Twitter の広告エンゲージメント分析プラットフォームをモダナイズ
Google Cloud Japan Team
※この投稿は米国時間 2020 年 3 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
Twitter の広告プラットフォームでは、日常業務の一環として数十億もの広告エンゲージメント イベントが日々発生しています。そしてこれらのイベントのひとつひとつが、ダウンストリームの数百もの集約指標に影響を及ぼす可能性があります。広告主がユーザー エンゲージメントを測定し、広告キャンペーンを効率よく追跡できるように、Twitter はさまざまな分析ツール、API、ダッシュボードを提供しています。これらは 1 秒あたりに数百万もの指標をほぼリアルタイムで集約することが可能です。
本投稿では、Steve Niemitz がリードを務めるTwitter の収益データプラットフォームエンジニアチームが、Twitter の広告分析プラットフォームの収益正確性と信頼性を向上させるために、どのようにオンプレミスのアーキテクチャを Google Cloud に移行したかを詳細に解説します。
移行決定の経緯
Twitter はこの 10 年間で、世界各国で増え続けるユーザーによる負荷に対応するための強力なデータ変換パイプラインを開発しました。こうしたパイプラインのうち、初期に開発されたものはすべて、当初は Twitter の自社データセンターで実行されていました。入力データは、さまざまなソースから Hadoop Distributed File System(HDFS)に、LZO 圧縮した Thrift ファイルとして Elephant Bird コンテナ形式でストリーミングされていました。このデータは次に、Scalding データ変換パイプラインで処理され、バッチに集約されました。その後、集約されたバッチは、Twitter が自社開発した分散型 Key-Value ストアである Manhattan に出力され、サービス提供されました。Twitter はまた、リアルタイム分析を提供する必要がありました。そこでさらに、Twitter の自社開発システムである Eventbus(DistributedLog を基盤に構築されたメッセージ ツール)、Heron(ストリーミング処理エンジン)、Nighthawk(シャーディングされた Redis デプロイメント)を使用したストリーミング システムによって、現在時刻と最後のバッチ実行との間の差異を埋めることで、リアルタイム分析を支えていました。
このシステムは圧倒的なスケールを一貫して維持してはいましたが、当初の設計と実装はいくつかの限界に達し始めていました。特に、システムの中でも長年にわたって有機的に成長を遂げてきた部分は、新しい機能による構成や拡張が難しくなっていました。複雑で長時間実行されるジョブの一部は、信頼性も低く、散発的なエラーを引き起こしていました。また、従来のエンドユーザー サービス システムは運用コストが非常に高く、大規模なクエリに対応できませんでした。
