
Bigtable
NoSQL のパイオニアを使用して、レイテンシの影響を受けやすいアプリケーションをスケール
ML、運用分析、ユーザー向けアプリケーションに適した、低レイテンシの Cassandra および HBase 対応 NoSQL データベース サービス。
無料トライアル インスタンスの使用を開始する。

機能
低レイテンシ、高スループット
Bigtable は Key-Value かつワイドカラム型ストアであり、構造化データ、半構造化データ、非構造化データへの高速アクセスに最適です。このため、パーソナライズなどのレイテンシの影響を受けやすいワークロードは Bigtable に最適です。
分散カウンタ、1 ドルあたりの読み書きスループットが高いため、クリックストリームや IoT のユースケース、さらには ML モデルのトレーニングを含むハイ パフォーマンス コンピューティング(HPC)アプリケーションのバッチ分析にも適しています。
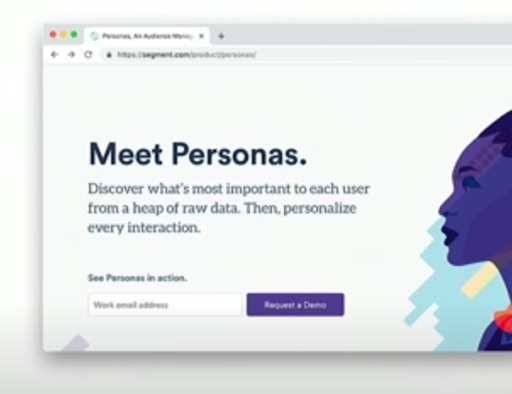
ハイブリッド ストレージ アーキテクチャ
Bigtable の RAM、SSD、HDD 間の自動かつシームレスなデータ階層化により、高いパフォーマンスを費用対効果の高い方法で実現できます。RAM を活用して超レイテンシを実現し、キャッシュ レイヤを必要とせずにホットスポットの問題を解消します。また、アクセス頻度の低いデータを HDD に階層化することで、データ パイプラインの管理や、複数のシステム間でデータを同期させるという煩わしさを伴わずに、大幅な費用削減を実現します。
SQL と継続的マテリアライズド ビュー
Bigtable SQL を使用すると、使い慣れた SQL 構文を使用して、フルマネージドのリアルタイム アプリケーションを構築できます。また、Bigtable の柔軟なスキーマを維持する特殊な機能も利用できます。また、SQL インターフェースを使用して、リアルタイム指標の作成を簡素化する増分マテリアライズド ビューを構築することもできます。Bigtable のマテリアライズド ビューは、書き込みや読み取りのパフォーマンスに影響を与えることなく、変更が発生したら直ちに処理することで、自動的にデータを最新の状態に保ち、トラフィックに応じてスケールします。
データモデルの柔軟性
