이 가이드에서는 내부 패스 스루 네트워크 부하 분산기를 사용하는 Red Hat Enterprise Linux(RHEL) 또는 SUSE Linux Enterprise Server(SLES) 고가용성(HA) 클러스터에서 SAP HANA 배포를 자동화하여 가상 IP(VIP) 주소를 관리하는 방법을 알려줍니다.
이 가이드에서는 Google Cloud, SAP, OS 공급업체의 모든 권장사항에 따라 Terraform을 사용하여 Compute Engine 가상 머신 (VM) 두 개, SAP HANA 수직 확장 시스템 두 개, 내부 패스 스루 네트워크 부하 분산기 구현이 포함된 가상 IP 주소(VIP), OS 기반 HA 클러스터를 배포합니다. Google Cloud
SAP HANA 시스템 중 하나는 기본 활성 시스템 역할을 하며 다른 하나는 보조 대기 시스템 역할을 합니다. 같은 리전 내에서, 이상적으로는 서로 다른 영역의 SAP HANA 시스템 두 개 모두를 배포합니다.

배포된 클러스터에는 다음 기능과 특징이 포함됩니다.
- Pacemaker 고가용성 클러스터 리소스 관리자
- Google Cloud 펜싱 메커니즘
- 다음을 포함하여 수준 4 TCP 내부 부하 분산기 구현을 사용하는 가상 IP(VIP):
- VIP에 선택한 IP 주소의 예약
- Compute Engine 인스턴스 그룹 두 개
- TCP 내부 부하 분산기
- Compute Engine 상태 점검
- RHEL HA 클러스터:
- Red Hat 고가용성 패턴
- Red Hat 리소스 에이전트 및 펜싱 패키지
- SLES HA 클러스터:
- SUSE 고가용성 패턴
- SAP용 SLES 15 SP6 이상인 경우 SUSE
SAPHanaSR-angi리소스 에이전트 패키지 이전 버전의 SLES의 경우 SUSESAPHanaSR리소스 에이전트 패키지
- 동기 시스템 복제
- 메모리 미리 로드
- 실패한 인스턴스를 새 보조 인스턴스로 자동 다시 시작
SAP HANA 자동 호스트 장애 조치를 위한 대기 호스트가 있는 수평 확장 시스템이 필요한 경우에는 대신 Terraform: 호스트 자동 장애 조치가 포함된 SAP HANA 수평 확장 시스템 배포 가이드를 참조하세요.
Linux 고가용성 클러스터나 대기 호스트 없이 SAP HANA 시스템을 배포하려면 Terraform: SAP HANA 배포 가이드를 참조하세요.
이 가이드는 SAP HANA용 Linux 고가용성 구성에 익숙한 SAP HANA 고급 사용자를 대상으로 합니다.
기본 요건
SAP HANA 고가용성 클러스터를 만들기 전에 다음 기본 요건을 충족하는지 확인하세요.
- SAP HANA 계획 가이드와 SAP HANA 고가용성 계획 가이드를 읽어야 합니다.
- 사용자 또는 사용자의 조직에 Google Cloud 계정이 있어야 하고 SAP HANA 배포를 위한 프로젝트를 만들어야 합니다.Google Cloud 계정 및 프로젝트를 만드는 방법에 대한 자세한 내용은 Google 계정 설정을 참고하세요.
- 데이터 상주, 액세스 제어, 지원 담당자 또는 규제 요건에 따라 SAP 워크로드를 실행해야 하는 경우 필요한 Assured Workloads 폴더를 만들어야 합니다. 자세한 내용은 Google Cloud 기반 SAP의 규정 준수 및 주권 제어 Google Cloud를 참고하세요.
SAP HANA 설치 미디어가 배포 프로젝트 및 리전에서 사용할 수 있는 Cloud Storage 버킷에 저장되어 있어야 합니다. SAP HANA 설치 미디어를 Cloud Storage 버킷에 업로드하는 방법에 대한 자세한 내용은 SAP HANA 설치 파일을 위한 Cloud Storage 버킷 만들기를 참조하세요.
프로젝트 메타데이터에 OS 로그인이 사용 설정되면 배포가 완료될 때까지 OS 로그인을 일시적으로 중지해야 합니다. 이 절차는 배포 목적으로 인스턴스 메타데이터에 SSH 키를 구성합니다. OS 로그인이 사용 설정되면 메타데이터 기반 SSH 키 구성이 사용 중지되고 이 배포가 실패합니다. 배포가 완료되면 OS 로그인을 다시 사용 설정할 수 있습니다.
자세한 내용은 다음을 참고하세요.
VPC 내부 DNS를 사용하는 경우 전체 영역에서 노드 이름을 확인하려면 프로젝트 메타데이터의
vmDnsSetting변수 값이GlobalOnly또는ZonalPreferred여야 합니다.vmDnsSetting의 기본 설정은ZonalOnly입니다. 자세한 내용은 다음을 참고하세요.
네트워크 만들기
보안 문제로 새 네트워크를 만들어야 합니다. 방화벽 규칙을 추가하거나 다른 액세스 제어 방법을 사용하여 액세스 권한이 있는 사용자를 제어할 수 있습니다.
프로젝트에 기본 VPC 네트워크가 있더라도 사용하지 마세요. 명시적으로 직접 만든 방화벽 규칙만 적용되도록 VPC 네트워크를 직접 만드시기 바랍니다.
배포 중에 Compute Engine 인스턴스는 일반적으로 SAP용 Google Cloud에이전트를 다운로드하기 위해 인터넷에 액세스할 수 있어야 합니다. Google Cloud에서 제공하는 SAP 인증 Linux 이미지 중 하나를 사용하는 경우 컴퓨팅 인스턴스도 라이선스를 등록하고 OS 공급업체 저장소에 액세스하기 위해 인터넷에 액세스할 수 있어야 합니다. NAT 게이트웨이 및 VM 네트워크 태그가 있는 구성은 대상 컴퓨팅 인스턴스에 외부 IP가 없더라도 이러한 액세스를 지원합니다.
프로젝트의 VPC 네트워크를 만들려면 다음 단계를 완료합니다.
-
커스텀 모드 네트워크를 만듭니다. 자세한 내용은 커스텀 모드 네트워크 만들기를 참조하세요.
-
서브네트워크를 만들고 리전과 IP 범위를 지정합니다. 자세한 내용은 서브넷 추가를 참조하세요.
NAT 게이트웨이 설정
공개 IP 주소가 없는 VM을 하나 이상 만들어야 하는 경우 네트워크 주소 변환 (NAT)을 사용하여 VM이 인터넷에 액세스하도록 설정해야 합니다. VM이 인터넷에 아웃바운드 패킷을 보내고 그에 따라 설정된 인바운드 응답 패킷을 받을 수 있도록 하는 Google Cloud 분산 소프트웨어 정의 관리형 서비스인 Cloud NAT를 사용하세요. 또는 별도의 VM을 NAT 게이트웨이로 설정할 수 있습니다.
프로젝트에 Cloud NAT 인스턴스를 만들려면 Cloud NAT 사용을 참조하세요.
프로젝트에 Cloud NAT를 구성하면 VM 인스턴스가 공개 IP 주소 없이 인터넷에 안전하게 액세스할 수 있습니다.
방화벽 규칙 추가
묵시적인 방화벽 규칙은 Virtual Private Cloud(VPC) 네트워크 외부에서 들어오는 연결을 차단하는 것이 기본 설정되어 있습니다. 들어오는 연결을 허용하려면 VM에 방화벽 규칙을 설정합니다. VM에 들어오는 연결이 설정되면 이 연결을 통한 양방향 트래픽이 허용됩니다.
SAP HANA용 HA 클러스터에는 방화벽 규칙이 최소 두 개 이상 필요합니다. 하나는 클러스터 노드 상태를 확인하도록 Compute Engine 상태 확인을 허용하고 다른 하나는 클러스터 노드 간 통신을 허용합니다.공유 VPC 네트워크를 사용하지 않을 경우에는 상태 확인이 아닌 노드 간 통신에 사용되는 방화벽 규칙을 만들어야 합니다. Terraform 구성 파일은 상태 점검을 위한 방화벽 규칙을 만듭니다. 배포가 완료된 후 필요에 따라 이 방화벽 규칙을 수정할 수 있습니다.
