このドキュメントでは、Google Kubernetes Engine(GKE)を使用して Google Cloud でフェデレーション ラーニング プラットフォームを作成する際に役立つ 2 つのリファレンス アーキテクチャについて説明します。このドキュメントで説明するリファレンス アーキテクチャと関連リソースは次のものをサポートします。
- クロスサイロ フェデレーション ラーニング
- クロスサイロ アーキテクチャを基盤とするクロスデバイス フェデレーション ラーニング
このドキュメントは、Google Cloud でフェデレーション ラーニングのユースケースを実装するクラウド アーキテクト、AI エンジニア、ML エンジニアを対象としています。また、Google Cloud にフェデレーション ラーニングを実装するかどうかを検討している意思決定者も対象にしています。
アーキテクチャ
このセクションの図は、フェデレーション ラーニングのクロスサイロ アーキテクチャとクロスデバイス アーキテクチャを示しています。これらのアーキテクチャのさまざまなアプリケーションについては、ユースケースをご覧ください。
クロスサイロ アーキテクチャ
次の図は、クロスサイロ フェデレーション ラーニングをサポートするアーキテクチャを示しています。

上記の図は、クロスサイロ アーキテクチャの単純な例を示しています。この図では、すべてのリソースが Google Cloud 組織内の同じプロジェクトにあります。これらのリソースには、ローカル クライアント モデル、グローバル クライアント モデル、関連するフェデレーション ラーニング ワークロードが含まれます。
このリファレンス アーキテクチャは、データサイロの複数の構成をサポートするように変更できます。コンソーシアムの各メンバーは、次の方法でデータサイロをホストできます。
- Google Cloud の同じ Google Cloud 組織の同じ Google Cloud プロジェクト。
- Google Cloud の同じ Google Cloud 組織の異なる Google Cloud プロジェクト。
- Google Cloud の異なる組織。
- プライベート、オンプレミス環境、または他のパブリック クラウド。
参加メンバーが共同で作業を行うには、環境間でセキュアな通信チャネルを確立する必要があります。参加メンバーがフェデレーション ラーニングで果たす役割、連携方法、共有する内容について詳しくは、ユースケースをご覧ください。
このアーキテクチャは、次のコンポーネントで構成されます。
- Virtual Private Cloud(VPC)ネットワークとサブネット。
- 限定公開 GKE クラスタ。次のことができます。
- クラスタノードをインターネットから分離する。
- 承認済みネットワークを使用して限定公開 GKE クラスタを作成し、クラスタノードとコントロール プレーンのインターネットへの公開を制限する。
- シールドされたクラスタノードで、強化されたオペレーティング システム イメージを使用する。
- 最適化された Kubernetes ネットワーキングに対して Dataplane V2 を有効にする。
- 専用の GKE ノードプール: テナントアプリとリソースを排他的にホストする専用のノードプールを作成します。ノードには、テナント ワークロードのみがテナントノードにスケジュールされるようにする taint があります。他のクラスタ リソースは、メインのノードプールにホストされます。
データの暗号化(デフォルトで有効):
- 保存データ。
- 転送中のデータ。
- アプリケーション レイヤのクラスタの Secret。
使用中のデータの暗号化(必要に応じて Confidential Google Kubernetes Engine Node を有効にします)。
VPC ファイアウォール ルール。次のものを適用します。
- クラスタ内のすべてのノードに適用されるベースライン ルール。
- テナント ノードプール内のノードにのみ適用される追加のルール。これらのファイアウォール ルールは、テナントノードとの上り(内向き)と下り(外向き)を制限します。
インターネットへの下り(外向き)を許可する Cloud NAT。
Cloud DNS レコード。限定公開の Google アクセスが有効になり、クラスタ内のアプリがインターネットを経由せずに Google API にアクセスできるようになります。
次のサービス アカウント:
- テナント ノードプール内のノード専用のサービス アカウント。
- Workload Identity 連携で使用するテナントアプリ専用のサービス アカウント。
Kubernetes のロールベース アクセス制御(RBAC)用の Google グループを使用するためのサポート。
構成記述子を格納する Git リポジトリ。
コンテナ イメージを保存するための Artifact Registry リポジトリ。
構成とポリシーをデプロイするための Config Sync と Policy Controller。
クラスタの上り(内向き)と下り(外向き)のトラフィックを個別に許可するための Cloud Service Mesh ゲートウェイ。
グローバル モデルとローカルモデルの重みを保存するための Cloud Storage バケット。
他の Google API と Google Cloud APIs へのアクセス。たとえば、トレーニング ワークロードは、Cloud Storage、BigQuery、Cloud SQL に保存されているトレーニング データにアクセスする必要がある場合があります。
クロスデバイス アーキテクチャ
次の図は、クロスデバイス フェデレーション ラーニングをサポートするアーキテクチャを示しています。
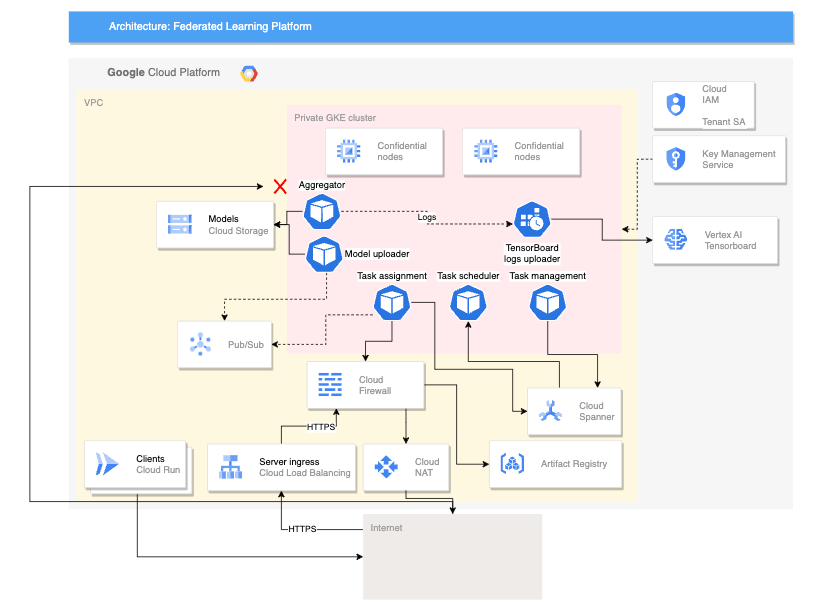
このクロスデバイス アーキテクチャは、クロスサイロ アーキテクチャを基盤とし、次のコンポーネントが追加されています。
- Cloud Run サービス。サーバーに接続するデバイスをシミュレートします。
- Certificate Authority Service。サーバーとクライアントで実行するプライベート証明書を作成します。
- Vertex AI TensorBoard。トレーニングの結果を可視化します。
- Cloud Storage バケット。統合モデルを保存します。
- 限定公開 GKE クラスタ。機密ノードをプライマリ プールとして使用して、使用中のデータを保護します。
クロスデバイス アーキテクチャでは、オープンソースの Federated Compute Platform(FCP)プロジェクトのコンポーネントを使用します。このプロジェクトには以下のものが含まれます。
- サーバーと通信してデバイス上でタスクを実行するクライアント コード
- クライアント / サーバー間の通信に使用するプロトコル
- TensorFlow Federated との接続ポイント。フェデレーション計算の定義を容易にします。
上の図に示す FCP コンポーネントは、一連のマイクロサービスとしてデプロイできます。これらのコンポーネントは次の処理を行います。
- アグリゲータ: このジョブはデバイスの勾配を読み取り、差分プライバシーを使用して集計結果を計算します。
- コレクタ: このジョブは定期的に実行され、アクティブなタスクと暗号化された勾配をクエリします。この情報により集計の開始時期が決まります。
