Questo documento di deployment descrive come eseguire il deployment di una pipeline Dataflow per elaborare file immagine su larga scala con l'API Cloud Vision. Questa pipeline archivia i risultati dei file elaborati in BigQuery. Puoi utilizzare i file a fini di analisi o per addestrare modelli BigQuery ML.
La pipeline Dataflow creata in questo deployment può elaborare milioni di immagini al giorno. L'unico limite è la quota dell'API Vision. Puoi aumentare la quota dell'API Vision in base alle tue esigenze di scalabilità.
Queste istruzioni sono rivolte a data engineer e data scientist. Questo documento presuppone che tu abbia una conoscenza di base della creazione di pipeline Dataflow utilizzando l'SDK Java di Apache Beam, GoogleSQL per BigQuery e scripting di shell di base. Si presume inoltre che tu abbia familiarità con l'API Vision.
Architettura
Il seguente diagramma illustra il flusso di sistema per la creazione di una soluzione di analisi della visione basata sull'IA.

Nel diagramma precedente, le informazioni fluiscono nell'architettura come segue:
- Un client carica file di immagini in un bucket Cloud Storage.
- Cloud Storage invia un messaggio relativo al caricamento dei dati a Pub/Sub.
- Pub/Sub invia una notifica a Dataflow relativa al caricamento.
- La pipeline Dataflow invia le immagini all'API Vision.
- L'API Vision elabora le immagini e restituisce le annotazioni.
- La pipeline invia i file annotati a BigQuery per consentirti di analizzarli.
Obiettivi
- Crea una pipeline Apache Beam per l'analisi delle immagini caricate in Cloud Storage.
- Utilizza Dataflow Runner v2 per eseguire la pipeline Apache Beam in modalità di streaming per analizzare le immagini non appena vengono caricate.
- Utilizza l'API Vision per analizzare le immagini per un insieme di tipi di funzionalità.
- Analizza le annotazioni con BigQuery.
Costi
In questo documento utilizzi i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi basata sull'utilizzo previsto,
utilizza il Calcolatore prezzi.
Al termine della creazione dell'applicazione di esempio, puoi evitare la fatturazione continua eliminando le risorse che hai creato. Per ulteriori informazioni, consulta la sezione Pulizia.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Clona il repository GitHub contenente il codice sorgente della pipeline Dataflow:
git clone https://github.com/GoogleCloudPlatform/dataflow-vision-analytics.git - Vai alla cartella principale del repository:
cd dataflow-vision-analytics - Segui le istruzioni riportate nella sezione Introduzione del repository dataflow-vision-analytics su GitHub per svolgere le seguenti attività:
- Abilita diverse API.
- Creare un bucket Cloud Storage.
- Crea un argomento e una sottoscrizione Pub/Sub.
- Creare un set di dati BigQuery.
- Configura diverse variabili di ambiente per questo deployment.
Eseguire la pipeline Dataflow per tutte le funzionalità dell'API Vision implementate
La pipeline Dataflow richiede ed elabora un insieme specifico di funzionalità e attributi dell'API Vision all'interno dei file annotati.
I parametri elencati nella tabella seguente sono specifici della pipeline Dataflow in questo deployment. Per l'elenco completo dei parametri di esecuzione di Dataflow standard, consulta Impostare le opzioni della pipeline Dataflow.
