How YouTube uses Bigtable to power one of the world’s largest streaming services
Sudarshan Kadambi
Engineering Manager, Bigtable
Bin Liu
Software Engineer, YouTube Data Warehouse
Cloud Bigtable is a popular and widely used key-value database available on Google Cloud. The service provides elastic and high scale, cost efficiency, excellent performance characteristics, and 99.999% availability SLA. This has led to massive adoption with customers trusting Bigtable to run a variety of their mission-critical workloads.
Bigtable has been in continuous production use at Google for more than 15 years now, processing over 6 billion requests per second at peak and with over 10 exabytes of data under management.
One Bigtable user within Google is YouTube, one of the largest streaming services in the world, supporting millions of creators and billions of users. YouTube uses Bigtable for a wide range of use cases from helping connect people with new content based on what they’ve watched, to recording metrics like view counts to powering advertising functionality.
In this post, we look at how YouTube uses Bigtable as a key component within a larger data architecture powering its reporting dashboards and analytics.
The YouTube Data Warehouse
YouTube captures several pieces of metadata about core entities such as videos, channels and playlists. The metadata includes attributes such as video upload times, titles, descriptions, category and video monetizability. The relationships between entities are also captured. For example, a video can be uploaded by one channel or owner, but its asset rights can be claimed by multiple owners.
The YouTube Data Warehouse stores and serves such dimensional metadata to drive data pipelines and dashboards across YouTube. The warehouse is built on Bigtable. Let’s look at some examples of how the warehouse is used for analytics.
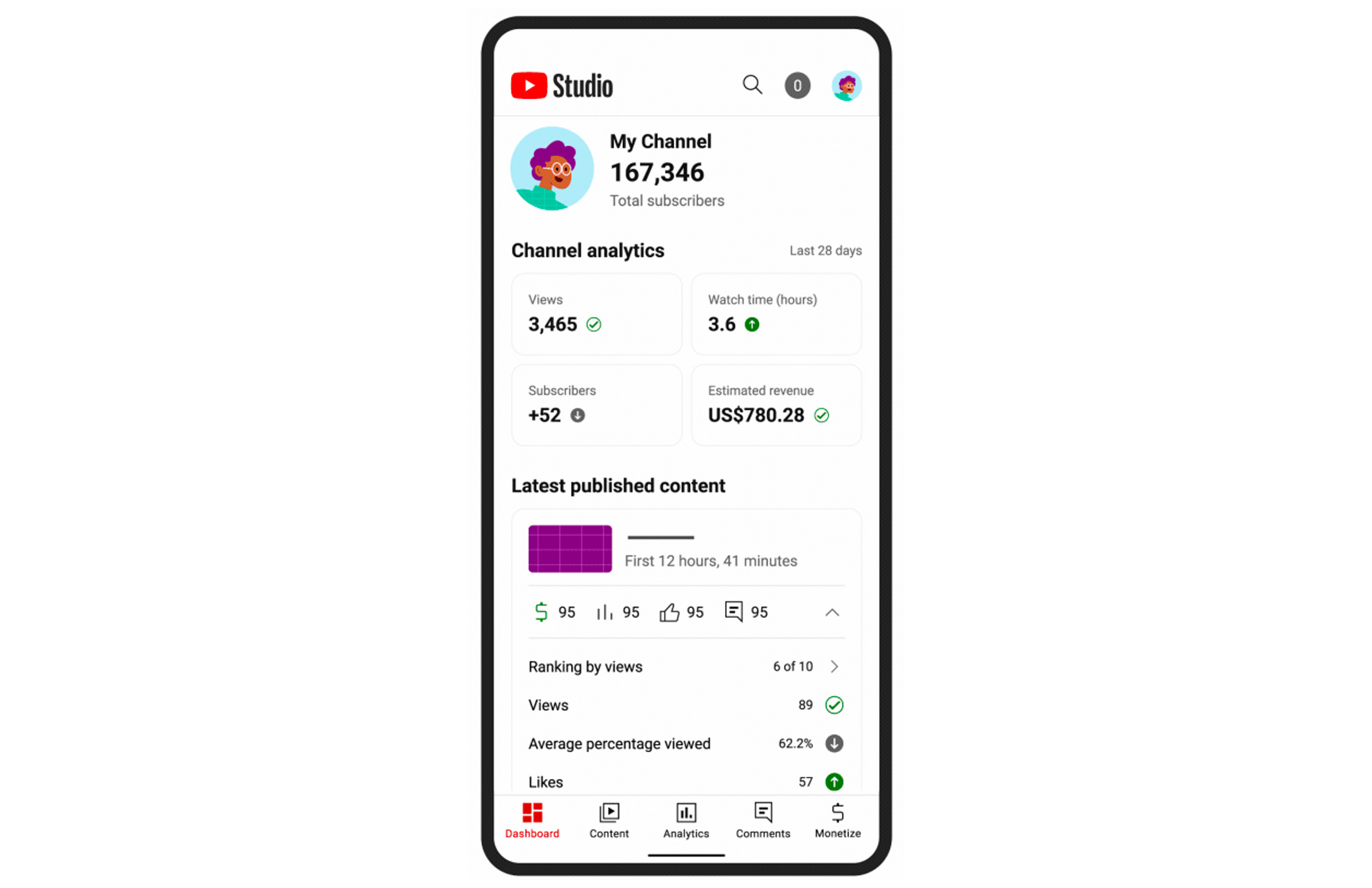
The Creator Analytics pipeline populates dashboards that give millions of creators insights into viewership data for the content they have created. The pipeline gets viewership data from YouTube service logs, in a privacy-compliant manner with strict safeguards. The logs are processed, sessionized and then enriched with video attributes and other forms of metadata from the warehouse to support functionality on the dashboard. Content creators use the dashboard to understand how many views and impressions a given video achieved with segment breakdowns, video trends over time, and so on.
