Neste guia, fornecemos instruções para operar sistemas SAP HANA implantados no Google Cloud seguindo o Terraform: guia de implantação do escalonamento vertical do SAP HANA. Este guia não se destina a substituir a documentação padrão da SAP.
Como administrar um sistema SAP HANA no Google Cloud
Esta seção mostra como executar tarefas administrativas normalmente necessárias para operar um sistema SAP HANA, incluindo informações sobre como iniciar, interromper e clonar sistemas.
Como iniciar e interromper instâncias
É possível interromper um ou vários hosts do SAP HANA a qualquer momento. Parar uma instância a encerra. Se o encerramento não for concluído dentro do período de encerramento, a instância será forçada a parar. Para evitar a perda de dados ou sistemas de arquivos corrompidos, recomendamos fazer uma ou ambas as seguintes ações:
Interrompa a execução do SAP HANA na instância antes de interromper a instância.
Para estender o período de desligamento de uma instância, ative o desligamento suave na instância.
Para saber como interromper ou reiniciar uma instância, consulte Interromper ou reiniciar uma instância do Compute Engine.
Como modificar uma VM
É possível alterar vários atributos de uma VM, incluindo o tipo de VM, depois que ela é implantada. Algumas mudanças podem exigir que você restaure backups do seu sistema SAP, enquanto outras exigem apenas a reinicialização da VM.
Para mais informações, consulte Como modificar configurações de VM para sistemas SAP.
Como criar um snapshot do SAP HANA
Para gerar um backup pontual do disco permanente, crie um snapshot. O Compute Engine armazena várias cópias de cada snapshot em vários locais com somas de verificação automáticas para garantir a integridade dos dados.
Para criar um snapshot, siga estas instruções do Compute Engine. Preste muita atenção às etapas de preparação antes de criar um snapshot consistente, como esvaziar os buffers de disco para o disco, para garantir que o snapshot seja consistente.
Os snapshot são úteis para os seguintes casos de uso:
| Caso de uso | Detalhes |
|---|---|
| Fornecer uma solução de backup de dados fácil, independente de software e econômica. | Fazer backup dos seus dados, registros, backup e discos compartilhados com snapshots. Programar um backup diário desses discos para backups pontuais de todo o conjunto de dados. Após o primeiro snapshot, apenas as alterações incrementais de bloco são armazenadas em snapshots subsequentes. Isso ajuda a economizar custos. |
| Migrar para um tipo de armazenamento diferente. | O Compute Engine oferece diferentes tipos de discos permanentes, incluindo tipos com armazenamento padrão (magnético) e tipos com armazenamento em unidade de estado sólido (discos permanentes baseados em SSD). Cada um tem
características de custo e desempenho diferentes. Por exemplo, use um
tipo padrão para o volume de backup e um tipo baseado em SSD para os volumes
/hana/log e /hana/data, porque eles exigem um desempenho melhor. Para migrar entre tipos de armazenamento, use o snapshot do volume, crie um novo volume usando o snapshot e selecione um tipo de armazenamento diferente. |
| Migrar o SAP HANA para outra região ou zona. | Usar snapshots para mover o sistema SAP HANA de uma zona para outra na mesma ou até para outra região. Os snapshots podem ser usados globalmente no Google Cloud para criar discos em outra zona ou região. Para mover para outra região ou zona, crie um snapshot dos discos, incluindo o disco raiz, e crie as máquinas virtuais na zona ou região desejada com discos criados a partir desses snapshots. |
Alterar as configurações do disco
É possível alterar as IOPS ou a capacidade de processamento provisionada ou aumentar o tamanho dos volumes Hyperdisk uma vez a cada 4 horas.
Se você tentar modificar o disco novamente antes de o prazo de quatro horas expirar, receberá uma mensagem de erro de limitação de taxa, como Cannot update provisioned throughput due to being rate limited.
Para resolver esses erros, aguarde quatro horas desde a última modificação antes de tentar modificar o disco novamente.
Use este procedimento somente em emergências quando não for possível esperar quatro horas para ajustar o tamanho do disco, as IOPS provisionadas ou a capacidade de processamento dos volumes Hyperdisk.
Para alterar as configurações do disco, siga estas etapas:
Interrompa sua instância do SAP HANA executando um dos seguintes comandos:
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
Substitua
INSTANCE_NUMBERpelo número da instância do sistema SAP HANA.Para mais informações, consulte Como iniciar e interromper sistemas SAP HANA.
Crie um snapshot ou uma imagem do disco atual:
Backup baseado em snapshots
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONSubstitua:
SNAPSHOT_NAME: nome do snapshot que você quer criar.PROJECT_NAME: o nome do projeto Google Cloud .SOURCE_DISK_NAME: o disco de origem usado para criar o snapshot.ZONE: zona do disco de origem na qual operar.LOCATION: local do Cloud Storage, regional ou multirregional, em que o conteúdo do snapshot será armazenado.Para mais informações, consulte Criar e gerenciar snapshots de discos.
Backup baseado em imagem
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONSubstitua:
IMAGE_NAME: nome da imagem do disco que você quer criar.PROJECT_NAME: o nome do projeto Google Cloud .SOURCE_DISK_NAME: o disco de origem usado para criar a imagem.ZONE: zona do disco de origem na qual operar.LOCATION: local do Cloud Storage, regional ou multirregional, em que o conteúdo da imagem será armazenado.Para mais informações, consulte Criar imagens personalizadas.
Crie um novo disco com base no snapshot ou na imagem.
Para volumes Hyperdisk, especifique o tamanho do disco, as IOPS e a capacidade de processamento para atender aos requisitos de carga de trabalho. Para mais informações sobre o provisionamento de IOPS e a capacidade de processamento do Hyperdisk, consulte Sobre o desempenho provisionado do Hyperdisk.
Com base em um snapshot
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTSubstitua:
NEW_DISK_NAME: nome do disco que você quer criar.PROJECT_NAME: o nome do projeto Google Cloud .DISK_TYPE: o tipo de disco a ser criado.DISK_SIZE: tamanho do disco.ZONE: zona dos discos a serem criados.SOURCE_SNAPSHOT: snapshot de origem usado para criar os discos.IOPS: IOPS provisionadas do disco a ser criado.THROUGHPUT: capacidade de processamento provisionada do disco a ser criado.
Com base em uma imagem
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTSubstitua:
NEW_DISK_NAME: nome do disco que você quer criar.PROJECT_NAME: o nome do projeto Google Cloud .DISK_TYPE: o tipo de disco a ser criado.DISK_SIZE: tamanho do disco.ZONE: zona dos discos a serem criados.SOURE_IMAGE_NAME: a imagem de origem a ser aplicada aos discos que estão sendo criados.IMAGE_PROJECT_NAME: o projeto Google Cloud em que todas as referências de imagem e família de imagens serão resolvidas.IOPS: IOPS provisionadas do disco a ser criado.THROUGHPUT: capacidade de processamento provisionada do disco a ser criado.
Para mais informações, consulte
gcloud compute disks create.Remova o disco atual do sistema SAP HANA:
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMESubstitua:
INSTANCE_NAME: nome da instância na qual operar.OLD_DISK_NAME: o disco a ser removido pelo nome do recurso.ZONE: zona da instância na qual operar.PROJECT_NAME: o nome do projeto Google Cloud .
Para ver mais informações, consulte
gcloud compute instances detach-disk.Anexe o novo disco ao sistema SAP HANA:
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMESubstitua:
INSTANCE_NAME: nome da instância na qual operar.NEW_DISK_NAME: o nome do disco a ser anexado à instância.ZONE: zona da instância na qual operar.PROJECT_NAME: o nome do projeto Google Cloud .
