Questa guida fornisce istruzioni per l'utilizzo dei sistemi SAP HANA implementati su Google Cloud seguendo Terraform: Guida al deployment di scale-up di SAP HANA. Tieni presente che questa guida non è pensata per sostituire la documentazione SAP standard.
Amministrazione di un sistema SAP HANA su Google Cloud
Questa sezione mostra come eseguire le attività amministrative in genere richieste per gestire un sistema SAP HANA, incluse informazioni su come avviare, arrestare e clonare i sistemi.
Avvio e arresto di istanze
Puoi interrompere uno o più host SAP HANA in qualsiasi momento. L'interruzione di un'istanza ne provoca l'arresto. Se l'arresto non viene completato entro il periodo di arresto, l'istanza viene arrestata forzatamente. Per evitare la perdita di dati o la corruzione dei sistemi di file, ti consigliamo di eseguire una o entrambe le seguenti operazioni:
Arresta SAP HANA in esecuzione sull'istanza prima di arrestare l'istanza.
Per estendere il periodo di arresto di un'istanza, attiva l'arresto controllato nell'istanza.
Per scoprire come arrestare o riavviare un'istanza, consulta Arrestare o riavviare un'istanza Compute Engine.
Modifica di una VM
Puoi modificare vari attributi di una VM, incluso il tipo di VM, dopo il deployment della VM. Alcune modifiche potrebbero richiedere il ripristino del sistema SAP dai backup, mentre altre richiedono solo il riavvio della VM.
Per ulteriori informazioni, consulta Modifica delle configurazioni delle VM per i sistemi SAP.
Creazione di uno snapshot di SAP HANA
Per generare un backup in un determinato momento del disco permanente, puoi creare uno snapshot. Compute Engine memorizza in modo ridondante più copie di ogni snapshot in più posizioni con checksum automatici per garantire l' integrità dei dati.
Per creare uno snapshot, segui le istruzioni di Compute Engine per la creazione di snapshot. Presta particolare attenzione ai passaggi di preparazione prima di creare uno snapshot coerente, ad esempio lo svuotamento dei buffer del disco sul disco, per assicurarti che lo snapshot sia coerente.
Gli snapshot sono utili per i seguenti casi d'uso:
| Caso d'uso | Dettagli |
|---|---|
| Fornire una soluzione di backup dei dati semplice, indipendente dal software e conveniente. | Esegui il backup di dati, log, backup e dischi condivisi con gli snapshot. Pianifica un backup giornaliero di questi dischi per i backup in un determinato momento dell'intero set di dati. Dopo il primo snapshot, solo le modifiche incrementali ai blocchi vengono memorizzate negli snapshot successivi. In questo modo puoi risparmiare sui costi. |
| Esegui la migrazione a un altro tipo di archiviazione. | Compute Engine offre diversi tipi di dischi permanenti, tra cui quelli basati su archiviazione standard (magnetica) e su archiviazione su unità a stato solido (dischi permanenti basati su SSD). Ognuno ha caratteristiche diverse in termini di costi e prestazioni. Ad esempio, utilizza un tipo standard per il volume di backup e un tipo basato su SSD per i volumi /hana/log e /hana/data, poiché richiedono prestazioni più elevate. Per eseguire la migrazione tra tipi di archiviazione, utilizza lo snapshot del volume, poi crea un nuovo volume utilizzando lo snapshot e seleziona un tipo di archiviazione diverso. |
| Esegui la migrazione di SAP HANA in un'altra regione o zona. | Utilizza gli snapshot per spostare il sistema SAP HANA da una zona all'altra all'interno della stessa regione o anche in un'altra regione. Gli snapshot possono essere utilizzati a livello globale all'interno diGoogle Cloud per creare dischi in un'altra zona o regione. Per spostarti in un'altra regione o zona, crea uno snapshot dei dischi, incluso il disco principale, quindi crea le macchine virtuali nella zona o nella regione che preferisci con i dischi creati da questi snapshot. |
Modificare le impostazioni del disco
Puoi modificare le IOPS o il throughput di cui è stato eseguito il provisioning oppure aumentare le dimensioni dei volumi Hyperdisk una volta ogni 4 ore.
Se provi a modificare di nuovo il disco prima della scadenza delle 4 ore, riceverai un messaggio di errore relativo alla limitazione della frequenza comeCannot update provisioned throughput due to being rate limited.
Per risolvere questi errori, attendi 4 ore dall'ultima modifica prima di tentare di modificare di nuovo il disco.
Utilizza questa procedura solo in caso di emergenza, quando non puoi attendere 4 ore per regolare le dimensioni del disco, le IOPS provisionate o il throughput dei volumi Hyperdisk.
Per modificare le impostazioni del disco, svolgi i seguenti passaggi:
Interrompi l'istanza SAP HANA eseguendo uno dei seguenti comandi:
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
Sostituisci
INSTANCE_NUMBERcon il numero di istanza per il tuo sistema SAP HANA.Per ulteriori informazioni, consulta Avvio e arresto dei sistemi SAP HANA.
Crea uno snapshot o un'immagine del disco esistente:
Backup basato su snapshot
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONSostituisci quanto segue:
SNAPSHOT_NAME: il nome dello snapshot da creare.PROJECT_NAME: il nome del tuo Google Cloud progetto.SOURCE_DISK_NAME: il disco di origine utilizzato per creare lo snapshot.ZONE: la zona del disco di origine su cui operare.LOCATION: posizione di Cloud Storage, regionale o multiregionale, in cui devono essere archiviati i contenuti degli snapshot.Per saperne di più, consulta Creare e gestire gli snapshot dei dischi.
Backup basato su immagini
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONSostituisci quanto segue:
IMAGE_NAME: il nome dell'immagine del disco che vuoi creare.PROJECT_NAME: il nome del tuo Google Cloud progetto.SOURCE_DISK_NAME: il disco di origine utilizzato per creare l'immagine.ZONE: la zona del disco di origine su cui operare.LOCATION: posizione di Cloud Storage, regionale o multiregionale, in cui devono essere archiviati i contenuti delle immagini.Per saperne di più, vedi Creare immagini personalizzate.
Crea un nuovo disco dallo snapshot o dall'immagine.
Per i volumi Hyperdisk, assicurati di specificare le dimensioni del disco, le IOPS e la velocità in modo da soddisfare i requisiti del tuo carico di lavoro. Per saperne di più sul provisioning di IOPS e sul throughput per Hyperdisk, consulta Informazioni sulle prestazioni di cui è stato eseguito il provisioning per Hyperdisk.
Da uno snapshot
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTSostituisci quanto segue:
NEW_DISK_NAME: il nome del disco che vuoi creare.PROJECT_NAME: il nome del tuo Google Cloud progetto.DISK_TYPE: il tipo di disco da creare.DISK_SIZE: dimensione del disco.ZONE: la zona dei dischi da creare.SOURCE_SNAPSHOT: snapshot di origine utilizzato per creare i dischi.IOPS: IOPS sottoposte a provisioning del disco da creare.THROUGHPUT: la velocità effettiva del disco da creare.
Da un'immagine
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTSostituisci quanto segue:
NEW_DISK_NAME: il nome del disco che vuoi creare.PROJECT_NAME: il nome del tuo Google Cloud progetto.DISK_TYPE: il tipo di disco da creare.DISK_SIZE: dimensione del disco.ZONE: la zona dei dischi da creare.SOURE_IMAGE_NAME: l'immagine di origine da applicare ai dischi in fase di creazione.IMAGE_PROJECT_NAME: il Google Cloud progetto in base al quale verranno risolti tutti i riferimenti alle immagini e alle famiglie di immagini.IOPS: IOPS sottoposte a provisioning del disco da creare.THROUGHPUT: la velocità effettiva del disco da creare.
Per ulteriori informazioni, vedi
gcloud compute disks create.Scollega il disco esistente dal sistema SAP HANA:
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMESostituisci quanto segue:
INSTANCE_NAME: il nome dell'istanza su cui operare.OLD_DISK_NAME: il disco da scollegare in base al nome della risorsa.ZONE: la zona dell'istanza su cui operare.PROJECT_NAME: il nome del tuo Google Cloud progetto.
Per ulteriori informazioni, vedi
gcloud compute instances detach-disk.Collega il nuovo disco al sistema SAP HANA:
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMESostituisci quanto segue:
INSTANCE_NAME: il nome dell'istanza su cui operare.NEW_DISK_NAME: il nome del disco da collegare all'istanza.ZONE: la zona dell'istanza su cui operare.PROJECT_NAME: il nome del tuo Google Cloud progetto.
