2024 年の Cloud Pub/Sub のハイライト: ネイティブなインテグレーション、共有など
Prateek Duble
Product Management Lead, Cloud Pub/Sub
Joaquín Ibar
Technical Account Manager, Google Cloud
※この投稿は米国時間 2024 年 12 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
急速に進化する昨今のデジタル環境において、組織は実用的な分析情報と意思決定の改善のために、リアルタイム データを活用する必要に迫られています。リアルタイム データの活用度は、ビジネスを進化させ、成長させるための重要な要素として浮上しています。Pub/Sub は Google Cloud のシンプルかつ信頼性の高い、スケーラブルなメッセージング サービスです。ストリーミング データを Google Cloud のエコシステムに取り込むための多用途のエントリ ポイントとして機能し、BigQuery、Cloud Storage、Dataflow などのプロダクトと統合されています。このデータはその後、ダウンストリームの分析、可視化、AI アプリケーションに使用できます。今年は、3 つの主要なデータ分析パターンにおいて、最新のストリーミング ワークロードの需要に対応するための新機能と機能強化を複数リリースしました。
-
ストリーミング取り込み - データを直接 BigQuery と Cloud Storage にストリーミングし、BigQuery での分析や ML などのダウンストリーム ユースケース、Cloud Storage でのバックアップに利用できます。