Bigtable を使用すると、データモデルを有機的に進化させることができます。スカラー、JSON、プロトコル バッファ、Avro、Arrow から、エンベディングや画像まであらゆるデータを保存でき、必要に応じて新しい列を動的に追加または削除できます。単一のデータベースで未加工のデータや非構造化データを扱い、低レイテンシのデータ提供や高パフォーマンスのバッチ分析を行えます。
NoSQL データベースから簡単に移行
Bigtable が提供する Apache Cassandra と HBase API と移行ツールを使用すると、少ない労力で正確なデータ移行を実現することで、オンボーディングをより迅速かつ簡単に行うことができます。HBase Bigtable レプリケーション ライブラリと Cassandra Proxy により、ダウンタイムなしのライブ マイグレーションが可能になります。また、Bigtable Data Bridge や Aerospike Migration Tool により、Amazon DynamoDB や Aerospike からの移行が簡素化されます。

単一のゾーンから一度に最大 8 つのリージョンをサポート
Bigtable を基盤とするアプリは、ユーザーがどこにいても、グローバルに分散したマルチプライマリ構成で低レイテンシの読み取りと書き込みを実現できます。ゾーン インスタンスは費用削減に優れており、自動レプリケーションによりマルチリージョンのデプロイにシームレスにスケールアップできます。また、マルチリージョン インスタンスを実行している場合、データベースがリージョンの障害から保護され、業界最高水準の 99.999% の可用性を実現します。
読み取りと書き込みのスケーラビリティに制限なし
Bigtable はコンピューティング リソースとデータ ストレージを切り離すことで、処理リソースを透過的に調整できるようにします。ノードを追加するたびに、読み取りと書き込みを同じように処理できるため、水平方向の拡張性を容易に実現できます。Bigtable は、サーバー トラフィックに合わせてリソースを自動的にスケーリングし、シャーディング、レプリケーション、クエリを処理することで、パフォーマンスを最適化します。
高パフォーマンスでワークロードから分離されたデータ処理