Per ulteriori informazioni, vedi
gcloud compute instances attach-disk.Verifica che i punti di montaggio siano collegati correttamente:
lsblkDovresti vedere un output simile al seguente:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/logAvvia l'istanza SAP HANA eseguendo uno dei seguenti comandi:
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
Sostituisci
INSTANCE_NUMBERcon il numero di istanza per il tuo sistema SAP HANA.Per ulteriori informazioni, consulta Avvio e arresto dei sistemi SAP HANA.
Convalida le dimensioni del disco, le IOPS e la velocità effettiva del nuovo volume Hyperdisk:
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAMESostituisci quanto segue:
DISK_NAME: il nome del disco da descrivere.ZONE: la zona del disco da descrivere.PROJECT_NAME: il nome del tuo Google Cloud progetto.
Per ulteriori informazioni, vedi
gcloud compute disks describe.
Clonazione del sistema SAP HANA
Puoi creare snapshot di un sistema SAP HANA esistente su Google Cloud per creare un clone esatto del sistema.
Per clonare un sistema SAP HANA a un solo host:
Crea uno snapshot dei dati e dei dischi di backup.
Crea nuovi dischi utilizzando gli snapshot.
Nella Google Cloud console, vai alla pagina Istanze VM.
Fai clic sull'istanza da clonare per aprire la pagina dei dettagli dell'istanza, quindi fai clic su Clona.
Collega i dischi creati dagli snapshot.
Per clonare un sistema SAP HANA multi-host:
Esegui il provisioning di un nuovo sistema SAP HANA con la stessa configurazione del sistema SAP HANA che vuoi clonare.
Esegui un backup dei dati del sistema originale.
Ripristina il backup del sistema originale nel nuovo sistema.
Installazione e aggiornamento dellgcloud CLI
Dopo aver eseguito il deployment di una VM per SAP HANA e aver installato il sistema operativo, è necessaria una versione aggiornata di Google Cloud CLI per vari scopi, ad esempio il trasferimento di file da e verso Cloud Storage, l'interazione con i servizi di rete e così via.
Se segui le istruzioni riportate nella guida al deployment di SAP HANA, l'gcloud CLI viene installata automaticamente.
Tuttavia, se importi il tuo sistema operativo in Google Cloud come immagine personalizzata o se utilizzi un'immagine pubblica precedente fornita daGoogle Cloud, potresti dover installare o aggiornare autonomamente la gcloud CLI.
Per verificare se gcloud CLI è installato e se sono disponibili aggiornamenti, apri un terminale o un prompt dei comandi e inserisci:
gcloud version
Se il comando non viene riconosciuto, significa che gcloud CLI non è installato.
Per installare gcloud CLI, segui le istruzioni riportate in Installazione di gcloud CLI.
Per sostituire la versione 140 o precedenti dell'interfaccia alla gcloud CLI integrata con SLES:
Accedi alla VM utilizzando
ssh.Passa all'utente super:
sudo suInserisci i seguenti comandi:
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
Attivazione del riavvio rapido di SAP HANA
Google Cloud Consiglia vivamente di attivare il riavvio rapido di SAP HANA per ogni istanza di SAP HANA, in particolare per le istanze più grandi. Il riavvio rapido di SAP HANA riduce il tempo di riavvio nel caso in cui SAP HANA si arresti, ma il sistema operativo rimanga in esecuzione.
Come configurato dagli script di automazione forniti,
le impostazioni del sistema operativo e del kernel supportano già il riavvio rapido di SAP HANA. Google Cloud
Devi definire il file system tmpfs e configurare SAP HANA.
Per definire il file system tmpfs e configurare SAP HANA, puoi seguire i passaggi manuali o utilizzare lo script di automazione fornito daGoogle Cloud per attivare il riavvio rapido di SAP HANA. Per ulteriori informazioni, consulta:
- Passaggi manuali: attivare il riavvio rapido di SAP HANA
- Passaggi automatici: attiva Fast Restart di SAP HANA
Per istruzioni autorevoli complete su SAP HANA Fast Restart, consulta la documentazione dell'opzione SAP HANA Fast Restart.
Procedura manuale
Configura il file system tmpfs
Dopo aver eseguito il deployment delle VM host e dei sistemi SAP HANA di base,
devi creare e montare le directory per i nodi NUMA nel file system tmpfs.
Mostra la topologia NUMA della VM
Prima di poter mappare il file system tmpfs richiesto, devi sapere quanti nodi NUMA sono presenti nella tua VM. Per visualizzare i nodi NUMA disponibili su una VM Compute Engine, inserisci il seguente comando:
lscpu | grep NUMA
Ad esempio, un tipo di VM m2-ultramem-208 ha quattro nodi NUMA,
numerati da 0 a 3, come mostrato nell'esempio seguente:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
Crea le directory dei nodi NUMA
Crea una directory per ogni nodo NUMA nella VM e imposta le autorizzazioni.
Ad esempio, per quattro nodi NUMA numerati da 0 a 3:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDMonta le directory dei nodi NUMA su tmpfs
Monta le directory del file system tmpfs e specifica
una preferenza per il nodo NUMA per ciascuna con mpol=prefer:
SID specifica il SID con lettere maiuscole.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
Aggiorna /etc/fstab
Per assicurarti che i punti di montaggio siano disponibili dopo il riavvio del sistema operativo, aggiungi voci alla tabella del file system, /etc/fstab:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
(Facoltativo) Imposta limiti all'utilizzo della memoria
Il file system tmpfs può aumentare e diminuire dinamicamente.
Per limitare la memoria utilizzata dal file system tmpfs, puoi impostare un limite di dimensioni per un volume del nodo NUMA con l'opzione size.
Ad esempio:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
Puoi anche limitare l'utilizzo complessivo della memoria tmpfs per tutti i nodi NUMA per
una determinata istanza SAP HANA e un determinato nodo del server impostando il
parametro persistent_memory_global_allocation_limit nella sezione [memorymanager]
del file global.ini.
Configurazione di SAP HANA per il riavvio rapido
Per configurare SAP HANA per il riavvio rapido, aggiorna il file global.ini
e specifica le tabelle da archiviare nella memoria persistente.
Aggiorna la sezione [persistence] nel file global.ini
Configura la sezione [persistence] nel file global.ini di SAP HANA
per fare riferimento alle località tmpfs. Separa ogni località tmpfs con un punto e virgola:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
L'esempio precedente specifica quattro volumi di memoria per quattro nodi NUMA,
che corrispondono a m2-ultramem-208. Se esegui la tua esecuzione su m2-ultramem-416, devi configurare otto volumi di memoria (0-7).
Riavvia SAP HANA dopo aver modificato il file global.ini.
Ora SAP HANA può utilizzare la posizione tmpfs come spazio di memoria permanente.
Specifica le tabelle da archiviare nella memoria persistente
Specifica tabelle o partizioni di colonne specifiche da archiviare nella memoria persistente.
Ad esempio, per attivare la memoria persistente per una tabella esistente, esegui la query SQL:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Per modificare il valore predefinito per le nuove tabelle, aggiungi il parametro
table_default nel file indexserver.ini. Ad esempio:
[persistent_memory] table_default = ON
Per ulteriori informazioni su come controllare le colonne, le tabelle e le visualizzazioni di monitoraggio che forniscono informazioni dettagliate, consulta Memoria persistente SAP HANA.
Passaggi automatici
Lo script di automazione fornito Google Cloud per attivare il riavvio rapido di SAP HANA apporta modifiche alle directory /hana/tmpfs*, al file /etc/fstab e alla configurazione di SAP HANA. Quando esegui lo script, potresti dover eseguire passaggi aggiuntivi a seconda che si tratti del deployment iniziale del sistema SAP HANA o se stai ridimensionando la macchina a una dimensione NUMA diversa.
Per il deployment iniziale del sistema SAP HANA o per il ridimensionamento della macchina al fine di aumentare il numero di nodi NUMA, assicurati che SAP HANA sia in esecuzione durante l'esecuzione dello script di automazione fornito per attivare il riavvio rapido di SAP HANA. Google Cloud
Quando redimensioni la macchina per ridurre il numero di nodi NUMA, assicurati che SAP HANA sia interrotta durante l'esecuzione dello script di automazione che consente di attivare il riavvio rapido di SAP HANA. Google Cloud Dopo l'esecuzione dello script, devi aggiornare manualmente la configurazione di SAP HANA per completare la configurazione del riavvio rapido di SAP HANA. Per ulteriori informazioni, consulta la configurazione di SAP HANA per il riavvio rapido.
