Este guia mostra como automatizar a implantação do SAP HANA em um cluster de alta disponibilidade Red Hat Enterprise Linux (RHEL) ou SUSE Linux Enterprise Server (SLES) que usa o balanceamento de carga interno de rede de passagem para gerenciar o endereço IP virtual (VIP).
O guia usa o Terraform para implantar duas máquinas virtuais (VMs) do Compute Engine, dois sistemas de escalonamento vertical do SAP HANA, um endereço IP virtual (VIP) com uma implementação de balanceador de carga de rede de passagem interna e um cluster de HA baseado em SO, de acordo com as práticas recomendadas do Google Cloud, da SAP e do fornecedor do SO.
Um dos sistemas SAP HANA funciona como o sistema primário ativo e o outro como sistema secundário em espera. Implante os dois sistemas SAP HANA na mesma região, de preferência em diferentes zonas.

O cluster implantado inclui as seguintes funções e recursos:
- O gerenciador de recursos do cluster de alta disponibilidade do Pacemaker
- Um Google Cloud mecanismo de isolamento.
- Um IP virtual (VIP) que usa uma implementação de balanceador de carga interno TCP de
nível 4, incluindo:
- Uma reserva do endereço IP que você seleciona para o VIP.
- Dois grupos de instâncias do Compute Engine.
- Um balanceador de carga interno de TCP.
- Uma verificação de integridade do Compute Engine.
- Nos clusters de alta disponibilidade do RHEL:
- O padrão de alta disponibilidade do Red Hat.
- O agente de recursos e pacotes de isolamento do Red Hat.
- Em clusters de alta disponibilidade do SLES:
- O padrão de alta disponibilidade do SUSE
- Para o SLES para SAP 15 SP6 ou mais recente, o pacote de agente de recursos
SAPHanaSR-angido SUSE. Para versões anteriores do SLES, o pacote de agente de recursosSAPHanaSRdo SUSE.
- Replicação síncrona do sistema
- Memória pré-carregada
- Reinicialização automática da instância com falha como nova instância secundária
Se você precisar de um sistema de escalonamento horizontal com hosts em espera para failover automático do host do SAP HANA, consulte Terraform: sistema de escalonamento horizontal do SAP HANA com guia de implantação de failover automático do host do Google Analytics.
Para implantar um sistema SAP HANA sem um cluster de alta disponibilidade do Linux ou hosts em espera, use o Guia de implantação do SAP HANA.
Este guia é destinado a usuários avançados do SAP HANA familiarizados com as configurações de alta disponibilidade do Linux para SAP HANA.
Pré-requisitos
Antes de criar o cluster de alta disponibilidade do SAP HANA, verifique se os pré-requisitos a seguir são atendidos:
- Você leu o Guia de planejamento do SAP HANA e o Guia de planejamento de alta disponibilidade do SAP HANA.
- Você ou sua organização têm uma conta do Google Cloud e criaram um projeto para a implantação do SAP HANA. Para informações sobre como criar Google Cloud contas e projetos, consulte Como configurar sua Conta do Google.
- Se você precisar que a carga de trabalho da SAP seja executada em conformidade com residência de dados, controle de acesso, equipes de suporte ou requisitos regulatórios, crie a pasta do Assured Workloads necessária. Para mais informações, consulte Controles soberanos e de conformidade para a SAP no Google Cloud.
A mídia de instalação do SAP HANA está armazenada em um bucket do Cloud Storage disponível no projeto e na região de implantação. Para informações sobre como fazer o upload da mídia de instalação do SAP HANA para um bucket do Cloud Storage, consulte Como criar um bucket do Cloud Storage para os arquivos de instalação do SAP HANA.
Se o login do SO estiver ativado nos metadados do projeto, você precisará desativar o login do SO temporariamente até que a implantação seja concluída. Para fins de implantação, este procedimento configura chaves SSH em metadados de instâncias. Quando o login do SO é ativado, as configurações de chave SSH baseadas em metadados são desativadas e a implantação falha. Após a conclusão da implantação, ative o login do SO novamente.
Veja mais informações em:
Se você estiver usando o DNS interno da VPC, o valor da variável
vmDnsSettingnos metadados do projeto precisará serGlobalOnlyouZonalPreferredpara ativar a resolução dos nomes de nó nas zonas. A configuração padrão devmDnsSettingéZonalOnly. Para mais informações, consulte estes tópicos:
Criar uma rede
Por motivos de segurança, crie uma nova rede. Para controlar quem tem acesso a ela, adicione regras de firewall ou use outro método de controle de acesso.
Caso o projeto tenha uma rede VPC padrão, não a use. Em vez disso, crie sua própria rede VPC para que as únicas regras de firewall aplicadas sejam aquelas criadas explicitamente por você.
Durante a implantação, as instâncias do Compute Engine geralmente exigem acesso à Internet para fazer o download do agente do Google Cloudpara SAP. Se você estiver usando uma das imagens do Linux certificadas pela SAP disponíveis em Google Cloud, a instância de computação também precisará de acesso à Internet para registrar a licença e acessar repositórios de fornecedores do sistema operacional. Uma configuração com um gateway NAT e tags de rede da VM é compatível com esse acesso, mesmo que as instâncias de computação de destino não tenham IPs externos.
Para criar uma rede VPC para o projeto, siga estas etapas:
-
Crie uma rede de modo personalizado. Para mais informações, consulte Como criar uma rede de modo personalizado.
-
Crie uma sub-rede e especifique a região e o intervalo de IP. Para mais informações, consulte Como adicionar sub-redes.
Como configurar um gateway NAT
Se você precisar criar uma ou mais VMs sem endereços IP públicos, será necessário usar a conversão de endereços de rede (NAT) para permitir que as VMs acessem a Internet. Use o Cloud NAT, um Google Cloud serviço gerenciado distribuído e definido por software que permite que as VMs enviem pacotes de saída para a Internet e recebam todos os pacotes de resposta de entrada estabelecidos. Se preferir, é possível configurar uma VM separada como um gateway NAT.
Para criar uma instância do Cloud NAT para seu projeto, consulte Como usar o Cloud NAT.
Depois de configurar o Cloud NAT para seu projeto, as instâncias de VM poderão acessar a Internet com segurança sem um endereço IP público.
Como adicionar regras de firewall
Por padrão, uma regra de firewall implícita bloqueia conexões de entrada de fora da rede de nuvem privada virtual (VPC). Para permitir conexões de entrada, configure uma regra de firewall para sua VM. Depois que uma conexão de entrada for estabelecida com uma VM, será permitido o tráfego nas duas direções nessa conexão.
Os clusters de alta disponibilidade para SAP HANA exigem pelo menos duas regras de firewall, uma que permite que a verificação de integridade do Compute Engine verifique a integridade dos nós do cluster e outra que permite que os nós do cluster se comuniquem entre si.Se você não estiver usando uma rede VPC compartilhada, precisará criar a regra de firewall para a comunicação entre os nós, mas não para as verificações de integridade. O arquivo de configuração do Terraform cria a regra de firewall para as verificações de integridade, que pode ser modificada após a conclusão da implantação, se necessário.
Se você estiver usando uma rede VPC compartilhada, um administrador de rede precisará criar as duas regras de firewall no projeto host.