そこで、今後数年にわたって予想されるユーザー エンゲージメントの拡大に備えるとともに、新機能の開発を効率的に行うため、Twitter の収益データ プラットフォーム エンジニア チームは、アーキテクチャを見直し、より柔軟でスケーラブルなシステムを Google Cloud にデプロイすることを決定しました。
プラットフォームのモダナイゼーション: 最初のイテレーション
2017 年の中頃、Niemitz 氏のチームは、広告データ プラットフォームのモダナイゼーションにおける再設計の最初のイテレーションに取り組みました。その結果、Twitter は Google Cloud とパートナーシップを結ぶことになりました。
当初、チームは従来のデータ集約機能である Scalding パイプラインは変更せずに、これらを Twitter のデータセンターで実行し続けることにしました。ただし、バッチレイヤの出力先は、Manhattan から Google Cloud の以下の 2 つの別個のストレージ ロケーションに切り替えました。
●BigQuery - Google のサーバーレスでスケーラビリティの高いデータ ウェアハウス。アドホック クエリとバッチクエリに対応。
●Bigtable - Google の低レイテンシでフルマネージドの NoSQL データベース。オンライン ダッシュボードとコンシューマー API のバックエンドとして機能。
Scalding パイプラインからの出力集計が、最初に Hadoop シーケンス ファイルから Avro オンプレミスにコード変換され、Cloud Storage への 4 時間の一括処理でステージングされてから BigQuery に読み込まれます。次に、Google Cloud のフルマネージド ストリーミングおよびバッチ分析サービスである Dataflow にデプロイされたシンプルなパイプラインが、BigQuery からデータを読み取って、軽微な変換を適用します。最後に、Dataflow パイプラインが Bigtable に結果を書き込むように変更しました。
チームは、Bigtable から集計値を取得し、エンドユーザーのクエリを処理する新しいクエリサービスを作成しました。また、Bigtable インスタンスと同じリージョンにある Google Kubernetes Engine(GKE)クラスタ内にこのクエリサービスをデプロイし、データアクセスのレイテンシを最適化しました。
このアーキテクチャは次のとおりです。
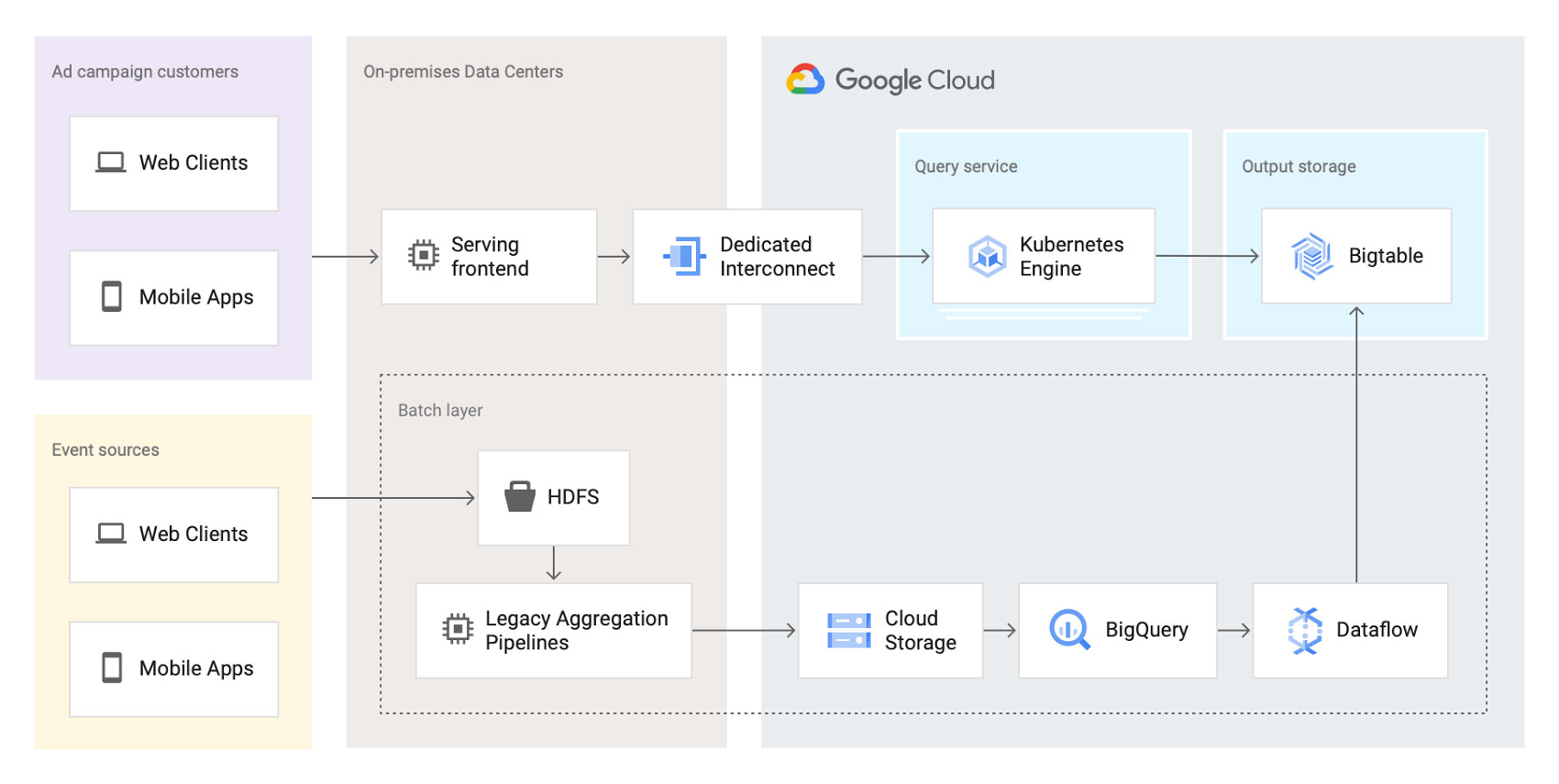
この最初のイテレーションを行った時点で、すでに多くの重要なメリットがもたらされました。
●全体的な移行作業のリスクが低減され、集計ビジネス ロジックとストレージを同時に移行することを避けられました。
●エンドユーザー サービス システムのパフォーマンスが大幅に向上しました。Bigtable の線形スケーラビリティと、データアクセスにおける極めて低いレイテンシのおかげで、サービス システムの P99 レイテンシが 2 秒以上から 300 ミリ秒まで低下しました。