| Nome parametro | Descrizione |
|---|---|
|
Il numero di immagini da includere in una richiesta all'API Vision. Il valore predefinito è 1. Puoi aumentare questo valore fino a un massimo di 16. |
|
Il nome del set di dati BigQuery di output. |
|
Un elenco di funzionalità di elaborazione delle immagini. La pipeline supporta le funzionalità di etichetta, punto di riferimento, logo, volto, suggerimento di ritaglio e proprietà immagine. |
|
Il parametro che definisce il numero massimo di chiamate parallele all'API Vision. Il valore predefinito è 1. |
|
Parametri di stringa con nomi di tabelle per varie annotazioni. I valori predefiniti sono forniti per ogni tabella, ad esempio label_annotation. |
|
Il tempo di attesa prima di elaborare le immagini quando è presente un insieme incompleto di immagini. Il valore predefinito è 30 secondi. |
|
L'ID dell'abbonamento Pub/Sub che riceve le notifiche di Cloud Storage in entrata. |
|
L'ID progetto da utilizzare per l'API Vision. |
In Cloud Shell, esegui il comando seguente per elaborare le immagini per tutti i tipi di elementi supportati dalla pipeline Dataflow:
./gradlew run --args=" \ --jobName=test-vision-analytics \ --streaming \ --runner=DataflowRunner \ --enableStreamingEngine \ --diskSizeGb=30 \ --project=${PROJECT} \ --datasetName=${BIGQUERY_DATASET} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=IMAGE_PROPERTIES,LABEL_DETECTION,LANDMARK_DETECTION,LOGO_DETECTION,CROP_HINTS,FACE_DETECTION"L'account di servizio dedicato deve avere accesso in lettura al bucket contenente le immagini. In altre parole, a questo account deve essere concesso il ruolo
roles/storage.objectViewerper il bucket.Per ulteriori informazioni sull'utilizzo di un account di servizio dedicato, consulta Sicurezza e autorizzazioni di Dataflow.
Apri l'URL visualizzato in una nuova scheda del browser o vai alla pagina Job Dataflow e seleziona la pipeline test-vision-analytics.
Dopo alcuni secondi viene visualizzato il grafico del job Dataflow:
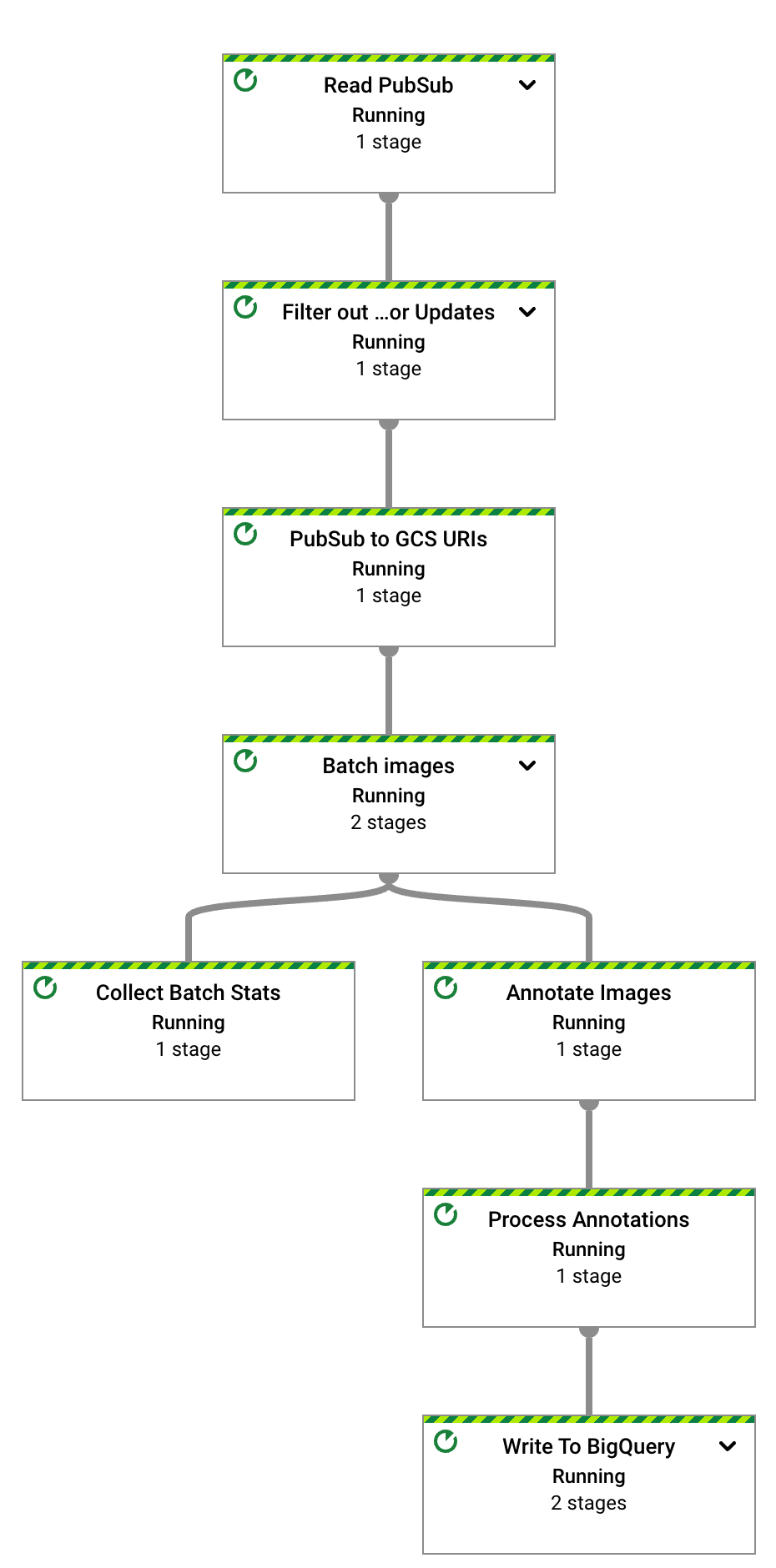
La pipeline Dataflow è in esecuzione e in attesa di ricevere notifiche di input dall'abbonamento Pub/Sub.
Attiva l'elaborazione delle immagini di Dataflow caricando i sei file di esempio nel bucket di input:
gcloud storage cp data-sample/* gs://${IMAGE_BUCKET}Nella console Google Cloud, individua il riquadro Contatori personalizzati e utilizzalo per esaminare i contatori personalizzati in Dataflow e verificare che Dataflow abbia elaborato tutte e sei le immagini. Puoi utilizzare la funzionalità di filtro del riquadro per accedere alle metriche corrette. Per visualizzare solo i contatori che iniziano con il prefisso
