このドキュメントでは、Google Cloud リソースから Splunk にログをストリーミングするエクスポート メカニズムをデプロイする方法について説明します。このユースケースに対応するリファレンス アーキテクチャをすでにお読みになっているものとします。
これらの手順は、Google Cloud から Splunk にログをストリーミングするオペレーションとセキュリティの管理者を対象としています。IT 運用またはセキュリティのユースケースでこれらの手順を使用する場合は、Splunk と Splunk HTTP Event Collector(HEC)に精通している必要があります。Dataflow パイプライン、Pub/Sub、Cloud Logging、Identity and Access Management、Cloud Storage に精通していることは、このデプロイに必須ではありませんが、役立ちます。
Infrastructure as Code(IaC)を使用してこのリファレンス アーキテクチャのデプロイ手順を自動化するには、terraform-splunk-log-export GitHub リポジトリをご覧ください。
アーキテクチャ
次の図は、リファレンス アーキテクチャと、Google Cloud から Splunk へのログデータの流れを示しています。

図に示すように、Cloud Logging は組織レベルのログシンクにログを収集し、Pub/Sub にログを送信します。Pub/Sub サービスは、ログに単一のトピックとサブスクリプションを作成し、メインの Dataflow パイプラインにログを転送します。メインの Dataflow パイプラインは、Pub/Sub から Splunk へのストリーミング パイプラインであり、Pub/Sub サブスクリプションからログを取得して Splunk に配信します。プライマリ Dataflow パイプラインと同様に、セカンダリ Dataflow パイプラインは Pub/Sub から Pub/Sub へのストリーミング パイプラインであり、配信が失敗した場合にメッセージを再生します。プロセスの最後に、Splunk Enterprise または Splunk Cloud Platform が HEC エンドポイントとして機能し、詳細な分析のためにログを受信します。詳細については、リファレンス アーキテクチャのアーキテクチャをご覧ください。
このリファレンス アーキテクチャをデプロイするには、次のタスクを行います。
- 設定タスクを行います。
- 専用のプロジェクトに集約ログシンクを作成します。
- デッドレター トピックを作成します。
- Splunk の HEC エンドポイントを設定します。
- Dataflow パイプラインの容量を構成します。
- Splunk にログをエクスポートします。
- Splunk Dataflow パイプライン内のユーザー定義関数(UDF)を使用して、処理中のログまたはイベントを変換します。
- 配信エラーに対処して、構成ミスや一時的なネットワークの問題によるデータ損失を回避します。
始める前に
Google Cloud から Splunk へのリファレンス アーキテクチャの環境を設定するには、次の手順を完了します。
プロジェクトを起動し、課金を有効にして、API を有効にする
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
IAM ロールを付与する
Google Cloud コンソールで、組織とプロジェクトのリソースに対して次の Identity and Access Management(IAM)権限があることを確認します。詳細については、リソースへのアクセス権の付与、変更、取り消しをご覧ください。
| 権限 | 事前定義ロール | リソース |
|---|---|---|
|
|
組織 |
|
|
プロジェクト |
|
|
プロジェクト |
事前定義された IAM ロールに業務の遂行に十分な権限がない場合は、カスタムロールを作成します。カスタムロールは必要なアクセス権を付与する一方で、最小権限の原則に従うことができるようサポートします。
環境の設定
In the Google Cloud console, activate Cloud Shell.