Para ver mais informações, consulte
gcloud compute instances attach-disk.Verifique se os pontos de montagem estão anexados corretamente:
lsblkA saída será semelhante a esta:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/logInicie sua instância do SAP HANA executando um dos seguintes comandos:
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
Substitua
INSTANCE_NUMBERpelo número da instância do sistema SAP HANA.Para mais informações, consulte Como iniciar e interromper sistemas SAP HANA.
Valide o tamanho do disco, as IOPS e a capacidade de processamento do novo volume Hyperdisk:
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAMESubstitua:
DISK_NAME: nome do disco a ser descrito.ZONE: a zona do disco a ser descrito.PROJECT_NAME: o nome do projeto Google Cloud .
Para ver mais informações, consulte
gcloud compute disks describe.
Como clonar seu sistema SAP HANA
É possível criar snapshots de um sistema SAP HANA atual no Google Cloud para criar um clone exato do sistema.
Para clonar um sistema SAP HANA de host único, siga estas etapas:
Crie um snapshot dos seus dados e discos de backup.
Crie novos discos usando os snapshots.
No Google Cloud console, acesse a página Instâncias de VM.
Clique na instância a ser clonada para abrir a página de detalhes da instância e clique em Clonar.
Anexe os discos que foram criados a partir dos snapshots.
Para clonar um sistema SAP HANA de vários hosts, siga estas etapas:
Provisione um novo sistema SAP HANA com a mesma configuração do sistema SAP HANA que você quer clonar.
Execute um backup de dados do sistema original.
Restaure o backup do sistema original para o novo sistema.
Como instalar e atualizar a gcloud CLI
Depois que uma VM é implantada no SAP HANA e o sistema operacional é instalado, uma Google Cloud CLI atualizada é necessária para várias finalidades, como a transferência de arquivos de e para o Cloud Storage, interação com serviços de rede e assim por diante.
Se você seguir as instruções no Guia de implantação do SAP HANA, a gcloud CLI será instalada automaticamente.
No entanto, se você levar seu próprio sistema operacional para o Google Cloud como uma imagem personalizada ou estiver usando uma imagem pública mais antiga fornecida pelo Google Cloud, talvez seja necessário instalar ou atualizar a CLI gcloud.
Para verificar se a CLI gcloud está instalada e se há atualizações disponíveis, abra um terminal ou prompt de comando e digite:
gcloud version
Se o comando não for reconhecido, a CLI gcloud não será instalada.
Para instalar a CLI gcloud, siga as instruções em Como instalar a CLI gcloud.
Para substituir a versão 140 ou mais antiga da CLI gcloud integrada ao SLES:
Faça login na VM usando
ssh.Mude para o superusuário:
sudo suDigite os seguintes comandos:
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
Como ativar a reinicialização rápida do SAP HANA
O Google Cloud recomenda fortemente ativar a reinicialização rápida do SAP HANA para cada instância do SAP HANA, especialmente para instâncias maiores.Google Cloud A reinicialização rápida do SAP HANA reduz os tempos de reinicialização caso o SAP HANA seja encerrado, mas o sistema operacional continua em execução.
Conforme definido pelos scripts de automação fornecidos pela Google Cloud ,
as configurações do sistema operacional e do kernel já são compatíveis com a reinicialização rápida do SAP HANA.
Você precisa definir o sistema de arquivos tmpfs e configurar o SAP HANA.
Para definir o sistema de arquivos tmpfs e configurar o SAP HANA, siga
as etapas manuais ou use o script de automação fornecido
porGoogle Cloud para ativar a reinicialização rápida do SAP HANA. Para mais informações, veja:
- Etapas manuais: ativar a reinicialização rápida do SAP HANA
- Etapas automatizadas: ativar a reinicialização rápida do SAP HANA
Para receber instruções completas sobre a reinicialização rápida do SAP HANA, consulte a documentação da opção de reinicialização rápida do SAP HANA.
Etapas manuais
Configurar o sistema de arquivos tmpfs
Depois que as VMs do host e os sistemas SAP HANA de base forem implantados, você precisará criar e ativar diretórios para os nós NUMA no sistema de arquivos tmpfs.
Exibir a topologia de NUMA da sua VM
Antes de mapear o sistema de arquivos tmpfs necessário, você precisa saber quantos
nós NUMA sua VM tem. Para exibir os nós NUMA disponíveis em uma
VM do Compute Engine, digite o seguinte comando:
lscpu | grep NUMA
Por exemplo, um tipo de VM m2-ultramem-208 tem quatro nós NUMA,
numerados de 0 a 3, conforme mostrado no exemplo a seguir:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
Criar os diretórios de nós NUMA
Crie um diretório para cada nó NUMA na sua VM e defina as permissões.
Por exemplo, para quatro nós NUMA numerados de 0 a 3:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDMontar os diretórios de nó NUMA em tmpfs
Monte os diretórios do sistema de arquivos tmpfs e especifique uma preferência de nó NUMA para cada um com mpol=prefer:
SID especifica o SID com letras maiúsculas.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
Atualizar /etc/fstab
Para garantir que os pontos de montagem estejam disponíveis após uma reinicialização do sistema operacional, adicione entradas à tabela do sistema de arquivos, /etc/fstab:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
Opcional: defina limites de uso de memória
O sistema de arquivos tmpfs pode aumentar e diminuir dinamicamente.
Para limitar a memória usada pelo sistema de arquivos tmpfs, defina um limite de tamanho para um volume de nó NUMA com a opção size.
Por exemplo:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
Também é possível limitar o uso geral da memória tmpfs para todos os nós NUMA de
uma determinada instância do SAP HANA e de um determinado nó do servidor definindo o
parâmetro persistent_memory_global_allocation_limit na seção [memorymanager]
do arquivo global.ini.
Configuração do SAP HANA para reinicialização rápida
Para configurar o SAP HANA para reinicialização rápida, atualize o arquivo global.ini e especifique as tabelas a serem armazenadas na memória permanente.
Atualize a seção [persistence] no arquivo global.ini
Configure a seção [persistence] no arquivo global.ini do SAP HANA para fazer referência aos locais tmpfs. Separe cada local tmpfs com
um ponto e vírgula:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
O exemplo anterior especifica quatro volumes de memória para quatro nós NUMA,
que correspondem a m2-ultramem-208. Se você estivesse executando no m2-ultramem-416, seria necessário configurar oito volumes de memória (0..7).
Reinicie o SAP HANA depois de modificar o arquivo global.ini.
O SAP HANA agora pode usar o local tmpfs como espaço de memória permanente.
Especificar as tabelas a serem armazenadas na memória permanente
Especifique tabelas ou partições específicas de coluna para armazenar na memória permanente.
Por exemplo, para ativar a memória permanente de uma tabela atual, execute a consulta SQL:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Para alterar o padrão de novas tabelas, adicione o parâmetro table_default no arquivo indexserver.ini. Por exemplo:
[persistent_memory] table_default = ON
Para mais informações sobre como controlar colunas, tabelas e quais visualizações de monitoramento fornecem informações detalhadas, consulte Memória permanente do SAP HANA.
Etapas automatizadas
O script de automação que Google Cloud fornece para ativar
a Reinicialização rápida do SAP HANA
faz mudanças nos diretórios /hana/tmpfs*, /etc/fstab e
na configuração do SAP HANA. Ao executar o script, talvez seja necessário executar
etapas adicionais, dependendo se essa é a implantação inicial do seu
sistema SAP HANA ou se você está redimensionando sua máquina para um tamanho de NUMA diferente.