공유 VPC 네트워크를 사용하는 경우 네트워크 관리자는 호스트 프로젝트에 두 방화벽 규칙을 모두 만들어야 합니다.
또한 동일한 네트워크에서 지정된 포트에 대한 외부 액세스를 허용하거나 VM 간 액세스를 제한하는 방화벽 규칙을 만들 수 있습니다. default VPC 네트워크 유형이 사용되는 경우 모든 포트에서 동일한 네트워크에 있는 VM 간의 연결을 허용하는 default-allow-internal 규칙과 같은 일부 기본 규칙도 추가로 적용됩니다.
사용자 환경에 적용 가능한 IT 정책 마다 다를 수 있지만, 방화벽 규칙 생성을 통해 데이터베이스 호스에 대한 연결을 격리하거나 제한해야 할 수도 있습니다.
시나리오에 따라 다음에 대한 액세스를 허용하는 방화벽 규칙을 만들 수 있습니다.
- 모든 SAP 제품의 TCP/IP에 나열된 기본 SAP 포트
- 사용자 컴퓨터 또는 기업 네트워크 환경에서 Compute Engine VM 인스턴스에 연결. 사용할 IP 주소를 모르는 경우 회사의 네트워크 관리자에게 문의하세요.
- SSH-in-browser를 포함하여 VM 인스턴스로의 SSH 연결
- Linux에서 타사 도구를 사용하여 VM에 연결. 방화벽을 통해 도구에 대한 액세스를 허용하는 규칙을 만듭니다.
프로젝트의 방화벽 규칙을 만들려면 방화벽 규칙 만들기를 참조하세요.
SAP HANA가 설치된 고가용성 Linux 클러스터 만들기
다음 안내에서는 Terraform 구성 파일을 사용하여 하나의 VM 인스턴스에 있는 기본 단일 호스트 SAP HANA 시스템 및 동일한 Compute Engine 리전의 다른 VM 인스턴스의 대기 SAP HANA 시스템이라는 2개의 SAP HANA 시스템이 있는 RHEL 또는 SLES 클러스터를 만듭니다. SAP HANA 시스템은 동기 시스템 복제를 사용하며, 대기 시스템은 복제된 데이터를 미리 로드합니다.
Terraform 구성 파일에서 SAP HANA 고가용성 클러스터의 구성 옵션을 정의합니다.
영구 디스크, CPU 등 리소스의 현재 할당량이 설치하려는 SAP HANA 시스템에 충분한지 확인합니다. 할당량이 충분하지 않은 경우 배포가 실패합니다.
SAP HANA 할당량 요구사항은 SAP HANA의 가격 책정 및 할당량 고려사항을 참조하세요.
Cloud Shell을 엽니다.
SAP HANA 고가용성 클러스터의
sap_hana_ha.tf구성 파일을 작업 디렉터리에 다운로드합니다.$wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/terraform/sap_hana_ha.tfCloud Shell 코드 편집기에서
sap_hana_ha.tf파일을 엽니다.Cloud Shell 코드 편집기를 열려면 Cloud Shell 터미널 창 오른쪽 상단에 있는 연필 아이콘을 클릭합니다.
sap_hana_ha.tf파일에서 큰따옴표 내 콘텐츠를 설치 값으로 바꿔 인수 값을 업데이트합니다. 인수는 다음 표에 설명되어 있습니다.인수 데이터 유형 설명 source문자열 배포 중에 사용할 Terraform 모듈의 위치와 버전을 지정합니다.
sap_hana_ha.tf구성 파일에는source인수의 인스턴스 두 개, 즉 활성 인스턴스와 주석으로 포함된 인스턴스가 포함됩니다. 기본적으로 활성화되는source인수는latest를 모듈 버전으로 지정합니다. 기본적으로 앞에 오는#문자에 의해 비활성화되는source인수의 두 번째 인스턴스에서 모듈 버전을 식별하는 타임스탬프를 지정합니다.모든 배포에서 동일한 모듈 버전을 사용해야 하는 경우 버전 타임스탬프를 지정하는
source인수에서 앞에 오는#문자를 삭제하고latest를 지정하는source인수에 추가합니다.project_id문자열 이 시스템을 배포할 Google Cloud 프로젝트의 ID를 지정합니다. 예를 들면 my-project-x입니다.machine_type문자열 SAP 시스템을 실행하는 데 필요한 Compute Engine 가상 머신(VM)의 유형을 지정합니다. 커스텀 VM 유형이 필요한 경우 사전 정의된 VM 유형을 필요한 수(더 큼)에 가장 가까운 vCPU 수로 지정합니다. 배포가 완료되면 vCPU 수와 메모리 양을 수정합니다. 예를 들면
n1-highmem-32입니다.sole_tenant_deployment불리언 선택사항입니다. SAP HANA 배포에 전용 테넌트 노드를 프로비저닝하려면 값
true을 지정합니다.기본값은
false입니다.이 인수는
sap_hana_ha버전1.3.704310921이상에서 사용할 수 있습니다.sole_tenant_name_prefix문자열 선택사항입니다. SAP HANA 배포에 대한 전용 테넌트 노드를 프로비저닝하는 경우 이 인수를 사용하여 Terraform이 해당 전용 테넌트 템플릿 및 전용 테넌트 그룹의 이름에 설정하는 접두사를 지정할 수 있습니다.
기본값은
st-SID_LC입니다.단독 테넌트 템플릿 및 단독 테넌트 그룹에 대한 자세한 내용은 단독 테넌시 개요를 참고하세요.
이 인수는
sap_hana_ha버전1.3.704310921이상에서 사용할 수 있습니다.sole_tenant_node_type문자열 선택사항입니다.SAP HANA 배포에 단독 테넌트 노드를 프로비저닝하려면 해당 노드 템플릿에 설정할 노드 유형을 지정합니다.
이 인수는
sap_hana_ha버전1.3.704310921이상에서 사용할 수 있습니다.network문자열 VIP를 관리하는 부하 분산기를 만들어야 하는 네트워크의 이름을 지정합니다. 공유 VPC 네트워크를 사용하는 경우 호스트 프로젝트의 ID를 네트워크 이름의 상위 디렉터리로 추가해야 합니다. 예를 들면
HOST_PROJECT_ID/NETWORK_NAME입니다.subnetwork문자열 이전 단계에서 만든 서브네트워크의 이름을 지정합니다. 공유 VPC에 배포하는 경우 이 값을 SHARED_VPC_PROJECT_ID/SUBNETWORK로 지정합니다. 예를 들면myproject/network1입니다.linux_image문자열 SAP 시스템을 배포할 Linux 운영체제 이미지의 이름을 지정합니다. 예를 들면 rhel-9-2-sap-ha또는sles-15-sp5-sap입니다. 사용 가능한 운영체제 이미지 목록은 Google Cloud 콘솔의 이미지 페이지를 참고하세요.linux_image_project문자열 인수 linux_image에 지정된 이미지가 포함된 Google Cloud 프로젝트를 지정합니다. 이 프로젝트는 자체 프로젝트이거나 Google Cloud 이미지 프로젝트일 수 있습니다. Compute Engine 이미지의 경우rhel-sap-cloud또는suse-sap-cloud를 지정합니다. 운영체제의 이미지 프로젝트를 찾으려면 운영체제 세부정보를 참고하세요.primary_instance_name문자열 기본 SAP HANA 시스템의 VM 인스턴스 이름을 지정합니다. 이름에 소문자, 숫자 또는 하이픈을 사용할 수 있습니다. primary_zone문자열 기본 SAP HANA 시스템이 배포되는 영역을 지정합니다. 기본 영역과 보조 영역은 같은 리전에 있어야 합니다. 예를 들면 us-east1-c입니다.secondary_instance_name문자열 보조 SAP HANA 시스템의 VM 인스턴스 이름을 지정합니다. 이름에 소문자, 숫자 또는 하이픈을 사용할 수 있습니다. secondary_zone문자열 보조 SAP HANA 시스템이 배포되는 영역을 지정합니다. 기본 영역과 보조 영역은 같은 리전에 있어야 합니다. 예를 들면 us-east1-b입니다.sap_hana_deployment_bucket문자열 배포된 VM에 SAP HANA를 자동으로 설치하려면 SAP HANA 설치 파일이 포함된 Cloud Storage 버킷의 경로를 지정합니다. 경로에 gs://를 포함하지 마세요. 버킷 이름과 폴더 이름만 포함하세요. 예를 들면my-bucket-name/my-folder입니다.Cloud Storage 버킷은
project_id인수에 지정하는 Google Cloud 프로젝트에 있어야 합니다.sap_hana_sid문자열 배포된 VM에 SAP HANA를 자동으로 설치하려면 SAP HANA 시스템 ID를 지정합니다. ID는 3자리 영숫자 문자로 구성되고 문자로 시작되어야 합니다. 모든 문자는 대문자여야 합니다. 예를 들면 ED1입니다.sap_hana_instance_number정수 선택사항. SAP HANA 시스템의 인스턴스 번호(0~99)를 지정합니다. 기본값은 0입니다.sap_hana_sidadm_password문자열 배포된 VM에 SAP HANA를 자동으로 설치하려면 배포 중에 사용할 설치 스크립트의 임시 SIDadm비밀번호를 지정합니다. 비밀번호는 8자 이상이어야 하며 대문자, 소문자, 숫자를 하나 이상 포함해야 합니다.비밀번호를 일반 텍스트로 지정하는 대신 보안 비밀을 사용하는 것이 좋습니다. 자세한 내용은 비밀번호 관리를 참조하세요.
