Panduan ini memberikan petunjuk untuk mengoperasikan sistem SAP HANA yang di-deploy di Google Cloud dengan mengikuti Terraform: Panduan deployment peningkatan skala SAP HANA. Perhatikan bahwa panduan ini tidak dimaksudkan untuk menggantikan dokumentasi SAP standar apa pun.
Mengelola sistem SAP HANA di Google Cloud
Bagian ini menunjukkan cara melakukan tugas administratif yang biasanya diperlukan untuk mengoperasikan sistem SAP HANA, termasuk informasi tentang cara memulai, menghentikan, dan meng-clone sistem.
Memulai dan menghentikan instance
Anda dapat menghentikan satu atau beberapa host SAP HANA kapan saja; menghentikan sebuah instance akan menonaktifkan instance tersebut. Jika penonaktifan tidak selesai dalam periode penonaktifan, instance akan dihentikan paksa. Untuk menghindari kehilangan data atau sistem file yang rusak, sebaiknya lakukan salah satu atau kedua hal berikut:
Hentikan SAP HANA yang berjalan di instance sebelum menghentikan instance.
Untuk memperpanjang periode penonaktifan instance, aktifkan penonaktifan halus di instance.
Untuk mempelajari cara menghentikan atau memulai ulang instance, lihat Menghentikan atau memulai ulang instance Compute Engine.
Mengubah VM
Anda dapat mengubah berbagai atribut VM, termasuk jenis VM, setelah VM di-deploy. Beberapa perubahan mungkin mengharuskan Anda memulihkan sistem SAP dari cadangan, sedangkan perubahan lainnya hanya mengharuskan Anda memulai ulang VM.
Untuk informasi selengkapnya, baca bagian Mengubah konfigurasi VM untuk sistem SAP.
Membuat snapshot SAP HANA
Untuk membuat cadangan titik waktu tertentu dari persistent disk, Anda dapat membuat snapshot. Compute Engine menyimpan beberapa salinan setiap snapshot secara redundan di beberapa lokasi dengan checksum otomatis untuk memastikan integritas data Anda.
Untuk membuat snapshot, ikuti petunjuk Compute Engine untuk membuat snapshot. Perhatikan langkah-langkah persiapan dengan cermat sebelum membuat snapshot yang konsisten, seperti mengosongkan buffer disk ke disk, untuk memastikan bahwa snapshot konsisten.
Snapshot berguna untuk kasus penggunaan berikut:
| Kasus penggunaan | Detail |
|---|---|
| Memberikan solusi pencadangan data yang mudah, tidak bergantung software, dan hemat biaya. | Mencadangkan data, log, cadangan, dan disk bersama dengan snapshot. Menjadwalkan pencadangan harian dari disk ini untuk cadangan titik waktu tertentu bagi seluruh set data Anda. Setelah snapshot pertama, hanya perubahan blok inkremental yang disimpan dalam snapshot berikutnya. Hal ini membantu menghemat biaya. |
| Bermigrasi ke jenis penyimpanan lain. | Compute Engine menawarkan berbagai jenis persistent disk,
termasuk jenis yang didukung oleh penyimpanan standar (magnetik) dan jenis yang didukung oleh
penyimpanan solid state drive (persistent disk berbasis SSD). Masing-masing memiliki
karakteristik biaya dan performa yang berbeda. Misalnya, gunakan
jenis standar untuk volume cadangan Anda dan gunakan jenis berbasis SSD untuk
volume /hana/log dan /hana/data, karena
keduanya memerlukan performa yang lebih tinggi. Untuk bermigrasi antarjenis penyimpanan, gunakan
snapshot volume, lalu buat volume baru menggunakan snapshot tersebut dan pilih
jenis penyimpanan yang berbeda. |
| Memigrasikan SAP HANA ke region atau zona lain. | Gunakan snapshot untuk memindahkan sistem SAP HANA dari satu zona ke zona lain di region yang sama atau bahkan ke region lain. Snapshot dapat digunakan secara global dalam Google Cloud untuk membuat disk di zona atau region lain. Untuk berpindah ke region atau zona lain, buat snapshot disk Anda, termasuk root disk, lalu buat virtual machine di zona atau region yang Anda inginkan dengan disk yang dibuat dari snapshot tersebut. |
Mengubah setelan disk
Anda dapat mengubah IOPS atau throughput yang disediakan, atau meningkatkan ukuran volume Hyperdisk setiap 4 jam sekali.
Jika Anda mencoba mengubah disk lagi sebelum masa berlaku 4 jam berakhir, Anda akan menerima pesan error batas kapasitas seperti Cannot update provisioned throughput due to being rate limited.
Untuk mengatasi error ini, tunggu selama 4 jam sejak modifikasi terakhir Anda sebelum
mencoba memodifikasi disk lagi.
Gunakan prosedur ini hanya dalam keadaan darurat jika Anda tidak dapat menunggu selama 4 jam untuk menyesuaikan ukuran disk, IOPS yang disediakan, atau throughput volume Hyperdisk.
Untuk mengubah setelan disk, lakukan langkah-langkah berikut:
Hentikan instance SAP HANA Anda dengan menjalankan salah satu perintah berikut:
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
Ganti
INSTANCE_NUMBERdengan nomor instance untuk sistem SAP HANA Anda.Untuk informasi selengkapnya, lihat Memulai dan Menghentikan Sistem SAP HANA.
Buat snapshot atau image disk yang ada:
Pencadangan berbasis snapshot
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONGanti kode berikut:
SNAPSHOT_NAME: nama snapshot yang ingin Anda buat.PROJECT_NAME: nama project Google Cloud Anda.SOURCE_DISK_NAME: disk sumber yang digunakan untuk membuat snapshot.ZONE: zona disk sumber yang akan dioperasikan.LOCATION: Lokasi Cloud Storage, baik regional maupun multi-regional, tempat konten snapshot akan disimpan.Untuk mengetahui informasi selengkapnya, lihat Membuat dan mengelola snapshot disk.
Pencadangan berbasis image
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATIONGanti kode berikut:
IMAGE_NAME: nama disk image yang ingin Anda buat.PROJECT_NAME: nama project Google Cloud Anda.SOURCE_DISK_NAME: disk sumber yang digunakan untuk membuat image.ZONE: zona disk sumber yang akan dioperasikan.LOCATION: Lokasi Cloud Storage, baik regional maupun multi-regional, tempat konten gambar akan disimpan.Untuk mengetahui informasi selengkapnya, lihat Membuat image kustom.
Buat disk baru dari snapshot atau image.
Untuk volume Hyperdisk, pastikan untuk menentukan ukuran disk, IOPS, dan throughput untuk memenuhi persyaratan workload Anda. Untuk mengetahui informasi selengkapnya tentang penyediaan IOPS dan throughput untuk Hyperdisk, lihat Tentang performa yang disediakan untuk Hyperdisk.
Dari snapshot
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTGanti kode berikut:
NEW_DISK_NAME: nama disk yang ingin Anda buat.PROJECT_NAME: nama project Google Cloud Anda.DISK_TYPE: jenis disk yang akan dibuat.DISK_SIZE: ukuran disk.ZONE: zona disk yang akan dibuat.SOURCE_SNAPSHOT: snapshot sumber yang digunakan untuk membuat disk.IOPS: IOPS yang disediakan dari disk yang akan dibuat.THROUGHPUT: throughput disk yang disediakan untuk dibuat.
Dari gambar
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUTGanti kode berikut:
NEW_DISK_NAME: nama disk yang ingin Anda buat.PROJECT_NAME: nama project Google Cloud Anda.DISK_TYPE: jenis disk yang akan dibuat.DISK_SIZE: ukuran disk.ZONE: zona disk yang akan dibuat.SOURE_IMAGE_NAME: image sumber yang akan diterapkan ke disk yang sedang dibuat.IMAGE_PROJECT_NAME: Google Cloud project yang akan digunakan untuk me-resolve semua referensi image dan kelompok image.IOPS: IOPS yang disediakan dari disk yang akan dibuat.THROUGHPUT: throughput disk yang disediakan untuk dibuat.
Untuk informasi selengkapnya, lihat
gcloud compute disks create.Lepaskan disk yang ada dari sistem SAP HANA Anda:
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEGanti kode berikut:
INSTANCE_NAME: nama instance yang akan dioperasikan.OLD_DISK_NAME: disk yang akan dilepas berdasarkan nama resource-nya.ZONE: zona instance yang akan dioperasikan.PROJECT_NAME: nama project Google Cloud Anda.
Untuk informasi selengkapnya, lihat
gcloud compute instances detach-disk.Pasang disk baru ke sistem SAP HANA Anda:
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEGanti kode berikut:
INSTANCE_NAME: nama instance yang akan dioperasikan.NEW_DISK_NAME: nama disk yang akan dilampirkan ke instance.ZONE: zona instance yang akan dioperasikan.PROJECT_NAME: nama project Google Cloud Anda.
