Zero-ETL approach to analytics on Bigtable data using BigQuery
Bora Beran
Group Product Manager
Gaurav Saxena
Sr Product Manager, BigQuery
Modern businesses are increasingly relying on real-time insights to stay ahead of their competition. Whether it's to expedite human decision-making or fully automate decisions, such insights require the ability to run hybrid transactional analytical workloads that often involve multiple data sources.
BigQuery is Google Cloud’s serverless, multi-cloud data warehouse that simplifies analytics by bringing together data from multiple sources. Cloud Bigtable is Google Cloud's fully-managed, NoSQL database for time-sensitive transactional and analytical workloads.
Customers use Bigtable for a wide range of use cases such as real time fraud detection, recommendations, personalization and time series. Data generated by these use cases has significant business value.
Historically, while it has been possible to use ETL tools like Dataflow to copy data from Bigtable into BigQuery to unlock this value, this approach has several shortcomings, such as data freshness issues and paying twice for the storage of the same data, not to mention having to maintain an ETL pipeline. Considering the fact that many Bigtable customers store hundreds of Terabytes or even Petabytes of data, duplication can be quite costly. Moreover, copying data using daily ETL jobs hinders your ability to derive insights from up-to-date data which can be a significant competitive advantage for your business.
Today, with the General Availability of Bigtable federated queries with BigQuery, you can query data residing in Bigtable via BigQuery faster, without moving or copying the data, in all Google Cloud regions with increased federated query concurrency limits, closing a longstanding gap between operational data and analytics.
During our feature preview period, we heard about two common patterns from our customers.
Enriching Bigtable data with additional attributes from other data sources (using SQL JOIN operator) such as BigQuery tables and other external databases (e.g. CloudSQL, Spanner) or file formats (e.g. CSV, Parquet) supported by BigQuery
Combining hot data in Bigtable with cold data in BigQuery for longitudinal data analysis over long time periods (using SQL UNION operator)
Let’s take a look at how to set up federated queries so BigQuery can access data stored in Bigtable.
Setting up an external table
Suppose you’re storing digital currency transaction logs in Bigtable. You can create an external table to make this data accessible inside BigQuery using a statement like the following.
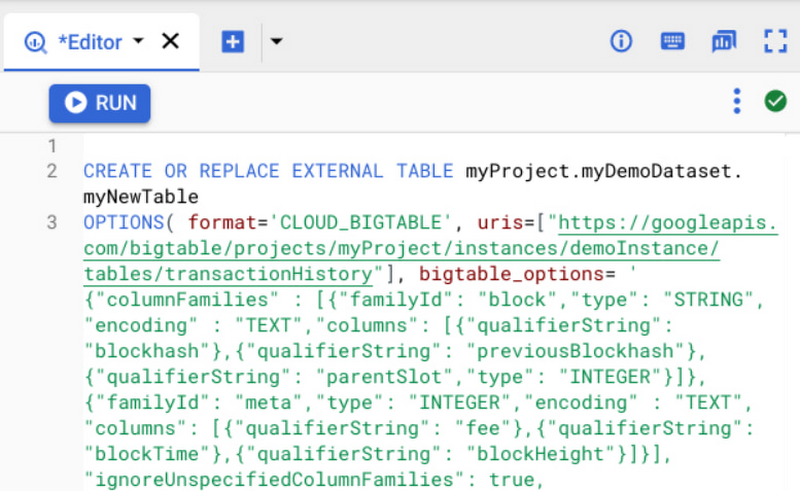
External table configuration provides BigQuery with information like column families, whether to return multiple versions for a record, column encoding and data types given Bigtable allows for a flexible schema with 1000s of columns and varying encodings with version history. You can also specify app profiles to reroute these analytical queries to a different cluster and/or track relevant metrics like CPU utilization separately.
Writing a query that accesses the Bigtable data
You can query external tables backed by Bigtable just like any other table in BigQuery.
The query will be executed by Bigtable, so you’ll be able to take advantage of Bigtable’s high throughput, low-latency database engine and quickly identify the requested columns and relevant rows within the selected row range even across a petabyte dataset. However note that unbounded queries like the example above could take a long time to execute over large tables so to achieve short response times make sure a rowkey filter is provided as part of the WHERE clause.
Query operators not supported by Bigtable will be executed by BigQuery with the required data streamed to BigQuery’s database engine seamlessly.
The external table we created can also take advantage of BigQuery features like JDBC/ODBC drivers and connectors for popular Business Intelligence and data visualization tools such as DataStudio, Looker and Tableau, in addition to AutoML tables for training machine learning models and BigQuery’s Spark connector for data scientists to load data into their model development environments.
To use the data in Spark you’ll need to provide a SQL query as shown in the PySpark example below. Note that the code for creating the Spark session is excluded for brevity.
In some cases, you may want to create views to reformat the data into flat tables since Bigtable is a NoSQL database that allows for nested data structures.
If your data includes JSON objects embedded in Bigtable cells, you can use BigQuery’s JSON functions to extract the object contents.
You can also use external tables to copy the data over to BigQuery rather than writing ETL jobs. If you’re exporting one day worth of data for the stock symbol GOOGL for some exploratory data analysis, the query might look like the example below.
Learn more
To get started with Bigtable, try it out with a Qwiklab.
You can learn more about Bigtable’s federated queries with BigQuery in the product documentation.



