Este guia apresenta uma visão geral das opções de recuperação de desastres para sistemas SAP HANA implantados no Google Cloud.
Este guia não tem o intuito de substituir a documentação padrão do SAP.
Como se preparar para a recuperação de desastres
Para se preparar para desastres, use a replicação do sistema SAP HANA para um sistema SAP HANA secundário, e faça backups do SAP HANA para ativar a recuperação ou os dois.
Para cargas de trabalho críticas para a missão que exigem tempos de recuperação rápidos, use a replicação do sistema HANA para minimizar o tempo de inatividade. Usar backups para recuperar um sistema custa menos, mas leva mais tempo, porque um novo sistema precisa ser criado para que, em seguida, os backups restaurados nele possam ser recuperados para o ponto desejado no tempo.
Em ambos os casos, é necessário usar o redirecionamento baseado em rede para redirecionar aplicativos clientes que usam o sistema SAP HANA para o endereço IP do sistema de substituição assim que estiver disponível. Para mais informações, consulte o Guia de administração do SAP HANA (em inglês).
A partir do SAP HANA SPS09, é possível usar a API baseada em Python incluída no SAP HANA para criar seu próprio provedor de alta disponibilidade/recuperação de desastres (HA/DR, na sigla em inglês) e integrá-lo ao processo de controle de replicação do sistema SAP HANA para automatizar tarefas, como redirecionar as conexões do cliente do banco de dados a partir do sistema primário para o sistema secundário após uma transferência. Para mais informações, consulte Como implantar um provedor de HA/DR (em inglês).
Observe que as restrições definidas pelo SAP, incluindo a limitação de distância para replicação síncrona, também estão em vigor no Google Cloud.
Como alternativa às opções nativas de recuperação de desastres, para a recuperação de desastres ativa e passiva entre regiões (DR), use a replicação assíncrona em disco permanente (DP). A replicação assíncrona de DPs oferece replicação assíncrona de dados entre duas Google Cloud regiões.
Recuperação de desastres usando a replicação do sistema para SAP HANA