Untuk informasi selengkapnya, lihat
gcloud compute instances attach-disk.Validasi apakah titik pemasangan terpasang dengan benar:
lsblkAnda akan melihat output yang mirip dengan berikut ini:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/logMulai instance SAP HANA Anda dengan menjalankan salah satu perintah berikut:
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
Ganti
INSTANCE_NUMBERdengan nomor instance untuk sistem SAP HANA Anda.Untuk informasi selengkapnya, lihat Memulai dan Menghentikan Sistem SAP HANA.
Validasi ukuran disk, IOPS, dan throughput volume Hyperdisk baru Anda:
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAMEGanti kode berikut:
DISK_NAME: nama disk yang akan dideskripsikan.ZONE: zona disk yang akan dijelaskan.PROJECT_NAME: nama project Google Cloud Anda.
Untuk informasi selengkapnya, lihat
gcloud compute disks describe.
Meng-clone sistem SAP HANA
Anda dapat membuat snapshot sistem SAP HANA yang ada di Google Cloud untuk membuat clone sistem secara persis.
Untuk meng-clone sistem SAP HANA host tunggal:
Buat snapshot data dan disk cadangan Anda.
Buat disk baru menggunakan snapshot.
Di konsol Google Cloud , buka halaman VM Instances.
Klik instance yang akan di-clone untuk membuka halaman detail instance, lalu klik Clone.
Pasang disk yang dibuat dari snapshot.
Untuk meng-clone sistem SAP HANA multi-host:
Sediakan sistem SAP HANA baru dengan konfigurasi yang sama dengan sistem SAP HANA yang ingin Anda clone.
Lakukan pencadangan data dari sistem asli.
Pulihkan cadangan sistem asli ke sistem baru.
Menginstal dan memperbarui gcloud CLI
Setelah VM di-deploy untuk SAP HANA dan sistem operasi diinstal, Google Cloud CLI versi terbaru diperlukan untuk berbagai tujuan, seperti mentransfer file ke dan dari Cloud Storage, berinteraksi dengan layanan jaringan, dan seterusnya.
Jika Anda mengikuti petunjuk dalam panduan deployment SAP HANA, gcloud CLI akan otomatis diinstal untuk Anda.
Namun, jika Anda menggunakan sistem operasi Anda sendiri ke Google Cloud sebagai image kustom atau menggunakan image publik lama yang disediakan oleh Google Cloud, Anda mungkin perlu menginstal atau memperbarui gcloud CLI sendiri.
Untuk memeriksa apakah gcloud CLI sudah diinstal dan apakah update tersedia, buka terminal atau command prompt, lalu masukkan:
gcloud version
Jika perintah tidak dikenali, gcloud CLI tidak diinstal.
Untuk menginstal gcloud CLI, ikuti petunjuk di bagian Menginstal gcloud CLI.
Untuk mengganti gcloud CLI versi 140 atau yang lebih lama yang terintegrasi dengan SLES:
Login ke VM dengan menggunakan
ssh.Beralih ke super user:
sudo suMasukkan perintah berikut:
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
Mengaktifkan Mulai Ulang Cepat SAP HANA
Google Cloud sangat merekomendasikan pengaktifan Mulai Ulang Cepat SAP HANA untuk setiap instance SAP HANA, terutama untuk instance yang lebih besar. Mulai Ulang Cepat SAP HANA mengurangi waktu mulai ulang jika SAP HANA dihentikan, tetapi sistem operasi tetap berjalan.
Seperti yang dikonfigurasi oleh skrip otomatisasi yang disediakan Google Cloud ,
setelan sistem operasi dan kernel sudah mendukung Mulai Ulang Cepat SAP HANA.
Anda perlu menentukan sistem file tmpfs dan mengonfigurasi SAP HANA.
Untuk menentukan sistem file tmpfs dan mengonfigurasi SAP HANA, Anda dapat mengikuti
langkah-langkah manual atau menggunakan skrip otomatisasi yang
Google Cloud sediakan untuk mengaktifkan Mulai Ulang Cepat SAP HANA. Untuk mengetahui informasi selengkapnya, lihat:
- Langkah manual: Mengaktifkan Mulai Ulang Cepat SAP HANA
- Langkah otomatis: Mengaktifkan Mulai Ulang Cepat SAP HANA
Untuk mengetahui petunjuk otoritatif lengkap terkait Mulai Ulang Cepat SAP HANA, lihat dokumentasi Opsi Mulai Ulang Cepat SAP HANA.
Langkah manual
Mengonfigurasi sistem file tmpfs
Setelah VM host dan sistem SAP HANA dasar berhasil di-deploy, Anda harus membuat dan memasang direktori untuk node NUMA di sistem file tmpfs.
Menampilkan topologi NUMA VM Anda
Sebelum dapat memetakan sistem file tmpfs yang diperlukan, Anda perlu mengetahui jumlah node NUMA yang dimiliki VM Anda. Untuk menampilkan node NUMA yang tersedia di VM Compute Engine, masukkan perintah berikut:
lscpu | grep NUMA
Misalnya, jenis VM m2-ultramem-208 memiliki empat node NUMA bernomor 0-3, seperti yang ditunjukkan pada contoh berikut:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
Membuat direktori node NUMA
Buat direktori untuk setiap node NUMA di VM Anda dan tetapkan izinnya.
Misalnya, untuk empat node NUMA yang bernomor 0-3:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDInstal direktori node NUMA ke tmpfs
Instal direktori sistem file tmpfs dan tentukan preferensi node NUMA untuk setiap direktori dengan mpol=prefer:
SID menentukan SID dengan huruf besar.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
Update /etc/fstab
Untuk memastikan direktori pemasangan tersedia setelah sistem operasi dimulai ulang, tambahkan entri ke tabel sistem file, /etc/fstab:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
Opsional: menetapkan batas penggunaan memori
Sistem file tmpfs dapat bertambah dan mengecil secara dinamis.
Untuk membatasi memori yang digunakan oleh sistem file tmpfs, Anda dapat menetapkan batas ukuran untuk volume node NUMA dengan opsi size.
Contoh:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
Anda juga dapat membatasi penggunaan memori tmpfs secara keseluruhan untuk semua node NUMA untuk instance SAP HANA tertentu dan node server tertentu, dengan menetapkan parameter persistent_memory_global_allocation_limit di bagian [memorymanager] dari file global.ini.
Mengonfigurasi SAP HANA untuk Mulai Ulang Cepat
Guna mengonfigurasi SAP HANA untuk Fast Restart, update file global.ini dan tentukan tabel yang akan disimpan dalam memori persisten.
Perbarui bagian [persistence] dalam file global.ini
Konfigurasi bagian [persistence] di file global.ini SAP HANA untuk mereferensikan lokasi tmpfs. Pisahkan setiap lokasi tmpfs dengan titik koma:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
Contoh sebelumnya menentukan empat volume memori untuk empat node NUMA, yang sesuai dengan m2-ultramem-208. Jika menjalankan m2-ultramem-416, Anda perlu mengonfigurasi delapan volume memori (0..7).
Mulai ulang SAP HANA setelah mengubah file global.ini.
SAP HANA kini dapat menggunakan lokasi tmpfs sebagai ruang memori persisten.
SAP HANA kini dapat menggunakan lokasi sebagai ruang memori persisten.
Menentukan tabel atau partisi kolom tertentu yang akan disimpan di memori persisten.
Misalnya, untuk mengaktifkan memori persisten pada tabel yang sudah ada, jalankan kueri SQL:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Guna mengubah default untuk tabel baru, tambahkan parameter table_default dalam file indexserver.ini. Contoh:
[persistent_memory] table_default = ON
Untuk informasi selengkapnya tentang cara mengontrol kolom, tabel, dan tampilan pemantauan mana yang memberikan informasi mendetail, lihat Memori Persisten SAP HANA.
Langkah otomatis
Skrip otomatisasi yang disediakan Google Cloud untuk mengaktifkan
Mulai Ulang Cepat SAP HANA
akan membuat perubahan pada direktori /hana/tmpfs*, file /etc/fstab, dan
konfigurasi SAP HANA. Saat menjalankan skrip, Anda mungkin perlu melakukan langkah tambahan, bergantung pada apakah ini adalah deployment awal sistem SAP HANA atau Anda mengubah ukuran mesin ke ukuran NUMA yang berbeda.
Untuk deployment awal sistem SAP HANA atau mengubah ukuran mesin guna meningkatkan jumlah node NUMA, pastikan SAP HANA berjalan selama eksekusi skrip otomatisasi yang disediakan Google Clouduntuk mengaktifkan Mulai Ulang Cepat SAP HANA.
Jika Anda mengubah ukuran mesin untuk mengurangi jumlah node NUMA, pastikan SAP HANA dihentikan selama eksekusi skrip otomatisasi yang disediakan Google Cloud untuk mengaktifkan Mulai Ulang Cepat SAP HANA. Setelah skrip dijalankan, Anda harus memperbarui konfigurasi SAP HANA secara manual untuk menyelesaikan penyiapan Mulai Ulang Cepat SAP HANA. Untuk mengetahui informasi selengkapnya, lihat Konfigurasi SAP HANA untuk Mulai Ulang Cepat.