numberOf, digitanumberOfnel filtro.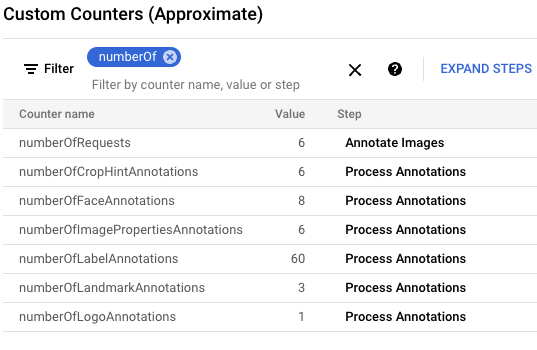
In Cloud Shell, verifica che le tabelle siano state create automaticamente:
bq query --nouse_legacy_sql "SELECT table_name FROM ${BIGQUERY_DATASET}.INFORMATION_SCHEMA.TABLES ORDER BY table_name"L'output è il seguente:
+----------------------+ | table_name | +----------------------+ | crop_hint_annotation | | face_annotation | | image_properties | | label_annotation | | landmark_annotation | | logo_annotation | +----------------------+
Visualizza lo schema della tabella
landmark_annotation. La funzionalitàLANDMARK_DETECTIONacquisisce gli attributi restituiti dalla chiamata API.bq show --schema --format=prettyjson ${BIGQUERY_DATASET}.landmark_annotationL'output è il seguente:
[ { "name":"gcs_uri", "type":"STRING" }, { "name":"feature_type", "type":"STRING" }, { "name":"transaction_timestamp", "type":"STRING" }, { "name":"mid", "type":"STRING" }, { "name":"description", "type":"STRING" }, { "name":"score", "type":"FLOAT" }, { "fields":[ { "fields":[ { "name":"x", "type":"INTEGER" }, { "name":"y", "type":"INTEGER" } ], "mode":"REPEATED", "name":"vertices", "type":"RECORD" } ], "name":"boundingPoly", "type":"RECORD" }, { "fields":[ { "fields":[ { "name":"latitude", "type":"FLOAT" }, { "name":"longitude", "type":"FLOAT" } ], "name":"latLon", "type":"RECORD" } ], "mode":"REPEATED", "name":"locations", "type":"RECORD" } ]Visualizza i dati di annotazione prodotti dall'API eseguendo i seguenti comandi
bq queryper visualizzare tutti i punti di riferimento trovati in queste sei immagini ordinati in base al punteggio più probabile:bq query --nouse_legacy_sql "SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score, locations FROM ${BIGQUERY_DATASET}.landmark_annotation ORDER BY score DESC"L'output è simile al seguente:
+------------------+-------------------+------------+---------------------------------+ | file_name | description | score | locations | +------------------+-------------------+------------+---------------------------------+ | eiffel_tower.jpg | Eiffel Tower | 0.7251996 | ["POINT(2.2944813 48.8583701)"] | | eiffel_tower.jpg | Trocadéro Gardens | 0.69601923 | ["POINT(2.2892823 48.8615963)"] | | eiffel_tower.jpg | Champ De Mars | 0.6800974 | ["POINT(2.2986304 48.8556475)"] | +------------------+-------------------+------------+---------------------------------+
Per descrizioni dettagliate di tutte le colonne specifiche per le annotazioni, consulta
AnnotateImageResponse.Per interrompere la pipeline di streaming, esegui il seguente comando. La pipeline continua a essere eseguita anche se non ci sono altre notifiche Pub/Sub da elaborare.
