이 가이드에서는 Terraform: SAP HANA 수직 확장 배포 가이드에 따라 Google Cloud 에 배포된 SAP HANA 시스템을 운영하는 방법을 설명합니다. 이 가이드의 목적은 표준 SAP 문서를 대신하려는 것이 아님을 알려드립니다.
SAP HANA 시스템 관리 Google Cloud
이 섹션에서는 시스템 시작, 중지, 클론에 대한 정보 등 SAP HANA 시스템을 작동하는 데 일반적으로 필요한 관리 작업 수행 방법을 설명합니다.
인스턴스 시작 및 중지
언제든지 SAP HANA 호스트를 한 개 이상 중지할 수 있으며, 인스턴스를 중지하면 인스턴스가 종료됩니다. 종료 기간 내에 종료가 완료되지 않으면 인스턴스가 강제로 중단됩니다. 데이터 손실 또는 파일 시스템 손상을 방지하려면 다음 중 하나 또는 둘 다를 실행하는 것이 좋습니다.
인스턴스를 중지하기 전에 인스턴스에서 실행되는 SAP HANA를 중지합니다.
인스턴스의 종료 기간을 연장하려면 인스턴스에서 단계적 종료를 사용 설정하세요.
인스턴스를 중지하거나 다시 시작하는 방법은 Compute Engine 인스턴스 중지 또는 다시 시작을 참고하세요.
VM 수정
VM이 배포된 후 VM 유형을 비롯한 VM의 다양한 속성을 변경할 수 있습니다. 백업에서 SAP 시스템을 복원해야 변경사항이 적용되는 경우도 있고 VM을 다시 시작하기만 하면 변경사항이 적용되는 경우도 있습니다.
자세한 내용은 SAP 시스템의 VM 구성 수정을 참조하세요.
SAP HANA의 스냅샷 만들기
영구 디스크의 특정 시점 백업을 생성하기 위해 스냅샷을 만들 수 있습니다. Compute Engine은 데이터 무결성을 보장하는 자동 체크섬을 사용하여 각 스냅샷의 복사본 여러 개를 여러 위치에 저장합니다.
스냅샷을 만들려면 스냅샷 만들기의 Compute Engine 지침을 따릅니다. 일관된 스냅샷을 만들 수 있도록 스냅샷을 만들기 전에 디스크 버퍼를 디스크로 플러시하는 등 준비 단계에 주의하세요.
스냅샷은 다음과 같은 사용 사례에 유용합니다.
| 사용 사례 | 세부정보 |
|---|---|
| 간편하고 소프트웨어 독립적이며 경제적인 백업 솔루션 제공 | 스냅샷을 사용하여 데이터, 로그, 백업, 공유 디스크를 백업합니다. 이 디스크의 일일 백업을 예약하면 전체 데이터 세트의 특정 시점 백업이 가능합니다. 첫 번째 스냅샷 이후에 생성되는 스냅샷에는 증분 블록 변경사항만 저장됩니다. 이를 통해 비용을 절감할 수 있습니다. |
| 다른 스토리지 유형으로 마이그레이션 | Compute Engine은 표준(자기) 스토리지가 지원하는 유형 및 솔리드 스테이트 드라이브 스토리지(SSD 기반 영구 디스크)가 지원하는 유형을 포함하여 다양한 유형의 영구 디스크를 제공합니다. 비용 및 성능 특성은 각각 다릅니다. 예를 들어 백업 볼륨에는 표준 유형을 사용하고 /hana/log 및 /hana/data 볼륨에는 고성능이 필요하므로 SSD 기반 유형을 사용합니다. 스토리지 유형 간에 마이그레이션하려면 볼륨 스냅샷을 사용한 후 스냅샷을 사용하여 새 볼륨을 만들고 다른 스토리지 유형을 선택합니다. |
| SAP HANA를 다른 리전 또는 영역으로 마이그레이션 | 스냅샷을 사용하여 SAP HANA 시스템을 한 영역에서 동일한 리전의 다른 영역으로 또는 다른 리전으로 이전할 수 있습니다. 스냅샷을Google Cloud 내에서 전역으로 사용하여 다른 영역 또는 리전에 디스크를 만들 수 있습니다. 다른 리전 또는 영역으로 이전하려면 루트 디스크를 포함한 디스크 스냅샷을 만든 후 스냅샷에서 생성된 디스크를 사용하여 원하는 영역 또는 리전에 가상 머신을 만듭니다. |
디스크 설정 변경
4시간에 한 번씩 프로비저닝된 IOPS 또는 처리량을 변경하거나 하이퍼디스크 볼륨 크기를 늘릴 수 있습니다.
4시간이 만료되기 전에 디스크를 수정하려고 시도하면 Cannot update provisioned throughput due to being rate limited와 같은 속도 제한 오류가 표시됩니다.
이러한 오류를 해결하려면 마지막 수정 이후 4시간을 기다린 후 디스크 수정을 다시 시도하세요.
디스크 크기, 프로비저닝된 IOPS, 하이퍼디스크 볼륨 처리량 조정을 위해 4시간까지 기다릴 수 없는 긴급 상황에서만 이 절차를 따르세요.
디스크 설정을 변경하려면 다음 단계를 수행합니다.
다음 명령어 중 하나를 실행하여 SAP HANA 인스턴스를 중지합니다.
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
INSTANCE_NUMBER를 SAP HANA 시스템의 인스턴스 수로 바꿉니다.자세한 내용은 SAP HANA 시스템 시작 및 중지를 참조하세요.
기존 디스크의 스냅샷 또는 이미지를 만듭니다.
스냅샷 기반 백업
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATION다음을 바꿉니다.
SNAPSHOT_NAME: 만들려는 스냅샷의 이름입니다.PROJECT_NAME: Google Cloud 프로젝트의 이름입니다.SOURCE_DISK_NAME: 스냅샷을 만드는 데 사용된 소스 디스크입니다.ZONE: 작업할 소스 디스크의 영역입니다.LOCATION: 스냅샷 콘텐츠가 저장되는 리전 또는 멀티 리전에 해당하는 Cloud Storage 위치입니다.자세한 내용은 디스크 스냅샷 만들기 및 관리를 참조하세요.
이미지 기반 백업
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATION다음을 바꿉니다.
IMAGE_NAME: 만들려는 디스크 이미지의 이름입니다.PROJECT_NAME: Google Cloud 프로젝트의 이름입니다.SOURCE_DISK_NAME: 이미지를 만드는 데 사용된 소스 디스크입니다.ZONE: 작업할 소스 디스크의 영역입니다.LOCATION: 이미지 콘텐츠가 저장되는 리전 또는 멀티 리전에 해당하는 Cloud Storage 위치입니다.자세한 내용은 커스텀 이미지 만들기를 참조하세요.
스냅샷 또는 이미지에서 새 디스크를 만듭니다.
하이퍼디스크 볼륨의 경우 워크로드 요구사항을 충족하도록 디스크 크기, IOPS, 처리량을 지정해야 합니다. Hyperdisk의 IOPS 및 처리량에 대한 자세한 내용은 프로비저닝된 Hyperdisk 성능 정보를 참고하세요.
스냅샷 사용
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUT다음을 바꿉니다.
NEW_DISK_NAME: 만들려는 디스크의 이름입니다.PROJECT_NAME: Google Cloud 프로젝트의 이름입니다.DISK_TYPE: 만들려는 디스크의 유형입니다.DISK_SIZE: 디스크의 크기입니다.ZONE: 만들려는 디스크의 영역입니다.SOURCE_SNAPSHOT: 디스크를 만드는 데 사용된 소스 스냅샷입니다.IOPS: 만들려는 디스크의 프로비저닝된 IOPS입니다.THROUGHPUT: 만들려는 디스크의 프로비저닝된 처리량입니다.
이미지 사용
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUT다음을 바꿉니다.
NEW_DISK_NAME: 만들려는 디스크의 이름입니다.PROJECT_NAME: Google Cloud 프로젝트의 이름입니다.DISK_TYPE: 만들려는 디스크의 유형입니다.DISK_SIZE: 디스크의 크기입니다.ZONE: 만들려는 디스크의 영역입니다.SOURE_IMAGE_NAME: 만들려는 디스크에 적용할 소스 이미지입니다.IMAGE_PROJECT_NAME: 모든 이미지 및 이미지 계열 참조를 확인하려는 대상 Google Cloud 프로젝트입니다.IOPS: 만들려는 디스크의 프로비저닝된 IOPS입니다.THROUGHPUT: 만들려는 디스크의 프로비저닝된 처리량입니다.