Bigtable Data Boost を使用すると、トランザクション ワークロードに影響を与えることなく、分析クエリ、バッチ ETL プロセス、ML モデルのトレーニング、データのエクスポートをより迅速に実行できます。Data Boost では、キャパシティ プランニングや管理は必要ありません。オンデマンド容量を使用して Google の分散ストレージ システムである Colossus に保存されたデータを直接クエリできるため、ユーザーは混在したワークロードを簡単に処理し、安心してデータを共有できます。
豊富なアプリケーションとツールのサポート
Apache HBase API を使用してオープンソース エコシステムに簡単に接続できます。Apache Spark、Hadoop、GKE、Dataflow、Dataproc、Vertex AI Vector Search、BigQuery を用いたシームレスな統合で、データ ドリブン アプリケーションを素早く構築することができます。Java、Go、Python、C#、Node.js、PHP、Ruby、C++、HBase の SQL とクライアント ライブラリ、そして LangChain とのインテグレーションにより、開発チームのニーズに応えます。
エージェント型開発
MCP サポート、Agent Development Kit(ADK)、LangChain のインテグレーションにより、プロセス自動化や会話型ユーザー エクスペリエンスをサポートするエージェント アプリケーションを簡単に構築できます。Bigtable Agent Skills を Antigravity、お気に入りの IDE、または CLI とともに使用することで、デベロッパーの生産性を次のレベルに引き上げ、Bigtable でより多くのものをより迅速に構築できます。
費用はすべて明示
IOPS やバックアップの取得や復元には費用がかかりません。また、ワークロードの増加に伴う予算への影響による、不均衡な読み取り/書き込み料金も発生しません。
リアルタイムの変更データ キャプチャとイベント処理
Bigtable 変更ストリームを使用して Bigtable データベースから変更データを取得し、他のシステムと統合して、分析、イベントのトリガー、コンプライアンスを実現します。
エンタープライズ クラスのセキュリティと制御
顧客管理の暗号鍵(CMEK)、Cloud External Key Manager のサポート、IAM インテグレーションによるアクセスと制御、VPC-SC のサポート、アクセスの透明性、アクセス承認、包括的な監査ロギングにより、データを確実に保護し、規制を遵守できます。きめ細かなアクセス制御により、テーブル、列、行のレベルでアクセスを承認できます。

