avez travaillé avec un analyste Looker pour configurer un tunnel SSH vers votre base de données, saisissez "localhost" dans le champ Hôte, et dans le champ Port, saisissez le numéro de port qui redirige vers votre base de données, que votre analyste Looker doit avoir fourni.
Si vous appliquez un attribut utilisateur au champ Hôte, un niveau d'accès utilisateur ne peut pas être défini sur Modifiable.
Si vous avez configuré un tunnel SSH pour vous connecter à votre base de données, vous ne pouvez pas appliquer d'attribut utilisateur au champ Remote Host:Port.
Base de données
Le nom de la base de données de votre hôte. Par exemple, vous pouvez avoir un nom d'hôte my-instance.us-east-1.redshift.amazonaws.com sur lequel se trouve une base de données appelée sales_info. Vous devez saisir sales_info dans ce champ. Si vous disposez de plusieurs bases de données sur le même hôte, vous devrez peut-être créer plusieurs connexions pour les utiliser (sauf pour MySQL, dans lequel le mot database signifie quelque chose de légèrement différent de la plupart des dialectes SQL).
Use OAuth
Pour les connexions à Snowflake et à Google BigQuery, vous pouvez utiliser OAuth. Il en résulte que les utilisateurs doivent se connecter à Snowflake ou à Google, respectivement, pour émettre des requêtes à partir de Looker.
Lorsque vous sélectionnez Utiliser OAuth, les champs ID client OAuth et Code secret du client OAuth s'affichent:

Ces valeurs sont générées par la base de données Snowflake ou par Google. Consultez la page de documentation sur la configuration OAuth de Snowflake ou la configuration OAuth de Google BigQuery pour découvrir la procédure complète.
Nom d'utilisateur
Le nom d'utilisateur que Looker doit utiliser pour se connecter à votre base de données. Vous devez configurer l'utilisateur à l'avance conformément à nos instructions de configuration de la base de données.
Mot de passe
Le mot de passe que Looker doit utiliser pour se connecter à votre base de données. Vous devez configurer le mot de passe à l'avance conformément à nos instructions de configuration de la base de données.
Schéma
Le schéma par défaut que Looker utilise lorsqu'aucun schéma n'est indiqué. Cela s'applique lorsque vous utilisez SQL Runner, que vous générez un projet LookML et que vous interrogez des tables.
Tables dérivées persistantes
Cochez cette case pour activer les tables dérivées persistantes. Les champs PDT supplémentaires et la colonne PDT Overrides (Remplacements PDT) s'affichent. Looker n'affiche cette option que si le dialecte de base de données est compatible avec PDT.
Remarques à propos des PDT :
- Les PDT ne sont pas compatibles avec les connexions Snowflake utilisant OAuth.
- La désactivation des PDT sur une connexion ne désactive pas les groupes de données qui y sont associés. Même si vous désactivez les PDT, les groupes de données existants continueront d'exécuter leurs requêtes
sql_triggersur la base de données. Si vous souhaitez empêcher un groupe de données d'exécuter sa requêtesql_triggersur votre base de données, vous devez supprimer ou commenter le paramètredatagroupde votre projet LookML. Vous pouvez également mettre à jour le paramètre PDT et planification de maintenance du groupe de données pour la connexion afin que Looker vérifie les PDT et les groupes de données très peu ou jamais. - Pour les connexions Snowflake, Looker définit la valeur du paramètre
AUTOCOMMITsurTRUE(valeur par défaut de Snowflake).AUTOCOMMITest requis pour les commandes SQL que Looker exécute pour gérer son système d'enregistrement PDT.
Temp Database
Même s'il porte le nom Temp Database (Base de données temporaire), vous devez saisir le nom de la base de données ou du schéma (selon votre dialecte SQL) que Looker doit utiliser pour créer des tables dérivées persistantes. Vous devez configurer cette base de données ou ce schéma à l'avance en utilisant les autorisations en écriture appropriées. Sur la page de documentation Instructions de configuration de la base de données, sélectionnez le dialecte de votre base de données pour afficher les instructions correspondantes.