Também é possível criar uma regra de firewall para permitir o acesso externo a portas especificadas ou para restringir o acesso entre as VMs na mesma rede. Se o tipo de rede VPC default for usado, algumas regras padrão complementares também serão aplicadas, como a regra default-allow-internal, que permite a conectividade entre VMs na mesma rede em todas as portas.
Dependendo da política de TI que for aplicada ao ambiente, pode ser necessário isolar ou então restringir a conectividade com o host do banco de dados, o que pode ser feito criando regras de firewall.
Dependendo do seu cenário, é possível criar regras de firewall para permitir o acesso para estes itens:
- Portas padrão do SAP listadas no TCP/IP de Todos os Produtos SAP.
- Conexões do seu computador ou do ambiente de rede corporativa para a instância de VM do Compute Engine. Se você não tiver certeza do endereço IP a ser usado, fale com o administrador de redes da sua empresa.
- Conexões SSH com a instância da VM, incluindo o SSH no navegador;
- Conexão com a VM por meio de uma ferramenta de terceiros no Linux. Crie uma regra para permitir o acesso da ferramenta pelo seu firewall.
Para criar as regras de firewall para seu projeto, consulte Como criar regras de firewall.
Como criar um cluster de alta disponibilidade do Linux com o SAP HANA instalado
As instruções a seguir usam o arquivo de configuração do Terraform para criar um cluster do RHEL ou do SLES com dois sistemas SAP HANA: um sistema SAP HANA primário de host único em uma instância de VM e um sistema SAP HANA em espera em outra instância de VM na mesma região do Compute Engine. Os sistemas SAP HANA usam replicação síncrona, e o sistema em espera pré-carrega os dados replicados.
Defina as opções de configuração do cluster de alta disponibilidade do SAP HANA em um arquivo de configuração do Terraform.
Confirme se as cotas atuais para recursos, como discos permanentes e CPUs, são suficientes para os sistemas SAP HANA que você está prestes a instalar. Se as cotas forem insuficientes, a implantação falhará.
Para saber os requisitos de cotas do SAP HANA, consulte Considerações sobre preços e cotas para SAP HANA.
Abra o Cloud Shell.
Faça o download do arquivo de configuração
sap_hana_ha.tfpara o cluster de alta disponibilidade do SAP HANA no diretório de trabalho:$wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/terraform/sap_hana_ha.tfAbra o arquivo
sap_hana_ha.tfno editor de código do Cloud Shell.Para abrir o editor de código, clique no ícone de lápis, no canto superior direito da janela do terminal do Cloud Shell.
No arquivo
sap_hana_ha.tf, atualize os valores do argumento substituindo o conteúdo dentro das aspas duplas pelos valores da sua instalação. Os argumentos são descritos na tabela a seguir.Argumento Tipo de dado Descrição sourceString Especifica o local e a versão do módulo do Terraform a serem usados durante a implantação.
O arquivo de configuração
sap_hana_ha.tfinclui duas instâncias do argumentosource: uma que está ativa e outra incluída como um comentário. O argumentosource, que é ativo por padrão, especificalatestcomo a versão do módulo. A segunda instância do argumentosource, que, por padrão, é desativada por um caractere#inicial, especifica um carimbo de data/hora que identifica uma versão do módulo.Se você precisar que todas as implantações usem a mesma versão do módulo, remova o caractere
#líder do argumentosourceque especifica o carimbo de data/hora da versão e o adiciona aossourceque especificalatest.project_idString Especifique o ID do projeto Google Cloud em que você está implantando esse sistema. Por exemplo, my-project-x.machine_typeString Especifique o tipo de máquina virtual (VM) do Compute Engine em que você precisa executar o sistema SAP. Se você precisar de um tipo de VM personalizado, especifique um tipo de VM predefinido com um número de vCPUs o mais próximo possível do necessário, mesmo que maior. Após a conclusão da implantação, modifique o número de vCPUs e a quantidade de memória. Por exemplo,
n1-highmem-32sole_tenant_deploymentBooleano Opcional. Se você quiser provisionar um nó de locatário único para a implantação do SAP HANA, especifique o valor
true.O valor padrão é
false.Esse argumento está disponível na versão
sap_hana_ha1.3.704310921ou mais recente.sole_tenant_name_prefixString Opcional. Se você estiver provisionando um nó de locatário individual para sua implantação do SAP HANA, use esse argumento para especificar um prefixo que o Terraform define para os nomes do modelo e do grupo de único locatário correspondentes.
O valor padrão é
st-SID_LC.Para informações sobre o modelo e o grupo de locatário individual, consulte Visão geral de locatário individual.
Esse argumento está disponível na versão
sap_hana_ha1.3.704310921ou mais recente.sole_tenant_node_typeString Opcional.Se você quiser provisionar um nó de locatário individual para sua implantação do SAP HANA, especifique o tipo de nó que você quer definir para o modelo de nó correspondente.
Esse argumento está disponível na versão
sap_hana_ha1.3.704310921ou mais recente.networkString Especifique o nome da rede em que você precisa criar o balanceador de carga que gerencia o VIP. Se você estiver usando uma rede VPC compartilhada, será preciso adicionar o ID do projeto host como um diretório pai do nome da rede. Por exemplo,
HOST_PROJECT_ID/NETWORK_NAME.subnetworkString O nome da sub-rede criada em um passo anterior. Se você estiver implantando em uma VPC compartilhada, especifique esse valor como SHARED_VPC_PROJECT_ID/SUBNETWORK. Por exemplo,myproject/network1.linux_imageString Especifique o nome da imagem do sistema operacional Linux em que você quer implantar o sistema SAP. Por exemplo, rhel-9-2-sap-haousles-15-sp5-sap. Para conferir a lista de imagens do sistema operacional disponíveis, consulte a página Imagens no console Google Cloud .linux_image_projectString Especifique o projeto Google Cloud que contém a imagem que você especificou para o argumento linux_image. Talvez seja seu próprio projeto ou um projeto de imagem Google Cloud . Para uma imagem do Compute Engine, especifiquerhel-sap-cloudoususe-sap-cloud. Para encontrar o projeto de imagem do sistema operacional, consulte Detalhes do sistema operacional.primary_instance_nameString Especifique um nome da instância de VM para o sistema SAP HANA principal. O nome pode conter letras minúsculas, números ou hífens. primary_zoneString Especifique uma zona em que o sistema SAP HANA principal está implantado. As zonas principal e secundária precisam estar na mesma região. Por exemplo, us-east1-csecondary_instance_nameString Especifique um nome da instância de VM para o sistema secundário do SAP HANA. O nome pode conter letras minúsculas, números ou hífens. secondary_zoneString Especifique uma zona em que o sistema secundário do SAP HANA está implantado. As zonas principal e secundária precisam estar na mesma região. Por exemplo, us-east1-bsap_hana_deployment_bucketString Para instalar automaticamente o SAP HANA nas VMs implantadas, especifique o caminho do bucket do Cloud Storage que contém os arquivos de instalação do SAP HANA. Não inclua gs://no caminho. Inclua apenas o nome do bucket e os nomes das pastas. Por exemplo,my-bucket-name/my-folder.O bucket do Cloud Storage precisa existir no projeto Google Cloud especificado para o argumento
project_id.sap_hana_sidString Para instalar automaticamente o SAP HANA nas VMs implantadas, especifique o ID do sistema SAP HANA. O ID precisa ter três caracteres alfanuméricos e começar com uma letra. Todas as letras precisam estar em maiúsculas. Por exemplo, ED1.sap_hana_instance_numberNúmero inteiro Opcional. Especifique o número da instância, de 0 a 99, do sistema SAP HANA. O padrão é 0.sap_hana_sidadm_passwordString Para instalar automaticamente o SAP HANA nas VMs implantadas, especifique uma senha temporária SIDadmpara os scripts de instalação a serem usados durante a implantação. A senha precisa conter pelo menos oito caracteres e incluir pelo menos uma letra maiúscula, uma letra minúscula e um número.Em vez de especificar uma senha como texto simples, recomendamos o uso de um secret. Para mais informações, consulte Gerenciamento de senhas.