Para a implantação inicial do seu sistema SAP HANA ou redimensionar a máquina para aumentar o número de nós NUMA, verifique se o SAP HANA está em execução durante a execução do script de automação que Google Cloud fornece para ativar a reinicialização rápida do SAP HANA.
Ao redimensionar a máquina para diminuir o número de nós NUMA, verifique se o SAP HANA é interrompido durante a execução do script de automação que Google Cloud fornece para ativar a reinicialização rápida do SAP HANA. Depois que o script for executado, você precisará atualizar manualmente a configuração do SAP HANA para concluir a configuração de reinício rápido do SAP HANA. Para mais informações, consulte Configuração do SAP HANA para reinicialização rápida.
Para ativar o reinício rápido do SAP HANA, siga estas etapas:
Estabeleça uma conexão SSH com sua VM do host.
Mudar para raiz:
sudo su -
Faça o download do script
sap_lib_hdbfr.sh:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Torne o arquivo executável:
chmod +x sap_lib_hdbfr.sh
Verifique se o script não tem erros:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Se o comando retornar um erro, entre em contato com o Cloud Customer Care. Para mais informações sobre como entrar em contato com o atendimento ao cliente, consulte Como receber suporte para a SAP no Google Cloud.
Execute o script depois de substituir o ID do sistema (SID) do SAP HANA e a senha do usuário SYSTEM do banco de dados do SAP HANA. Para fornecer a senha com segurança, recomendamos que você use uma chave secreta no Gerenciador de secrets.
Execute o script usando o nome de um secret no Secret Manager. Esse secret precisa existir no projeto Google Cloud que contém a instância de VM do host.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Substitua:
SID: especifique o SID com letras maiúsculas. Por exemplo,AHA.SECRET_NAME: especifique o nome do secret que corresponde à senha do usuário do SYSTEM do banco de dados do SAP HANA. Esse secret precisa existir no projeto Google Cloud que contém a instância de VM do host.
Outra opção é executar o script com uma senha de texto simples. Depois que a reinicialização rápida do SAP HANA estiver ativada, altere sua senha. Não é recomendável usar uma senha de texto simples, porque ela seria registrada no histórico de linha de comando da VM.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Substitua:
SID: especifique o SID com letras maiúsculas. Por exemplo,AHA.PASSWORD: especifique a senha do usuário do SYSTEM do banco de dados SAP HANA.
Para uma execução inicial bem-sucedida, você verá uma saída semelhante a esta:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
Como configurar seu canal de suporte SAP com o SAProuter
Se você precisar permitir que um engenheiro de suporte da SAP acesse seus sistemas SAP HANA no Google Cloud, faça isso usando o SAProuter. Siga estas etapas:
Inicie a instância de VM do Compute Engine em que o software SAProuter será instalado e atribua um endereço IP externo para que a instância tenha acesso à Internet.
Crie um novo endereço IP externo estático e atribua esse endereço IP à instância.
Crie e configure uma regra de firewall específica do SAProuter na sua rede. Nesta regra, permita apenas o acesso de entrada e saída necessário à rede de suporte da SAP, para a instância do SAProuter.
Limite o acesso de entrada e saída a um endereço IP específico que a SAP fornece para se conectar, além da porta TCP
3299. Adicione uma tag de destino à regra de firewall e insira o nome da instância. Isso garante que a regra de firewall se aplique apenas à nova instância. Consulte a documentação de regras de firewall para mais detalhes sobre como criar e configurar regras de firewall.Instale o software SAProuter seguindo a Nota SAP 1628296 e crie um arquivo
saprouttabque permita o acesso do SAP aos sistemas SAP HANA no Google Cloud.Configure a conexão com a SAP. Para sua conexão com a Internet, use a comunicação de rede segura. Para mais informações, consulte Suporte remoto do SAP - Ajuda.
Como configurar sua rede
Você está provisionando seu sistema SAP HANA usando VMs com a Google Cloud rede virtual. Google Cloud usa tecnologias de ponta, redes definidas por software e sistemas distribuídos para hospedar e fornecer seus serviços em todo o mundo.
Para o SAP HANA, crie uma rede de sub-rede não padrão com intervalos de endereços IP CIDR não sobrepostos para cada sub-rede na rede. Observe que cada sub-rede e os respectivos intervalos de endereços IP internos são mapeados para uma única região.
Uma sub-rede abrange todas as zonas na região em que é criada.
No entanto, ao criar uma instância de VM, você especifica uma zona e uma sub-rede para a VM. Por exemplo, é possível criar um conjunto de instâncias em subnetwork1 e em zone1 de region1 e outro conjunto de instâncias em subnetwork2 e em zone2 de region1, dependendo suas necessidades.
Uma nova rede não tem regras de firewall e, portanto, não tem acesso à rede. Crie regras de firewall que abram o acesso às instâncias do SAP HANA com base em um modelo de privilégio mínimo. As regras de firewall se aplicam a toda a rede e também podem ser configuradas para serem aplicadas a instâncias de destino específicas usando o mecanismo de inclusão de tag.
As rotas são recursos globais, não regionais, que estão anexados a uma única rede. As rotas criadas pelo usuário se aplicam a todas as instâncias de uma rede. Isso significa que é possível adicionar uma rota que encaminhe o tráfego de uma instância para outra dentro da mesma rede e até mesmo entre sub-redes, sem precisar de endereços IP externos.
Para sua instância do SAP HANA, inicie a instância sem endereço IP externo e configure outra VM como um gateway NAT para acesso externo. Essa configuração exige que você adicione o gateway NAT como uma rota para a instância do SAP HANA. Este procedimento é descrito no guia de implantação.
Segurança
As seções a seguir discutem as operações de segurança.
Modelo de privilégio mínimo
Sua primeira linha de defesa é restringir quem pode alcançar a instância usando firewalls. Ao criar regras de firewall, é possível restringir todo o tráfego a uma rede ou máquinas de destino em um determinado conjunto de portas para endereços IP de origem específicos. Siga o modelo de privilégio mínimo para restringir o acesso a portas, protocolos e endereços IP específicos que precisam de acesso. Por exemplo, você sempre deve configurar um Bastion Host e permitir o SSH no sistema SAP HANA somente desse host.
Alterações de configuração
Configure o sistema SAP HANA e o sistema operacional com as configurações de segurança recomendadas. Por exemplo, verifique se apenas as portas de rede relevantes estão listadas para permitir o acesso, proteja o sistema operacional em execução no SAP HANA e assim por diante.
Consulte as seguintes notas da SAP (é necessário ter uma conta de usuário SAP):
- 1944799: diretrizes para instalação do SLES no SAP HANA
- 1730999: alterações de configuração recomendadas
- 1731000: alterações de configuração não recomendadas
Como desativar serviços desnecessários do SAP HANA
Se você não precisar dos Serviços de aplicativos estendidos do SAP HANA (SAP HANA XS), desative o serviço. Consulte a nota SAP 1697613: como remover o serviço do SAP HANA XS clássico da topologia.
Depois que o serviço for desativado, remova todas as portas TCP que foram abertas para o serviço. No Google Cloud, isso significa editar as regras de firewall da rede para remover essas portas da lista de permissões.