Untuk mengaktifkan Mulai Ulang Cepat SAP HANA, ikuti langkah-langkah berikut:
Buat koneksi SSH dengan VM host Anda.
Beralih ke root:
sudo su -
Download skrip
sap_lib_hdbfr.sh:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Setel agar file dapat dieksekusi:
chmod +x sap_lib_hdbfr.sh
Pastikan bahwa skrip tidak memiliki error:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Jika perintah menampilkan error, hubungi Cloud Customer Care. Untuk mengetahui informasi selengkapnya tentang cara menghubungi Layanan Pelanggan, lihat Mendapatkan dukungan untuk SAP di Google Cloud.
Jalankan skrip setelah mengganti ID sistem (SID) dan sandi SAP HANA untuk pengguna SISTEM dari database SAP HANA. Untuk memberikan sandi dengan aman, sebaiknya gunakan secret di Secret Manager.
Jalankan skrip menggunakan nama secret di Secret Manager. Secret ini harus ada di project Google Cloud yang berisi instance VM host Anda.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Ganti kode berikut:
SID: menentukan SID dengan huruf besar. Contoh,AHA.SECRET_NAME: menentukan nama secret yang sesuai dengan sandi untuk pengguna SISTEM dari database SAP HANA. Secret ini harus ada di project Google Cloud yang berisi instance VM host Anda.
Atau, Anda dapat menjalankan skrip menggunakan sandi teks biasa. Setelah Mulai Ulang Cepat SAP HANA diaktifkan, pastikan untuk mengubah sandi Anda. Sebaiknya jangan gunakan sandi teks biasa karena sandi Anda akan dicatat dalam histori command line VM Anda.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Ganti kode berikut:
SID: menentukan SID dengan huruf besar. Contoh,AHA.PASSWORD: menentukan sandi untuk pengguna SISTEM dari database SAP HANA.
Agar operasi awal berhasil, Anda akan melihat output yang mirip dengan berikut ini:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
Menyiapkan saluran dukungan SAP dengan SAProuter
Jika perlu mengizinkan engineer dukungan SAP mengakses sistem SAP HANA di Google Cloud, Anda dapat melakukannya menggunakan SAProuter. Ikuti langkah-langkah berikut:
Luncurkan instance VM Compute Engine tempat software SAProuter akan diinstal, dan tetapkan alamat IP eksternal sehingga instance memiliki akses internet.
Buat alamat IP eksternal statis yang baru, lalu tetapkan alamat IP ini ke instance.
Buat dan konfigurasi aturan firewall SAProuter tertentu di jaringan Anda. Dalam aturan ini, hanya izinkan akses masuk dan keluar yang diperlukan ke jaringan dukungan SAP, untuk instance SAProuter.
Batasi akses masuk dan keluar ke alamat IP tertentu yang disediakan oleh SAP agar Anda dapat terhubung, bersama dengan port TCP
3299. Tambahkan tag target ke aturan firewall dan masukkan nama instance Anda. Hal ini memastikan bahwa aturan firewall hanya berlaku untuk instance baru. Lihat dokumentasi aturan firewall untuk detail tambahan tentang cara membuat dan mengonfigurasi aturan firewall.Instal software SAProuter, dengan mengikuti Catatan SAP 1628296, dan buat file
saprouttabyang mengizinkan akses dari SAP ke sistem SAP HANA Anda di Google Cloud.Siapkan koneksi dengan SAP. Untuk koneksi internet, gunakan Komunikasi Jaringan Aman. Untuk mengetahui informasi selengkapnya, lihat Dukungan Jarak Jauh SAP – Bantuan.
Mengonfigurasi jaringan Anda
Anda menyediakan sistem SAP HANA menggunakan VM dengan jaringan virtualGoogle Cloud . Google Cloud menggunakan teknologi software-defined networking dan sistem terdistribusi yang canggih untuk menghosting dan memberikan layanan Anda di seluruh dunia.
Untuk SAP HANA, buat jaringan subnet non-default dengan rentang alamat IP CIDR yang tidak tumpang-tindih untuk setiap subnetwork di jaringan. Perhatikan bahwa setiap subnetwork dan rentang alamat IP internalnya dipetakan ke satu region.
Subnetwork menjangkau semua zona di region tempatnya dibuat.
Namun, saat membuat instance VM, Anda akan menentukan zona dan subnetwork untuk
VM. Misalnya, Anda dapat membuat satu kumpulan instance di subnetwork1 dan di
zone1 dari region1 serta kumpulan instance lainnya di subnetwork2 dan di
zone2 dari region1, tergantung kebutuhan Anda.
Jaringan baru tidak memiliki aturan firewall sehingga tidak memiliki akses jaringan. Anda harus membuat aturan firewall yang membuka akses ke instance SAP HANA berdasarkan model hak istimewa minimum. Aturan firewall berlaku untuk seluruh jaringan dan juga dapat dikonfigurasi untuk diterapkan ke instance target tertentu menggunakan mekanisme pemberian tag.
Rute adalah resource global, bukan regional, yang terhubung ke satu jaringan. Rute yang dibuat pengguna berlaku untuk semua instance di jaringan. Artinya, Anda dapat menambahkan rute yang meneruskan traffic dari instance ke instance dalam jaringan yang sama, bahkan di seluruh subnetwork, tanpa memerlukan alamat IP eksternal.
Untuk instance SAP HANA, luncurkan instance tanpa alamat IP eksternal dan konfigurasi VM lain sebagai gateway NAT untuk akses eksternal. Konfigurasi ini mengharuskan Anda untuk menambahkan gateway NAT sebagai rute untuk instance SAP HANA. Prosedur ini dijelaskan dalam panduan deployment.
Keamanan
Bagian berikut membahas operasi keamanan.
Model hak istimewa minimum
Baris pertahanan pertama Anda adalah membatasi siapa yang dapat menjangkau instance menggunakan firewall. Dengan membuat aturan firewall, Anda dapat membatasi semua traffic ke jaringan atau mesin target pada sekumpulan port tertentu ke alamat IP sumber tertentu. Anda harus mengikuti model hak istimewa minimum untuk membatasi akses ke alamat IP, protokol, dan port tertentu yang memerlukan akses. Misalnya, Anda harus selalu menyiapkan bastion host, dan mengizinkan SSH ke sistem SAP HANA Anda hanya dari host tersebut.
Perubahan konfigurasi
Anda harus mengonfigurasi sistem SAP HANA dan sistem operasi dengan setelan keamanan yang direkomendasikan. Misalnya, pastikan hanya port jaringan yang relevan yang dicantumkan untuk mengizinkan akses, memperkuat sistem operasi yang menjalankan SAP HANA, dan seterusnya.
Lihat catatan SAP berikut (akun pengguna SAP diperlukan):
- 1944799: Panduan penginstalan SLES SAP HANA
- 1730999: Perubahan konfigurasi yang direkomendasikan
- 1731000: Perubahan konfigurasi yang tidak direkomendasikan
Menonaktifkan Layanan SAP HANA yang tidak dibutuhkan
Jika Anda tidak memerlukan SAP HANA Extended Application Services (SAP HANA XS), nonaktifkan layanan tersebut. Lihat catatan SAP 1697613: Menghapus layanan SAP HANA XS Classic Engine dari topologi.
Setelah layanan dinonaktifkan, hapus semua port TCP yang dibuka untuk layanan tersebut. Di Google Cloud, hal ini berarti mengedit aturan firewall untuk jaringan Anda guna menghapus port ini dari daftar akses.
Logging audit
Cloud Audit Logs terdiri dari dua aliran log, yaitu aktivitas admin dan akses data, yang keduanya dihasilkan secara otomatis oleh Google Cloud. Ini dapat membantu Anda menjawab pertanyaan, "Siapa yang melakukan apa, di mana, dan kapan?" dalam projectGoogle Cloud Anda.
Log aktivitas admin berisi entri log untuk panggilan API atau tindakan administratif yang mengubah konfigurasi atau metadata layanan atau project. Log ini selalu diaktifkan dan dapat dilihat oleh semua anggota project.
Log akses data berisi entri log untuk panggilan API yang membuat, mengubah, atau membaca data yang disediakan pengguna yang dikelola oleh layanan, seperti data yang disimpan dalam layanan database. Jenis logging ini diaktifkan secara default di project Anda dan dapat Anda akses melalui Cloud Logging atau feed aktivitas Anda.
Mengamankan bucket Cloud Storage
Jika menggunakan Cloud Storage untuk menghosting cadangan untuk data dan log, pastikan Anda menggunakan TLS (HTTPS) saat mengirim data ke Cloud Storage dari instance untuk melindungi data dalam pengiriman. Cloud Storage secara otomatis mengenkripsi data dalam penyimpanan. Anda dapat menentukan kunci enkripsi sendiri jika memiliki sistem pengelolaan kunci Anda sendiri.