sap_hana_sidadm_password_secretString Opcional. Se você estiver usando o Secret Manager para armazenar a SIDadme depois especifique o Nome do secret que corresponde a essa senha.No Secret Manager, verifique se o valor do Secret, que é a senha, contém pelo menos oito caracteres e inclui pelo menos uma letra maiúscula, uma minúscula e um número.
Para mais informações, consulte Gerenciamento de senhas.
sap_hana_system_passwordString Para instalar automaticamente o SAP HANA nas VMs implantadas, especifique uma senha temporária de superusuário do banco de dados para os scripts de instalação usarem durante a implantação. A senha precisa conter pelo menos oito caracteres e incluir pelo menos uma letra maiúscula, uma letra minúscula e um número. Em vez de especificar uma senha como texto simples, recomendamos o uso de um secret. Para mais informações, consulte Gerenciamento de senhas.
sap_hana_system_password_secretString Opcional. Se você estiver usando o Secret Manager para armazenar a senha de superusuário do banco de dados, especifique o Nome do secret que corresponde a essa senha. No Secret Manager, verifique se o valor do Secret, que é a senha, contém pelo menos oito caracteres e inclui pelo menos uma letra maiúscula, uma minúscula e um número.
Para mais informações, consulte Gerenciamento de senhas.
sap_hana_double_volume_sizeBooleano Opcional. Para duplicar o tamanho do volume do HANA, especifique true. Esse argumento é útil quando você quer implantar várias instâncias do SAP HANA ou uma instância de recuperação de desastres do SAP HANA na mesma VM. Por padrão, o tamanho do volume é calculado automaticamente para ser o tamanho mínimo necessário para o tamanho da VM, sem deixar de atender aos requisitos de certificação e suporte da SAP. O valor padrão éfalse.sap_hana_backup_sizeNúmero inteiro Opcional. Especifique o tamanho do volume /hanabackupem GB. Se você não especificar ou definir esse argumento como0, o script de instalação vai provisionar a instância do Compute Engine com um volume de backup do HANA duas vezes maior que a memória total.sap_hana_sidadm_uidNúmero inteiro Opcional. Especifique um valor para substituir o valor padrão do ID do usuário SID_LCadm. O valor padrão é 900. É possível alterá-lo para um valor diferente para maior consistência no cenário da SAP.sap_hana_sapsys_gidNúmero inteiro Opcional. Substitui o ID do grupo padrão para sapsys. O valor padrão é79.sap_vipString Opcional. Especifique o endereço IP que você usará para o VIP. O endereço IP precisa estar dentro do intervalo de endereços IP atribuídos à sua sub-rede. O arquivo de configuração do Terraform reserva esse endereço IP para você.
Na versão
1.3.730053050do módulosap_hana_ha, o argumentosap_vipé opcional. Se você não especificar, o Terraform vai atribuir automaticamente um endereço IP disponível da sub-rede que você especificar para o argumentosubnetwork.primary_instance_group_nameString Opcional. Define o nome do grupo de instâncias não gerenciadas para o nó principal.a O nome padrão é ig-PRIMARY_INSTANCE_NAME.secondary_instance_group_nameString Opcional. Define o nome do grupo de instâncias não gerenciadas para o nó secundário. O nome padrão é ig-SECONDARY_INSTANCE_NAME.loadbalancer_nameString Opcional. Especifique o nome do balanceador de carga de rede de passagem interno. O nome padrão é lb-SAP_HANA_SID-ilb.network_tagsString Opcional. Especifique uma ou mais tags de rede separadas por vírgula que você quer associar às suas instâncias de VM para fins de firewall ou roteamento. Uma tag de rede para os componentes do ILB é adicionada automaticamente às Tags de rede da VM.
nic_typeString Opcional. Especifique a interface de rede a ser usada com a instância de VM. É possível especificar o valor GVNICouVIRTIO_NET. Para usar uma NIC virtual do Google (gVNIC), você precisa especificar uma imagem do SO compatível com gVNIC como o valor do argumentolinux_image. Para conferir a lista de imagens do SO, consulte Detalhes do sistema operacional.Se você não especificar um valor para esse argumento, a interface de rede será selecionada automaticamente com base no tipo de máquina especificado para o argumento
Este argumento está disponível na versãomachine_type.202302060649do módulosap_hanaou posterior.disk_typeString Opcional. Especifique o tipo padrão de disco permanente ou Volume do hiperdisco que você quer implantar para os dados do SAP e os volumes de registro da implantação. Para informações sobre a implantação do disco padrão feita pelas configurações do Terraform fornecidas por Google Cloud, consulte Implantação de disco pelo Terraform. Os seguintes valores são válidos para esse argumento:
pd-ssd,pd-balanced,hyperdisk-extreme,hyperdisk-balancedepd-extreme. Nas implantações de escalonamento vertical do SAP HANA, um disco permanente equilibrado e separado também é implantado no diretório/hana/shared.É possível modificar esse tipo de disco padrão e o tamanho do disco padrão associado e as IOPS padrão usando alguns argumentos avançados. Para ver mais informações, navegue até seu diretório de trabalho, execute o comando
terraform inite veja o arquivo/.terraform/modules/sap_hana_ha/variables.tf. Antes de usar esses argumentos na produção, é preciso testá-los em um ambiente que não seja de produção.Se você quiser usar a extensão de armazenamento nativa do SAP HANA (NSE, na sigla em inglês) (link em inglês), provisione discos maiores usando os argumentos avançados.
