이 가이드에서는 Google Cloud의 Compute Engine 가상 머신 (VM)에서 실행되는 SAP LT Replication Server에 SAP용 BigQuery 커넥터 버전 2.0 또는 2.1을 설치하고 구성하는 방법을 설명합니다.
이 가이드에서는 SAP 애플리케이션에서 BigQuery로 직접 실시간으로 SAP 데이터를 복제하기 위해 BigQuery, SAP Landscape Transformation Replication Server(SAP LT Replication Server) 및 SAP용 BigQuery 커넥터를 준비하는 방법을 보여줍니다.
이 가이드는 SAP 관리자, Google Cloud 관리자, 기타 SAP 및 Google Cloud 보안 및 데이터 전문가를 대상으로 합니다.
기본 요건
SAP용 BigQuery 커넥터를 설치하려면 먼저 다음 기본 요건이 충족되었는지 확인합니다.
- SAP용 BigQuery 커넥터 계획 가이드를 읽습니다. 계획 가이드에서는 SAP용 BigQuery 커넥터 옵션, 성능 고려 사항, 필드 매핑, SAP용 BigQuery 커넥터의 최적 구성에 필요한 기타 정보를 설명합니다.
아직 Google Cloud 프로젝트가 없다면 다음 단계에 따라 만듭니다.
프로젝트에 결제가 사용 설정되어 있습니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요. BigQuery Streaming API 및 BigQuery를 사용하고 SAP용 BigQuery 커넥터를 다운로드하려면 결제 계정이 필요합니다.
설치된 SAP 소프트웨어의 유지보수가 최신 상태이고 모든 SAP 소프트웨어 버전이 SAP 제품 지원 여부 표에 설명된 대로 서로 호환됩니다.
사용 중인 SAP 소프트웨어 버전이 소프트웨어 요구사항에 설명된 대로 SAP용 BigQuery 커넥터에서 지원됩니다.
SAP LT Replication Server SDK를 통해 모든 대상에 데이터를 복제하는 데 필요한 올바른 SAP 라이선스가 있습니다. SAP 라이선스에 대한 자세한 내용은 SAP Note 2707835를 참조하세요.
SAP LT Replication Server가 설치되어 있습니다. SAP LT Replication Server 설치에 대한 자세한 내용은 SAP 문서를 참조하세요.
SAP LT Replication Server와 소스 시스템 간의 RFC 또는 데이터베이스 연결이 구성되어 있습니다. 필요에 따라 SAP 트랜잭션
SM59를 사용해서 RFC 연결을 테스트합니다. SAP 트랜잭션DBACOCKPIT을 사용해서 데이터베이스 연결을 테스트합니다.
설치 및 구성 프로세스 개요
다음 표에서는 이 가이드에 포함된 절차 및 이를 수행하는 역할을 보여줍니다.
| 절차 | 역할 |
|---|---|
| 필요에 따라 SAP에서 모든 적합한 라이선스를 검사한 후 SAP 안내에 따라 SAP Landscape Transformation Replication Server를 설치합니다. | SAP 관리자 |
| 필요한 경우 SAP NetWeaver용 사용자 인터페이스(UI) 부가기능을 설치합니다. 자세한 내용은 SAP 소프트웨어 버전 요구사항을 참조하세요. | SAP 관리자 |
| 필요한 Google Cloud API를 사용 설정합니다. | Google Cloud 관리자. |
| 필요한 경우 SAP LT Replication Server 호스트에 gcloud CLI를 설치합니다. | SAP 관리자 |
| BigQuery 데이터세트 만들기 | Google Cloud 관리자 또는 데이터 엔지니어. |
| 인증 및 승인을 설정합니다 Google Cloud . | Google Cloud 보안 관리자 |
| SAP용 BigQuery 커넥터 설치 패키지를 다운로드합니다. | Google Cloud 결제 계정 소유자 |
| SAP용 BigQuery 커넥터를 설치합니다. | SAP 관리자 |
| SAP용 BigQuery 커넥터의 SAP 역할 및 권한을 만듭니다. | SAP 관리자 |
| 복제를 구성합니다. | 데이터 엔지니어 또는 관리자 |
| 복제를 테스트합니다. | 데이터 엔지니어 또는 관리자 |
| 복제를 검사합니다. | 데이터 엔지니어 또는 관리자 |
필요한 Google Cloud API 사용 설정
SAP용 BigQuery 커넥터가 BigQuery에 액세스하려면 먼저 다음 Google Cloud API를 사용 설정해야 합니다.
- BigQuery API
- IAM Service Account Credentials API
Google Cloud API를 사용 설정하는 방법에 관한 자세한 내용은 API 사용 설정을 참고하세요.
gcloud CLI 설치
BigQuery에 복제하려면 sidadm 사용자 계정에 SAP LT Replication Server 호스트의 Google Cloud CLI(gcloud CLI)에 대한 액세스 권한이 있어야 합니다.
gcloud
components list를 실행하여 설치를 확인할 수 있습니다. 명령어가 인식되지 않으면 gcloud CLI를 설치해야 합니다.
SAP 관리자가 gcloud CLI를 설치할 수 있습니다.
gcloud CLI를 설치하려면 다음 단계를 완료합니다.
gcloud CLI 설치 안내를 따릅니다.
sidadm사용자 계정이 gcloud CLI 설치 디렉터리에 액세스하도록 승인합니다.선택적으로
sidadm으로 gcloud CLI의 기본 프로젝트를 설정합니다.gcloud config set project PROJECT_ID
PROJECT_ID를 BigQuery 데이터 세트가 포함된 프로젝트의 ID로 바꿉니다. 예를 들면example-project-123456입니다.gcloud CLI에 대해 기본 프로젝트를 설정하지 않으면 실행되는 각
gcloud명령어에--project속성을 지정해야 합니다.
gcloud CLI의 SAP용 BigQuery 커넥터 요구사항에 대한 자세한 내용은 gcloud CLI 요구사항을 참조하세요.