オブザーバビリティ
サーバーサイドの指標で Bigtable データベースのパフォーマンスをモニタリングする。Key Visualizer インタラクティブ モニタリング ツールで使用パターンを分析する。クエリの統計データ、テーブルの統計情報、ホット タブレット ツールを使用してクエリ パフォーマンスの問題のトラブルシューティングを行い、クライアントサイドのモニタリングによりレイテンシの問題を迅速に診断できます。
障害復旧
費用対効果の高い方法でデータベースの増分バックアップを即座に取得し、オンデマンドで復元します。復元力を高めるためにバックアップを異なるリージョンに保存し、インスタント間や、テスト環境と本番環境のプロジェクト間で簡単に復元できます。

リアルタイム分析
ータの鮮度を高め、クエリのレイテンシを短縮
学習用リソース
ータの鮮度を高め、クエリのレイテンシを短縮
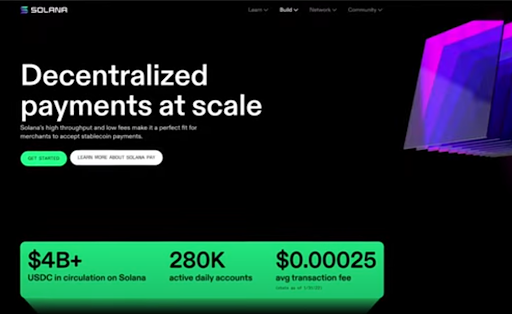
広告テクノロジーと小売
エクスペリエンスをリアルタイムでパーソナライズ
学習用リソース
エクスペリエンスをリアルタイムでパーソナライズ
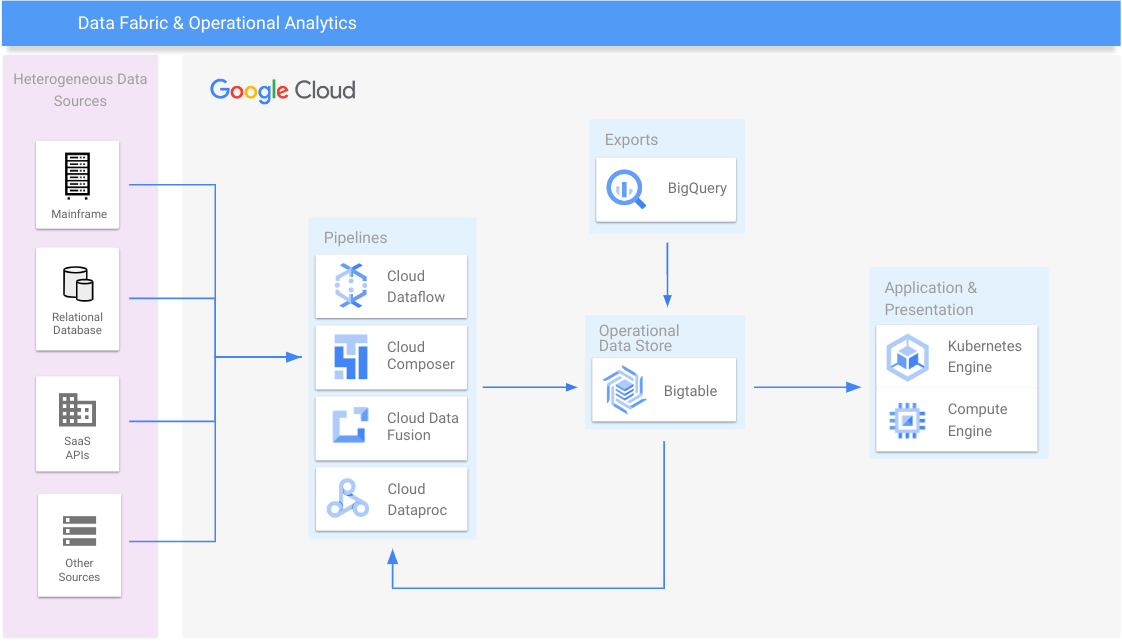
データ ファブリックと運用分析
データサイロを統合し、以前のシステムをスケールアウトする
学習用リソース
データサイロを統合し、以前のシステムをスケールアウトする
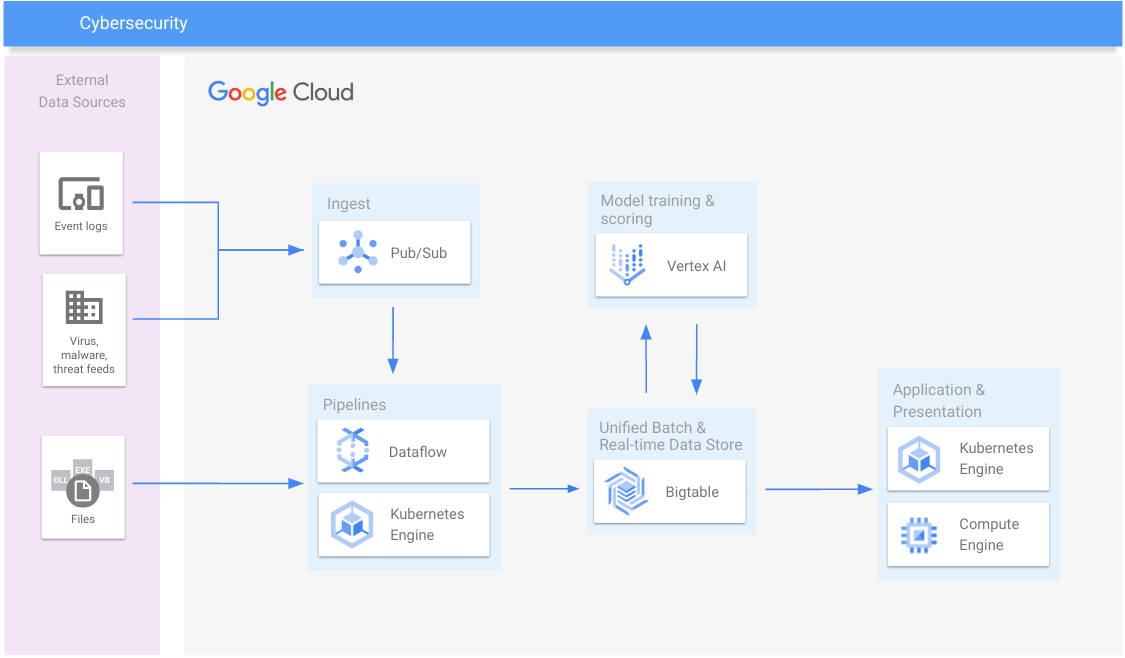
サイバーセキュリティ
マルウェアや支払いに関する不正行為を検出し、スパムや詐欺を阻止
学習用リソース
マルウェアや支払いに関する不正行為を検出し、スパムや詐欺を阻止
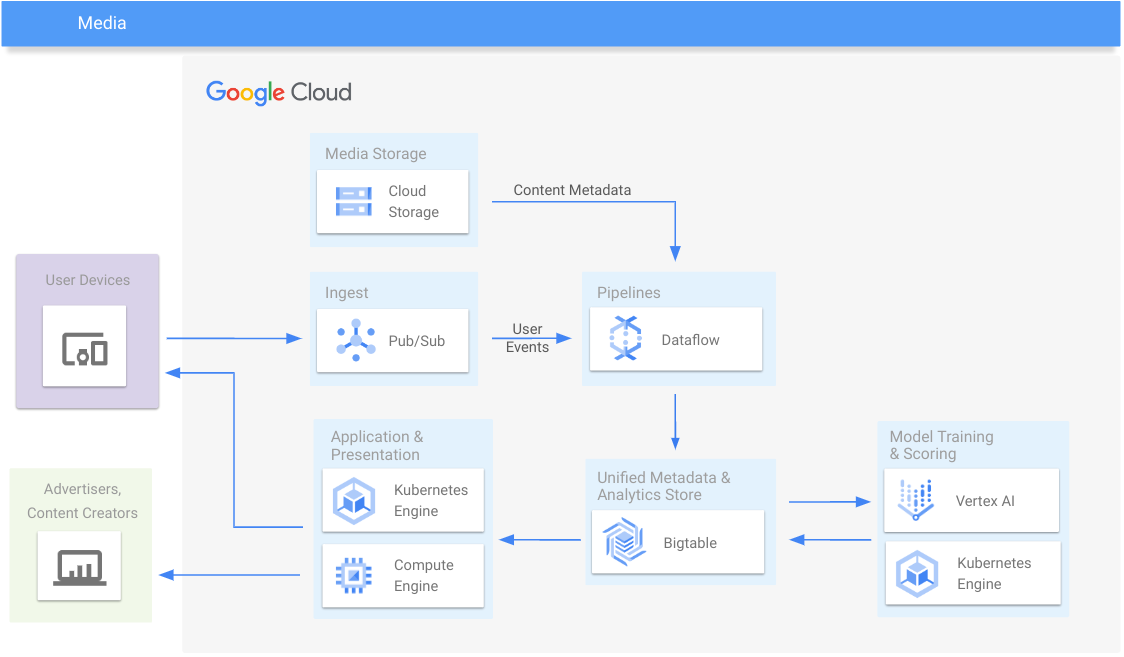
メディア
メディア コンテンツとエンゲージメント分析の提供
学習用リソース
メディア コンテンツとエンゲージメント分析の提供
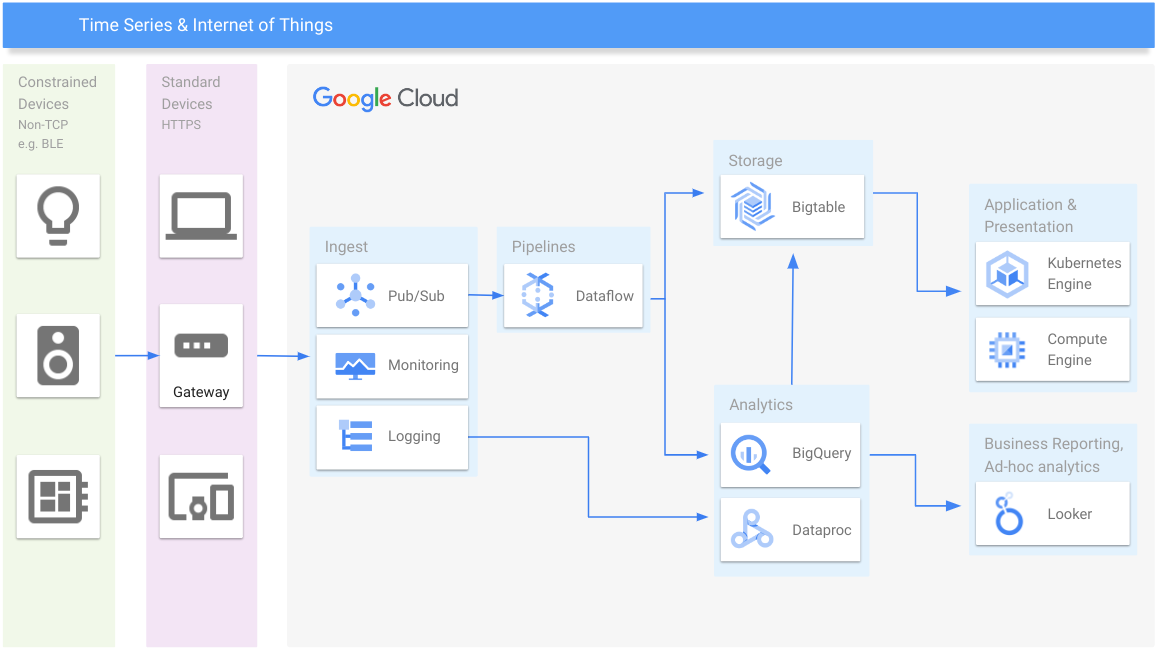
時系列と IoT
あらゆる規模の時系列データを管理
学習用リソース
あらゆる規模の時系列データを管理
ML インフラストラクチャ
モデルのトレーニングとサービス提供のスケーリング。
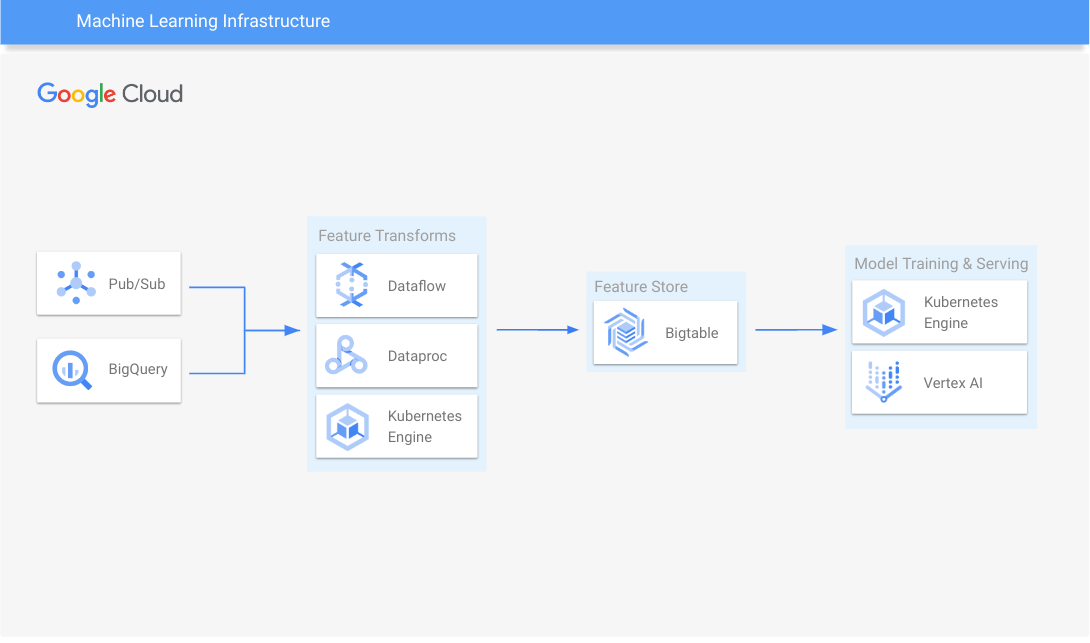
一般的なオープンソースの特徴量ストアで Bigtable を使用する方法をご覧ください