- モデル アップローダー: このジョブは、イベントをリッスンして結果をパブリッシュし、更新されたモデルをデバイスがダウンロードできるようにします。
- タスク割り当て: これはフロントエンド サービスで、トレーニング タスクをデバイスに配信します。
- タスク管理: このジョブはタスクを管理します。
- タスク スケジューラ: このジョブは定期的に実行されるか、特定のイベントによってトリガーされます。
使用するプロダクト
これらのフェデレーション ラーニングのユースケースのリファレンス アーキテクチャでは、次の Google Cloud コンポーネントを使用します。
- Google Cloud Kubernetes Engine(GKE): GKE は、フェデレーション ラーニングの基礎となるプラットフォームを提供します。
- TensorFlow Federated(TFF): TFF は、分散データに対する ML やその他の計算のためのオープンソース フレームワークを提供します。
また、GKE はフェデレーション ラーニング プラットフォームに次の機能を提供します。
- フェデレーション ラーニング コーディネーターのホスティング: フェデレーション ラーニング コーディネーターはフェデレーション ラーニング プロセスの管理を担当します。この管理には、グローバル モデルを参加者に配布する、参加者からの更新を集約する、グローバル モデルを更新する、などのタスクが含まれます。GKE を使用すると、高可用性が確保されたスケーラブルな方法でフェデレーション ラーニング コーディネーターをホストできます。
- フェデレーション ラーニングの参加者のホスティング: フェデレーション ラーニングの参加者は、ローカルデータでグローバル モデルをトレーニングします。GKE を使用すると、分離された安全な方法でフェデレーション ラーニング参加者をホストできます。このアプローチにより、参加者のデータがローカルに保持されるようになります。
- 安全でスケーラブルな通信チャネルの提供: フェデレーション ラーニングの参加者は、安全かつスケーラブルな方法でフェデレーション ラーニング コーディネーターと通信する必要があります。GKE を使用すると、参加者とコーディネーター間に安全かつスケーラブルな通信チャネルを構築できます。
- フェデレーション ラーニングのデプロイのライフサイクルの管理: GKE では、フェデレーション ラーニングのデプロイのライフサイクルを管理できます。この管理には、リソースのプロビジョニング、フェデレーション ラーニング プラットフォームのデプロイ、フェデレーション ラーニング プラットフォームのパフォーマンスのモニタリング、などのタスクが含まれます。
これらのメリットに加えて、GKE には、フェデレーション ラーニングのデプロイに役立つ次のような機能も用意されています。
- リージョン クラスタ: GKE ではリージョン クラスタを作成できます。これにより、参加者とコーディネーターの間のレイテンシを短縮し、フェデレーション ラーニングのデプロイのパフォーマンスを改善できます。
- ネットワーク ポリシー: GKE では、ネットワーク ポリシーを作成して、参加者とコーディネーター間のトラフィック フローを制御することで、フェデレーション ラーニングのデプロイのセキュリティを向上させることができます。
- ロード バランシング: GKE には、参加者とコーディネーター間でトラフィックを分散し、フェデレーション ラーニングのデプロイのスケーラビリティを向上させる、いくつかのロード バランシング オプションが用意されています。
TFF には、フェデレーション ラーニングのユースケースの実装を容易にする次の機能が用意されています。
- 連携計算(サーバーとクライアントのセットで実行される一連の処理ステップ)を宣言的に表現する機能。これらの計算は、さまざまなランタイム環境にデプロイできます。
- カスタム アグリゲータは TFF オープンソースを使用して構築できます。
- 次のアルゴリズムを含む、さまざまなフェデレーション ラーニング アルゴリズムのサポート。
- 連携平均: 参加するクライアントのモデル パラメータの平均を算出するアルゴリズム。データが比較的均一で、モデルが複雑すぎないユースケースに適しています。一般的なユースケースは次のとおりです。
- パーソナライズされたレコメンデーション: 連携平均を使用することで、購入履歴に基づいてユーザーに商品をおすすめするモデルをトレーニングできます。
- 不正行為の検出: 銀行のコンソーシアムでは、連携平均を使用することで、不正な取引を検出するモデルをトレーニングできます。
- 医学的診断: 病院グループは、連携平均を使用することで、がんの診断モデルをトレーニングできます。
- 連携確率的勾配降下法(FedSGD): 確率的勾配降下法を使用してモデル パラメータを更新するアルゴリズム。これは、さまざまなデータが存在し、モデルが複雑なユースケースに適しています。一般的なユースケースは次のとおりです。
- 自然言語処理: FedSGD を使用することで、音声認識の精度を向上させるモデルをトレーニングできます。
- 画像認識: FedSGD を使用することで、画像内のオブジェクトを識別できるモデルをトレーニングできます。
- 予測メンテナンス: FedSGD を使用することで、マシンに障害が発生する可能性が高いタイミングを予測するモデルをトレーニングできます。
- Federated Adam: Adam オプティマイザーを使用してモデル パラメータを更新するアルゴリズム。一般的なユースケースは次のとおりです。
- レコメンデーション システム: 企業は、Adam との連携により、購入履歴に基づいてユーザーに商品をおすすめするモデルをトレーニングできます。
- ランキング: Adam との連携により、検索結果をランク付けするモデルをトレーニングできます。
- クリック率の予測: Adam との連携により、ユーザーが広告をクリックする可能性を予測するモデルをトレーニングできます。
- 連携平均: 参加するクライアントのモデル パラメータの平均を算出するアルゴリズム。データが比較的均一で、モデルが複雑すぎないユースケースに適しています。一般的なユースケースは次のとおりです。
ユースケース
このセクションでは、クロスサイロ アーキテクチャとクロスデバイス アーキテクチャが、フェデレーション ラーニング プラットフォームに適しているユースケースについて説明します。
フェデレーション ラーニングは、多くのクライアントが共同でモデルをトレーニングする ML 設定です。このプロセスは中央のコーディネーターが主導し、トレーニング データは分散されたままになります。
フェデレーション ラーニング パラダイムでは、クライアントがグローバル モデルをダウンロードし、自身のデータを使用してローカルでトレーニングすることでモデルを改善します。各クライアントは、計算されたモデルの更新を中央のサーバーに返します。ここでモデルの更新が集約され、グローバル モデルの新しいイテレーションが生成されます。これらのリファレンス アーキテクチャでは、モデル トレーニングのワークロードは GKE で実行されます。
フェデレーション ラーニングは、データ最小化のプライバシー原則を具現化し、計算の各段階で収集されるデータを制限します。これにより、データへのアクセスを制限し、処理したデータをできるだけ早く破棄します。また、フェデレーション ラーニングの問題設定は、追加のプライバシー保護手法と互換性があります。たとえば、差分プライバシー(DP)を使用してモデルの匿名化を改善し、最終モデルが個々のユーザーのデータを記憶しないようにします。