Per attivare il riavvio rapido di SAP HANA, segui questi passaggi:
Stabilisci una connessione SSH con la VM host.
Passa al root:
sudo su -
Scarica lo script
sap_lib_hdbfr.sh:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Rendi eseguibile il file:
chmod +x sap_lib_hdbfr.sh
Verifica che lo script non contenga errori:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Se il comando restituisce un errore, contatta l'assistenza clienti Google Cloud. Per ulteriori informazioni su come contattare l'assistenza clienti, consulta Ricevere assistenza per SAP su Google Cloud.
Esegui lo script dopo aver sostituito l'ID sistema (SID) e la password di SAP HANA per l'utente SYSTEM del database SAP HANA. Per fornire la password in modo sicuro, ti consigliamo di utilizzare un secret in Secret Manager.
Esegui lo script utilizzando il nome di un secret in Secret Manager. Questo segreto deve esistere nel Google Cloud progetto che contiene l'istanza VM host.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Sostituisci quanto segue:
SID: specifica l'SID con lettere maiuscole. Ad esempio,AHA.SECRET_NAME: specifica il nome del segreto corrispondente alla password per l'utente SYSTEM del database SAP HANA. Questo segreto deve esistere nel Google Cloud progetto che contiene l'istanza VM host.
In alternativa, puoi eseguire lo script utilizzando una password in testo normale. Dopo aver attivato il riavvio rapido di SAP HANA, assicurati di cambiare la password. L'utilizzo di una password in testo normale non è consigliato perché la password verrà registrata nella cronologia della riga di comando della VM.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Sostituisci quanto segue:
SID: specifica l'SID con lettere maiuscole. Ad esempio,AHA.PASSWORD: specifica la password per l'utente SYSTEM del database SAP HANA.
Se l'esecuzione iniziale è andata a buon fine, dovresti visualizzare un output simile al seguente:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
Configurare il canale di assistenza SAP con SAProuter
Se devi consentire a un tecnico del servizio di assistenza SAP di accedere ai tuoi sistemi SAP HANA su Google Cloud, puoi farlo utilizzando SAProuter. Segui questi passaggi:
Avvia l'istanza VM Compute Engine su cui verrà installato il software SAProuter e assegna un indirizzo IP esterno in modo che l'istanza abbia accesso a internet.
Crea un nuovo indirizzo IP esterno statico e poi assegnalo all'istanza.
Crea e configura una regola firewall SAProuter specifica nella tua rete. In questa regola, consenti solo l'accesso in entrata e in uscita obbligatorio alla rete di assistenza SAP per l'istanza SAProuter.
Limita l'accesso in entrata e in uscita a un indirizzo IP specifico a cui SAP ti consente di connetterti, insieme alla porta TCP
3299. Aggiungi un tag target alla regola firewall e inserisci il nome dell'istanza. In questo modo, la regola del firewall viene applicata solo alla nuova istanza. Per ulteriori dettagli sulla creazione e sulla configurazione delle regole firewall, consulta la documentazione relativa alle regole firewall.Installa il software SAProuter, seguendo la nota SAP 1628296, e crea un file
saprouttabche consenta l'accesso da SAP ai tuoi sistemi SAP HANA su Google Cloud.Configura la connessione con SAP. Per la connessione a internet, utilizza la comunicazione di rete sicura. Per ulteriori informazioni, consulta SAP Remote Support – Help.
Configurare la rete
Esegui il provisioning del sistema SAP HANA utilizzando VM con la Google Cloud virtual network. Google Cloud utilizza tecnologie di networking software-defined e sistemi distribuiti all'avanguardia per ospitare e fornire i tuoi servizi in tutto il mondo.
Per SAP HANA, crea una rete di subnet non predefinita con intervalli di indirizzi IP CIDR non sovrapposti per ogni subnet della rete. Tieni presente che ogni subnet e i relativi intervalli di indirizzi IP interni sono mappati a una singola regione.
Una subnet abbraccia tutte le zone della regione in cui viene creata.
Tuttavia, quando crei un'istanza VM, devi specificare una zona e una sottorete per la VM. Ad esempio, puoi creare un insieme di istanze in subnetwork1 e in
zone1 di region1 e un altro insieme di istanze in subnetwork2 e in
zone2 di region1, a seconda delle tue esigenze.
Una nuova rete non ha regole firewall e, di conseguenza, non ha accesso alla rete. Devi creare regole firewall che aprono l'accesso alle tue istanze SAP HANA in base a un modello di privilegi minimi. Le regole firewall si applicano all'intera rete e possono essere configurate anche per essere applicate a istanze target specifiche utilizzando il meccanismo di tagging.
Le route sono risorse globali, non regionali, collegate a una singola rete. I route creati dall'utente si applicano a tutte le istanze di una rete. Ciò significa che puoi aggiungere un percorso che inoltra il traffico da un'istanza all'altra all'interno della stessa rete, anche tra subnet, senza necessità di indirizzi IP esterni.
Per l'istanza SAP HANA, avvia l'istanza senza indirizzo IP esterno e configura un'altra VM come gateway NAT per l'accesso esterno. Questa configurazione richiede di aggiungere il gateway NAT come route per la tua istanza SAP HANA. Questa procedura è descritta nella guida all'implementazione.
Sicurezza
Le sezioni seguenti illustrano le operazioni di sicurezza.
Modello di privilegio minimo
La prima linea di difesa è limitare chi può raggiungere l'istanza utilizzando firewall. Creando regole firewall, puoi limitare tutto il traffico a una rete o a macchine di destinazione su una determinata serie di porte a indirizzi IP di origine specifici. Devi seguire il modello con privilegi minimi per limitare l'accesso agli indirizzi IP, ai protocolli e alle porte specifici che richiedono l'accesso. Ad esempio, devi sempre configurare un bastion host e consentire l'accesso tramite SSH al sistema SAP HANA solo da quell'host.
Modifiche alla configurazione
Devi configurare il sistema SAP HANA e il sistema operativo con le impostazioni di sicurezza consigliate. Ad esempio, assicurati che siano elencate solo le porte di rete pertinenti per consentire l'accesso, rafforza il sistema operativo su cui esegui SAP HANA e così via.
Fai riferimento alle seguenti note SAP (è necessario un account utente SAP):
- 1944799: linee guida per l'installazione di SAP HANA su SLES
- 1730999: modifiche alla configurazione consigliata
- 1731000: modifiche alla configurazione non consigliate
Disattivazione di servizi SAP HANA non necessari
Se non hai bisogno di SAP HANA Extended Application Services (SAP HANA XS), disattiva il servizio. Fai riferimento alla nota SAP 1697613: Rimozione del servizio SAP HANA XS Classic Engine dalla topologia.
Dopo aver disattivato il servizio, rimuovi tutte le porte TCP aperte per il servizio. In Google Cloud, significa modificare le regole del firewall per la rete in modo da rimuovere queste porte dall'elenco di accesso.
Audit logging
Cloud Audit Logs è costituito da due stream di log, attività di amministrazione e accesso ai dati, entrambi generati automaticamente da Google Cloud. Questi possono aiutarti a rispondere alle domande "Chi ha fatto cosa, dove e quando?" nel tuo progettoGoogle Cloud .
I log delle attività di amministrazione contengono voci di log per le chiamate API o le azioni amministrative che modificano la configurazione o i metadati di un servizio o di un progetto. Questo log è sempre attivo ed è visibile a tutti i membri del progetto.
I log di accesso ai dati contengono voci di log per le chiamate API che creano, modificano o leggono i dati forniti dall'utente gestiti da un servizio, ad esempio i dati archiviati in un servizio database. Questo tipo di logging è abilitato per impostazione predefinita nel progetto ed è accessibile tramite Cloud Logging o tramite il feed delle attività.
Protezione di un bucket Cloud Storage
Se utilizzi Cloud Storage per ospitare i backup dei dati e dei log, assicurati di utilizzare TLS (HTTPS) durante l'invio dei dati a Cloud Storage dalle tue istanze per proteggere i dati in transito. Cloud Storage cripta automaticamente i dati a riposo. Puoi specificare le tue chiavi di crittografia se hai il tuo sistema di gestione delle chiavi.