アクティブな Cloud Shell セッションのプロジェクトを設定します。
gcloud config set project PROJECT_ID
PROJECT_IDは、実際のプロジェクト ID に置き換えます。
安全なネットワークを設定する
このステップでは、ログを処理して Splunk Enterprise にエクスポートする前に、安全なネットワークを設定します。
VPC ネットワークとサブネットを作成します。
gcloud compute networks create NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets create SUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24
以下を置き換えます。
NETWORK_NAME: ネットワークの名前SUBNET_NAME: サブネットの名前REGION: このネットワークに使用するリージョン
Dataflow ワーカー仮想マシン(VM)が相互に通信するためのファイアウォール ルールを作成します。
gcloud compute firewall-rules create allow-internal-dataflow \ --network=NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346
このルールは、TCP ポート 12, 345 ~ 12, 346 を使用する Dataflow VM 間の内部トラフィックを許可します。また、Dataflow サービスは
dataflowタグを設定します。Cloud NAT ゲートウェイを作成します。
gcloud compute routers create nat-router \ --network=NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION
サブネットで限定公開の Google アクセスを有効にする
gcloud compute networks subnets update SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
ログシンクを作成する
このセクションでは、組織全体にわたるログシンクとその Pub/Sub の宛先、さらに必要な権限を作成します。
Cloud Shell で、新しいログシンクのエクスポート先として Pub/Sub トピックと関連するサブスクリプションを作成します。
gcloud pubsub topics create INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topic INPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME
以下を置き換えます。
INPUT_TOPIC_NAME: ログシンクの宛先として使用される Pub/Sub トピックの名前INPUT_SUBSCRIPTION_NAME: ログシンクの宛先への Pub/Sub サブスクリプションの名前
組織のログシンクを作成します。
gcloud logging sinks create ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID/topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID/logs/dataflow.googleapis.com'
次のように置き換えます。
ORGANIZATION_SINK_NAME: 組織内のシンクの名前ORGANIZATION_ID: 組織 ID
コマンドは、次のフラグで構成されています。
--organizationフラグは、これが組織レベルのログシンクであることを指定します。--include-childrenフラグは必須で、組織レベルのログシンクにすべてのサブフォルダとプロジェクトのすべてのログが含まれるようになります。--log-filterフラグは、転送するログを指定します。この例では、プロジェクトPROJECT_IDに固有の Dataflow オペレーション ログを除外します。これは、ログ エクスポート Dataflow パイプラインがログを処理するときにそれよりも多くのログを生成するためです。フィルタは、パイプラインが独自のログをエクスポートしないようにして、負荷の急増を防ぎます。出力には、o#####-####@gcp-sa-logging.iam.gserviceaccount.comの形式のサービス アカウントが含まれます。