자세한 내용은
gcloud compute disks create를 참조하세요.SAP HANA 시스템에서 기존 디스크를 분리합니다.
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAME다음을 바꿉니다.
INSTANCE_NAME: 작업하려는 인스턴스의 이름입니다.OLD_DISK_NAME: 리소스 이름으로 분리하려는 디스크입니다.ZONE: 작업하려는 인스턴스의 영역입니다.PROJECT_NAME: Google Cloud 프로젝트의 이름입니다.
자세한 내용은
gcloud compute instances detach-disk를 참조하세요.SAP HANA 시스템에 새 디스크를 연결합니다.
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAME다음을 바꿉니다.
INSTANCE_NAME: 작업하려는 인스턴스의 이름입니다.NEW_DISK_NAME: 인스턴스에 연결하려는 디스크의 이름입니다.ZONE: 작업하려는 인스턴스의 영역입니다.PROJECT_NAME: Google Cloud 프로젝트의 이름입니다.
자세한 내용은
gcloud compute instances attach-disk를 참조하세요.마운트 지점이 올바르게 연결되었는지 확인합니다.
lsblk다음과 비슷한 출력이 표시됩니다.
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/log다음 명령어 중 하나를 실행하여 SAP HANA 인스턴스를 시작합니다.
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
INSTANCE_NUMBER를 SAP HANA 시스템의 인스턴스 수로 바꿉니다.자세한 내용은 SAP HANA 시스템 시작 및 중지를 참조하세요.
새 하이퍼디스크 볼륨의 디스크 크기, IOPS, 처리량을 검사합니다.
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAME다음을 바꿉니다.
DISK_NAME: 확인하려는 디스크의 이름입니다.ZONE: 확인하려는 디스크의 영역입니다.PROJECT_NAME: Google Cloud 프로젝트의 이름입니다.
자세한 내용은
gcloud compute disks describe를 참조하세요.
SAP HANA 시스템 클론
Google Cloud 에서 기존 SAP HANA 시스템의 스냅샷을 만들어 시스템의 정확한 클론을 만들 수 있습니다.
단일 호스트 SAP HANA 시스템을 클론하려면 다음 안내를 따르세요.
데이터 및 백업 디스크의 스냅샷을 만듭니다.
스냅샷을 사용하여 새 디스크를 만듭니다.
Google Cloud 콘솔에서 VM 인스턴스 페이지로 이동합니다.
클론할 인스턴스를 클릭하여 인스턴스 세부정보 페이지를 연 후 클론을 클릭합니다.
스냅샷에서 생성된 디스크를 연결합니다.
멀티 호스트 SAP HANA 시스템을 클론하려면 다음 안내를 따르세요.
클론할 SAP HANA 시스템과 구성이 동일한 새 SAP HANA 시스템을 프로비저닝합니다.
원래 시스템의 데이터를 백업합니다.
원래 시스템의 백업을 새 시스템에 복원합니다.
gcloud CLI 설치 및 업데이트
SAP HANA용 VM을 배포하고 운영체제를 설치한 후에는 Cloud Storage와 파일을 주고 받거나 네트워크 서비스와 상호작용하는 등 다양한 목적을 위해 최신 Google Cloud CLI가 필요합니다.
SAP HANA 배포 가이드의 안내를 따르면 gcloud CLI가 자동으로 설치됩니다.
하지만 자체 운영체제를 커스텀 이미지로 Google Cloud 에 가져오거나Google Cloud에서 제공하는 이전 공개 이미지를 사용하는 경우 gcloud CLI를 직접 설치하거나 업데이트해야 할 수 있습니다.
gcloud CLI가 설치되어 있고 업데이트 가능 여부를 확인하려면 터미널 또는 명령 프롬프트를 열고 다음 명령어를 입력합니다.
gcloud version
명령어가 인식되지 않으면 gcloud CLI가 설치되지 않은 것입니다.
gcloud CLI를 설치하려면 gcloud CLI 설치의 안내를 따르세요.
SLES 통합 gcloud CLI 버전 140 이하를 대체하려면 다음 안내를 따르세요.
ssh를 사용하여 VM에 로그인합니다.최고 사용자로 전환합니다.
sudo su다음 명령어를 입력합니다.
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
SAP HANA 빠른 다시 시작 사용 설정
Google Cloud 특히 큰 인스턴스의 경우 SAP HANA의 각 인스턴스에 SAP HANA 빠른 다시 시작을 사용 설정하는 것이 적극적으로 권장됩니다. SAP HANA 빠른 다시 시작은 SAP HANA가 종료되지만 운영체제는 계속 실행되는 경우 다시 시작하는 시간을 줄입니다.
Google Cloud 에서 제공하는 자동화 스크립트에서 구성한 대로 운영체제와 커널 설정에서는 이미 SAP HANA 빠른 재시작을 지원합니다.
tmpfs 파일 시스템을 정의하고 SAP HANA를 구성해야 합니다.
tmpfs 파일 시스템을 정의하고 SAP HANA를 구성하려면 수동 단계를 수행하거나Google Cloud 에서 제공하는 자동화 스크립트를 사용하여 SAP HANA 빠른 다시 시작을 사용 설정하면 됩니다. 자세한 내용은 다음을 참조하세요.
SAP HANA 빠른 다시 시작 옵션에 대한 전체 안내는 SAP HANA 빠른 다시 시작 옵션 문서를 참조하세요.
수동 단계
tmpfs 파일 시스템 구성
호스트 VM 및 기본 SAP HANA 시스템이 성공적으로 배포되면 tmpfs 파일 시스템에 NUMA 노드의 디렉터리를 만들고 마운트해야 합니다.
VM의 NUMA 토폴로지 표시
필요한 tmpfs 파일 시스템을 매핑하려면 먼저 VM에 있는 NUMA 노드 수를 알아야 합니다. Compute Engine VM에 사용 가능한 NUMA 노드를 표시하려면 다음 명령어를 입력합니다.
lscpu | grep NUMA
예를 들어 m2-ultramem-208 VM 유형에는 다음 예시와 같이 0~3으로 번호가 지정된 4개의 NUMA 노드가 있습니다.
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
NUMA 노드 디렉터리 만들기
VM에서 각 NUMA 노드의 디렉터리를 만들고 권한을 설정합니다.
예를 들어 0~3으로 번호가 지정된 4개의 NUMA 노드는 다음과 같습니다.
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDNUMA 노드 디렉터리를 tmpfs에 마운트
tmpfs 파일 시스템 디렉터리를 마운트하고 각각에 대해 mpol=prefer로 NUMA 노드 기본 설정을 지정합니다.
SID: SID를 대문자로 지정합니다.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
/etc/fstab 업데이트
운영체제 재부팅 후 마운트 지점을 사용할 수 있도록 하려면 파일 시스템 테이블 /etc/fstab에 항목을 추가합니다.
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
선택사항: 메모리 사용량 한도 설정
tmpfs 파일 시스템은 동적으로 확장 및 축소할 수 있습니다.
tmpfs 파일 시스템에서 사용하는 메모리를 제한하려면 size 옵션을 사용하여 NUMA 노드 볼륨의 크기 제한을 설정하면 됩니다.
예를 들면 다음과 같습니다.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
global.ini 파일의 [memorymanager] 섹션에서 persistent_memory_global_allocation_limit 매개변수를 설정하여 특정 SAP HANA 인스턴스 및 지정된 서버 노드의 모든 NUMA 노드에 대한 전체 tmpfs 메모리 사용량을 제한할 수도 있습니다.
빠른 다시 시작을 위한 SAP HANA 구성
빠른 다시 시작을 위해 SAP HANA를 구성하려면 global.ini 파일을 업데이트하고 영구 메모리에 저장할 테이블을 지정합니다.
global.ini 파일에서 [persistence] 섹션 업데이트
SAP HANA global.ini 파일에서 tmpfs 섹션을 참조하도록 [persistence] 섹션을 구성합니다. 각 tmpfs 위치를 세미콜론으로 구분합니다.
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
앞의 예시는 m2-ultramem-208에 해당하는 4개의 NUMA 노드에 메모리 볼륨 4개를 지정합니다. m2-ultramem-416에서 실행 중인 경우 메모리 볼륨 8개(0~7)를 구성해야 합니다.
global.ini 파일을 수정한 후 SAP HANA를 다시 시작합니다.