学習用リソース
モデルのトレーニングとサービス提供のスケーリング。
一般的なオープンソースの特徴量ストアで Bigtable を使用する方法をご覧ください
料金
| Bigtable の料金の仕組み | Spanner の料金は、コンピューティング容量、データベース ストレージ、バックアップ ストレージ、ネットワーク使用量に基づいて決まります。確約利用割引では、さらに料金が下がります。 | |
|---|---|---|
| サービス | 説明 | 価格 |
コンピューティング容量 | Enterprise エディション ML、時系列、運用分析、ユーザー向けアプリケーションを大規模にサポートする主要機能を提要し、数ミリ秒のレイテンシを実現します。 コンピューティング容量はノードとしてプロビジョニングされます。 | 目安 $0.65 1 ノード、1 時間あたり |
Enterprise Plus エディション 最高レベルの構成可能性、パフォーマンス、オブザーバビリティ、ガバナンスを備え、極めて要求の厳しいワークロードをサポートします。Enterprise エディションのすべての機能が含まれており、ミリ秒未満のレイテンシを実現します。 コンピューティング容量はノードとしてプロビジョニングされます。 | 目安 $0.85 1 ノード、1 時間あたり | |
インメモリ階層 ホットスポット耐性が高く、超低レイテンシの読み取りを実現するインメモリ読み取りスループット容量。Enterprise Plus エディションでのみ利用可能。 読み取りスループットは、1 秒あたり 40,000 行(1 KB)単位でプロビジョニングされ、ノードごとに 1 秒あたり最大 120,000 行までプロビジョニングできます。 | 目安 $0.20 40,000 行ごと、1 秒容量あたり | |
Data Boost | バッチ処理のためのオンデマンドの分離されたコンピューティング リソース | 目安 $0.000845 サーバーレス処理ユニットごと、1 時間あたり |
データ ストレージ | SSD 料金はテーブルの物理サイズに基づきます。各レプリカは個別に課金されます。低レイテンシのサービングにおすすめです。 | 目安 $0.17 GB 単位/月 |
HDD 料金はテーブルの物理サイズに基づきます。各レプリカは個別に課金されます。低頻度アクセス(IA)では HDD が使用され、同一の料金が課金されます。 | 目安 $0.026 GB 単位/月 | |