use_single_shared_data_log_diskBooleano Opcional. O valor padrão é false, que direciona o Terraform para implantar um disco permanente ou hiperdisco separado para cada um dos seguintes volumes SAP:/hana/data,/hana/loge/hana/sharede/usr/sap. Para montar esses volumes SAP no mesmo disco permanente ou Hyperdisk, especifiquetrue.enable_data_stripingBooleano Opcional. Esse argumento permite implantar o volume /hana/dataem dois discos. O valor padrão éfalse, que direciona o Terraform a implantar um único disco para hospedar seu volume/hana/data.Este argumento está disponível na versão
1.3.674800406do módulosap_hana_haou posterior.include_backup_diskBooleano Opcional. Esse argumento é aplicável a implantações de escalonamento vertical do SAP HANA. O valor padrão é true, que direciona o Terraform para implantar um disco separado que hospeda o diretório/hanabackup.O tipo de disco é determinado pelo argumento
backup_disk_type. O tamanho desse disco é determinado pelo argumentosap_hana_backup_size.Se você definir o valor de
include_backup_diskcomofalse, nenhum disco será implantado no diretório/hanabackup.backup_disk_typeString Opcional. Em implantações de escalonamento vertical, especifique o tipo de disco permanente ou hiperdisco que você quer implantar para o volume /hanabackup. Para informações sobre a implantação do disco padrão feita pelas configurações do Terraform fornecidas por Google Cloud, consulte Implantação de disco pelo Terraform.Os seguintes valores são válidos para esse argumento:
pd-ssd,pd-balanced,pd-standard,hyperdisk-extreme,hyperdisk-balancedepd-extreme.Este argumento está disponível na versão
202307061058do módulosap_hana_haou posterior.enable_fast_restartBooleano Opcional. Esse argumento determina se a opção de reinicialização rápida do SAP HANA está ativada para sua implantação. O valor padrão é true. Google Cloud recomenda ativar a opção de reinicialização rápida do SAP HANA.Este argumento está disponível na versão
202309280828do módulosap_hana_haou posterior.public_ipBooleano Opcional. Determina se um endereço IP público é adicionado na sua instância de VM. O valor padrão é true.service_accountString Opcional. Especifique o endereço de e-mail de uma conta de serviço gerenciada pelo usuário que será usada pelas VMs do host e pelos programas executados nas VMs do host. Por exemplo, svc-acct-name@project-id..Se você especificar esse argumento sem um valor ou omiti-lo, o script de instalação usará a conta de serviço padrão do Compute Engine. Para mais informações, consulte Gerenciamento de identidade e acesso para programas SAP no Google Cloud.
sap_deployment_debugBooleano Opcional. Somente quando o Cloud Customer Care solicitar que você ative a depuração da sua implantação, especifique true, o que faz com que a implantação gere registros de implantação detalhados. O valor padrão éfalse.primary_reservation_nameString Opcional. Para usar uma reserva de VM do Compute Engine específica para provisionar a instância da VM que hospeda a instância principal do SAP HANA do cluster de alta disponibilidade, especifique o nome da reserva. Por padrão, o script de instalação seleciona qualquer reserva disponível do Compute Engine com base nas condições a seguir. Para que uma reserva seja utilizável, independentemente de você especificar um nome ou o script de instalação a selecionar automaticamente, a reserva precisa ser definida com o seguinte:
-
A opção
specificReservationRequiredestá definida comotrueou, no console Google Cloud , a opção Selecionar reserva específica está selecionada. -
Alguns tipos de máquina do Compute Engine são compatíveis com plataformas de CPU que não são
cobertas pela certificação SAP do tipo de máquina. Se a reserva
de destino for de qualquer um dos seguintes tipos de máquina, a reserva
precisará especificar as plataformas mínimas de CPU, conforme indicado:
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
As plataformas de CPU mínimas para todos os outros tipos de máquina que são
certificadas pela SAP para uso no Google Cloud estão em conformidade com o requisito de CPU mínimo
da SAP. Google Cloud
secondary_reservation_nameString Opcional. Para usar uma reserva de VM específica do Compute Engine para provisionar a instância da VM que hospeda a instância secundária do SAP HANA do cluster de alta disponibilidade, especifique o nome da reserva. Por padrão, o script de instalação seleciona qualquer reserva disponível do Compute Engine com base nas condições a seguir. Para que uma reserva seja utilizável, independentemente de você especificar um nome ou o script de instalação a selecionar automaticamente, a reserva precisa ser definida com o seguinte:
-
A opção
specificReservationRequiredestá definida comotrueou, no console Google Cloud , a opção Selecionar reserva específica está selecionada. -
Alguns tipos de máquina do Compute Engine são compatíveis com plataformas de CPU que não são
cobertas pela certificação SAP do tipo de máquina. Se a reserva
de destino for de qualquer um dos seguintes tipos de máquina, a reserva
precisará especificar as plataformas mínimas de CPU, conforme indicado:
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
As plataformas de CPU mínimas para todos os outros tipos de máquina que são
certificadas pela SAP para uso no Google Cloud estão em conformidade com o requisito de CPU mínimo
da SAP. Google Cloud
primary_static_ipString Opcional. Especifique um endereço IP estático válido para a instância de VM primária no cluster de alta disponibilidade. Se não houver uma especificação, um endereço IP será gerado automaticamente para sua instância de VM. Por exemplo, 128.10.10.10.Este argumento está disponível na versão
202306120959do módulosap_hana_haou posterior.secondary_static_ipString Opcional. Especifique um endereço IP estático válido para a instância de VM secundária no cluster de alta disponibilidade. Se não houver uma especificação, um endereço IP será gerado automaticamente para sua instância de VM. Por exemplo, 128.11.11.11.Este argumento está disponível na versão
202306120959do módulosap_hana_haou posterior.can_ip_forwardBooleano Especifique se o envio e o recebimento de pacotes com IPs de origem ou de destino não correspondentes é permitido, o que permite que uma VM funcione como um roteador. O valor padrão é
true.Se você pretende usar apenas os balanceadores de carga internos do Google para gerenciar endereços IP virtuais para as VMs implantadas, defina o valor como
false. Um balanceador de carga interno é implantado automaticamente como parte dos modelos de alta disponibilidade.Os exemplos a seguir mostram o modelo de arquivo de configuração concluído que define um cluster de alta disponibilidade para o SAP HANA. O cluster usa um balanceador de carga de rede de passagem interno para gerenciar o VIP.
O Terraform implanta os recursos Google Cloud definidos no arquivo de configuração. Em seguida, os scripts assumem a configuração do sistema operacional, instalam o SAP HANA, configuram a replicação e configuram o cluster de alta disponibilidade do Linux.
Clique em
RHELouSLESpara ver o exemplo específico de seu sistema operacional. Para esclarecer, os comentários no arquivo de configuração são omitidos nos exemplos.RHEL
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "rhel-8-4-sap-ha" linux_image_project = "rhel-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456." primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }SLES
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "sles-15-sp3-sap" linux_image_project = "suse-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456." primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }-
A opção
Para inicializar seu diretório de trabalho atual e fazer o download do plug-in do provedor do Terraform e dos arquivos de módulo para Google Cloud:
terraform init
O comando
terraform initprepara seu diretório de trabalho para outros comandos do Terraform.Para forçar uma atualização do plug-in do provedor e dos arquivos de configuração no diretório de trabalho, especifique a sinalização
--upgrade. Se a--upgradesinalização é omitida e você não faz alterações no seu diretório de trabalho, o Terraform usa as cópias em cache local, mesmo selatesté especificado nasourceURLterraform init --upgrade
Como opção, crie o plano de execução do Terraform:
terraform plan
O comando
terraform planmostra as alterações exigidas pela configuração atual. Se você pular essa etapa, o comandoterraform applycriará automaticamente um novo plano e solicitará que você o aprove.Aplique o plano de execução:
terraform apply
Quando for solicitada a aprovação das ações, digite
yes.O comando
terraform applyconfigura a infraestrutura Google Cloud e, em seguida, transfere o controle para um script que configura o cluster de alta disponibilidade e instala o SAP HANA de acordo com os argumentos definidos no arquivo de configuração do Terraform.Embora o Terraform tenha controle, as mensagens de status são gravadas no Cloud Shell. Depois que o script é invocado, as mensagens de status são gravadas no Logging e podem ser visualizadas no console Google Cloud , conforme descrito em Verificar os registros.