Para maximizar o uso dos recursos da infraestrutura e otimizar sua solução de recuperação de desastres, use o sistema secundário para casos de uso que não sejam de produção, por exemplo, para um sistema de desenvolvimento ou controle de qualidade. Nesse caso, o sistema secundário não é pré-carregado com dados. Portanto, o tempo de failover é mais longo do que o sistema secundário pré-carregado com dados e mantido em sincronia com o sistema primário.
O HANA 2 SPS00 inclui compatibilidade com o modo de configuração Ativo/Ativo (ativado para leitura), que permite que a replicação do sistema para SAP HANA seja compatível com o acesso de leitura ao sistema secundário. Para mais informações, consulte Ativo/Ativo (ativado para leitura), em inglês.
A replicação síncrona e assíncrona são compatíveis com a replicação do sistema SAP HANA com Google Cloud.
Se possível, recomendamos o uso da replicação síncrona, em que as transações SQL não são confirmadas na instância principal do banco de dados até que sejam confirmadas na instância em espera. Isso mantém a instância em espera 100% sincronizada e garante um objetivo de ponto de recuperação zero. A replicação síncrona pode ser usada para instâncias que residem em quaisquer zonas da mesma região.
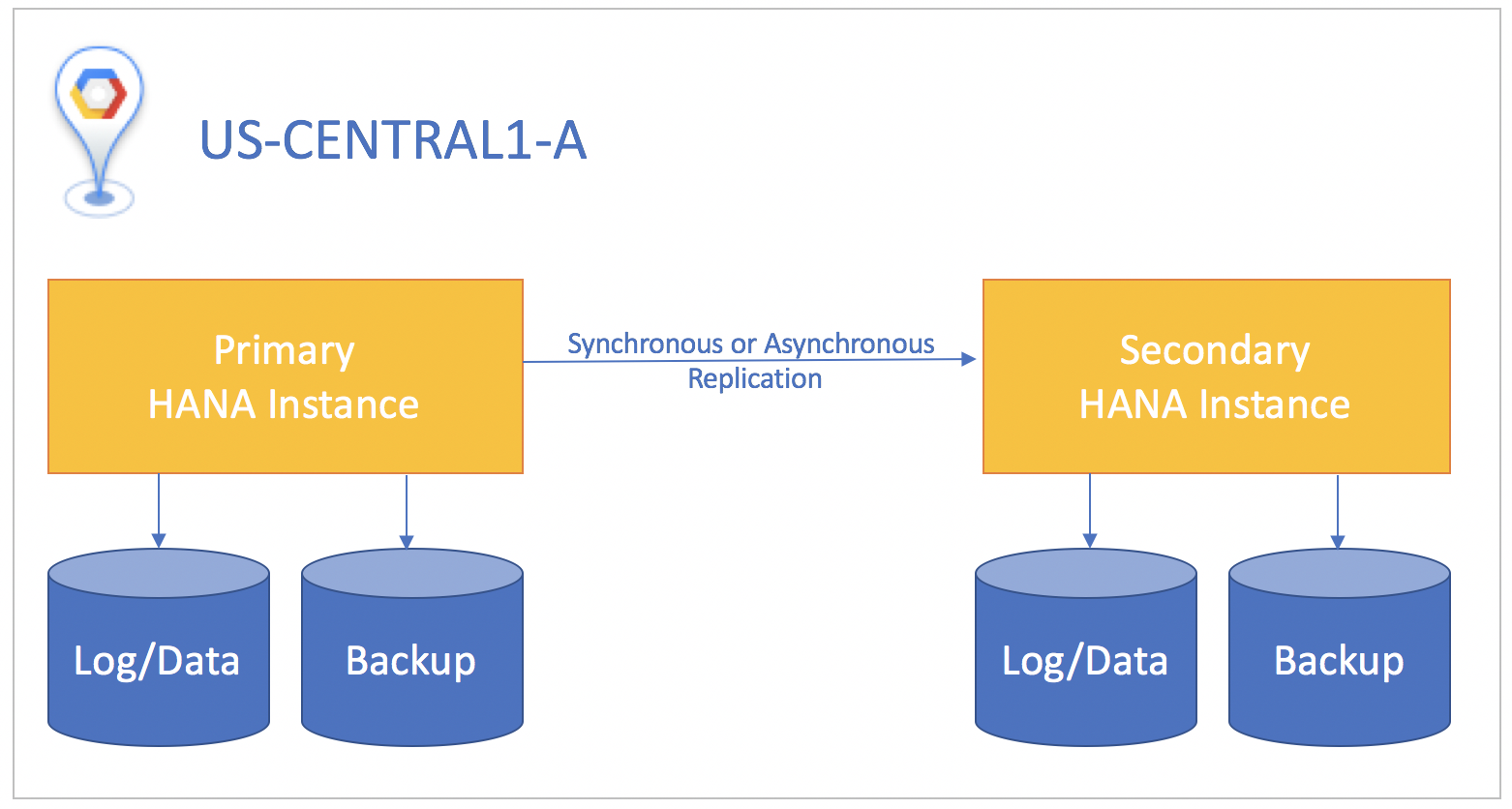
Se o sistema em espera estiver em uma região diferente do sistema primário, use a replicação assíncrona, porque nela não é necessário esperar que a instância em espera reconheça os dados antes de confirmar a instância principal. Nesse cenário, é possível perder pequenas quantidades de dados caso ocorra um desastre. Um contraponto é que a replicação assíncrona fornece um objetivo de ponto de recuperação maior que zero.
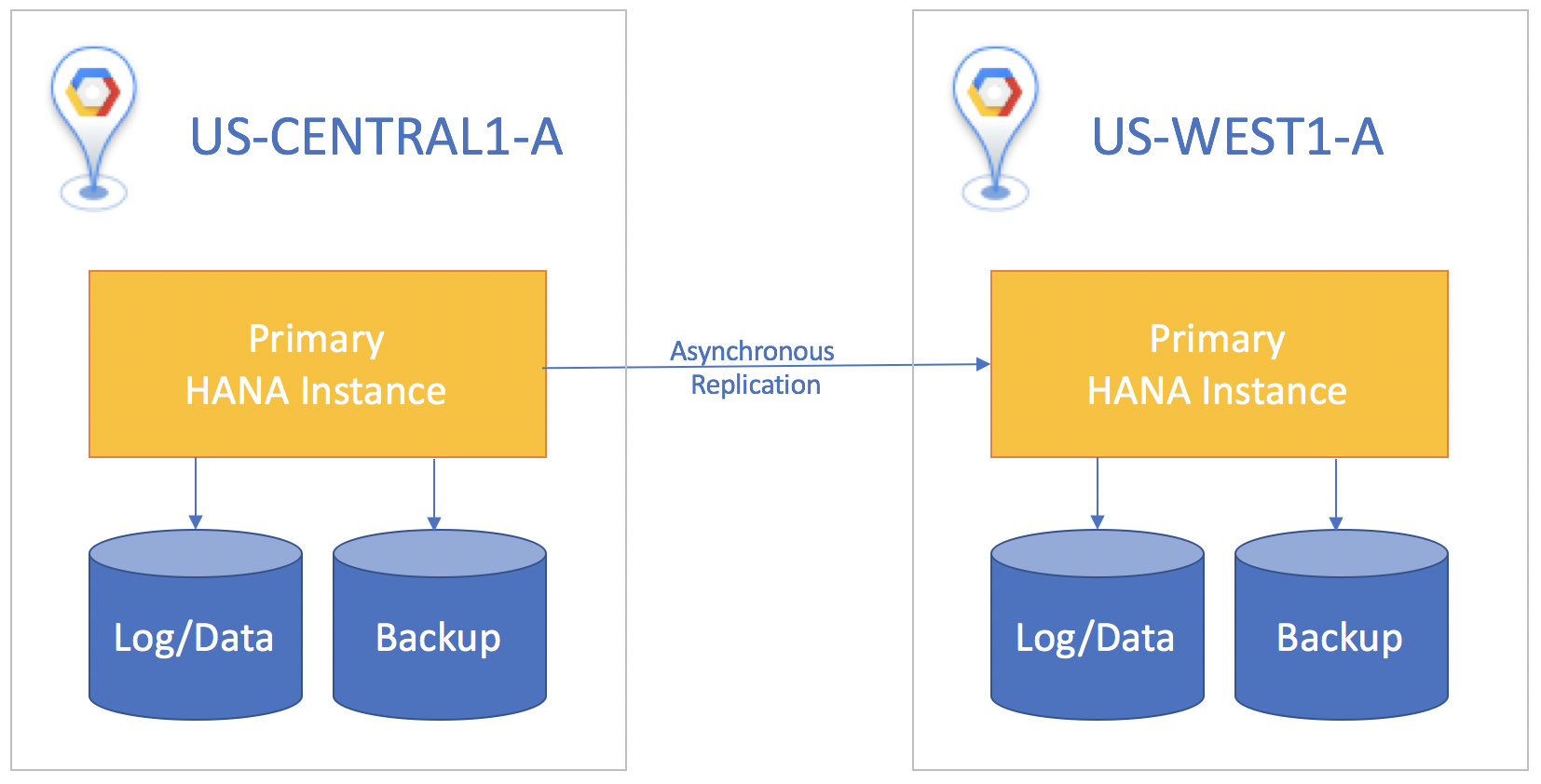
Para todos os cenários de replicação, é necessário executar manualmente uma transferência no sistema em espera para iniciar a recuperação de desastres. Você também precisa redirecionar manualmente os aplicativos que usam o banco de dados do SAP HANA para direcionar a instância na qual ele efetuou failover no sistema em espera.