バックアップ | 標準バックアップ 料金はバックアップの物理サイズに基づきます。Bigtable バックアップは増分的です。 | 目安 $0.026 GB 単位/月 |
ホット バックアップ 復元時間を大幅に短縮できるように最適化されています。料金はバックアップの物理サイズに基づきます。 | 目安 $0.12 GB 単位/月 | |
ネットワーク | Ingress | 無料 |
同一リージョン内の下り(外向き) | 無料 | |
リージョン間の下り(外向き) | 目安 $0.10 GB 単位 | |
レプリケーション | 同一リージョン内 | 無料 |
リージョン間 | 目安 $0.01 GB 単位 | |
Bigtable の料金の仕組み
Spanner の料金は、コンピューティング容量、データベース ストレージ、バックアップ ストレージ、ネットワーク使用量に基づいて決まります。確約利用割引では、さらに料金が下がります。
コンピューティング容量
Enterprise エディション
ML、時系列、運用分析、ユーザー向けアプリケーションを大規模にサポートする主要機能を提要し、数ミリ秒のレイテンシを実現します。
コンピューティング容量はノードとしてプロビジョニングされます。
Starting at
$0.65
1 ノード、1 時間あたり
Enterprise Plus エディション
最高レベルの構成可能性、パフォーマンス、オブザーバビリティ、ガバナンスを備え、極めて要求の厳しいワークロードをサポートします。Enterprise エディションのすべての機能が含まれており、ミリ秒未満のレイテンシを実現します。
コンピューティング容量はノードとしてプロビジョニングされます。
Starting at
$0.85
1 ノード、1 時間あたり
インメモリ階層
ホットスポット耐性が高く、超低レイテンシの読み取りを実現するインメモリ読み取りスループット容量。Enterprise Plus エディションでのみ利用可能。
読み取りスループットは、1 秒あたり 40,000 行(1 KB)単位でプロビジョニングされ、ノードごとに 1 秒あたり最大 120,000 行までプロビジョニングできます。
Starting at
$0.20
40,000 行ごと、1 秒容量あたり
Data Boost
バッチ処理のためのオンデマンドの分離されたコンピューティング リソース
Starting at