Documenti sulla sicurezza correlati
Consulta le seguenti risorse di sicurezza aggiuntive per il tuo ambiente SAP HANA su Google Cloud:
- Centro sicurezza
- Conformità in Google Cloud
- White paper sulla sicurezza di Google Cloud
- Progettazione della sicurezza dell'infrastruttura Google
Alta disponibilità per SAP HANA su Google Cloud
Google Cloud offre una serie di opzioni per garantire l'alta disponibilità per il tuo sistema SAP HANA, tra cui le funzionalità di migrazione live e riavvio automatico di Compute Engine. Queste funzionalità, insieme all'elevata percentuale di uptime mensile delle VM Compute Engine, potrebbero rendere non necessario il pagamento e la manutenzione dei sistemi di standby.
Tuttavia, se necessario, puoi eseguire il deployment di un sistema scalabile orizzontalmente con più host che include gli host di riserva per il failover automatico dell'host SAP HANA oppure puoi eseguire il deployment di un sistema scalabile verticalmente con un'istanza SAP HANA di riserva in un cluster Linux ad alta disponibilità.
Per ulteriori informazioni sulle opzioni di alta disponibilità per SAP HANA su Google Cloud, consulta la guida alla pianificazione dell'alta disponibilità di SAP HANA.
Attivare il hook del provider SAP HANA HA/RE
SUSE consiglia di attivare i hook del provider SAP HANA HA/RE, che consentono a SAP HANA di inviare notifiche per determinati eventi e migliorano il rilevamento degli errori.
I hook del provider SAP HANA HA/RE necessitano di SAP HANA 2.0 SPS 03 o una versione successiva per l'hook SAPHanaSR e di SAP HANA 2.0 SPS 05 o una versione successiva per l'hook SAPHanaSR-angi.
Sia sul sito principale che su quello secondario, completa i seguenti passaggi:
Come utente root o
SID_LCadm, apri il fileglobal.iniper la modifica:>vi /hana/shared/SID/global/hdb/custom/config/global.iniAggiungi le seguenti definizioni al file
global.ini:Scale up
Per SLES for SAP 15 SP5 o versioni precedenti:
[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/ execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasr = info
Per SLES for SAP 15 SP6 o versioni successive:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
Scale out
Per SLES for SAP 15 SP5 o versioni precedenti:
[ha_dr_provider_saphanasrmultitarget] provider = SAPHanaSrMultiTarget path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 1 [ha_dr_provider_sustkover] provider = susTkOver path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 2 sustkover_timeout = 30 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasrmultitarget = info ha_dr_sustkover = info
Per SLES for SAP 15 SP6 o versioni successive:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
Come utente root, crea un file di configurazione personalizzato nella directory
/etc/sudoers.deseguendo il seguente comando. Questo nuovo file di configurazione consente all'utenteSID_LCadmdi accedere agli attributi del nodo del cluster quando viene chiamato il metodo di hooksrConnectionChanged().>visudo -f /etc/sudoers.d/SAPHanaSRNel file
/etc/sudoers.d/SAPHanaSR, aggiungi il seguente testo:Scale up
Per SLES for SAP 15 SP5 o versioni precedenti:
Sostituisci quanto segue:
SITE_A: il nome del sito del server SAP HANA principaleSITE_B: il nome del sito del server SAP HANA secondarioSID_LC: l'SID, specificato utilizzando lettere minuscole
crm_mon -A1 | grep sitecome utente root sul server SAP HANA principale o sul server secondario.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Per SLES for SAP 15 SP6 o versioni successive:
Sostituisci quanto segue:
SITE_A: il nome del sito del server SAP HANA principaleSITE_B: il nome del sito del server SAP HANA secondarioSID_LC: l'SID, specificato utilizzando lettere minuscole
crm_mon -A1 | grep sitecome utente root sul server principale SAP HANA o sul server secondario.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HOOK_HELPER = /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Scale out
Per SLES for SAP 15 SP5 o versioni precedenti:
Sostituisci
SID_LCcon l'ID cliente in lettere minuscole.SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_* SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_gsh * SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/SAPHanaSR-hookHelper --sid=SID_LC *
Per SLES for SAP 15 SP6 o versioni successive:
Sostituisci quanto segue:
SITE_A: il nome del sito del server SAP HANA principaleSITE_B: il nome del sito del server SAP HANA secondarioSID_LC: l'SID, specificato utilizzando lettere minuscole
crm_mon -A1 | grep sitecome utente root sul server SAP HANA principale o sul server secondario.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Nel file
/etc/sudoers, assicurati che sia incluso il seguente testo:Per SLES for SAP 15 SP3 o versioni successive:
@includedir /etc/sudoers.d
Per le versioni fino a SLES for SAP 15 SP2:
#includedir /etc/sudoers.d
Tieni presente che
#in questo testo fa parte della sintassi e non indica che la riga è un commento.
Impostare il pacemaker in modalità di manutenzione:
>crm configure property maintenance-mode=trueApplica le modifiche:
HANA SPS4 e versioni successive
Come SID_LCadm, carica le modifiche sui nodi SAP HANA master principali e secondari.
>hdbnsutil -reloadHADRProvidersUtilizza una delle seguenti opzioni per evitare o ridurre al minimo il tempo di riposo del tuo sito principale:
Opzione 1
Riavviare il sito secondario come SID_LCadm.
>HDB restartOpzione 2
Esegui un failover controllato dal principale al secondario
HANA SPS3
Come SID_LCadm, riavvia entrambi i sistemi SAP HANA principali e secondari:
>HDB restartPer annullare l'impostazione del pacemaker dalla modalità di manutenzione:
>crm configure property maintenance-mode=falseDopo aver completato la configurazione del cluster per SAP HANA, puoi verificare che l'hook funzioni correttamente durante un test di failover come descritto in Risoluzione dei problemi relativi all'hook Python SAPHanaSR e Il rilevamento del cluster HA richiede troppo tempo in caso di errore dell'index server HANA.
Ripristino di emergenza
Il sistema SAP HANA fornisce diverse funzionalità di alta disponibilità per garantire che il database SAP HANA possa resistere agli errori a livello di software o infrastruttura. Tra queste funzionalità sono incluse la replica del sistema SAP HANA e i backup di SAP HANA, entrambi supportati da Google Cloud .
Per ulteriori informazioni sui backup di SAP HANA, consulta Backup e recupero.
Per ulteriori informazioni sulla replica di sistema, consulta la Guida alla pianificazione del ripristino di emergenza di SAP HANA.
Backup e ripristino
I backup sono fondamentali per proteggere il tuo sistema di record (il tuo database). Poiché SAP HANA è un database in memoria, la creazione regolare di backup e l'implementazione di una strategia di backup adeguata ti aiutano a recuperare il database SAP HANA in situazioni come la corruzione o la perdita di dati a causa di un'interruzione o un guasto imprevisto nella tua infrastruttura. Il sistema SAP HANA fornisce funzionalità di backup e recupero integrate per aiutarti a farlo. Puoi utilizzare Google Cloud servizi come Cloud Storage come destinazione di backup per il backup di SAP HANA.
Puoi anche attivare la funzionalità Backint dell'Agente per SAP di Google Cloudin modo da poter utilizzare Cloud Storage direttamente per i backup e i ripristini.
Per informazioni sui consigli per il backup e il ripristino dei sistemi SAP HANA eseguiti su istanze bare metal di Compute Engine come X4, consulta Backup e ripristino per SAP HANA su istanze bare metal.
Questo documento presuppone che tu abbia familiarità con il backup e il ripristino di SAP HANA, nonché con le seguenti note del servizio SAP:
- 1642148: Domande frequenti: backup e ripristino del database SAP HANA
- 1821207: determinazione dei file di ripristino richiesti
- 1869119: verifica dei backup utilizzando
hdbbackupcheck - 1873247: verifica della recuperabilità con
hdbbackupdiag --check - 1651055: Pianificazione dei backup del database SAP HANA in Linux
Utilizzo dei volumi dei dischi permanenti di Compute Engine e di Cloud Storage per i backup
Se hai seguito le istruzioni di deployment basate su Terraform fornite da Google Cloud per eseguire il deployment del sistema SAP HANA, hai un'installazione SAP HANA con una directory /hanabackup ospitata su un volume di dischi rigidi permanenti bilanciati.