-
ストリーミング分析 - Dataflow か Apache Flink 向け BigQuery Engine、あるいは BigQuery の継続的クエリを使用して、リアルタイムのイベント ストリームを処理および分析することで、価値の高いリアルタイムの分析情報に基づいてビジネス上の意思決定を行えます。
-
ストリームの共有とエクスポート - 社内チームや外部の顧客とのデータ交換を通じて、貴重なストリーミング データをキュレート、共有、収益化します。
この 3 つの分野に関する 2024 年の Pub/Sub のハイライトを詳しく見ていきましょう。
ストリーミング取り込み
多くのお客様は、あるパブリック クラウド上に一部のワークロードを配置し、別のパブリック クラウド上に他のワークロード(分析など)を配置しています。Pub/Sub は従来、エクスポート サブスクリプションを通じて BigQuery や Cloud Storage へのストリーミング取り込みをサポートしてきました。今年は、AWS Kinesis Data Streams をはじめとするさまざまなソースからの Pub/Sub へのインポートを簡素化しました。Pub/Sub インポート トピックは、AWS Kinesis Data Streams から Pub/Sub にストリーミング データを取り込むための、ノーコードかつワンクリックの新しい方法です。これにより、カスタム コネクタのメンテナンスと実行に関わるオーバーヘッドがなくなり、ストリーミング データの取り込みパイプラインを簡素化できます。