Chaque connexion doit avoir sa propre base de données temporaire ou schéma ; elle ne peut pas être partagée entre les connexions.
Max de connexions du générateur de PDT
Le paramètre Max PDT Builder Connections (Connexions au compilateur PDT max.) vous permet de spécifier le nombre de compilations de tables simultanées que le générateur de Looker peut lancer sur votre connexion à la base de données. Le paramètre Max PDT Builder Connections (Connexions au compilateur PDT maximales) s'applique uniquement aux types de tables pour lesquels le régénérateur Looker lance des recompilations:
- Tables persistantes au niveau du déclencheur (tables dérivées persistantes et tables agrégées qui utilisent la stratégie de persistance
datagroup_triggerousql_trigger_value) - Tables persistantes utilisant la stratégie
persist_for, mais uniquement lorsque la tablepersist_forfait partie d'une cascade de tables dérivées dont la dépendance dépend d'une table utilisant la stratégie de persistancedatagroup_triggerousql_trigger_value. Dans ce cas, le régénérateur Looker va recompiler une tablepersist_for, car celle-ci est nécessaire pour recréer une autre table de la cascade. Sinon, le générateur ne lance pas de compilation pour les tablespersist_for.
Le paramètre Max PDT Builder Connections (Connexions au PDT max.) est défini sur 1, mais il peut être défini sur 10. Cependant, la valeur ne peut pas être supérieure à celle définie dans le champ Max Connections (Connexions maximales) ou dans les per-user-query-limit options définies dans les options de démarrage de Looker.
Vous devez configurer cette valeur attentivement. Si cette valeur est trop élevée, vous risquez de submerger votre base de données. Si cette valeur est faible, les tables PDT ou agrégées de grande taille peuvent retarder la création d'autres tables persistantes ou ralentir les autres requêtes sur la connexion. Les bases de données compatibles avec l'architecture mutualisée, telles que BigQuery, Snowflake et Redshift, peuvent gérer plus efficacement les compilations de requêtes parallèles.
Si vous souhaitez augmenter le paramètre Max PDT Builder Connections (Connexions au compilateur PDT max.), nous vous conseillons d'augmenter la valeur par incrément de 1. Si un comportement inattendu se produit, rétablissez la valeur par défaut 1. Sinon, si les performances de la requête ne sont pas affectées, vous pouvez continuer à l'augmenter de manière incrémentielle de 1 et vérifier les performances à chaque incrément avant d'augmenter davantage le paramètre.
Notez les points suivants concernant le paramètre Max PDT Builder Connections (Connexions au compilateur PDT maximales) :
- Le paramètre Max PDT Builder Connections (Connexions au compilateur PDT maximales) s'applique uniquement aux connexions requises pour la reconstruction des tables, et non aux connexions nécessaires pour les vérifications de déclencheurs. Une vérification de déclencheurs est une requête qui vérifie si la stratégie de persistance de la table est déclenchée. Comme ces requêtes sont toujours exécutées de manière séquentielle, le paramètre Max PDT Builder Connections (Connexions au compilateur PDT maximales) ne s'applique pas.
- Dans une instance Looker en cluster, le générateur ne s'exécute que sur le nœud principal. Le paramètre Max PDT Builder Connections (Connexions au compilateur PDT) s'applique uniquement au nœud principal et définit donc la limite pour l'ensemble du cluster.
- Le paramètre Max PDT Builder Connections (Connexions au compilateur PDT max.) ne s'applique pas aux types de tables suivants. Ces types de tables sont construits de manière consécutive :
- Les tables sont conservées via le paramètre
persist_for(sauf si elles dépendent des tables utilisant les stratégiesdatagroup_triggerousql_trigger_value). - Tables en mode développement.
- Tables recréées à l'aide de l'option Recompiler des tables dérivées &.
