Apache Iceberg をサポートする統合メタデータ サービス、BigQuery metastore のご紹介
Yuri Volobuev
Principal Engineer
Vinod Ramachandran
Senior Product Manager, Google
※この投稿は米国時間 2025 年 1 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
組織で BigQuery、Apache Spark、Apache Flink、Apache Hive といった複数のデータ処理エンジンを使用している場合、すべての分析ワークロードに対して信頼できる唯一の情報源を提供できたら素晴らしいと思いませんか。公開プレビュー版としてリリースされた BigQuery metastore は、それを可能にします。BigQuery metastore は一貫したデータ ガバナンスを実現しつつ、処理エンジンの相互運用性を提供する、フルマネージドの統合メタデータサービスです。
BigQuery metastore は、スケーラビリティに優れたランタイム メタデータ サービスで、BigQuery、Apache Spark、Apache Hive、Apache Flink などの複数のエンジンに対応し、オープンソースのテーブル形式である Apache Iceberg をサポートします。これにより、BigQuery ストレージ テーブル、Apache Iceberg 用 BigQuery テーブル、BigLake 外部テーブルのいずれにデータが保存されていても、分析エンジンは単一のスキーマを使用する、データの 1 つのコピーをクエリするだけで済みます。BigQuery metastore は、従来のデータレイクから最新のレイクハウス アーキテクチャに移行してモダナイズすることを検討しているお客様にとって、重要なコンポーネントとなります。BigQuery のエンタープライズ機能と緊密に統合されており、ユーザーのデータ操作に組み込みのセキュリティとガバナンスを適用します。
メタデータ管理の課題
従来、メタストアとその他のメタデータ管理システムは、データ処理エンジンと密接に関連しています。複数の処理エンジンを使用しているということは、データやメタデータの複数のコピーが維持され、それぞれが異なるメタストアに保持されていることになります。たとえば、Hive Metastore で Spark などのオープンソース エンジンからクエリするためのテーブル定義を作成した場合、BigQuery で同じデータをクエリするにはテーブル定義を再作成する必要があります。また、テーブル定義を異なるメタストア間で同期させるには、パイプラインを構築する必要があります。このような断片化により、最新ではないメタデータ、データリネージの可視性の欠如、セキュリティやアクセス面の課題、水準以下のユーザー エクスペリエンスといった問題が生じる可能性があります。
レイクハウス時代のメタストア
BigQuery metastore は、レイクハウス アーキテクチャ向けに設計されています。レイクハウスはデータレイクとデータ ウェアハウスの両方の利点を兼ね備えており、あらゆるデータ、ユーザー、ワークロードを 1 つの統合プラットフォームで管理できるため、データレイクとデータ ウェアハウスの両方を管理する必要がなくなります。BigQuery metastore は Apache Iceberg などのオープンソース データ形式をサポートしており、BigQuery、Spark、Flink、Hive といったさまざまな処理エンジンでアクセスできます。さまざまなエンジン間でメタデータを統合することで、データをより簡単に発見し、活用できるようになるため、データ ガバナンスを維持しつつ、セルフサービスの BI ツールおよび ML ツールによるイノベーションを促進できます。