sap_hana_sidadm_password_secret문자열 선택사항. Secret Manager를 사용하여 SIDadm비밀번호를 저장하는 경우 이 비밀번호에 해당하는 보안 비밀의 이름을 지정합니다.Secret Manager에서 비밀번호인 보안 비밀 값이 최소 8자 이상이며 대문자, 소문자, 숫자가 각각 최소 1자 이상 포함되는지 확인합니다.
자세한 내용은 비밀번호 관리를 참조하세요.
sap_hana_system_password문자열 배포된 VM에 SAP HANA를 자동으로 설치하려면 배포 중에 사용할 설치 스크립트의 임시 데이터베이스 수퍼유저 비밀번호를 지정합니다. 비밀번호는 최소 8자 이상이어야 하며 대문자, 소문자, 숫자를 각각 최소 1자 이상 포함해야 합니다. 비밀번호를 일반 텍스트로 지정하는 대신 보안 비밀을 사용하는 것이 좋습니다. 자세한 내용은 비밀번호 관리를 참조하세요.
sap_hana_system_password_secret문자열 선택사항. Secret Manager를 사용하여 데이터베이스 수퍼유저 비밀번호를 저장하는 경우 이 비밀번호에 해당하는 보안 비밀의 이름을 지정합니다. Secret Manager에서 비밀번호인 보안 비밀 값이 최소 8자 이상이며 대문자, 소문자, 숫자가 각각 최소 1자 이상 포함되는지 확인합니다.
자세한 내용은 비밀번호 관리를 참조하세요.
sap_hana_double_volume_size불리언 선택사항. HANA 볼륨 크기를 두 배로 늘리려면 true를 지정합니다. 이 인수는 같은 VM에 SAP HANA 인스턴스 여러 개나 재해 복구 SAP HANA 인스턴스를 배포하려는 경우에 유용합니다. 기본적으로 볼륨 크기는 SAP 자격증 요구사항과 지원 요구사항을 계속 충족하면서 VM 크기에 필요한 최소 크기로 자동 계산됩니다. 기본값은false입니다.sap_hana_backup_size정수 선택사항. /hanabackup볼륨 크기(GB)를 지정합니다. 이 인수를 지정하지 않거나0으로 설정하면 설치 스크립트에서 총 메모리 두 배인 HANA 백업 볼륨으로 Compute Engine 인스턴스를 프로비저닝합니다.sap_hana_sidadm_uid정수 선택사항. SID_LCadm 사용자 ID의 기본값을 재정의할 값을 지정합니다. 기본값은 900입니다. SAP 환경 내에서 일관성을 위해 이 값을 다른 값으로 변경할 수 있습니다.sap_hana_sapsys_gid정수 선택사항. sapsys의 기본 그룹 ID를 재정의합니다. 기본값은79입니다.sap_vip문자열 선택사항입니다. VIP에 사용할 IP 주소를 지정합니다. IP 주소는 서브네트워크에 할당된 IP 주소 범위 내에 있어야 합니다. Terraform 구성 파일에서 자동으로 이 IP 주소를 예약합니다.
sap_hana_ha모듈의 버전1.3.730053050부터sap_vip인수는 선택사항입니다. 지정하지 않으면 Terraform은subnetwork인수에 지정한 서브넷에서 사용 가능한 IP 주소를 자동으로 할당합니다.primary_instance_group_name문자열 선택사항. 기본 노드의 비관리형 인스턴스 그룹 이름을 정의합니다. 기본 이름은 ig-PRIMARY_INSTANCE_NAME입니다.secondary_instance_group_name문자열 선택사항. 보조 노드의 비관리형 인스턴스 그룹 이름을 지정합니다. 기본 이름은 ig-SECONDARY_INSTANCE_NAME입니다.loadbalancer_name문자열 선택사항. 내부 패스 스루 네트워크 부하 분산기의 이름을 지정합니다. 기본 이름은 lb-SAP_HANA_SID-ilb입니다.network_tags문자열 선택사항. 방화벽 또는 라우팅 목적으로 VM 인스턴스와 연결하려는 하나 이상의 쉼표로 구분된 네트워크 태그를 지정합니다. ILB 구성요소의 네트워크 태그는 VM의 네트워크 태그에 자동으로 추가됩니다.
nic_type문자열 선택사항. VM 인스턴스에 사용할 네트워크 인터페이스를 지정합니다. GVNIC또는VIRTIO_NET값을 지정할 수 있습니다. Google 가상 NIC(gVNIC)를 사용하려면 gVNIC를 지원하는 OS 이미지를linux_image인수의 값으로 지정해야 합니다. OS 이미지 목록은 운영체제 세부정보를 참조하세요.이 인수 값을 지정하지 않으면
이 인수는machine_type인수에 지정하는 머신 유형에 따라 네트워크 인터페이스가 자동으로 선택됩니다.sap_hana모듈 버전202302060649이상에서 사용할 수 있습니다.disk_type문자열 선택사항. 배포의 SAP 데이터와 로그 볼륨에 배포할 Persistent Disk 또는 하이퍼디스크 볼륨의 기본 유형을 지정합니다. Google Cloud에서 제공하는 Terraform 구성에서 수행하는 기본 디스크 배포에 대한 자세한 내용은 Terraform의 디스크 배포를 참고하세요. 이 인수에 유효한 값은
pd-ssd,pd-balanced,hyperdisk-extreme,hyperdisk-balanced,pd-extreme입니다. SAP HANA 수직 확장 배포에서는/hana/shared디렉터리에 별도의 균형 있는 영구 디스크도 배포됩니다.일부 고급 인수를 사용하여 이 기본 디스크 유형과 연결된 기본 디스크 크기 및 기본 IOPS를 재정의할 수 있습니다. 자세한 내용을 보려면 작업 디렉터리로 이동한 후
terraform init명령어를 실행한 후/.terraform/modules/sap_hana_ha/variables.tf파일을 확인합니다. 프로덕션에서 이러한 인수를 사용하려면 먼저 비프로덕션 환경에서 테스트해야 합니다.SAP HANA 네이티브 스토리지 확장(NSE)을 사용하려면 고급 인수를 사용하여 더 큰 디스크를 프로비저닝해야 합니다.