- Tables dont l'une dépend d'une autre dans une cascade de dépendance. Une table ne peut pas être créée en même temps qu'une table dont elle dépend. Par exemple, si
table_Bdépend detable_A,table_Adoit terminer la recompilation pour quetable_Bpuisse commencer à la recompiler.
- Les tables sont conservées via le paramètre
Always Retry Failed PDT Builds
Le paramètre Toujours réessayer les builds PDT ayant échoué configure la manière dont le générateur de Looker tente de recréer les tables persistantes ayant échoué lors du cycle de génération précédent. Le régénérateur Looker est le processus qui recrée les tables persistantes (déclencheurs et tables agrégées) en fonction de l'intervalle configuré dans le paramètre de connexion PDT et planification de maintenance des groupes de données. Lorsque le paramètre Toujours réessayer les builds PDT ayant échoué est activé, le régénérateur Looker tente de recréer un PDT ayant échoué au cours du cycle précédent, même si la condition de déclenchement du modèle PDT n'est pas remplie. Lorsque ce paramètre est désactivé, le générateur de Looker tente de recréer un PDT ayant échoué précédemment uniquement lorsque la condition de déclenchement du PDT est remplie. L'option Always Réessayer Échecs PDT est désactivée par défaut.
Pour en savoir plus sur le régénérateur Looker, consultez la page de documentation Tables dérivées dans Looker.
Activer la commande API PDT
Le paramètre Activer le contrôle de l'API PDT détermine si les appels d'API start_pdt_build, check_pdt_build et stop_pdt_build peuvent être utilisés pour cette connexion. Lorsque ce paramètre est désactivé, ces appels d'API échoueront lorsqu'ils font référence aux PDT sur cette connexion. L'option Activer le contrôle de l'API PDT est désactivée par défaut.
Additional Params
Vous pouvez ajouter des paramètres Java Database Connectivity (JDBC) supplémentaires à cet endroit, le cas échéant.
Pour référencer un attribut utilisateur dans un paramètre JDBC, utilisez la syntaxe de modélisation Liquid : _user_attributes['name_of_attribute']. Exemple :
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Voici à quoi cela pourrait ressembler dans le champ Additional Params (Paramètres supplémentaires) de Looker:

Les paramètres JDBC supplémentaires ne sont pas testés par Looker et peuvent altérer son fonctionnement normal.
Planification du suivi des tables PDT et des groupes de données
Ce paramètre accepte une expression cron qui indique quand le générateur de Looker doit vérifier les groupes de données et les tables persistantes (à la fois tables agrégées et tables dérivées persistantes) basées sur sql_trigger_value, et voir quelles tables doivent être générées à nouveau ou supprimées.
La valeur par défaut de */5 * * * * signifie « vérifier toutes les 5 minutes », ce qui correspond à la fréquence maximale des vérifications. Une expression cron indiquant que les vérifications sont plus fréquentes entraînera des vérifications toutes les cinq minutes.
Pendant la création de tables PDT, Looker n'effectue aucune autre vérification de déclencheurs. Lorsque toutes les tables PDT depuis la dernière vérification de déclencheurs sont créées, Looker reprendra la vérification des déclencheurs des groupes de données et des tables PDT selon la planification du suivi des tables PDT et des groupes de données.
Si votre base de données n'est pas opérationnelle 24h/24, 7j/7, vous pouvez limiter les vérifications aux heures où la base de données est opérationnelle. Voici quelques expressions cron supplémentaires:
Expression cron |
Définition |
|---|---|
*/5 8-17 * * MON-FRI |
Vérifier les groupes de données et les tables PDT toutes les 5 minutes pendant les heures de travail, du lundi au vendredi |
*/5 8-17 * * * |
Vérifier les groupes de données et les tables PDT toutes les 5 minutes pendant les heures de travail, au quotidien |
0 8-17 * * MON-FRI |
Vérifier les groupes de données et les tables PDT toutes les heures pendant les heures de travail, du lundi au vendredi |
1 3 * * * |
Vérifier les groupes de données et les tables PDT tous les jours à 3 h 01 |
Voici quelques points à noter lorsque vous créez une expression cron:
- Looker utilise parse-cron v0.1.3, qui n'est pas compatible avec
?dans les expressionscron. - L'expression
cronutilise le fuseau horaire de l'application Looker pour déterminer quand les vérifications sont effectuées. - Si les disques persistants ne sont pas en cours de création, rétablissez la chaîne par défaut
*/5 * * * *.