BigQuery 데이터 세트 만들기
BigQuery에 대해 Google Cloud 인증 및 승인을 테스트하거나 대상 BigQuery 테이블을 만들려면 귀하나 데이터 엔지니어 또는 관리자가 BigQuery 데이터 세트를 만들어야 합니다.
BigQuery 데이터 세트를 만들려면 사용자 계정에 BigQuery에 대해 적절한 IAM 권한이 있어야 합니다. 자세한 내용은 필수 권한을 참조하세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
프로젝트 ID 옆에서 작업 보기 아이콘 을 클릭한 후 데이터 세트 만들기를 클릭합니다.
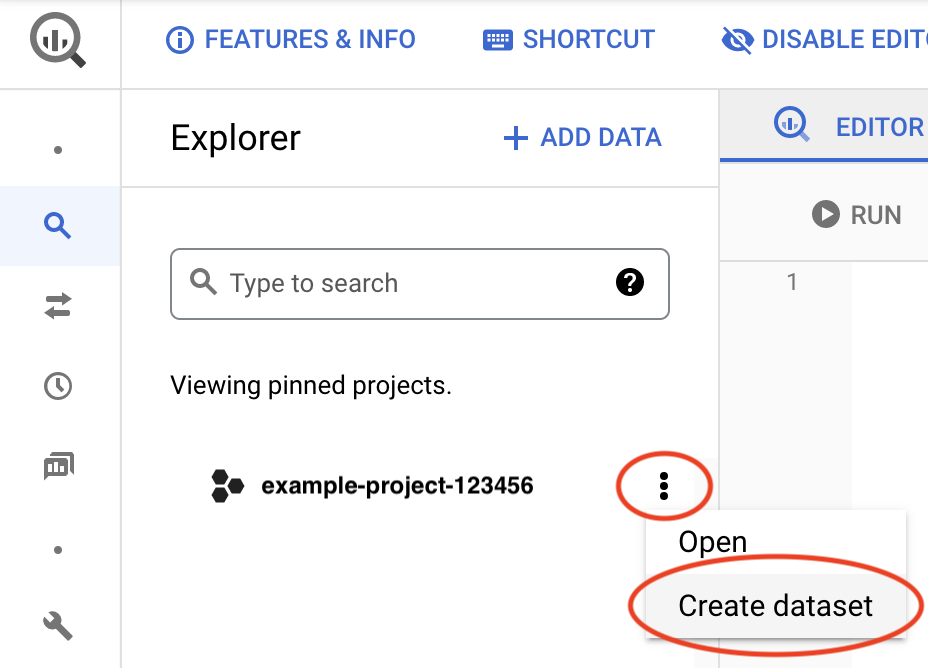
데이터 세트 ID 필드에 고유한 이름을 입력합니다. 자세한 내용은 데이터 세트 이름 만들기를 참조하세요.
Google Cloud 인증 및 승인을 설정한 후에는 이 데이터 세트에 대한 정보를 검색하여 Google Cloud 액세스를 테스트합니다.
BigQuery 데이터 세트 만들기에 대한 자세한 내용은 데이터 세트 만들기를 참조하세요.
Google Cloud 인증 및 승인 설정
BigQuery에 Google Cloud 인증하고 액세스 권한을 승인하려면 Google Cloud 보안 관리자와 SAP 관리자가 다음을 수행해야 합니다.
- SAP용 BigQuery 커넥터의 서비스 계정을 만듭니다.
- BigQuery에 액세스하는 데 필요한 IAM 역할을 서비스 계정에 부여합니다.
- SAP용 BigQuery 커넥터의 서비스 계정을 BigQuery 프로젝트의 주 구성원으로 추가합니다.
- SAP LT Replication Server 호스트에서 Google Cloud 에 대한 보안 설정을 구성합니다.
- 호스트 VM에 액세스 토큰을 가져오기 위한 권한을 부여합니다.
- 필요에 따라 호스트 VM의 API 액세스 범위를 수정합니다.
서비스 계정 만들기
SAP용 BigQuery 커넥터가 BigQuery에 액세스하기 위해서는 인증 및 승인을 위한 IAM 서비스 계정이 필요합니다.
이 서비스 계정은 BigQuery 데이터 세트가 포함된 Google Cloud 프로젝트의 주 구성원이어야 합니다. BigQuery 데이터 세트와 동일한 프로젝트에 서비스 계정을 만들면 서비스 계정이 자동으로 프로젝트에 주 구성원으로 추가됩니다.
BigQuery 데이터 세트가 포함된 프로젝트가 아닌 다른 프로젝트에 서비스 계정을 만드는 경우 추가적인 단계를 수행하여 BigQuery 데이터 세트 프로젝트에 서비스 계정을 추가해야 합니다.
서비스 계정을 만들려면 다음 단계를 완료하세요.
Google Cloud 콘솔에서 IAM 및 관리자 서비스 계정 페이지로 이동합니다.
메시지가 표시되면 Google Cloud 프로젝트를 선택합니다.
서비스 계정 만들기를 클릭합니다.
서비스 계정의 이름과 설명(선택 사항)을 지정합니다.
만들고 계속하기를 클릭합니다.
BigQuery 데이터 세트와 동일한 프로젝트에 서비스 계정을 만드는 경우 이 서비스 계정에 프로젝트에 대한 액세스 권한 부여 패널에서 다음 역할을 선택합니다.
- BigQuery 데이터 편집자
- BigQuery 작업 사용자
BigQuery 데이터 세트와 다른 프로젝트에 서비스 계정을 만드는 경우 서비스 계정에 역할을 부여하지 마세요.
계속을 클릭합니다.
필요에 따라 다른 사용자에게 서비스 계정에 대한 액세스 권한을 부여합니다.
완료를 클릭합니다. 프로젝트의 서비스 계정 목록에 서비스 계정이 표시됩니다.