Registro de auditoria
Os Registros de auditoria do Cloud consistem em dois streams de registro, atividade do administrador e acesso a dados, ambos gerados automaticamente pelo Google Cloud. Isso pode ajudar você a responder às perguntas "Quem fez o quê, onde e quando?" no seu projetoGoogle Cloud .
Os registros de “atividade do administrador” contêm entradas para chamadas de API ou ações administrativas que modificam a configuração ou os metadados de um serviço ou projeto. Esse registro fica sempre ativado e visível para todos os membros do projeto.
Os registros “Acesso a dados” contêm entradas de registro para chamadas de API que criam, modificam ou leem dados fornecidos pelo usuário gerenciados por um serviço, como os dados armazenados em um serviço de banco de dados. Esse tipo de geração de registros é ativado por padrão no projeto e pode ser acessado por meio do Cloud Logging ou do feed de atividades.
Como proteger um bucket do Cloud Storage
Se você usa o Cloud Storage para hospedar os backups dos dados e do registro, use o TLS (HTTPS) ao enviar dados das instâncias para o Cloud Storage para proteger os dados em trânsito. O Cloud Storage criptografa automaticamente os dados em repouso. É possível especificar suas próprias chaves de criptografia se tiver seu próprio sistema de gerenciamento de chaves.
Documentos de segurança relacionados
Consulte os seguintes recursos de segurança extras para seu ambiente SAP HANA no Google Cloud:
- Central de segurança
- Conformidade no Google Cloud
- Whitepaper sobre segurança do Google Cloud
- Design de segurança da infraestrutura do Google
Alta disponibilidade para SAP HANA no Google Cloud
OGoogle Cloud oferece várias opções para garantir alta disponibilidade para seu sistema SAP HANA, incluindo os recursos de migração em tempo real do Compute Engine e reinicialização automática. Esses recursos, além da alta porcentagem de tempo de atividade mensal das VMs do Compute Engine, podem tornar o pagamento e a manutenção de sistemas em espera desnecessários.
No entanto, se necessário, implante um sistema de escalonamento horizontal de vários hosts que inclua hosts em espera para failover automático de host do SAP HANA ou implante um sistema de escalonamento vertical com uma instância do SAP HANA em espera em um cluster Linux de alta disponibilidade.
Para mais informações sobre as opções de alta disponibilidade do SAP HANA no Google Cloud, consulte o Guia de planejamento de alta disponibilidade do SAP HANA.
Ativar o gancho de provedor HA/DR do SAP HANA
Recuperação de desastres
O sistema SAP HANA fornece vários recursos de alta disponibilidade para garantir que o banco de dados possa suportar falhas no nível do software ou da infraestrutura. Entre esses recursos está a replicação do sistema e os backups do SAP HANA, ambos compatíveis com o Google Cloud .
Para mais informações sobre backups do SAP HANA, consulte Backup e recuperação.
Para mais informações sobre a replicação do sistema, consulte o Guia de planejamento de recuperação de desastres do SAP HANA.
Backup e recuperação
Os backups são essenciais para proteger seu sistema de registro (seu banco de dados). Como o SAP HANA é um banco de dados na memória, criar backups regularmente e implementar uma estratégia de backup adequada ajudam a recuperar seu banco de dados do SAP HANA em situações como corrupção ou perda de dados devido a uma interrupção do serviço não planejada ou falha na infraestrutura. O sistema SAP HANA oferece recursos de backup e recuperação integrados para ajudar você a fazer isso. É possível usar Google Cloud serviços como o Cloud Storage para servir como o destino do backup do SAP HANA.
Também é possível ativar o recurso Backint do agente do Google Cloudpara SAP para usar o Cloud Storage diretamente para backups e recuperações.
Para informações sobre recomendações de backup e recuperação para sistemas SAP HANA executados em instâncias bare metal do Compute Engine, como X4, consulte Backup e recuperação para SAP HANA em instâncias bare metal.
Neste documento, presumimos que você esteja familiarizado com o backup e a recuperação do SAP HANA, além das seguintes notas do serviço SAP:
- 1642148: perguntas frequentes sobre backup e recuperação de banco de dados SAP HANA
- 1821207: determinação dos arquivos de recuperação necessários
- 1869119: verificação de backups usando
hdbbackupcheck - 1873247: verificação da capacidade de recuperação com
hdbbackupdiag --check - 1651055: como programar backups de banco de dados SAP HANA no Linux
Como usar volumes do Persistent Disk do Compute Engine e o Cloud Storage para backups
Se você seguiu as instruções de implantação
baseadas no Terraform fornecidas por Google Cloud para implantar o sistema SAP HANA,
você terá uma instalação do SAP HANA com um diretório /hanabackup hospedado em
um volume de disco permanente equilibrado.
Para criar backups de banco de dados on-line para o diretório /hanabackup, use as ferramentas padrão da SAP, como o SAP HANA Studio, o SAP HANA Cockpit, transação DB13 do SAP ABAP ou as instruções SQL do SAP HANA. Por fim, salve o backup completo fazendo upload dele para um bucket do Cloud Storage, do qual é possível fazer o download do backup quando precisar recuperar o sistema SAP HANA.
Como usar o Compute Engine para criar backups e snapshots de disco
É possível usar o Compute Engine para backups do SAP HANA, mas você também tem a opção de fazer backup de todo o disco que hospeda os volumes de registro e dados do SAP HANA usando snapshots de disco padrão.
Se você seguiu as instruções no guia de implantação, você terá uma instalação do SAP HANA com um diretório /hanabackup para seus backups de banco de dados on-line. É possível usar esse mesmo diretório para armazenar snapshots do volume /hanabackup e manter um backup pontual dos volumes de registro e dados do SAP HANA.
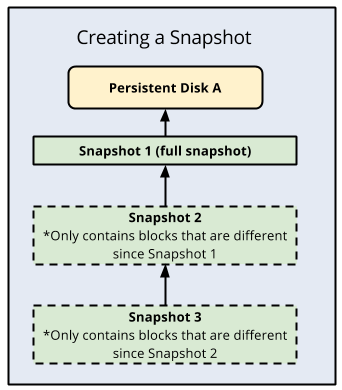
Uma vantagem dos snapshots de disco padrão é que eles são incrementais, em que cada backup subsequente armazena apenas alterações incrementais de blocos em vez de criar um backup totalmente novo. O Compute Engine armazena várias cópias de cada snapshot em vários locais com somas de verificação automáticas para garantir a integridade dos dados.
Esta é uma ilustração dos backups incrementais:
Cloud Storage como destino de backup
O Cloud Storage é uma boa opção para usar como destino de backup do SAP HANA, porque oferece alta durabilidade e disponibilidade de dados.
O Cloud Storage é um armazenamento de objetos para arquivos de qualquer tipo ou formato. Ele tem praticamente armazenamento ilimitado, e você não precisa se preocupar em provisioná-lo ou adicionar mais capacidade a ele. Um objeto no Cloud Storage consiste em dados de arquivos e metadados associados e pode ter até 5 TB. Um bucket do Cloud Storage pode armazenar qualquer número de objetos.
Com o Cloud Storage, seus dados são armazenados em vários locais, o que proporciona alta durabilidade e alta disponibilidade. Quando você copia ou faz o upload de seus dados no Cloud Storage, ele relata a ação como bem-sucedida somente se houver redundância de objetos.