gcloud dataflow jobs cancel --region ${REGION} $(gcloud dataflow jobs list --region ${REGION} --filter="NAME:test-vision-analytics AND STATE:Running" --format="get(JOB_ID)")La sezione seguente contiene altre query di esempio che analizzano diverse caratteristiche delle immagini.
Analisi di un set di dati Flickr30K
In questa sezione, rileverai etichette e punti di riferimento nel pubblico set di dati di immagini Flickr30k ospitato su Kaggle.
In Cloud Shell, modifica i parametri della pipeline Dataflow in modo che sia ottimizzata per un set di dati di grandi dimensioni. Per consentire un throughput più elevato, aumenta anche i valori
batchSizeekeyRange. Dataflow scala il numero di worker in base alle esigenze:./gradlew run --args=" \ --runner=DataflowRunner \ --jobName=vision-analytics-flickr \ --streaming \ --enableStreamingEngine \ --diskSizeGb=30 \ --autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=5 \ --project=${PROJECT} \ --region=${REGION} \ --subscriberId=projects/${PROJECT}/subscriptions/${GCS_NOTIFICATION_SUBSCRIPTION} \ --visionApiProjectId=${PROJECT} \ --features=LABEL_DETECTION,LANDMARK_DETECTION \ --datasetName=${BIGQUERY_DATASET} \ --batchSize=16 \ --keyRange=5"Poiché il set di dati è di grandi dimensioni, non puoi utilizzare Cloud Shell per recuperare le immagini da Kaggle e inviarle al bucket Cloud Storage. Per farlo, devi utilizzare una VM con una dimensione del disco più grande.
Per recuperare le immagini basate su Kaggle e inviarle al bucket Cloud Storage, segui le istruzioni riportate nella sezione Simulare il caricamento delle immagini nel bucket di archiviazione nel repository GitHub.
Per osservare lo stato di avanzamento del processo di copia esaminando le metriche personalizzate disponibili nell'interfaccia utente di Dataflow, vai alla pagina Job Dataflow e seleziona la pipeline
vision-analytics-flickr. I contatori del cliente dovrebbero cambiare periodicamente finché la pipeline Dataflow non elabora tutti i file.L'output è simile allo screenshot seguente del riquadro Contatori personalizzati. Uno dei file nel set di dati è di tipo errato e il contatore
rejectedFileslo riflette. Questi valori del contatore sono approssimativi. Potresti vedere numeri più elevati. Inoltre, il numero di annotazioni molto probabilmente cambierà a causa dell'aumento dell'accuratezza dell'elaborazione da parte dell'API Vision.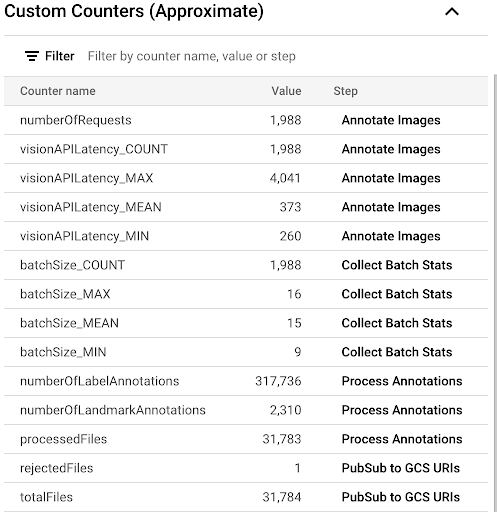
Per determinare se stai per raggiungere o superare le risorse disponibili, consulta la pagina della quota dell'API Vision.