Dokumen keamanan terkait
Lihat referensi keamanan tambahan berikut untuk lingkungan SAP HANA Anda di Google Cloud:
- Pusat keamanan
- Kepatuhan di Google Cloud
- Laporan resmi keamanan Google Cloud
- Desain keamanan infrastruktur Google
Ketersediaan tinggi untuk SAP HANA di Google Cloud
Google Cloud menyediakan berbagai opsi untuk memastikan ketersediaan tinggi untuk sistem SAP HANA Anda, termasuk migrasi langsung Compute Engine dan fitur mulai ulang otomatis. Fitur ini, beserta persentase waktu beroperasi bulanan yang tinggi dari VM Compute Engine, dapat membuat Anda tidak perlu membayar dan memelihara sistem standby.
Namun, jika diperlukan, Anda dapat men-deploy sistem penyebaran skala multi-host yang menyertakan host standby untuk Failover Otomatis Host SAP HANA, atau Anda dapat men-deploy sistem peningkatan skala dengan instance SAP HANA standby di cluster Linux dengan ketersediaan tinggi.
Untuk mengetahui informasi selengkapnya tentang opsi ketersediaan tinggi untuk SAP HANA diGoogle Cloud, lihat panduan perencanaan ketersediaan tinggi SAP HANA.
Mengaktifkan hook penyedia HA/DR SAP HANA
SUSE merekomendasikan
agar Anda mengaktifkan hook penyedia HA/DR SAP HANA, yang memungkinkan
SAP HANA mengirimkan notifikasi untuk peristiwa tertentu dan meningkatkan deteksi
kegagalan.
Hook penyedia SAP HANA HA/DR
memerlukan SAP HANA 2.0 SPS 03 atau versi yang lebih baru untuk hook SAPHanaSR, dan SAP
HANA 2.0 SPS 05 atau versi yang lebih baru untuk hook SAPHanaSR-angi.
Di situs utama dan sekunder, selesaikan langkah-langkah berikut:
Sebagai root atau
SID_LCadm, buka fileglobal.iniuntuk mengedit:>vi /hana/shared/SID/global/hdb/custom/config/global.iniTambahkan definisi berikut ke file
global.ini:Peningkatan skala
Untuk SLES untuk SAP 15 SP5 atau yang lebih lama:
[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR/ execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasr = info
Untuk SLES untuk SAP 15 SP6 atau yang lebih baru:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
penyebaran skala
Untuk SLES untuk SAP 15 SP5 atau yang lebih lama:
[ha_dr_provider_saphanasrmultitarget] provider = SAPHanaSrMultiTarget path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 1 [ha_dr_provider_sustkover] provider = susTkOver path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 2 sustkover_timeout = 30 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-ScaleOut/ execution_order = 3 action_on_lost = stop [trace] ha_dr_saphanasrmultitarget = info ha_dr_sustkover = info
Untuk SLES untuk SAP 15 SP6 atau yang lebih baru:
[ha_dr_provider_susHanaSR] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = stop [ha_dr_provider_susTkOver] provider = susTkOver path = /usr/share/SAPHanaSR-angi execution_order = 1 sustkover_timeout = 30 [trace] ha_dr_sushanasr = info ha_dr_suschksrv = info ha_dr_sustkover = info
Sebagai root, buat file konfigurasi kustom di direktori
/etc/sudoers.ddengan menjalankan perintah berikut. File konfigurasi baru ini memungkinkan penggunaSID_LCadmmengakses atribut node cluster saat metode hooksrConnectionChanged()dipanggil.>visudo -f /etc/sudoers.d/SAPHanaSRDi file
/etc/sudoers.d/SAPHanaSR, tambahkan teks berikut:Peningkatan skala
Untuk SLES untuk SAP 15 SP5 atau yang lebih lama:
Ganti kode berikut:
SITE_A: nama situs server SAP HANA utamaSITE_B: nama situs server SAP HANA sekunderSID_LC: SID, yang ditentukan menggunakan huruf kecil
crm_mon -A1 | grep sitesebagai pengguna root, di server utama SAP HANA atau server sekunder.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Untuk SLES untuk SAP 15 SP6 atau yang lebih baru:
Ganti kode berikut:
SITE_A: nama situs server SAP HANA utamaSITE_B: nama situs server SAP HANA sekunderSID_LC: SID, yang ditentukan menggunakan huruf kecil
crm_mon -A1 | grep sitesebagai pengguna root, di server utama SAP HANA atau server sekunder.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HOOK_HELPER = /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
penyebaran skala
Untuk SLES untuk SAP 15 SP5 atau yang lebih lama:
Ganti
SID_LCdengan SID dengan format huruf kecil.SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_* SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_SID_LC_gsh * SID_LCadm ALL=(ALL) NOPASSWD: /usr/sbin/SAPHanaSR-hookHelper --sid=SID_LC *
Untuk SLES untuk SAP 15 SP6 atau yang lebih baru:
Ganti kode berikut:
SITE_A: nama situs server SAP HANA utamaSITE_B: nama situs server SAP HANA sekunderSID_LC: SID, yang ditentukan menggunakan huruf kecil
crm_mon -A1 | grep sitesebagai pengguna root, di server utama SAP HANA atau server sekunder.Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_A -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_SID_LC_site_srHook_SITE_B -v SFAIL -t crm_config -s SAPHanaSR SID_LCadm ALL=(ALL) NOPASSWD: /usr/bin/SAPHanaSR-hookHelper --sid=SID --case=* SID_LCadm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB
Di file
/etc/sudoersAnda, pastikan teks berikut disertakan:Untuk SLES untuk SAP 15 SP3 atau yang lebih baru:
@includedir /etc/sudoers.d
Untuk versi hingga SLES untuk SAP 15 SP2:
#includedir /etc/sudoers.d
Perhatikan bahwa
#dalam teks ini adalah bagian dari sintaksis dan bukan berarti baris tersebut merupakan komentar.
Setel Pacemaker ke dalam mode pemeliharaan:
>crm configure property maintenance-mode=trueTerapkan perubahan:
HANA SPS4 dan yang lebih baru
Sebagai SID_LCadm, muat perubahan pada node SAP HANA master utama dan sekunder.
>hdbnsutil -reloadHADRProvidersGunakan salah satu opsi berikut untuk menghindari atau meminimalkan periode nonaktif situs utama Anda:
Opsi 1
Setelah SID_LCadm memulai ulang situs sekunder.
>HDB restartOpsi 2
Melakukan failover terkontrol dari utama ke sekunder
HANA SPS3
Setelah SID_LCadm memulai ulang sistem SAP HANA utama dan sekunder:
>HDB restartBatalkan setelan Pacemaker dari mode pemeliharaan:
>crm configure property maintenance-mode=falseSetelah menyelesaikan konfigurasi cluster untuk SAP HANA, Anda dapat memverifikasi bahwa hook berfungsi dengan benar selama pengujian failover seperti yang dijelaskan dalam Memecahkan masalah hook python SAPHanaSR dan pengambilalihan cluster HA membutuhkan waktu terlalu lama saat kegagalan server indeks HANA.
Pemulihan dari bencana
Sistem SAP HANA menyediakan beberapa fitur ketersediaan tinggi untuk memastikan database SAP HANA dapat menahan kegagalan di tingkat software atau infrastruktur. Di antara fitur tersebut adalah replikasi Sistem SAP HANA dan cadangan SAP HANA, yang keduanya didukung oleh Google Cloud .
Untuk informasi selengkapnya tentang cadangan SAP HANA, lihat Pencadangan dan pemulihan.
Untuk mengetahui informasi lebih lanjut tentang replikasi sistem, lihat panduan perencanaan pemulihan dari bencana SAP HANA.
Pencadangan dan pemulihan
Cadangan sangat penting untuk melindungi sistem kumpulan data (database) Anda. Karena SAP HANA adalah database dalam memori, membuat cadangan secara rutin dan menerapkan strategi pencadangan yang tepat akan membantu Anda memulihkan database SAP HANA dalam situasi seperti kerusakan data atau kehilangan data karena pemadaman atau kegagalan yang tidak terencana dalam infrastruktur Anda. Sistem SAP HANA menyediakan fitur pencadangan dan pemulihan bawaan untuk membantu Anda melakukan hal ini. Anda dapat menggunakan layanan Google Cloudseperti Cloud Storage sebagai tujuan pencadangan untuk pencadangan SAP HANA.
Anda juga dapat mengaktifkan fitur Backint Agen Google Clouduntuk SAP sehingga dapat menggunakan Cloud Storage secara langsung untuk pencadangan dan pemulihan.
Untuk mengetahui informasi tentang rekomendasi pencadangan dan pemulihan untuk sistem SAP HANA yang berjalan di instance bare metal Compute Engine seperti X4, lihat Pencadangan dan pemulihan untuk SAP HANA di instance bare metal.