Pub/Sub パブリッシャー IAM ロールを、Pub/Sub トピック
INPUT_TOPIC_NAMEのログシンク サービス アカウントに付与します。このロールは、ログシンク サービス アカウントがトピックにメッセージをパブリッシュできるようにします。gcloud pubsub topics add-iam-policy-binding INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/pubsub.publisher
LOG_SINK_SERVICE_ACCOUNTは、ログシンクのサービス アカウントの名前に置き換えます。
デッドレター トピックを作成する
メッセージの配信に失敗した場合に発生するデータ損失を回避するには、Pub/Sub デッドレター トピックとそれに対応するサブスクリプションを作成する必要があります。失敗したメッセージは、オペレーターまたはサイト信頼性エンジニアが失敗を調査して修正できるようになるまで、デッドレター トピックに保存されます。詳細については、リファレンス アーキテクチャの失敗したメッセージを再生するをご覧ください。
Cloud Shell で Pub/Sub デッドレター トピックとサブスクリプションを作成し、配信不能メッセージを格納してデータ損失を防ぎます。
gcloud pubsub topics create DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topic DEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME
以下を置き換えます。
DEAD_LETTER_TOPIC_NAME: デッドレター トピックとなる Pub/Sub トピックの名前DEAD_LETTER_SUBSCRIPTION_NAME: デッドレター トピックの Pub/Sub サブスクリプションの名前
Splunk の HEC エンドポイントを設定する
次の手順では、Splunk HEC エンドポイントを設定し、新しく作成された HEC トークンをシークレットとして Secret Manager に保存します。Splunk Dataflow パイプラインをデプロイする場合は、エンドポイント URL とトークンの両方を供給する必要があります。
Splunk の HEC を構成する
- まだ Splunk の HEC エンドポイントを構成していない場合は、Splunk のドキュメントで Splunk の HEC の構成方法をご覧ください。Splunk HEC は、Splunk Cloud Platform サービスまたは独自の Splunk Enterprise インスタンスで実行されます。Splunk HEC インデクサーの確認応答オプションは、Splunk Dataflow でサポートされていないため、無効のままにします。
- Splunk で、Splunk HEC トークンを作成したら、トークン値をコピーします。
- Cloud Shell で、Splunk HEC トークンの値を
splunk-hec-token-plaintext.txtという名前の一時ファイルに保存します。
Secret Manager に Splunk の HEC トークンを保存する
このステップでは、シークレットと、Splunk の HEC トークン値を格納する単一の基盤となるシークレット バージョンを作成します。
Cloud Shell で、Splunk の HEC トークンを含むシークレットを作成します。
gcloud secrets create hec-token \ --replication-policy="automatic"
シークレットのレプリケーション ポリシーの詳細については、レプリケーション ポリシーを選択するをご覧ください。
splunk-hec-token-plaintext.txtファイルの内容を使用して、トークンをシークレット バージョンとして追加します。gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
もう必要でなくなったら、ファイル(
splunk-hec-token-plaintext.txt)を削除します。
Dataflow パイプライン容量を構成する