The Payments pipeline provides daily reports with estimated earnings to creators. This is based on video viewership data. This pipeline gets video metadata, asset rights and ownership claims from the warehouse and determines how the earnings should be split across owners.
The business requirements of the warehouse are as follows:
Provide historical versioning of entity data
Support near real-time ingestion of data sources
Allow for querying this data at the scale and capacity necessary for reporting needs across YouTube
Be compliant with YouTube’s policies around user data privacy protection
Before we discuss how Bigtable helps YouTube meet these business requirements for its warehouse, let's look at its architecture at a high level.
Architecture
The processing pipelines that feed into the data warehouse have three distinct stages.
In the first stage, data from upstream canonical sources like operational databases (Spanner and other Bigtable databases) is read and written in its raw form to the Bigtable warehouse database.
This raw data is read back from the warehouse, cleaned, transformed and stored back into the warehouse. The transformations ensure that the data is normalized across sources, has an efficient representation and is easy to understand and use. This helps ensure consistent reporting across YouTube.
The standardized data is then made available to consumers through real-time point lookups or periodic batch dumps.
There is a 1:1 mapping between entity types (e.g. playlists) and a table in the warehouse Bigtable database. An entity (e.g., a single playlist and its attributes) is stored in a single row and contains data from different upstream sources, encoded as Protobufs.
The warehouse contains dimensions tracked in two different ways. Standard dimension tables show the current status for the entity. For instance if a creator uploads a new video, a new row is written to the video entity table. If a week later the creator changes the video's title, the original row is altered with the new title. If the creator deletes the video, the row is deleted from the table.
Change-tracked dimension tables identify changes to an entity over time. For example, if a creator uploads a new video, a new row is written. If a week later the creator changes the video's title, the original row remains in the table, with a mark showing it is no longer current and a new row is created with the new title. If the creator deletes the video, the row is marked deleted and purged from the warehouse per YouTube’s user data privacy protection policies. Change-tracked dimension tables provide point in time access to historical metadata through “as of” queries. This is critical for data backfills (e.g., restate data due to data quality issues) and for backtesting (e.g., offline model evaluation on historical data).
Why Bigtable?
There are a few reasons why Bigtable is a compelling choice for the YouTube Data Warehouse.
Flexible schema and data models
Bigtable has a flexible data model, which makes it suitable for use cases where we want the cost of integrating a new data source to be minimal. We want to be able to quickly land raw data and then as we understand the semantics of the data better, start to create a more appropriate and standardized data model. This allows the architecture and teams to be more responsive to an environment of constant change.
Scale, cost and performance
The warehouse stores metadata about all of YouTube’s core entities going back in time and underpins a majority of the reporting analytics at YouTube. This is a massive amount of data that needs to be stored and regularly processed and needs a scalable database with a low cost of ownership. Bigtable’s price/performance is industry-leading. Its high read and write throughput per $ of resource spend is well suited for the batch analytics that consumes data from the warehouse.
The warehouse is used by a variety of downstream clients with different access patterns, latencies and throughput requirements. Bigtable supports the ability to associate priorities with requests, allowing high-priority serving traffic to be interleaved with lower-priority analytics traffic without contending with each other. Thus, Bigtable makes it possible for the warehouse to support a heterogeneous client base with hybrid transactional and analytical (HTAP) processing needs.
Change Data Capture
The warehouse makes use of Bigtable’s Change Streams feature. As upstream data changes, the corresponding entity rows in Bigtable are invalidated. Streaming pipelines that consume the Bigtable change stream identify entity rows that have been invalidated to go and get the latest data from the source(s). This ensures that entities always have fresh metadata to use in reporting.
Conclusion
For operational analytics workloads such as the ones serviced by the YouTube Data Warehouse, Bigtable offers low-cost storage with excellent performance. Its flexible data model reduces the friction inherent in integrating new data sources into the warehouse, allowing for data to be landed quickly in its raw form and then gradually be more structured as we better understand the semantics of the data. Such iterative processes for data modeling create greater organizational agility and responsiveness to change.
Learn more
To get started with Bigtable, try it out with a Qwiklab and learn more about the product here.