●信頼性が大幅に向上しました。今では、チームがサービス システムのために呼び出されることはめったになくなりました。
プラットフォームのモダナイゼーション: 2 つ目のイテレーション
新しいサービス システムを配置したので、Twitter チームは 2019 年に、Google Cloud テクノロジーを使用してデータ分析パイプラインの残りの部分の再設計を開始しました。この再設計では、次のような既存の課題を解決することを目指しました。
●バッチレイヤとストーミング レイヤが異なるシステムで実行されていたため、ロジックの多くがシステム間で重複していました。
●サービス システムをクラウドに移行したものの、Hadoop 集計プロセスの既存の課題は残ったままでした。
●リアルタイム レイヤの実行は高コストで、オペレーションに相当な注意を払う必要がありました。
チームはこのような課題を解決できるテクノロジーの評価を開始しました。まず、オープンソースのストリーム処理フレームワークである Apache Flink、Apache Kafka Streams、Apache Beam を検討しました。可能性のある選択肢をすべて評価したあと、チームは主に次のような理由から Apache Beam を選択しました。
●複数のクラスタ間で極めて大規模に実行できる 1 回限りのオペレーションを、Beam は組み込みでサポートしている。
●他の Google Cloud プロダクト(Bigtable、BigQuery、Google Cloud のフルマネージドのリアルタイム メッセージング サービスである Pub/Sub など)と緊密に統合できる。
●Beam のプログラミング モデルによって、バッチとストリーミングを統合し、1 つのジョブでバッチ入力(Cloud Storage)またはストリーミング入力(Pub/Sub)いずれかのオペレーションが可能。
●Beam パイプラインを Dataflow のフルマネージド サービスにデプロイできる。
Dataflow のフルマネージドなアプローチと Beam の包括的な機能セットによって、Twitter はデータ変換パイプラインの構造を簡素化できたほか、全体的なデータ処理の容量と信頼性を向上させることができました。
2 つ目のイテレーションを行った後のアーキテクチャは次のとおりです。
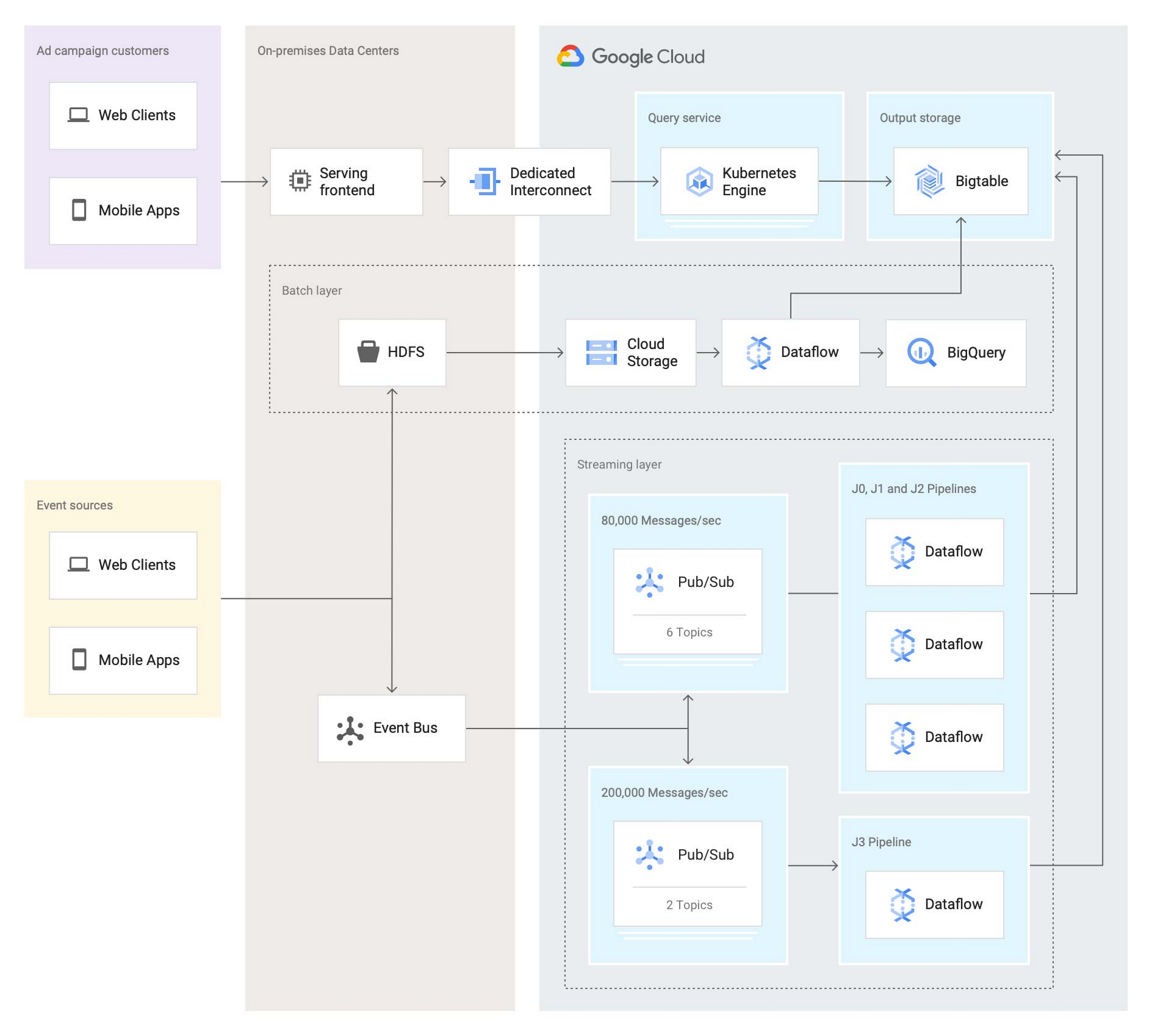
この 2 つ目のイテレーションでは、Twitter チームは次のようにバッチレイヤを再実装しました。まず、データがオンプレミス HDFS から Cloud Storage にステージングされます。次に、Dataflow のバッチジョブが Cloud Storage から定期的にデータを読み込み、集計を処理し、結果を BigQuery(アドホック分析用)と Bigtable(サービス システム用)の両方に書き込みます。
