Questa guida fornisce una panoramica delle opzioni di ripristino di emergenza per i sistemi SAP HANA di cui è stato eseguito il deployment su Google Cloud.
Questa guida non intende sostituire la documentazione SAP standard.
Preparazione al ripristino di emergenza
Per prepararti alle catastrofi, puoi utilizzare la replica del sistema SAP HANA a un sistema SAP HANA secondario, eseguire il backup di SAP HANA per abilitare il recupero o utilizzare entrambi.
Per i carichi di lavoro mission critical che richiedono tempi di recupero rapidi, utilizza la replica del sistema HANA per ridurre al minimo i tempi di inattività. L'utilizzo dei backup per recuperare un sistema costa meno, ma richiede più tempo, in quanto è necessario creare un nuovo sistema e ripristinarvi i backup per recuperare il punto in tempo desiderato.
In entrambi i casi, devi utilizzare il reindirizzamento basato sulla rete per reindirizzare le applicazioni client che utilizzano il sistema SAP HANA all'indirizzo IP del sistema sostitutivo quando sarà disponibile. Per ulteriori informazioni, consulta la Guida all'amministrazione di SAP HANA.
A partire da SAP HANA SPS09, puoi utilizzare l'API basata su Python inclusa in SAP HANA per creare il tuo provider di alta disponibilità/ripristino dopo disastro (HA/DR) e integrarlo con la procedura di acquisizione della replica di sistema SAP HANA per automatizzare attività come il reindirizzamento delle connessioni dei client di database dal sistema principale al sistema secondario dopo un'acquisizione. Per ulteriori informazioni, consulta la sezione Implementazione di un provider HA/DR.
Tieni presente che eventuali limitazioni definite da SAP, inclusa la limitazione di distanza per la replica sincrona, sono in vigore anche su Google Cloud.
In alternativa alle opzioni di ripristino di emergenza native, per il ripristino di emergenza attivo-passivo tra regioni puoi utilizzare la replica asincrona del disco permanente (DP asincrono). La replica asincrona del disco permanente fornisce la replica asincrona dei dati tra due Google Cloud regioni.
Ripristino di emergenza utilizzando la replica di sistema SAP HANA
Per massimizzare l'utilizzo delle risorse dell'infrastruttura e ottimizzare i costi della soluzione di RP, puoi utilizzare il sistema secondario per casi d'uso non di produzione, ad esempio per un sistema di sviluppo o QA. In questo caso, il sistema secondario non è precaricato con i dati, pertanto il tempo di failover è più lungo rispetto al caso in cui il sistema secondario sia precaricato con i dati e mantenuto sincronizzato con il sistema principale.
HANA 2 SPS00 include il supporto della modalità di configurazione Active/Active (lettura abilitata), che consente alla replica del sistema SAP HANA di supportare l'accesso in lettura sul sistema secondario. Per maggiori informazioni, consulta Attivo/attivo (lettura abilitata).
La replica sia sincrona che asincrona è supportata quando si utilizza la replica del sistema SAP HANA con Google Cloud.
Se possibile, ti consigliamo di utilizzare la replica sincrona, in cui le transazioni SQL non vengono confermate nell'istanza del database principale finché non vengono confermate nell'istanza di standby. In questo modo, l'istanza di standby rimane sincronizzata al 100% e garantisce un Recovery Point Objective pari a zero. La replica sincrona può essere utilizzata per le istanze che si trovano in qualsiasi zona all'interno della stessa regione.