Vous trouverez ci-dessous des ressources pour vous aider à créer des chaînes cron:
- https://crontab.guru : permet de modifier et de tester les chaînes
cron. - http://www.crontab-generator.org : sélectionnez les paramètres de temps pour que le générateur crée la chaîne
croncorrespondante.
SSL
Choisissez si vous souhaitez, ou non, utiliser le chiffrement SSL pour protéger vos données pendant leur transition entre Looker et votre base de données. SSL n'est qu'une des options permettant de protéger vos données. D'autres options de sécurité sont décrites sur la page de documentation Activer l'accès sécurisé aux bases de données.
Verify SSL Cert
Choisissez si vous souhaitez demander une vérification du certificat SSL utilisé par la connexion. Si une validation est requise, l'autorité de certification SSL qui a signé le certificat SSL doit provenir de la liste des sources de confiance du client. Si l'AC n'est pas une source fiable, la connexion de base de données n'est pas établie.
Si cette case n'est pas cochée, le chiffrement SSL est toujours utilisé sur la connexion, mais la vérification de la connexion SSL n'est pas requise. Une connexion peut donc être établie lorsque l'autorité de certification ne figure pas dans la liste de sources de confiance du client.
Max Connections
Ici, vous pouvez configurer le nombre maximal de connexions que Looker peut établir avec votre base de données. Dans la majorité des cas, vous configurez le nombre de requêtes simultanées que Looker peut exécuter sur votre base de données. Looker consacre également jusqu'à trois connexions à la suppression des requêtes. Si le pool de connexions est de taille très restreinte, Looker consacrera moins de connexions.
Vous devez configurer cette valeur attentivement. Si cette valeur est trop élevée, vous risquez de submerger votre base de données. Si cette valeur est trop faible, les requêtes devront partager une petite quantité de connexions. Chaque requête devant attendre le retour des autres requêtes précédemment exécutées, il se peut donc que de nombreuses requêtes semblent lentes aux utilisateurs.
La valeur par défaut (qui varie en fonction de votre dialecte SQL) constitue généralement un point de départ raisonnable. Pour ce qui est du nombre maximal de connexions qu'elles acceptent, la plupart des bases de données disposent également de leur propre configuration. Si la configuration de votre base de données limite les connexions, assurez-vous que la valeur Max Connections (Nombre maximal de connexions) est égale ou inférieure à la limite de votre base de données.
Connection Pool Timeout
Si vos utilisateurs demandent plus de connexions que le paramètre Max Connections (Connexions maximales), les requêtes devront attendre la fin de l'opération avant d'être exécutées. Le temps d'attente maximal d'une requête se configure à cet endroit. Vous devez configurer cette valeur attentivement. Si cette valeur est trop faible, les requêtes des utilisateurs risquent d'être annulées, car le temps alloué aux autres requêtes utilisateur est insuffisant. S'il est trop élevé, il se peut qu'une grande quantité de requêtes s'accumulent et que le temps d'attente soit très long pour les utilisateurs. La valeur par défaut constitue généralement un point de départ raisonnable.
Estimation des coûts
La case à cocher Coût estimé s'applique uniquement aux connexions de base de données suivantes:
- Flocon de neige
- Amazon Redshift
- Amazon Aurora
- PostgreSQL, Cloud SQL pour PostgreSQL et Microsoft Azure PostgreSQL
La case à cocher Coût estimé active les fonctionnalités suivantes pour la connexion:
- Estimations des coûts pour les requêtes Explorer
- Estimations des coûts pour les requêtes SQL Runner
- Estimation des économies réalisées pour les calculs pour les requêtes de notoriété agrégées
Les connexions BigQuery et MySQL sont également compatibles avec la fonctionnalité Coût estimé. Toutefois, comme cette fonctionnalité est toujours activée, il n'existe aucune case à cocher Estimation du coût pour les connexions BigQuery et MySQL.