이제 SAP HANA에서 tmpfs 위치를 영구 메모리 공간으로 사용할 수 있습니다.
영구 메모리에 저장할 테이블 지정
영구 메모리에 저장할 특정 열 테이블 또는 파티션을 지정합니다.
예를 들어 기존 테이블에 영구 메모리를 사용 설정하려면 SQL 쿼리를 실행합니다.
ALTER TABLE exampletable persistent memory ON immediate CASCADE
새 테이블의 기본값을 변경하려면 indexserver.ini 파일에 table_default 매개변수를 추가합니다. 예를 들면 다음과 같습니다.
[persistent_memory] table_default = ON
열, 테이블 제어 방법 및 자세한 정보를 제공하는 모니터링 뷰에 대한 자세한 내용은 SAP HANA 영구 메모리를 참조하세요.
자동 단계
SAP HANA 빠른 다시 시작을 사용 설정하도록 Google Cloud 제공하는 자동화 스크립트는 /hana/tmpfs* 디렉터리, /etc/fstab 파일, SAP HANA 구성을 변경합니다. 스크립트를 실행할 때 SAP HANA 시스템의 초기 배포인지 여부 또는 머신 크기를 다른 NUMA 크기로 조절하는지 여부에 따라 추가 단계를 수행해야 할 수 있습니다.
SAP HANA 시스템을 처음 배포하거나 머신 크기를 조절하여 NUMA 노드 수를 늘리려면 SAP HANA 빠른 다시 시작을 사용 설정하도록 Google Cloud 제공하는 자동화 스크립트를 실행하는 동안 SAP HANA가 실행 중인지 확인합니다.
NUMA 노드 수가 줄어들도록 머신 크기를 조절하는 경우 SAP HANA 빠른 다시 시작을 사용 설정하도록 Google Cloud 제공하는 자동화 스크립트를 실행하는 동안 SAP HANA가 중지되었는지 확인합니다. 스크립트가 실행된 후 SAP HANA 구성을 수동으로 업데이트하여 SAP HANA 빠른 다시 시작 설정을 완료해야 합니다. 자세한 내용은 빠른 다시 시작을 위한 SAP HANA 구성을 참고하세요.
SAP HANA 빠른 다시 시작을 사용 설정하려면 다음 단계를 수행합니다.
호스트 VM과의 SSH 연결을 설정합니다.
루트로 전환하기:
sudo su -
sap_lib_hdbfr.sh스크립트 다운로드:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
파일을 실행 가능하게 만듭니다.
chmod +x sap_lib_hdbfr.sh
스크립트에 오류가 없는지 확인합니다.
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
명령어에서 오류를 반환하면 Cloud Customer Care팀에 문의하세요. 고객 관리에 문의하는 방법에 대한 자세한 내용은 Google Cloud에서 SAP 지원 받기를 참고하세요.
SAP HANA 데이터베이스의 SYSTEM 사용자에 대한 SAP HANA 시스템 ID(SID)와 비밀번호를 바꾼 후 스크립트를 실행합니다. 비밀번호를 안전하게 제공하려면 Secret Manager에서 보안 비밀을 사용하는 것이 좋습니다.
Secret Manager에서 보안 비밀 이름을 사용하여 스크립트를 실행합니다. 이 보안 비밀은 Google Cloud 호스트 VM 인스턴스가 포함된 프로젝트에 있어야 합니다.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
다음을 바꿉니다.
SID: 대문자로 SID를 지정합니다. 예를 들면AHA입니다.SECRET_NAME: SAP HANA 데이터베이스의 SYSTEM 사용자에 대한 비밀번호에 해당하는 보안 비밀의 이름을 지정합니다. 이 보안 비밀은 호스트 VM 인스턴스가 포함된 Google Cloud 프로젝트에 있어야 합니다.
또는 일반 텍스트 비밀번호를 사용하여 스크립트를 실행할 수 있습니다. SAP HANA 빠른 다시 시작을 사용 설정한 후에 비밀번호를 변경해야 합니다. VM의 명령줄 기록에 비밀번호가 기록되므로 일반 텍스트 비밀번호를 사용하지 않는 것이 좋습니다.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
다음을 바꿉니다.
SID: 대문자로 SID를 지정합니다. 예를 들면AHA입니다.PASSWORD: SAP HANA 데이터베이스의 SYSTEM 사용자에 대한 비밀번호를 지정합니다.
초기 실행이 성공하면 다음과 비슷한 출력이 표시됩니다.
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
SAProuter로 SAP 지원 채널 설정
SAP 지원 엔지니어가Google Cloud의 SAP HANA 시스템에 액세스하도록 허용해야 하는 경우에는 SAProuter를 사용하면 됩니다. 다음 단계를 따르세요.
SAProuter 소프트웨어가 설치될 Compute Engine VM 인스턴스를 시작하고 인스턴스가 인터넷에 액세스할 수 있도록 외부 IP 주소를 할당합니다.
새로운 고정 외부 IP 주소를 만든 후 이 IP 주소를 인스턴스에 할당합니다.
네트워크에서 특정 SAProuter 방화벽 규칙을 만들고 구성합니다. SAProuter 인스턴스의 경우 이 규칙에서는 SAP 지원 네트워크에 대한 필요한 인바운드 및 아웃바운드 액세스만 허용합니다.
TCP 포트
3299와 함께 SAP가 연결을 위해 제공하는 특정 IP 주소에 대한 인바운드 및 아웃바운드 액세스를 제한합니다. 방화벽 규칙에 대상 태그를 추가하고 인스턴스 이름을 입력합니다. 이렇게 하면 방화벽 규칙이 새 인스턴스에만 적용됩니다. 방화벽 규칙 만들기 및 구성에 대한 자세한 내용은 방화벽 규칙 문서를 참조하세요.SAP Note 1628296에 따라 SAProuter 소프트웨어를 설치하고 SAP에서 Google Cloud의 SAP HANA 시스템에 액세스할 수 있도록 해주는
saprouttab파일을 만듭니다.SAP와의 연결을 설정합니다. 인터넷 연결에 보안 네트워크 통신을 사용합니다. 자세한 내용은 SAP 원격 지원 – 도움말을 참조하세요.
네트워크 구성
Google Cloud 가상 네트워크에서 VM을 사용하여 SAP HANA 시스템을 프로비저닝합니다. Google Cloud 는 최신 소프트웨어 정의 네트워킹 및 분산 시스템 기술을 사용하여 전 세계에 서비스를 호스팅하고 제공합니다.
SAP HANA의 경우 네트워크의 각 서브네트워크에 겹치지 않는 CIDR IP 주소 범위를 가진 기본이 아닌 서브넷 네트워크를 만듭니다. 각 서브네트워크와 내부 IP 주소 범위는 단일 리전에 매핑됩니다.
서브네트워크는 서브네트워크가 생성된 리전의 모든 영역에 걸쳐 있습니다.
하지만 VM 인스턴스를 만들 때는 VM의 영역과 서브네트워크를 지정합니다. 예를 들어 subnetwork1 및 region1의 zone1에 인스턴스의 한 집합을, subnetwork2 및 region1의 zone2에 인스턴스의 다른 집합을 필요에 따라 만들 수 있습니다.
새로운 네트워크에는 방화벽 규칙이 없으므로 네트워크 액세스가 불가능합니다. 최소 권한 모델을 바탕으로 SAP HANA 인스턴스에 액세스할 수 있는 방화벽 규칙을 만들어야 합니다. 방화벽 규칙은 전체 네트워크에 적용되며 태깅 메커니즘을 사용하여 특정 대상 인스턴스에 적용되도록 구성할 수도 있습니다.
경로는 단일 네트워크에 연결된 리전이 아닌 전역 리소스입니다. 사용자가 만든 경로는 네트워크에 있는 모든 인스턴스에 적용됩니다. 즉, 외부 IP 주소를 요구하지 않고도 같은 네트워크의 여러 서브네트워크에 있는 인스턴스 간에 트래픽을 전달하는 경로를 추가할 수 있습니다.
SAP HANA 인스턴스의 경우 외부 IP 주소 없이 인스턴스를 시작하고 다른 VM을 외부 액세스용 NAT 게이트웨이로 구성합니다. 이렇게 구성하려면 NAT 게이트웨이를 SAP HANA 인스턴스의 경로로 추가해야 합니다. 이 절차는 배포 가이드에 설명되어 있습니다.