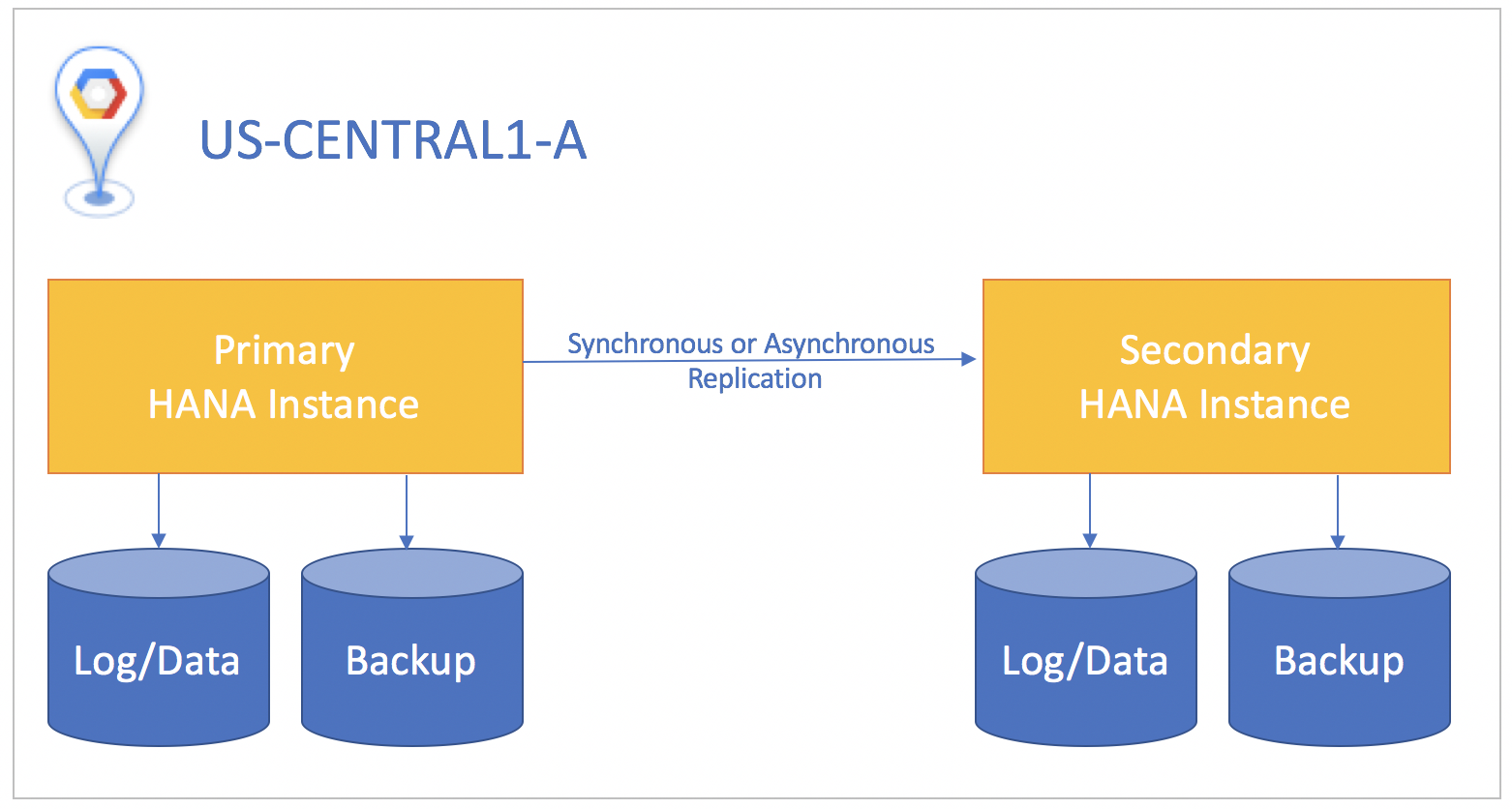
Se il sistema di standby si trova in una regione diversa da quella del sistema principale, utilizza la replica asincrona, in cui non è necessario attendere che l'istanza di standby confermi i dati prima del commit sull'istanza principale. In questo scenario, potresti perdere piccole quantità di dati in caso di incidente. Un compromesso è che la replica asincrona consente di avere un Recovery Point Objective maggiore di zero.