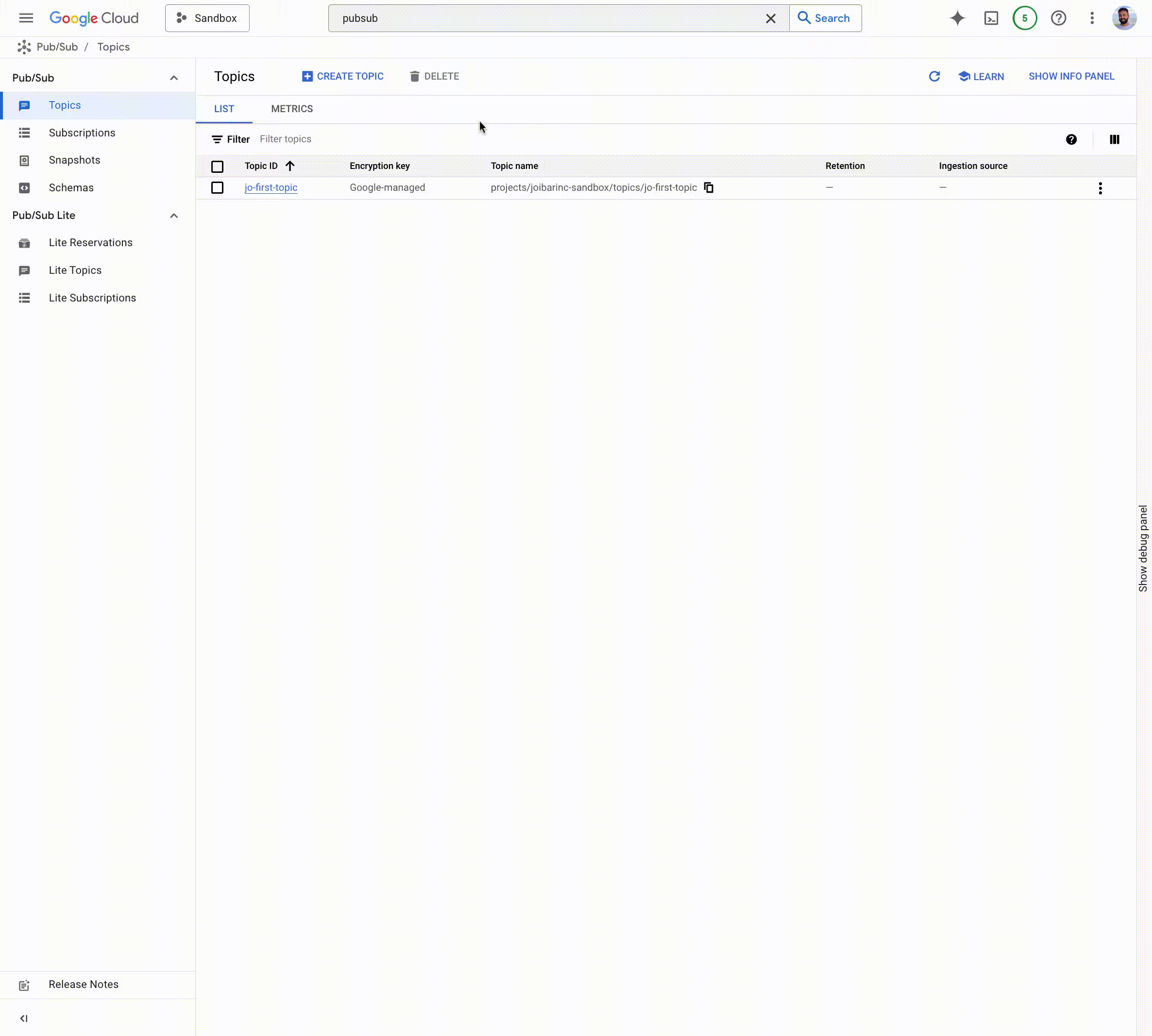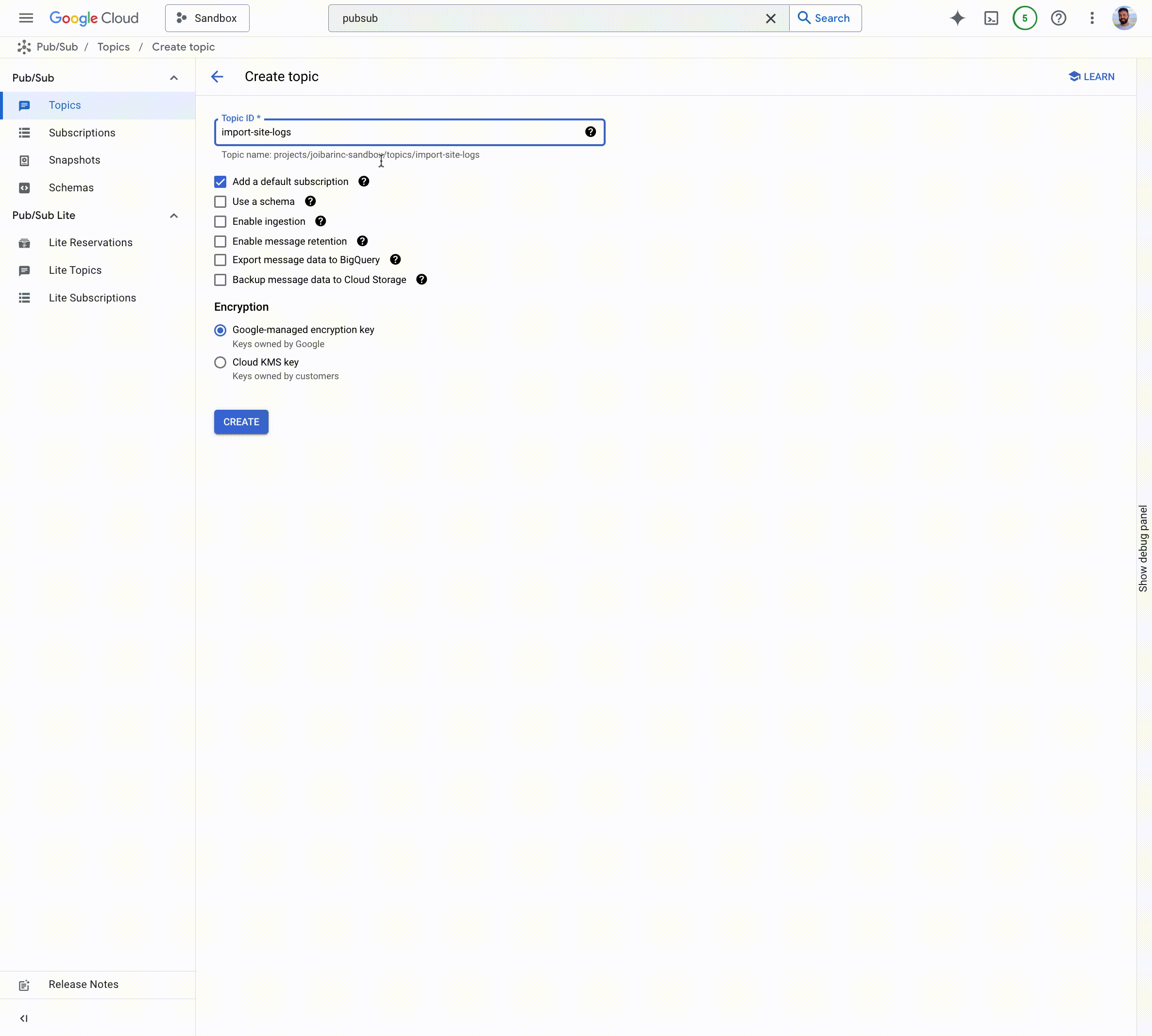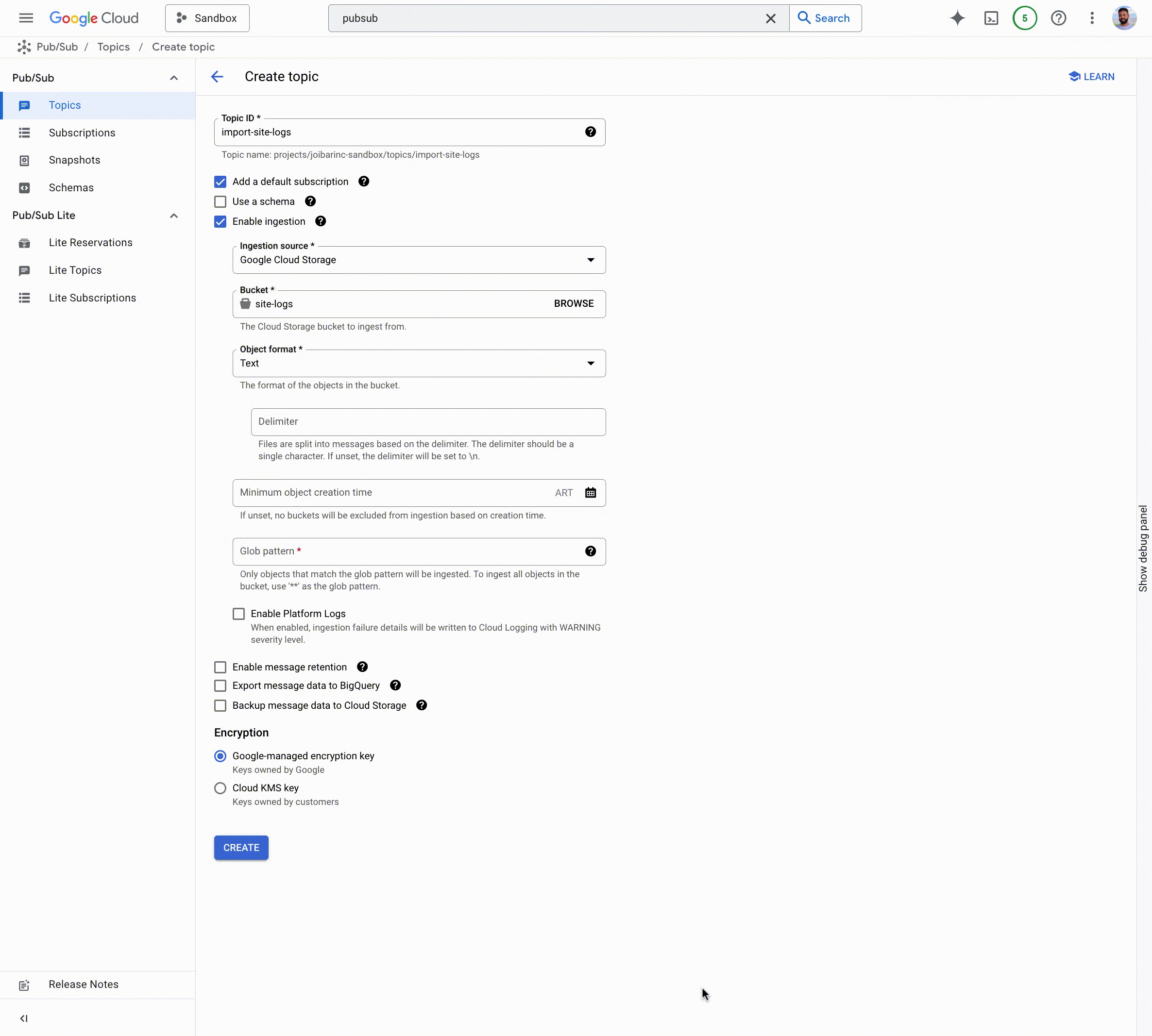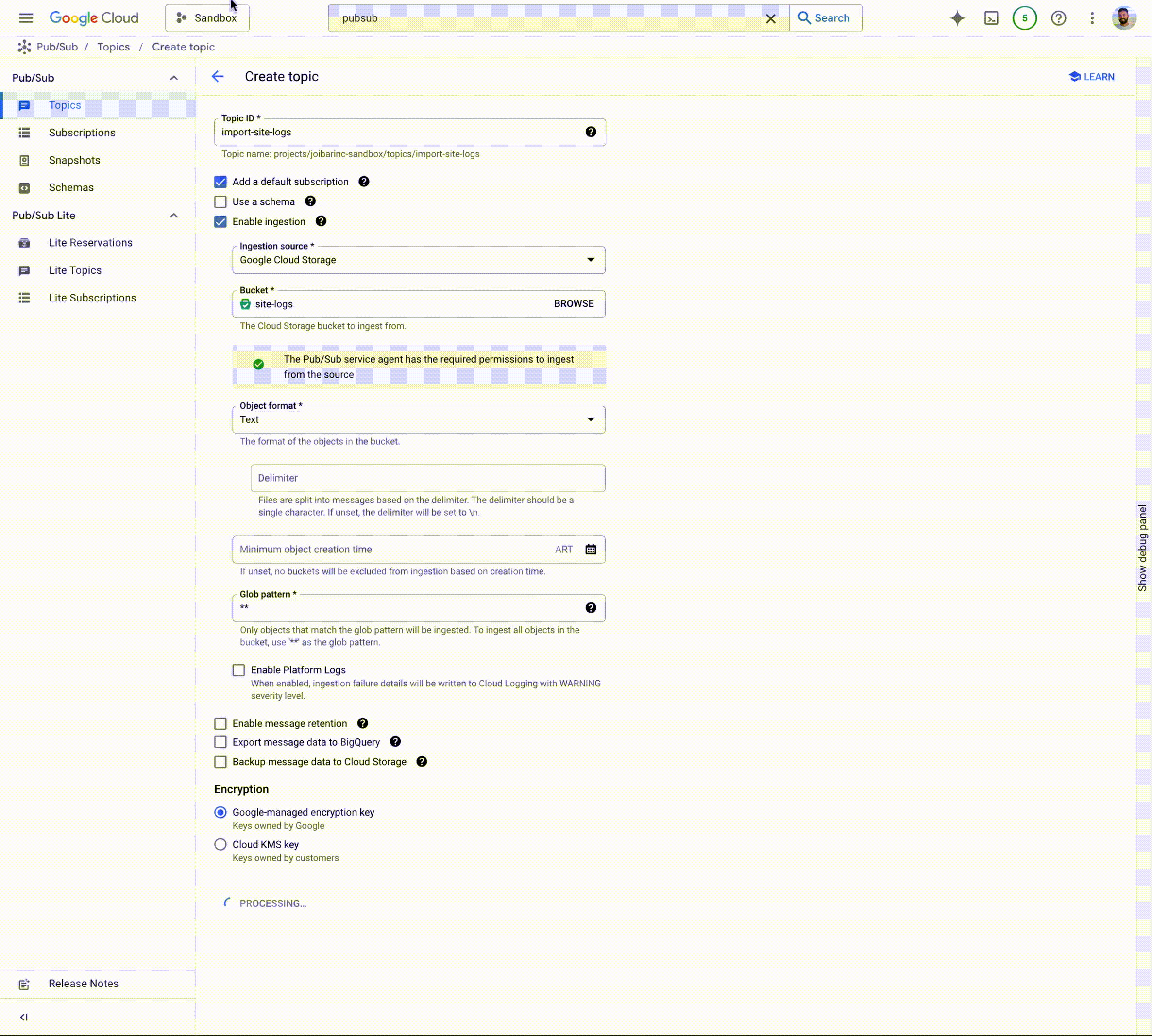
ストリーミング取り込みのもう一つの一般的なユースケースとして、バッチデータの Pub/Sub への取り込みが挙げられます。Cloud Storage から Pub/Sub にデータを取り込むには、以前はカスタム コネクタを構成、デプロイ、実行、管理、スケールするか、Dataflow テンプレートを使用する必要がありました。今回の機能強化により、取り込みプロパティを有効にして Cloud Storage インポート トピックを作成し、Cloud Storage から Pub/Sub トピックにバッチデータを取り込めるようになりました。データがインポート トピックに流れ込むと、サブスクリプション(pull、push、BigQuery、Cloud Storage)を作成して、ダウンストリーム処理のために選択したシンクにデータを取得できます。
Cloud Storage インポート トピックには、2 つの主なユースケースがあります。
-
バッチからストリーミングへ - 予測や活性化などのストリーミング分析ユースケースでバッチデータを活用するには、まずそれをストリーミング形式に変換する必要があります。Cloud Storage のインポート トピックを使用すると、この取り込みをフルマネージドで実施できます。