次の表は、Dataflow パイプラインの容量設定を構成するためにおすすめの一般的なベスト プラクティスをまとめたものです。
| 設定 | 一般的なベスト プラクティス |
|---|---|
|
コスト比に対する最適なパフォーマンスを実現するため、ベースライン マシンサイズ |
|
計算に基づく予想ピーク時の EPS を処理するために必要な最大ワーカー数に設定する |
|
2 x ワーカー当たりの vCPU 数 x ワーカーの最大数を設定して、Splunk の HEC 接続の並列数を最大化する。 |
|
2 秒の最大遅延バッファが許容される場合、ログのイベント / リクエストを 10 ~ 50 に設定 |
このリファレンス アーキテクチャを環境にデプロイする場合は、独自の一意の値と計算を使用するようにしてください。
マシンタイプとマシン台数の値を設定します。クラウド環境に適した値を計算するには、リファレンス アーキテクチャのマシンタイプとマシン台数をご覧ください。
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT
Dataflow の並列処理とバッチ数の値を設定します。クラウド環境に適した値を計算するには、リファレンス アーキテクチャの並列処理とバッチ数をご覧ください。
JOB_PARALLELISM JOB_BATCH_COUNT
Dataflow パイプラインの容量パラメータを計算する方法の詳細については、リファレンス アーキテクチャのパフォーマンスと費用の最適化の設計上の考慮事項をご覧ください。
Dataflow パイプラインを使用してログをエクスポートする
このセクションでは、次の手順で Dataflow パイプラインをデプロイします。
- Cloud Storage バケットと Dataflow ワーカー サービス アカウントを作成する。
- Dataflow ワーカー サービス アカウントにロールとアクセス権を付与する。
- Dataflow パイプラインをデプロイします。
- Splunk でログを表示します。
パイプラインは、Google Cloud のログメッセージを Splunk の HEC に配信します。
Cloud Storage バケットと Dataflow ワーカー サービス アカウントを作成する
Cloud Shell で、均一なバケットレベルのアクセスの設定で新しい Cloud Storage バケットを作成します。
gcloud storage buckets create gs://PROJECT_ID-dataflow/ --uniform-bucket-level-access
作成したばかりの Cloud Storage バケットで Dataflow ジョブが一時ファイルをステージングします。
Cloud Shell で、Dataflow ワーカーのサービス アカウントを作成します。
gcloud iam service-accounts create WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"
WORKER_SERVICE_ACCOUNTは、Dataflow ワーカー サービス アカウントに使用する名前に置き換えます。
Dataflow ワーカー サービス アカウントにロールとアクセス権を付与する
このセクションでは、次の表に示すように、必要なロールを Dataflow ワーカー サービス アカウントに付与します。
| ロール | パス | 目的 |
|---|---|---|
| Dataflow 管理者 |
|
サービス アカウントを Dataflow 管理者として機能するようにします。 |
| Dataflow ワーカー |
|
サービス アカウントを Dataflow ワーカーとして機能するようにします。 |
| ストレージのオブジェクト管理者 |
|
サービス アカウントが、ファイルのステージングに Dataflow が使用する Cloud Storage バケットにアクセスできるようにします。 |
| Pub/Sub パブリッシャー |
|
サービス アカウントが、失敗したメッセージを Pub/Sub デッドレター トピックに公開できるようにします。 |
| Pub/Sub サブスクライバー |
|
サービス アカウントが入力サブスクリプションにアクセスできるようにします。 |
| Pub/Sub 閲覧者 |
|
サービス アカウントがサブスクリプションを表示できるようにします。 |
| Secret Manager のシークレット アクセサー |
|