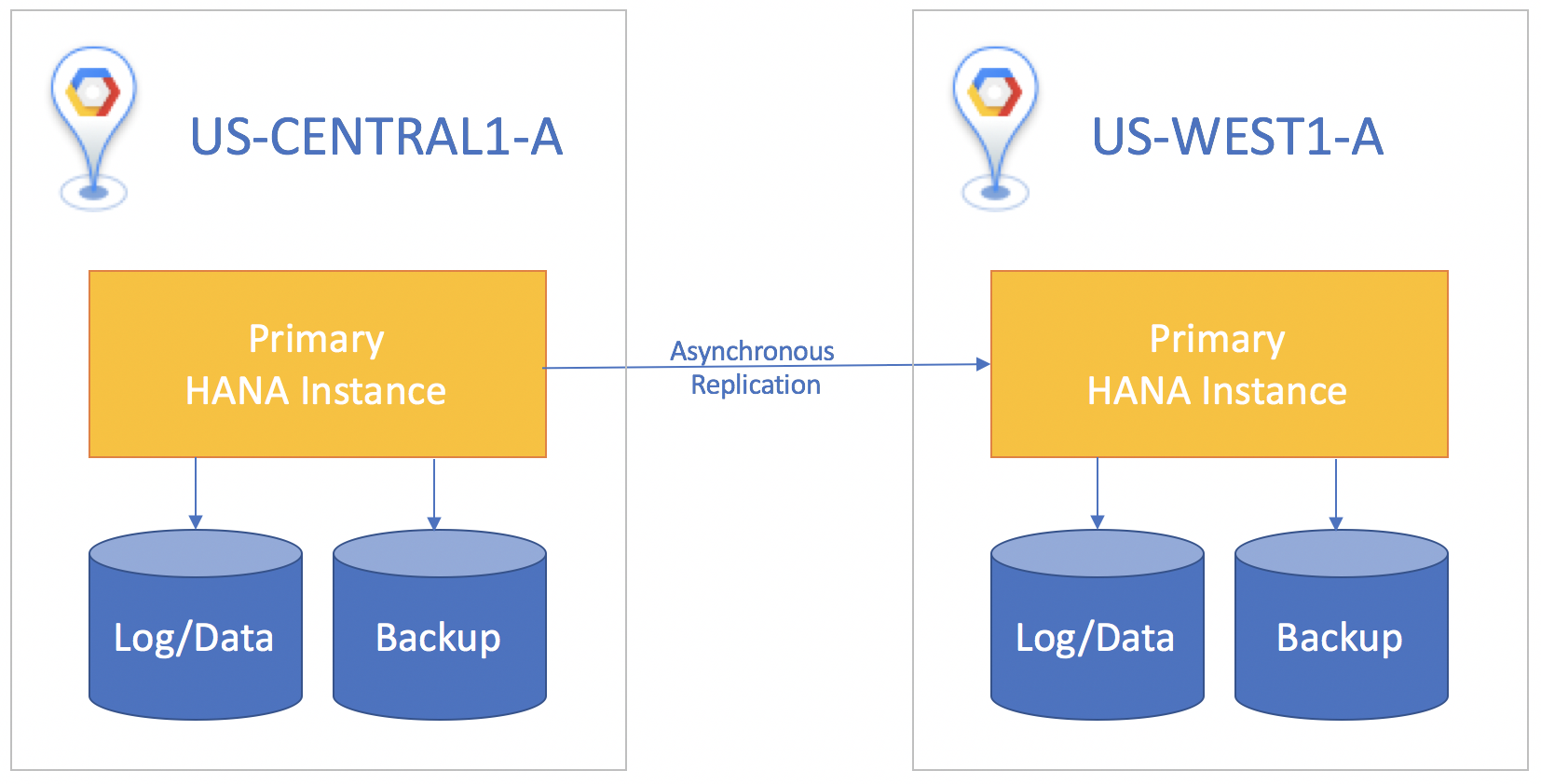
Per tutti gli scenari di replica, devi eseguire manualmente una presa in carico sul sistema di standby per avviare il disaster recovery. Devi anche reindirizzare manualmente tutte le applicazioni che utilizzano il database SAP HANA in modo che abbiano come target l'istanza a cui è stato eseguito il failover nel sistema di standby.