Pour en savoir plus, consultez la page Explorer les données dans Looker.
SQL Runner Precache
Dans SQL Runner, toutes les informations de la table sont préchargées dès que vous sélectionnez une connexion et un schéma. Cela permet à SQL Runner d'afficher les colonnes de la table rapidement dès que vous cliquez sur un nom de table. Néanmoins, pour les connexions et les schémas comportant de nombreuses tables ou des tables très volumineuses, il se peut que vous ne souhaitiez pas que SQL Runner précharge l'ensemble des informations.
Si vous préférez que l'exécuteur SQL charge les informations de la table uniquement lorsqu'une table est sélectionnée, vous pouvez désélectionner l'option Préchargement de l'exécuteur SQL pour désactiver le préchargement SQL Runner pour la connexion.
Télécharger un schéma d'informations pour l'écriture SQL
Pour certaines fonctionnalités d'écriture SQL telles que la notoriété agrégée, Looker utilise le schéma d'informations de votre base de données pour optimiser l'écriture en SQL. Si le schéma d'informations n'est pas mis en cache, Looker peut être amené à bloquer l'écriture SQL sur la base de données afin de télécharger le schéma d'informations. Pour les dialectes qui utilisent le système de fichiers distribué Hadoop (HDFS, Hadoop Distributed File System), la récupération du schéma d'informations peut prendre suffisamment de temps pour affecter de manière significative les performances de vos requêtes Looker. Si vous savez que votre schéma d'informations est lent, vous pouvez désactiver l'option Fetch Information Schema For SQL Write (Récupérer le schéma d'informations pour l'écriture SQL). La désactivation de cette fonctionnalité empêchera certaines fonctionnalités d'optimisation SQL de Looker pour certaines fonctionnalités. Vous devez donc activer l'option Extraire le schéma d'informations pour l'écriture SQL, sauf si vous savez que le schéma d'informations de votre connexion est particulièrement lent.
Désactiver le commentaire de contexte
L'option Désactiver le commentaire de contexte s'applique uniquement aux connexions BigQuery. Les commentaires contextuels sur les connexions Google BigQuery sont désactivés par défaut, car ils empêchent la mise en cache de Google BigQuery et peuvent avoir un impact négatif sur les performances du cache. Vous pouvez activer les commentaires contextuels pour une connexion BigQuery en décochant le paramètre Disable Context Comment (Désactiver le commentaire de contexte) sur la page Connection Settings (Paramètres de connexion) de la connexion. Pour en savoir plus, consultez la page de la documentation Google BigQuery.
Fuseau horaire de la base de données
Le fuseau horaire dans lequel votre base de données stocke les informations temporelles. Looker doit connaître cette information afin de convertir les valeurs de date/heure pour les utilisateurs et ainsi simplifier la compréhension et l'utilisation des données temporelles. Pour en savoir plus, consultez la page Utiliser les paramètres de fuseau horaire.
Requête Fuseau horaire
L'option Fuseau horaire de la requête n'est visible que si vous avez désactivé les Fuseaux horaires spécifiques à l'utilisateur.
Lorsque les fuseaux horaires spécifiques à l'utilisateur sont désactivés, le fuseau horaire de requête est le fuseau horaire qui s'affiche pour vos utilisateurs lorsqu'ils interrogent des données temporelles, et le fuseau horaire dans lequel Looker convertira les données basées sur l'heure à partir du Fuseau horaire de la base de données.
Pour en savoir plus, consultez la page Utiliser les paramètres de fuseau horaire.