さらに、BigQuery metastore はサーバーレスで設定も構成も不要なうえ、ワークロードに合わせて自動的にスケールされます。この NoOps 環境により、TCO が削減され、データ アナリスト、データ エンジニア、データ サイエンティストの誰もがデータを簡単に利用できるようになります。
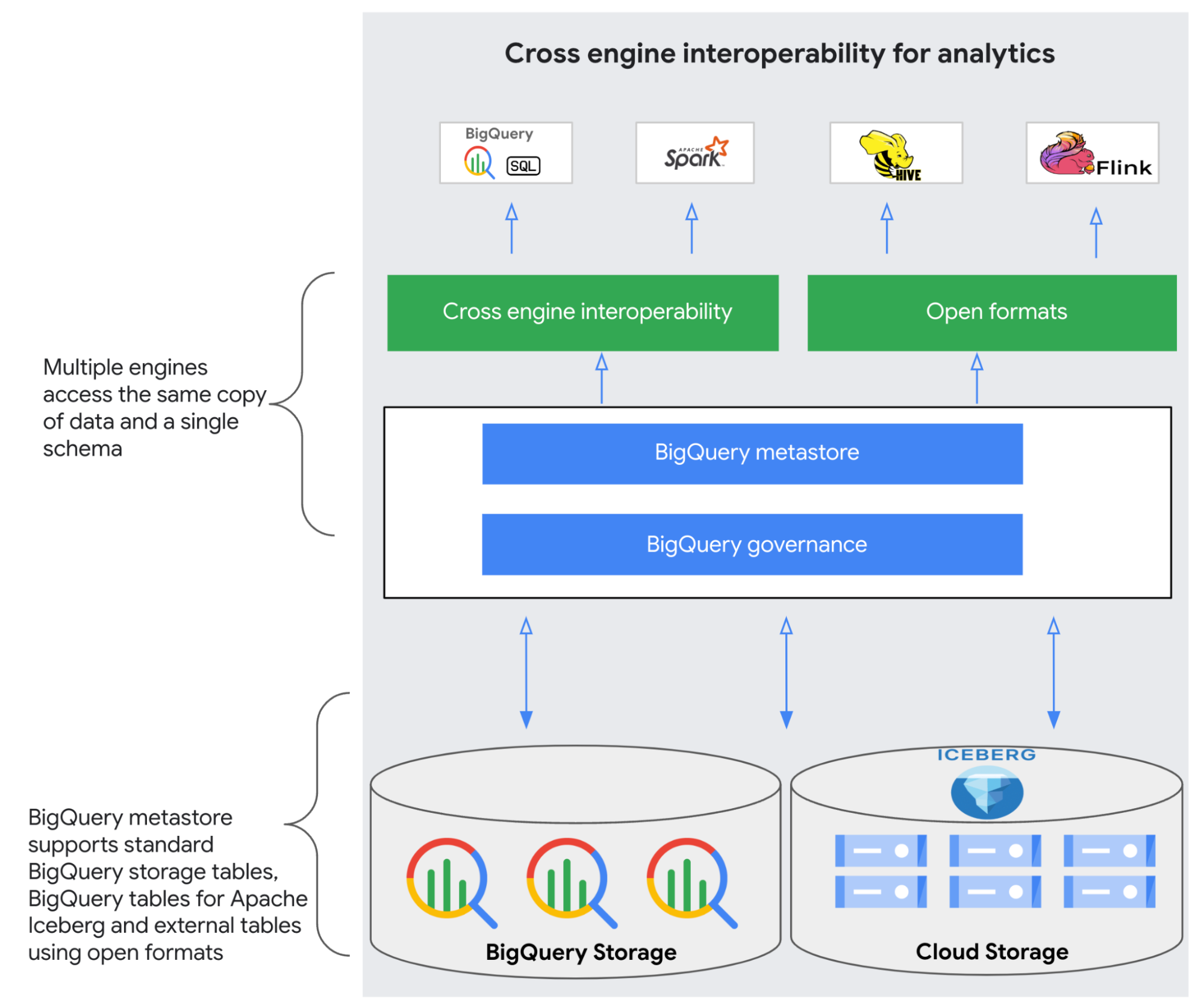
BigQuery metastore の主な利点は次のとおりです。
-
エンジン間の相互運用性: BigQuery metastore は、レイクハウス アーキテクチャ向けの単一の共有メタストアとして、レイクハウス内のすべてのデータソースにわたるすべてのメタデータの統合ビューを提供するため、ユーザーは必要なデータを簡単に見つけて把握できます。これにより、オブジェクト ストア、BigQuery ストレージ、分析ランタイム全体にオープン形式や独自の形式で保存されたデータに対して、クエリ処理や DML を実行できます。
-
オープン形式とカタログのサポート: BigQuery metastore は、BigQuery ストレージ テーブル、Apache Iceberg 用 BigQuery テーブル、外部テーブルに対応しています。
-
組み込みのガバナンス: BigQuery metastore は、自動カタログ化機能やユニバーサル検索、ビジネス メタデータ、データ プロファイリング、データ品質、きめ細かいアクセス制御、データ マスキング、データ共有、データリネージ、監査ロギングなど、BigQuery で提供される主要なガバナンス機能と統合されています。
-
BigQuery 規模のフルマネージド: BigQuery metastore はサーバーレスのフルマネージド サービスであるため、使いやすく、主要なエンジン(BigQuery、Spark、Hive、Flink)と統合されています。BigQuery metastore に使用されているインフラストラクチャ基盤は、アプリケーションのクエリ処理量の増加に合わせたスケーリングと、BigQuery 規模のトラフィック処理を可能にします。
BigQuery metastore の実例
では、BigQuery metastore の使用方法を見ていきましょう。以下の PySpark スクリプトは、BigQuery ストレージ テーブル、Apache Iceberg 用 BigQuery テーブル、BigQuery 外部テーブルを操作する Spark 環境をセットアップします。詳細なドキュメントについては、こちらをご覧ください。
このスクリプトをご自身の環境に合わせてカスタマイズするには、次の変数を置き替えます。
-
WAREHOUSE_DIRECTORY: データ ウェアハウスが格納された Cloud Storage フォルダの URI
-
CATALOG_NAME: 使用しているカタログの名前
-
MATERIALIZATION_NAMESPACE: 一時的な結果を保存する名前空間
その他のリソース
BigQuery metastore を使用することで、メタデータ管理のニーズを満たす最新のサーバーレス ソリューションを手に入れて、組み込みのガバナンスを備えたエンジン間の相互運用性を実現できます。BigQuery metastore を今すぐ試すには、こちらのドキュメントをご覧ください。Dataproc Metastore から BigQuery metastore に移行する場合は、移行ツールに関するドキュメントをご覧ください。