Per creare i backup del database online nella directory /hanabackup, utilizza gli strumenti SAP standard come SAP HANA Studio, SAP HANA Cockpit, la transazione SAP ABAP DB13 o gli statement SQL di SAP HANA. Infine, salva il backup completato caricandolo in un bucket Cloud Storage, da cui puoi scaricarlo quando devi recuperare il sistema SAP HANA.
Utilizzo di Compute Engine per creare backup e snapshot dei dischi
Puoi utilizzare Compute Engine per i backup di SAP HANA e hai anche la possibilità di eseguire il backup dell'intero disco che ospita i volumi di dati e log di SAP HANA utilizzando gli snapshot dei dischi standard.
Se hai seguito le istruzioni riportate nella
guida al deployment, hai un'installazione SAP HANA con una directory /hanabackup per i backup del database online. Puoi utilizzare la stessa directory per archiviare gli snapshot del volume /hanabackup
e mantenere un backup in un determinato momento dei volumi di dati e log SAP HANA.
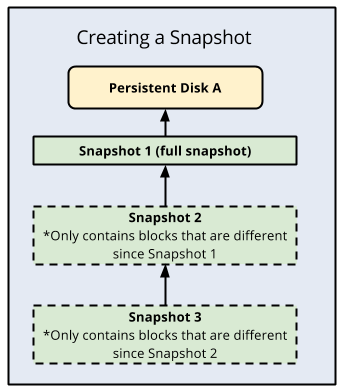
Un vantaggio degli snapshot dei dischi standard è che sono incrementali, in quanto ogni backup successivo memorizza solo le modifiche incrementali dei blocchi anziché creare un backup completamente nuovo. Compute Engine memorizza in modo ridondante più copie di ogni snapshot in più posizioni con checksum automatici per garantire l'integrità dei dati.
Di seguito è riportata un'illustrazione dei backup incrementali:
Cloud Storage come destinazione di backup
Cloud Storage è una buona scelta come destinazione di backup per SAP HANA perché offre elevata durabilità e disponibilità dei dati.
Cloud Storage è uno spazio di archiviazione di oggetti per file di qualsiasi tipo o formato. Ha uno spazio di archiviazione praticamente illimitato e non devi preoccuparti di eseguirne il provisioning o di aggiungere altra capacità. Un oggetto in Cloud Storage è costituito dai dati del file e dai relativi metadati associati e può avere dimensioni fino a 5 TB. Un bucket Cloud Storage può archiviare un numero qualsiasi di oggetti.
Con Cloud Storage, i dati vengono archiviati in più posizioni, il che garantisce elevata durabilità e disponibilità. Quando carichi i dati su Cloud Storage o li copi al suo interno, Cloud Storage segnala l'operazione come riuscita solo se viene raggiunta la ridondanza degli oggetti.
La tabella seguente mostra le opzioni di archiviazione offerte da Cloud Storage:
| Frequenza di lettura/scrittura dei dati | L'opzione Cloud Storage consigliata |
|---|---|
| Letture o scritture frequenti | Scegli la classe di archiviazione Standard per i database in uso, in quanto potrebbero accedere di frequente a Cloud Storage per scrivere e leggere i file di backup. |
| Letture o scritture rare | Scegli Nearline o Coldline per i dati a cui si accede di rado, ad esempio i backup archiviati che devono essere gestiti in base ai criteri di conservazione della tua organizzazione. Nearline è una buona scelta per i dati di cui hai eseguito il backup e a cui prevedi di accedere al massimo una volta al mese, mentre Coldline è più adatto per i dati a cui è molto bassa la probabilità di accedere, ad esempio una volta all'anno. |
| Dati archiviati | Scegli lo spazio di archiviazione per l'archivio dei dati a lungo termine. La classe Archive è una buona scelta per i dati di cui devi conservare una copia per un lungo periodo di tempo, ma a cui non intendi accedere più di una volta all'anno. Ad esempio, utilizza lo spazio di archiviazione Archiviazione per i backup che devi conservare per un lungo periodo per soddisfare i requisiti normativi. Valuta la possibilità di sostituire la soluzione di backup basata su nastro con Archive. |
Quando pianifichi l'utilizzo di queste opzioni di archiviazione, inizia con il livello di accesso frequente e fai invecchiare i dati di backup fino ai livelli di accesso infrequente. I backup vengono generalmente utilizzati raramente man mano che invecchiano. La probabilità di dover recuperare un backup di 3 anni fa è estremamente bassa e puoi spostarlo nel livello Archive per risparmiare sui costi. Per informazioni sui costi di Cloud Storage, consulta la pagina Prezzi di Cloud Storage.
Cloud Storage rispetto al backup su nastro
La destinazione di backup on-premise convenzionale è il nastro. Cloud Storage offre molti vantaggi rispetto alle unità a nastro, inclusa la possibilità di archiviare automaticamente i backup "offsite" dal sistema di origine, perché i dati in Cloud Storage vengono replicati in più strutture. Ciò significa anche che i backup archiviati in Cloud Storage sono altamente disponibili.
Un'altra differenza fondamentale è la velocità di ripristino dei backup quando devi utilizzarli. Se devi creare un nuovo sistema SAP HANA da un backup o ripristinare un sistema esistente da un backup, Cloud Storage ti consente di accedere più rapidamente ai tuoi dati, il che ti aiuta a creare il sistema più velocemente.
Funzionalità Backint dell'agente per SAP di Google Cloud
Puoi utilizzare Cloud Storage direttamente per i backup e i ripristini sia per le installazioni on-premise sia per quelle cloud utilizzando la funzionalità Backint certificata SAP dell'Agent for SAP di Google Cloud.
Per saperne di più su questa funzionalità, consulta Backup e recupero basati su Backint per SAP HANA.
Esegui il backup e recupera SAP HANA utilizzando Backint
Le sezioni seguenti forniscono informazioni su come eseguire il backup e il recupero di SAP HANA utilizzando la funzionalità Backint dell'agente per SAP di Google Cloud.
- Attivazione dei backup dei dati e delta
- Attivazione dei backup dei log
- Eseguire query sul catalogo dei backup
- Recupero di un database
Attivazione di backup dei dati e delta
Per attivare un backup del volume di dati SAP HANA e inviarlo a Cloud Storage utilizzando la funzionalità Backint dell'agente per SAP di Google Cloud, puoi utilizzare SAP HANA Studio, SAP HANA Cockpit, SAP HANA SQL o DBA Cockpit.
Di seguito sono riportate le istruzioni SQL di SAP HANA per attivare i backup dei dati:
Per creare un backup completo del database di sistema:
BACKUP DATA USING BACKINT ('BACKUP_NAME');Sostituisci
BACKUP_NAMEcon il nome che vuoi impostare per il backup.Per creare un backup completo per un database del tenant:
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Sostituisci
TENANT_SIDcon l'SID del database del tenant.Per creare backup differenziali e incrementali:
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Sostituisci
BACKUP_TYPEconDIFFERENTIALoINCREMENTAL, a seconda del tipo di backup che vuoi creare.
Esistono diverse opzioni che puoi utilizzare per attivare i backup dei dati. Per informazioni su queste opzioni, consulta la guida di riferimento SQL di SAP HANA BACKUP DATA Statement (Backup and Recovery).
Per ulteriori informazioni sui backup dei dati e delta, consulta i documenti SAP Data Backups e Delta Backups.
Attivazione dei backup dei log
Per attivare un backup del volume dei log di SAP HANA e inviarlo a Cloud Storage utilizzando la funzionalità Backint dell'agente per SAP di Google Cloud, completa i seguenti passaggi:
- Crea un backup completo del database. Per istruzioni, consulta la documentazione SAP per la tua versione di SAP HANA.
- Nel file
global.iniSAP HANA, imposta il parametrocatalog_backup_using_backintsuyes.
Assicurati che la modalità di log per il sistema SAP HANA sia normal, che è il valore predefinito. Se la modalità di log è impostata su overwrite, il database SAP HANA
disattiva la creazione di backup dei log.
Per ulteriori informazioni sui backup dei log, consulta il documento SAP Backup dei log.
Esecuzione di query sul catalogo dei backup
Il catalogo di backup di SAP HANA è una parte fondamentale delle operazioni di backup e recupero. Contiene informazioni sui backup creati per il database SAP HANA.