Configuration d'identifiants de connexion distincts pour les processus PDT
Si votre base de données accepte les tables dérivées persistantes et que vous avez coché la case Persistent Derived Tables (Tables dérivées persistantes) dans les paramètres de connexion, Looker affiche la colonne PDT Overrides (Remplacements PPD). Dans la colonne Remplacements PDT, vous pouvez saisir des paramètres JDBC distincts (hôte, port, base de données, nom d'utilisateur, mot de passe, schéma et paramètres supplémentaires) spécifiques aux processus PDT. Cette possibilité est précieuse pour plusieurs raisons :
- En créant un utilisateur de base de données distinct pour les processus PDT, vous pouvez utiliser des PDT dans votre modèle même si vous attribuez des attributs utilisateur à vos identifiants de connexion à la base de données.
- Les processus PDT peuvent s'authentifier par l'intermédiaire d'un utilisateur de base de données distinct dont la priorité est plus élevée. La base de données peut ainsi placer les jobs PDT en priorité au détriment des requêtes de moindre importance des utilisateurs.
- L'accès en écriture peut être révoqué pour la connexion standard à la base de données Looker, et être octroyé seulement à un utilisateur spécifique que les processus PDT utiliseront pour s'authentifier. Il s'agit d'une meilleure stratégie de sécurité pour la plupart des organisations.
- Pour les bases de données telles que Snowflake, les processus PDT peuvent être acheminés vers du matériel plus puissant qui n'est pas partagé avec le reste des utilisateurs de Looker. Les tables PDT peuvent ainsi être créées rapidement en évitant les coûts inhérents à l'exécution d'un matériel onéreux à temps plein.
Par exemple, la configuration suivante illustre une connexion dans laquelle les champs « username » et « password » sont définis avec des attributs utilisateur. Chaque utilisateur peut ainsi accéder à la base de données avec ses propres identifiants. La colonne PDT Override crée un utilisateur distinct (pdt_user) avec son propre mot de passe. Le compte pdt_user sera utilisé pour tous les processus PDT, avec des niveaux d'accès adaptés à la création et à la mise à jour du PDT:
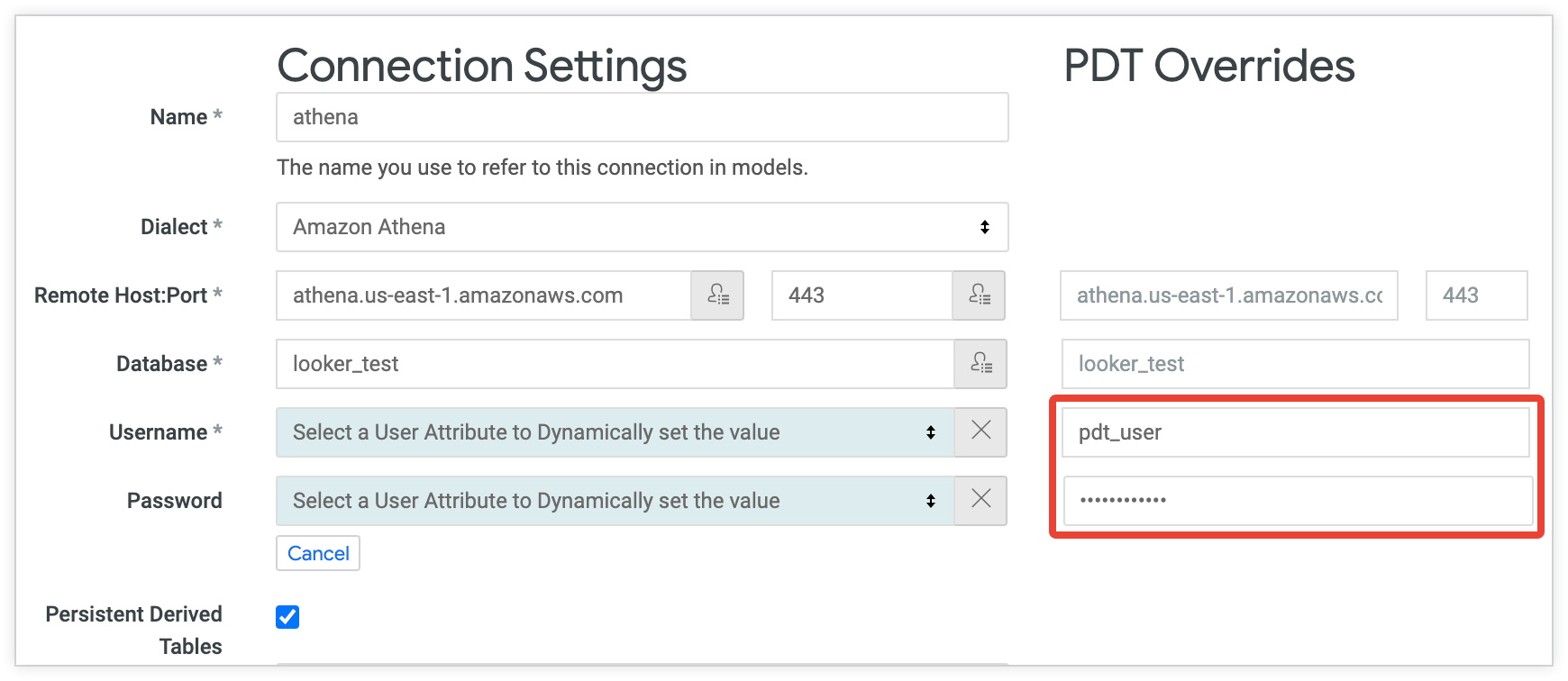
Bien que la colonne Remplacements PDT vous permette de modifier l'utilisateur de la base de données et d'autres propriétés de connexion, un remplacement PDT doit lire les mêmes données que la connexion par défaut et écrire les données au même endroit. Looker ne peut pas lire les données à partir d'un emplacement et les écrire dans un autre.