ユースケースにもよりますが、フェデレーション ラーニングを使用したモデルのトレーニングには次のようなメリットがあります。
- コンプライアンス: 規制によりデータの使用方法や共有方法が制限される場合があります。これらの規制を遵守するために、フェデレーション ラーニングが使用される場合があります。
- 通信の効率化: データを一元化するよりも、分散データでモデルをトレーニングするほうが効率的な場合があります。たとえば、モデルのトレーニングに必要なデータセットが大きいために一か所に移動できない場合などが該当します。
- データへのアクセスを可能にする: フェデレーション ラーニングでは、トレーニング データをユーザーごとまたは組織ごとのデータサイロに分散させることができます。
- モデルの精度の向上: 合成データ(プロキシデータ)ではなく、プライバシーを確保しながら実際のユーザーデータでトレーニングすることで、モデルの精度を向上させることができます。
フェデレーション ラーニングにはさまざまな種類があり、データの発生元とローカル計算が行われる場所に特徴があります。このドキュメントのアーキテクチャでは、クロスサイロとクロスデバイスの 2 種類のフェデレーション ラーニングについて説明しています。他のタイプのフェデレーション ラーニングは取り扱いません。
フェデレーション ラーニングは、次のようにデータセットのパーティショニング方法によってさらに分類されます。
- 水平フェデレーション ラーニング(HFL): 特徴(列)が同じで、サンプル(行)が異なるデータセット。たとえば、複数の病院に同じ医療パラメータの患者記録があっても、患者集団が異なる場合があります。
- 垂直フェデレーション ラーニング(VFL): サンプル(行)が同じで、特徴(列)が異なるデータセット。たとえば、銀行と e コマース会社で同じ顧客データを所有していても、顧客の財務情報や購入情報が異なる場合があります。
- フェデレーション トランスファー ラーニング(FTL): データセット内のサンプルと特徴の両方で部分的に重複しています。たとえば、2 つの病院の患者レコードで、一部の患者が重複し、一部の医療パラメータが共有されていますが、各データセットに固有の特徴が含まれている場合があります。
クロスサイロの連携コンピューティングでは、参加するメンバーが組織または会社になります。実際には、メンバーの数は通常ごくわずかです(例: 100 人程度)。通常、クロスサイロ計算は参加組織の異なるデータセットを使用しますが、元データを共有することなく、共有モデルをトレーニングしたり、集計結果を分析したい場合もあります。たとえば、参加メンバーは、異なる法人を代表する場合など、異なる Google Cloud 組織に環境を配置できます。また、同じ法人の異なる部門を代表する場合など、同じ Google Cloud 組織に環境を配置することもできます。
参加メンバーは、互いのワークロードを信頼できるエンティティと見なせない場合があります。たとえば、参加メンバーは、コーディネーターなどのサードパーティから受け取ったトレーニング ワークロードのソースコードにアクセスできない場合があります。このソースコードにアクセスできないため、参加メンバーはワークロードを完全に信頼できるとは言えません。
信頼できないワークロードが承認なしにデータやリソースにアクセスできないようにするには、次の方法をおすすめします。
- 信頼できないワークロードを分離された環境にデプロイします。
- 信頼できないワークロードには、ワークロードに割り当てられたトレーニング ラウンドを完了するために厳密に必要なアクセス権と権限のみを付与します。
信頼できない可能性のあるワークロードを分離できるように、これらのリファレンス アーキテクチャでは、分離された Kubernetes namespace の構成などのセキュリティ制御を実装します。各 namespace には専用の GKE ノードプールがあります。ネームスペース間の通信とクラスタのインバウンド トラフィックとアウトバウンド トラフィックは、この設定を明示的にオーバーライドしない限り、デフォルトで禁止されています。
次に、クロスサイロのフェデレーション ラーニングのユースケースの例を示します。
- 不正行為の検出: フェデレーション ラーニングを使用すると、複数の組織に分散されたデータに対する不正行為検出モデルをトレーニングできます。たとえば、銀行のコンソーシアムは、フェデレーション ラーニングを使用して、不正な取引を検出するモデルをトレーニングできます。
- 医療診断: フェデレーション ラーニングを使用すると、複数の病院に分散されたデータで医療診断モデルをトレーニングできます。たとえば、病院グループはフェデレーション ラーニングを使用して、がんの診断モデルをトレーニングできます。
クロスデバイス フェデレーション ラーニングは、参加メンバーがスマートフォン、車両、IoT デバイスなどのエンドユーザー デバイスである連携型コンピューティングの一種です。メンバーの数は、数百万人から数千万人の規模になることもあります。
クロスデバイス フェデレーション ラーニングのプロセスは、クロスサイロ フェデレーション ラーニングのプロセスと似ています。ただし、数千台から数百万台ものデバイスを扱う際に必要になるいくつかの追加要素に対応するために、リファレンス アーキテクチャを適応させる必要もあります。クロスデバイス フェデレーション ラーニングのユースケースで発生するシナリオに対処するには、管理ワークロードをデプロイする必要があります。たとえば、トレーニング ラウンドでクライアントのサブセットの調整が必要になる場合などです。クロスデバイス アーキテクチャでは、FCP サービスをデプロイすることでこの機能を利用できます。これらのサービスは、TFF との接続ポイントがあるワークロードを使用します。この調整を管理するコードの記述には TFF が使用されます。
次に、クロスデバイス フェデレーション ラーニングのユースケースの例を示します。
- パーソナライズされたおすすめ: クロスデバイス フェデレーション ラーニングを使用して、複数のデバイスに分散しているデータでパーソナライズされたおすすめを提供するモデルをトレーニングできます。たとえば、購入履歴に基づいてユーザーに商品をおすすめするモデルをトレーニングするために、フェデレーション ラーニングを使用できます。
- 自然言語処理: フェデレーション ラーニングを使用すると、複数のデバイスに分散されたデータで自然言語処理モデルをトレーニングできます。たとえば、フェデレーション ラーニングを使用して、音声認識の精度を向上させるモデルをトレーニングできます。
- 車両のメンテナンスの必要性の予測: フェデレーション ラーニングを使用して、車両のメンテナンスが必要な時期を予測するモデルをトレーニングできます。このモデルは、複数の車両から収集されたデータでトレーニングできます。このアプローチにより、モデルはプライバシーを侵害することなく、すべての車両のデータから学習できます。
次の表に、クロスサイロ アーキテクチャおよびクロスデバイス アーキテクチャの機能と、ユースケースに適用可能なフェデレーション ラーニングのシナリオを分類する方法を示します。
| 機能 | クロスサイロの連携計算 | クロスデバイスの連携計算 |
|---|---|---|