보안
다음 섹션에서는 보안 운영을 설명합니다.
최소 권한 모델
첫 번째 방어선은 방화벽을 사용하여 인스턴스에 연결할 수 있는 대상을 제한하는 것입니다. 방화벽 규칙을 만들면 특정 포트 집합의 네트워크 또는 대상 머신에 대한 모든 트래픽을 특정 소스 IP 주소로 제한할 수 있습니다. 액세스 권한을 액세스가 필요한 특정 IP 주소, 프로토콜, 포트로 제한하려면 최소 권한 모델을 따라야 합니다. 예를 들어 항상 배스천 호스트를 설정하고 이 호스트에서만 SSH를 통해 SAP HANA 시스템에 연결되도록 해야 합니다.
구성 변경사항
권장 보안 설정으로 SAP HANA 시스템 및 운영체제를 구성해야 합니다. 예를 들어 액세스를 허용하고 SAP HANA를 실행 중인 운영체제를 강화하는 등 관련 네트워크 포트만 나열되는지 확인합니다.
다음 SAP Note(SAP 사용자 계정 필요)를 참조하세요.
- 1944799: Guidelines for SLES SAP HANA installation
- 1730999: Recommended configuration changes
- 1731000: Unrecommended configuration changes
불필요한 SAP HANA 서비스 사용 중지
SAP HANA Extended Application Services(SAP HANA XS)가 필요하지 않으면 이 서비스를 사용 중지합니다. SAP Note 1697613: Removing the SAP HANA XS Classic Engine service from the topology를 참조하세요.
서비스가 사용 중지되었으면 서비스용으로 열려 있는 모든 TCP 포트를 삭제합니다. Google Cloud에서 이는 네트워크의 방화벽 규칙을 수정하여 액세스 목록에서 이러한 포트를 삭제하는 것을 의미합니다.
감사 로깅
Cloud 감사 로그는 관리자 활동 및 데이터 액세스의 두 가지 로그 스트림으로 구성되며, 이들 모두 Google Cloud에서 자동으로 생성됩니다. 이를 통해Google Cloud 프로젝트에서 '누가 언제 어디서 무엇을 했는지'를 확인할 수 있습니다.
관리자 활동 로그에는 서비스 또는 프로젝트의 구성이나 메타데이터를 수정하는 API 호출 또는 관리 작업의 로그 항목이 포함됩니다. 이 로그는 항상 사용 설정되어 있고 모든 프로젝트 구성원에게 표시됩니다.
데이터 액세스 로그에는 서비스에서 관리하는 사용자 제공 데이터(예: 데이터베이스 서비스에 저장된 데이터)를 만들거나 수정하거나 읽는 API 호출의 로그 항목이 포함됩니다. 이 유형의 로깅은 프로젝트에서 기본적으로 사용 설정되며 Cloud Logging 또는 활동 피드를 통해 액세스 할 수 있습니다.
Cloud Storage 버킷 보안
Cloud Storage를 사용하여 데이터와 로그의 백업을 호스팅하는 경우, 전송 중 데이터를 보호하려면 인스턴스에서 Cloud Storage로 데이터를 전송할 때 TLS(HTTPS)를 사용해야 합니다. Cloud Storage는 저장 데이터를 자동으로 암호화합니다. 자체 키 관리 시스템이 있는 경우 자체 암호화 키를 지정할 수 있습니다.
관련 보안 문서
Google Cloud의 SAP HANA 환경과 관련된 다음 추가 보안 자료를 참고하세요.
SAP HANA의 고가용성 Google Cloud
Google Cloud 는 Compute Engine 라이브 마이그레이션 및 자동 다시 시작 기능을 포함하여 SAP HANA 시스템의 고가용성을 보장하는 다양한 옵션을 제공합니다. 이러한 기능과 함께 Compute Engine VM의 월간 업타임 비율이 높기 때문에 대기 시스템 비용을 지불하고 유지할 필요가 없습니다.
그러나 필요한 경우 SAP HANA 호스트 자동 장애 조치용 대기 호스트가 포함된 멀티 호스트 수평 확장 시스템을 배포하거나 고가용성 Linux 클러스터에 대기 SAP HANA 인스턴스가 있는 수직 확장 시스템을 배포할 수도 있습니다.
Google Cloud기반 SAP HANA의 고가용성 옵션에 대한 자세한 내용은 SAP HANA 고가용성 계획 가이드를 참고하세요.
SAP HANA HA/DR 제공업체 후크 사용 설정
SUSE는 SAP HANA가 특정 이벤트의 알림을 보낼 수 있게 해주고 장애 감지를 향상시키는 SAP HANA HA/DR 제공업체 후크를 사용 설정할 것을 권장합니다.
SAP HANA HA/DR 제공업체 후크를 사용하려면 SAPHanaSR 후크의 경우 SAP HANA 2.0 SPS 03 이상 버전, SAPHanaSR-angi 후크의 경우 SAP HANA 2.0 SPS 05 이상 버전이 필요합니다.
기본 및 보조 사이트 모두에서 다음 단계를 완료합니다.
루트 또는
SID_LCadm로 수정할global.ini파일을 엽니다.>vi /hana/shared/SID/global/hdb/custom/config/global.iniglobal.ini파일에 다음 정의를 추가합니다.수직 확장
SLES for SAP 15 SP5 이하의 경우:
[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/ execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasr = info
SLES for SAP 15 SP6 이상:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
수평 확장
SLES for SAP 15 SP5 이하의 경우:
[ha_dr_provider_saphanasrmultitarget] provider = SAPHanaSrMultiTarget path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 1 [ha_dr_provider_sustkover] provider = susTkOver path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 2 sustkover_timeout = 30 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasrmultitarget = info ha_dr_sustkover = info
SLES for SAP 15 SP6 이상:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
루트로 다음 명령어를 실행하여
/etc/sudoers.d디렉터리에 커스텀 구성 파일을 만듭니다. 이 새로운 구성 파일을 사용하면srConnectionChanged()후크 메서드가 호출될 때SID_LCadm사용자가 클러스터 노드 속성에 액세스할 수 있습니다.>visudo -f /etc/sudoers.d/SAPHanaSR/etc/sudoers.d/SAPHanaSR파일에 다음 텍스트를 추가합니다.수직 확장
SLES for SAP 15 SP5 이하의 경우:
다음을 바꿉니다.
SITE_A: 기본 SAP HANA 서버의 사이트 이름SITE_B: 보조 SAP HANA 서버의 사이트 이름SID_LC: 소문자를 사용하여 지정한 SID입니다.
crm_mon -A1 | grep site명령어를 루트 사용자로 실행하면 됩니다.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
SLES for SAP 15 SP6 이상:
다음을 바꿉니다.
SITE_A: 기본 SAP HANA 서버의 사이트 이름SITE_B: 보조 SAP HANA 서버의 사이트 이름SID_LC: 소문자를 사용하여 지정한 SID입니다.
crm_mon -A1 | grep site명령어를 루트 사용자로 실행하면 됩니다.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HOOK_HELPER = /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
수평 확장
SLES for SAP 15 SP5 이하의 경우:
SID_LC를 소문자로 표시된 SID로 바꿉니다.SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_* SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_gsh * SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/SAPHanaSR-hookHelper --sid=SID_LC *
SLES for SAP 15 SP6 이상:
다음을 바꿉니다.
SITE_A: 기본 SAP HANA 서버의 사이트 이름SITE_B: 보조 SAP HANA 서버의 사이트 이름SID_LC: 소문자를 사용하여 지정한 SID입니다.
crm_mon -A1 | grep site명령어를 루트 사용자로 실행하면 됩니다.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
/etc/sudoers파일에 다음 텍스트가 포함되어 있는지 확인합니다.SLES for SAP 15 SP3 이상:
@includedir /etc/sudoers.d
최대 SLES for SAP 15 SP2 버전:
#includedir /etc/sudoers.d
이 텍스트에서
#은 문법의 일부이며 줄이 주석임을 의미하는 것은 아닙니다.
Pacemaker를 유지보수 모드로 설정합니다.
>crm configure property maintenance-mode=true변경사항을 적용합니다.
HANA SPS4 이상
SID_LCadm이 기본 및 보조 마스터 SAP HANA 노드 모두에 변경사항을 로드합니다.