Per eseguire query sul catalogo dei backup per informazioni sui backup di un database del tenant, compila i seguenti passaggi:
- Metti offline il database del tenant.
Nel database di sistema, esegui il seguente istruzione SQL:
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
In alternativa, per eseguire una query su un punto in tempo specifico, esegui il seguente statement SQL:
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
L'istruzione crea il file
strategyOutput.xmlnella seguente directory:/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID.
Per informazioni sull'istruzione BACKUP LIST DATA, consulta la Guida di riferimento SQL di SAP HANA
BACKUP DATA (backup e ripristino).
Per informazioni sul catalogo di backup, consulta il documento
Catalogo di backup di SAP.
Recupero di un database
Quando esegui un recupero utilizzando un backup dei dati con più stream, SAP HANA utilizza lo stesso numero di canali utilizzati per la creazione del backup. Per ulteriori informazioni, consulta il documento SAP Prerequisiti: recupero mediante backup multistream.
Per ripristinare un backup del database SAP HANA creato utilizzando la funzionalità Backint dell'agente per SAP di Google Cloud, SAP HANA fornisce gli statement SQL RECOVER DATA e RECOVER DATABASE.
Entrambe le istruzioni SQL ripristinano i backup dal bucket Cloud Storage che hai specificato per il parametro bucket nel file PARAMETERS.json, a meno che tu non abbia specificato un bucket per il parametro recover_bucket.
Di seguito sono riportate istruzioni SQL di esempio per il recupero di un database SAP HANA utilizzando un backup creato utilizzando la funzionalità Backint dell'agente per SAP diGoogle Cloud:
Per recuperare un database del tenant specificando il nome del file di backup:
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;Per recuperare un database del tenant specificando l'ID backup:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
Sostituisci
BACKUP_IDcon l'ID del backup richiesto.Per recuperare un database del tenant specificando l'ID backup quando devi utilizzare il backup del catalogo di backup di SAP HANA, archiviato nel tuo bucket Cloud Storage:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
Per recuperare il database di un tenant in un momento specifico o in una posizione del log specifica:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
Per recuperare un database tenant utilizzando un backup da un database esterno:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
Sostituisci quanto segue:
SOURCE_TENANT_SID: l'SID del database del tenant di origineSOURCE_SID: l'SID del sistema SAP in cui esiste il database del tenant di origine
Se devi recuperare un database SAP HANA quando il catalogo di backup SAP HANA non è disponibile nel backup archiviato nel bucket Cloud Storage, segui le istruzioni riportate nella nota SAP 3227931 - Recover a HANA DB From Backint Without a HANA Backup Catalog.
Gestione dell'identità e dell'accesso ai backup
Quando utilizzi Cloud Storage o Compute Engine per eseguire il backup dei dati SAP HANA, l'accesso a questi backup è controllato da Identity and Access Management (IAM). Questa funzionalità consente agli amministratori di autorizzare gli utenti che possono intervenire su risorse specifiche. IAM ti offre controllo e visibilità centralizzati per la gestione di tutte le tue risorseGoogle Cloud , inclusi i backup.
IAM fornisce anche una cronologia di audit trail completa di autorizzazioni, rimozioni e deleghe viene visualizzata automaticamente per gli amministratori. In questo modo puoi configurare criteri che monitorano l'accesso ai tuoi dati nei backup, consentendoti di completare l'intero ciclo di controllo dell'accesso con i tuoi dati. IAM offre una visualizzazione unificata dei criteri di sicurezza in tutta l'organizzazione, con audit integrato per semplificare i processi di conformità.
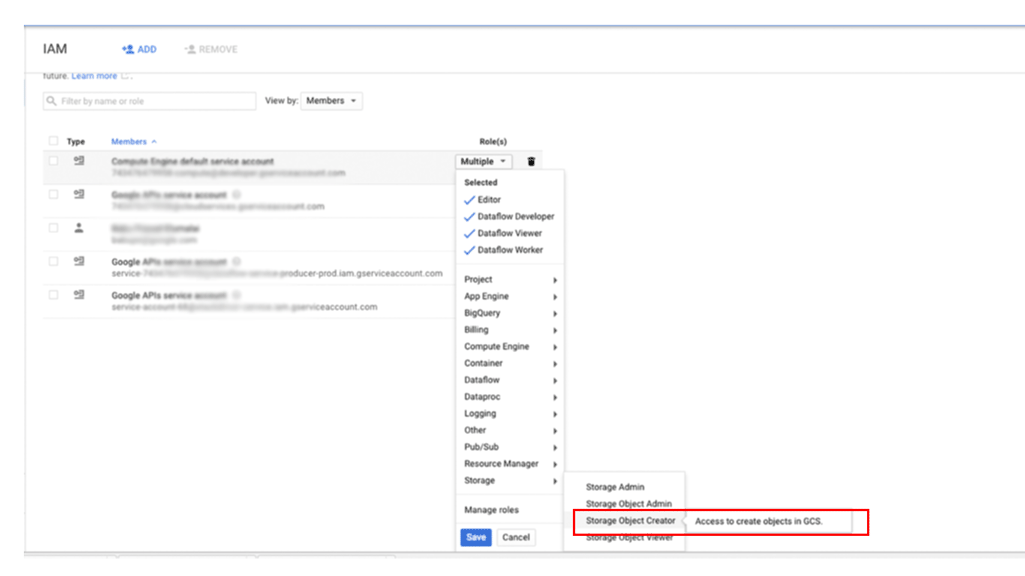
Per concedere a un principale l'accesso ai tuoi backup in Cloud Storage:
Nella Google Cloud console, vai alla pagina IAM e amministrazione:
Specifica l'utente a cui vuoi concedere l'accesso e poi assegna il ruolo Storage > Storage Object Creator:
Come creare backup basati sul file system per SAP HANA
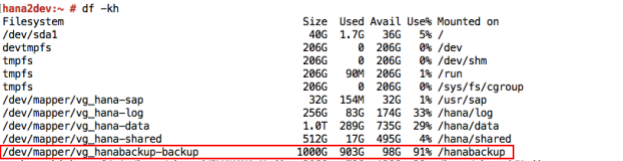
I sistemi SAP HANA di cui è stato eseguito il deployment su Google Cloud utilizzando la
guida al deployment sono
configurati con un insieme di volumi Persistent Disk o Hyperdisk
da utilizzare come destinazione di backup montata NFS. I backup di SAP HANA vengono inizialmente memorizzati su questi dischi locali, dopodiché devi copiarli in Cloud Storage per l'archiviazione a lungo termine. Puoi copiare manualmente i backup su Cloud Storage o pianificare la copia su Cloud Storage in un crontab.
Se utilizzi la funzionalità Backint dell'Agent for SAP di Google Cloud, esegui il backup e il ripristino direttamente in un bucket Cloud Storage, eliminando così la necessità di spazio di archiviazione su disco permanente per i backup.
Per avviare o pianificare i backup dei dati SAP HANA, puoi utilizzare SAP HANA Studio, i comandi SQL o DBA Cockpit. I backup dei log vengono scritti automaticamente, a meno che non vengano disabilitati. Lo screenshot seguente mostra un esempio:
Configurazione di SAP HANA global.ini
Se hai seguito le istruzioni della
guida all'implementazione, il file di configurazione SAP HANA global.ini è personalizzato con
i backup del database archiviati in /hanabackup/data/ e i file di archiviazione automatica dei log sono
memorizzati in /hanabackup/log/. Di seguito è riportato un esempio di come appare global.ini:
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
Per personalizzare il file di configurazione global.ini per la funzionalità Backint dell'agente per SAP diGoogle Cloud, consulta Configurare SAP HANA per la funzionalità Backint.
Note per le implementazioni di scale out
In un'implementazione di scalabilità, una
soluzione ad alta disponibilità che utilizza migrazione live e il riavvio automatico
funziona nello stesso modo di una configurazione a un solo host. La differenza principale è che il volume /hana/shared è montato NFS su tutti gli host worker e masterizzato nel master HANA. Si verifica un breve periodo di inaccessibilità sul volume NFS in caso di migrazione live o riavvio automatico di un host master. Quando l'host principale viene riavviato, il volume NFS inizia nuovamente a funzionare su tutti gli host e le normali operazioni riprendono automaticamente.