| 母集団のサイズ | 通常は小さい(たとえば、100 台未満のデバイス) | 数千台、数百万台、数億台のデバイスに対応するスケーラビリティ |
| 参加メンバー | 組織または企業 | モバイル デバイス、エッジデバイス、車両 |
| 最も一般的なデータ パーティショニング | HFL、VFL、FTL | HFL |
| データの機密性 | 参加者が未加工の状態で共有したくない機密データ | 中央のサーバーと共有され、機密性が非常に高いデータ |
| データの可用性 | ほとんどの参加者が常に利用できる | 参加者の一部しか利用できない |
| サンプル ユースケース | 不正行為の検出、医療診断、財務予測 | フィットネスの記録、音声認識、画像分類 |
設計上の考慮事項
このセクションでは、このリファレンス アーキテクチャを使用して、セキュリティ、信頼性、運用効率、費用、パフォーマンスに関する特定の要件を満たす 1 つ以上のアーキテクチャを開発する際に役立つガイダンスを示します。
クロスサイロ アーキテクチャの設計上の考慮事項
Google Cloud にクロスサイロ フェデレーション ラーニング アーキテクチャを実装するには、次の最小限の前提条件を実装する必要があります。詳細については、以降のセクションで説明します。
- フェデレーション ラーニング コンソーシアムを確立する
- 実装するフェデレーション ラーニング コンソーシアムのコラボレーション モデルを決定します。
- 参加組織の責任を決定する
これらの前提条件に加えて、フェデレーションのオーナーは、以下のようなアクションを行う必要があります(このドキュメントでは説明しません)。
- フェデレーション ラーニング コンソーシアムを管理する。
- コラボレーション モデルを設計して実装する。
- モデルのトレーニング データと、フェデレーション オーナーがトレーニングするモデルを準備し、管理、操作する。
- フェデレーション ラーニング ワークフローの作成、コンテナ化、オーケストレーションを行う。
- フェデレーション ラーニング ワークロードをデプロイして管理する。
- データを安全に転送するために参加組織の通信チャネルを設定する。
フェデレーション ラーニング コンソーシアムを確立する
フェデレーション ラーニング コンソーシアムは、クロスサイロ フェデレーション ラーニングに参加する組織のグループです。コンソーシアムの組織は ML モデルのパラメータのみを共有します。また、プライバシーを強化するため、これらのパラメータは暗号化されます。フェデレーション ラーニング コンソーシアムで許可されている場合は、組織は個人情報(PII)を含まないデータを集約することもできます。
フェデレーション ラーニング コンソーシアムのコラボレーション モデルを決定する
フェデレーション ラーニング コンソーシアムは、次のようなさまざまなコラボレーション モデルを実装できます。
- フェデレーション オーナーまたはオーケストレーターと呼ばれる 1 つの調整組織と、参加組織またはデータオーナーのセットで構成される集中モデル。
- グループとして調整される組織で構成される分散モデル。
- 多様な参加組織のコンソーシアムで構成される異種モデル(すべての組織が異なるリソースをコンソーシアムに導入する)。
このドキュメントでは、コラボレーション モデルが集中モデルであることを前提としています。
参加組織の責任を決定する
フェデレーション ラーニング コンソーシアムのコラボレーション モデルを選択したら、フェデレーション オーナーは参加組織の責任を決める必要があります。
フェデレーション オーナーは、フェデレーション ラーニング コンソーシアムの構築時に、以下のことも行う必要があります。
- フェデレーション ラーニング作業を調整する。
- グローバル ML モデルと、参加組織と共有する ML モデルを設計して実装する。
- フェデレーション ラーニング ラウンド(ML トレーニング プロセスのイテレーションの手法)を定義する。
- 特定のフェデレーション ラーニング ラウンドに参加する参加者の組織を選択する。この選択はコホートと呼ばれます。
- 参加者組織のコンソーシアムのメンバーシップ確認手順を設計して実装する。
- グローバル ML モデルと ML モデルを更新して、参加組織と共有する。
- フェデレーション ラーニング コンソーシアムがプライバシー、セキュリティ、規制の要件を満たしていることを確認するツールを参加組織に提供する。
- 安全で暗号化された通信チャネルを参加組織に提供する。
- 各フェデレーション ラーニング ラウンドを完了するために必要となる、機密情報でない集計データを参加組織に提供する。
参加組織に次の責任を担う必要があります。
- 安全な隔離環境(サイロ)を用意し、維持する。サイロは、参加組織が独自のデータを保存し、ML モデルのトレーニングを実装する場所です。参加組織は、独自のデータを他の組織と共有しません。
- 独自のコンピューティング インフラストラクチャと独自のローカルデータを使用して、フェデレーション オーナーから提供されるモデルをトレーニングする。
- PII を削除した後、モデルのトレーニング結果を集計データの形式でフェデレーション オーナーと共有する。
連携オーナーと参加組織は、Cloud Storage を使用して更新されたモデルとトレーニング結果を共有できます。
フェデレーション オーナーと参加組織は、モデルが要件を満たすまで ML モデル トレーニングを改良します。
Google Cloud にフェデレーション ラーニングを実装する
フェデレーション ラーニング コンソーシアムを確立し、コラボレーションの方法を決定したら、参加組織で以下を行うことをおすすめします。
フェデレーション ラーニング コンソーシアムのインフラストラクチャをプロビジョニングして構成する
フェデレーション ラーニング コンソーシアムのインフラストラクチャをプロビジョニングして構成する場合、フェデレーション ML モデルをトレーニングするワークロードを作成して参加組織に配信するのは、フェデレーション オーナーの責任です。サードパーティ(フェデレーション オーナー)がワークロードを作成して提供しているため、参加組織は、それらのワークロードをランタイム環境にデプロイする際に注意が必要です。
参加組織は、個々のセキュリティのベスト プラクティスに従って環境を構成し、各ワークロードに付与されるスコープと権限を制限するコントロールを適用する必要があります。個々のセキュリティのベスト プラクティスに従うことに加えて、フェデレーション オーナーと参加組織は、フェデレーション ラーニングに固有の脅威ベクターを検討することをおすすめします。
コラボレーション モデルを実装する
フェデレーション ラーニング コンソーシアム インフラストラクチャを準備した後、フェデレーション オーナーは、参加組織が相互にやり取りできるメカニズムを設計して実装します。この手法は、フェデレーション オーナーがフェデレーション ラーニング コンソーシアムに選択したコラボレーション モデルに沿っています。
フェデレーション ラーニング作業を開始する
コラボレーション モデルの実装後、フェデレーション オーナーはトレーニングするグローバル ML モデルと、参加者の組織と共有する ML モデルを実装します。これらの ML モデルの準備ができたら、フェデレーション オーナーはフェデレーション ラーニング作業の最初のラウンドを開始します。
フェデレーション ラーニングの各ラウンド中に、フェデレーション オーナーは次のことを行います。