Como verificar a implantação do sistema HANA de alta disponibilidade
A verificação de um cluster de alta disponibilidade do SAP HANA envolve vários procedimentos diferentes:
- Como verificar a geração de registros
- Como verificar a configuração da VM e a instalação do SAP HANA
- Como verificar a configuração do cluster
- Como verificar o balanceador de carga e a integridade dos grupos de instâncias
- Como verificar o sistema SAP HANA usando o SAP HANA Studio
- Como realizar um teste de failover
Verificar os registros
No console Google Cloud , abra o Cloud Logging para monitorar o progresso da instalação e verificar se há erros.
Filtre os registros:
Explorador de registros
Na página Explorador de registros, acesse o painel Consulta.
No menu suspenso Recurso, selecione Global e clique em Adicionar.
Se a opção Global não for exibida, insira a seguinte consulta no editor de consultas:
resource.type="global" "Deployment"Clique em Run query.
Visualizador de registros legado
- Na página Visualizador de registros legado, no menu de seleção básico, selecione Global como o recurso de registros.
Analise os registros filtrados:
- Se
"--- Finished"for exibido, o processamento do Deployment Manager estará concluído e será possível prosseguir para a próxima etapa. Se você vir um erro de cota:
Na página Cotas do IAM e Admin, aumente as cotas que não atendem aos requisitos do SAP HANA listados no Guia de planejamento do SAP HANA.
Abra o Cloud Shell.
Acesse seu diretório de trabalho e exclua a implantação para limpar as VMs e os discos permanentes da instalação com falha:
terraform destroy
Quando for solicitada a aprovação da ação, digite
yes.Execute a implantação novamente.
- Se
Verificar a configuração da VM e a instalação do SAP HANA
Depois de implantar o sistema SAP HANA sem erros, conecte-se a cada VM usando SSH. Na página Instâncias de VM do Compute Engine, clique no botão "SSH" para cada instância de VM ou use seu método de SSH preferido.

Mude para o usuário raiz.
sudo su -
No prompt de comando, insira
df -h. Verifique se você vê uma saída que inclui os diretórios/hana, como/hana/data.RHEL
[root@example-ha-vm1 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 0 126G 0% /dev tmpfs 126G 54M 126G 1% /dev/shm tmpfs 126G 25M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda2 30G 5.4G 25G 18% / /dev/sda1 200M 6.9M 193M 4% /boot/efi /dev/mapper/vg_hana-shared 251G 52G 200G 21% /hana/shared /dev/mapper/vg_hana-sap 32G 477M 32G 2% /usr/sap /dev/mapper/vg_hana-data 426G 9.8G 417G 3% /hana/data /dev/mapper/vg_hana-log 125G 7.0G 118G 6% /hana/log /dev/mapper/vg_hanabackup-backup 512G 9.3G 503G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/899 tmpfs 26G 0 26G 0% /run/user/1003
SLES
example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 54M 189G 1% /dev/shm tmpfs 126G 34M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 30G 5.4G 25G 18% / /dev/sda2 20M 2.9M 18M 15% /boot/efi /dev/mapper/vg_hana-shared 251G 50G 202G 20% /hana/shared /dev/mapper/vg_hana-sap 32G 281M 32G 1% /usr/sap /dev/mapper/vg_hana-data 426G 8.0G 418G 2% /hana/data /dev/mapper/vg_hana-log 125G 4.3G 121G 4% /hana/log /dev/mapper/vg_hanabackup-backup 512G 6.4G 506G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/473 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1003
Verifique o status do novo cluster digitando o comando de status específico para seu sistema operacional:
RHEL
pcs statusSLES
crm statusA saída é semelhante ao exemplo a seguir, em que ambas as instâncias da VM são iniciadas e
example-ha-vm1é a instância primária ativa:RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.4-4b1f869f0f) - partition with quorum * Last updated: Wed Jul 7 23:05:11 2021 * Last change: Wed Jul 7 23:04:43 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ] Failed Resource Actions: * rsc_healthcheck_HA1_start_0 on example-ha-vm1 'error' (1): call=29, status='complete', exitreason='', last-rc-change='2021-07-07 21:07:35Z', queued=0ms, exec=2097ms * SAPHana_HA1_00_monitor_61000 on example-ha-vm1 'not running' (7): call=44, status='complete', exitreason='', last-rc-change='2021-07-07 21:09:49Z', queued=0ms, exec=0ms Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledSLES para SAP 15 SP5 ou anterior
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Wed Jul 7 22:57:59 2021 * Last change: Wed Jul 7 22:57:03 2021 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]SLES para SAP 15 SP6 ou mais recente
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Mon Oct 7 22:57:59 2024 * Last change: Mon Oct 7 22:57:03 2024 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]Altere para o usuário administrador do SAP substituindo SID_LC no seguinte comando pelo valor de
sap_hana_sidque você especificou no arquivosap_hana_ha.tf. O valor SID_LC precisa estar em letras minúsculas.su - SID_LCadmPara verificar se os serviços do SAP HANA, como
hdbnameserver,hdbindexservere outros, estão sendo executados na instância, digite o seguinte comando:HDB infoSe você estiver usando o RHEL for SAP 9.0 ou posterior, verifique se os pacotes
chkconfigecompat-openssl11estão instalados na instância de VM.Para mais informações da SAP, consulte a Nota SAP 3108316 – Red Hat Enterprise Linux 9.x: instalação e configuração .
Verificar a configuração do cluster
Verifique as configurações de parâmetros do cluster. Verifique as configurações exibidas pelo software do cluster e as configurações dos parâmetros no arquivo de configuração do cluster. Compare suas configurações com as dos exemplos abaixo, que foram criadas pelos scripts de automação usados neste guia.
Clique na guia do seu sistema operacional.
RHEL
Exiba as configurações de recursos do cluster:
pcs config show
O exemplo a seguir mostra as configurações de recursos que são criadas pelos scripts de automação no RHEL 8.1 e nas versões posteriores.