A tabela a seguir mostra as opções de armazenamento oferecidas pelo Cloud Storage:
| Frequência de leitura/gravação de dados | A opção recomendada do Cloud Storage |
|---|---|
| Leituras ou gravações frequentes | Escolha a classe de armazenamento Standard para bancos de dados que estão em uso, porque eles podem acessar o Cloud Storage com frequência para gravar e ler arquivos de backup. |
| Leituras ou gravações não frequentes | Escolha o Nearline ou Coldline Storage para dados acessados com pouca frequência, como backups arquivados que precisam ser mantidos seguindo a política de retenção da sua organização. Nearline é uma boa opção para dados de backup que você planeja acessar no máximo uma vez por mês, enquanto Coldline é melhor para dados com probabilidade muito baixa de serem acessados, como uma vez por ano no máximo. |
| Dados de arquivo | Escolha Archive Storage para seus dados de arquivamento de longo prazo. Archive é uma boa opção para os dados que você precisa reter uma cópia por um período prolongado, mas que não pretende acessar mais de uma vez por ano. Por exemplo, use o Archive Storage para backups que você precisa reter por um longo prazo para atender aos requisitos regulatórios. Considere substituir sua solução de backup baseada em fita por Archive. |
Ao planejar o uso dessas opções de armazenamento, comece com o nível acessado com frequência e classifique seus dados de backup nos níveis de acesso não frequentes. Os backups geralmente se tornam raramente usados à medida que se tornam mais antigos. A probabilidade de você precisar de um backup de três anos é extremamente baixa, sendo possível usar esse backup no nível Archive para economizar custos. Para informações sobre os custos do Cloud Storage, consulte Preços do Cloud Storage.
Cloud Storage em comparação com o backup em fita
O destino de backup convencional no local é a fita. O Cloud Storage tem muitos benefícios sobre a fita, incluindo a capacidade de armazenar automaticamente backups "externos" do sistema de origem, porque os dados no Cloud Storage são replicados em várias instalações. Isso também significa que os backups armazenados no Cloud Storage estão altamente disponíveis.
Outra diferença importante é a velocidade de restauração de backups quando você precisa usá-los. Se você precisar criar um novo sistema SAP HANA a partir de um backup ou restaurar um sistema que já existe usando um backup, o Cloud Storage fornecerá acesso mais rápido aos seus dados, o que ajudará a criar o sistema com mais rapidez.
Recurso Backint do agente do Google Cloudpara SAP
É possível usar o Cloud Storage diretamente para backups e recuperações de instalações locais e na nuvem usando o recurso Backint certificado pela SAP do agente do Google Cloudpara SAP.
Para mais informações sobre esse recurso, consulte Backup e recuperação baseados no Backint para SAP HANA.
Fazer backup e recuperar o SAP HANA usando o Backint
As seções a seguir contêm informações sobre como fazer backup e recuperar o SAP HANA usando o recurso Backint do agente do Google Cloudpara SAP.
- Como acionar backups de dados e delta
- Como acionar backups de registros
- Como consultar o catálogo de backups
- Como recuperar um banco de dados
Como acionar backups de dados e delta
Para acionar um backup do volume de dados do SAP HANA e enviá-lo ao Cloud Storage usando o recurso Backint do agente do Google Cloudpara SAP, use o SAP HANA Studio, SAP HANA Cockpit, SAP HANA SQL ou o DBA Cockpit.
Veja a seguir as instruções SQL do SAP HANA para acionar backups de dados:
Para criar um backup completo para o banco de dados do sistema:
BACKUP DATA USING BACKINT ('BACKUP_NAME');Substitua
BACKUP_NAMEpelo nome que você quer definir para o backup.Para criar um backup completo para um banco de dados do locatário:
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Substitua
TENANT_SIDpelo SID do banco de dados do locatário.Para criar backups diferenciais e incrementais:
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Substitua
BACKUP_TYPEporDIFFERENTIALouINCREMENTAL, dependendo do tipo de backup que você quer criar.
Há várias opções que podem ser usadas com o acionamento de backups de dados. Para informações sobre essas opções, consulte o guia de referência do SAP HANA SQL sobre a Instrução BACKUP DATA (backup e recuperação).
Para mais informações sobre backups de dados e delta, consulte os documentos da SAP Backups de dados e Backups Delta (links em inglês).
Como acionar backups de registros
Para acionar um backup do volume de registro do SAP HANA e enviá-lo ao Cloud Storage usando o recurso Backint do agente do Google Cloudpara SAP, conclua as etapas a seguir:
- Crie um backup completo do banco de dados. Para instruções, consulte a documentação da SAP sobre sua versão do SAP HANA.
- No arquivo
global.inido SAP HANA, defina o parâmetrocatalog_backup_using_backintcomoyes.
Verifique se o modo de registro do sistema SAP HANA é normal, que é o valor padrão. Se o modo de registro estiver definido como overwrite, o banco de dados do SAP HANA desativará a criação de backups de registros.
Para mais informações sobre backups de registros, consulte o documento da SAP Backups de registros (em inglês).
Como consultar o catálogo de backups
O catálogo de backups do SAP HANA é uma parte essencial das operações de backup e recuperação. Ele contém informações sobre os backups criados para o banco de dados do SAP HANA.
Para consultar o catálogo de backups sobre informações a respeito de backups de um banco de dados de locatário, conclua as seguintes etapas:
- Deixe o banco de dados do locatário off-line.
No banco de dados do sistema, execute a seguinte instrução SQL:
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
Outra possibilidade para consultar um ponto específico no tempo, execute a seguinte instrução SQL:
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
A instrução cria o arquivo
strategyOutput.xmlno seguinte diretório:/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID.
Para informações sobre a instrução BACKUP LIST DATA, consulte o guia de referência do SAP HANA SQL sobre a Instrução BACKUP DATA (backup e recuperação) (em inglês).
Para informações sobre o catálogo de backups, consulte o documento da SAP Catálogo de backups (em inglês).
Como recuperar um banco de dados
Quando você executa uma recuperação usando um backup de dados multistream, o SAP HANA usa o mesmo número de canais usados quando o backup foi criado. Para mais informações, consulte o documento da SAP Pré-requisitos: recuperação usando backups multistream.
Para restaurar um backup de banco de dados do SAP HANA criado usando o recurso Backint
do agente do Google Cloudpara SAP, o SAP HANA fornece as instruções SQL
RECOVER DATA
e
RECOVER DATABASE.
As duas instruções SQL restauram backups do bucket do Cloud Storage que você especificou para o parâmetro bucket no arquivo PARAMETERS.json, a menos que você tenha especificado um bucket para parâmetro recover_bucket.
Confira a seguir exemplos de instruções SQL para recuperar um banco de dados do SAP HANA usando um backup criado com o recurso Backint do agente doGoogle Cloudpara SAP:
Para recuperar um banco de dados de locatário especificando o nome de arquivo do backup:
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;Para recuperar um banco de dados de locatário especificando o ID do backup:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
Substitua
BACKUP_IDpelo ID do backup necessário.Para recuperar um banco de dados de locatário especificando o ID do backup quando precisar usar o backup do catálogo de backups do SAP HANA armazenado no seu bucket do Cloud Storage:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
Para recuperar um banco de dados de locatário para um ponto específico no tempo ou para uma posição de registro específica:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
Para recuperar um banco de dados de locatário usando um backup a partir de um banco de dados externo:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
Substitua:
SOURCE_TENANT_SID: o SID do banco de dados do locatário de origemSOURCE_SID: o SID do sistema SAP em que o banco de dados do locatário de origem existe
Se for necessário recuperar um banco de dados do SAP HANA quando o catálogo de backups dele não estiver disponível no backup armazenado no seu bucket do Cloud Storage, siga as instruções apresentadas na Nota SAP 3227931 - Recuperar um banco de dados do HANA via Backint sem um catálogo de backup do HANA (em inglês).