Dokumen ini mengasumsikan bahwa Anda sudah memahami pencadangan dan pemulihan SAP HANA, beserta Catatan layanan SAP berikut:
- 1642148: FAQ: Pencadangan & Pemulihan Database SAP HANA
- 1821207: Menentukan file pemulihan yang diperlukan
- 1869119: Memeriksa cadangan menggunakan
hdbbackupcheck - 1873247: Memeriksa kemampuan pemulihan dengan
hdbbackupdiag --check - 1651055: Menjadwalkan Pencadangan Database SAP HANA di Linux
Menggunakan volume Persistent Disk Compute Engine dan Cloud Storage untuk pencadangan
Jika Anda mengikuti
petunjuk deployment
berbasis Terraform yang disediakan oleh Google Cloud untuk men-deploy sistem SAP HANA,
Anda akan memiliki penginstalan SAP HANA dengan direktori /hanabackup yang dihosting di
volume Balanced Persistent Disk.
Untuk membuat cadangan database online ke direktori /hanabackup, Anda menggunakan
alat SAP standar seperti SAP HANA Studio, SAP HANA Cockpit, transaksi SAP ABAP
DB13, atau pernyataan SQL SAP HANA. Terakhir, Anda menyimpan cadangan yang telah selesai dengan menguploadnya ke bucket Cloud Storage, tempat Anda dapat mendownload cadangan tersebut, saat Anda perlu memulihkan sistem SAP HANA.
Menggunakan Compute Engine untuk membuat cadangan dan snapshot disk
Anda dapat menggunakan Compute Engine untuk pencadangan SAP HANA, dan juga memiliki opsi untuk mencadangkan seluruh disk yang menghosting data dan volume log SAP HANA Anda menggunakan snapshot disk standar.
Jika mengikuti petunjuk dalam
panduan deployment, Anda
memiliki penginstalan SAP HANA
dengan direktori /hanabackup untuk pencadangan database
online. Anda dapat menggunakan direktori yang sama untuk menyimpan snapshot volume /hanabackup
dan mempertahankan cadangan titik waktu tertentu untuk volume data dan log
SAP HANA Anda.
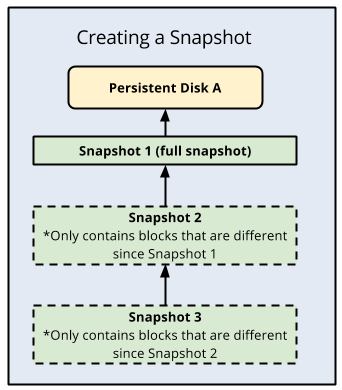
Keuntungan dari snapshot disk standar adalah bersifat inkremental, di mana setiap pencadangan berikutnya hanya menyimpan perubahan blok inkremental, bukan membuat cadangan yang benar-benar baru. Compute Engine menyimpan beberapa salinan setiap snapshot secara redundan di beberapa lokasi dengan checksum otomatis untuk memastikan integritas data Anda.
Berikut adalah ilustrasi pencadangan inkremental:
Cloud Storage sebagai tujuan pencadangan Anda
Cloud Storage adalah pilihan tepat untuk digunakan sebagai tujuan cadangan Anda untuk SAP HANA karena memberikan ketahanan dan ketersediaan data yang tinggi.
Cloud Storage adalah penyimpanan objek untuk file dengan jenis atau format apa pun. Layanan ini memiliki penyimpanan hampir tanpa batas dan Anda tidak perlu khawatir untuk menyediakannya atau menambah kapasitasnya. Objek di Cloud Storage terdiri dari data file dan metadata yang terkait, dan dapat berukuran hingga 5 TB. Bucket Cloud Storage dapat menyimpan objek dalam jumlah berapa pun.
Dengan Cloud Storage, data Anda disimpan di beberapa lokasi, yang memberikan ketahanan tinggi dan ketersediaan tinggi. Ketika Anda mengupload data ke Cloud Storage atau menyalin data di dalamnya, Cloud Storage melaporkan tindakan tersebut sebagai berhasil hanya jika redundansi objek tercapai.
Tabel berikut menunjukkan opsi penyimpanan yang ditawarkan oleh Cloud Storage:
| Frekuensi baca/tulis data | Opsi Cloud Storage yang direkomendasikan |
|---|---|
| Operasi baca atau tulis yang sering dilakukan | Pilih kelas penyimpanan Standar untuk database yang sedang digunakan, karena database tersebut mungkin sering mengakses Cloud Storage untuk menulis dan membaca file cadangan. |
| Operasi baca atau tulis yang tidak sering | Pilih penyimpanan Nearline atau Coldline untuk data yang jarang diakses, seperti cadangan yang diarsipkan yang perlu dikelola sesuai dengan kebijakan retensi organisasi Anda. Nearline adalah pilihan tepat untuk data yang dicadangkan yang akan Anda akses paling banyak sebulan sekali, sedangkan Coldline lebih cocok untuk data yang memiliki probabilitas akses sangat rendah, seperti paling banyak setahun sekali. |
| Data arsip | Pilih Archive storage untuk data arsip jangka panjang. Arsip adalah pilihan yang tepat untuk data yang salinannya perlu Anda simpan dalam jangka waktu yang lama, tetapi tidak ingin diakses lebih dari setahun sekali. Misalnya, gunakan Archive storage untuk pencadangan yang perlu Anda simpan dalam jangka panjang untuk memenuhi persyaratan peraturan. Pertimbangkan untuk mengganti solusi pencadangan berbasis pita dengan Archive. |
Saat Anda merencanakan penggunaan opsi penyimpanan ini, mulailah dengan tingkat yang sering diakses dan usia data cadangan Anda hingga tingkat akses yang jarang diakses. Cadangan umumnya jarang digunakan seiring bertambahnya usia. Probabilitas memerlukan cadangan yang berusia 3 tahun sangat rendah dan Anda dapat menambahkan cadangan ini ke tingkat Archive untuk menghemat biaya. Untuk mengetahui informasi tentang biaya Cloud Storage, lihat Harga Cloud Storage.
Cloud Storage dibandingkan dengan pencadangan pita
Tujuan pencadangan lokal konvensional adalah pita. Cloud Storage memiliki banyak manfaat dibandingkan pita, termasuk kemampuan untuk menyimpan cadangan "di luar lokasi" secara otomatis dari sistem sumber, karena data dalam Cloud Storage direplikasi di berbagai fasilitas. Ini juga berarti bahwa cadangan yang disimpan di Cloud Storage sangat tersedia.
Perbedaan utama lainnya adalah kecepatan pemulihan cadangan saat Anda perlu menggunakannya. Jika Anda perlu membuat sistem SAP HANA baru dari cadangan, atau memulihkan sistem yang ada dari cadangan, Cloud Storage akan memberikan akses lebih cepat ke data Anda, yang membantu Anda membuat sistem lebih cepat.
Fitur backint Agen Google Clouduntuk SAP
Anda dapat menggunakan Cloud Storage secara langsung untuk pencadangan dan pemulihan, baik untuk penginstalan lokal maupun cloud, menggunakan fitur Backint bersertifikasi SAP dari Agen Google Clouduntuk SAP.
Untuk informasi selengkapnya tentang fitur ini, lihat Pencadangan dan pemulihan berbasis Backint untuk SAP HANA.
Mencadangkan dan memulihkan SAP HANA menggunakan Backint
Bagian berikut memberikan informasi tentang cara mencadangkan dan memulihkan SAP HANA menggunakan fitur Backint dari Agen Google Clouduntuk SAP.
- Memicu pencadangan data dan delta
- Memicu pencadangan log
- Mengirim kueri ke katalog cadangan
- Memulihkan database
Memicu pencadangan data dan delta
Untuk memicu pencadangan volume data SAP HANA dan mengirimkannya ke Cloud Storage menggunakan fitur Backint dari Agen Google Clouduntuk SAP, Anda dapat menggunakan SAP HANA Studio, SAP HANA Cockpit, SAP HANA SQL, atau DBA Cockpit.
Berikut adalah pernyataan SQL SAP HANA untuk memicu pencadangan data:
Untuk membuat cadangan penuh database sistem:
BACKUP DATA USING BACKINT ('BACKUP_NAME');Ganti
BACKUP_NAMEdengan nama yang ingin Anda tetapkan untuk pencadangan.Untuk membuat cadangan penuh database tenant:
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Ganti
TENANT_SIDdengan SID database tenant.Untuk membuat cadangan diferensial dan tambahan:
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');Ganti
BACKUP_TYPEdenganDIFFERENTIALatauINCREMENTAL, bergantung pada jenis pencadangan yang ingin Anda buat.
Ada beberapa opsi yang dapat Anda gunakan saat memicu pencadangan data. Untuk
mengetahui informasi tentang opsi ini, lihat panduan referensi SQL SAP HANA
Pernyataan BACKUP DATA (Pencadangan dan Pemulihan).
Untuk informasi selengkapnya tentang pencadangan data dan delta, lihat dokumen SAP Pencadangan Data dan Pencadangan Delta.