use_single_shared_data_log_disk불리언 선택사항. 기본값은 false이며 Terraform이 다음 SAP 볼륨/hana/data,/hana/log,/hana/shared,/usr/sap마다 별도의 영구 디스크 또는 하이퍼디스크를 배포하도록 지시합니다. 이러한 SAP 볼륨을 동일한 영구 디스크 또는 하이퍼디스크에 마운트하려면true를 지정합니다.enable_data_striping불리언 선택사항. 이 인수를 사용하면 /hana/data볼륨을 두 개의 디스크에 배포할 수 있습니다. 기본값은false이며 이는 Terraform이/hana/data볼륨을 호스팅하기 위해 단일 디스크를 배포하도록 지시합니다.이 인수는
sap_hana_ha모듈 버전1.3.674800406이상에서 사용할 수 있습니다.include_backup_disk불리언 선택사항. 이 인수는 SAP HANA 수직 확장 배포에 적용됩니다. 기본값은 true이며 Terraform이/hanabackup디렉터리를 호스팅하기 위해 별도의 디스크를 배포하도록 지시합니다.디스크 유형은
backup_disk_type인수에 따라 결정됩니다. 이 디스크의 크기는sap_hana_backup_size인수에 따라 결정됩니다.include_backup_disk값을false로 설정하면/hanabackup디렉터리에 디스크가 배포되지 않습니다.backup_disk_type문자열 선택사항. 수직 확장 배포의 경우 /hanabackup볼륨에 배포할 Persistent Disk 또는 하이퍼디스크 유형을 지정합니다. Google Cloud에서 제공하는 Terraform 구성에서 수행하는 기본 디스크 배포에 대한 자세한 내용은 Terraform의 디스크 배포를 참고하세요.이 인수에 유효한 값은
pd-ssd,pd-balanced,pd-standard,hyperdisk-extreme,hyperdisk-balanced,pd-extreme입니다.이 인수는
sap_hana_ha모듈 버전202307061058이상에서 사용할 수 있습니다.enable_fast_restart불리언 선택사항. 이 인수는 배포에 SAP HANA 빠른 재시작 옵션이 사용 설정되었는지 여부를 결정합니다. 기본값은 true입니다. Google Cloud 에서는 SAP HANA 빠른 재시작 옵션의 사용 설정을 적극 권장합니다.이 인수는
sap_hana_ha모듈 버전202309280828이상에서 사용할 수 있습니다.public_ip불리언 선택사항. 공개 IP 주소가 VM 인스턴스에 추가되는지 여부를 결정합니다. 기본값은 true입니다.service_account문자열 선택사항. 호스트 VM와 호스트 VM에서 실행되는 프로그램에서 사용할 사용자 관리형 서비스 계정의 이메일 주소를 지정합니다. 예를 들면 svc-acct-name@project-id.입니다.이 인수를 값 없이 지정하거나 생략하면 설치 스크립트에서 Compute Engine 기본 서비스 계정을 사용합니다. 자세한 내용은 Google Cloud에서 SAP 프로그램의 ID 및 액세스 관리를 참고하세요.
sap_deployment_debug불리언 선택사항. Cloud Customer Care에서 배포에 디버깅을 사용 설정하도록 요청하는 경우에만 true를 지정하여 배포 시 상세 배포 로그를 생성합니다. 기본값은false입니다.primary_reservation_name문자열 선택사항. 특정 Compute Engine VM 예약을 사용하여 HA 클러스터의 기본 SAP HANA 인스턴스를 호스팅하는 VM 인스턴스를 프로비저닝하려면 예약 이름을 지정합니다. 기본적으로 설치 스크립트는 다음 조건에 따라 사용 가능한 Compute Engine 예약을 선택합니다. 예약을 사용할 수 있도록 하려면 이름을 지정했는지 또는 설치 스크립트가 자동으로 예약을 선택했는지 여부에 관계없이 다음을 사용하여 예약을 설정해야 합니다.
-
specificReservationRequired옵션이true로 설정되거나 Google Cloud 콘솔에서 특정 예약 선택 옵션이 선택됩니다. -
일부 Compute Engine 머신 유형은 머신 유형의 SAP 인증서로 처리되지 않는 CPU 플랫폼을 지원합니다. 다음 머신 유형 중 하나에 대한 대상 예약인 경우 예약에서 다음과 같이 최소 CPU 플랫폼을 지정해야 합니다.
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
SAP에서 인증한 다른 모든 머신 유형의 최소 CPU 플랫폼은 SAP 최소 CPU 요구사항을 준수합니다. Google Cloud
secondary_reservation_name문자열 선택사항. 특정 Compute Engine VM 예약을 사용하여 HA 클러스터의 보조 SAP HANA 인스턴스를 호스팅하는 VM 인스턴스를 프로비저닝하려면 예약 이름을 지정합니다. 기본적으로 설치 스크립트는 다음 조건에 따라 사용 가능한 Compute Engine 예약을 선택합니다. 예약을 사용할 수 있도록 하려면 이름을 지정했는지 또는 설치 스크립트가 자동으로 예약을 선택했는지 여부에 관계없이 다음을 사용하여 예약을 설정해야 합니다.
-
specificReservationRequired옵션이true로 설정되거나 Google Cloud 콘솔에서 특정 예약 선택 옵션이 선택됩니다. -
일부 Compute Engine 머신 유형은 머신 유형의 SAP 인증서로 처리되지 않는 CPU 플랫폼을 지원합니다. 다음 머신 유형 중 하나에 대한 대상 예약인 경우 예약에서 다음과 같이 최소 CPU 플랫폼을 지정해야 합니다.
n1-highmem-32: Intel Broadwelln1-highmem-64: Intel Broadwelln1-highmem-96: Intel Skylakem1-megamem-96: Intel Skylake
SAP에서 인증한 다른 모든 머신 유형의 최소 CPU 플랫폼은 SAP 최소 CPU 요구사항을 준수합니다. Google Cloud
primary_static_ip문자열 선택사항. 고가용성 클러스터에서 기본 VM 인스턴스에 대해 적합한 고정 IP 주소를 지정합니다. 지정하지 않으면 VM 인스턴스에 대해 IP 주소가 자동으로 생성됩니다. 예를 들면 128.10.10.10입니다.이 인수는
sap_hana_ha모듈 버전202306120959이상에서 사용할 수 있습니다.secondary_static_ip문자열 선택사항. 고가용성 클러스터에서 보조 VM 인스턴스에 대해 적합한 고정 IP 주소를 지정합니다. 지정하지 않으면 VM 인스턴스에 대해 IP 주소가 자동으로 생성됩니다. 예를 들면 128.11.11.11입니다.이 인수는
sap_hana_ha모듈 버전202306120959이상에서 사용할 수 있습니다.can_ip_forward부울 일치하지 않는 소스 또는 대상 IP로 패킷의 전송 및 수신 허용 여부를 지정합니다. 그러면 VM이 라우터 역할을 합니다. 기본값은
true입니다.Google의 내부 부하 분산기만 사용하여 배포된 VM의 가상 IP를 관리하려면 값을
false로 설정합니다. 내부 부하 분산기는 고가용성 템플릿의 일부로 자동 배포됩니다.다음 예시에서는 SAP HANA용 고가용성 클러스터를 정의하는 완성된 구성 파일을 보여줍니다. 클러스터는 내부 패스 스루 네트워크 부하 분산기를 사용하여 VIP를 관리합니다.
Terraform은 구성 파일에 정의된 Google Cloud 리소스를 배포한 후 스크립트를 이어서 수행하여 운영체제를 구성하고 SAP HANA를 설치하고 복제를 구성하며 Linux HA 클러스터를 구성합니다.
RHEL또는SLES를 클릭하여 운영체제에 해당하는 예시를 확인합니다. 명확하게 하기 위해 구성 파일의 주석은 예시에서 생략됩니다.RHEL
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "rhel-8-4-sap-ha" linux_image_project = "rhel-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456." primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }SLES
# ... module "sap_hana_ha" { source = "https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # By default, this source file uses the latest release of the terraform module # for SAP on Google Cloud. To fix your deployments to a specific release # of the module, comment out the source argument above and uncomment the source argument below. # # source = "https://storage.googleapis.com/cloudsapdeploy/terraform/YYYYMMDDHHMM/terraform/sap_hana_ha/sap_hana_ha_module.zip" # # ... # project_id = "example-project-123456" machine_type = "n2-highmem-32" network = "example-network" subnetwork = "example-subnet-us-central1" linux_image = "sles-15-sp3-sap" linux_image_project = "suse-sap-cloud" primary_instance_name = "example-ha-vm1" primary_zone = "us-central1-a" secondary_instance_name = "example-ha-vm2" secondary_zone = "us-central1-c" # ... sap_hana_deployment_bucket = "my-hana-bucket" sap_hana_sid = "HA1" sap_hana_instance_number = 00 sap_hana_sidadm_password = "TempPa55word" sap_hana_system_password = "TempPa55word" # ... sap_vip = 10.0.0.100 primary_instance_group_name = ig-example-ha-vm1 secondary_instance_group_name = ig-example-ha-vm2 loadbalancer_name = lb-ha1 # ... network_tags = hana-ha-ntwk-tag service_account = "sap-deploy-example@example-project-123456." primary_static_ip = "10.0.0.1" secondary_static_ip = "10.0.0.2" enable_fast_restart = true # ... }-
현재 작업 디렉터리를 초기화하고 Google Cloud용 Terraform 제공업체 플러그인과 모듈 파일을 다운로드합니다.