サービス アカウントが Splunk HEC トークンを含むシークレットにアクセスできるようにします。 |
Cloud Shell で、このアカウントが Dataflow ジョブ オペレーションと管理タスクを実行するために必要な Dataflow 管理者と Dataflow ワーカーのロールを Dataflow ワーカー サービス アカウントに付与します。
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.worker"
Dataflow ワーカー サービス アカウントに、Pub/Sub 入力サブスクリプションからのメッセージを表示、使用するアクセス権を付与します。
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber"
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.viewer"
Dataflow ワーカー サービス アカウントに、失敗したメッセージを Pub/Sub 未処理トピックに公開するアクセス権を付与します。
gcloud pubsub topics add-iam-policy-binding DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.publisher"
Dataflow ワーカー サービス アカウントに Secret Manager の Splunk の HEC トークン シークレットへのアクセス権を付与します。
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/secretmanager.secretAccessor"
Dataflow ワーカー サービス アカウントに、Dataflow ジョブがファイルのステージングに使用する Cloud Storage バケットへの読み取りと書き込みのアクセス権を付与します。
gcloud storage buckets add-iam-policy-binding gs://PROJECT_ID-dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" --role=”roles/storage.objectAdmin”
Dataflow パイプラインをデプロイする
Cloud Shell で、Splunk の HEC URL 用に次の環境変数を設定します。
export SPLUNK_HEC_URL=SPLUNK_HEC_URL
以下で、
SPLUNK_HEC_URL変数を [protocol://host[:port] の形式を使用して置き換えます。protocolはhttpかhttpsのどちらかです。hostは、Splunk HEC インスタンスの完全修飾ドメイン名(FQDN)または IP アドレスです。複数の HEC インスタンスがある場合は、関連する HTTP(S)(または DNS ベース)ロードバランサの FQDN または IP アドレスです。portは、HEC ポート番号です。これは省略可能で、Splunk の HEC エンドポイント構成によって異なります。
有効な Splunk HEC URL 入力の例は
https://splunk-hec.example.com:8088です。Splunk Cloud Platform の HEC にデータを送信する場合は、Splunk Cloud の HEC にデータを送信するを参照して、上記の特定の Splunk HEC URL のhostとportの部分を確認します。Splunk HEC URL には HEC エンドポイント パス(たとえば、
/services/collector)を含めることはできません。Pub/Sub to Splunk Dataflow テンプレートは現在、JSON 形式のイベント用の/services/collectorエンドポイントのみをサポートし、そのパスを Splunk HEC URL 入力に自動的に追加します。HEC エンドポイントの詳細については、services/collector エンドポイントの Splunk のドキュメントをご覧ください。Pub/Sub to Splunk Dataflow テンプレートを使用して、Dataflow パイプラインをデプロイします。
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID-dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