- アーカイブ データのストリーミング - 多くのお客様は履歴データを保存する必要があります。Cloud Storage サブスクリプションで Pub/Sub を使用すると、アーカイブを簡単に構築できます。そこから、Cloud Storage インポート トピックを使用して、ストリーミング分析のユースケース用に履歴データを Pub/Sub トピックに簡単に取り込むことが可能です。
今年は Apache Iceberg 用 BigQuery テーブルのプレビュー版をリリースしました。これは Apache Iceberg と互換性のある BigQuery のフルマネージド ストレージ エンジンで、自律的なストレージ、最適化、クラスタリング、高スループットのストリーミング取り込みといった機能を備えています。Pub/Sub BigQuery サブスクリプションを Apache Iceberg 用 BigQuery テーブルと統合し、取り込まれたタプルを行指向形式で永続的に保存して、定期的に Parquet に変換してお客様所有の Cloud Storage バケットに保存することで、高スループットのストリーミング取り込みを実現します。Apache Iceberg 用 BigQuery テーブルを Pub/Sub と併用して、ストリーミング データを Parquet 形式で Cloud Storage に保存することもできます。
ストリーミング分析
お客様は、Pub/Sub をストリーム処理エンジンと組み合わせて使用することで、異常検出やパーソナライゼーションなどのストリーミング分析ユースケースを強化しています。Pub/Sub はすでに Dataflow とネイティブに統合されているため、2024 年には企業での採用が拡大しているオープンソースのストリーム処理フレームワークである Apache Flink のサポートに重点的に取り組みました。現在、Apache Flink を Pub/Sub と併用する方法は 2 つあります。