Como gerenciar a identidade e o acesso a backups
Quando você usa o Cloud Storage ou o Compute Engine para fazer backup dos dados do SAP HANA, o acesso a esses backups é controlado pelo Identity and Access Management (IAM). Esse recurso permite que os administradores autorizem quem pode realizar ações em recursos específicos. O IAM oferece controle e visibilidade centralizados para gerenciar todos os recursos doGoogle Cloud , incluindo os backups.
O IAM também fornece um histórico completo de trilha de auditoria de autorização, remoção e delegação de permissões que são exibidas automaticamente para seus administradores. Isso permite configurar políticas que monitoram o acesso aos seus dados nos backups, permitindo que você conclua o ciclo completo de controle de acesso com seus dados. O IAM oferece uma visualização unificada da política de segurança em toda a organização, com auditoria integrada para facilitar os processos de compliance.
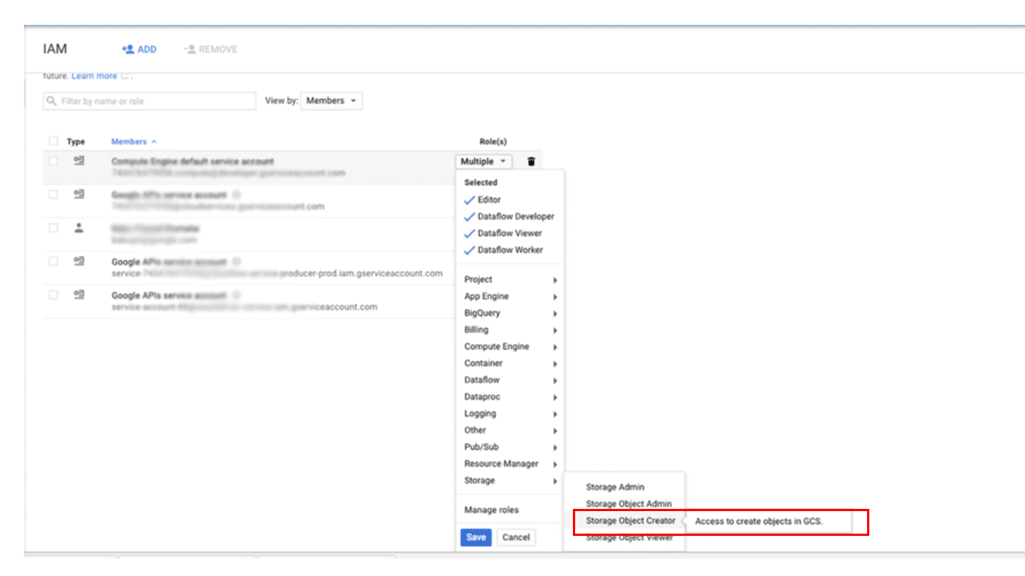
Para conceder a um principal acesso aos backups no Cloud Storage:
No Google Cloud console, acesse a página IAM e administrador:
Especifique o usuário a quem você quer conceder acesso e atribua o papel Storage > Criador de objeto do Storage:
Como criar backups baseados no sistema de arquivos para o SAP HANA
Os sistemas SAP HANA implantados no Google Cloud usando o
guia de implantação são
configurados com um conjunto de volumes do Persistent Disk ou Hyperdisk
para serem usados como um destino de backup montado com formato NFS. Os backups do SAP HANA são armazenados primeiro nesses discos locais. Depois disso, é necessário copiá-los para o Cloud Storage para armazenamento de longo prazo. É possível copiar manualmente os backups para o Cloud Storage ou programar a cópia para o Cloud Storage em um crontab.
Se você estiver usando o recurso Backint do agente do Google Cloudpara SAP, faça backup e a recuperação diretamente de um bucket do Cloud Storage, sem precisar do armazenamento em disco permanente para backups.
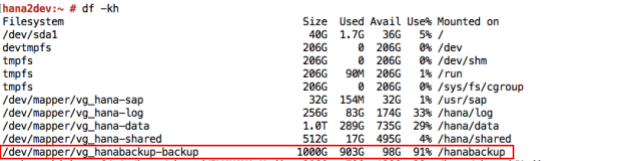
Para iniciar ou programar os backups de dados do SAP HANA, é possível usar o SAP HANA Studio, comandos SQL ou o DBA Cockpit. Os backups de registros são gravados automaticamente, a menos que sejam desativados. A captura de tela a seguir mostra um exemplo:
Como configurar global.ini do SAP HANA
Se você seguiu as instruções do guia de implantação, o arquivo de configuração global.ini do SAP HANA será personalizado com backups de banco de dados armazenados em /hanabackup/data/ e os arquivos de registros automáticos serão armazenados em /hanabackup/log/. Confira abaixo um exemplo de como é o global.ini:
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
Para personalizar o arquivo de configuração global.ini do recurso Backint do agente doGoogle Cloudpara SAP, consulte Configurar o SAP HANA para o recurso Backint.
Observações para implantações em escala horizontal
Em uma implementação de escalonamento horizontal, uma solução de alta disponibilidade que usa migração em tempo real e reinicialização automática funciona da mesma forma que em uma configuração de host único. A principal diferença é que o volume /hana/shared é montado com formato NFS para todos os hosts de worker e é definido como principal no mestre HANA. Há um breve período de inacessibilidade no volume NFS no caso de migração em tempo real do host mestre ou reinicialização automática. Quando o host mestre é reiniciado, o volume NFS começa a funcionar novamente em todos os hosts e as operações normais são retomadas automaticamente.
O volume de backup do SAP HANA, /hanabackup, precisa estar disponível em todos os hosts durante as operações de backup e recuperação. Em caso de falha, verifique se o /hanabackup está montado em todos os hosts e remonte os que não estiverem. Se você decidir copiar o conjunto de backups para outro volume ou para o Cloud Storage, execute a cópia no host mestre para conseguir um melhor desempenho de E/S e reduzir o uso da rede. Para simplificar o processo de backup e recuperação, use o Cloud Storage Fuse para montar o bucket do Cloud Storage em cada host.
O desempenho do escalonamento horizontal é tão bom quanto a distribuição de dados. Quanto melhor os dados forem distribuídos, melhor será o desempenho da sua consulta. Isso exige que você conheça bem seus dados, entenda como eles estão sendo consumidos e projete adequadamente a distribuição e o particionamento de tabelas. Para mais informações, consulte a Nota SAP 2081591 - Perguntas frequentes: distribuição de tabelas do SAP HANA.
Gcloud Python
O Gcloud Python é um cliente Python idiomático que pode ser usado para acessar serviçosGoogle Cloud . Neste guia, usamos o Gcloud Python para executar operações de backup e restauração do Cloud Storage para backups de banco de dados do SAP HANA.
Se você seguiu as instruções do guia de implantação, as bibliotecas do Gcloud Python já estarão disponíveis nas instâncias do Compute Engine.
As bibliotecas são de código aberto e permitem que você opere no bucket do Cloud Storage para armazenar e recuperar dados de backup.
É possível executar o seguinte comando para listar objetos no bucket do Cloud Storage. É possível usá-lo para listar os backups disponíveis:
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
Para detalhes completos sobre o Gcloud Python, consulte a documentação de referência da biblioteca de cliente de armazenamento.