- 参加組織と共有する ML モデルを配布する。
- 参加組織が、フェデレーション オーナーによって共有されている ML モデルのトレーニングの結果を提供するのを待機する。
- 参加組織が生成したトレーニング結果を収集して処理する。
- 参加組織から適切なトレーニング結果を受け取ったときに、グローバル ML モデルを更新する。
- 必要に応じて、ML モデルを更新してコンソーシアムの他のメンバーと共有する。
- フェデレーション ラーニングの次のラウンド用にトレーニング データを準備する。
- フェデレーション ラーニングの次のラウンドを開始する。
セキュリティ、プライバシー、コンプライアンス
このセクションでは、このリファレンス アーキテクチャを使用して、Google Cloud でフェデレーション ラーニング プラットフォームを設計して構築する際に考慮すべき要素について説明します。このガイダンスは、このドキュメントで説明する両方のアーキテクチャに適用されます。
環境にデプロイするフェデレーション ラーニング ワークロードにより、ユーザー、データ、フェデレーション ラーニング モデル、インフラストラクチャが脅威にさらされ、ビジネスに影響を与える可能性があります。
フェデレーション ラーニング環境のセキュリティを強化するために、これらのリファレンス アーキテクチャでは、環境のインフラストラクチャに重点を置いた GKE セキュリティ コントロールを構成します。これらの制御では、フェデレーション ラーニングのワークロードやユースケースに固有の脅威から保護するのに十分でない場合があります。各フェデレーション ラーニングのワークロードとユースケースの特殊性により、フェデレーション ラーニングの実装の保護を目的としたセキュリティ管理については、このドキュメントで取り扱いません。これらの脅威の詳細と例については、フェデレーション ラーニングのセキュリティに関する考慮事項をご覧ください。
GKE のセキュリティ管理
このセクションでは、これらのアーキテクチャで適用するコントロールについて説明します。これらのコントロールにより、GKE クラスタを保護することができます。
GKE クラスタのセキュリティの強化
これらのリファレンス アーキテクチャは、次のセキュリティ設定を実装する GKE クラスタを作成する際に役立ちます。
- 承認済みネットワークを使用して限定公開 GKE クラスタを作成し、クラスタノードとコントロール プレーンのインターネットへの公開を制限する。
containerdランタイムで強化されたノードイメージを使用するシールドされたノードを使用する。- GKE Sandbox を使用して、テナント ワークロードの分離を強化する。
- デフォルトで保存データを暗号化する。
- 転送中のデータはデフォルトで暗号化される。
- アプリケーション レイヤでクラスタの Secret を暗号化する。
- 必要に応じて、Confidential Google Kubernetes Engine Node を有効にして、使用中のデータを暗号化します。
GKE のセキュリティ設定の詳細については、クラスタのセキュリティを強化するとセキュリティ ポスチャー ダッシュボードについてをご覧ください。
VPC ファイアウォール ルール
Virtual Private Cloud(VPC)ファイアウォール ルールは、Compute Engine VM との間で許可するトラフィックを制御します。このルールを使用すると、レイヤ 4 属性に応じて VM の粒度でトラフィックをフィルタリングできます。
デフォルトの GKE クラスタのファイアウォール ルールを使用して GKE クラスタを作成します。これらのファイアウォール ルールにより、クラスタノードと GKE コントロール プレーン間の通信、およびクラスタ内のノードと Pod 間の通信が有効になります。
テナント ノードプール内のノードに追加のファイアウォール ルールを適用します。これらのファイアウォール ルールは、テナントノードからの下り(外向き)トラフィックを制限します。このアプローチでは、テナントノードの分離を強化できます。デフォルトでは、テナントノードからの下り(外向き)トラフィックはすべて拒否されます。必要な下り(外向き)は明示的に構成する必要があります。たとえば、テナントノードから GKE コントロール プレーンへの下り(外向き)と、限定公開の Google アクセスを使用した Google API への下り(外向き)を許可するファイアウォール ルールを作成します。ファイアウォール ルールは、テナント ノード プールのサービス アカウントを使用して、テナントノードを対象とします。
Namespace
Namespace を使用すると、Pod、Service、レプリケーション コントローラなど、クラスタ内の関連付けられたリソースのスコープを指定できます。名前空間を使用することによって、関連付けられたリソースの管理責任を 1 つのユニットとして委任できます。したがって、名前空間はほとんどのセキュリティ パターンに不可欠です。
名前空間は、制御プレーンを分離するための重要な機能です。ただし、ノード分離、データプレーンの分離、ネットワークの分離を行うことはできません。
一般的な方法は、個別のアプリケーションに Namespace を作成することです。たとえば、アプリケーションの UI コンポーネントに myapp-frontend という Namespace を作成できます。
これらのリファレンス アーキテクチャは、サードパーティ アプリをホストする専用の Namespace を作成する際に役立ちます。Namespace とそのリソースは、クラスタ内のテナントとして扱われます。名前空間にポリシーとコントロールを適用して、名前空間内のリソースのスコープを制限します。
ネットワーク ポリシー
ネットワーク ポリシーは、Pod レベルのファイアウォール ルールを使用して、レイヤ 4 ネットワーク トラフィック フローを処理します。ネットワーク ポリシーのスコープは Namespace です。
このドキュメントで説明するリファレンス アーキテクチャでは、サードパーティ アプリをホストするテナント Namespace にネットワーク ポリシーを適用します。デフォルトでは、ネットワーク ポリシーは Namespace 内の Pod との間で送受信されるすべてのトラフィックを拒否します。必要なトラフィックは、明示的に許可リストに追加する必要があります。たとえば、これらのリファレンス アーキテクチャのネットワーク ポリシーは、必要なクラスタ サービス(クラスタの内部 DNS や Cloud Service Mesh コントロール プレーンなど)へのトラフィックを明示的に許可します。
Config Sync
Config Sync は、Git リポジトリに保存されている構成ファイルと GKE クラスタの同期を維持します。Git リポジトリは、クラスタ構成とポリシーに関する信頼できる単一の情報源として機能します。Config Sync は宣言型です。ポリシーを適用するためにクラスタの状態を継続的にチェックし、構成ファイルで宣言されている状態を適用します。これにより、構成のずれを防ぐことができます。
Config Sync を GKE クラスタにインストールします。Cloud Source Repositories からクラスタの構成とポリシーを同期するように Config Sync を構成します。同期されるリソースには次のものがあります。
- クラスタレベルの Cloud Service Mesh の構成