1. Apache Flink 向け BigQuery Engine先日、Apache Flink 向け BigQuery Engine のプレビュー版をリリースしました。これにより、Java、Python、SQL によるステートフル ストリーム処理に、使い慣れた Apache Flink API とエコシステムを使用できるようになります。また、Apache Flink 向け BigQuery Engine はフルマネージド デプロイ、自動スケーリング、透明性の高いアップグレード、従量課金制の料金体系を備えたサーバーレス サービスであり、Google の統合データと AI Platform にネイティブに統合されています。Pub/Sub は Apache Flink 向け BigQuery Engine とも統合されています。
2. Pub/Sub Apache Flink コネクタ既存の Apache Flink デプロイでストリーミング分析をサポートするために、Pub/Sub Flink コネクタの新しいバージョンをリリースしました。現在一般提供中のこのコネクタを使用すると、わずか数ステップで既存の Apache Flink デプロイを Pub/Sub に接続できます。このコネクタでは、Apache Flink 出力を Pub/Sub トピックにパブリッシュする、あるいは Pub/Sub サブスクリプションを Apache Flink アプリケーションのソースとして使用する、といったことも可能です。
ストリームの共有とエクスポート
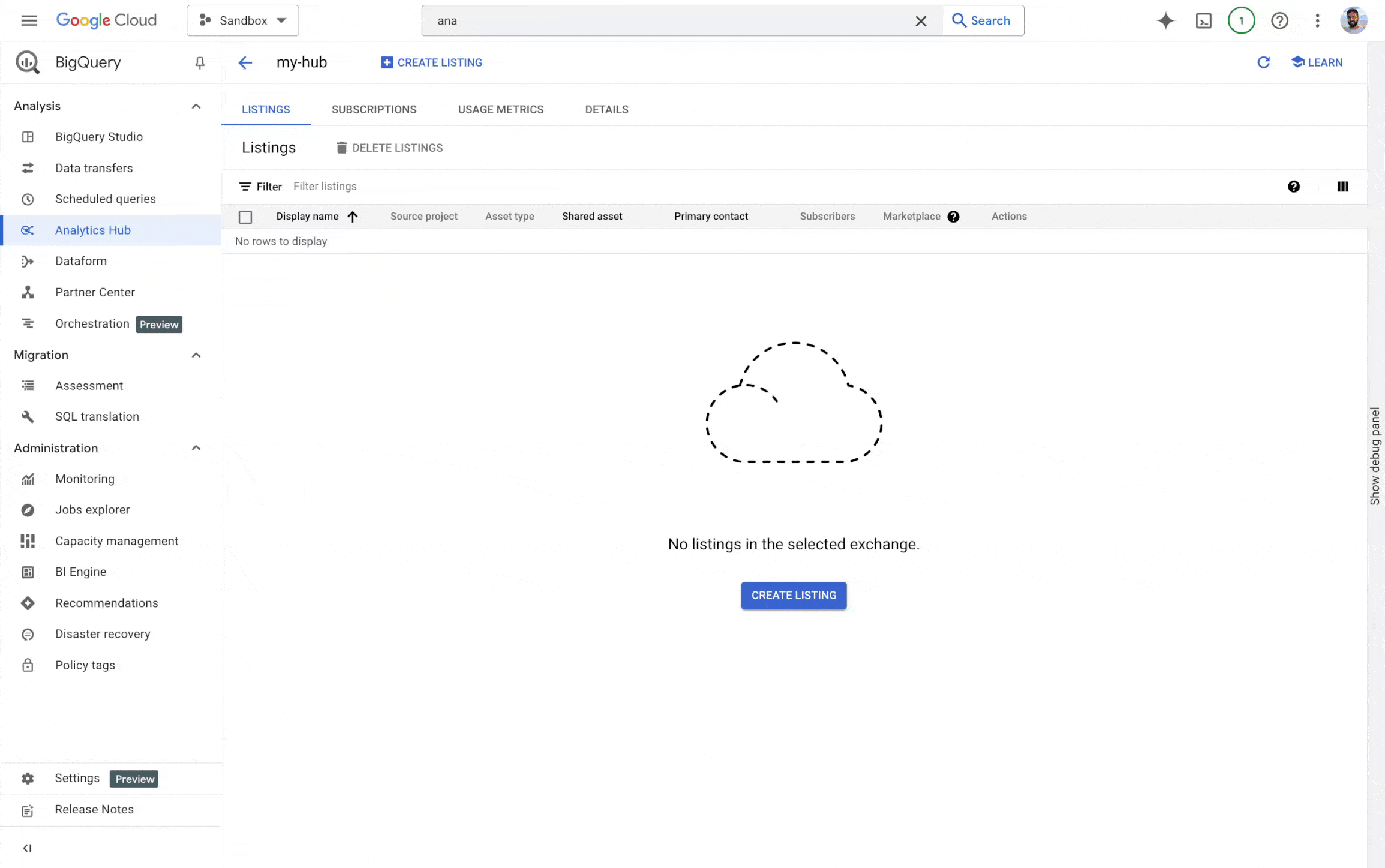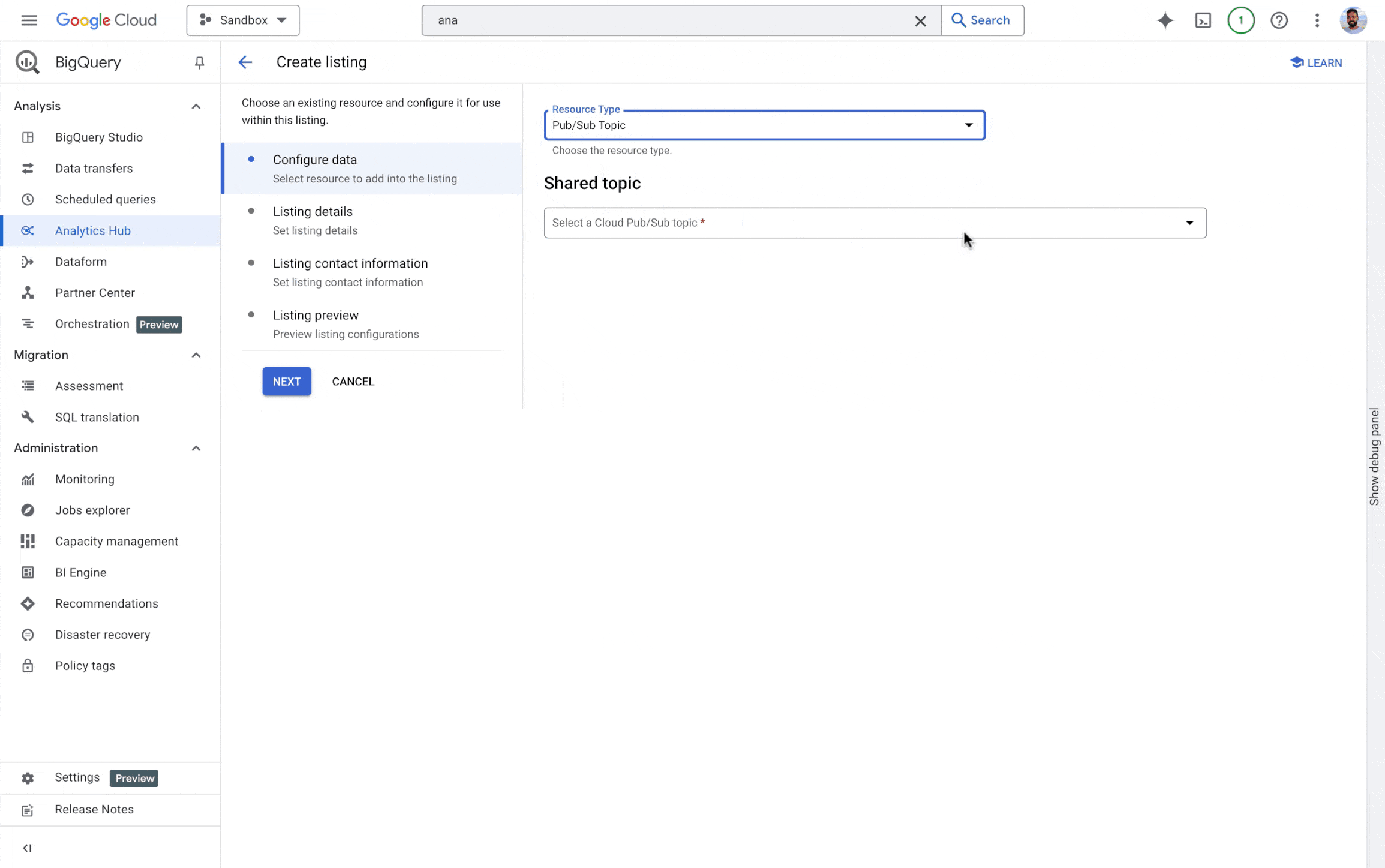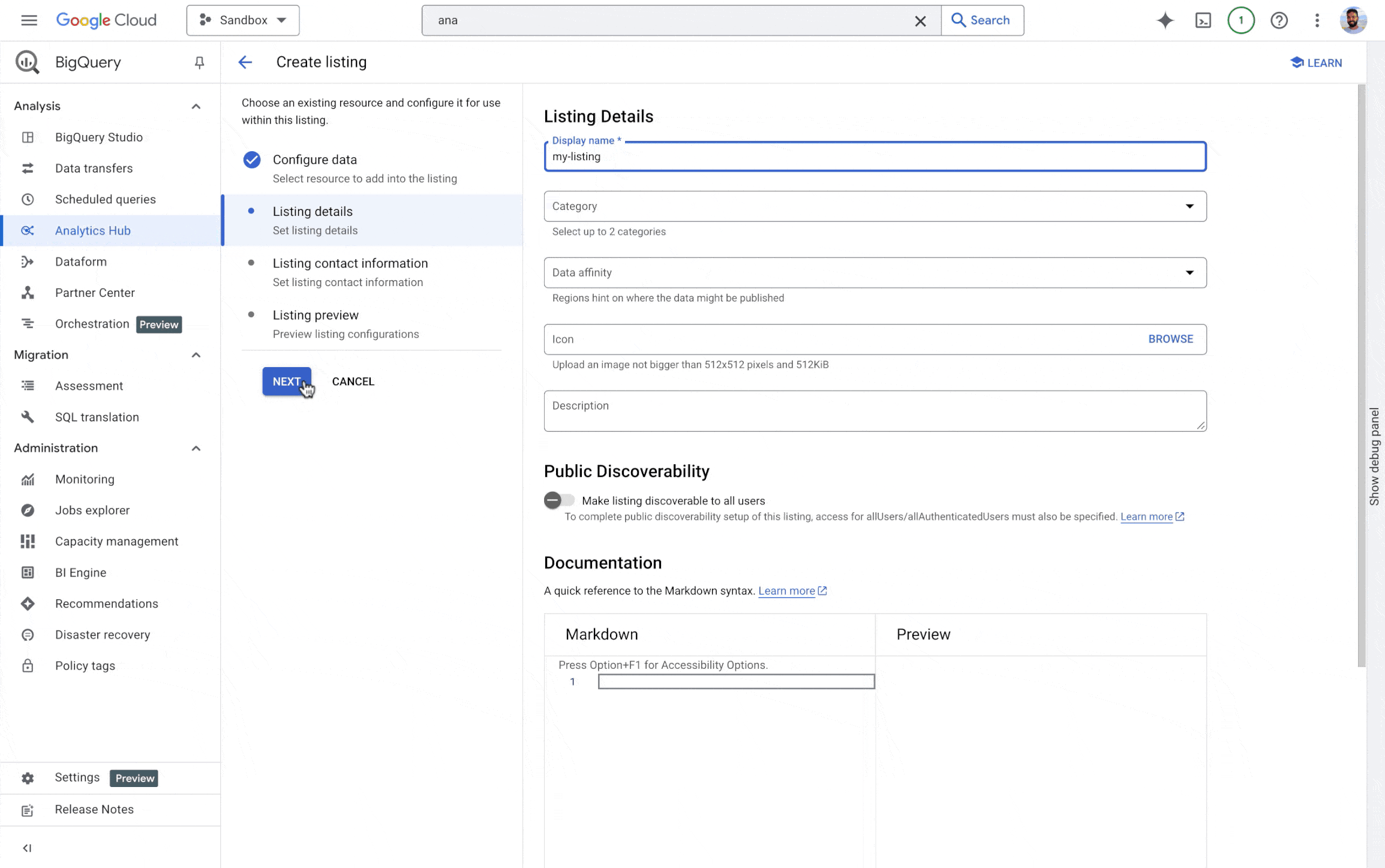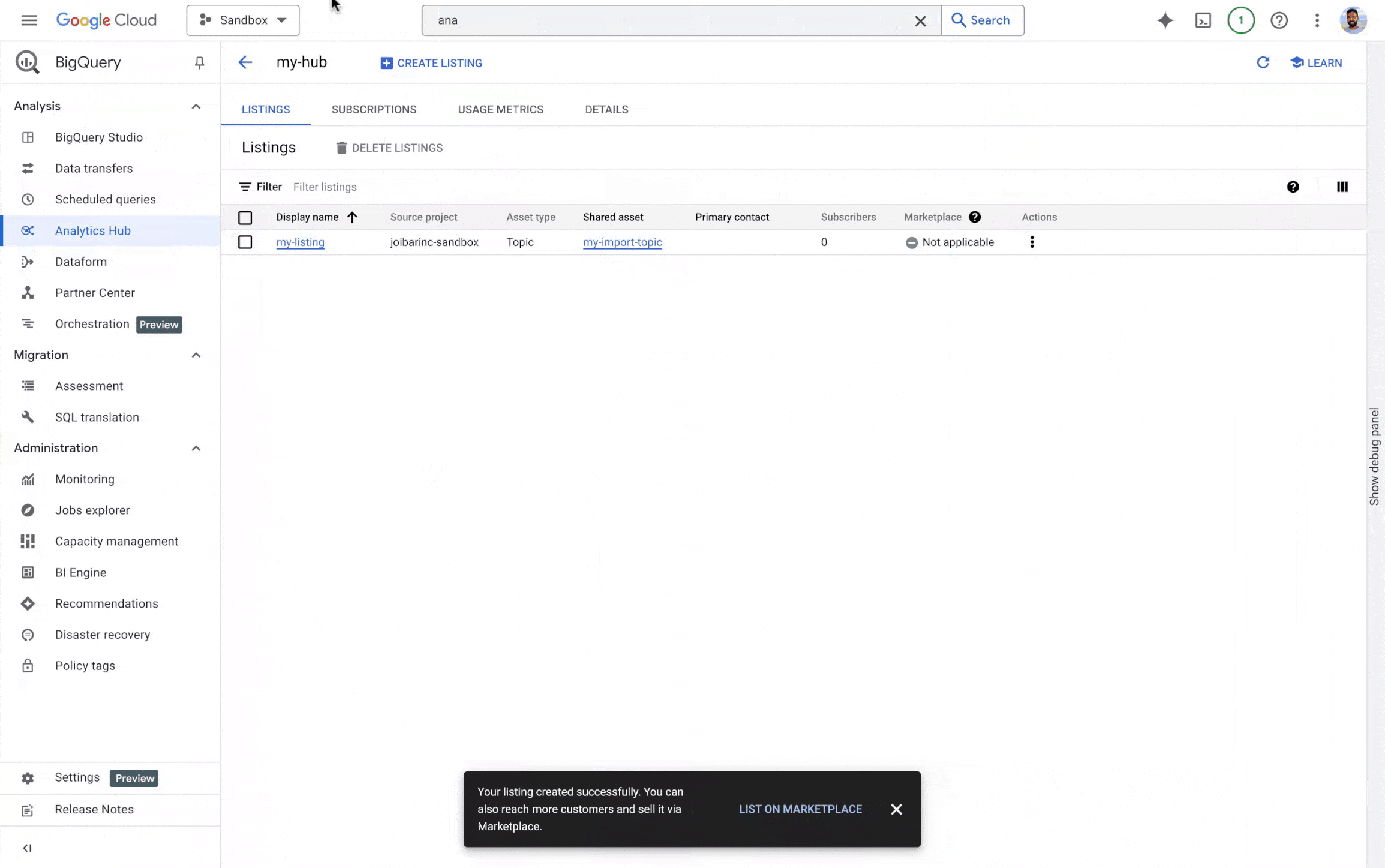
BigQuery Analytics Hub を使用すると、企業が組織間でバッチデータ アセットを効率的かつ安全に共有できます。ただし、多くの組織では、社内チームだけでなくパートナーや顧客ともリアルタイムでストリーミング データを共有する必要があります。この対策として、Analytics Hub での Pub/Sub トピック共有(プレビュー)では次の機能が提供されています。
-
リアルタイムのデータ共有: データ プロバイダはデータの更新を即座に共有できるため、最新データにタイムリーにアクセスできるようになります。
-
データ検出機能の強化: Pub/Sub トピックをデータ プロダクトとしてリスティングすることで、プロデューサーはデータ ストリームの可視性と検出可能性を高めることができます。
- データアクセスの簡素化: 組織のストリーミング データへのアクセスを一元的に管理できる統合エクスペリエンスを提供します。
BigQuery から外部システムやベンダーへのリアルタイム データ ストリーミングを簡素化するには、Pub/Sub で BigQuery の継続的クエリを使用します。