En esta guía, se proporciona una descripción general de las opciones de recuperación ante desastres para los sistemas SAP HANA implementados en Google Cloud.
Esta guía no tiene como objetivo reemplazar la documentación estándar de SAP.
Prepárate para la recuperación ante desastres
A fin de prepararte para los desastres, puedes usar la replicación del sistema SAP HANA en un sistema SAP HANA secundario, realizar copias de seguridad de SAP HANA a fin de habilitar la recuperación, o ambos.
Para cargas de trabajo esenciales que requieren tiempos de recuperación rápidos, usa la replicación del sistema HANA a fin de minimizar el tiempo de inactividad. El uso de copias de seguridad para recuperar un sistema cuesta menos, pero lleva más tiempo, ya que se debe crear un sistema nuevo y, luego, restablecer las copias de seguridad en el momento deseado.
En cualquier caso, debes usar el redireccionamiento basado en la red para redireccionar las aplicaciones cliente que usan el sistema SAP HANA a la dirección IP del sistema de reemplazo una vez que esté disponible. Para obtener más información, consulta la Guía de administración de SAP HANA.
A partir de SAP HANA SPS09, puedes usar la API basada en Python incluida en SAP HANA a fin de crear tu propio proveedor de alta disponibilidad/recuperación ante desastres (HA/DR) e integrarlo en el proceso de toma de control de la replicación del sistema SAP HANA para automatizar tareas como el redireccionamiento de las conexiones de cliente de la base de datos del sistema principal al secundario después de una toma de control. Para obtener más información, consulta Implementing a HA/DR Provider (Implementa un proveedor de HA/DR).
Ten en cuenta que cualquier restricción que SAP define, incluida la limitación de distancia para la replicación síncrona, también está vigente en Google Cloud.
Como alternativa a las opciones de recuperación ante desastres nativas, para la recuperación ante desastres (pasiva) activa-pasiva (DR), puedes usar la replicación asíncrona de Persistent Disk (replicación asíncrona de PD). PD Async Replication proporciona replicación asíncrona de datos entre dos regiones deGoogle Cloud .