Memicu pencadangan log
Untuk memicu pencadangan volume log SAP HANA dan mengirimkannya ke Cloud Storage menggunakan fitur Backint dari Agen Google Clouduntuk SAP, selesaikan langkah-langkah berikut:
- Buat cadangan database lengkap. Untuk mengetahui petunjuknya, lihat dokumentasi SAP untuk versi SAP HANA Anda.
- Dalam file
global.iniSAP HANA, tetapkan parametercatalog_backup_using_backintkeyes.
Pastikan mode log untuk sistem SAP HANA Anda adalah normal, yang merupakan
nilai default. Jika mode log ditetapkan ke overwrite, database SAP HANA
akan menonaktifkan pembuatan cadangan log.
Untuk informasi selengkapnya tentang pencadangan log, lihat dokumen SAP Pencadangan Log.
Membuat kueri katalog cadangan
Katalog cadangan SAP HANA adalah bagian penting dari operasi pencadangan dan pemulihan. File ini berisi informasi tentang cadangan yang dibuat untuk database SAP HANA.
Untuk membuat kueri pada katalog cadangan guna mendapatkan informasi tentang cadangan database tenant, selesaikan langkah-langkah berikut:
- Nonaktifkan database tenant.
Di database sistem, jalankan pernyataan SQL berikut:
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
Atau, untuk membuat kueri pada titik waktu tertentu, jalankan pernyataan SQL berikut:
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
Pernyataan ini akan membuat file
strategyOutput.xmldi direktori berikut:/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID.
Untuk informasi tentang pernyataan BACKUP LIST DATA, lihat panduan referensi SQL SAP HANA
Pernyataan BACKUP DATA (Pencadangan dan Pemulihan).
Untuk informasi tentang katalog cadangan, lihat dokumen SAP Backup Catalog.
Memulihkan database
Saat Anda melakukan pemulihan menggunakan pencadangan data multi-streaming, SAP HANA menggunakan jumlah saluran yang sama dengan yang digunakan saat pencadangan dibuat. Untuk informasi selengkapnya, lihat dokumen SAP Prasyarat: Pemulihan Menggunakan Pencadangan Multi-aliran.
Untuk memulihkan cadangan database SAP HANA yang Anda buat menggunakan fitur Backint
Agen Google Clouduntuk SAP, SAP HANA menyediakan
pernyataan SQL RECOVER DATA
dan
RECOVER DATABASE.
Kedua pernyataan SQL memulihkan cadangan dari bucket Cloud Storage yang
Anda tentukan untuk parameter bucket dalam
file PARAMETERS.json, kecuali jika Anda telah menentukan bucket
untuk parameter recover_bucket.
Berikut adalah contoh pernyataan SQL untuk memulihkan database SAP HANA menggunakan cadangan yang Anda buat menggunakan fitur Backint dari AgenGoogle Clouduntuk SAP:
Untuk memulihkan database tenant dengan menentukan nama file cadangan:
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;Untuk memulihkan database tenant dengan menentukan ID cadangan:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
Ganti
BACKUP_IDdengan ID cadangan yang diperlukan.Untuk memulihkan database tenant dengan menentukan ID cadangan saat Anda perlu menggunakan cadangan katalog cadangan SAP HANA, yang disimpan di bucket Cloud Storage:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
Untuk memulihkan database tenant ke titik waktu tertentu atau ke posisi log tertentu:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
Untuk memulihkan database tenant menggunakan cadangan dari database eksternal:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
Ganti kode berikut:
SOURCE_TENANT_SID: SID database tenant sumberSOURCE_SID: SID sistem SAP tempat database tenant sumber berada
Jika Anda perlu memulihkan database SAP HANA saat katalog cadangan SAP HANA tidak tersedia di cadangan yang disimpan di bucket Cloud Storage, ikuti petunjuk yang diberikan dalam Catatan SAP 3227931 - Recover a HANA DB From Backint Without a HANA Backup Catalog.
Mengelola identitas dan akses ke cadangan
Saat Anda menggunakan Cloud Storage atau Compute Engine untuk mencadangkan data SAP HANA, akses ke cadangan tersebut dikontrol oleh Identity and Access Management (IAM). Fitur ini memberi admin kemampuan untuk mengizinkan siapa saja yang dapat mengambil tindakan terhadap resource tertentu. IAM memberi Anda kontrol dan visibilitas terpusat untuk mengelola semua resourceGoogle Cloud , termasuk cadangan Anda.
IAM juga menyediakan histori jejak audit lengkap untuk otorisasi, penghapusan, dan pendelegasian izin yang muncul secara otomatis untuk admin Anda. Dengan begitu, Anda dapat mengonfigurasi kebijakan yang memantau akses ke data di cadangan, sehingga Anda dapat menyelesaikan siklus kontrol akses penuh dengan data Anda. IAM memberikan tampilan terpadu tentang kebijakan keamanan di seluruh organisasi Anda, dengan audit bawaan untuk memudahkan proses kepatuhan.
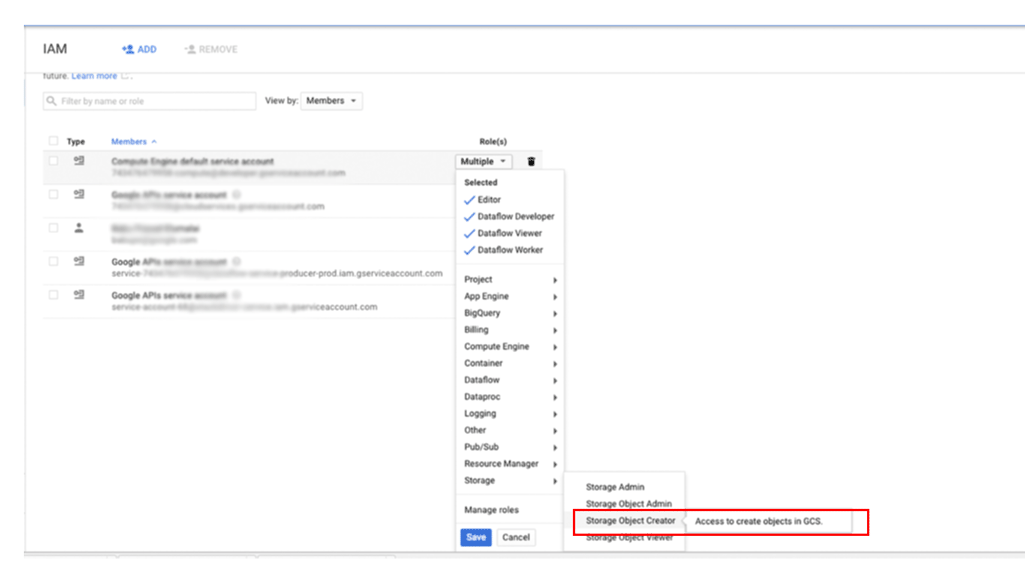
Untuk memberikan akses akun utama ke cadangan Anda di Cloud Storage:
Di konsol Google Cloud , buka halaman IAM & Admin:
Tentukan pengguna yang ingin Anda beri akses, lalu tetapkan peran Penyimpanan > Pembuat Objek Penyimpanan:
Cara membuat cadangan berbasis sistem file untuk SAP HANA
Sistem SAP HANA yang di-deploy di Google Cloud menggunakan
panduan deployment
dikonfigurasi dengan serangkaian volume Persistent Disk atau Hyperdisk
untuk digunakan sebagai tujuan pencadangan yang dipasang di NFS. Cadangan SAP HANA pertama-tama disimpan di disk lokal ini, lalu Anda perlu menyalinnya ke Cloud Storage untuk penyimpanan jangka panjang. Anda dapat menyalin cadangan secara manual ke Cloud Storage atau menjadwalkan salinan ke Cloud Storage di crontab.
Jika menggunakan fitur Backint dari Agen Google Clouduntuk SAP, Anda akan mencadangkan dan memulihkan dari bucket Cloud Storage secara langsung, sehingga tidak memerlukan penyimpanan disk persisten untuk pencadangan.
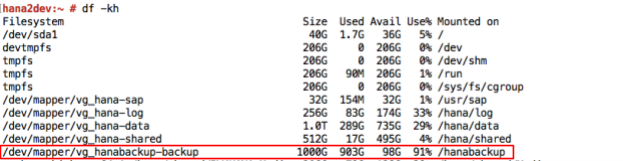
Untuk memulai atau menjadwalkan pencadangan data SAP HANA, Anda dapat menggunakan SAP HANA Studio, perintah SQL, atau DBA Cockpit. Cadangan log ditulis secara otomatis kecuali jika dinonaktifkan. Screenshot berikut menampilkan contoh:
Mengonfigurasi global.ini SAP HANA
Jika Anda mengikuti petunjuk
panduan deployment, file konfigurasi global.ini SAP HANA akan disesuaikan dengan
cadangan database yang disimpan di /hanabackup/data/ dan file arsip log otomatis
disimpan di /hanabackup/log/. Berikut adalah contoh tampilan global.ini:
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
Untuk menyesuaikan file konfigurasi global.ini untuk fitur Backint
AgenGoogle Clouduntuk SAP, lihat
Mengonfigurasi SAP HANA untuk fitur Backint.