Twitter チームは、Google Cloud でまったく新しいストリーミング レイヤもデプロイしました。現在、データの取り込みは、オンプレミスのサービスが Avro 形式メッセージの 2 つのストリームを Pub/Sub に push する仕組みになっています。各メッセージには、100~1,000 件の集計に関わる複数の元イベントデータのバンドルが含まれています。これを受け、1 秒あたり 300 万件以上の集計が 4 つの Dataflow ジョブ(上の図の J0~3)によって実行されます。各 Dataflow ジョブは異なるストリームやトピックからのメッセージを使用しますが、どのジョブも同じトポロジとなっています。
このうち、重要度の高いデータを含む 1 つのストリームは、1 秒あたりメッセージ 20 万件の速さでシステムに流入し、2 つの Pub/Sub トピックにパーティショニングされます。2 つにパーティショニングされたこのストリームは、1 つの Dataflow ジョブ(図の J3)によって使用されます。1 秒あたり 40 万件の集計が行われ、その結果が Bigtable のテーブルに出力されます。
重要度が低めで量が多いデータを含むもう一方のストリームは、1 秒あたりメッセージ約 8 万件の速さでシステムに流入し、6 つのトピックにパーティショニングされます。3 つの Dataflow ジョブ(J0、J1、J2)は、この大規模なストリームの処理を共有します。各ジョブで 6 つのトピックのうち 2 つを並行して処理し、その結果を Bigtable のテーブルに出力します。合計すると、これら 3 つのジョブで 1 秒あたり 200 万件以上の集計を処理します。
大容量のストリームを複数のトピックにパーティショニングすることで、数々のメリットが得られます。
●パーティショニングは、集計キーにハッシュ関数を適用し、その関数の結果を利用可能なパーティション数(この場合は 6)で割ってまとめられています。これにより、ダウンストリーム パイプラインでのキー別グループ化オペレーションの際に、1 つのパーティションのみをスコープにできます。これは一貫した集計結果を得るために必須の条件です。
●Dataflow ジョブにアップデートをデプロイする際、管理者が各ジョブを個別にドレインして順番に再起動できます。これにより、残りのパイプラインの稼働を中断させることなく、エンドユーザーへの影響を最小限に抑えられます。
●現在、3 つのジョブそれぞれで 2 つのトピックを問題なく処理できていますが、必要に応じて 6 つのジョブまで水平スケーリングできる余裕があります。現在のトピック数(6 つ)は任意で決定したものですが、現在のニーズとトラフィックの急増の可能性を考慮してもバランスの良いものとなっています。
ジョブの構成を支援するため、Twitter では当初 Dataflow のテンプレート システムを使用することを検討していました。これは、Dataflow パイプラインを、実行時に構成できる反復可能なテンプレートにカプセル化できる強力な機能です。しかし、時間の経過とともに変化する可能性のあるトポロジにジョブをデプロイする必要があったため、Twitter チームはテンプレート システムではなく、カスタマイズした宣言型システムを導入しました。