Dieser Leitfaden bietet einen Überblick über die Optionen für die Notfallwiederherstellung für SAP HANA-Systeme, die in Google Cloudbereitgestellt werden.
Er ersetzt nicht die Standarddokumentation von SAP.
Vorbereitung auf die Notfallwiederherstellung
Zur Vorbereitung auf Notfälle können Sie eine SAP HANA-Systemreplikation auf ein sekundäres SAP HANA-System vornehmen oder Sicherungen von SAP HANA erstellen, um eine Wiederherstellung zu ermöglichen, oder beides.
Verwenden Sie für geschäftskritische Arbeitslasten, die kurze Wiederherstellungszeiten erfordern, die HANA-Systemreplikation, um die Ausfallzeit zu minimieren. Das Verwenden von Sicherungen zur Systemwiederherstellung kostet weniger, dauert aber länger. Das liegt daran, dass ein neues System erstellt werden muss und darauf dann die Sicherungen des gewünschten Zeitpunkts wiederhergestellt werden müssen.
In jedem Fall müssen Sie die netzwerkbasierte Weiterleitung verwenden, um Clientanwendungen, die das SAP HANA-System nutzen, zur IP-Adresse des Ersatzsystems weiterzuleiten, sobald dieses verfügbar ist. Weitere Informationen finden Sie im Administratorhandbuch für SAP HANA.
Ab SAP HANA SPS09 können Sie die in SAP HANA enthaltene Python-basierte API verwenden, um einen eigenen HA-/DR-Anbieter (High Availability/Disaster Recovery, Hochverfügbarkeit/Notfallwiederherstellung) zu erstellen und in das Takeover-Verfahren der SAP HANA-Systemreplikation einzubinden. Dadurch lassen sich Aufgaben wie das Weiterleiten von Datenbankclient-Verbindungen vom primären zum sekundären System nach dem Takeover automatisieren. Weitere Informationen finden Sie unter HA-/DR-Anbieter implementieren.
Beachten Sie, dass von SAP angegebene Einschränkungen, einschließlich der Abstandsbeschränkung für die synchrone Replikation, auch auf Google Cloudgelten.
Als Alternative zu nativen Optionen zur Notfallwiederherstellung können Sie für die regionenübergreifende Aktiv-Passiv-Notfallwiederherstellung die asynchrone Replikation von nichtflüchtigem Speicher (Persistent Disk Recovery Replication, PD Async Replication) verwenden. PD Async Replication bietet eine asynchrone Replikation von Daten zwischen zweiGoogle Cloud -Regionen.
Notfallwiederherstellung mithilfe der SAP HANA-Systemreplikation
Wenn Sie die Nutzung der Infrastrukturressourcen maximieren und die Kosten Ihrer DR-Lösung minimieren möchten, können Sie das sekundäre System für nicht produktionsbezogene Anwendungsfälle verwenden, z. B. für die Entwicklung oder für ein QA-System (Quality Assurance, Qualitätssicherung). In diesem Fall werden keine Daten vorab in das sekundäre System geladen. Die Failover-Zeit ist dadurch länger als bei dem Ansatz, Daten vorab in das sekundäre System zu laden und es mit dem primären System synchronisiert zu halten.
HANA 2 SPS00 umfasst Unterstützung für den Aktiv/Aktiv-Konfigurationsmodus (Lesezugriff aktiviert). Dieser ermöglicht die SAP HANA-Systemreplikation und damit den Lesezugriff auf das sekundäre System. Weitere Informationen finden Sie unter Aktiv/Aktiv (Lesezugriff aktiviert).
Bei Verwendung der SAP HANA-Systemreplikation mit Google Cloudwerden sowohl die synchrone als auch die asynchrone Replikation unterstützt.
Es empfiehlt sich, nach Möglichkeit die synchrone Replikation zu verwenden, wobei für SQL-Transaktionen erst dann ein Commit auf der primären Datenbankinstanz durchgeführt wird, nachdem für sie ein Commit auf der Standby-Instanz durchgeführt wurde. Dadurch bleibt die Standby-Instanz zu 100 % synchronisiert und es wird ein Recovery Point Objective von null erreicht. Die synchrone Replikation kann für Instanzen verwendet werden, die sich in beliebigen Zonen innerhalb derselben Region befinden.