Scegli l'opzione di replica del sistema HANA più adatta alle esigenze della tua attività, come l'obiettivo di tempo di recupero (RTO) e l'obiettivo di punto di recupero (RPO). Per maggiori informazioni, consulta Modalità di replica per la replica del sistema SAP HANA.
Replica di sistema SAP HANA con precaricamento
In questo scenario, il sistema SAP HANA viene replicato in un sistema di standby dedicato. Il database SAP HANA viene replicato in una VM Compute Engine che ha un nome host univoco e i propri dischi permanenti collegati. Tutti i dati di SAP HANA vengono caricati in memoria sul sistema di standby. Se devi eseguire il failover, il tempo necessario è di circa 90 secondi perché tutti i dati sono precaricati.
Per ulteriori informazioni sulla replica di sistema SAP HANA con precaricamento, consulta la sezione Replica di sistema in SAP HANA - Alta disponibilità.
Replica di sistema SAP HANA senza precaricamento
In questo scenario, il sistema SAP HANA viene replicato in un sistema di standby dedicato. Il database SAP HANA viene replicato in una VM Compute Engine che ha un nome host univoco e i propri dischi permanenti collegati. I dati SAP HANA non vengono caricati nella memoria del sistema di standby. Se devi eseguire il failover, il tempo di failover può richiedere da alcuni minuti a diverse ore, a seconda delle dimensioni del set di dati.
Se non carichi in anteprima i dati, i requisiti di memoria per la VM Compute Engine che ospita il database SAP HANA sono molto inferiori. Per le indicazioni di dimensionamento più recenti, consulta la nota SAP 1999880 - Domande frequenti: replica di sistema SAP HANA nella sezione "Quali regole si applicano all'utilizzo della memoria nei siti di replica di sistema secondari?".
Puoi ottenere informazioni sull'impronta in memoria del mazzo di righe eseguendo la seguente query:
SELECT round (sum(USED_FIXED_PART_SIZE + USED_VARIABLE_PART_SIZE)/1024/1024) AS "Row Tables MB" FROM M_RS_TABLES;
Il requisito di memoria ridotto ti offre opzioni di risparmio sui costi quando scegli un tipo di macchina Compute Engine.
Per ridurre i costi di gestione, puoi utilizzare un tipo di macchina con specifiche di memoria ridotte per ospitare il database SAP HANA nel sistema di standby. Una VM con poca memoria non è supportata per SAP HANA in un sistema di produzione, ma puoi utilizzare questa VM a basso costo per eseguire un takeover in uno scenario di disaster recovery e poi modificarla per impostare un tipo di macchina con una quantità di memoria supportata. Per farlo, devi arrestare la VM per eseguire l'upgrade, quindi dovrai prevedere un tempo di riposo aggiuntivo prima che il sistema SAP HANA sia disponibile.
Puoi utilizzare un tipo di macchina con molta memoria per ospitare il database SAP HANA nel sistema di standby e condividerlo con sistemi di sviluppo o di test per migliorare il ritorno sull'investimento. Puoi impostare il limite di allocazione globale per il database SAP HANA su 64 GB seguendo le istruzioni riportate in Modificare il limite di allocazione della memoria globale, lasciando il resto della memoria per l'utilizzo da parte di altri sistemi. Quando il sistema di riserva è necessario, arresta le operazioni di sviluppo e test, esegui un takeover e poi rimuovi il limite di allocazione globale.