terraform init
terraform init명령어는 다른 Terraform 명령어를 위한 작업 디렉터리를 준비합니다.작업 디렉터리에서 제공업체 플러그인과 구성 파일을 강제로 새로고침하려면
--upgrade플래그를 지정합니다.--upgrade플래그가 생략되고 작업 디렉터리를 변경하지 않으면 Terraform은latest가sourceURL에 지정되더라도 로컬에서 캐시된 복사본을 사용합니다.terraform init --upgrade
선택적으로 Terraform 실행 계획을 만듭니다.
terraform plan
terraform plan명령어에서는 현재 구성에 필요한 변경사항을 보여줍니다. 이 단계를 건너뛰면terraform apply명령어가 자동으로 새 계획을 만들고 승인하라는 메시지를 표시합니다.실행 계획을 적용합니다.
terraform apply
작업을 승인하라는 메시지가 표시되면
yes를 입력합니다.terraform apply명령어는 인프라를 설정한 후 Terraform 구성 파일에 정의된 인수에 따라 HA 클러스터를 구성하고 SAP HANA를 설치하는 스크립트를 직접 제어합니다. Google CloudTerraform에는 제어 기능이 있지만 상태 메시지는 Cloud Shell에 기록됩니다. 스크립트가 호출되면 상태 메시지는 Logging에 기록되고 로그 확인의 설명대로 Google Cloud 콘솔에서 이 메시지를 볼 수 있습니다.
HANA HA 시스템 배포 확인
SAP HANA HA 클러스터 확인에는 다음과 같은 여러 다양한 절차가 포함됩니다.
- Logging 확인
- SAP HANA 설치 및 VM의 구성 확인
- 클러스터 구성 확인
- 부하 분산기 및 인스턴스 그룹 상태 확인
- SAP HANA Studio를 사용하여 SAP HANA 시스템 확인
- 장애 조치 테스트 수행
로그 확인
Google Cloud 콘솔에서 Cloud Logging을 열어 설치 진행 상태를 모니터링하고 오류를 확인합니다.
로그를 필터링합니다.
로그 탐색기
로그 탐색기 페이지에서 쿼리 창으로 이동합니다.
리소스 드롭다운 메뉴에서 전역을 선택한 후 추가를 클릭합니다.
전역 옵션이 표시되지 않으면 쿼리 편집기에 다음 쿼리를 입력합니다.
resource.type="global" "Deployment"쿼리 실행을 클릭합니다.
기존 로그 뷰어
- 기존 로그 뷰어 페이지의 기본 선택기 메뉴에서 전역을 로깅 리소스로 선택합니다.
필터링된 로그를 분석합니다.
"--- Finished"가 표시되면 배포 처리가 완료된 것이므로 다음 단계를 진행할 수 있습니다.할당량 오류가 표시되면 다음을 수행합니다.
IAM 및 관리자 할당량 페이지에서 SAP HANA 계획 가이드에 나와 있는 SAP HANA 요구사항을 충족하지 않는 할당량을 늘립니다.
Cloud Shell을 엽니다.
작업 디렉터리로 이동하고 배포를 삭제하여 설치에 실패한 VM과 영구 디스크를 삭제합니다.
terraform destroy
작업을 승인하라는 메시지가 표시되면
yes를 입력합니다.배포를 다시 실행합니다.
SAP HANA 설치 및 VM의 구성 확인
SAP HANA 시스템이 오류 없이 배포되면 SSH를 사용하여 각 VM에 연결합니다. Compute Engine VM 인스턴스 페이지에서 각 VM 인스턴스의 SSH 버튼을 클릭하거나 선호하는 SSH 방법을 사용할 수 있습니다.

루트 사용자로 변경합니다.
sudo su -
명령 프롬프트에서
df -h를 입력합니다. 출력에/hana/data같은/hana디렉터리가 표시되는지 확인합니다.RHEL
[root@example-ha-vm1 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 0 126G 0% /dev tmpfs 126G 54M 126G 1% /dev/shm tmpfs 126G 25M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda2 30G 5.4G 25G 18% / /dev/sda1 200M 6.9M 193M 4% /boot/efi /dev/mapper/vg_hana-shared 251G 52G 200G 21% /hana/shared /dev/mapper/vg_hana-sap 32G 477M 32G 2% /usr/sap /dev/mapper/vg_hana-data 426G 9.8G 417G 3% /hana/data /dev/mapper/vg_hana-log 125G 7.0G 118G 6% /hana/log /dev/mapper/vg_hanabackup-backup 512G 9.3G 503G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/899 tmpfs 26G 0 26G 0% /run/user/1003
SLES
example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 54M 189G 1% /dev/shm tmpfs 126G 34M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 30G 5.4G 25G 18% / /dev/sda2 20M 2.9M 18M 15% /boot/efi /dev/mapper/vg_hana-shared 251G 50G 202G 20% /hana/shared /dev/mapper/vg_hana-sap 32G 281M 32G 1% /usr/sap /dev/mapper/vg_hana-data 426G 8.0G 418G 2% /hana/data /dev/mapper/vg_hana-log 125G 4.3G 121G 4% /hana/log /dev/mapper/vg_hanabackup-backup 512G 6.4G 506G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/473 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1003
사용자의 운영체제에 해당하는 상태 명령어를 입력하여 새 클러스터의 상태를 확인합니다.
RHEL
pcs statusSLES
crm status출력은 다음 예시와 비슷합니다. 이 예시에서는 두 VM 인스턴스가 모두 시작되고
example-ha-vm1이 활성 기본 인스턴스입니다.RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.4-4b1f869f0f) - partition with quorum * Last updated: Wed Jul 7 23:05:11 2021 * Last change: Wed Jul 7 23:04:43 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ] Failed Resource Actions: * rsc_healthcheck_HA1_start_0 on example-ha-vm1 'error' (1): call=29, status='complete', exitreason='', last-rc-change='2021-07-07 21:07:35Z', queued=0ms, exec=2097ms * SAPHana_HA1_00_monitor_61000 on example-ha-vm1 'not running' (7): call=44, status='complete', exitreason='', last-rc-change='2021-07-07 21:09:49Z', queued=0ms, exec=0ms Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledSLES for SAP 15 SP5 이하
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Wed Jul 7 22:57:59 2021 * Last change: Wed Jul 7 22:57:03 2021 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]SLES for SAP 15 SP6 이상
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Mon Oct 7 22:57:59 2024 * Last change: Mon Oct 7 22:57:03 2024 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]다음 명령어에서 SID_LC를
sap_hana_ha.tf파일에 지정한sap_hana_sid값으로 바꿔 SAP 관리자로 변경합니다. SID_LC 값은 소문자여야 합니다.su - SID_LCadm다음 명령어를 입력하여 SAP HANA 서비스(예:
hdbnameserver,hdbindexserver)가 인스턴스에서 실행 중인지 확인합니다.HDB infoRHEL for SAP 9.0 이상을 사용하는 경우
chkconfig및compat-openssl11패키지가 VM 인스턴스에 설치되어 있는지 확인합니다.SAP의 자세한 내용은 SAP Note 3108316 - Red Hat Enterprise Linux 9.x: Installation and Configuration을 참조하세요.
클러스터 구성 확인
클러스터의 매개변수 설정을 확인합니다. 클러스터 소프트웨어에 표시된 설정과 클러스터 구성 파일의 매개변수 설정을 모두 확인합니다. 이 가이드에서 사용되는 자동화 스크립트에서 만든 아래 예시의 설정과 자체 설정을 비교합니다.
운영체제 탭을 클릭합니다.
RHEL
클러스터 리소스 구성을 표시합니다.
pcs config show
다음 예시는 RHEL 8.1 이상에서 자동화 스크립트로 만든 리소스 구성을 보여줍니다.