Escolha a opção de replicação do sistema para HANA que melhor se adapta às necessidades do seu negócio, como o objetivo de tempo de recuperação (RTO, na sigla em inglês) e o objetivo de ponto de recuperação (RPO, na sigla em inglês). Para mais informações, consulte Modos de replicação para a replicação do sistema SAP HANA (em inglês).
Replicação do sistema SAP HANA com pré-carregamento
Neste cenário, o sistema SAP HANA é replicado para um sistema dedicado em espera. O banco de dados SAP HANA é replicado para uma VM do Compute Engine com um nome de host exclusivo e discos permanentes próprios anexados. Todos os dados do SAP HANA são carregados na memória no sistema em espera. Caso você precise fazer um failover, ele levará apenas cerca de 90 segundos, porque todos os dados serão pré-carregados.
Para mais informações sobre a replicação do sistema SAP HANA com pré-carregamento, consulte a seção Replicação do sistema em SAP HANA: alta disponibilidade.
Replicação do sistema SAP HANA sem pré-carregamento
Neste cenário, o sistema SAP HANA é replicado para um sistema dedicado em espera. O banco de dados SAP HANA é replicado para uma VM do Compute Engine com um nome de host exclusivo e discos permanentes próprios anexados. Os dados do SAP HANA não são carregados na memória do sistema em espera. Caso você precise fazer um failover, ele pode levar de minutos a horas, dependendo do tamanho do conjunto de dados.
Quando você não pré-carrega os dados, os requisitos de memória da VM do Compute Engine que hospeda o banco de dados SAP HANA são muito menores. Para receber mais orientações sobre o dimensionamento, consulte a Nota SAP 1999880 - Perguntas frequentes: replicação de sistema do SAP HANA em "Quais regras se aplicam à utilização da memória em sites de replicação do sistema secundário?".
Para informações sobre o espaço ocupado na memória pelo armazenamento de linhas, execute a consulta a seguir:
SELECT round (sum(USED_FIXED_PART_SIZE + USED_VARIABLE_PART_SIZE)/1024/1024) AS "Row Tables MB" FROM M_RS_TABLES;
Ao escolher um tipo de máquina do Compute Engine, os requisitos reduzidos de memória oferecem opções de economia de custos.