>hdbnsutil -reloadHADRProviders다음 옵션 중 하나를 사용하여 기본 사이트의 다운타임을 방지하거나 최소화합니다.
옵션 1
SID_LCadm이 보조 사이트를 다시 시작합니다.
>HDB restart옵션 2
제어된 장애 조치를 기본 사이트에서 보조 사이트로 수행합니다.
HANA SPS3
SID_LCadm이 기본 SAP HANA 및 보조 SAP HANA 시스템을 모두 다시 시작합니다.
>HDB restart유지보수 모드에서 Pacemaker를 설정 해제합니다.
>crm configure property maintenance-mode=falseSAP HANA의 클러스터 구성을 완료한 후 SAPHanaSR Python 후크 문제 해결 및 HANA 인덱스 서버 장애 시 HA 클러스터 인계가 너무 오래 걸림의 설명대로 장애 조치 테스트 중에 후크가 올바르게 작동하는지 확인할 수 있습니다.
재해 복구
SAP HANA 시스템은 SAP HANA 데이터베이스가 소프트웨어 또는 인프라 수준에서 오류가 발생하지 않도록 몇 가지 고가용성 기능을 제공합니다. 이러한 기능 중에는 SAP HANA 시스템 복제 및 SAP HANA 백업 기능이 있으며, 이들 모두 Google Cloud 에서 지원됩니다.
SAP HANA 백업에 대한 자세한 내용은 백업 및 복구를 참조하세요.
시스템 복제에 대한 자세한 내용은 SAP HANA 재해 복구 계획 가이드를 참조하세요.
백업 및 복구
백업은 레코드 시스템(데이터베이스)을 보호하는 데 매우 중요합니다. SAP HANA는 인메모리 데이터베이스이므로 정기적으로 백업을 만들고 적절한 백업 전략을 구현하면 계획되지 않은 서비스 중단이나 인프라 장애로 인한 데이터 손상 또는 데이터 손실 등의 상황에서 SAP HANA 데이터베이스를 복구하는 데 도움이 됩니다. 이를 위해 SAP HANA 시스템은 백업 및 복구 기능을 기본 제공합니다. Cloud Storage와 같은 Google Cloud 서비스를 SAP HANA 백업의 백업 대상으로 사용할 수 있습니다.
백업 및 복구에 직접 Cloud Storage를 사용할 수 있도록 Google Cloud의 SAP용 에이전트의 Backint 기능을 사용 설정할 수도 있습니다.
X4와 같은 Compute Engine 베어메탈 인스턴스에서 실행되는 SAP HANA 시스템에 대한 백업 및 복구 권장사항은 베어메탈 인스턴스의 SAP HANA 백업 및 복구를 참조하세요.
이 문서에서는 개발자가 다음 SAP Service Note와 함께 SAP HANA 백업 및 복구를 잘 알고 있다고 가정합니다.
- 1642148: FAQ: SAP HANA Database Backup & Recovery
- 1821207: Determining required recovery files
- 1869119: Checking backups using
hdbbackupcheck - 1873247: Checking recoverability with
hdbbackupdiag --check - 1651055: Scheduling SAP HANA Database Backups in Linux
백업에 Compute Engine Persistent Disk 볼륨 및 Cloud Storage 사용
SAP HANA 시스템을 배포하기 위해 Google Cloud 에서 제공하는 Terraform 기반 배포 안내를 따랐다면 균형 있는 영구 디스크 볼륨에서 호스팅되는 /hanabackup 디렉터리에 SAP HANA가 설치됩니다.
온라인 데이터베이스 백업을 /hanabackup 디렉터리에 만들려면 SAP HANA Studio, SAP HANA Cockpit, SAP ABAP 트랜잭션 DB13, SAP HANA SQL 문과 같은 표준 SAP 도구를 사용합니다. 마지막으로 SAP HANA 시스템을 복구해야 하는 경우 백업을 다운로드할 수 있는 Cloud Storage 버킷에 업로드하여 완료된 백업을 저장합니다.
Compute Engine을 사용하여 백업 및 디스크 스냅샷 만들기
SAP HANA용 Compute Engine 백업을 사용할 수 있으며 표준 디스크 스냅샷을 사용하여 SAP HANA 데이터 및 로그 볼륨을 호스팅하는 전체 디스크를 백업할 수도 있습니다.
배포 가이드의 안내를 따랐다면 SAP HANA 설치 시 온라인 데이터베이스 백업용 /hanabackup 디렉터리가 생성되어 있습니다. 같은 디렉터리를 사용하여 /hanabackup 볼륨의 스냅샷을 저장하고 SAP HANA 데이터 및 로그 볼륨의 특정 시점 백업을 유지할 수 있습니다.
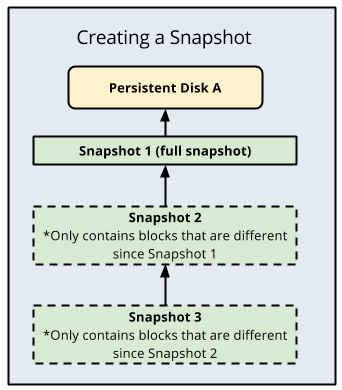
표준 디스크 스냅샷의 장점은 증분식이라는 점입니다. 즉, 각 후속 백업 시 완전히 새로운 백업을 만드는 것이 아니라 증분식 블록 변경사항만 저장합니다. Compute Engine은 데이터 무결성을 보장하는 자동 체크섬을 사용하여 각 스냅샷의 복사본 여러 개를 여러 위치에 저장합니다.
다음 이미지에서는 증분 백업을 보여줍니다.
Cloud Storage를 백업 대상으로 사용
Cloud Storage는 내구성과 데이터 가용성이 뛰어나므로 SAP HANA의 백업 대상으로 사용하기에 알맞습니다.
Cloud Storage는 모든 유형 또는 형식의 파일을 저장할 수 있는 객체 저장소입니다. 스토리지가 거의 무제한이므로 프로비저닝이나 용량 추가를 걱정할 필요가 없습니다. Cloud Storage에서 객체는 파일 데이터와 관련 메타데이터로 구성되며 크기는 최대 5TB까지입니다. Cloud Storage 버킷은 객체를 무제한으로 저장할 수 있습니다.
Cloud Storage를 사용하면 데이터가 여러 위치에 저장되므로 높은 내구성과 고가용성을 얻을 수 있습니다. Cloud Storage에 데이터를 업로드하거나 여기에 있는 데이터를 복사하는 경우 객체 중복이 수행됐을 때만 Cloud Storage가 작업을 성공한 것으로 보고합니다.
다음 표에서는 Cloud Storage에서 제공하는 스토리지 옵션을 보여줍니다.
| 데이터 읽기/쓰기 빈도 | 권장 Cloud Storage 옵션 |
|---|---|
| 빈도가 높은 읽기 또는 쓰기 | 사용 중인 데이터베이스에는 표준 스토리지 클래스를 선택합니다. 백업 파일을 쓰고 읽기 위해 Cloud Storage에 자주 액세스할 수 있기 때문입니다. |
| 빈도가 낮은 읽기 또는 쓰기 | 조직 보관 정책에 따라 유지해야 하는 보관 처리된 백업과 같이 자주 액세스하지 않는 데이터에는 Nearline 또는 Coldline Storage를 선택합니다. Nearline은 1달에 최대 1번 액세스하려는 백업 데이터에 적합하며, Coldline은 기껏해야 1년에 한 번과 같이 액세스 가능성이 매우 낮은 데이터에 적합합니다. |
| 보관 데이터 | 장기 보관 데이터에 대해 Archive Storage를 선택합니다. 오랜 기간 동안 사본을 보관할 필요는 있지만 1년에 두 번 이상 액세스하지 않는 데이터에는 보관 처리가 적합합니다. 예를 들어 규제 기관 요구사항이 충족되도록 장기간 보관해야 하는 백업에는 Archive Storage를 사용합니다. 테이프 기반 백업 솔루션을 Archive로 교체해보세요. |
이러한 스토리지 옵션 사용을 계획할 때는 먼저 자주 액세스하는 계층부터 시작하고 오래 보관할 백업 데이터는 자주 액세스하지 않는 계층에 저장하는 것이 좋습니다. 일반적으로 백업은 시간이 지날수록 거의 사용하지 않기 때문입니다. 3년 지난 백업 데이터가 필요할 가능성은 극히 낮기 때문에 이러한 백업 데이터는 Archive 계층에 저장하여 비용을 절약할 수 있습니다. Cloud Storage 비용에 대한 자세한 내용은 Cloud Storage 가격 책정을 참조하세요.