RHEL 7.7 이하를 실행하는 경우 리소스 정의
Clone: SAPHana_HA1_00-clone에Meta Attrs: promotable=true가 포함되지 않습니다.Cluster Name: hacluster Corosync Nodes: example-rha-vm1 example-rha-vm2 Pacemaker Nodes: example-rha-vm1 example-rha-vm2 Resources: Group: g-primary Resource: rsc_healthcheck_HA1 (class=service type=haproxy) Operations: monitor interval=10s timeout=20s (rsc_healthcheck_HA1-monitor-interval-10s) start interval=0s timeout=100 (rsc_healthcheck_HA1-start-interval-0s) stop interval=0s timeout=100 (rsc_healthcheck_HA1-stop-interval-0s) Resource: rsc_vip_HA1_00 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=32 ip=10.128.15.100 nic=eth0 Operations: monitor interval=3600s timeout=60s (rsc_vip_HA1_00-monitor-interval-3600s) start interval=0s timeout=20s (rsc_vip_HA1_00-start-interval-0s) stop interval=0s timeout=20s (rsc_vip_HA1_00-stop-interval-0s) Clone: SAPHanaTopology_HA1_00-clone Meta Attrs: clone-max=2 clone-node-max=1 interleave=true Resource: SAPHanaTopology_HA1_00 (class=ocf provider=heartbeat type=SAPHanaTopology) Attributes: InstanceNumber=00 SID=HA1 Operations: methods interval=0s timeout=5 (SAPHanaTopology_HA1_00-methods-interval-0s) monitor interval=10 timeout=600 (SAPHanaTopology_HA1_00-monitor-interval-10) reload interval=0s timeout=5 (SAPHanaTopology_HA1_00-reload-interval-0s) start interval=0s timeout=600 (SAPHanaTopology_HA1_00-start-interval-0s) stop interval=0s timeout=300 (SAPHanaTopology_HA1_00-stop-interval-0s) Clone: SAPHana_HA1_00-clone Meta Attrs: promotable=true Resource: SAPHana_HA1_00 (class=ocf provider=heartbeat type=SAPHana) Attributes: AUTOMATED_REGISTER=true DUPLICATE_PRIMARY_TIMEOUT=7200 InstanceNumber=00 PREFER_SITE_TAKEOVER=true SID=HA1 Meta Attrs: clone-max=2 clone-node-max=1 interleave=true notify=true Operations: demote interval=0s timeout=3600 (SAPHana_HA1_00-demote-interval-0s) methods interval=0s timeout=5 (SAPHana_HA1_00-methods-interval-0s) monitor interval=61 role=Slave timeout=700 (SAPHana_HA1_00-monitor-interval-61) monitor interval=59 role=Master timeout=700 (SAPHana_HA1_00-monitor-interval-59) promote interval=0s timeout=3600 (SAPHana_HA1_00-promote-interval-0s) reload interval=0s timeout=5 (SAPHana_HA1_00-reload-interval-0s) start interval=0s timeout=3600 (SAPHana_HA1_00-start-interval-0s) stop interval=0s timeout=3600 (SAPHana_HA1_00-stop-interval-0s) Stonith Devices: Resource: STONITH-example-rha-vm1 (class=stonith type=fence_gce) Attributes: pcmk_delay_max=30 pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm1 project=example-project-123456 zone=us-central1-a Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm1-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm1-start-interval-0) Resource: STONITH-example-rha-vm2 (class=stonith type=fence_gce) Attributes: pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm2 project=example-project-123456 zone=us-central1-c Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm2-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm2-start-interval-0) Fencing Levels: Location Constraints: Resource: STONITH-example-rha-vm1 Disabled on: example-rha-vm1 (score:-INFINITY) (id:location-STONITH-example-rha-vm1-example-rha-vm1--INFINITY) Resource: STONITH-example-rha-vm2 Disabled on: example-rha-vm2 (score:-INFINITY) (id:location-STONITH-example-rha-vm2-example-rha-vm2--INFINITY) Ordering Constraints: start SAPHanaTopology_HA1_00-clone then start SAPHana_HA1_00-clone (kind:Mandatory) (non-symmetrical) (id:order-SAPHanaTopology_HA1_00-clone-SAPHana_HA1_00-clone-mandatory) Colocation Constraints: g-primary with SAPHana_HA1_00-clone (score:4000) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-g-primary-SAPHana_HA1_00-clone-4000) Ticket Constraints: Alerts: No alerts defined Resources Defaults: migration-threshold=5000 resource-stickiness=1000 Operations Defaults: timeout=600s Cluster Properties: cluster-infrastructure: corosync cluster-name: hacluster dc-version: 2.0.2-3.el8_1.2-744a30d655 have-watchdog: false stonith-enabled: true stonith-timeout: 300s Quorum: Options:클러스터 구성 파일
corosync.conf를 표시합니다.cat /etc/corosync/corosync.conf
다음 예시는 RHEL 8.1 이상에서 자동화 스크립트가 설정한 매개변수를 보여줍니다.
RHEL 7.7 이하를 사용하는 경우
transport:값은knet대신udpu입니다.totem { version: 2 cluster_name: hacluster transport: knet join: 60 max_messages: 20 token: 20000 token_retransmits_before_loss_const: 10 crypto_cipher: aes256 crypto_hash: sha256 } nodelist { node { ring0_addr: example-rha-vm1 name: example-rha-vm1 nodeid: 1 } node { ring0_addr: example-rha-vm2 name: example-rha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum two_node: 1 } logging { to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes timestamp: on }
SLES for SAP 15 SP5 이하
클러스터 리소스 구성을 표시합니다.
crm config show
이 가이드에서 사용되는 자동화 스크립트는 다음 예시와 같이 리소스 구성을 만듭니다.
node 1: example-ha-vm1 \ attributes hana_ha1_op_mode=logreplay lpa_ha1_lpt=1635380335 hana_ha1_srmode=syncmem hana_ha1_vhost=example-ha-vm1 hana_ha1_remoteHost=example-ha-vm2 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes lpa_ha1_lpt=30 hana_ha1_op_mode=logreplay hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 hana_ha1_srmode=syncmem hana_ha1_remoteHost=example-ha-vm1 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHana \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta notify=true clone-max=2 clone-node-max=1 target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600클러스터 구성 파일
corosync.conf를 표시합니다.cat /etc/corosync/corosync.conf
이 가이드에서 사용되는 자동화 스크립트는 다음 예시와 같이
corosync.conf파일에 매개변수 설정을 지정합니다.totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
SLES for SAP 15 SP6 이상
클러스터 리소스 구성을 표시합니다.
crm config show
이 가이드에서 사용되는 자동화 스크립트는 다음 예시와 같이 리소스 구성을 만듭니다.