Il volume di backup SAP HANA, /hanabackup, deve essere disponibile su tutti gli host durante le operazioni di backup
e recupero. In caso di errore, devi verificare che /hanabackup sia montato su tutti gli host e rimontare quelli non montati. Quando
scegli di copiare il set di backup su un altro volume o Cloud Storage,
esegui la copia sull'host principale per ottenere prestazioni I/O migliori e
ridurre l'utilizzo della rete. Per semplificare la procedura di backup e ripristino, puoi utilizzare Cloud Storage FUSE per montare il bucket Cloud Storage su ogni host.
Il rendimento dello scaling out è buono solo se la distribuzione dei dati è ottimale. Migliore è la distribuzione dei dati, migliori sono le prestazioni delle query. Per questo, è necessario conoscere bene i dati, comprendere come vengono consumati e progettare la distribuzione e la partizione delle tabelle di conseguenza. Per ulteriori informazioni, consulta la nota SAP 2081591 - Domande frequenti: distribuzione delle tabelle SAP HANA.
Gcloud Python
Gcloud Python è un client Python idiomatico che puoi utilizzare per accedere ai serviziGoogle Cloud . Questa guida utilizza Gcloud Python per eseguire operazioni di backup e ripristino da e verso Cloud Storage per i backup del database SAP HANA.
Se hai seguito le istruzioni della guida al deployment, le librerie Python di Gcloud sono già disponibili nelle istanze Compute Engine.
Le librerie sono open source e consentono di eseguire operazioni sul bucket Cloud Storage per archiviare e recuperare i dati di backup.
Puoi eseguire il seguente comando per elencare gli oggetti nel bucket Cloud Storage. Puoi utilizzarlo per elencare i backup disponibili:
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
Per informazioni dettagliate su Gcloud Python, consulta la documentazione di riferimento della libreria client di archiviazione.
Esempio di backup e ripristino
Le sezioni seguenti illustrano la procedura che potresti seguire per le attività di backup e ripristino di tipo comune utilizzando SAP HANA Studio.
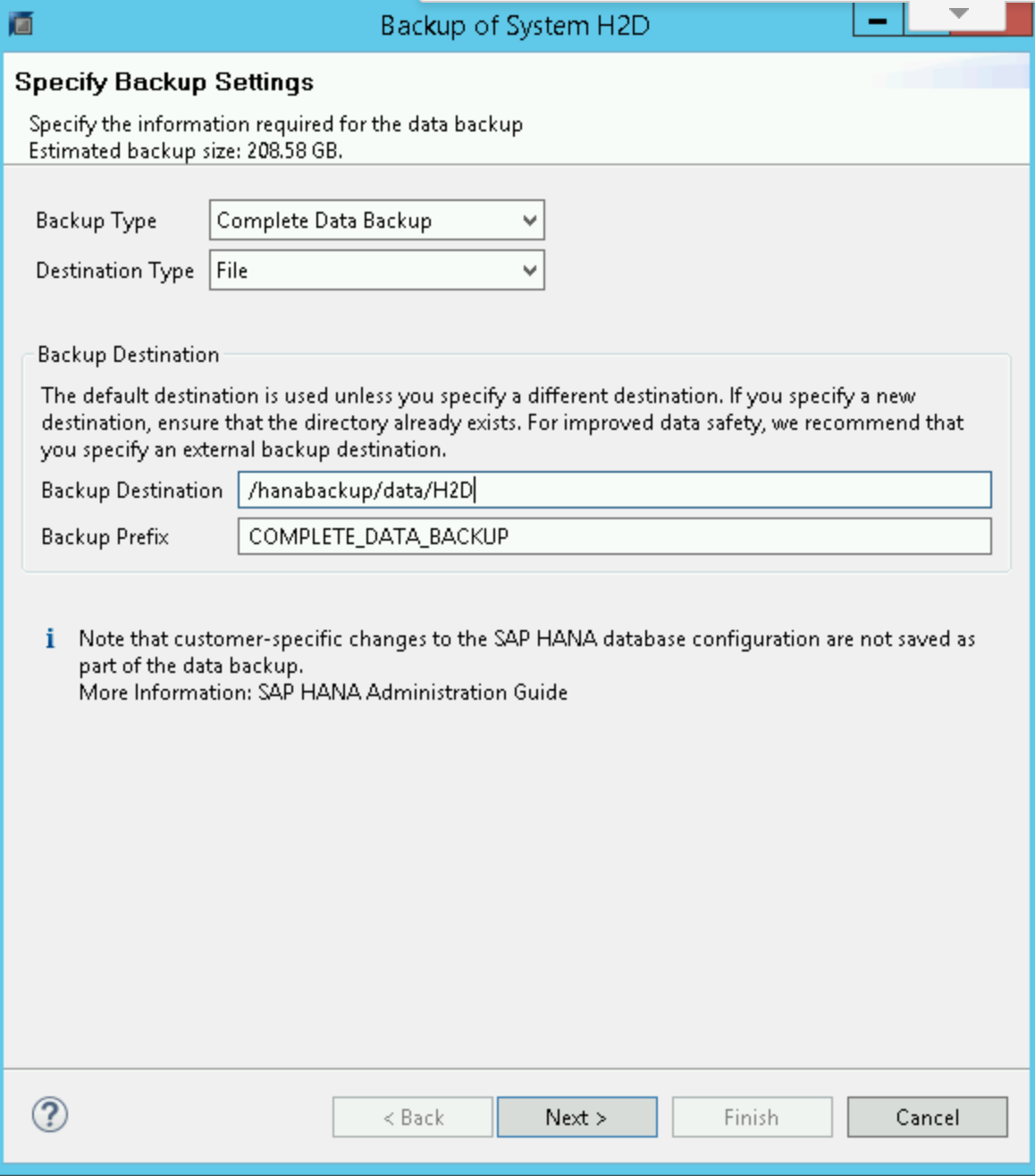
Esempio di creazione di backup
In SAP HANA Backup Editor, seleziona Apri la procedura guidata di backup.
- Seleziona File come tipo di destinazione. Il backup del database viene eseguito nei file del file system specificato.
- Specifica la destinazione del backup,
/hanabackup/data/SID, e il prefisso del backup. SostituisciSIDcon l'ID sistema del tuo sistema SAP. - Fai clic su Avanti.
Fai clic su Fine nel modulo di conferma per avviare il backup.
Quando il backup inizia, una finestra di stato mostra l'avanzamento del backup. Attendi il completamento del backup.