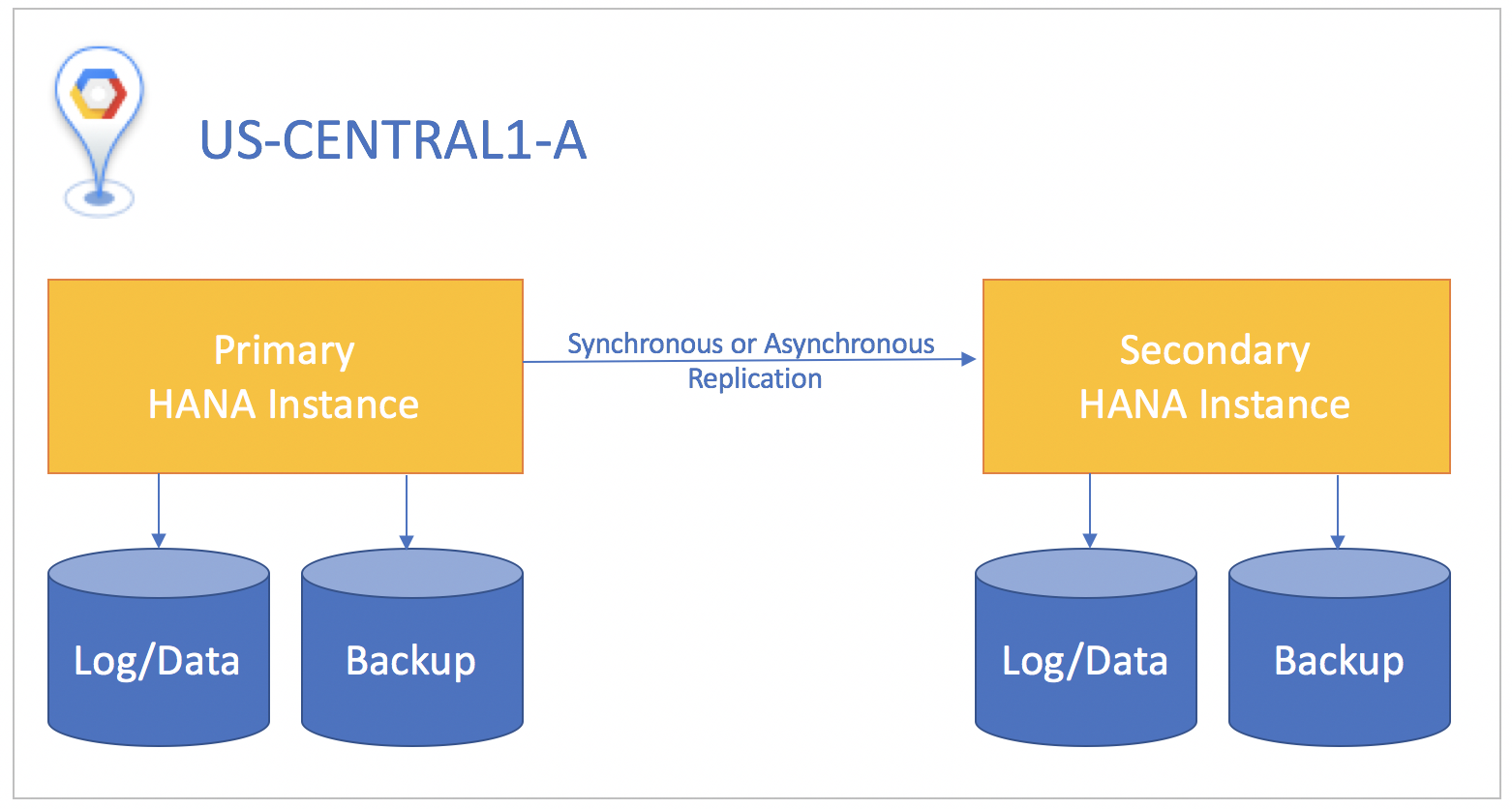
Wenn sich das Standby-System in einer anderen Region als das primäre System befindet, verwenden Sie die asynchrone Replikation. Bei dieser wird nicht darauf gewartet, dass die Standby-Instanz den Empfang der Daten bestätigt, bevor das Commit auf der primären Instanz erfolgt. In diesem Szenario können Sie kleine Datenmengen verlieren, wenn ein Notfallereignis eintritt. Außerdem liegt das Recovery Point Objective über null.