Nel nostro esempio, la pipeline Dataflow ha utilizzato solo circa il 50% della sua quota. In base alla percentuale della quota utilizzata, puoi decidere di aumentare il parallelismo della pipeline aumentando il valore del parametro
keyRange.Arresta la pipeline:
gcloud dataflow jobs list --region $REGION --filter="NAME:vision-analytics-flickr AND STATE:Running" --format="get(JOB_ID)"
Analizza le annotazioni in BigQuery
In questo deployment, hai elaborato più di 30.000 immagini per l'etichettatura e l'annotazione di punti di riferimento. In questa sezione raccogli le statistiche relative a questi file. Puoi eseguire queste query nello spazio di lavoro GoogleSQL per BigQuery o utilizzare lo strumento a riga di comando bq.
Tieni presente che i numeri visualizzati possono variare dai risultati della query di esempio in questo deployment. L'API Vision migliora costantemente l'accuratezza della sua analisi. Può produrre risultati più completi analizzando la stessa immagine dopo aver inizialmente testato la soluzione.
Nella console Google Cloud, vai alla pagina Editor di query di BigQuery ed esegui il seguente comando per visualizzare i 20 etichette principali nel set di dati:
SELECT description, count(*)ascount \ FROM vision_analytics.label_annotation GROUP BY description ORDER BY count DESC LIMIT 20L'output è simile al seguente:
+------------------+-------+ | description | count | +------------------+-------+ | Leisure | 7663 | | Plant | 6858 | | Event | 6044 | | Sky | 6016 | | Tree | 5610 | | Fun | 5008 | | Grass | 4279 | | Recreation | 4176 | | Shorts | 3765 | | Happy | 3494 | | Wheel | 3372 | | Tire | 3371 | | Water | 3344 | | Vehicle | 3068 | | People in nature | 2962 | | Gesture | 2909 | | Sports equipment | 2861 | | Building | 2824 | | T-shirt | 2728 | | Wood | 2606 | +------------------+-------+
Determina quali altre etichette sono presenti in un'immagine con una determinata etichetta, classificate in base alla frequenza:
DECLARE label STRING DEFAULT 'Plucked string instruments'; WITH other_labels AS ( SELECT description, COUNT(*) count FROM vision_analytics.label_annotation WHERE gcs_uri IN ( SELECT gcs_uri FROM vision_analytics.label_annotation WHERE description = label ) AND description != label GROUP BY description) SELECT description, count, RANK() OVER (ORDER BY count DESC) rank FROM other_labels ORDER BY rank LIMIT 20;L'output è il seguente. Per l'etichetta Strumenti a corde pizzicate utilizzata nel comando precedente, dovresti vedere:
+------------------------------+-------+------+ | description | count | rank | +------------------------------+-------+------+ | String instrument | 397 | 1 | | Musical instrument | 236 | 2 | | Musician | 207 | 3 | | Guitar | 168 | 4 | | Guitar accessory | 135 | 5 | | String instrument accessory | 99 | 6 | | Music | 88 | 7 | | Musical instrument accessory | 72 | 8 | | Guitarist | 72 | 8 | | Microphone | 52 | 10 | | Folk instrument | 44 | 11 | | Violin family | 28 | 12 | | Hat | 23 | 13 | | Entertainment | 22 | 14 | | Band plays | 21 | 15 | | Jeans | 17 | 16 | | Plant | 16 | 17 | | Public address system | 16 | 17 | | Artist | 16 | 17 | | Leisure | 14 | 20 | +------------------------------+-------+------+
Visualizza i 10 punti di riferimento rilevati più importanti:
SELECT description, COUNT(description) AS count FROM vision_analytics.landmark_annotation GROUP BY description ORDER BY count DESC LIMIT 10L'output è il seguente:
+--------------------+-------+ | description | count | +--------------------+-------+ | Times Square | 55 | | Rockefeller Center | 21 | | St. Mark's Square | 16 | | Bryant Park | 13 | | Millennium Park | 13 | | Ponte Vecchio | 13 | | Tuileries Garden | 13 | | Central Park | 12 | | Starbucks | 12 | | National Mall | 11 | +--------------------+-------+
Determina le immagini che contengono molto probabilmente delle cascate:
SELECT SPLIT(gcs_uri, '/')[OFFSET(3)] file_name, description, score FROM vision_analytics.landmark_annotation WHERE LOWER(description) LIKE '%fall%' ORDER BY score DESC LIMIT 10L'output è il seguente:
+----------------+----------------------------+-----------+ | file_name | description | score | +----------------+----------------------------+-----------+ | 895502702.jpg | Waterfall Carispaccha | 0.6181358 | | 3639105305.jpg | Sahalie Falls Viewpoint | 0.44379658 | | 3672309620.jpg | Gullfoss Falls | 0.41680416 | | 2452686995.jpg | Wahclella Falls | 0.39005348 | | 2452686995.jpg | Wahclella Falls | 0.3792498 | | 3484649669.jpg | Kodiveri Waterfalls | 0.35024035 | | 539801139.jpg | Mallela Thirtham Waterfall | 0.29260656 | | 3639105305.jpg | Sahalie Falls | 0.2807213 | | 3050114829.jpg | Kawasan Falls | 0.27511594 | | 4707103760.jpg | Niagara Falls | 0.18691841 | +----------------+----------------------------+-----------+
Trova immagini di punti di riferimento a 3 chilometri dal Colosseo a Roma (la funzione
ST_GEOPOINTutilizza la longitudine e la latitudine del Colosseo):WITH landmarksWithDistances AS ( SELECT gcs_uri, description, location, ST_DISTANCE(location, ST_GEOGPOINT(12.492231, 41.890222)) distance_in_meters, FROM `vision_analytics.landmark_annotation` landmarks CROSS JOIN UNNEST(landmarks.locations) AS location ) SELECT SPLIT(gcs_uri,"/")[OFFSET(3)] file, description, ROUND(distance_in_meters) distance_in_meters, location, CONCAT("https://storage.cloud.google.com/", SUBSTR(gcs_uri, 6)) AS image_url FROM landmarksWithDistances WHERE distance_in_meters < 3000 ORDER BY distance_in_meters LIMIT 100Quando esegui la query, vedrai che ci sono più immagini del Colosseo, ma anche dell'Arco di Costantino, del Monte Palatino e di una serie di altri luoghi fotografati di frequente.