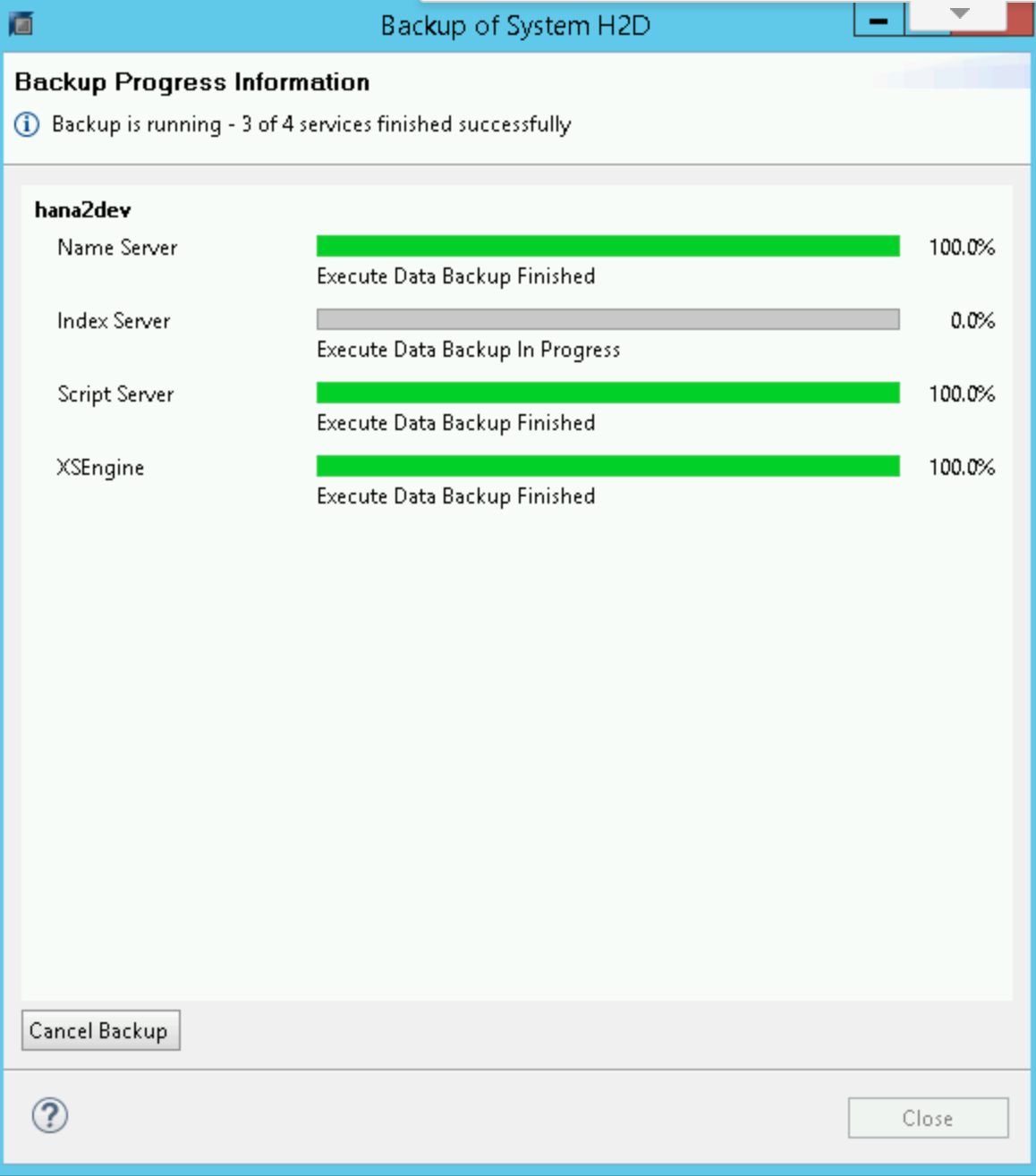
Al termine del backup, nel riepilogo del backup viene visualizzato un messaggio
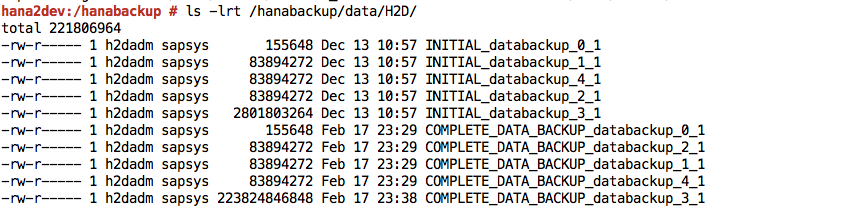
Finished.Accedi al sistema SAP HANA e verifica che i backup siano disponibili nelle posizioni previste nel file system. Ad esempio:

Esegui il push o la sincronizzazione dei file di backup dal file system
/hanabackupa Cloud Storage. Il seguente script Python di esempio spinge i dati da/hanabackup/datae/hanabackup/logal bucket utilizzato per i backup, sotto forma diNODE_NAME/DATAoLOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME. In questo modo puoi identificare i file di backup in base al momento in cui è stato eseguito il backup. Esegui questo scriptgcloud Pythonsul prompt bash del sistema operativo:python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOFUtilizza le librerie Python di Gcloud o la Google Cloud console per elencare i dati di backup.
Esempio di ripristino del backup
Se i file di backup non sono disponibili nella directory
/hanabackup, ma sono disponibili in Cloud Storage, scaricali da Cloud Storage eseguendo il seguente script dal prompt bash del sistema operativo:python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOFPer recuperare il database SAP HANA, fai clic su Backup e ripristino > Ripristina sistema:
Fai clic su Avanti.
Specifica la posizione dei backup nel file system locale e fai clic su Aggiungi.
Fai clic su Avanti.
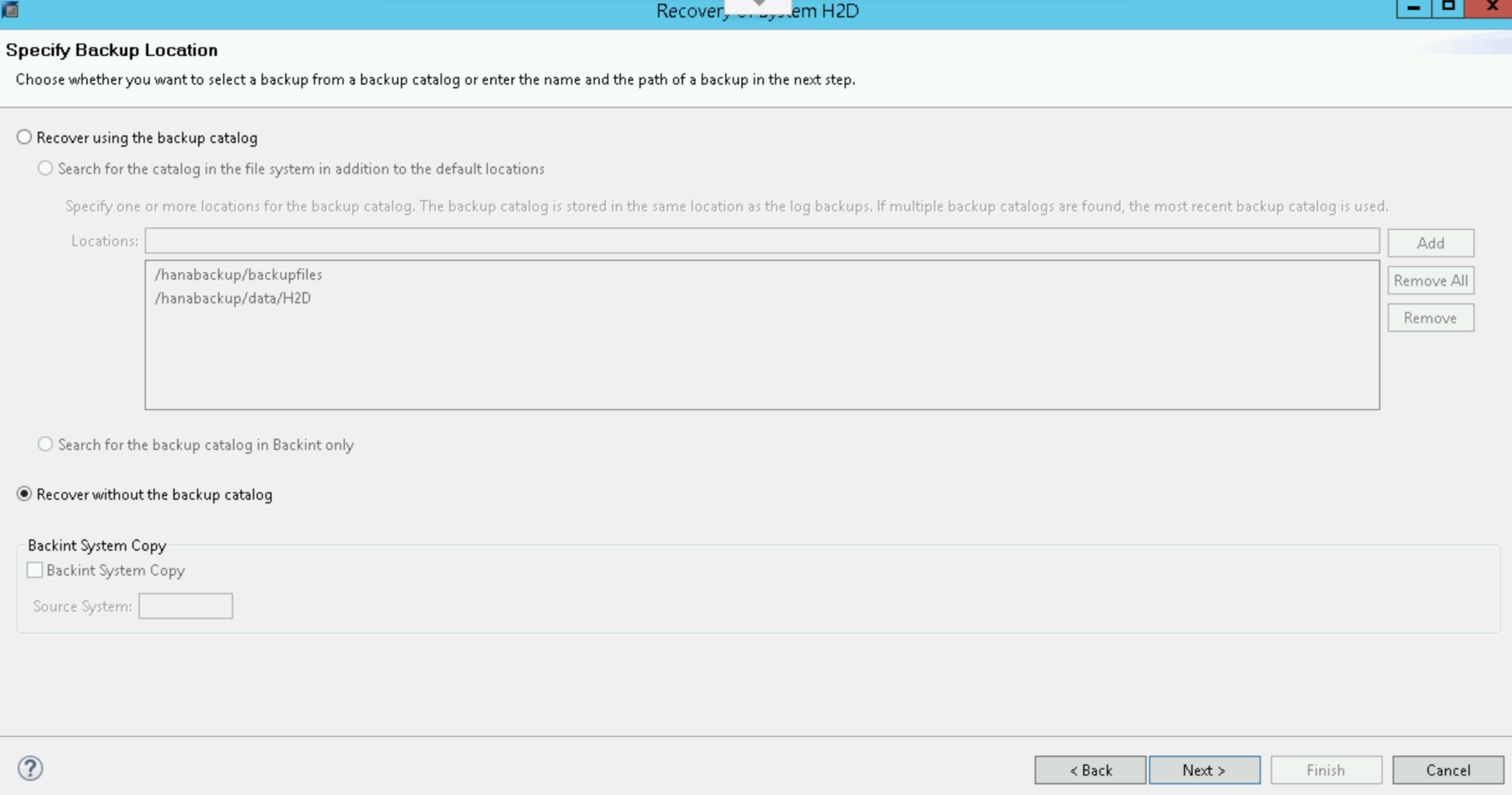
Seleziona Recupero senza il catalogo di backup:
Fai clic su Avanti.
Seleziona File come tipo di destinazione, quindi specifica la posizione dei file di backup e il prefisso corretto per il backup. Se hai seguito la procedura di creazione di un backup di esempio, ricorda che
COMPLETE_DATA_BACKUPè stato impostato come prefisso.Fai clic su Avanti due volte.
Fai clic su Fine per avviare il ripristino.
Al termine del recupero, riprendi le normali operazioni e rimuovi i file di backup dalle directory
/hanabackup/data/SID/*.
Passaggi successivi
Potrebbero esserti utili i seguenti documenti SAP standard:
Potrebbero esserti utili anche i seguenti Google Cloud documenti:
- Funzionalità cloud gratuite e offerta di prova
- Guida introduttiva a Google Cloud
- Compute Engine
- Persistent Disk