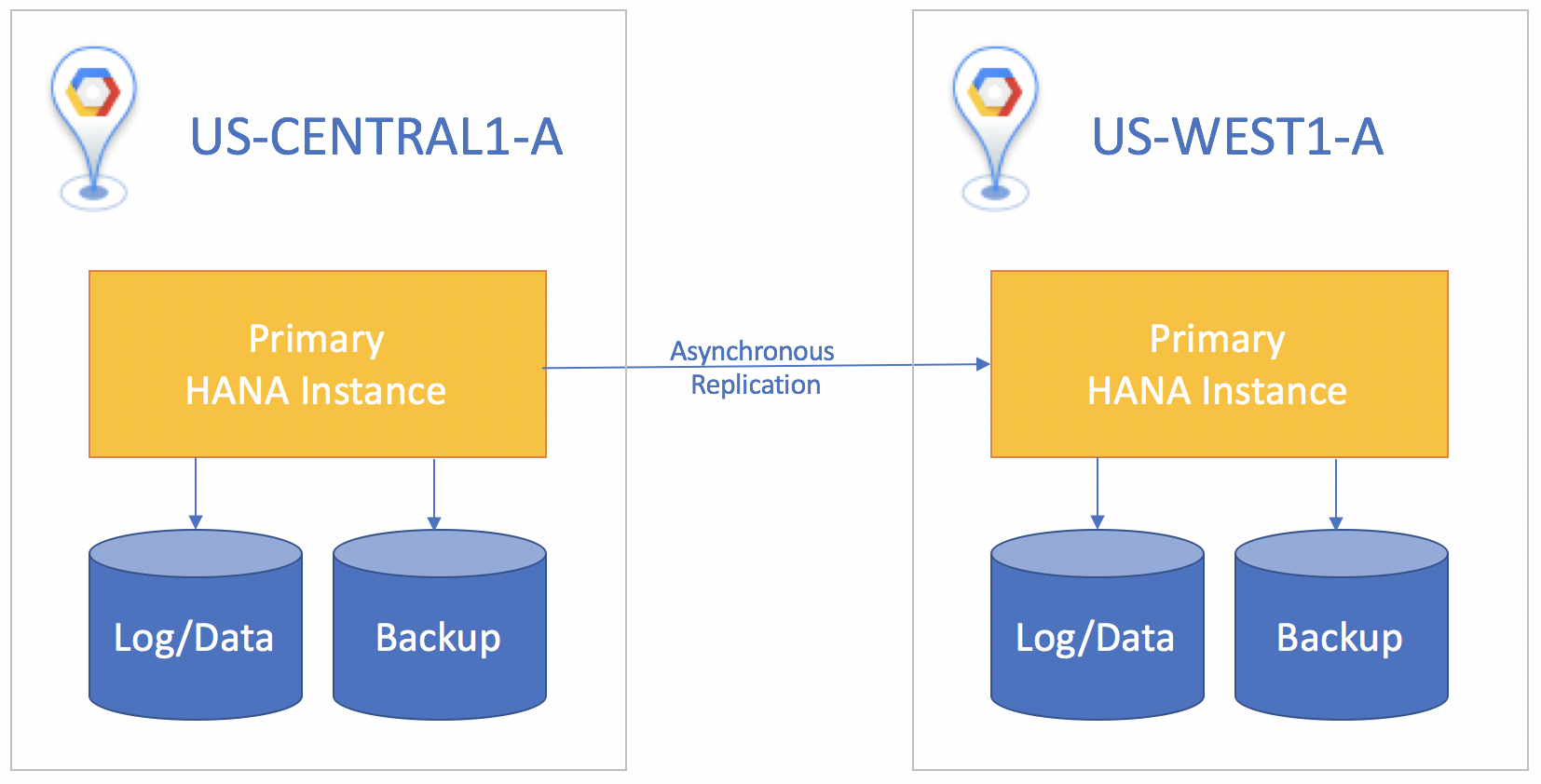
In allen Replikationsszenarien müssen Sie manuell einen Takeover auf dem Standby-System durchführen, um die Notfallwiederherstellung zu starten. Außerdem müssen Sie die Anwendungen, die die SAP HANA-Datenbank nutzen, manuell weiterleiten, um auf die Instanz im Standby-System abzuzielen, auf die der Failover erfolgt ist.