Cloud Storage와 테이프 백업 비교
전통적인 온프레미스 백업 매체는 테이프입니다. Cloud Storage의 데이터는 여러 시설에 걸쳐 복제되므로 Cloud Storage는 소스 시스템의 '외부 사이트'에 백업을 자동으로 저장하는 기능을 포함하여 테이프보다 많은 이점이 있습니다. 이는 또한 Cloud Storage에 저장된 백업의 가용성이 높다는 것을 의미합니다.
또 다른 주요 차이점은 필요 시 백업을 복원하는 속도입니다. 백업에서 새 SAP HANA 시스템을 만들거나 백업에서 기존 시스템을 복원해야 하는 경우 Cloud Storage는 데이터에 더 빠르게 액세스하여 시스템을 더 빠르게 빌드할 수 있습니다.
SAP용 Google Cloud에이전트의 Backint 기능
SAP용 Google Cloud에이전트의 SAP 인증 Backint 기능을 사용하면 온프레미스 설치와 클라우드 설치 모두의 백업과 복구에 Cloud Storage를 직접 사용할 수 있습니다.
이 기능에 대한 자세한 내용은 SAP HANA용 Backint 기반 백업 및 복구를 참조하세요.
Backint를 사용하여 SAP HANA 백업 및 복구
다음 섹션에서는 SAP용 Google Cloud에이전트의 Backint 기능을 사용하여 SAP HANA를 백업하고 복구하는 방법에 대한 정보를 제공합니다.
데이터 및 델타 백업 트리거
SAP HANA 데이터 볼륨에 대한 백업을 트리거하고 SAP용 Google Cloud에이전트의 Backint 기능을 사용하여 이를 Cloud Storage로 전송하려면 SAP HANA Studio, SAP HANA Cockpit, SAP HANA SQL 또는 DBA Cockpit을 사용하면 됩니다.
다음은 데이터 백업을 트리거하는 SAP HANA SQL 문입니다.
시스템 데이터베이스 전체 백업을 만들려면 다음 명령어를 실행합니다.
BACKUP DATA USING BACKINT ('BACKUP_NAME');BACKUP_NAME을 백업에 설정할 이름으로 바꿉니다.테넌트 데이터베이스 전체 백업을 만들려면 다음 명령어를 실행합니다.
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');TENANT_SID를 테넌트 데이터베이스 SID로 바꿉니다.차등식 및 증분식 백업을 만들려면 다음 안내를 따르세요.
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');만들려는 백업 유형에 따라
BACKUP_TYPE을DIFFERENTIAL또는INCREMENTAL로 바꿉니다.
데이터 백업을 트리거하는 동안 사용할 수 있는 옵션에는 여러 가지가 있습니다. 이러한 옵션에 대한 자세한 내용은 SAP HANA SQL 참조 가이드 BACKUP DATA 문(백업 및 복구)을 참조하세요.
데이터 및 델타 백업에 대한 자세한 내용은 SAP 문서 데이터 백업 및 델타 백업을 참조하세요.
로그 백업 트리거
SAP HANA 로그 볼륨 백업을 트리거하고 SAP용 Google Cloud에이전트의 Backint 기능을 사용하여 Cloud Storage로 전송하려면 다음 단계를 완료합니다.
- 전체 데이터베이스 백업을 만듭니다. 자세한 내용은 SAP HANA 버전의 SAP 문서를 참조하세요.
- SAP HANA
global.ini파일에서catalog_backup_using_backint매개변수를yes로 설정합니다.
SAP HANA 시스템의 로그 모드가 기본값인 normal인지 확인합니다. 로그 모드가 overwrite로 설정되면 SAP HANA 데이터베이스에서 로그 백업 만들기가 중지됩니다.
로그 백업에 대한 자세한 내용은 SAP 문서 로그 백업을 참조하세요.
백업 카탈로그 쿼리
SAP HANA 백업 카탈로그는 백업 및 복구 작업에 중요한 부분입니다. 여기에는 SAP HANA 데이터베이스에 생성된 백업에 대한 정보가 포함됩니다.
테넌트 데이터베이스 백업 정보에 대한 백업 카탈로그를 쿼리하려면 다음 단계를 완료합니다.
- 테넌트 데이터베이스를 오프라인으로 전환합니다.
시스템 데이터베이스에서 다음 SQL 문을 실행합니다.
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
또는 특정 시점을 쿼리하려면 다음 SQL 문을 실행합니다.
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
이 문은
/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID디렉터리에strategyOutput.xml파일을 만듭니다.
BACKUP LIST DATA 문에 대한 자세한 내용은 SAP HANA SQL 참조 가이드 BACKUP DATA 문(백업 및 복구)을 참조하세요.
백업 카탈로그에 대한 자세한 내용은 SAP 문서 백업 카탈로그를 참조하세요.
데이터베이스 복구
멀티 스트리밍 데이터 백업을 사용하여 복구를 수행하면 SAP HANA는 백업을 만들 때 사용했던 채널과 같은 수의 채널을 사용합니다. 자세한 내용은 SAP 문서 기본 요건: 멀티스트리밍 백업을 사용하여 복구를 참조하세요.
SAP용 Google Cloud에이전트의 Backint 기능을 사용하여 만든 SAP HANA 데이터베이스 백업을 복원하기 위해 SAP HANA는 RECOVER DATA 및 RECOVER DATABASE SQL 문을 제공합니다.
recover_bucket 매개변수에 버킷을 지정하지 않는 한, 두 SQL 문은 PARAMETERS.json 파일의 bucket 매개변수에 지정한 Cloud Storage 버킷에서 백업을 복원합니다.
다음은Google Cloud의 SAP용 에이전트의 Backint 기능을 사용하여 만든 백업을 사용하여 SAP HANA 데이터베이스를 복구하기 위한 샘플 SQL 문입니다.
백업 파일 이름을 지정하여 테넌트 데이터베이스를 복구하려면 다음 명령어를 실행합니다.
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;백업 ID를 지정하여 테넌트 데이터베이스를 복구하려면 다음 명령어를 실행합니다.
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
BACKUP_ID를 필요한 백업의 ID로 바꿉니다.Cloud Storage 버킷에 저장된 SAP HANA 백업 카탈로그 백업을 사용해야 하는 경우 백업 ID를 지정하여 테넌트 데이터베이스를 복구하려면 다음 명령어를 실행합니다.
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
테넌트 데이터베이스를 특정 시점이나 특정 로그 위치로 복구하려면 다음 명령어를 실행합니다.
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
외부 데이터베이스에서 백업을 사용하여 테넌트 데이터베이스를 복구하려면 다음 명령어를 실행합니다.
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
다음을 바꿉니다.
SOURCE_TENANT_SID: 소스 테넌트 데이터베이스의 SID입니다.SOURCE_SID: 소스 테넌트 데이터베이스가 있는 SAP 시스템의 SID입니다.
Cloud Storage 버킷에 저장된 백업에서 SAP HANA 백업 카탈로그를 사용할 수 없을 때 SAP HANA 데이터베이스를 복구해야 하는 경우, SAP Note 3227931 - HANA 백업 카탈로그 없이 Backint에서 HANA DB 복구에 제공된 안내를 따르세요.
ID 및 백업 액세스 관리
Cloud Storage 또는 Compute Engine을 사용하여 SAP HANA 데이터를 백업하는 경우 백업에 대한 액세스는 Identity and Access Management(IAM)에서 제어됩니다. 관리자는 이 기능을 사용하여 특정 리소스에서 작업을 수행할 수 있는 권한을 사용자에게 부여할 수 있습니다. IAM은 백업을 포함한 모든Google Cloud 리소스를 관리할 수 있는 중앙 집중식 제어 기능을 제공합니다.
또한 IAM은 권한 승인, 삭제, 위임에 대한 전체 감사 추적 기록을 제공하며 관련 정보가 자동으로 관리자에게 표시됩니다. 따라서 백업 데이터에 대한 액세스를 모니터링하는 정책을 구성하여 데이터에 대한 전체 액세스 제어 주기를 완료할 수 있습니다. IAM을 사용하면 조직 전체에 적용되는 보안 정책의 통합 뷰가 제공되고 기본 제공 감사 기능을 통해 규정 준수 프로세스를 수월하게 진행할 수 있습니다.