Catatan untuk deployment penyebaran skala
Dalam implementasi penyebaran skala, solusi ketersediaan tinggi yang menggunakan migrasi langsung dan mulai ulang otomatis
berfungsi dengan cara yang sama seperti dalam penyiapan host tunggal. Perbedaan
utamanya adalah volume /hana/shared dipasang di NFS ke semua host
worker dan menjadi master di master HANA. Volume NFS akan tidak dapat diakses
secara singkat jika ada migrasi langsung atau mulai ulang otomatis
host master. Saat host master dimulai ulang, volume NFS akan segera
berfungsi kembali pada semua host, dan operasi normal akan dilanjutkan secara otomatis.
Volume pencadangan SAP HANA, /hanabackup, harus tersedia di semua host selama operasi
pencadangan dan pemulihan. Jika terjadi kegagalan, Anda harus memverifikasi bahwa
/hanabackup terpasang di semua host dan memasang kembali setiap host yang tidak terpasang. Saat Anda
memilih untuk menyalin set cadangan ke volume lain atau Cloud Storage,
jalankan salinan di host master untuk mencapai performa I/O yang lebih baik dan
mengurangi penggunaan jaringan. Untuk menyederhanakan proses pencadangan dan pemulihan, Anda dapat menggunakan
Cloud Storage Fuse untuk memasang bucket Cloud Storage
di setiap host.
Performa penyebaran skala hanya sebagus distribusi data Anda. Semakin baik data didistribusikan, semakin baik performa kueri Anda. Hal ini mengharuskan Anda mengetahui data dengan baik, memahami cara data digunakan, serta merancang distribusi dan partisi tabel yang sesuai. Untuk informasi selengkapnya, lihat Catatan SAP 2081591 - FAQ: Distribusi Tabel SAP HANA.
Gcloud Python
Gcloud Python adalah klien Python idiomatis yang dapat Anda gunakan untuk mengakses layananGoogle Cloud . Panduan ini menggunakan Gcloud Python untuk melakukan operasi pencadangan dan pemulihan ke dan dari Cloud Storage untuk pencadangan database SAP HANA Anda.
Jika Anda mengikuti petunjuk panduan deployment, library Gcloud Python sudah tersedia di instance Compute Engine.
Library ini bersifat open source dan memungkinkan Anda beroperasi di bucket Cloud Storage untuk menyimpan dan mengambil data cadangan.
Anda dapat menjalankan perintah berikut untuk membuat daftar objek di bucket Cloud Storage. Anda dapat menggunakannya untuk membuat daftar cadangan yang tersedia:
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
Untuk mengetahui detail selengkapnya tentang Gcloud Python, lihat dokumentasi referensi library klien penyimpanan.
Contoh pencadangan dan pemulihan
Bagian berikut mengilustrasikan prosedur yang dapat Anda ikuti untuk tugas pencadangan dan pemulihan biasa menggunakan SAP HANA Studio.
Contoh pembuatan cadangan
Di SAP HANA Backup Editor, pilih Buka Wizard Pencadangan.
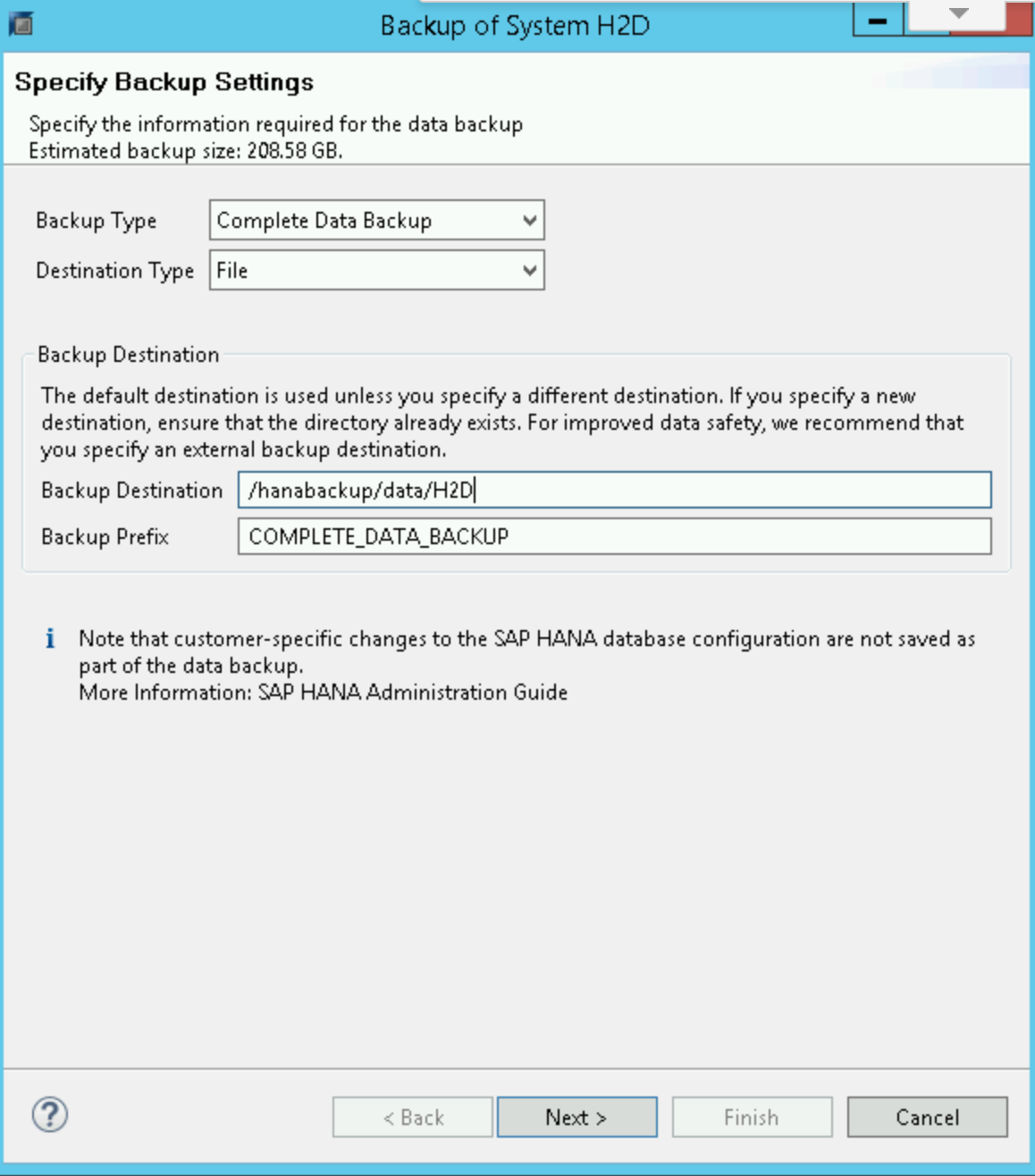
- Pilih File sebagai jenis tujuan. Ini mencadangkan database ke file dalam sistem file yang ditentukan.
- Tentukan tujuan pencadangan,
/hanabackup/data/SID, dan awalan cadangan. GantiSIDdengan ID sistem SAP Anda. - Klik Berikutnya.
Klik Selesai di formulir konfirmasi untuk memulai pencadangan.
Saat pencadangan dimulai, jendela status akan menampilkan progres pencadangan Anda. Tunggu hingga pencadangan selesai.