Recuperación ante desastres mediante la replicación del sistema SAP HANA
Para maximizar el uso de los recursos de infraestructura y optimizar los costos de la solución de DR, puedes usar el sistema secundario para los casos prácticos que no sean de producción, como un sistema de control de calidad o de desarrollo. En este caso, el sistema secundario no está precargado con datos, por lo que la conmutación por error tarda más tiempo que tener el sistema secundario precargado con datos y mantenerlo sincronizado con el sistema principal.
En HANA 2 SPS00, se incluye compatibilidad con el modo de configuración Activa/Activa (lectura habilitada), que permite que la replicación del sistema SAP HANA admita el acceso de lectura en el sistema secundario. Para obtener más información, consulta Activa/Activa (lectura habilitada).
Se admite la replicación síncrona y asíncrona cuando se usa la replicación del sistema SAP HANA con Google Cloud.
Si es posible, recomendamos usar la replicación síncrona, en la que las transacciones de SQL no se confirman en la instancia de la base de datos principal hasta que se confirman en la instancia en espera. Esto mantiene la instancia en espera 100% sincronizada y garantiza un objetivo de punto de recuperación cero. Se puede usar la replicación síncrona para instancias que residen en cualquier zona dentro de la misma región.
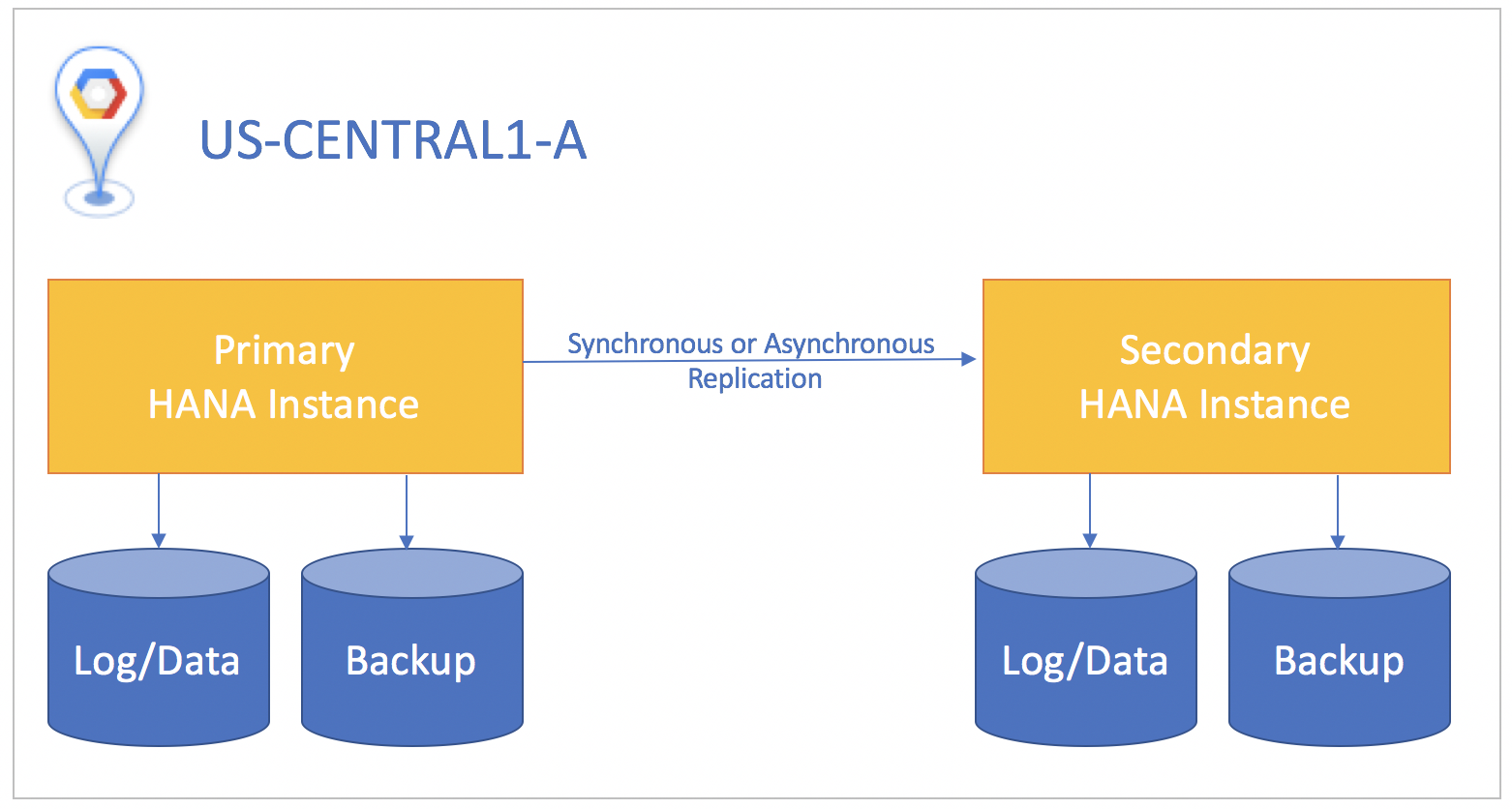
Si el sistema en espera está en una región diferente del sistema principal, usa la replicación asíncrona, en la que no hay que esperar a que la instancia en espera reconozca los datos antes de la confirmación en la instancia principal. En este caso, es posible que pierdas pequeñas cantidades de datos si ocurre un desastre. Una compensación es que la replicación asíncrona te brinda un objetivo de punto de recuperación mayor que cero.
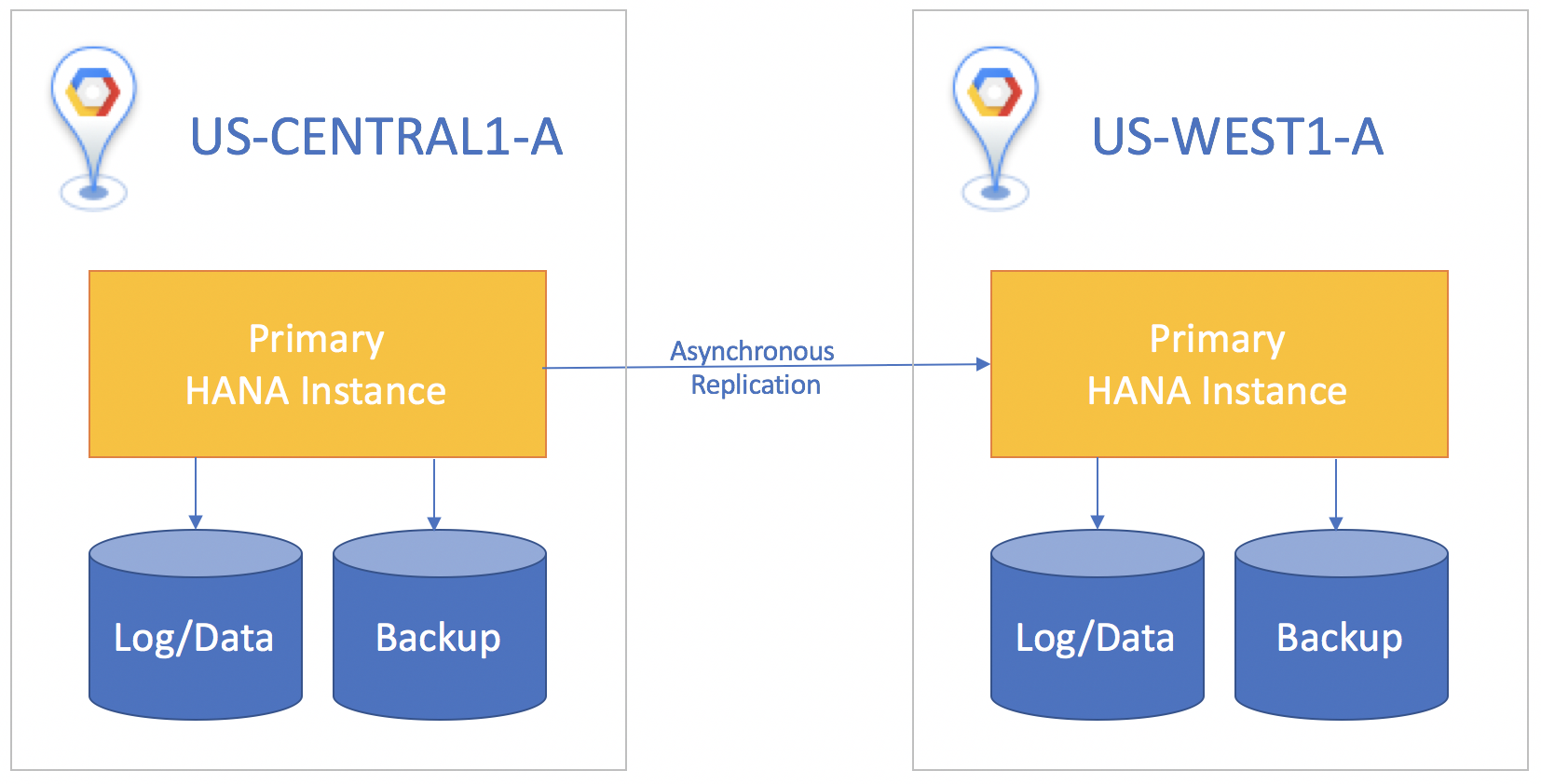
Para todas las situaciones de replicación, debes realizar una toma de control de forma manual en el sistema en espera a fin de iniciar la recuperación ante desastres. También debes redireccionar de forma manual las aplicaciones que usan la base de datos de SAP HANA para orientar la instancia a la que falló en el sistema en espera.