Se você estiver executando o RHEL 7.7 ou uma versão anterior, a definição de recurso
Clone: SAPHana_HA1_00-clonenão incluiráMeta Attrs: promotable=true.Cluster Name: hacluster Corosync Nodes: example-rha-vm1 example-rha-vm2 Pacemaker Nodes: example-rha-vm1 example-rha-vm2 Resources: Group: g-primary Resource: rsc_healthcheck_HA1 (class=service type=haproxy) Operations: monitor interval=10s timeout=20s (rsc_healthcheck_HA1-monitor-interval-10s) start interval=0s timeout=100 (rsc_healthcheck_HA1-start-interval-0s) stop interval=0s timeout=100 (rsc_healthcheck_HA1-stop-interval-0s) Resource: rsc_vip_HA1_00 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=32 ip=10.128.15.100 nic=eth0 Operations: monitor interval=3600s timeout=60s (rsc_vip_HA1_00-monitor-interval-3600s) start interval=0s timeout=20s (rsc_vip_HA1_00-start-interval-0s) stop interval=0s timeout=20s (rsc_vip_HA1_00-stop-interval-0s) Clone: SAPHanaTopology_HA1_00-clone Meta Attrs: clone-max=2 clone-node-max=1 interleave=true Resource: SAPHanaTopology_HA1_00 (class=ocf provider=heartbeat type=SAPHanaTopology) Attributes: InstanceNumber=00 SID=HA1 Operations: methods interval=0s timeout=5 (SAPHanaTopology_HA1_00-methods-interval-0s) monitor interval=10 timeout=600 (SAPHanaTopology_HA1_00-monitor-interval-10) reload interval=0s timeout=5 (SAPHanaTopology_HA1_00-reload-interval-0s) start interval=0s timeout=600 (SAPHanaTopology_HA1_00-start-interval-0s) stop interval=0s timeout=300 (SAPHanaTopology_HA1_00-stop-interval-0s) Clone: SAPHana_HA1_00-clone Meta Attrs: promotable=true Resource: SAPHana_HA1_00 (class=ocf provider=heartbeat type=SAPHana) Attributes: AUTOMATED_REGISTER=true DUPLICATE_PRIMARY_TIMEOUT=7200 InstanceNumber=00 PREFER_SITE_TAKEOVER=true SID=HA1 Meta Attrs: clone-max=2 clone-node-max=1 interleave=true notify=true Operations: demote interval=0s timeout=3600 (SAPHana_HA1_00-demote-interval-0s) methods interval=0s timeout=5 (SAPHana_HA1_00-methods-interval-0s) monitor interval=61 role=Slave timeout=700 (SAPHana_HA1_00-monitor-interval-61) monitor interval=59 role=Master timeout=700 (SAPHana_HA1_00-monitor-interval-59) promote interval=0s timeout=3600 (SAPHana_HA1_00-promote-interval-0s) reload interval=0s timeout=5 (SAPHana_HA1_00-reload-interval-0s) start interval=0s timeout=3600 (SAPHana_HA1_00-start-interval-0s) stop interval=0s timeout=3600 (SAPHana_HA1_00-stop-interval-0s) Stonith Devices: Resource: STONITH-example-rha-vm1 (class=stonith type=fence_gce) Attributes: pcmk_delay_max=30 pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm1 project=example-project-123456 zone=us-central1-a Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm1-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm1-start-interval-0) Resource: STONITH-example-rha-vm2 (class=stonith type=fence_gce) Attributes: pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm2 project=example-project-123456 zone=us-central1-c Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm2-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm2-start-interval-0) Fencing Levels: Location Constraints: Resource: STONITH-example-rha-vm1 Disabled on: example-rha-vm1 (score:-INFINITY) (id:location-STONITH-example-rha-vm1-example-rha-vm1--INFINITY) Resource: STONITH-example-rha-vm2 Disabled on: example-rha-vm2 (score:-INFINITY) (id:location-STONITH-example-rha-vm2-example-rha-vm2--INFINITY) Ordering Constraints: start SAPHanaTopology_HA1_00-clone then start SAPHana_HA1_00-clone (kind:Mandatory) (non-symmetrical) (id:order-SAPHanaTopology_HA1_00-clone-SAPHana_HA1_00-clone-mandatory) Colocation Constraints: g-primary with SAPHana_HA1_00-clone (score:4000) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-g-primary-SAPHana_HA1_00-clone-4000) Ticket Constraints: Alerts: No alerts defined Resources Defaults: migration-threshold=5000 resource-stickiness=1000 Operations Defaults: timeout=600s Cluster Properties: cluster-infrastructure: corosync cluster-name: hacluster dc-version: 2.0.2-3.el8_1.2-744a30d655 have-watchdog: false stonith-enabled: true stonith-timeout: 300s Quorum: Options:Exiba o arquivo de configuração do cluster,
corosync.conf:cat /etc/corosync/corosync.conf
O exemplo a seguir mostra os parâmetros que os scripts de automação definem para o RHEL 8.1 e versões mais recentes.
Se você estiver usando o RHEL 7.7 ou uma versão mais antiga, o valor de
transport:seráudpuem vez deknet:totem { version: 2 cluster_name: hacluster transport: knet join: 60 max_messages: 20 token: 20000 token_retransmits_before_loss_const: 10 crypto_cipher: aes256 crypto_hash: sha256 } nodelist { node { ring0_addr: example-rha-vm1 name: example-rha-vm1 nodeid: 1 } node { ring0_addr: example-rha-vm2 name: example-rha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum two_node: 1 } logging { to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes timestamp: on }
SLES para SAP 15 SP5 ou anterior
Exiba as configurações de recursos do cluster:
crm config show
Os scripts de automação usados neste guia criam as configurações de recursos mostradas no exemplo a seguir:
node 1: example-ha-vm1 \ attributes hana_ha1_op_mode=logreplay lpa_ha1_lpt=1635380335 hana_ha1_srmode=syncmem hana_ha1_vhost=example-ha-vm1 hana_ha1_remoteHost=example-ha-vm2 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes lpa_ha1_lpt=30 hana_ha1_op_mode=logreplay hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 hana_ha1_srmode=syncmem hana_ha1_remoteHost=example-ha-vm1 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHana \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta notify=true clone-max=2 clone-node-max=1 target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Exiba o arquivo de configuração do cluster,
corosync.conf:cat /etc/corosync/corosync.conf
Os scripts de automação usados neste guia especificam as configurações de parâmetros no arquivo
corosync.conf, conforme mostrado no exemplo a seguir:totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
SLES para SAP 15 SP6 ou mais recente
Exiba as configurações de recursos do cluster:
crm config show
Os scripts de automação usados neste guia criam as configurações de recursos mostradas no exemplo a seguir:
node 1: example-ha-vm1 \ attributes hana_ha1_vhost=example-ha-vm1 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHanaFileSystem_HA1_HDB00 ocf:suse:SAPHanaFilesystem \ operations $id=rsc_sap3_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHanaController \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Promoted timeout=700 \ op monitor interval=61 role=Unpromoted timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 clone mst_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta clone-node-max=1 promotable=true interleave=true clone cln_SAPHanaFileSystem_HA1_HDB00 rsc_SAPHanaFileSystem_HA1_HDB00 \ meta clone-node-max=1 interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started mst_SAPHana_HA1_HDB00:Promoted order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 mst_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Exiba o arquivo de configuração do cluster,
corosync.conf:cat /etc/corosync/corosync.conf
Os scripts de automação usados neste guia especificam as configurações de parâmetros no arquivo
corosync.conf, conforme mostrado no exemplo a seguir:totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
Verificar o balanceador de carga e a integridade dos grupos de instâncias
Para confirmar se o balanceador de carga e a verificação de integridade foram configurados corretamente, verifique o balanceador de carga e os grupos de instâncias no console Google Cloud .