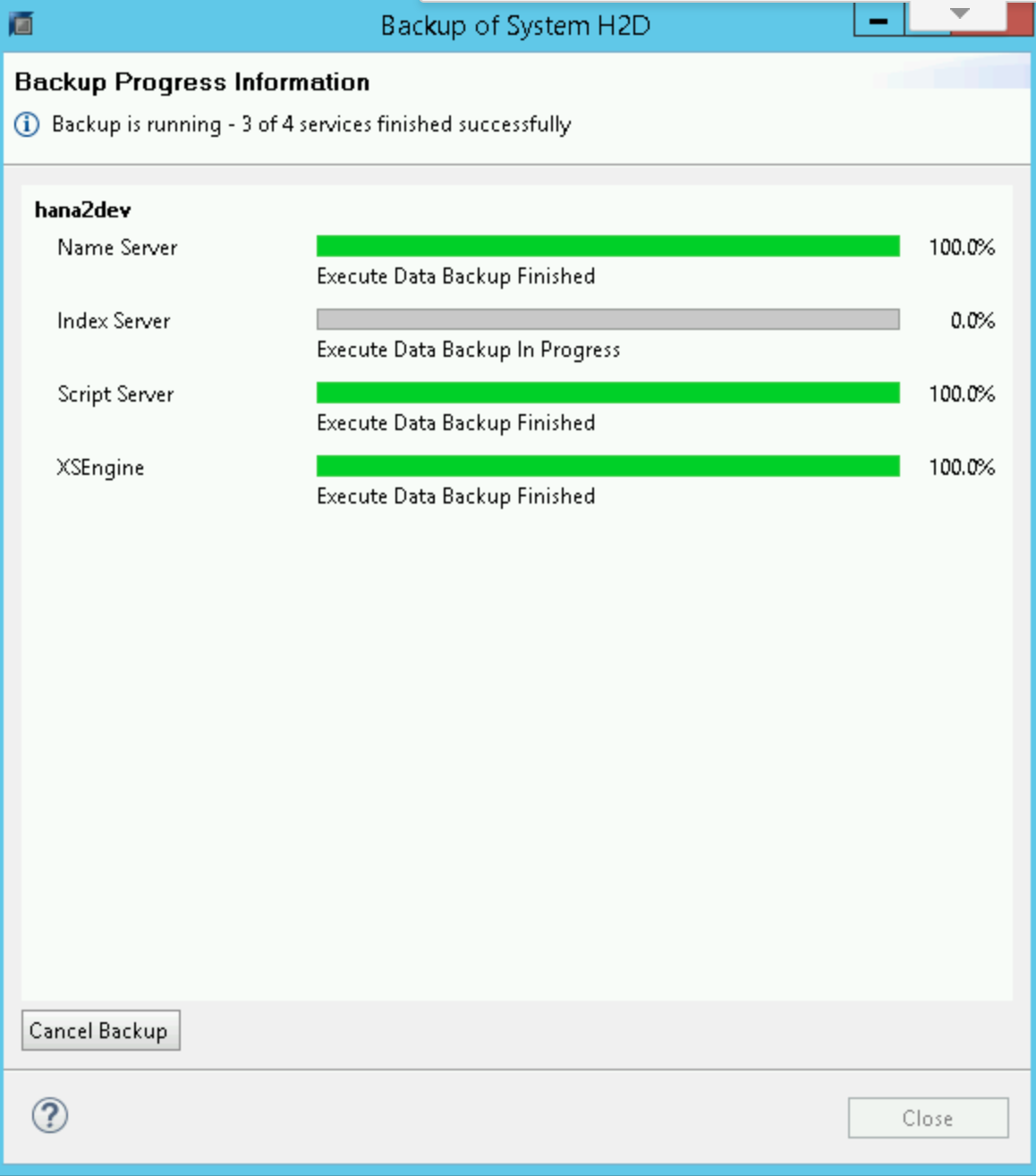
Setelah pencadangan selesai, ringkasan pencadangan akan menampilkan pesan
Finished.Login ke sistem SAP HANA Anda dan verifikasi bahwa cadangan tersedia di lokasi yang diharapkan dalam sistem file. Contoh:
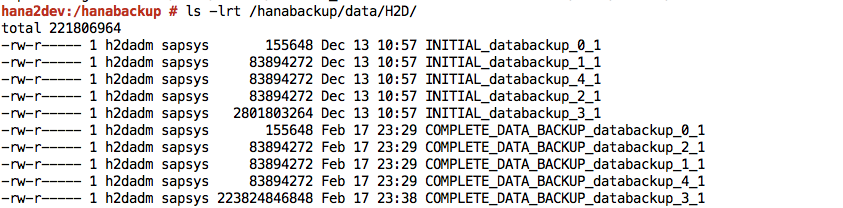

Kirim atau sinkronkan file cadangan dari sistem file
/hanabackupke Cloud Storage. Contoh skrip Python berikut mengirim data dari/hanabackup/datadan/hanabackup/logke bucket yang digunakan untuk pencadangan, dalam bentukNODE_NAME/DATAatauLOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME. Hal ini memungkinkan Anda mengidentifikasi file cadangan berdasarkan waktu saat cadangan disalin. Jalankan skripgcloud Pythonini di prompt bash sistem operasi:python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOFGunakan library Gcloud Python atau konsol Google Cloud untuk membuat daftar data cadangan.
Contoh pemulihan cadangan
Jika file cadangan tidak tersedia di direktori
/hanabackup, tetapi tersedia di Cloud Storage, download file dari Cloud Storage, dengan menjalankan skrip berikut dari perintah bash sistem operasi Anda:python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOFUntuk memulihkan database SAP HANA, klik Pencadangan dan Pemulihan > Pulihkan Sistem:
Klik Berikutnya.
Tentukan lokasi cadangan di sistem file lokal Anda, lalu klik Tambahkan.
Klik Berikutnya.
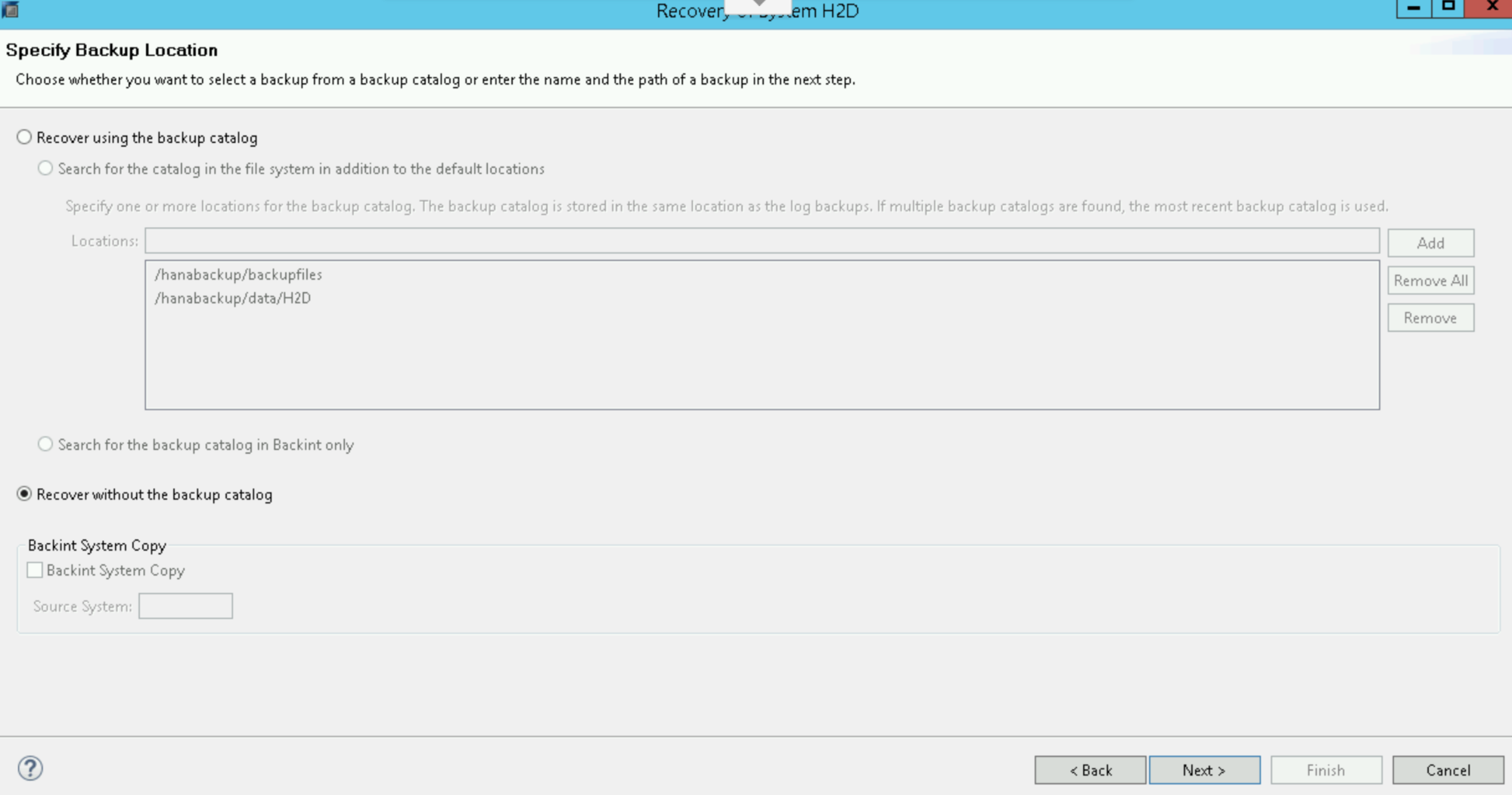
Pilih Pulihkan tanpa katalog cadangan:
Klik Next.
Pilih File sebagai jenis tujuan, lalu tentukan lokasi file cadangan dan awalan yang benar untuk cadangan Anda. Jika Anda mengikuti prosedur Contoh pembuatan cadangan, ingatlah bahwa
COMPLETE_DATA_BACKUPditetapkan sebagai awalan.Klik Next dua kali.
Klik Selesai untuk memulai pemulihan.
Setelah pemulihan selesai, lanjutkan operasi normal dan hapus file cadangan dari direktori
/hanabackup/data/SID/*.
Langkah berikutnya
Dokumen SAP standar berikut mungkin akan bermanfaat bagi Anda:
Dokumen Google Cloud berikut mungkin juga berguna bagi Anda:
- Penawaran uji coba dan fitur cloud gratis
- Mulai menggunakan Google Cloud
- Compute Engine
- Persistent Disk