Para reduzir seu custo operacional, use um tipo de máquina com poucas especificações de memória para hospedar o banco de dados SAP HANA no sistema em espera. Uma VM com pouca memória não é compatível com o SAP HANA em um sistema de produção, mas é possível usar essa VM de baixo custo para realizar uma aquisição em um cenário de recuperação de desastre e, em seguida, modificar a VM para alterar o tipo de máquina para um com uma quantidade compatível de memória. Para isso, é necessário interromper a VM para executar a atualização. Assim, haverá um tempo de inatividade extra antes que o sistema SAP HANA esteja disponível.
Para melhorar seu retorno do investimento, use um tipo de máquina com alta memória para hospedar o banco de dados SAP HANA no sistema em espera e compartilhá-lo com sistemas de desenvolvimento ou de teste. É possível definir o limite de alocação global do banco de dados SAP HANA para 64 GB seguindo as instruções em Alterar o limite de alocação de memória global (em inglês), liberando o restante da memória para que ela seja usada por outros sistemas. Quando for necessário usar o sistema em espera, encerre as operações de desenvolvimento e teste, execute uma aquisição e remova o limite de alocação global.
É possível a replicação síncrona e assíncrona sem pré-carregamento. No entanto, a replicação síncrona exige que as instâncias de origem e destino estejam na mesma região Google Cloud .
É possível usar um provedor de HA/DR para resolver problemas, como desligar os sistemas de desenvolvimento e/ou de teste no host secundário.
Como ativar uma transferência
Para invocar a recuperação de desastres, acione o procedimento de transferência de replicação do sistema SAP HANA no sistema em espera. A nota 2063657 do SAP apresenta diretrizes para ajudar a decidir se a transferência é a melhor opção.
Para acionar a transferência, siga o processo de transição padrão do SAP HANA. Para mais informações sobre esse procedimento, consulte Como executar uma replicação de sistema para SAP HANA 2.0.
Caso haja problemas de dados ou falha de software, pode não haver notificações automáticas que permitam que você execute a aquisição. Considere criar uma solução personalizada para enviar alertas usando as ferramentas de monitoramento Cloud Monitoring ou HANA.
Recuperação de desastres usando backups do SAP HANA
Nos casos em que um objetivo de tempo de recuperação mais longo for aceitável e o objetivo do ponto de recuperação for maior que 15 minutos, é possível se recuperar de um desastre restaurando a partir do backup. Para garantir uma recuperação bem-sucedida usando backups, faça cópias frequentes dos arquivos de backup, especialmente de registros, em um bucket do Cloud Storage ou em algum outro local de armazenamento de longo prazo fora da região em que o sistema SAP HANA é executado. Recomendamos documentar a infraestrutura do seu sistema primário e criar scripts que permitam criar rapidamente um sistema substituto para restaurar seus backups.
Para mais informações, consulte o Guia de operações do SAP HANA.
Recuperação de desastres usando a replicação assíncrona de DPs
Para as cargas de trabalho SAP em execução no Google Cloud, a replicação assíncrona de DP permite a recuperação de desastres replicando dados entre duas regiões Google Cloud . A replicação assíncrona do DP fornece uma replicação assíncrona baixa do objetivo de ponto de recuperação (RPO, na sigla em inglês) e do objetivo de tempo de recuperação (RTO, na sigla em inglês) para a recuperação de desastres ativa passiva entre regiões. No caso improvável de uma falha temporária regional, a replicação assíncrona de DPs permite fazer failover dos dados para uma região secundária e reiniciar a carga de trabalho SAP nessa região.
É possível usar a replicação assíncrona do PD para gerenciar a replicação para cargas de trabalho do SAP baseadas no Compute Engine no nível da infraestrutura, em vez do nível da carga de trabalho do SAP, como a replicação do sistema SAP HANA.
A replicação assíncrona do DP replica os dados da SAP de um disco primário anexado a uma carga de trabalho em execução para um disco em branco secundário, localizado em outra região. Para mais informações, consulte Sobre replicação assíncrona de disco permanente.
Limitações da replicação assíncrona de DP
Para a replicação assíncrona de PD, só é possível usar volumes de disco permanente equilibrado (pd-balanced) e de desempenho (SSD) (pd-ssd) em pares de regiões com suporte.
Saiba
mais em
Limitações.
Monitore e avalie a taxa de alteração na carga de trabalho em relação à capacidade da replicação assíncrona de DP, revisando as métricas de monitoramento do par de dispositivos, conforme descrito em Analisar o desempenho da replicação assíncrona de disco permanente.
Não é esperado que a métrica async_replication/sent_bytes_count mostre um aumento constante na quantidade de dados transferidos porque ela representa o delta do número de bytes enviados por meio da rede entre regiões.