Exemplo de backup e restauração
Nas próximas seções, ilustramos o procedimento que pode ser seguido para tarefas típicas de backup e restauração usando o SAP HANA Studio.
Exemplo de criação de backup
No Editor de backup do SAP HANA, selecione Open Backup Wizard.
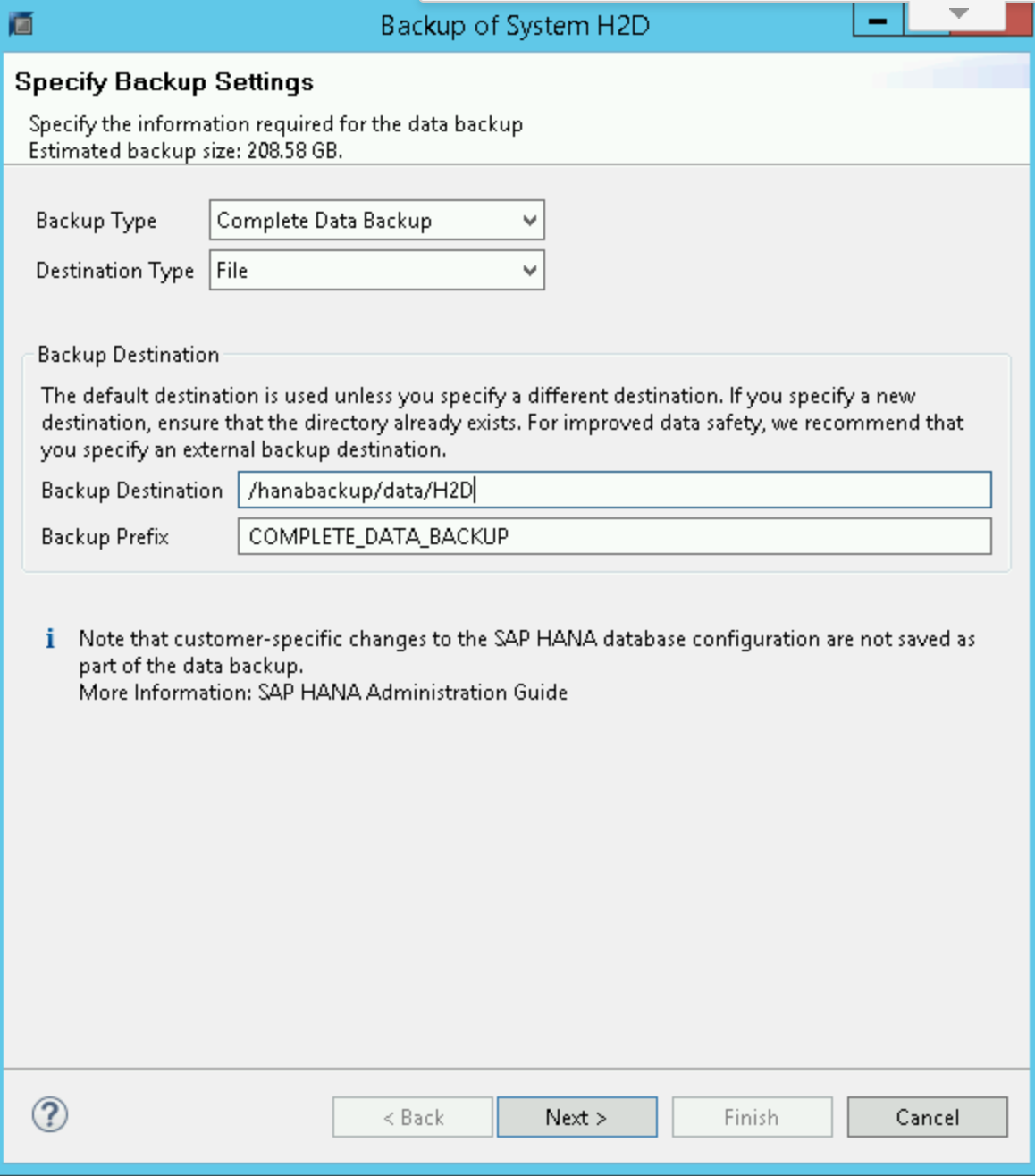
- Selecione File como o tipo de destino. Isso faz o backup do banco de dados para arquivos no sistema de arquivos especificado.
- Especifique o destino do backup,
/hanabackup/data/SID, e o prefixo do backup. SubstituaSIDpelo ID do seu sistema SAP. - Clique em Próxima.
Clique em Finish no formulário de confirmação para iniciar o backup.
Quando o backup é iniciado, uma janela de status exibe o andamento do backup. Aguarde a conclusão do backup.
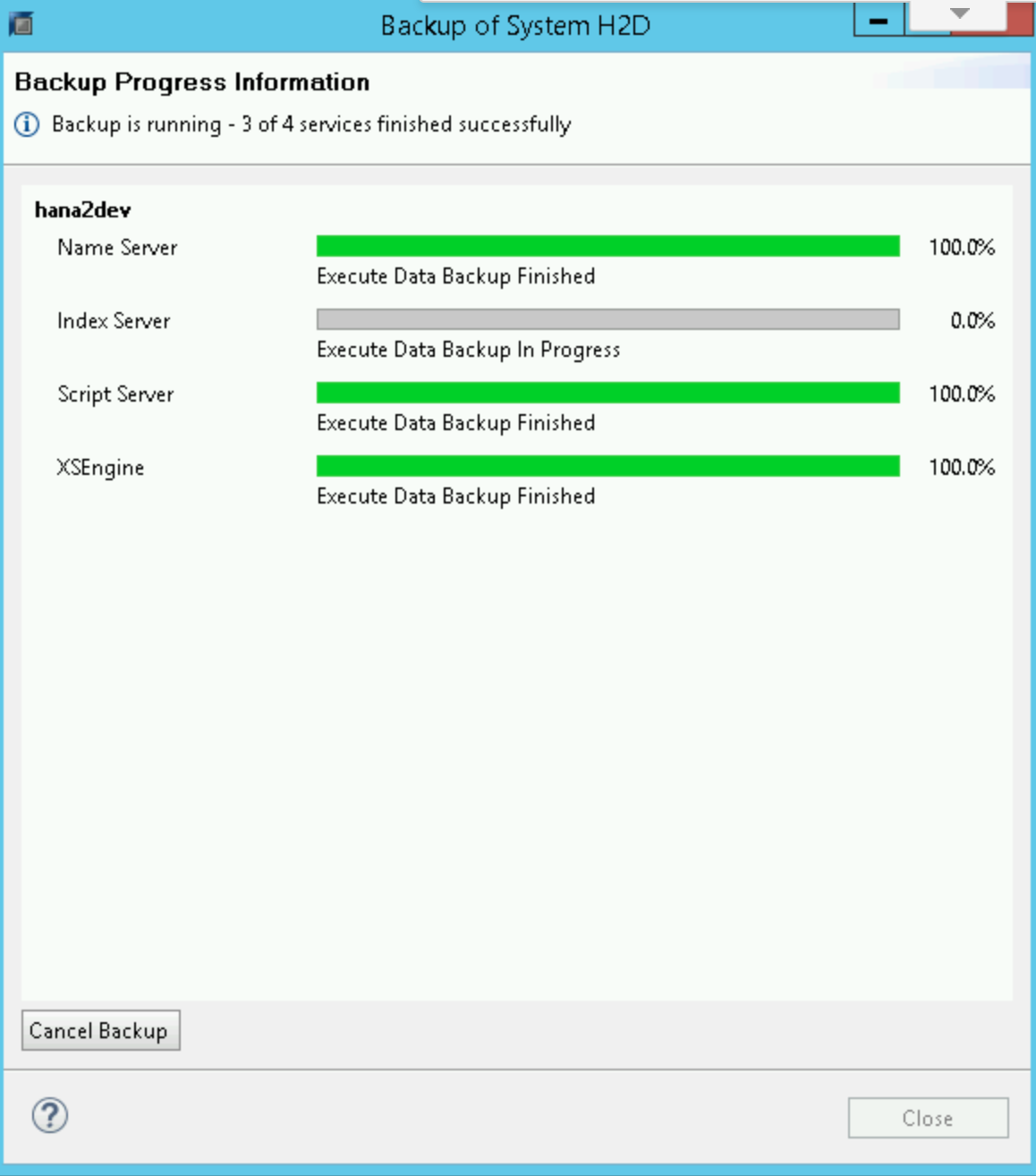
Quando o backup for concluído, o resumo do backup exibirá uma mensagem
Finished.Faça login no sistema SAP HANA e verifique se os backups estão disponíveis nos locais esperados no sistema de arquivos. Por exemplo:
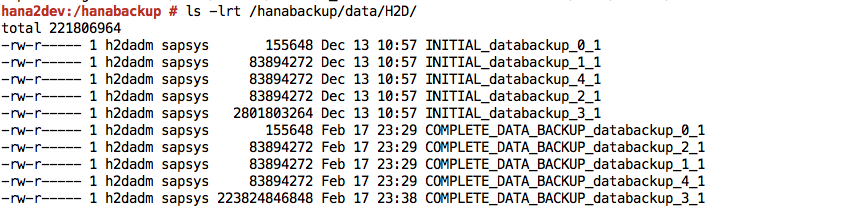

Envie ou sincronize os arquivos de backup do sistema de arquivos
/hanabackuppara o Cloud Storage. O exemplo de script Python a seguir envia os dados de/hanabackup/datae/hanabackup/logpara o bucket usado para backups, no formatoNODE_NAME/DATAouLOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME. Isso permite identificar os arquivos de backup com base no tempo em que o backup foi copiado. Execute este scriptgcloud Pythonno comando Bash do sistema operacional:python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOFUse as bibliotecas do Gcloud Python ou o console Google Cloud para listar os dados de backup.