node 1: example-ha-vm1 \ attributes hana_ha1_vhost=example-ha-vm1 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 primitive STONITH-example-ha-vm1 stonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm1 zone="us-central1-a" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 sstonith:fence_gce \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params port=example-ha-vm2 zone="us-central1-c" project="example-project-123456" pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHanaFileSystem_HA1_HDB00 ocf:suse:SAPHanaFilesystem \ operations $id=rsc_sap3_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHanaController \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Promoted timeout=700 \ op monitor interval=61 role=Unpromoted timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary meta resource-stickiness=0 clone mst_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta clone-node-max=1 promotable=true interleave=true clone cln_SAPHanaFileSystem_HA1_HDB00 rsc_SAPHanaFileSystem_HA1_HDB00 \ meta clone-node-max=1 interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started mst_SAPHana_HA1_HDB00:Promoted order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 mst_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600클러스터 구성 파일
corosync.conf를 표시합니다.cat /etc/corosync/corosync.conf
이 가이드에서 사용되는 자동화 스크립트는 다음 예시와 같이
corosync.conf파일에 매개변수 설정을 지정합니다.totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
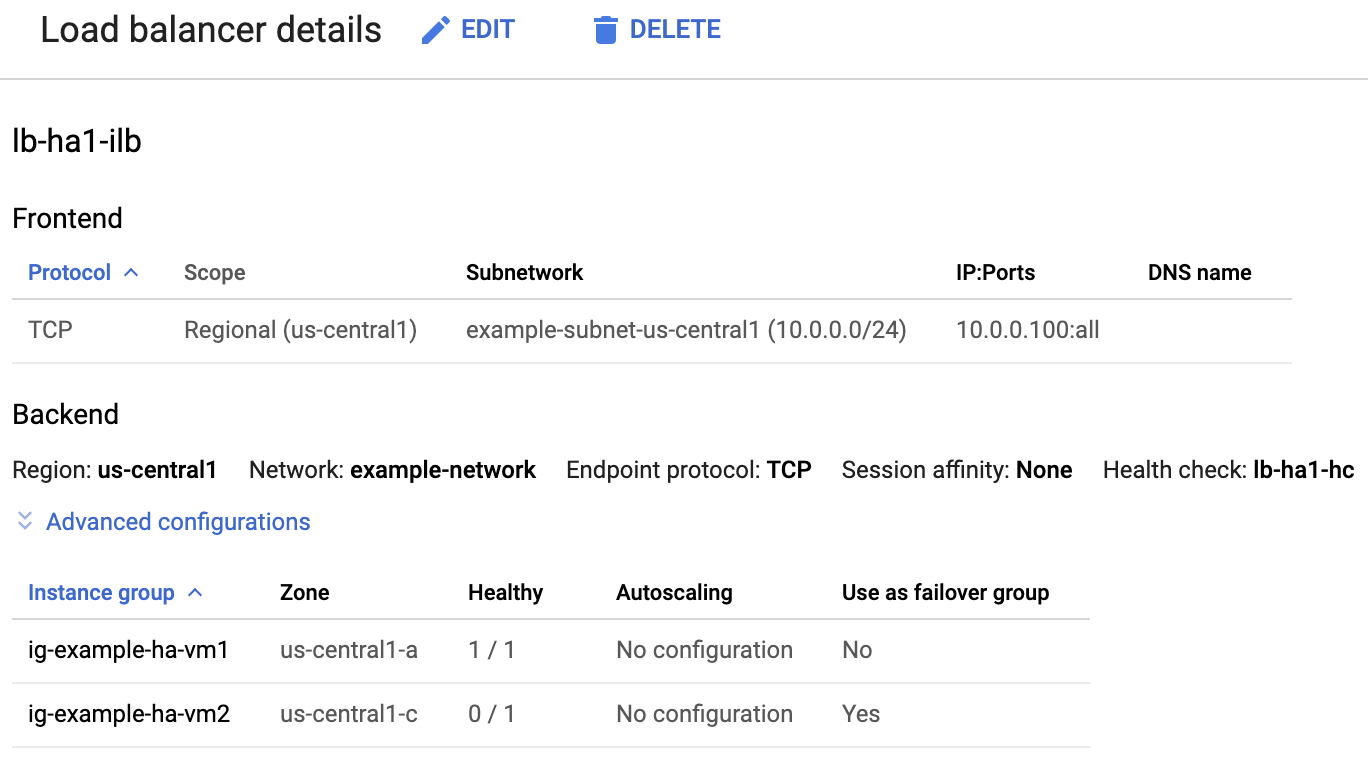
부하 분산기 및 인스턴스 그룹 상태 확인
부하 분산기와 상태 점검이 올바르게 설정되었는지 확인하려면 Google Cloud 콘솔에서 부하 분산기와 인스턴스 그룹을 확인합니다.
Google Cloud 콘솔에서 부하 분산 페이지를 엽니다.
부하 분산기 목록에서 HA 클러스터용 부하 분산기가 생성되었는지 확인합니다.
백엔드 섹션의 인스턴스 그룹에서 정상 열의 부하 분산기 세부정보 페이지에서 인스턴스 그룹 중 하나가 '1/1'로 표시되고 다른 그룹은 '0/1'로 표시되는지 확인합니다. 장애 조치 후 정상 표시기인 '1/1'이 새 활성 인스턴스 그룹으로 전환됩니다.
SAP HANA Studio를 사용하여 SAP HANA 시스템 확인
SAP HANA Cockpit 또는 SAP HANA Studio를 사용하여 고가용성 클러스터에서 SAP HANA 시스템을 모니터링하고 관리할 수 있습니다.
SAP HANA Studio를 사용하여 HANA 시스템에 연결합니다. 연결을 정의할 때 다음 값을 지정합니다.
- Specify System(시스템 지정) 패널에서 Host Name(호스트 이름)으로 유동 IP 주소를 지정합니다.
- Connection Properties(연결 속성) 패널에서 데이터베이스 사용자 인증에 데이터베이스 수퍼유저 이름과
sap_hana_ha.tf파일의sap_hana_system_password인수에 지정한 비밀번호를 지정합니다.
SAP HANA Studio 설치에 대한 SAP 정보는 SAP HANA Studio 설치 및 업데이트 가이드를 참조하세요.
SAP HANA Studio가 HANA HA 시스템에 연결된 후 창 왼쪽의 탐색창에 있는 시스템 이름을 더블클릭하여 시스템 개요를 표시합니다.
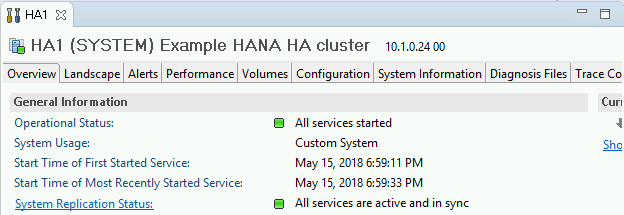
Overview(개요) 탭의 General Information(일반 정보) 아래에서 다음을 확인합니다.
- Operational Status(운영 상태)가 'All services started(모든 서비스 시작됨)'로 표시됩니다.
- System Replication Status(시스템 복제 상태)가 'All services are active and in sync(모든 서비스가 활성이며 동기화됨)'로 표시됩니다.
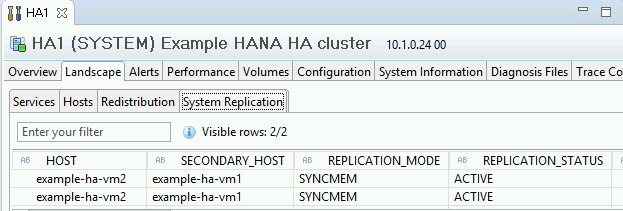
General Information(일반 정보) 아래의 System Replication Status(시스템 복제 상태) 링크를 클릭하여 복제 모드를 확인합니다. 동기 복제는 System Replication(시스템 복제) 탭에서 REPLICATION_MODE 열의
SYNCMEM에 나타납니다.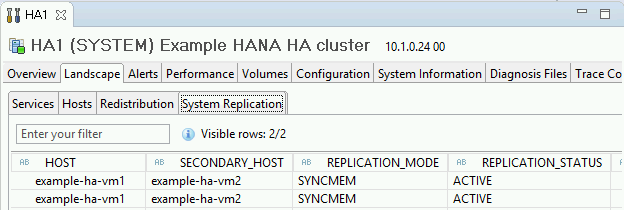
배포 삭제 및 재시도
이전 섹션의 배포 확인 단계에서 설치 실패를 표시하면 다음 단계를 완료하여 배포를 실행취소하고 재시도해야 합니다.
같은 이유로 배포가 다시 실패하지 않도록 오류를 해결합니다. 로그 확인 또는 할당량 관련 오류 해결에 대한 자세한 내용은 로그 확인을 참조하세요.
Cloud Shell을 열거나 로컬 워크스테이션에 Google Cloud CLI를 설치한 경우에는 터미널을 엽니다.
이 배포에 사용된 Terraform 구성 파일이 있는 디렉터리로 이동합니다.
다음 명령어를 실행하여 배포에 포함된 모든 리소스를 삭제합니다.
terraform destroy
작업을 승인하라는 메시지가 표시되면
yes를 입력합니다.이 가이드의 앞부분에서 설명한 대로 배포를 재시도합니다.
장애 조치 테스트 수행
장애 조치 테스트를 수행하려면 다음 단계를 완료합니다.
SSH를 사용하여 기본 VM에 연결합니다. 각 VM 인스턴스의 SSH 버튼을 클릭하여 Compute Engine VM 인스턴스 페이지에서 연결하거나 선호하는 SSH 방법을 사용할 수 있습니다.