- クラスタレベルのセキュリティ ポリシー
- テナントの名前空間レベルの構成とポリシー(ネットワーク ポリシー、サービス アカウント、RBAC ルール、Cloud Service Mesh の構成など)
Policy Controller
Google Kubernetes Engine(GKE)Enterprise エディションの Policy Controller は、Kubernetes 向けの動的アドミッション コントローラであり、Open Policy Agent(OPA)によって実行される CustomResourceDefinition ベース(CRD ベース)のポリシーを適用します。
アドミッション コントローラは、オブジェクトが永続化される前、かつリクエストが認証、承認された後に Kubernetes API サーバーへのリクエストをインターセプトする Kubernetes プラグインです。アドミッション コントローラを使用して、クラスタの使用方法を制限できます。
Policy Controller を GKE クラスタにインストールします。これらのリファレンス アーキテクチャには、クラスタの保護に役立つサンプル ポリシーが含まれています。Config Sync を使用して、ポリシーをクラスタに自動的に適用します。次のポリシーを適用します。
- Pod セキュリティの適用に役立つ選択済みのポリシー。たとえば、Pod が特権コンテナを実行するのを禁止し、読み取り専用のルート ファイル システムを必須にするポリシーを適用します。
- Policy Controller テンプレート ライブラリのポリシー。たとえば、NodePort タイプのサービスを禁止するポリシーを適用します。
Cloud Service Mesh
Cloud Service Mesh は、サービス間の安全な通信の管理を簡素化するサービス メッシュです。これらのリファレンス アーキテクチャでは、次の処理を行うように Cloud Service Mesh が構成されます。
- サイドカー プロキシを自動的に挿入する。
- メッシュ内のサービス間に mTLS 通信を適用する。
- 既知のホストへのアウトバウンド メッシュ トラフィックのみに制限する。
- 特定のクライアントからのインバウンド トラフィックのみに制限する。
- ネットワーク上のピアの IP アドレスではなく、サービス ID に基づいてネットワーク セキュリティ ポリシーを構成できるようにする。
- メッシュ内のサービス間の承認済みの通信を制限する。たとえば、テナントの Namespace 内のアプリは、同じ Namespace 内のアプリまたは既知の外部ホストのセットとのみ通信できます。
- すべてのインバウンドおよびアウトバウンド トラフィックをメッシュ ゲートウェイ経由で転送する。このゲートウェイで、詳細なトラフィック制御を適用できます。
- クラスタ間のセキュアな通信をサポートします。
Node Taints とアフィニティ
Node Taints とノード アフィニティは、Pod をクラスタノードにスケジュールする方法に影響を与える Kubernetes メカニズムです。
taint を追加したノードは Pod を排除します。Kubernetes は、Pod に taint の toleration がなければ、taint が追加されたノードに Pod をスケジュールしません。Node Taints を使用すると、特定のワークロードまたはテナントのみが使用するノードを予約できます。taint と toleration はマルチテナント クラスタでよく使用されます。詳細については、taint と toleration を使用した専用ノードのドキュメントをご覧ください。
ノード アフィニティを使用すると、Pod を特定のラベルを持つノードに制限できます。Pod にノード アフィニティの要件が存在する場合は、ノードにアフィニティの要件と一致するラベルが付加されている場合を除き、Kubernetes はノードに Pod をスケジュール設定しません。ノード アフィニティを使用すると、Pod を適切なノードにスケジュール設定できます。
Node Taints とノード アフィニティを併用すると、テナント ワークロード Pod がテナント用に予約されたノードにのみスケジュールされます。
これらのリファレンス アーキテクチャは、次の方法でテナントアプリのスケジューリングを制御する際に役立ちます。
- テナント専用の GKE ノードプールを作成する。プール内の各ノードには、テナント名に関連する taint があります。
- テナント名前空間をターゲットとする Pod に適切な toleration とノード アフィニティを自動的に適用する。toleration とアフィニティは、PolicyController のミューテーションを使用して適用します。
最小権限
セキュリティのベスト プラクティスは、Google Cloud プロジェクトと GKE クラスタなどのリソースに対して最小権限の原則を採用することです。これにより、クラスタ内で実行されるアプリと、クラスタを使用するデベロッパーやオペレーターには、必要最小限の権限セットのみが付与されます。
これらのリファレンス アーキテクチャは、次の方法で最小権限のサービス アカウントを使用する際に役立ちます。
- 各 GKE ノードプールは独自のサービス アカウントを受け取ります。たとえば、テナント ノードプール内のノードは、それらのノード専用のサービス アカウントを使用します。ノードサービス アカウントは、必要最小限の権限で構成されます。
- クラスタは Workload Identity Federation for GKE を使用して、Kubernetes サービス アカウントを Google サービス アカウントに関連付けます。これにより、サービス アカウント キーをダウンロードして保存することなく、必要な Google API への制限付きアクセス権をテナントアプリに付与できます。たとえば、Cloud Storage バケットからデータを読み取る権限をサービス アカウントに付与できます。
これらのリファレンス アーキテクチャは、次の方法でクラスタ リソースへのアクセスを制限する際に活用できます。
- アプリを管理するための権限が限定された Kubernetes RBAC ロールのサンプルを作成します。このロールは、テナント名前空間でアプリを操作するユーザーとグループに付与できます。ユーザーとグループのこの制限付きロールを適用することで、これらのユーザーには、テナント名前空間内のアプリリソースを変更する権限のみが付与されます。クラスタレベルのリソースや、Cloud Service Mesh ポリシーなどの機密性の高いセキュリティ設定を変更する権限は付与されません。
Binary Authorization
Binary Authorization を使用すると、GKE 環境にデプロイされるコンテナ イメージについて定義したポリシーを適用できます。Binary Authorization では、定義されたポリシーに準拠するコンテナ イメージのみがデプロイされます。他のコンテナ イメージのデプロイは許可されません。
このリファレンス アーキテクチャでは、Binary Authorization はデフォルト構成で有効になっています。Binary Authorization のデフォルト構成を検査するには、ポリシー YAML ファイルをエクスポートするをご覧ください。
ポリシーの構成方法の詳細については、次の具体的なガイダンスをご覧ください。