Test de vos paramètres de connexion
Une fois que vous avez saisi les identifiants, cliquez sur Tester ces paramètres pour vérifier que les informations sont correctes et que la base de données peut se connecter.
Si votre connexion ne réussit pas un ou plusieurs tests :
- Essayez certaines étapes de dépannage sur la page de documentation Test de la connectivité à la base de données.
- Si vous exécutez Mongo version 3.6 ou une version antérieure sur Atlas et que vous ne parvenez pas à accéder au lien de communication, consultez la page de documentation de Mongo Connector.
- Pour recevoir des messages indiquant une connexion réussie concernant le schéma et les tables PDT temporaires, vous devrez avoir activé cette fonctionnalité au moment du paramétrage de votre base de données Looker. Pour ce faire, suivez les instructions figurant sur la page de documentation Instructions de configuration de la base de données.
Les connexions à une base de données utilisant OAuth, telles que Snowflake et Google BigQuery, nécessitent une connexion utilisateur. Si vous n'êtes pas connecté à votre compte utilisateur OAuth lorsque vous testez l'une de ces connexions, Looker affiche un avertissement avec un lien Connexion. Cliquez sur le lien pour saisir vos identifiants OAuth ou pour autoriser Looker à accéder à vos informations de compte OAuth.
Si vous rencontrez encore des difficultés, contactez le support Looker pour obtenir de l'aide.
Tester en tant qu'utilisateur
Si vous avez défini une ou plusieurs valeurs de paramètre de connexion pour un attribut utilisateur, l'option Tester en tant qu'utilisateur s'affiche au-dessus du bouton Tester ces paramètres. Sélectionnez un utilisateur, puis cliquez sur Tester ces paramètres pour vérifier que la base de données peut se connecter et exécuter des requêtes en tant qu'utilisateur.
Ajout de votre connexion de base de données
Une fois que vous avez configuré et testé vos paramètres de connexion à la base de données, cliquez sur Add Connection (Ajouter une connexion). Votre connexion à la base de données est maintenant ajoutée à la liste sur la page Connexions.
Étapes suivantes
Une fois votre base de données connectée à Looker, vous pouvez configurer des options de connexion pour vos utilisateurs.