Puoi visualizzare i dati in BigQuery Geo Viz incollando la query precedente. Seleziona un punto sulla mappa per visualizzarne i dettagli. L'attributo
Image_urlcontiene un link al file immagine.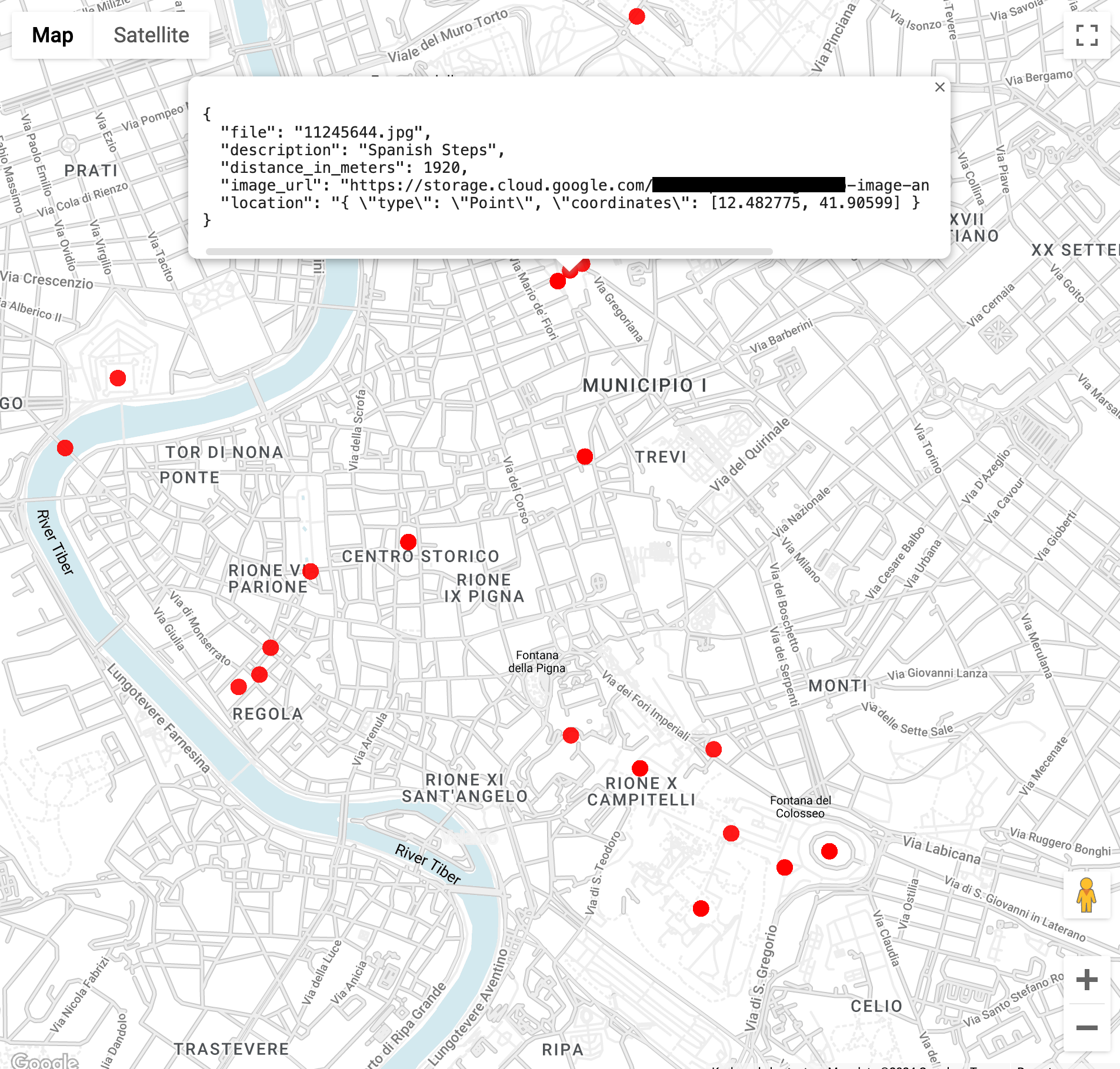
Una nota sui risultati delle query. In genere, le informazioni sulla posizione sono presenti per i punti di riferimento. La stessa immagine può contenere più posizioni dello stesso punto di riferimento.
Questa funzionalità è descritta nel tipo
AnnotateImageResponse.
Poiché una posizione può indicare la posizione della scena nell'immagine, possono essere presenti più elementi LocationInfo. Un'altra località può indicare dove è stata scattata l'immagine.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questa guida, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto Google Cloud
Il modo più semplice per eliminare la fatturazione è eliminare il progetto Google Cloud che hai creato per il tutorial.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Se decidi di eliminare le risorse singolarmente, segui i passaggi descritti nella sezione Pulizia del repository GitHub.
Passaggi successivi
- Per altre architetture di riferimento, diagrammi e best practice, visita il Cloud Architecture Center.
Collaboratori
Autori:
- Masud Hasan | Site Reliability Engineering Manager
- Sergei Lilichenko | Solutions Architect
- Lakshmanan Sethu | Technical Account Manager
Altri collaboratori:
- Jiyeon Kang | Customer Engineer
- Sunil Kumar Jang Bahadur | Customer Engineer