Wählen Sie jene Option der HANA-Systemreplikation aus, die am besten Ihre Geschäftsanforderungen erfüllt, z. B. in Bezug auf das Recovery Time Objective (RTO) und das Recovery Point Objective (RPO). Weitere Informationen finden Sie unter Replikationsmodi für die SAP HANA-Systemreplikation.
SAP HANA-Systemreplikation mit Vorabladen
In diesem Szenario wird Ihr SAP HANA-System zu einem dedizierten Standby-System repliziert. Die SAP HANA-Datenbank wird zu einer Compute Engine-VM repliziert, die einen eindeutigen Hostnamen hat und an die ein eigener nichtflüchtiger Speicher angehängt ist. Die gesamten SAP HANA-Daten werden in den Arbeitsspeicher des Standby-Systems geladen. Ein Failover dauert hier nur ungefähr 90 Sekunden, weil alle Daten vorab geladen werden.
Weitere Informationen zur SAP HANA-Systemreplikation mit Vorabladen finden Sie im Abschnitt Systemreplikation des Artikels SAP HANA – Hochverfügbarkeit.
SAP HANA-Systemreplikation ohne Vorabladen
In diesem Szenario wird Ihr SAP HANA-System zu einem dedizierten Standby-System repliziert. Die SAP HANA-Datenbank wird zu einer Compute Engine-VM repliziert, die einen eindeutigen Hostnamen hat und an die ein eigener nichtflüchtiger Speicher angehängt ist. Die SAP HANA-Daten werden nicht in den Arbeitsspeicher des Standby-Systems geladen. Ein Failover kann hier je nach der Größe Ihres Datasets Minuten bis Stunden dauern.
Wenn Sie die Daten nicht vorab laden, braucht die Compute Engine-VM, die die SAP HANA-Datenbank hostet, viel weniger Arbeitsspeicher. Den neuesten Leitfaden für die Größenbestimmung finden Sie im SAP-Hinweis 1999880 – FAQ: SAP HANA-Systemreplikation im Abschnitt "Welche Regeln gelten für die Speicherauslastung der sekundären Systemreplikationsstandorte?".
Sie können den Arbeitsspeicherbedarf des Row Store mithilfe der folgenden Abfrage ermitteln:
SELECT round (sum(USED_FIXED_PART_SIZE + USED_VARIABLE_PART_SIZE)/1024/1024) AS "Row Tables MB" FROM M_RS_TABLES;
Der geringere Arbeitsspeicherbedarf ermöglicht Ihnen Kosteneinsparungen, wenn Sie einen Compute Engine-Maschinentyp auswählen.
Zur Verringerung der laufenden Kosten können Sie einen Maschinentyp mit weniger Arbeitsspeicher wählen, um die SAP HANA-Datenbank im Standby-System zu hosten. Eine VM mit wenig Arbeitsspeicher wird für SAP HANA in einem Produktionssystem nicht unterstützt. Sie können diese preisgünstigere VM aber verwenden, um im Szenario einer Notfallwiederherstellung einen Takeover durchzuführen, und können die VM dann später anpassen, um den Maschinentyp in einen mit einer unterstützten Arbeitsspeichergröße zu ändern. Dabei müssen Sie die VM beenden, um das Upgrade durchzuführen. So kommt es zu zusätzlicher Ausfallzeit, bevor das SAP HANA-System verfügbar ist.
Sie können einen Maschinentyp mit großem Arbeitsspeicher verwenden, um die SAP HANA-Datenbank im Standby-System zu hosten. Er lässt sich dann auch für die Entwicklung oder für Systemtests nutzen, um den Return on Investment zu verbessern. Sie können das globale Zuweisungslimit für die SAP HANA-Datenbank auf 64 GB setzen. Folgen Sie dazu der Anleitung unter Globales Arbeitsspeicherzuweisungslimit ändern. Der übrige Arbeitsspeicher steht dann für andere Systeme zur Verfügung. Wenn das Standby-System benötigt wird, beenden Sie alle Entwicklungs- und Testvorgänge, führen Sie einen Takeover durch und heben Sie das globale Zuweisungslimit auf.
Sie können entweder synchrone und asynchrone Replikation ohne Vorabladen verwenden. Für die synchrone Replikation müssen sich die Quell- und Zielinstanzen jedoch in derselben Google Cloud Region befinden.