$0.000845
サーバーレス処理ユニットごと、1 時間あたり
データ ストレージ
SSD
料金はテーブルの物理サイズに基づきます。各レプリカは個別に課金されます。低レイテンシのサービングにおすすめです。
Starting at
$0.17
GB 単位/月
HDD
料金はテーブルの物理サイズに基づきます。各レプリカは個別に課金されます。低頻度アクセス(IA)では HDD が使用され、同一の料金が課金されます。
Starting at
$0.026
GB 単位/月
バックアップ
標準バックアップ
料金はバックアップの物理サイズに基づきます。Bigtable バックアップは増分的です。
Starting at
$0.026
GB 単位/月
ホット バックアップ
復元時間を大幅に短縮できるように最適化されています。料金はバックアップの物理サイズに基づきます。
Starting at
$0.12
GB 単位/月
ネットワーク
Ingress
無料
同一リージョン内の下り(外向き)
無料
リージョン間の下り(外向き)
Starting at
$0.10
GB 単位
レプリケーション
同一リージョン内
無料
リージョン間
Starting at
$0.01
GB 単位
ビジネスケース
他の企業が Bigtable を利用して革新的なアプリを作成し、優れたカスタマー エクスペリエンスを実現し、コストを削減し、ROI を向上させた方法をご覧ください



メリットとお客様
あらゆるニーズに応じて無制限にスケーリングできる革新的なアプリケーションで、ビジネスを拡大しましょう。
クラス最高のコスト パフォーマンスを実現します。料金は使用した分に対してのみ発生します。
他の NoSQL データベースから簡単に移行できます。オープンソースの API と移行ツールを使用してハイブリッド クラウドやマルチクラウドのデプロイを実行できます。















パートナーとインテグレーション
評価からビジネスケース、移行、Bigtable での新しいアプリのビルドまで、お客様のあらゆる段階で、Bigtable の専門知識を持つパートナーをご活用ください。

































システム インテグレータ
ビジネスに最適なパートナーやサードパーティ統合について詳細を確認するには、パートナー ディレクトリをご覧ください。
詳細
よくある質問
Bigtable はどのような種類のデータベースですか?