Elige la opción de replicación del sistema HANA que mejor se adapte a tus necesidades comerciales, como el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO). A fin de obtener más información, consulta Modos de replicación para la replicación del sistema SAP HANA.
Replicación del sistema SAP HANA con carga previa
En esta situación, el sistema SAP HANA se replica en un sistema en espera dedicado. La base de datos de SAP HANA se replica en una VM de Compute Engine que tiene un nombre de host único y sus propios discos persistentes adjuntos. Todos los datos de SAP HANA se cargan en la memoria del sistema en espera. Si tienes que realizar una conmutación por error, el tiempo de conmutación por error solo será de unos 90 segundos porque todos los datos están precargados.
Para obtener más información sobre la replicación del sistema SAP HANA con carga previa, consulta la sección Replicación del sistema en SAP HANA: Alta disponibilidad.
Replicación del sistema SAP HANA sin carga previa
En esta situación, el sistema SAP HANA se replica en un sistema en espera dedicado. La base de datos de SAP HANA se replica en una VM de Compute Engine que tiene un nombre de host único y sus propios discos persistentes adjuntos. Los datos de SAP HANA no se cargan en la memoria del sistema en espera. Si tienes que realizar una conmutación por error, el tiempo puede ser de minutos a horas, según el tamaño del conjunto de datos.
Cuando no cargas los datos de forma previa, los requisitos de memoria para la VM de Compute Engine que aloja la base de datos de SAP HANA son mucho más pequeños. Para obtener la guía de tamaño más reciente, consulta la nota de SAP 1999880 - Preguntas frecuentes: Replicación del sistema de SAP HANA en “¿Qué reglas se aplican para el uso de memoria en sitios secundarios de replicación del sistema?”.
Para obtener información sobre el alcance de memoria del almacén de filas, ejecuta la siguiente consulta:
SELECT round (sum(USED_FIXED_PART_SIZE + USED_VARIABLE_PART_SIZE)/1024/1024) AS "Row Tables MB" FROM M_RS_TABLES;
El requisito de memoria reducida te brinda opciones para ahorrar costos cuando eliges un tipo de máquina de Compute Engine.