BigQuery 데이터 세트가 포함된 프로젝트가 아닌 다른 프로젝트에 서비스 계정을 만든 경우 이 서비스 계정의 이름을 메모하세요. BigQuery 프로젝트에 서비스 계정을 추가할 때 이름을 지정합니다. 자세한 내용은 BigQuery 프로젝트에 서비스 계정 추가를 참조하세요.
이제 서비스 계정이 생성된 Google Cloud 프로젝트의 IAM 권한 페이지에 서비스 계정이 주 구성원으로 나열됩니다.
BigQuery 프로젝트에 서비스 계정 추가
대상 BigQuery 데이터 세트가 포함된 프로젝트가 아닌 다른 프로젝트에 SAP용 BigQuery 커넥터의 서비스 계정을 만든 경우 BigQuery 데이터 세트 프로젝트에 서비스 계정을 추가해야 합니다.
BigQuery 데이터 세트와 동일한 프로젝트에 서비스 계정을 만든 경우 이 단계를 건너뛸 수 있습니다.
BigQuery 데이터 세트 프로젝트에 기존 서비스 계정을 추가하려면 다음 단계를 완료하세요.
Google Cloud 콘솔에서 IAM 권한 페이지로 이동합니다.
대상 BigQuery 데이터 세트가 포함된 프로젝트의 이름이 페이지 상단 근처에 표시되는지 확인합니다. 예를 들면 다음과 같습니다.
'
PROJECT_NAME' 프로젝트의 권한표시되지 않은 경우 프로젝트를 전환합니다.
IAM 페이지에서 추가를 클릭합니다. '
PROJECT_NAME'에 주 구성원 추가 대화상자가 열립니다.'
PROJECT_NAME'에 주 구성원 추가 대화상자에서 다음 단계를 수행합니다.- 새 주 구성원 필드에서 서비스 계정의 이름을 지정합니다.
- 역할 선택 필드에 BigQuery 데이터 편집자를 지정합니다.
- 다른 역할 추가를 클릭합니다. 역할 선택 필드가 다시 표시됩니다.
- 역할 선택 필드에 BigQuery 작업 사용자를 지정합니다.
- 저장을 클릭합니다. IAM 페이지의 프로젝트 주 구성원 목록에 서비스 계정이 표시됩니다.
이제 서비스 계정을 사용하여 이 프로젝트의 BigQuery 데이터 세트에 액세스할 수 있습니다.
호스트 VM에서 보안 구성
SAP용 BigQuery 커넥터를 사용하려면 다음 보안 옵션을 사용해서 SAP LT Replication Server를 호스팅하는 Compute Engine VM을 구성해야 합니다.
- Cloud API에 대해 전체 액세스를 허용하도록 호스트 VM의 액세스 범위를 설정해야 합니다.
- 호스트 VM의 서비스 계정에는 IAM 서비스 계정 토큰 생성자 역할이 있어야 합니다.
이러한 옵션이 호스트 VM에 구성되지 않았으면 이를 구성해야 합니다.
VM의 액세스 범위를 변경하려면 VM을 중지해야 합니다.
호스트 VM의 API 액세스 범위 확인
SAP LT Replication Server 호스트 VM의 현재 액세스 범위 설정을 확인합니다. VM에 이미 모든 Cloud API에 대한 전체 액세스 권한이 있는 경우 액세스 범위를 변경할 필요가 없습니다.
호스트 VM의 액세스 범위를 확인하려면 다음 단계를 완료합니다.
Google Cloud 콘솔
Google Cloud 콘솔에서 VM 인스턴스 페이지를 엽니다.
필요한 경우 SAP LT Replication Server 호스트가 포함된 Google Cloud 프로젝트를 선택합니다.
VM 인스턴스 페이지에서 호스트 VM의 이름을 클릭합니다. VM 세부정보 페이지가 열립니다.
호스트 VM 세부정보 페이지의 API 및 ID 관리에서 Cloud API 액세스 범위의 현재 설정을 확인합니다.
- 설정이 모든 Cloud API에 대한 전체 액세스 허용이면 설정이 올바른 상태이므로 변경할 필요가 없습니다.
- 설정이 모든 Cloud API에 대한 전체 액세스 허용이 아닌 경우 VM을 중지하고 설정을 변경해야 합니다. 자세한 내용은 다음 섹션을 참조하세요.
gcloud CLI
호스트 VM의 현재 액세스 범위를 표시합니다.
gcloud compute instances describe VM_NAME --zone=VM_ZONE --format="yaml(serviceAccounts)"
액세스 범위에
https://www.googleapis.com/auth/cloud-platform이 포함되지 않은 경우 호스트 VM의 액세스 범위를 변경해야 합니다. 예를 들어 기본 Compute Engine 서비스 계정을 사용하여 VM 인스턴스를 만들 경우 다음 기본 액세스 범위를 변경해야 합니다.serviceAccounts: - email: 600915385160-compute@developer.gserviceaccount.com scopes: - https://www.googleapis.com/auth/devstorage.read_only - https://www.googleapis.com/auth/logging.write - https://www.googleapis.com/auth/monitoring.write - https://www.googleapis.com/auth/servicecontrol - https://www.googleapis.com/auth/service.management.readonly - https://www.googleapis.com/auth/trace.append
다음 예시와 같이
scopes에 나열된 유일한 범위가https://www.googleapis.com/auth/cloud-platform이면 범위를 변경할 필요가 없습니다.serviceAccounts: - email: 600915385160-compute@developer.gserviceaccount.com scopes: - https://www.googleapis.com/auth/cloud-platform
호스트 VM의 API 액세스 범위 변경
SAP LT Replication Server 호스트 VM에Google Cloud API에 대한 전체 액세스 권한이 없으면 모든 Cloud API에 대해 전체 액세스를 허용하도록 액세스 범위를 변경합니다.
호스트 VM의 Cloud API 액세스 범위 설정을 변경하려면 다음 단계를 완료하세요.
Google Cloud 콘솔
필요한 경우 호스트 VM의 보안 계정에 부여되는 역할을 제한합니다.