これにより、BigQuery 内の新しいストリーミング SQL 機能を拡張して、無期限に実行可能かつ到着した瞬間にリアルタイム データを処理できる SQL ジョブの形式として実行できます。BigQuery の継続的クエリを使用すると、ストリーミング データをリアルタイムで分析し、その分析情報に基づいて即座に行動できます。
Pub/Sub をリアルタイム データ処理の入力と出力の両方として活用することもできます。BigQuery サブスクリプションを使用してストリーミング データを BigQuery に取り込み、BigQuery の継続的クエリによりイベント ドリブン データ パイプラインを処理、分析、開発して、クエリ結果を別の Pub/Sub トピックにエクスポートすることで、ダウンストリームのアプリケーションに分析情報を伝達します。すでに複数の Google Cloud ISV パートナーが、継続的クエリから生成された Pub/Sub メッセージをサポートしています。これには、Aiven、Census、Confluent、Estuary、Hightouch、Keboola、Lytics、Nexla、Qlik、Redpanda が含まれます(ただし、これらに限定されません)。
オブザーバビリティ
Pub/Sub での OpenTelemetry の新しいサポートにより、メッセージが公開された瞬間から受信、処理されるまでの分散トレースを確認できる機能など、メッセージのライフサイクルの詳細なトレースを確認できるようになりました。これらのトレースを分析することで、Pub/Sub アプリケーションのボトルネック、構成ミス、その他の障害を迅速に特定でき、トラブルシューティングに要する時間を短縮できます。
今後の展望