명령어 프롬프트에서 다음 명령어를 입력합니다.
sudo ip link set eth0 down
ip link set eth0 down명령어는 기본 호스트와의 통신을 끊어 장애 조치를 트리거합니다.SSH를 사용하여 두 호스트 중 하나에 다시 연결하고 루트 사용자로 변경합니다.
보조 호스트를 포함하는 데 사용됐던 VM에서 지금 기본 호스트가 활성 상태임을 확인합니다. 클러스터에 자동으로 다시 시작이 사용 설정되어, 중지된 호스트가 다시 시작되고 보조 호스트 역할이 할당됩니다.
RHEL
pcs statusSLES
crm status다음 예시에서는 각 호스트의 역할이 전환되었음을 보여줍니다.
RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.3-4b1f869f0f) - partition with quorum * Last updated: Fri Mar 19 21:22:07 2021 * Last change: Fri Mar 19 21:21:28 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES for SAP 15 SP5 이하
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Thu Jul 8 17:33:44 2021 * Last change: Thu Jul 8 17:33:07 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES for SAP 15 SP6 이상
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.1.7+20231219.0f7f88312-150600.6.3.1-2.1.7+20231219.0f7f88312) - partition with quorum * Last updated: Tue Oct 8 21:47:19 2024 * Last change: Tue Oct 8 21:47:13 2024 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: cln_SAPHanaFileSystem_HA1_HDB00 [rsc_SAPHanaFileSystem_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: mst_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]콘솔의 부하 분산기 세부정보 페이지에서 새 활성 기본 인스턴스가 정상 열에 '1/1'을 표시하는지 확인합니다. 필요한 경우 페이지를 새로고칩니다.
예를 들면 다음과 같습니다.

SAP HANA Studio에서 탐색창의 시스템 항목을 더블클릭하여 시스템 정보를 새로고쳐 시스템에 여전히 연결되어 있는지 확인합니다.
System Replication Status(시스템 복제 상태) 링크를 클릭하여 기본 및 보조 호스트가 호스트를 바꿨고 활성 상태인지 확인합니다.
SAP용 Google Cloud에이전트 설치 검증
VM을 배포하고 SAP 시스템을 설치했으면Google Cloud의 SAP용 에이전트가 올바르게 작동하는지 확인합니다.
SAP용 Google Cloud에이전트가 실행 중인지 확인
에이전트가 실행 중인지 확인하려면 다음 단계를 따릅니다.
Compute Engine 인스턴스와 SSH 연결을 설정합니다.
다음 명령어를 실행합니다.
systemctl status google-cloud-sap-agent
에이전트가 올바르게 작동하는 경우 출력에
active (running)이 포함됩니다. 예를 들면 다음과 같습니다.google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
에이전트가 실행되고 있지 않으면 에이전트를 다시 시작합니다.
SAP 호스트 에이전트가 측정항목을 수신하는지 확인
Google Cloud의 SAP용 에이전트가 인프라 측정항목을 수집하고 SAP 호스트 에이전트로 올바르게 전송하는지 확인하려면 다음 단계를 따르세요.
- SAP 시스템에서
ST06트랜잭션을 입력합니다. 개요 창에서 다음 필드의 가용성과 콘텐츠를 확인하여 SAP 및 Google 모니터링 인프라의 엔드 투 엔드 설정이 올바른지 확인합니다.
- 클라우드 제공업체:
Google Cloud Platform - 향상된 모니터링 액세스:
TRUE - 향상된 모니터링 세부정보:
ACTIVE
- 클라우드 제공업체:
SAP HANA 모니터링 설정
원하는 경우Google Cloud의 SAP용 에이전트를 사용하여 SAP HANA 인스턴스를 모니터링할 수 있습니다. 버전 2.0부터는 SAP HANA 모니터링 측정항목을 수집하고 이를 Cloud Monitoring으로 전송하도록 에이전트를 구성할 수 있습니다. Cloud Monitoring을 사용하면 대시보드를 만들어서 이러한 측정항목을 시각화하고, 측정항목 임곗값을 기반으로 알림을 설정할 수 있습니다.
SAP용 Google Cloud에이전트를 사용하여 HA 클러스터를 모니터링하려면 에이전트에 대한 고가용성 구성에 설명된 안내를 따르세요.SAP용Google Cloud에이전트를 사용하는 SAP HANA 모니터링 측정항목 수집에 대한 자세한 내용은 SAP HANA 모니터링 측정항목 수집을 참고하세요.
SAP HANA에 연결
이 안내에서는 SAP HANA에 외부 IP 주소를 사용하지 않으므로 SSH를 사용하여 배스천 인스턴스를 통하거나 SAP HANA Studio를 사용하여 Windows Server를 통해서만 SAP HANA 인스턴스에 연결할 수 있습니다.
배스천 인스턴스를 통해 SAP HANA에 연결하려면 배스천 호스트에 연결한 다음 원하는 SSH 클라이언트를 사용하여 SAP HANA 인스턴스에 연결합니다.
SAP HANA Studio를 통해 SAP HANA 데이터베이스에 연결하려면 원격 데스크톱 클라이언트를 사용하여 Windows Server 인스턴스에 연결합니다. 연결 후 수동으로 SAP HANA Studio를 설치하고 SAP HANA 데이터베이스에 액세스합니다.
HANA 활성/활성(읽기 지원) 구성
SAP HANA 2.0 SPS1부터는 Pacemaker 클러스터에서 HANA 활성/활성(읽기 지원)을 구성할 수 있습니다. 자세한 안내는 다음을 참조하세요.
배포 후 작업 수행
SAP HANA 인스턴스를 사용하기 전에 다음과 같은 배포 후 단계를 수행하는 것이 좋습니다. 자세한 내용은 SAP HANA 설치 및 업데이트 가이드를 참조하세요.
SAP HANA 시스템 관리자와 데이터베이스 수퍼유저의 임시 비밀번호를 변경합니다.
SAP HANA 소프트웨어를 최신 패치로 업데이트합니다.
SAP HANA 시스템이 VirtIO 네트워크 인터페이스에 배포된 경우 TCP 매개변수
/proc/sys/net/ipv4/tcp_limit_output_bytes값이1048576으로 설정되어 있는지 확인하는 것이 좋습니다. 이러한 수정은 네트워크 지연 시간에 영향을 주지 않으면서 VirtIO 네트워크 인터페이스에서 전체적인 네트워크 처리량을 향상시키는 데 도움이 됩니다.Application Function Libraries(AFL) 또는 Smart Data Access(SDA)와 같은 추가 구성요소를 설치합니다.
새로운 SAP HANA 데이터베이스를 구성 및 백업합니다. 자세한 내용은 SAP HANA 운영 가이드를 참조하세요.
SAP HANA 워크로드 평가
Google Cloud에서 실행되는 SAP HANA 고가용성 워크로드에 대한 지속적 유효성 검사를 자동화하려면 워크로드 관리자를 사용하면 됩니다.
워크로드 관리자를 사용하면 SAP HANA 고가용성 워크로드를 SAP, Google Cloud, OS 공급업체의 권장사항에 따라 자동으로 스캔하고 평가할 수 있습니다. 이를 통해 워크로드의 품질, 성능, 안정성을 향상시킬 수 있습니다.
Google Cloud에서 실행되는 SAP HANA 고가용성 워크로드를 평가할 수 있도록 워크로드 관리자가 지원하는 권장사항에 대한 자세한 내용은 SAP용 워크로드 관리자 권장사항을 참고하세요. 워크로드 관리자를 사용하여 평가를 만들고 실행하는 방법은 평가 작성 및 실행을 참고하세요.
다음 단계
-
SAP 15 SP4 또는 SP5용 SLES를 사용하는 경우 HA 클러스터에서 SUSE
SAPHanaSR-angi리소스 에이전트로 업그레이드하는 방법에 관한 자세한 내용은 SLES의 확장 HA 클러스터에서SAPHanaSR를SAPHanaSR-angi로 업그레이드를 참고하세요. /hana/shared또는/hanabackup와 같은 SAP HANA 디렉터리를 호스팅하기 위해 영구 디스크 또는 Hyperdisk 볼륨 대신 Google Cloud NetApp 볼륨을 사용해야 하는 경우 SAP HANA 계획 가이드의 NetApp 볼륨 배포 정보를 참고하세요.- VM 관리 및 모니터링에 대한 자세한 내용은 SAP HANA 작업 가이드를 참조하세요.