호스트 VM 세부정보 페이지의 API 및 ID 관리 아래에서 보안 계정 이름을 확인할 수 있습니다. Google Cloud 콘솔의 주 구성원 아래 IAM 페이지에서 서비스 계정에 부여된 역할을 변경할 수 있습니다.
필요한 경우 호스트 VM에서 실행 중인 워크로드를 중지합니다.
Google Cloud 콘솔에서 VM 인스턴스 페이지를 엽니다.
VM 인스턴스 페이지에서 호스트 VM 이름을 클릭하여 VM 세부정보 페이지를 엽니다.
호스트 VM 세부정보 페이지 상단에서 중지를 클릭하여 호스트 VM을 중지합니다.
VM이 중지된 다음 수정을 클릭합니다.
보안 및 액세스 > 액세스 범위에서 모든 Cloud API에 대한 전체 액세스 허용을 선택합니다.
저장을 클릭합니다.
호스트 VM 세부정보 페이지 상단에서 시작/재개를 클릭하여 호스트 VM을 시작합니다.
필요한 경우 호스트 VM에서 중지된 워크로드를 다시 시작합니다.
gcloud CLI
필요한 경우 호스트 VM에서 Google Cloud서비스에 대한 액세스가 적절하게 제한되도록 VM 서비스 계정에 부여되는 IAM 역할을 조정합니다.
서비스 계정에 부여된 역할을 변경하는 방법은 서비스 계정 업데이트를 참조하세요.
필요한 경우 호스트 VM에서 실행되는 SAP 소프트웨어를 중지합니다.
VM을 중지합니다.
gcloud compute instances stop VM_NAME --zone=VM_ZONE
VM의 액세스 범위를 변경합니다.
gcloud compute instances set-service-account VM_NAME --scopes=cloud-platform --zone=VM_ZONE
다음을 실행하여 VM을 시작합니다.
gcloud compute instances start VM_NAME --zone=VM_ZONE
필요한 경우 호스트 VM에서 실행되는 SAP 소프트웨어를 시작합니다.
호스트 VM이 액세스 토큰을 얻을 수 있도록 설정
SAP용 BigQuery 커넥터가 BigQuery에 액세스하기 위해 필요한 액세스 토큰을 가져오려면 호스트 VM의 서비스 계정에 권한을 부여해야 합니다.
액세스 토큰을 생성할 수 있는 권한을 부여하려면 다음 단계를 완료하세요.
Google Cloud 콘솔에서 VM 인스턴스 페이지를 엽니다.
VM 인스턴스 페이지에서 호스트 VM 이름을 클릭하여 VM 세부정보 페이지를 엽니다.
API 및 ID 관리 아래의 VM 세부정보 페이지에 나온 서비스 계정 이름을 기록해 둡니다. 다음은 기본 Compute Engine 서비스 계정의 예시 이름입니다.
SVC-ACCT-NUMBER-compute@developer.gserviceaccount.com
Google Cloud 콘솔에서 IAM 페이지로 이동합니다.
프로젝트 주 구성원 목록에서 서비스 계정 이름을 찾고 주 구성원 수정을 클릭합니다. 권한 수정 대화상자가 열립니다.
권한 수정 대화상자에서 다른 역할 추가를 클릭합니다. 역할 선택 필드가 표시됩니다.
역할 선택 필드에 서비스 계정 토큰 생성자를 지정합니다.
저장을 클릭합니다. IAM 권한 페이지로 돌아갑니다.
이제 호스트 VM에 액세스 토큰을 만들 수 있는 권한이 있습니다.
SSL 인증서 및 HTTPS 설정
SAP용 BigQuery 커넥터와 BigQuery API 간의 통신은 SSL 및 HTTPS를 사용하여 보호됩니다.
Google Trust Services 저장소에서 다음 인증서를 다운로드합니다.
GTS Root R1GTS CA 1C3
SAP GUI에서
STRUST트랜잭션을 사용하여 루트 인증서와 하위 인증서를 모두SSL client SSL Client (Standard)PSE 폴더로 가져옵니다.SAP의 자세한 내용은 SAP 도움말 - PSE 인증 목록 유지보수를 참조하세요.
SAP LT Replication Server 호스트에서 방화벽 규칙 또는 프록시가 HTTPS 포트에서 BigQuery API로 이그레스 트래픽을 허용하도록 구성되었는지 확인합니다.
특히 SAP LT Replication Server가 다음Google Cloud API에 액세스할 수 있어야 합니다.
- https://bigquery.googleapis.com
- https://iamcredentials.googleapis.com
SAP에서 SSL 설정에 대한 자세한 내용은 SAP Note 510007 - 애플리케이션 서버 ABAP에 SSL 설정을 위한 추가 고려사항을 참조하세요.
테스트 Google Cloud 인증 및 승인
액세스 토큰을 요청하고 BigQuery 데이터 세트에 대해 정보를 검색하여 Google Cloud 인증이 올바르게 구성되었는지 확인합니다.
다음 절차에 따라 SAP LT Replication Server 호스트 VM에서 Google Cloud 인증 및 승인을 테스트합니다.
SAP LT Replication Server 호스트 VM에서 명령줄 셸을 엽니다.
sidadm사용자로 전환합니다.호스트 VM의 메타데이터 서버에서 첫 번째 액세스 토큰을 요청합니다.
curl "http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token" -H "Metadata-Flavor: Google"
메타데이터 서버는 다음 예시와 비슷한 액세스 토큰을 반환합니다. 여기에서 ACCESS_TOKEN_STRING_1은 다음 단계에서 명령어에 복사할 액세스 토큰 문자열입니다.
{"access_token":"ACCESS_TOKEN_STRING_1", "expires_in":3599,"token_type":"Bearer"}자리표시자 값을 바꾸고 다음 명령어를 실행해서 IAM API에서 두 번째 액세스 토큰을 요청합니다.
curl --request POST \ 'https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/SERVICE_ACCOUNT:generateAccessToken' \ --header 'Authorization: Bearer ACCESS_TOKEN_STRING_1' \ --header 'Accept: application/json' \ --header 'Content-Type: application/json' \ --data '{"scope":["https://www.googleapis.com/auth/bigquery"],"lifetime":"300s"}' \ --compressed다음을 바꿉니다.