2025 年に向けて、以下の主要分野でのイノベーションを計画しています。
-
Kafka の取り込みの簡素化 - 多くの場合、お客様はメッセージング インフラストラクチャを簡素化し、シンプルさ、信頼性、自動スケーラビリティといった Pub/Sub の主なメリットを享受するために Kafka から Pub/Sub に移行しています。この移行プロセスを簡素化するため、2025 年初頭にインポート トピックによるクロスクラウド Kafka ソースをリリースする予定です。
-
単一メッセージ変換 - ほぼすべてのストリーミング データ パイプラインでは、なんらかの形式の変換が必要です。お客様によって、データレイクやデータ ウェアハウスにデータを格納した後に変換するのを好む場合(ELT パターン)もあれば、シンク(データレイク、データ ウェアハウス)に格納する前にデータを変換するのを好む場合もあります。2025 年には、ネイティブで軽量な単一メッセージ変換を提供することで、ストリーミング分析アーキテクチャをさらに簡素化する予定です。Pub/Sub 単一メッセージ変換(SMT)では、JavaScript ユーザー定義関数(UDF)を使用してメッセージ属性やデータに対してシンプルで軽量な変更を実行できます。
ここまでお読みいただきありがとうございました。これらの機能を皆様にお届けできることを楽しみにしています。今すぐ Pub/Sub の使用を開始し、最も困難なビジネス課題を解決してくれるこれらの新機能をぜひお試しください。
-Cloud Pub/Sub、プロダクト管理リード、Prateek Duble
-Google Cloud、テクニカル アカウント マネージャー、Joaquín Ibar