このシステムでは、pystachio の固有言語(DSL)でジョブに異なるパラメータ(調整パラメータ、操作するデータソース、集計の出力先シンクテーブル、ジョブのソースコードの場所)を指定できます。Flex Templates という新しいメジャー バージョンの Dataflow テンプレートでは、以前のテンプレート アーキテクチャの制限が一部取り除かれており、どんな Dataflow ジョブでもテンプレート化できます。
ジョブ オーケストレーションのため、Twitter チームは Dataflow API を呼び出してジョブを送信するための構成ファイルを処理するカスタム コマンドライン ツールを構築しました。このツールには、以下のような複数の手順を自動的に実行して、デベロッパーによるジョブの更新を可能にする役割もあります。
古いジョブを廃棄する。
Dataflow API を呼び出し、ジョブで使用されるデータソースを識別します(例: Pub/Sub トピック リーダー)。
ドレイン リクエストを開始します。
識別されたデータソースのウォーターマークを Dataflow API でポーリングします。それが最大数に達したらドレインのオペレーションが完了となります。
新しいジョブを更新されたコードで起動する。
このシンプルで柔軟性と機能性に優れた仕組みにより、デベロッパーはジョブ オーケストレーションや基盤となるインフラストラクチャの詳細を気にすることなく、データ変換コードに集中することができます。
今後の対応
Twitter の広告アナリティクス データ プラットフォームを Google Cloud に完全移行して 6 か月が経過し、すでに大きな成果が表れています。Twitter のデベロッパーは、既存のデータ パイプラインをより簡単に構成して新しい機能をすばやく構築できるようになり、俊敏性が向上しました。リアルタイムのデータ パイプラインも信頼性と正確性が大幅に向上しました。これは Beam の 1 回限りのセマンティクスと、Pub/Sub、Dataflow、Bigtable による処理速度とデータ取り込み許容量の増加に拠るところです。
Twitter のエンジニアは、バージョン 2.2 以降、数年間にわたって Dataflow と Beam で快適に作業に取り組み、今後も引き続きその活用範囲を広げていく予定です。最も重要なことは、Twitter チームがまもなくバッチとストリーミングのレイヤを単一の信頼できるレイヤにまとめることです。
このプロジェクトで Twitter チームは一貫して、Google エンジニアと緊密に連携し、意見交換やプロダクト機能強化の議論を深めています。Google Cloud では、Twitter で進行する数々の大規模な移行プロジェクトにおいて、今後も技術協力を継続していきたいと考えています。今後の最新情報にぜひご期待ください。
-By Julien Phalip, Solutions Architect, Google Cloud and Steve Niemitz, Staff Software Engineer, Twitter