Exemplo de restauração de backup
Se os arquivos de backup não estiverem disponíveis no diretório
/hanabackup, mas estiverem disponíveis no Cloud Storage, faça o download dos arquivos do Cloud Storage executando o seguinte script no comando Bash do sistema operacional:python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOFPara recuperar o banco de dados do SAP HANA, clique em Backup e recuperação > Recuperar sistema:
Clique em Próxima.
Especifique o local dos backups no sistema de arquivos local e clique em Adicionar.
Clique em Próxima.
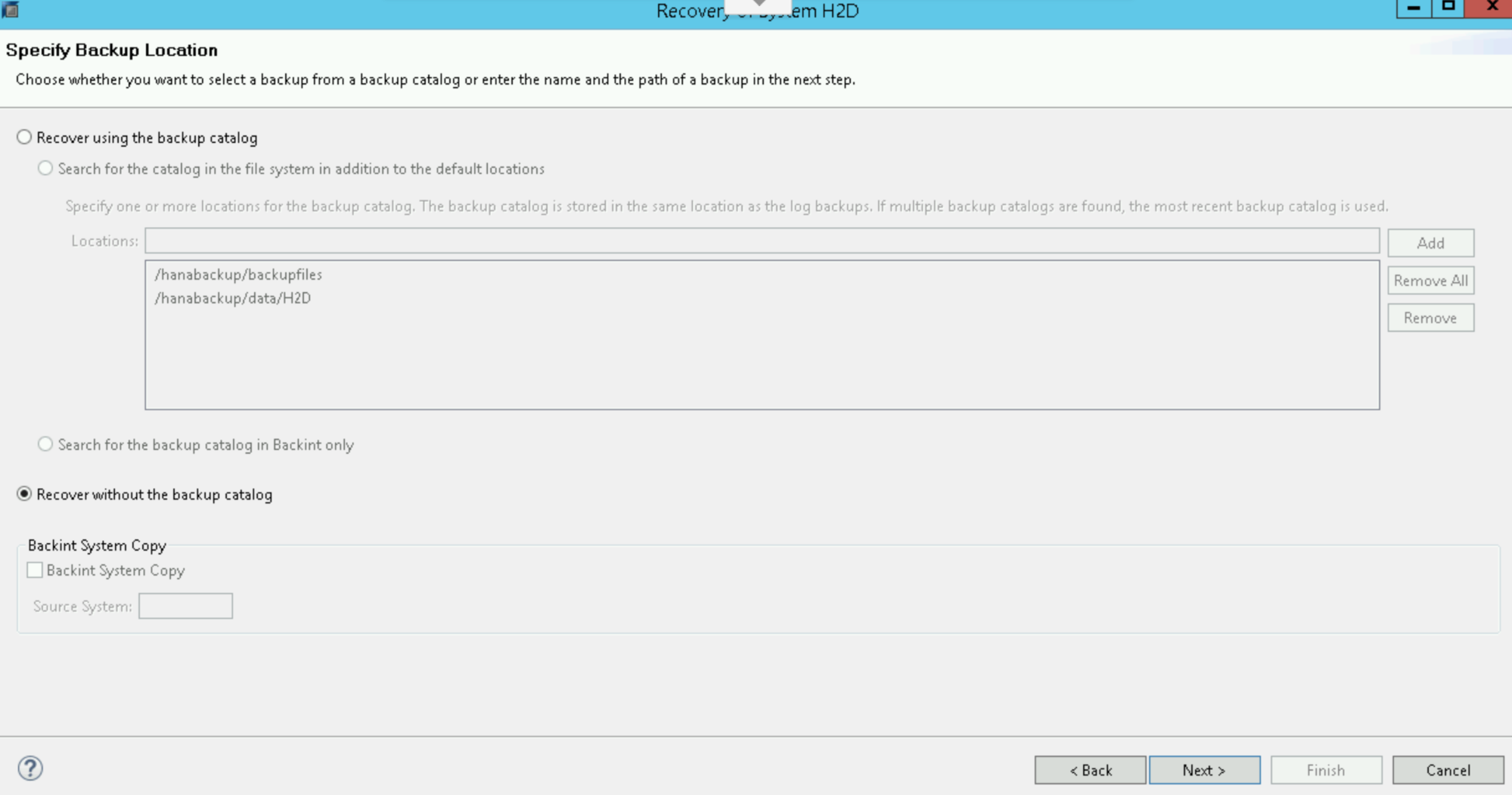
Selecione Recover without the backup catalog:
Clique em Next.
Selecione File como o tipo de destino e especifique o local dos arquivos de backup e o prefixo correto para o backup. Se você seguiu o procedimento do Exemplo de criação de backup, lembre-se que
COMPLETE_DATA_BACKUPfoi definido com o prefixo.Clique em Next duas vezes.
Clique em Finish para iniciar a recuperação.
Quando a recuperação for concluída, retome as operações normais e remova os arquivos de backup dos diretórios
/hanabackup/data/SID/*.
A seguir
Os seguintes documentos SAP padrão podem ser úteis:
Os seguintes documentos Google Cloud também podem ser úteis:
- Recursos de nuvem gratuitos e opção de teste
- Começar a usar o Google Cloud
- Compute Engine
- Persistent Disk