Bigtable は NoSQL データベース サービスです。具体的には、数万列からなる非常に幅の広いテーブルに対応する Key-Value ストアであることから、ワイドカラム型データベースまたは分散多次元マップとも呼ばれます。「ゼロ SQL」というよりは、「SQL にとどまらない」という意味で、Bigtable は NoSQL データベースです。キーと値の検索だけでなく、集計やグローバル セカンダリ インデックスなど、多くの機能をサポートしています。
Bigtable は、Apache HBase や Cassandra など、影響を受けた一般的なオープンソース プロジェクトとよく似ているため、Google Cloud で高パフォーマンスで費用対効果の高いフルマネージド NoSQL データベース ソリューションを求める大量のデータを扱うお客様にとって、最も一般的な移行先です。
Bigtable は SQL をサポートしていますか?
Bigtable は、Key-Value API に加えて、次の 3 つの方法で SQL クエリもサポートしています。
- 低レイテンシのアプリケーション開発のために、Bigtable は SQL クエリ API を提供しています。この API は、Cassandra クエリ言語(CQL)に似たワイドカラム型データモデルの拡張機能を使用して GoogleSQL を基盤として構築されています。集計(GROUP BY)、ウィンドウ処理、地理空間処理、JSON 処理関数、ベクトル検索(kNN)など、200 以上の関数をサポートしています。Bigtable は、標準クエリ構文とパイプクエリ構文の両方をサポートしています。
- データ サイエンスのユースケースやその他の種類のバッチ処理や ETL の場合、Bigtable は Spark クライアントを使用して SparkSQL をサポートします。
- 事後探索的分析を行う場合や、バッチ分析のために複数のソースからデータをブレンドする場合は、BigQuery から Bigtable データにアクセスすることもできます。BigQuery で Bigtable テーブルを登録するだけで、ETL やデータの重複なしに、他の BigQuery テーブルと同様にクエリできます。
データベースを Bigtable に移行するにはどうすればよいですか?
Bigtable が提供する Apache Cassandra と HBase API と移行ツールを使用すると、少ない労力で正確なデータ移行を実現することで、オンボーディングをより迅速かつ簡単に行うことができます。Bigtable の HBase レプリケーション ライブラリと Cassandra 移行ツールにより、ダウンタイムなしのライブ マイグレーションが可能になります。Bigtable には、DynamoDB や Aerospike からの移行を簡素化するユーティリティも用意されています。
Bigtable はサーバーレスですか?
Bigtable のストレージは、サーバーレス モデルと同様に、使用した GB 単位で課金されます。また、Bigtable では水平方向の線形スケーリングが可能で、需要の変動に応じてコンピューティング リソースを自動的にスケールアップまたはスケールダウンします。そのため、ストレージやコンピューティングの容量について長期的なコミットメントは必要ありません。ただし、低レイテンシ コンピューティングの料金は容量ベースであり、リクエスト単位ではなくノード単位で課金されます。ここでは各ノードが 1 秒あたり最大 17,000 のリクエストを処理できます。このため、Bigtable の料金は大規模なワークロードには有利ですが、小規模なアプリケーションにはあまり適していません。小規模なアプリケーションの場合、Firestore などの Google Cloud データベースの方が適している可能性があります。
Bigtable ではバッチデータ処理に対して Data Boost を利用できます。Data Boost ではサーバーレス処理ユニット(SPU)単位で課金されます。
Bigtable は永続的キャッシュですか?
Bigtable は、永続性のあるキャッシュではなく、キャッシュのようなパフォーマンスを持つデータベースです。強力なデータベース内処理機能、SQL API、継続的なマテリアライズド ビュー、非同期セカンダリ インデックスを提供するほか、RDMA テクノロジーを使用して RAM に直接アクセスできるため、データベース サーバーの CPU 容量に制限されない高スループットとパフォーマンスを実現します。Bigtable を MemoryDB のような耐久性のあるキャッシュ ソリューションの代替として使用することは可能ですが、その逆は必ずしも当てはまりません。これは、Redis のようなソリューションはデータベースではなくキャッシュとして設計されているためです。


