JOB_NAMEは、名前の形式pubsub-to-splunk-date+"%Y%m%d-%H%M%S"に置き換えます。任意のパラメータ
javascriptTextTransformGcsPathとjavascriptTextTransformFunctionNameには、一般公開されているサンプル UDF(gs://splk-public/js/dataflow_udf_messages_replay.js)を指定します。サンプル UDF には、失敗した配信をリプレイするために使用するイベント変換とデコード ロジックのコードサンプルが含まれています。UDF の詳細については、UDF で処理中イベントを変換するをご覧ください。パイプライン ジョブが完了したら、出力で新しいジョブ ID を探し、ジョブ ID をコピーして保存します。このジョブ ID は後の手順で入力します。
Splunk でログを表示する
Dataflow パイプライン ワーカーがプロビジョニングされ、Splunk の HEC にログを配信できるようになるまでに数分を要します。ログが正常に受信され、Splunk Enterprise または Splunk Cloud Platform 検索インターフェースでインデックスに登録されていることを確認できます。モニタリング対象リソースの種類別のログ数を表示するには:
Splunk で [Splunk Search & Reporting] を開きます。
MY_INDEXインデックスが Splunk の HEC トークンに構成されているindex=[MY_INDEX] | stats count by resource.typeの検索を実行します。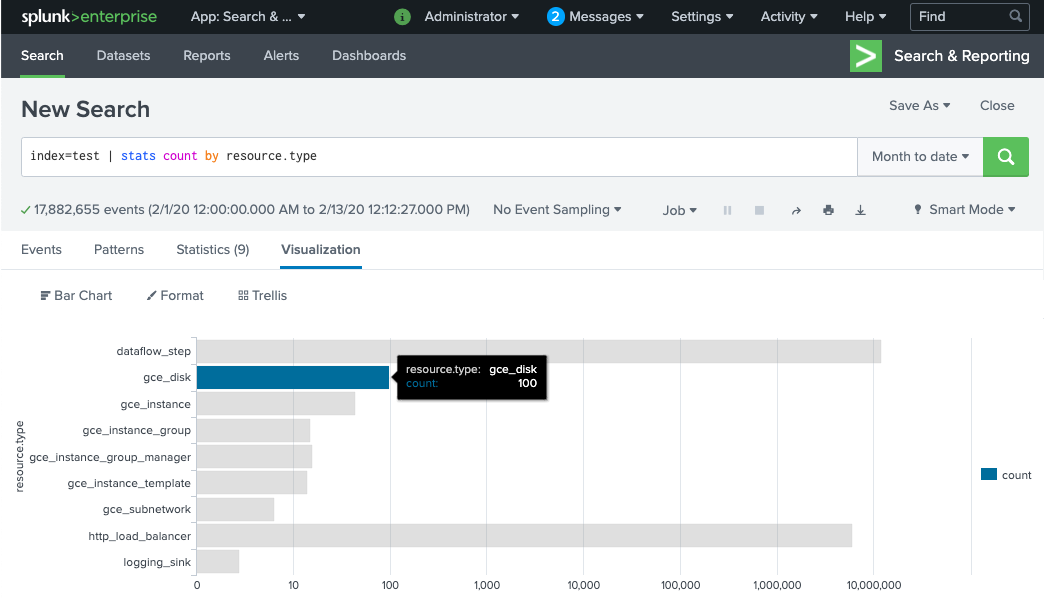
イベントが表示されない場合は、配信エラーを処理するをご覧ください。
UDF で処理中イベントを変換する
Pub/Sub to Splunk Dataflow テンプレートでは、新しいフィールドの追加やイベントベースでの Splunk HEC メタデータの設定など、カスタム イベント変換用の JavaScript UDF がサポートされています。デプロイしたパイプラインは、このサンプル UDF を使用します。
このセクションでは、サンプルの UDF 関数をまず編集して、新しいイベント フィールドを追加します。この新しいフィールドでは、追加のコンテキスト情報として元の Pub/Sub サブスクリプションの値を指定します。その後、変更した UDF で Dataflow パイプラインを更新します。
サンプル UDF を変更する
Cloud Shell で、サンプル UDF 関数を含む JavaScript ファイルをダウンロードします。
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
任意のテキスト エディタで JavaScript ファイルを開き、
event.inputSubscriptionフィールドを見つけてその行のコメント化解除し、以下のようにsplunk-dataflow-pipelineをINPUT_SUBSCRIPTION_NAMEに置き換えます。event.inputSubscription = "INPUT_SUBSCRIPTION_NAME";
ファイルを保存します。
ファイルを Cloud Storage バケットにアップロードします。
gcloud storage cp ./dataflow_udf_messages_replay.js gs://PROJECT_ID-dataflow/js/
新しい UDF で Dataflow パイプラインを更新する
Cloud Shell で [ドレイン オプション] を使用してパイプラインを停止します。これにより、すでに Pub/Sub から pull されたログが失われないようにできます。
gcloud dataflow jobs drain JOB_ID --region=REGION
更新された UDF で Dataflow パイプライン ジョブを実行します。
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://PROJECT_ID-dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
JOB_NAMEは、名前の形式pubsub-to-splunk-date+"%Y%m%d-%H%M%S"に置き換えます。