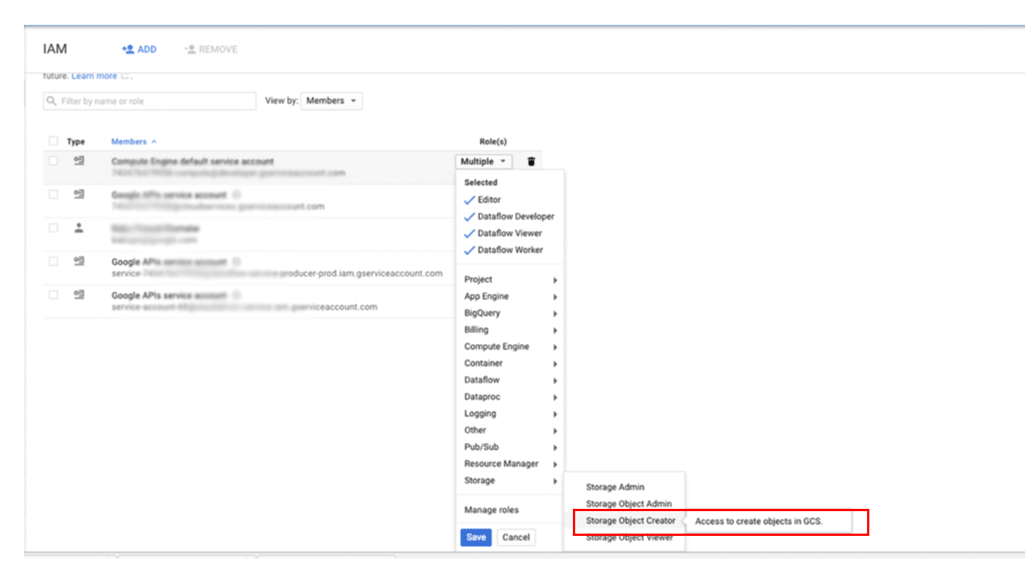
주 구성원에게 Cloud Storage의 백업에 대한 액세스 권한을 부여하려면 다음 안내를 따르세요.
Google Cloud 콘솔에서 IAM 및 관리자 페이지로 이동합니다.
액세스 권한을 부여할 사용자를 지정한 후 스토리지 > 스토리지 객체 생성자 역할을 할당합니다.
SAP HANA용 파일 시스템 기반 백업을 만드는 방법
배포 가이드를 사용하여 Google Cloud 배포된 SAP HANA 시스템은 NFS 마운트 백업 대상으로 사용할 Persistent Disk 또는 Hyperdisk 볼륨 집합으로 구성됩니다. SAP HANA 백업은 먼저 이러한 로컬 디스크에 저장된 후 장기 스토리지용으로 Cloud Storage에 복사되어야 합니다. 백업을 Cloud Storage에 수동으로 복사하거나 crontab에서 Cloud Storage에 사본을 예약할 수 있습니다.
SAP용 Google Cloud에이전트의 Backint 기능을 사용하는 경우 Cloud Storage 버킷에 직접 백업하고 복구하므로 백업용 영구 디스크 스토리지가 필요하지 않습니다.
SAP HANA 데이터 백업을 시작하거나 예약하려면 SAP HANA Studio, SQL 명령어 또는 DBA Cockpit을 사용하면 됩니다. 로그 백업은 사용 중지되지 않으면 자동으로 기록됩니다. 다음 스크린샷은 예시입니다.
SAP HANA global.ini 구성
배포 가이드 안내를 따랐다면 SAP HANA global.ini 구성 파일은 /hanabackup/data/에 저장된 데이터베이스 백업으로 맞춤설정되고 자동 로그 보관 파일은 /hanabackup/log/에 저장됩니다. 다음은 global.ini를 보여주는 예시입니다.
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
SAP용Google Cloud에이전트의 Backint 기능에 대한 global.ini 구성 파일을 맞춤설정하려면 Backint 기능에 대한 SAP HANA 구성을 참고하세요.
수평 확장 배포 참고사항
수평 확장 구현에서 라이브 마이그레이션 및 자동 다시 시작을 사용하는 고가용성 솔루션은 단일 호스트 설정과 동일한 방식으로 작동합니다. 주요 차이점은 /hana/shared 볼륨이 모든 작업자 호스트에 NFS 마운트되고 HANA 마스터에서 마스터된다는 점입니다. 마스터 호스트에서 라이브 마이그레이션 또는 자동 다시 시작이 수행될 때는 NFS 볼륨에 잠시 동안 액세스할 수 없습니다. 마스터 호스트가 다시 시작되면 NFS 볼륨이 곧 모든 호스트에서 다시 작동하기 시작하고 정상 작업이 자동으로 계속합니다.
백업 및 복구 작업 중에 모든 호스트에서 SAP HANA 백업 볼륨 /hanabackup을 사용할 수 있어야 합니다. 사용할 수 없는 경우 /hanabackup이 모든 호스트에 마운트되었는지 확인하고 그렇지 않은 호스트에는 다시 마운트해야 합니다. 백업 세트를 다른 볼륨이나 Cloud Storage에 복사할 경우 마스터 호스트에서 복사를 실행하여 I/O 성능을 향상시키고 네트워크 사용량을 줄입니다. Cloud Storage Fuse를 사용하여 각 호스트에 Cloud Storage 버킷을 마운트하면 백업 및 복구 프로세스를 간소화할 수 있습니다.
수평 확장 성능은 데이터 분산 정도에 비례합니다. 데이터가 더 많이 분산될수록 쿼리 성능이 향상됩니다. 이렇게 하려면 데이터를 잘 알고 데이터가 소비되는 방식을 이해하고 이에 따라 테이블 분산과 파티셔닝을 설계해야 합니다. 자세한 내용은 SAP Note 2081591 - FAQ: SAP HANA Table Distribution을 참조하세요.
Gcloud Python
Gcloud Python은Google Cloud 서비스에 액세스하는 데 사용할 수 있는 관용적인 Python 클라이언트입니다. 이 가이드에서는 SAP HANA 데이터베이스 백업에 Gcloud Python을 사용하여 Cloud Storage와의 백업 및 복원 작업을 수행합니다.
배포 가이드 안내를 따랐다면 Compute Engine 인스턴스에서 Gcloud Python 라이브러리를 사용할 수 있습니다.
이 라이브러리는 오픈소스이며 Cloud Storage 버킷에서 작동하여 백업 데이터를 저장 및 검색할 수 있습니다.
다음 명령어를 실행하면 Cloud Storage 버킷의 객체를 나열할 수 있습니다. 이를 사용하여 사용 가능한 백업을 나열할 수 있습니다.
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
Gcloud Python에 대한 자세한 내용은 스토리지 클라이언트 라이브러리 참조 문서를 확인하세요.
백업 및 복원 예시
다음 섹션에서는 SAP HANA Studio를 사용하여 일반적인 백업 및 복원 태스크에 따를 수 있는 절차를 보여줍니다.
백업 만들기 예시
SAP HANA 백업 편집기에서 Open Backup Wizard(백업 마법사 열기)를 선택합니다.

- 대상 유형으로 File(파일)을 선택합니다. 이렇게 하면 지정된 파일 시스템의 파일에 데이터베이스가 백업됩니다.
- 백업 목적지,
/hanabackup/data/SID, 백업 접두사를 지정합니다.SID를 SAP 시스템의 시스템 ID로 바꿉니다. - 다음을 클릭합니다.
확인 양식에서 Finish(마침)를 클릭하여 백업을 시작합니다.
백업이 시작되면 상태 창에 백업 진행률이 표시됩니다. 백업이 완료될 때까지 기다립니다.
백업이 완료되면 백업 요약에
Finished메시지가 표시됩니다.SAP HANA 시스템에 로그인하고 파일 시스템의 예상 위치에서 백업을 사용할 수 있는지 확인합니다. 예를 들면 다음과 같습니다.