組織間の証明書の検証
Binary Authorization を使用すると、サードパーティの署名者によって生成された証明書を検証できます。たとえば、クロスサイロ フェデレーション ラーニングのユースケースでは、別の参加組織が作成した証明書を検証できます。
サードパーティが作成した証明書を検証するには、次の操作を行います。
- 検証する証明書の作成に第三者が使用した公開鍵を受け取ります。
- 証明書を検証する証明書発行者を作成します。
- サードパーティから受け取った公開鍵を、作成した認証者に追加します。
認証者の作成の詳細については、次の具体的なガイダンスをご覧ください。
GKE Compliance ダッシュボード
GKE Compliance ダッシュボードは、セキュリティ ポスチャーを強化するための実用的な分析情報を提供します。また、業種別ベンチマークと標準に関するコンプライアンス レポートの自動化にも役立ちます。GKE クラスタを登録して、コンプライアンス レポートの自動化を有効にできます。
詳細については、GKE Compliance ダッシュボードについてをご覧ください。
フェデレーション ラーニングのセキュリティに関する考慮事項
厳格なデータ共有モデルにもかかわらず、フェデレーション ラーニングは、すべての標的型攻撃に対して本質的に安全ではありません。このドキュメントで説明するいずれかのアーキテクチャをデプロイする際は、これらのリスクを考慮する必要があります。また、ML モデルやモデル トレーニング データに関する意図しない情報の漏洩のリスクもあります。たとえば、攻撃者は、グローバルな ML モデルやフェデレーション ラーニングの取り組みのラウンドを意図的に侵害したり、タイミング攻撃(一種のサイドチャネル攻撃)を使用して、トレーニング データセットのサイズに関する情報を収集する可能性があります。
フェデレーション ラーニングの実装に対する最も一般的な脅威は次のとおりです。
- 意図的または非意図的なトレーニング データの記録。フェデレーション ラーニングの実装または攻撃者が、意図的または意図せずにデータを操作しにくい方法で保存している場合があります。攻撃者が、保存されたデータをリバース エンジニアリングして、グローバル ML モデルやフェデレーション ラーニングの過去のラウンドに関する情報を収集できる場合があります。
- グローバル ML モデルの更新からの情報の抽出。フェデレーション ラーニングの最中に、フェデレーション オーナーが参加組織とデバイスから収集したグローバル ML モデルの更新を、攻撃者がリバース エンジニアリングする場合があります。
- フェデレーション オーナーがラウンドを損なう可能性がある。侵害を受けたフェデレーション オーナーが不正なサイロまたはデバイスを制御し、フェデレーション ラーニング作業のラウンドを開始する場合があります。ラウンドの最後に、侵害を受けたフェデレーション オーナーは、不正なサイロが生成した更新と比較することで、正規の参加組織とデバイスから収集した更新に関する情報を収集できます。
- 参加組織とデバイスがグローバル ML モデルを損なう可能性がある。フェデレーション ラーニングの最中に、攻撃者が不正な更新や重要性の低い更新を生成して、グローバル ML モデルのパフォーマンス、品質、整合性に悪影響を及ぼす可能性があります。
このセクションで説明する脅威の影響を軽減するために、次のベスト プラクティスをおすすめします。
- モデルをチューニングして、トレーニング データの記憶を最小限に抑える。
- プライバシー保護メカニズムを実装する。
- グローバル ML モデル、共有する ML モデル、トレーニング データ、フェデレーション ラーニングを実現するために実装したインフラストラクチャを定期的に監査する。
- Secure Aggregation アルゴリズムを実装して、参加組織が生成するトレーニング結果を処理する。
- 公開鍵基盤を使用して、データ暗号鍵を安全に生成および配布する。
- Confidential Computing プラットフォームにインフラストラクチャをデプロイする。
フェデレーション オーナーは、次の追加手順も行う必要があります。
- クロスサイロ アーキテクチャの場合は各参加組織の ID と各サイロの整合性、クロスデバイス アーキテクチャの場合は各デバイスの ID と整合性を確認する。
- 参加組織とデバイスが生成できるグローバル ML モデルの更新スコープを制限する。
信頼性
このセクションでは、このドキュメントのいずれかのリファレンス アーキテクチャを使用して、Google Cloud でフェデレーション ラーニング プラットフォームを設計および構築するときに考慮すべき設計要素について説明します。
Google Cloud でフェデレーション ラーニング アーキテクチャを設計する際は、このセクションのガイダンスに従ってワークロードの可用性とスケーラビリティを改善し、アーキテクチャが停止や災害に耐えられるようにすることをおすすめします。
GKE: GKE は、ワークロードの可用性要件と予算に合わせて調整できる複数のクラスタタイプをサポートしています。たとえば、コントロール プレーンとノードをリージョン内の複数のゾーンに分散するリージョン クラスタや、1 つのゾーンにコントロール プレーンとノードがあるゾーンクラスタを作成できます。リージョン GKE クラスタは、クロスサイロ アーキテクチャとクロスデバイス アーキテクチャの両方で使用されます。GKE クラスタを作成する際に考慮すべき事項の詳細については、クラスタ構成の選択をご覧ください。
クラスタの種類や、コントロール プレーンとクラスタノードをリージョンとゾーンに分散する方法に応じて、GKE はゾーンやリージョンの停止からワークロードを保護するさまざまな障害復旧機能を提供します。GKE の障害復旧機能の詳細については、クラウド インフラストラクチャの停止に対する障害復旧の設計: Google Kubernetes Engine をご覧ください。
Google Cloud Load Balancing: GKE は、ワークロードへのトラフィックのロード バランシングをいくつかの方法でサポートしています。Kubernetes Gateway API と Kubernetes Service API の GKE 実装を使用すると、Cloud Load Balancing を自動的にプロビジョニングして構成し、GKE クラスタで実行されているワークロードを安全かつ確実に公開できます。
これらのリファレンス アーキテクチャでは、すべての上り(内向き)トラフィックと下り(外向き)トラフィックが Cloud Service Mesh ゲートウェイを通過します。これらのゲートウェイにより、GKE クラスタの内外でトラフィックの流れを厳密に制御できます。
クロスデバイス フェデレーション ラーニングにおける信頼性の課題
クロスデバイス フェデレーション ラーニングには、クロスサイロ シナリオでは発生しない信頼性に関する課題がいくつかあります。次に例を示します。
- デバイスの接続が不安定または断続的
- デバイスの保存容量が制限される
- コンピューティング能力とメモリが制限される
接続が不安定な場合、次のような問題が発生する可能性があります。
- 最新でない更新とモデルの逸脱: デバイスの接続が断続的に発生すると、ローカルのモデル更新が古くなり、グローバル モデルの現在の状態と比較して情報が古くなることがあります。古い更新を集計すると、モデルの逸脱が発生する可能性があります。これは、トレーニング プロセスの不整合により、グローバル モデルが最適なソリューションから逸脱することを意味します。