Abra a página Balanceamento de carga no Google Cloud console:
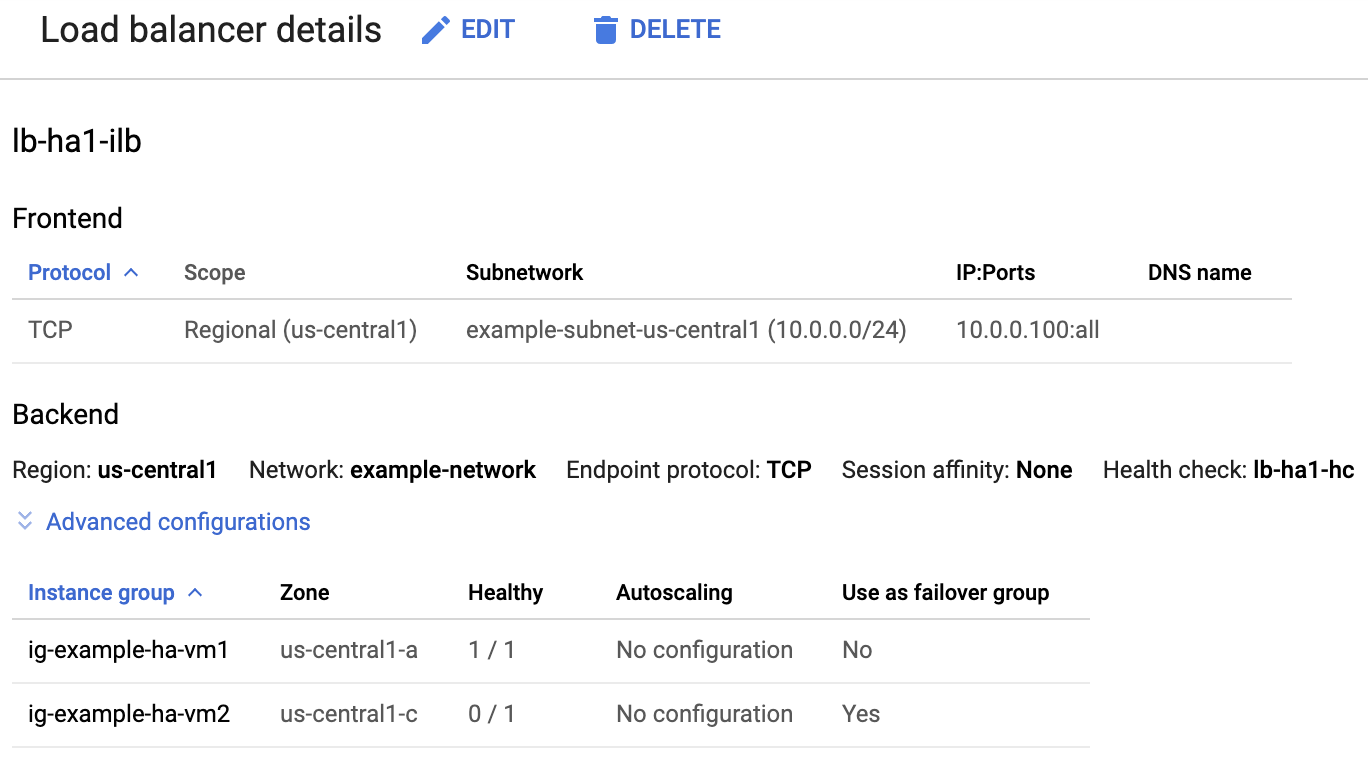
Na lista de balanceadores de carga, confirme se um balanceador de carga foi criado para seu cluster de alta disponibilidade.
Na página Detalhes do balanceador de carga, na coluna Íntegro em Grupo de instâncias, na seção Back-end, confirme que um dos grupos de instâncias mostra "1/1" e o outro mostra "0/1". Depois de um failover, o indicador de integridade "1/1" alterna para o novo grupo de instâncias ativo.
Verificar o sistema SAP HANA usando o SAP HANA Studio
É possível usar o Cockpit do SAP HANA ou o SAP HANA Studio para monitorar e gerenciar os sistemas SAP HANA em um cluster de alta disponibilidade.
Conecte-se ao sistema HANA usando o SAP HANA Studio. Ao definir a conexão, especifique os seguintes valores:
- No painel "Especificar o sistema", especifique o endereço IP flutuante como o nome do host.
- No painel "Propriedades de conexão", para autenticação do usuário do banco de dados,
especifique o nome do superusuário do banco de dados e a senha que você especificou
para o argumento
sap_hana_system_passwordno arquivosap_hana_ha.tf.
Para mais informações da SAP sobre a instalação do SAP HANA Studio, consulte o Guia de instalação e atualização do SAP HANA Studio.
Depois que o SAP HANA Studio estiver conectado ao sistema HANA de alta disponibilidade, exiba a visão geral do sistema clicando duas vezes no nome do sistema no painel de navegação no lado esquerdo da janela.
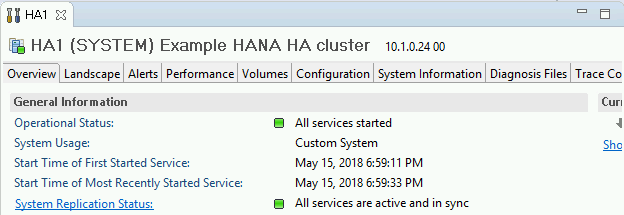
Em "General Information", na guia "Overview", verifique se:
- o campo "Operational Status" mostra "All services started";
- o campo "System Replication Status" mostra "All services are active and in sync".
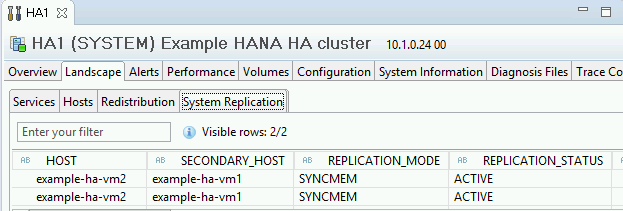
Confirme o modo de replicação clicando no link System Replication Status em "General Information". A replicação síncrona é indicada por
SYNCMEMna coluna REPLICATION_MODE, na guia "System Replication".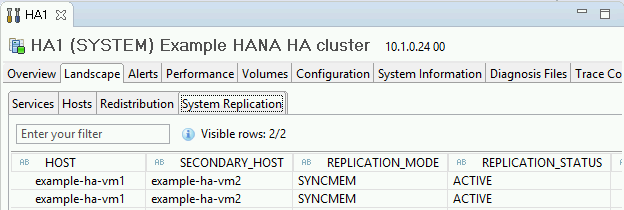
Limpar e tentar implantar novamente
Se alguma das etapas de verificação de implantação nas seções anteriores mostrar que a instalação não foi concluída, desfaça a implantação e tente novamente seguindo as etapas a seguir:
Resolva os erros para garantir que a implantação não falhe novamente pelo mesmo motivo. Para mais informações sobre como verificar os registros ou resolver erros relacionados a cotas, consulte Verificar os registros.
Abra o Cloud Shell ou, se você instalou a CLI do Google Cloud na sua estação de trabalho local, abra um terminal.
Acesse o diretório que contém o arquivo de configuração do Terraform que você usou nesta implantação.
Exclua todos os recursos que fazem parte da implantação executando o seguinte comando:
terraform destroy
Quando for solicitada a aprovação da ação, digite
yes.Tente fazer a implantação novamente, conforme indicado anteriormente neste guia.
Executar um teste de failover
Para executar um teste de failover, siga estas etapas:
Conecte-se à VM principal usando SSH. É possível fazer isso na página Instâncias de VM do Compute Engine, clicando no botão "SSH" para cada instância da VM ou usando seu método SSH preferido.