SERVICE_ACCOUNT: 이전 단계에서 SAP용 BigQuery 커넥터에 대해 만든 서비스 계정입니다.ACCESS_TOKEN_STRING_1: 이전 단계에서 첫 번째 액세스 토큰 문자열입니다.
IAM API는 다음 예시와 비슷한 두 번째 액세스 토큰인 ACCESS_TOKEN_STRING_2를 반환합니다. 다음 단계에서는 이 두 번째 토큰 문자열을 BigQuery API에 대한 요청에 복사합니다.
{"access_token":"ACCESS_TOKEN_STRING_2","expires_in":3599,"token_type":"Bearer"}자리표시자 값을 바꾸고 다음 명령어를 실행하여 BigQuery API에서 BigQuery 데이터 세트에 대해 정보를 검색합니다.
curl "https://bigquery.googleapis.com/bigquery/v2/projects/PROJECT_ID/datasets/DATASET_NAME" \ -H "Accept: application/json" -H "Authorization: Bearer ACCESS_TOKEN_STRING_2"
다음을 바꿉니다.
PROJECT_ID: BigQuery 데이터 세트가 포함된 객체의 ID입니다.DATASET_NAME: BigQuery에 정의된 대상 데이터 세트의 이름입니다.ACCESS_TOKEN_STRING_2: 이전 단계에서 IAM API가 반환한 액세스 토큰 문자열입니다.
인증이 올바르게 구성되면 Google Cloud 데이터 세트 정보가 반환됩니다.
올바르게 구성되지 않았으면 SAP용 BigQuery 커넥터 문제 해결을 참조하세요.
설치 패키지 다운로드
SAP용 BigQuery 커넥터 다운로드 포털에서 SAP용 BigQuery 커넥터 설치 패키지를 다운로드합니다.
다운로드를 완료하려면 Cloud Billing 번호가 필요합니다. 결제 계정에 대한 자세한 내용은 Cloud Billing 및 결제 프로필을 참조하세요.
설치 패키지에는 SAP LT Replication Server의 적합한 전송 디렉터리에 복사할 전송 파일이 포함되어 있습니다.
SAP용 BigQuery 커넥터 설치
SAP용 BigQuery 커넥터 전송 파일이 포함된 설치 패키지를 수신한 후 SAP 관리자가 전송 파일을 SAP LT Replication Server로 가져와서 SAP용 BigQuery 커넥터를 설치할 수 있습니다.
SAP용 BigQuery 커넥터의 SAP 전송에는 /GOOG/ 네임스페이스, DDIC 객체, SLT SDK BADI 구현 및 클래스, 보고서 프로그램 등 SAP용 BigQuery 커넥터에 필요한 객체가 모두 포함되어 있습니다.
전송 파일을 SAP LT Replication Server로 가져오기 전에 소프트웨어 요구사항의 설명대로 SAP LT Replication Server가 SAP용 BigQuery 커넥터에서 지원되는지 확인합니다.
지원되는 버전의 SAP LT Replication Server를 사용하더라도 전송 파일을 가져올 때 오류 메시지 Requests do not match the component version of the target system이 표시될 수 있습니다. 이 경우 전송 파일을 SAP LT Replication Server로 다시 가져와야 하며 다시 가져오는 동안 전송 요청 가져오기 화면 > 옵션 탭에서 잘못된 구성요소 버전 무시 체크박스를 선택합니다.
다음 절차는 일반적인 절차입니다. SAP 시스템이 서로 다르기 때문에 SAP 관리자와 협력해서 해당 SAP 시스템에 맞게 절차를 변경해야 합니다.
SAP용 BigQuery 커넥터 전송 파일을 다음 SAP LT Replication Server 전송 가져오기 디렉터리에 복사합니다.
/usr/sap/trans/cofiles/KXXXXXX.ED1/usr/sap/trans/data/RXXXXXX.ED1
앞의 예시에서
XXXXXX는 번호가 지정된 파일 이름을 나타냅니다.SAP GUI에서는 트랜잭션 코드
STMS_IMPORT또는STMS를 사용해서 SAP 시스템으로 파일을 가져옵니다./GOOG/SLT_SDK패키지의 모든 객체가 활성 상태이고 일치하는지 확인합니다.- SAP 인터페이스에서 트랜잭션 코드
SE80을 입력합니다. - 패키지 선택기에서
/GOOG/SLT_SDK를 선택합니다. 객체 이름 필드에서 패키지
/GOOG/SLT_SDK를 마우스 오른쪽 버튼으로 클릭한 후 확인 > 패키지 확인 > 패키지 객체를 선택합니다.결과 열에서 녹색 체크표시는 모든 객체가 패키지 확인을 통과했음을 나타냅니다.
- SAP 인터페이스에서 트랜잭션 코드
SAP용 BigQuery 커넥터 구성 준비 확인
또한 전송 파일을 올바르게 가져왔고 SAP용 BigQuery 커넥터가 구성 준비되었는지 확인하려면 SAP용 BigQuery 커넥터 비즈니스 부가기능(BAdI) 구현이 활성 상태이고 SAP용 BigQuery 커넥터 복제 애플리케이션에 IUUC_REPL_APPL 테이블의 항목이 포함되어 있는지 확인합니다.
- BAdI 구현을 확인합니다.
- 트랜잭션 SE80을 사용해서 탐색하고
/GOOG/EI_IUUC_REPL_RUNTIME_BQ수정 객체 폴더를 선택합니다. - 페이지 오른쪽에서 수정 구현 요소를 선택합니다.
- 런타임 동작에서 구현이 활성임이 선택되었는지 확인합니다.
- 트랜잭션 SE80을 사용해서 탐색하고
- 복제 애플리케이션을 확인합니다.