配信エラーを処理する
イベント処理または Splunk の HEC への接続に関するエラーにより、配信エラーが発生する場合があります。このセクションでは、エラー処理ワークフローのデモを行うための配信エラーを導入します。また、Splunk への配信に失敗したメッセージを表示して再配信をトリガーする方法についても説明します。
配信エラーをトリガーする
Splunk で配信エラーを手動で周知するには、次のいずれかを行います。
- 単一インスタンスを実行している場合は、Splunk サーバーを停止して接続エラーを発生させます。
- Splunk 入力構成から、関連する HEC トークンを無効にします。
失敗したメッセージに関するトラブルシューティング
失敗したメッセージを調べるには、Google Cloud コンソールを使用します。
Google Cloud コンソールで、[Pub/Sub サブスクリプション] ページに移動します。
作成した未処理のサブスクリプションをクリックします。上記の例を使用した場合、サブスクリプション名は
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAMEです。メッセージ ビューアを開くには、[メッセージを表示] をクリックします。
メッセージを表示するには、[PULL] をクリックします。[確認応答メッセージを有効にする] はオフのままにします。
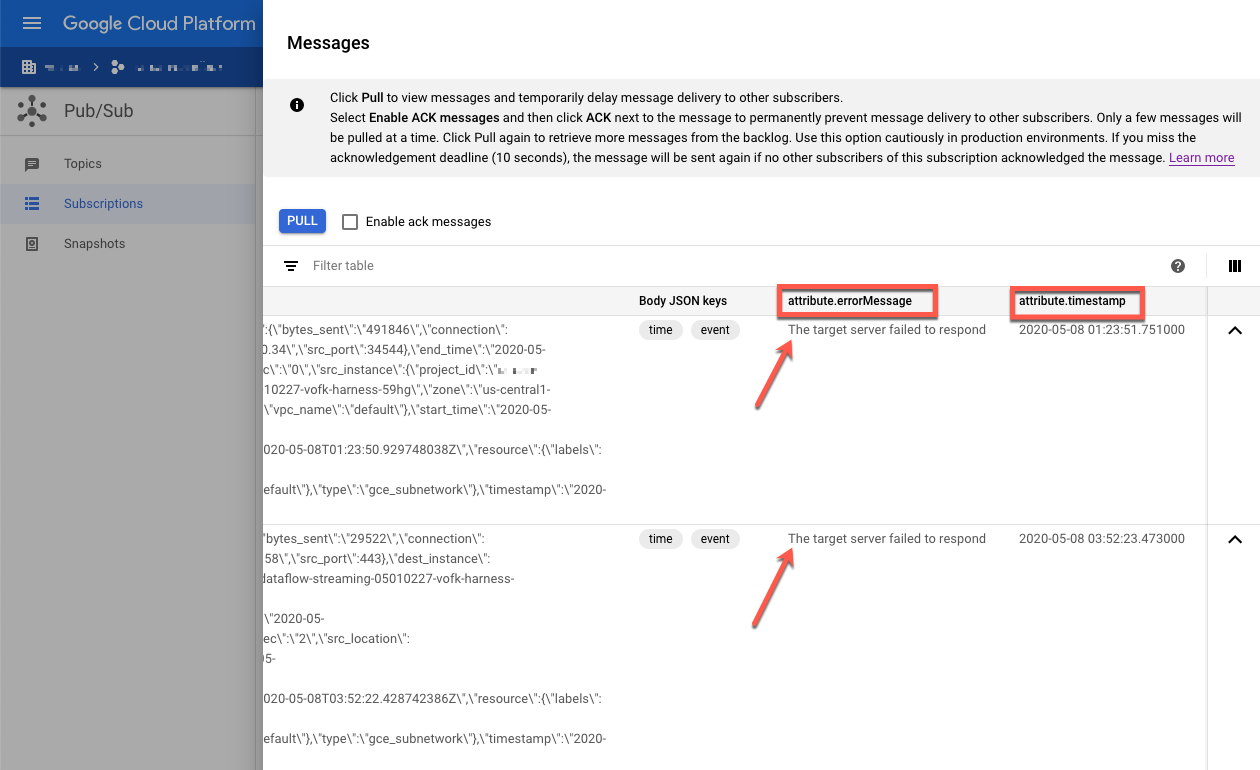
失敗したメッセージを確認します。次のことに注意してください。
Message body列の Splunk イベント ペイロード。attribute.errorMessage列のエラー メッセージ。attribute.timestamp列のエラー タイムスタンプ。
次のスクリーンショットは、Splunk の HEC エンドポイントが一時的に停止している、または到達できない場合に受信するエラー メッセージの例を示しています。errorMessage 属性のテキストは The target server failed to respond となることに留意してください。また、メッセージには、各失敗に関連するタイムスタンプも表示されています。このタイムスタンプを使用して、失敗の根本原因をトラブルシューティングできます。
失敗したメッセージを再生する
このセクションでは、Splunk サーバーを再起動するか、Splunk の HEC エンドポイントを有効にして、配信エラーを修正する必要があります。その後、未処理のメッセージを再生できます。
Splunk で、次のいずれかの方法で Google Cloud への接続を復元します。
- Splunk サーバーを停止した場合は、サーバーを再起動します。
- 配信エラーをトリガーするで Splunk の HEC エンドポイントを無効にした場合は、Splunk の HEC エンドポイントが動作するようになっていることを確認します。
Cloud Shell で、このサブスクリプション内のメッセージを再処理する前に、未処理のサブスクリプションのスナップショットを作成します。スナップショットにより、予期しない構成エラーが発生した場合にメッセージが失われないようにすることができます。
gcloud pubsub snapshots create SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME
SNAPSHOT_NAMEは、スナップショットを識別できる名前(dead-letter-snapshot-date+"%Y%m%d-%H%M%Sなど)に置き換えます。Pub/Sub to Splunk Dataflow テンプレートを使用して、Pub/Sub から Pub/Sub へのパイプラインを作成します。パイプラインは、別の Dataflow ジョブを使用して、未処理のサブスクリプションから入力トピックにメッセージを転送しなおします。
DATAFLOW_INPUT_TOPIC="INPUT_TOPIC_NAME" DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME" JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs run JOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n2-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME,\ outputTopic=projects/PROJECT_ID/topics/INPUT_TOPIC_NAME