No prompt de comando, digite o seguinte comando:
sudo ip link set eth0 down
O comando
ip link set eth0 downaciona um failover ao interromper as comunicações com o host principal.Reconecte-se ao host usando o SSH e mude para o usuário raiz
Confirme se o host principal está ativo na VM que costumava conter o host secundário. A reinicialização automática está ativada no cluster. Portanto, o host parado será reiniciado e assumirá a função de host secundário.
RHEL
pcs statusSLES
crm statusOs exemplos a seguir mostram que os papéis em cada host foram alternados.
RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.3-4b1f869f0f) - partition with quorum * Last updated: Fri Mar 19 21:22:07 2021 * Last change: Fri Mar 19 21:21:28 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES para SAP 15 SP5 ou anterior
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Thu Jul 8 17:33:44 2021 * Last change: Thu Jul 8 17:33:07 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES para SAP 15 SP6 ou mais recente
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Tue Oct 8 21:47:19 2024 * Last change: Tue Oct 8 21:47:13 2024 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]Na página Detalhes do balanceador de carga no console, confirme se a nova instância primária ativa mostra "1/1" na coluna Íntegro. Se necessário, atualize a página.
Acessar o Cloud Load Balancing
Exemplo:

No SAP HANA Studio, para confirmar se você ainda está conectado ao sistema, clique duas vezes na entrada do sistema no painel de navegação para atualizar as informações.
Clique no link System Replication Status para confirmar se os hosts principal e secundário foram trocados e estão ativos.
Valide a instalação do agente do Google Cloudpara SAP
Depois de implantar uma VM e instalar o sistema SAP, confirme se o agente doGoogle Cloudpara SAP está funcionando corretamente.
Verificar se o agente do Google Cloudpara SAP está em execução
Para verificar se o agente está em execução, siga estas etapas:
Estabeleça uma conexão SSH com a instância do Compute Engine.
Execute este comando:
systemctl status google-cloud-sap-agent
Se o agente estiver funcionando corretamente, a saída conterá
active (running). Por exemplo:google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
Se o agente não estiver em execução, reinicie-o.
Verificar se o SAP Host Agent está recebendo métricas
Para verificar se as métricas de infraestrutura são coletadas pelo agente doGoogle Cloudpara SAP e enviadas corretamente ao SAP Host Agent, siga estas etapas:
- No sistema SAP, insira a transação
ST06. No painel de visão geral, verifique a disponibilidade e o conteúdo dos seguintes campos para a configuração completa da infraestrutura de monitoramento da SAP e do Google:
- Provedor de nuvem:
Google Cloud Platform - Acesso ao monitoramento avançado:
TRUE - Detalhes do monitoramento avançado:
ACTIVE
- Provedor de nuvem:
Configurar o monitoramento para o SAP HANA
Como opção, monitore as instâncias do SAP HANA usando o agente doGoogle Cloudpara SAP. A partir da versão 2.0, é possível configurar o agente para coletar as métricas de monitoramento do SAP HANA e enviá-las para o Cloud Monitoring. O Cloud Monitoring permite criar painéis para visualizar essas métricas, configurar alertas com base em limites de métrica e muito mais.
Para monitorar um cluster de alta disponibilidade usando o agente do Google Cloudpara SAP, siga as orientações fornecidas em Configuração de alta disponibilidade para o agente.Para mais informações sobre a coleta de métricas de monitoramento do SAP HANA usando o agente doGoogle Cloudpara SAP, consulte Coleta de métricas de monitoramento do SAP HANA.
Conectar-se ao SAP HANA
Como essas instruções não usam um endereço IP externo para o SAP HANA, só será possível se conectar às instâncias do SAP HANA por meio da instância Bastion usando SSH ou por meio do Windows Server usando o SAP HANA Studio.
Para se conectar ao SAP HANA por meio da instância Bastion, conecte-se ao Bastion Host e depois às instâncias do SAP HANA usando o cliente SSH de sua escolha.
Para conectar o banco de dados SAP HANA por meio do SAP HANA Studio, use um cliente de área de trabalho remota para se conectar à instância do Windows Server. Após a conexão, instale o SAP HANA Studio (em inglês) manualmente e acesse o banco de dados SAP HANA.
Configurar o HANA ativo/ativo (ativado para leitura)
A partir do SAP HANA 2.0 SPS1, é possível configurar o HANA Active/Active (Read Enabled) em um cluster do Pacemaker. Para instruções, consulte:
- Configurar o HANA ativo/ativo (ativado para leitura) em um cluster do Pacemaker do SUSE
- Configurar o HANA ativo/ativo (ativado para leitura) em um cluster do Red Hat Pacemaker
Como realizar tarefas de pós-implantação
Antes de usar sua instância do SAP HANA, recomendamos que você siga os passos de pós-implantação a seguir. Para mais informações, consulte o guia de instalação e atualização do SAP HANA (em inglês).
Altere as senhas temporárias do superusuário do sistema SAP HANA e do superusuário do banco de dados.
Atualize o software SAP HANA com os patches mais recentes.
Se o sistema SAP HANA for implantado em uma interface de rede VirtIO, recomendamos que você garanta que o valor do parâmetro TCP
/proc/sys/net/ipv4/tcp_limit_output_bytesesteja definido como1048576. Essa modificação ajuda a melhorar a capacidade geral da rede na interface de rede VirtIO sem afetar a latência da rede.Instale todos os componentes extras, como o Application Function Libraries (AFL) ou o Smart Data Access (SDA).
Configure e faça o backup do seu novo banco de dados SAP HANA. Para mais informações, consulte o guia de operações do SAP HANA.
Avaliar sua carga de trabalho do SAP HANA
Para automatizar verificações de validação contínua para suas cargas de trabalho de alta disponibilidade do SAP HANA em execução no Google Cloud, use o Gerenciador de carga de trabalho.
O Gerenciador de cargas de trabalho permite verificar e avaliar automaticamente as cargas de trabalho de alta disponibilidade do SAP HANA em relação às práticas recomendadas de fornecedores da SAP, do Google Cloude do SO. Isso ajuda a melhorar a qualidade, o desempenho e a confiabilidade das cargas de trabalho.
Para informações sobre as práticas recomendadas compatíveis com o Gerenciador de cargas de trabalho para avaliar cargas de trabalho de alta disponibilidade do SAP HANA em execução no Google Cloud, consulte Práticas recomendadas do Gerenciador de cargas de trabalho para SAP. Para informações sobre como criar e executar uma avaliação usando o Gerenciador de cargas de trabalho, consulte Criar e executar uma avaliação.
A seguir
-
Se você estiver usando o SLES para SAP 15 SP4 ou SP5, consulte
Fazer upgrade do
SAPHanaSRparaSAPHanaSR-angiem um cluster de alta disponibilidade de escalonamento vertical no SLES para saber como fazer upgrade para o agente de recursosSAPHanaSR-angido SUSE no cluster de alta disponibilidade. - Se você precisar usar o Google Cloud NetApp Volumes em vez de volumes de Persistent Disk ou
Hyperdisk para hospedar diretórios do SAP HANA, como
/hana/sharedou/hanabackup, consulte as informações de implantação do NetApp Volumes no Guia de planejamento do SAP HANA. - Para mais informações sobre administração e monitoramento de VMs, consulte o Guia de operações do SAP HANA.