- SAP 데이터 브라우저 또는 트랜잭션
SE16을 사용해서IUUC_REPL_APPL테이블을 표시합니다. - 다음 애플리케이션이
IUUC_REPL_APPL테이블에 표시되는지 확인합니다./GOOG/SLT_BQZGOOG_SLT_BQ는/GOOG/네임스페이스가 등록되지 않은 경우에 사용됩니다.
- SAP 데이터 브라우저 또는 트랜잭션
SAP용 BigQuery 커넥터에 대한 SAP 역할 및 승인 만들기
SAP용 BigQuery 커넥터를 사용하려면 표준 SAP LT Replication Server 승인 외에도 사용자가 SAP용 BigQuery 커넥터에 제공되는 커스텀 트랜잭션 /GOOG/SLT_SETTINGS 및 /GOOG/REPLIC_VALID에 액세스할 수 있어야 합니다.
기본적으로 커스텀 트랜잭션에 액세스할 수 있는 사용자가 모든 구성 설정을 수정할 수 있으므로, 필요에 따라 액세스 권한을 특정 구성으로 제한할 수 있습니다.
SAP용 BigQuery 커넥터 전송 파일에는 SAP용 BigQuery 커넥터에 한정된 승인을 위한 Google BigQuery
Settings Authorization 객체 ZGOOG_MTID가 포함되어 있습니다.
커스텀 트랜잭션에 대해 액세스 권한을 부여하고 특정 구성으로 액세스를 제한하려면 다음 안내를 따르세요.
SAP 트랜잭션 코드
PFCG를 사용해서 SAP용 BigQuery 커넥터에 대해 역할을 정의합니다.이 역할에 커스텀 트랜잭션
/GOOG/SLT_SETTINGS및/GOOG/REPLIC_VALID에 대한 액세스 권한을 부여합니다.역할의 액세스 권한을 제한하려면
ZGOOG_MTID승인 객체를 사용해서 해당 역할이 액세스할 수 있는 각 구성의 승인 그룹을 지정합니다. 예를 들면 다음과 같습니다.- SAP용 BigQuery 커넥터에 대한 승인 객체(
ZGOOG_MTID):Activity 01Authorization Group AUTH_GROUP_1,AUTH_GROUP_N
AUTH_GROUP_01및AUTH_GROUP_N은 SAP LT Replication Server 구성에 정의된 값입니다.ZGOOG_MTID에 지정된 승인 그룹은 SAPS_DMIS_SLT승인 객체에서 역할에 대해 지정된 승인 그룹과 일치해야 합니다.- SAP용 BigQuery 커넥터에 대한 승인 객체(
복제 구성
복제를 구성하려면 SAP용 BigQuery 커넥터 및 SAP LT Replication Server 설정을 모두 지정해야 합니다.
/GOOG/CLIENT_KEY에서 액세스 설정 지정
SM30 트랜잭션을 사용하여 BigQuery에 대한 액세스 설정을 지정합니다. SAP용 BigQuery 커넥터는 이 설정을 /GOOG/CLIENT_KEY 커스텀 구성 테이블에 레코드로 저장합니다.
액세스 설정을 지정하려면 다음 안내를 따르세요.
SAP GUI에서 트랜잭션 코드
SM30를 입력합니다./GOOG/CLIENT_KEY구성 테이블을 선택합니다.다음 테이블 필드의 값을 입력합니다.
필드 데이터 유형 설명 이름 문자열 CLIENT_KEY구성의 설명이 포함된 이름(예:ABAP_SDK_CKEY)을 지정합니다.클라이언트 키 이름은 SAP용 BigQuery 커넥터에서 BigQuery에 액세스하기 위한 구성을 식별하는 데 사용하는 고유 식별자입니다.
서비스 계정 이름 문자열 서비스 계정 만들기 단계에서 SAP용 BigQuery 커넥터용으로 생성된 서비스 계정 이름(이메일 주소 형식)입니다. 예를 들면
sap-example-svc-acct@example-project-123456.iam.gserviceaccount.com입니다.범위 문자열 Compute Engine에서 권장한 대로
https://www.googleapis.com/auth/cloud-platformAPI 액세스 범위를 지정합니다. 이 액세스 범위는 호스트 VM의Allow full access to all Cloud APIs설정에 해당합니다. 자세한 내용은 호스트 VM에서 액세스 범위 설정을 참조하세요.프로젝트 ID 문자열 대상 BigQuery 데이터 세트가 포함된 프로젝트의 ID입니다. 명령어 이름 문자열 이 입력란은 비워둡니다.
승인 클래스 문자열 복제에 사용할 승인 클래스입니다. /GOOG/CL_GCP_AUTH_GOOGLE을 지정합니다.승인 필드 해당 사항 없음 이 입력란은 비워둡니다. 토큰 새로고침 시간(초) 정수 액세스 토큰이 만료되기 전에 새로고침해야 하는 시간(초)을 지정합니다. 기본값은
3600(1시간)입니다.1~3599까지 값을 지정하면 기본 만료 시간인3600초가 재정의됩니다.0을 지정하면 SAP용 BigQuery 커넥터에 기본값3600이 사용됩니다.
SAP LT Replication Server 복제 구성 만들기
SAP 트랜잭션 LTRC를 사용해서 SAP LT Replication Server 복제 구성을 만듭니다.
SAP LT Replication Server가 소스 SAP 시스템과 다른 서버에서 실행되는 경우 복제 구성을 만들기 전 두 시스템 간 RFC 연결이 설정되어 있는지 확인합니다.
복제 구성의 일부 설정은 성능에 영향을 줍니다. 설치에 적합한 설정 값을 결정하려면 SAP 도움말 포털에서 SAP LT Replication Server 버전에 대한 성능 최적화 가이드를 참조하세요.
SAP LT Replication Server의 인터페이스 및 구성 옵션은 사용 중인 버전에 따라 약간 다를 수 있습니다.