コマンド出力から Dataflow ジョブ ID をコピーして、今後のために保存します。Dataflow ジョブをドレインするときに、このジョブ ID を
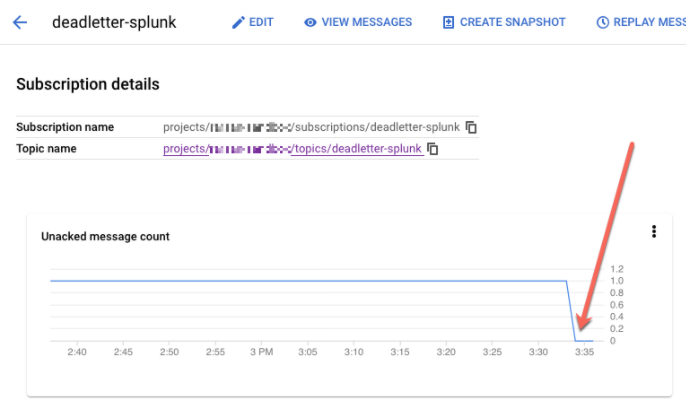
REPLAY_JOB_IDとして入力します。Google Cloud コンソールで、[Pub/Sub サブスクリプション] ページに移動します。
未処理のサブスクリプションを選択します。次のスクリーンショットに示すように、[ACK 処理されていないメッセージ数] グラフが 0 に減少していることを確認します。
Cloud Shell で、作成した Dataflow ジョブをドレインします。
gcloud dataflow jobs drain REPLAY_JOB_ID --region=REGION
REPLAY_JOB_IDは、前に保存した Dataflow ジョブ ID に置き換えます。
メッセージが元の入力トピックに転送されると、メインの Dataflow パイプラインは自動的に失敗したメッセージを取得して Splunk に再配信します。
Splunk でメッセージを確認する
メッセージが再配信されたことを確認するには、Splunk で [Splunk Search & Reporting] を開きます。
delivery_attempts > 1を検索します。これは、サンプル UDF が各イベントに追加され、配信試行回数を追跡する特別なフィールドです。検索の期間の範囲を拡張して、以前に発生した可能性のあるイベントが含まれるようにしてください。これは、イベントのタイムスタンプはインデックス登録の日時ではなく、イベントを最初に作成した日時であるためです。
次のスクリーンショットでは、最初に失敗した 2 つのメッセージが、正しいタイムスタンプを使用して Splunk に正常に配信されてインデックスに登録されています。
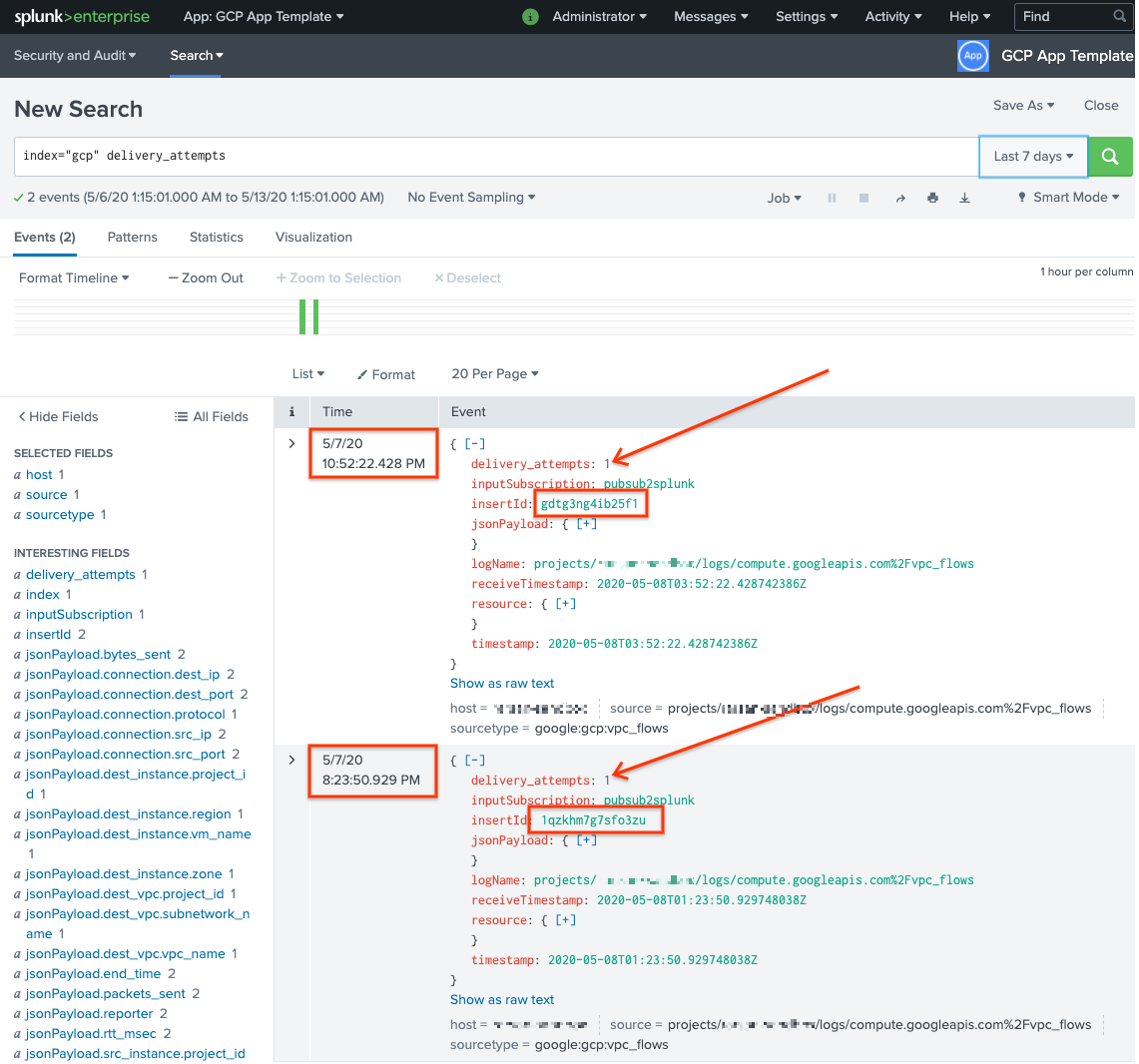
insertId フィールド値は、未処理のサブスクリプションを表示するときに失敗したメッセージに表示される値と同じであることに留意してください。insertId フィールドは、Cloud Logging が元のログエントリに割り当てる一意の識別子です。insertId は Pub/Sub メッセージ本文にも表示されます。
クリーンアップ
このリファレンス アーキテクチャで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
組織レベルのシンクを削除する
- 組織レベルのログシンクを削除するには、次のコマンドを使用します。
gcloud logging sinks delete ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
プロジェクトの削除
ログシンクを削除したら、ログの受信とエクスポート用に作成されたリソースの削除を進めます。最も簡単な方法は、リファレンス アーキテクチャ用に作成したプロジェクトを削除することです。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- Pub/Sub to Splunk Dataflow テンプレート パラメータの一覧については、Pub/Sub to Splunk Dataflow のドキュメントをご覧ください。
- このリファレンス アーキテクチャのデプロイに役立つ、対応する Terraform テンプレートについては、
terraform-splunk-log-exportGitHub リポジトリをご覧ください。それには、Splunk Dataflow パイプラインをモニタリングするためのビルド済みの Cloud Monitoring ダッシュボードが含まれています。 - Splunk Dataflow のモニタリングとトラブルシューティングに役立つ Splunk Dataflow のカスタム指標とロギングの詳細については、ブログ Splunk Dataflow ストリーミング パイプライン用の新しいオブザーバビリティ機能をご覧ください。
- リファレンス アーキテクチャ、図、ベスト プラクティスについては、Cloud アーキテクチャ センターをご確認ください。