Sie können einen HA-/DR-Anbieter verwenden, um Probleme wie das Herunterfahren der Entwicklungs- und/oder Testsysteme auf den sekundären Hosts zu bewältigen.
Takeover auslösen
Wenn Sie die Notfallwiederherstellung starten möchten, lösen Sie in Ihrem Standby-System das Takeover-Verfahren der SAP HANA-Systemreplikation aus. Der SAP-Hinweis 2063657 enthält Richtlinien, anhand derer Sie leichter entscheiden können, ob ein Takeover die beste Option ist.
Wenn Sie den Takeover auslösen möchten, folgen Sie dem standardmäßigen SAP HANA-Takeover-Verfahren. Weitere Informationen zu diesem Verfahren finden Sie unter Systemreplikation für SAP HANA 2.0 durchführen.
Bei Datenproblemen oder Softwarefehlern gibt es möglicherweise keine automatischen Benachrichtigungen, die auf die Notwendigkeit eines Takeovers hindeuten. Sie können mithilfe von Cloud Monitoring- oder HANA-Monitoringtools eine benutzerdefinierte Lösung erstellen, um entsprechende Benachrichtigungen senden zu lassen.
Notfallwiederherstellung mithilfe von SAP HANA-Sicherungen
Wenn ein höheres Recovery Time Objective akzeptabel ist und das Recovery Point Objective mehr als 15 Minuten beträgt, können Sie eine Notfallwiederherstellung mithilfe einer Sicherung durchführen. Um beim Verwenden von Sicherungen eine erfolgreiche Wiederherstellung zu gewährleisten, sollten Sie häufig Kopien Ihrer Sicherungsdateien und v. a. der Logsicherungen erstellen, und zwar in einem Cloud Storage-Bucket oder an einem anderen langfristigen Speicherort außerhalb der Region, in der das SAP HANA-System ausgeführt wird. Es empfiehlt sich, die Infrastruktur Ihres primären Systems zu dokumentieren und Skripts zu erstellen, über die Sie schnell ein Ersatzsystem erstellen können, auf dem sich Ihre Sicherungen wiederherstellen lassen.
Weitere Informationen finden Sie in der Betriebsanleitung für SAP HANA.
Notfallwiederherstellung mithilfe von PD Async Replication
Für Ihre in Google Cloudausgeführten SAP-Arbeitslasten ermöglicht PD Async Replication die Notfallwiederherstellung, indem Daten zwischen zwei Google Cloud -Regionen repliziert werden. PD Async Replication bietet eine asynchrone Replikation mit einem niedrigen Recovery Point Objective (RPO) und einem asynchronen RTO-Wert (Recovery Time Objective) für Blockspeicher für die regionenübergreifende Aktiv-Passiv-Notfallwiederherstellung. Im unwahrscheinlichen Fall eines regionalen Ausfalls können Sie mit PD Async Replication Ihre SAP-Daten in eine sekundäre Region übertragen und Ihre SAP-Arbeitslast in dieser Region neu starten.
Sie können PD Async Replication verwenden, um die Replikation für Compute Engine-basierte SAP-Arbeitslasten auf Infrastrukturebene zu verwalten, anstatt die SAP-Arbeitslastebene wie SAP HANA-Systemreplikation.
Die PD Async Replication repliziert SAP-Daten von einem primären Laufwerk, das an eine laufende Arbeitslast angehängt ist, auf ein sekundäres leeres Laufwerk, das sich in einer anderen Region befindet. Weitere Informationen finden Sie unter Persistent Disk Asynchronous Replication.
Einschränkungen für PD Async Replication
Für PD Async Replication können Sie nur ausgeglichene nichtflüchtige Speicher (pd-balanced) und nichtflüchtige SSD-Speicher (pd-ssd) in unterstützten Regionspaaren verwenden.
Weitere Informationen finden Sie unter Einschränkungen.
Überwachen Sie die Änderungsrate Ihrer Arbeitslast im Hinblick auf die Funktion von PD Async Replication. Bewerten Sie dazu die Monitoring-Messwerte für Ihr Gerätepaar, wie unter Persistent Disk Asynchronous Replication prüfen beschrieben.
Der Messwert async_replication/sent_bytes_count soll keine konstante Zunahme der übertragenen Daten aufweisen, da dieser Messwert das Delta der Anzahl von Byte darstellt, die über das regionenübergreifende Netzwerk gesendet werden.