복제를 구성하려면 SAP LT Replication Server 버전에 맞는 절차를 따르세요.
DMIS 2011 SP17, DMIS 2018 SP02 이상에서 복제 구성
다음 단계에서는 SAP LT Replication Server의 이후 버전에서 복제를 구성합니다. 이전 버전을 사용하는 경우에는 DMIS 2011 SP16, DMIS 2018 SP01 이하에서 복제 구성을 참조하세요.
SAP GUI에서 트랜잭션 코드
LTRC를 입력합니다.구성 만들기 아이콘을 클릭합니다. 구성 만들기 마법사가 열립니다.
구성 이름 및 설명 필드에 해당 구성의 이름 및 설명을 입력한 후 다음을 클릭합니다.
특정 승인 그룹으로 액세스를 제한하기 위해 지금 승인 그룹을 지정하거나 나중에 이를 지정할 수 있습니다.
소스 시스템 연결 세부정보 패널에서 다음을 수행합니다.
- RFC 연결 라디오 버튼을 선택합니다.
- RFC 대상 필드에서 소스 시스템에 대한 RFC 연결 이름을 지정합니다.
- 필요에 따라 다중 사용 허용 및 단일 클라이언트에서 읽기 체크박스를 선택합니다. 자세한 내용은 SAP LT Replication Server 문서를 참조하세요.
- 다음을 클릭합니다.
이러한 단계는 RFC 연결에 사용되지만, 소스가 데이터베이스인 경우 대신
DBACOCKPIT트랜잭션을 사용해서 연결을 이미 정의했으면 DB 연결을 선택할 수 있습니다.대상 시스템 연결 세부정보 패널에서 다음을 수행합니다.
- 기타 라디오 버튼을 선택합니다.
- 시나리오 필드의 드롭다운 메뉴에서 SLT SDK를 선택합니다.
- 다음을 클릭합니다.
전송 설정 지정 패널에서 다음을 수행합니다.
데이터 전송 설정 섹션의 애플리케이션 필드에
/GOOG/SLT_BQ또는ZGOOG_SLT_BQ를 입력합니다.작업 옵션 섹션의 다음 각 필드에 시작 값을 입력합니다.
- 데이터 전송 작업 수
- 초기 로드 작업 수
- 계산 작업 수
복제 옵션 섹션에서 실시간 라디오 버튼을 선택합니다.
다음을 클릭합니다.
구성을 검토한 후 저장을 클릭합니다.
대량 전송 열에서 세 자릿수 ID를 기록해 둡니다. 이후 단계에서 사용됩니다.
자세한 내용은 SAP Note 2652704: Replicating Data Using SLT SDK - DMIS 2011 SP17, DMIS 2018 SP02.pdf에 첨부된 PDF를 참조하세요.
DMIS 2011 SP16, DMIS 2018 SP01 이하에서 복제 구성
다음 단계에서는 SAP LT Replication Server의 이전 버전에서 복제를 구성합니다. 이후 버전을 사용하는 경우에는 DMIS 2011 SP17, DMIS 2018 SP02 이상에서 복제 구성을 참조하세요.
- SAP GUI에서 트랜잭션 코드
LTRC를 입력합니다. - 새로 만들기를 클릭합니다. 새 구성을 지정하는 대화상자가 열립니다.
- 소스 시스템 지정 단계에서 다음을 수행합니다.
- 연결 유형으로 RFC 연결을 선택합니다.
- RFC 연결 이름을 입력합니다.
- 다중 사용 허용 필드가 선택되었는지 확인합니다.
- 대상 시스템 지정 단계에서 다음을 수행합니다.
- 대상 시스템에 대한 연결 데이터를 입력합니다.
- 연결 유형으로 RFC 연결을 선택합니다.
- RFC 통신 시나리오 필드의 드롭다운 목록에서 BAdI을 사용하여 대상에 데이터 쓰기 값을 선택합니다. RFC 연결이 자동으로 NONE으로 설정됩니다.
- 전송 설정 지정 단계에서 F4 도움말을 누릅니다. 이전에 정의한 애플리케이션이 애플리케이션 필드에 표시됩니다.
- 대량 전송 열에서 세 자릿수 ID를 기록해 둡니다. 이후 단계에서 사용됩니다.
자세한 내용은 SAP Note 2652704: Replicating Data Using SLT SDK - DMIS 2011 SP15, SP16, DMIS 2018 SP00, SP01.pdf에 첨부된 PDF를 참조하세요.
BigQuery용 대량 전송 구성 만들기
커스텀 /GOOG/SLT_SETTINGS 트랜잭션을 사용하여 BigQuery용 대량 전송을 구성하고 테이블 및 필드 매핑을 지정합니다.
초기 대량 전송 옵션 선택
/GOOG/SLT_SETTINGS 트랜잭션을 처음 입력할 때 BigQuery 대량 전송 구성에서 수정해야 하는 부분을 선택합니다.
대량 전송 구성의 부분을 선택하려면 다음 안내를 따르세요.
SAP GUI에서
/n에 이어/GOOG/SLT_SETTINGS트랜잭션을 입력합니다./n/GOOG/SLT_SETTINGS/GOOG/SLT_SETTINGS트랜잭션 시작 화면의 설정 테이블 드롭다운 메뉴에서 대량 전송을 선택합니다.새 대량 전송 구성의 경우 대량 전송 키 필드를 비워 둡니다.
실행 아이콘을 클릭합니다. BigQuery 설정 유지보수 - 대량 전송 화면이 표시됩니다.
테이블 만들기 및 기타 일반 속성 지정
BigQuery 대량 전송 구성의 초기 섹션에서는 대량 전송 구성을 식별하고 대상 BigQuery 테이블 만들기와 관련된 특정 속성뿐 아니라 연결된 클라이언트 키를 지정합니다.
SAP LT Replication Server는 대량 전송 구성을 /GOOG/BQ_MASTR 커스텀 구성 테이블의 레코드로 저장합니다.