Puedes usar un tipo de máquina que tenga especificaciones de memoria bajas para alojar la base de datos de SAP HANA en el sistema en espera a fin de reducir el costo de ejecución. Una VM con poca memoria no es compatible con SAP HANA en un sistema de producción, pero podrías usar esta VM de menor costo a fin de realizar una toma de control en una situación de recuperación ante desastres y, luego, modificarla para cambiar el tipo de máquina a uno con una cantidad de memoria admitida. Para hacer esto, debes detener la VM a fin de realizar la actualización, por lo que tendrás tiempo de inactividad adicional antes de que el sistema SAP HANA esté disponible.
Puedes usar un tipo de máquina con alta capacidad de memoria para alojar la base de datos de SAP HANA en el sistema en espera y compartirla con sistemas de desarrollo o prueba a fin de mejorar el retorno de la inversión. Puedes establecer el límite de asignación global para la base de datos de SAP HANA en 64 GB si sigues las instrucciones en Cambia el límite de asignación global de memoria, lo que deja el resto de la memoria disponible para que la usen otros sistemas. Cuando se necesita el sistema en espera, cierra las operaciones de desarrollo y prueba, realiza una toma de control y, luego, quita el límite de asignación global.
Puedes usar la replicación síncrona y asíncrona sin carga previa. Sin embargo, la replicación síncrona requiere que las instancias de origen y destino estén en la misma Google Cloud región.
Puedes usar un proveedor de HA/DR para abordar problemas como el cierre de los sistemas de desarrollo o prueba en el host secundario.
Activa una toma de control
Para invocar la recuperación ante desastres, activa el procedimiento de toma de control de replicación del sistema SAP HANA en el sistema en espera. En Nota de SAP 2063657, se proporcionan lineamientos para ayudarte a decidir si la toma de control es la mejor opción.
Para activar la toma de control, sigue el proceso de toma de control estándar de SAP HANA. A fin de obtener más información sobre este procedimiento, consulta Cómo realizar la replicación del sistema para SAP HANA 2.0.
En casos de problemas de datos o fallas de software, es posible que no haya notificaciones automáticas para que puedas realizar la toma de control. Considera crear una solución personalizada para enviar alertas mediante Cloud Monitoring o las herramientas de supervisión de HANA.
Recuperación ante desastres mediante copias de seguridad de SAP HANA
En los casos en los que un objetivo de tiempo de recuperación más largo es aceptable y tu objetivo de punto de recuperación es superior a 15 minutos, puedes recuperarte de un error si restableces la copia de seguridad. Para garantizar una recuperación exitosa cuando usas copias de seguridad, realiza copias frecuentes de los archivos de copia de seguridad, en especial de los registros, en un bucket de Cloud Storage o en otra ubicación de almacenamiento a largo plazo fuera de la región en la que se ejecuta el sistema SAP HANA. Recomendamos documentar la infraestructura del sistema principal y crear secuencias de comandos que te permitan crear un sistema de reemplazo con rapidez a fin de restablecer las copias de seguridad.
Para obtener más información, consulta la guía de operaciones de SAP HANA
Recuperación ante desastres mediante PD Async Replication
Para las cargas de trabajo de SAP que se ejecutan en Google Cloud, PD Async Replication permite la recuperación ante desastres mediante la replicación de datos entre dos regiones de Google Cloud . PD Async Replication proporciona un objetivo de punto de recuperación (RPO) y un objetivo de tiempo de recuperación (RTO) bajos de almacenamiento en bloque, la replicación asíncrona para la recuperación ante desastres entre regiones activa-pasiva. En el improbable caso de una interrupción regional, PD Async Replication te permite conmutar por error tus datos de SAP a una región secundaria y reiniciar tu carga de trabajo de SAP en esa región.
Puedes usar PD Async Replication para administrar la replicación de las cargas de trabajo de SAP basadas en Compute Engine a nivel de infraestructura, en lugar de a nivel de carga de trabajo de SAP, como la replicación del sistema SAP HANA.
PD Async Replication replica los datos de SAP de un disco principal que está conectado a una carga de trabajo en ejecución a un disco en blanco secundario que se encuentra en otra región. Para obtener más información, consulta Información sobre Persistent Disk Asynchronous Replication.
Limitaciones de PD Async Replication
Para la replicación asíncrona de PD, solo puedes usar volúmenes de disco persistente balanceado (pd-balanced) y disco persistente de rendimiento (SSD) (pd-ssd) en pares de regiones compatibles.
Para obtener más información, consulta Limitaciones.
Supervisa y evalúa la tasa de cambio en tu carga de trabajo en comparación con la capacidad de PD Async Replication mediante la revisión de las métricas de supervisión para tu par de dispositivos, como se describe en Revisa el rendimiento de Persistent Disk Asynchronous Replication.
No se espera que la métrica async_replication/sent_bytes_count muestre un aumento constante en la cantidad de datos transferidos porque esta métrica representa el delta de la cantidad de bytes enviados a través de la red entre regiones.