- 不均衡な貢献とバイアスのかかったモデル: 通信が断続的になると、参加デバイスからの貢献が不均一に分散する可能性があります。接続が不安定なデバイスでは提供される更新が少なくなるため、基盤となるデータ分布の表現が不均衡になる可能性があります。この不均衡により、グローバル モデルは、接続の信頼性が高いデバイスのデータに対してバイアスをかける可能性があります。
- 通信オーバーヘッドとエネルギー消費の増加: 通信が断続的になると、デバイスが失われた更新や破損した更新を再送信する必要があるため、通信オーバーヘッドが増加する可能性があります。この問題により、特にバッテリー駆動時間の短いデバイスではデバイスのエネルギー消費量が増加する可能性があります。これは、更新を正常に送信するために、アクティブな接続を長期間維持しなければならないためです。
断続的な通信による影響を軽減するために、このドキュメントのリファレンス アーキテクチャで FCP を使用できます。
FCP プロトコルを実行するシステム アーキテクチャは、次の要件を満たすように設計できます。
- 長時間実行ラウンドを処理する。
- 投機的実行を可能にする(すぐにチェックインが増えることを想定し、必要な数のクライアントが集まる前にラウンドを開始できます)。
- デバイスで、参加するタスクを選択できるようにする。このアプローチでは、置換なしのサンプリングなどの機能を有効にできます。これは、母集団のサンプリング単位が選択される機会が 1 回のみのサンプリング方法です。このアプローチでは、不均衡な貢献とバイアスのかかったモデルを回避できます。
- 差分プライバシー(DP)や信頼された集計(TAG)などの匿名化手法を拡張できる。
デバイスのストレージとコンピューティング能力の制限を緩和するには、次の方法が役立ちます。
- フェデレーション ラーニングの計算を実行するために使用できる最大容量を確認する
- 特定の時点で保持できるデータ量を把握する
- クライアントで利用可能なコンピューティングと RAM 内で動作するようにクライアント側のフェデレーション ラーニング コードを設計する
- ストレージの空き容量が不足した場合の影響を把握し、これを管理するプロセスを実装する
費用の最適化
このセクションでは、このリファレンス アーキテクチャを使用して確立したフェデレーション ラーニング プラットフォームを Google Cloud 上に構築し、実行するコストを最適化するためのガイダンスを示します。このガイダンスは、このドキュメントで説明する両方のアーキテクチャに適用されます。
GKE でワークロードを実行すると、ワークロードのリソース要件に応じてクラスタをプロビジョニングして構成することで、環境の費用を最適化できます。また、クラスタノードと Pod の自動スケーリングや、クラスタの適切なサイジングなど、クラスタとクラスタノードを動的に再構成する機能も有効になります。
GKE 環境のコストを最適化する方法については、GKE でコストが最適化された Kubernetes アプリケーションを実行するためのベスト プラクティスをご覧ください。
運用効率
このセクションでは、このリファレンス アーキテクチャを使用して Google Cloud でフェデレーション ラーニング プラットフォームを構築して実行する際の効率を最適化するために考慮すべき要素について説明します。このガイダンスは、このドキュメントで説明する両方のアーキテクチャに適用されます。
フェデレーション ラーニング アーキテクチャの自動化とモニタリングを強化するには、MLOps の原則(DevOps の原則を ML システムに応用したもの)を採用することをおすすめします。MLOps を実践すると、統合、テスト、リリース、デプロイ、インフラストラクチャ管理など、ML システム構築のすべてのステップで自動化とモニタリングを推進できます。MLOps の詳細については、MLOps: ML における継続的デリバリーと自動化のパイプラインをご覧ください。
パフォーマンスの最適化
このセクションでは、このリファレンス アーキテクチャを使用して Google Cloud でフェデレーション ラーニング プラットフォームを構築して実行する際に、ワークロードのパフォーマンスを最適化するために考慮すべき要素について説明します。このガイダンスは、このドキュメントで説明する両方のアーキテクチャに適用されます。
GKE では、ワークロードの需要に合わせて GKE 環境のサイジングとスケーリングを自動的または手動で行い、リソースのオーバー プロビジョニングを回避することができます。たとえば、Recommender を使用して分析情報と推奨事項を生成し、GKE リソースの使用率を最適化できます。
GKE 環境のスケーリング方法を検討する際は、環境とワークロードのスケーリング方法を短期、中期、長期の計画で設計することをおすすめします。たとえば、数週間、数か月、数年で GKE のフットプリントがどのように拡大するのかを検討します。計画を準備しておくと、GKE が提供するスケーラビリティ機能を最大限に活用して GKE 環境を最適化し、コストを削減できます。クラスタとワークロードのスケーラビリティの計画の詳細については、GKE のスケーラビリティについてをご覧ください。
ML ワークロードのパフォーマンスを向上させるため、Google が設計し、大規模な AI モデルのトレーニングと推論用に最適化された AI アクセラレータである Cloud Tensor Processing Unit(Cloud TPU)を採用できます。
デプロイ
このドキュメントで説明しているクロスサイロとクロスデバイスのリファレンス アーキテクチャをデプロイするには、Google Cloud でのフェデレーション ラーニングの GitHub リポジトリをご覧ください。
次のステップ
- TensorFlow Federated プラットフォームにフェデレーション ラーニング アルゴリズムを実装する方法を確認する。
- Advances and Open Problems in Federated Learning について学習する。
- Google AI ブログでフェデレーション ラーニングについて確認する。
- ML モデルを改善するために、匿名化された集計情報でフェデレーション ラーニングを行う際に、Google がプライバシーをどのように保護しているのかを確認する。
- Towards Federated learning at scale を読む。
- ML モデルのライフサイクルを管理する MLOps パイプラインの実装方法を確認する。
- Google Cloud の AI ワークロードと ML ワークロードに固有の原則と推奨事項の概要については、アーキテクチャ フレームワークの AI と ML の視点をご覧ください。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
寄稿者
作成者:
- Grace Mollison | ソリューション リード
- Marco Ferrari | クラウド ソリューション アーキテクト
その他の寄稿者:
- Chloé Kiddon | スタッフ ソフトウェア エンジニア / マネージャー
- Laurent Grangeau | ソリューション アーキテクト
- Lilian Felix | クラウド エンジニア