Puoi utilizzare la replica sincrona e asincrona senza precaricamento. Tuttavia, la replica sincrona richiede che le istanze di origine e di destinazione si trovino nella stessa Google Cloud regione.
Puoi utilizzare un fornitore di HA/DR per risolvere problemi come l'arresto dei sistemi di sviluppo e/o test nell'host secondario.
Attivazione di un takeover
Per invocare il ripristino di emergenza, attiva la procedura di acquisizione della replica del sistema SAP HANA nel sistema di riserva. La nota SAP 2063657 fornisce linee guida per aiutarti a decidere se il takeover è l'opzione migliore.
Per attivare il rilevamento, segui la procedura standard di rilevamento di SAP HANA. Per ulteriori informazioni su questa procedura, consulta Come eseguire la replica di sistema per SAP HANA 2.0.
In caso di problemi con i dati o di errori del software, potresti non ricevere notifiche automatiche per poter eseguire il passaggio di proprietà. Valuta la possibilità di creare una soluzione personalizzata per inviare avvisi utilizzando gli strumenti di monitoraggio di Cloud Monitoring o HANA.
Ripristino di emergenza mediante i backup di SAP HANA
Se un Recovery Time Objective più lungo è accettabile e il tuo Recovery Point Objective è superiore a 15 minuti, puoi eseguire il ripristino da un backup per far fronte a un'emergenza. Per garantire un recupero efficace quando utilizzi i backup, esegui copie frequenti dei file di backup, in particolare dei backup dei log, in un bucket Cloud Storage o in un'altra posizione di archiviazione a lungo termine esistente al di fuori della regione in cui è in esecuzione il sistema SAP HANA. Ti consigliamo di documentare l'infrastruttura del sistema principale e di creare script che ti consentano di creare rapidamente un sistema sostitutivo su cui ripristinare i backup.
Per ulteriori informazioni, consulta la guida alle operazioni di SAP HANA.
Ripristino di emergenza mediante la replica asincrona di PD
Per i workload SAP in esecuzione su Google Cloud, la replica asincrona del disco permanente consente il ripristino di emergenza replicando i dati tra due regioni Google Cloud . La replica asincrona del disco permanente fornisce una replica asincrona dell'archiviazione a blocchi con RPO (Recovery Point Objective) e RTO (Recovery Time Objective) bassi per il ripristino di emergenza attivo-passivo tra regioni. Nell'improbabile caso di un'interruzione in una regione, la replica asincrona del disco permanente consente di eseguire il failover dei dati SAP in una regione secondaria e di riavviare il carico di lavoro SAP in quella regione.
Puoi utilizzare la replica asincrona PD per gestire la replica per i workload SAP basati su Compute Engine a livello di infrastruttura anziché a livello di workload SAP, ad esempio la replica di sistema SAP HANA.
La replica asincrona del disco permanente replica i dati SAP da un disco principale collegato a un carico di lavoro in esecuzione a un disco secondario vuoto che si trova in un'altra regione. Per ulteriori informazioni, consulta Informazioni sulla replica asincrona dei dischi permanenti.
Limiti della replica asincrona di PD
Per la replica asincrona del disco permanente, puoi utilizzare solo i volumi dei dischi permanenti bilanciati (pd-balanced) e dei dischi permanenti prestazionali (SSD) (pd-ssd) nelle coppie di regioni supportate.
Per ulteriori informazioni, vedi Limitazioni.
Monitora e valuta il tasso di variazione del tuo carico di lavoro rispetto alle funzionalità della replica asincrona dei dischi permanenti esaminando le metriche di monitoraggio per la coppia di dispositivi come descritto in Esaminare le prestazioni della replica asincrona dei dischi permanenti.
Non è previsto che la metrica async_replication/sent_bytes_count mostri un aumento costante della quantità di dati trasferiti perché rappresenta il delta del numero di byte inviati attraverso la rete tra regioni.