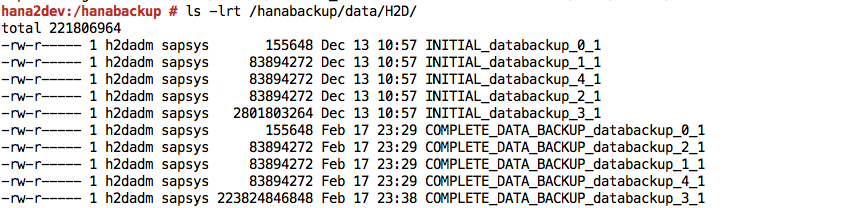

/hanabackup파일 시스템에서 Cloud Storage로 백업 파일을 푸시하거나 동기화합니다. 다음 샘플 Python 스크립트는/hanabackup/data및/hanabackup/log의 데이터를NODE_NAME/DATA또는LOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME형식으로 백업에 사용되는 버킷에 푸시합니다. 이렇게 하면 백업이 복사된 시간을 기준으로 백업 파일을 식별할 수 있습니다. 운영체제 bash 프롬프트에서 이gcloud Python스크립트를 실행합니다.python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOFGcloud Python 라이브러리 또는 Google Cloud 콘솔을 사용하여 백업 데이터를 나열합니다.
백업 복원 예시
백업 파일을
/hanabackup디렉터리에서 사용할 수 없지만 Cloud Storage에서 사용할 수 있는 경우 운영체제 bash 프롬프트에서 다음 스크립트를 실행하여 Cloud Storage에서 파일을 다운로드합니다.python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOFSAP HANA 데이터베이스를 복구하려면 Backup and Recovery(백업 및 복구) > Recover System(시스템 복구)을 클릭합니다.
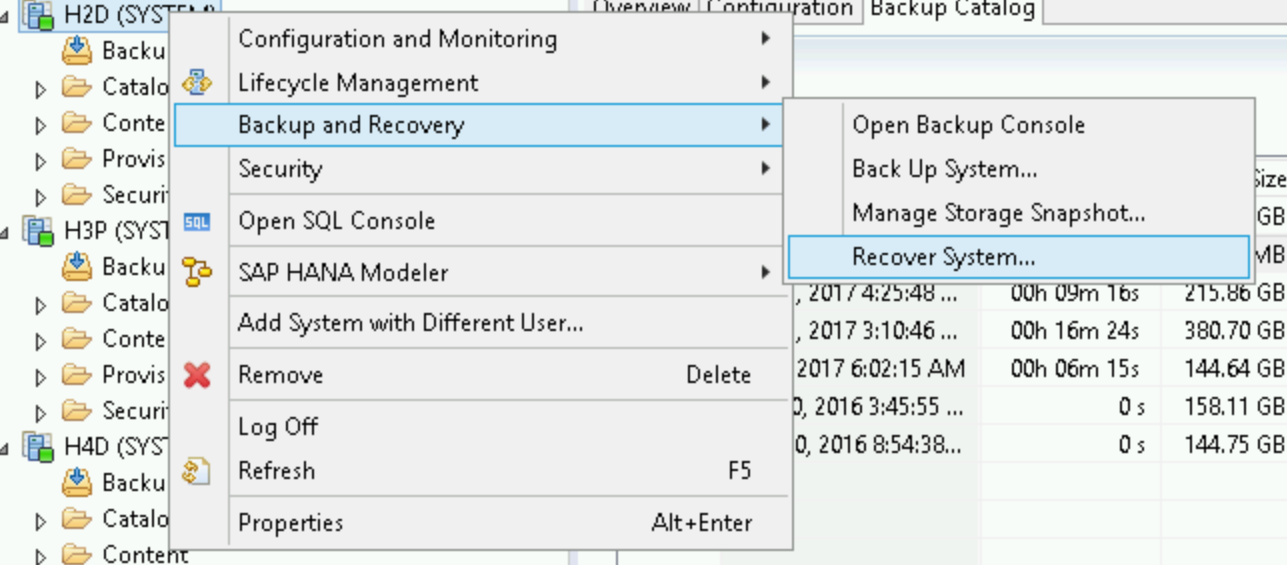
다음을 클릭합니다.
로컬 파일 시스템의 백업 위치를 지정하고 추가를 클릭합니다.
다음을 클릭합니다.
Recover without the backup catalog(백업 카탈로그 없이 복구)를 선택합니다.
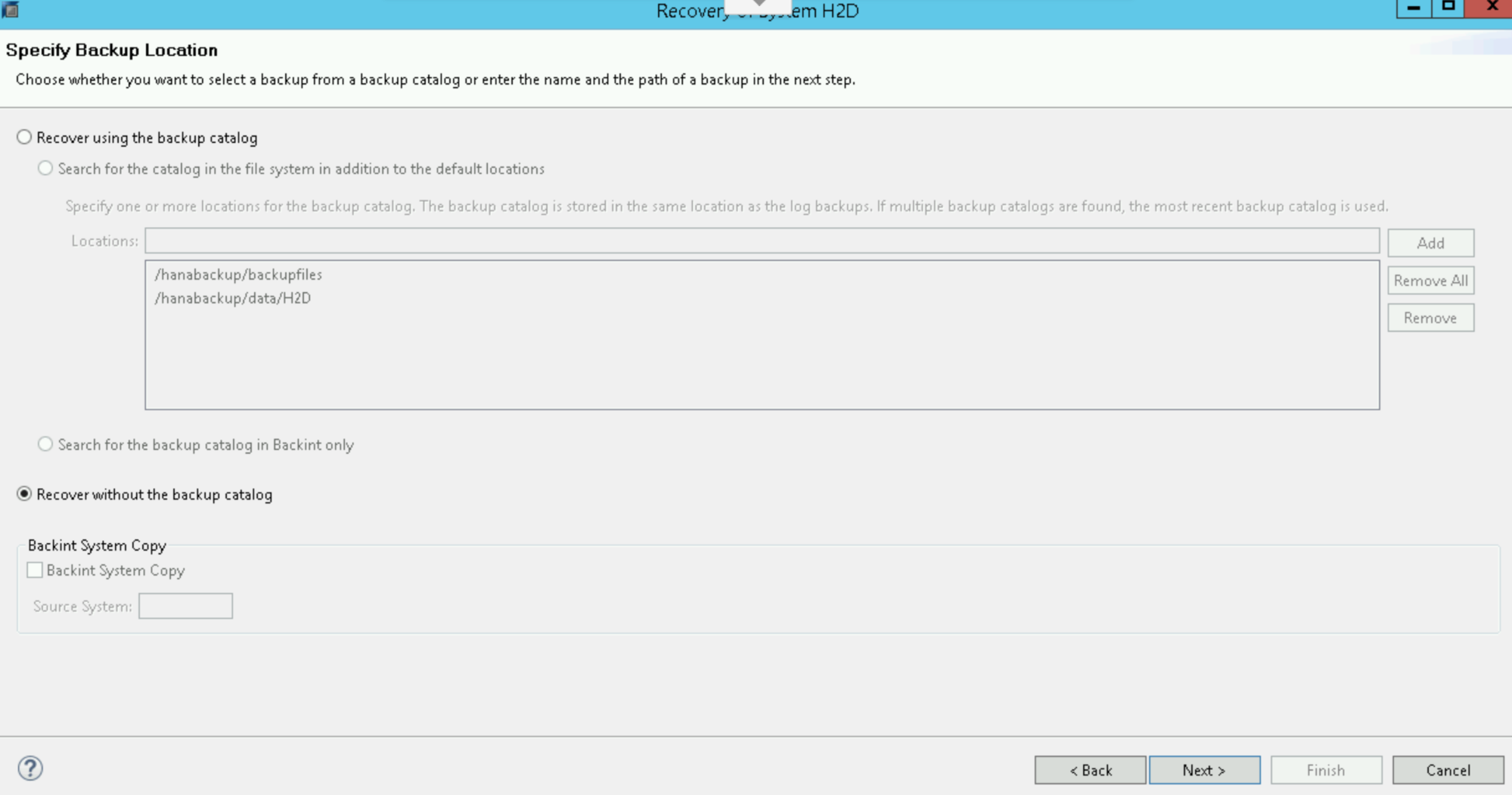
다음을 클릭합니다.
대상 유형으로 파일을 선택한 후 백업 파일 위치와 백업의 올바른 접두사를 지정합니다. 백업 생성 예시 절차를 따랐다면
COMPLETE_DATA_BACKUP는 접두사로 설정되었습니다.다음을 더블클릭합니다.
Finish(마침)를 클릭하여 복구를 시작합니다.
복구가 완료되면 일반 작업을 재개하고
/hanabackup/data/SID/*디렉터리에서 백업 파일을 삭제합니다.
다음 단계
다음의 표준 SAP 문서가 유용할 수 있습니다.
다음 Google Cloud 문서도 유용할 수 있습니다.