다음 단계에서 지정하는 필드가 필요합니다.
BigQuery 설정 유지보수 - 대량 전송 화면에서 행 추가 아이콘을 클릭합니다.
표시된 행에서 다음 설정을 지정합니다.
- 대량 전송 키 필드에 이 전송의 이름을 정의합니다. 이 이름이 대량 전송의 기본 키가 됩니다.
- 대량 전송 ID 필드에서 해당 SAP LT Replication Server 복제 구성을 만들 때 생성된 세 자릿수 ID를 입력합니다.
- 소스 필드의 라벨 또는 간단 설명을 BigQuery에서 대상 필드 이름으로 사용하려면 커스텀 이름 플래그 사용 체크박스를 선택합니다. 필드 이름에 대한 자세한 내용은 필드 기본 이름 지정 옵션을 참조하세요.
삽입을 트리거한 변경 유형을 저장하고 소스 테이블, SAP LT Replication Server 통계, BigQuery 테이블 간의 레코드 수 유효성 검사를 사용 설정하려면 추가 필드 플래그 체크박스를 선택합니다.
이 플래그를 설정하면 SAP용 BigQuery 커넥터가 BigQuery 테이블 스키마에 열을 추가합니다. 자세한 내용은 레코드 변경사항 및 카운트 쿼리를 위한 추가 필드를 참조하세요.
데이터 오류가 있는 레코드가 발견되었을 때 데이터 전송을 중지하려면 첫 번째 오류 플래그에서 중지 체크박스를 클릭하는 것이 좋습니다. 자세한 내용은 BREAK 플래그를 참조하세요.
데이터 오류가 있는 레코드가 발견되었을 때 레코드를 건너뛰고 BigQuery 테이블에 레코드 삽입을 계속하려면 잘못된 레코드 플래그 건너뛰기 체크박스를 클릭합니다. 이 체크박스는 선택하지 않는 것이 좋습니다. 자세한 내용은 SKIP 플래그를 참조하세요.
Google Cloud 키 이름 필드에서 해당
/GOOG/CLIENT_KEY구성 이름을 입력합니다.SAP용 BigQuery 커넥터는
/GOOG/CLIENT_KEY구성에서 Google Cloud 프로젝트 식별자를 자동으로 검색합니다.BigQuery 데이터 세트 필드에 이 절차의 앞에서 만든 대상 BigQuery 데이터 세트 이름을 입력합니다.
설정 활성 여부 플래그 필드에서 체크박스를 클릭하여 대량 전송 구성을 사용 설정합니다.
저장을 클릭합니다.
대량 전송 레코드가
/GOOG/BQ_MASTR테이블에 추가되고 변경한 사람, 변경 시간, 변경 위치 필드가 자동으로 채워집니다.테이블 표시를 클릭합니다.
새로운 대량 전송 레코드가 테이블 속성 입력 패널 다음에 표시됩니다.
테이블 속성 지정
BigQuery에 전송되는 각 전송 또는 청크에 /GOOG/SLT_SETTINGS 트랜잭션의 초 단위로 포함할 테이블 이름 및 테이블 파티션 나누기와 같은 테이블 속성과 레코드 수를 지정할 수 있습니다.
지정한 설정은 /GOOG/BQ_TABLE 구성 테이블에 레코드로 저장됩니다.
이러한 설정은 선택사항입니다.
테이블 속성을 지정하려면 다음 안내를 따르세요.
행 추가 아이콘을 클릭합니다.
SAP 테이블 이름 필드에 소스 SAP 테이블의 이름을 입력합니다.
외부 테이블 이름 필드에 대상 BigQuery 테이블 이름을 입력합니다. 대상 테이블이 아직 없으면 SAP용 BigQuery 커넥터가 이 이름으로 테이블을 만듭니다. 테이블에 대한 BigQuery 이름 지정 규칙은 테이블 이름 지정을 참조하세요.
압축되지 않은 플래그 전송 필드는 레코드 압축을 사용 중지합니다. SAP용 BigQuery 커넥터를 사용해서 소스 레코드의 모든 빈 필드를 소스 테이블에서 필드가 초기화된 값으로 복제해야 할 경우에만 이 플래그를 지정합니다. 성능 향상을 위해서는 이 플래그를 지정하지 마세요. 자세한 내용은 레코드 압축을 참조하세요.
선택적으로 청크 크기 필드에서 BigQuery에 전송되는 각 청크에 포함할 레코드 최대 개수를 지정합니다. 가능하면 SAP용 BigQuery 커넥터에서 허용되는 최대 청크 크기를 사용합니다. 이 크기는 현재 10,000개 레코드이고 기본값입니다. 소스 레코드에 많은 필드가 없으면 필드 수에 따라 청크의 전체 바이트 크기가 증가하여 청크 오류가 발생할 수 있습니다. 이 경우 바이트 크기를 줄이기 위해 청크 크기를 줄여보세요. 자세한 내용은 SAP용 BigQuery 커넥터의 청크 크기를 참조하세요.
선택적으로 파티션 유형 필드에서 파티션 나누기에 사용할 증분 시간을 지정합니다. 유효한 값은
HOUR,DAY,MONTH,YEAR입니다. 자세한 내용은 테이블 파티션 나누기를 참조하세요.선택적으로 파티션 필드에서 파티션 나누기에 사용할 타임스탬프가 포함된 필드 이름을 대상 BigQuery 테이블에 지정합니다. 파티션 필드를 지정할 때는 파티션 유형도 지정해야 합니다. 자세한 내용은 테이블 파티션 나누기를 참조하세요.
설정 활성 여부 플래그 필드에서 체크박스를 클릭하여 테이블 속성을 사용 설정합니다. 설정 활성 여부 플래그 체크박스를 선택하면 SAP용 BigQuery 커넥터가 파티션 나누기를 제외하고 SAP 소스 테이블 및 기본 청크 크기를 사용해서 BigQuery 테이블을 만듭니다.
저장을 클릭합니다.
속성이
/GOOG/BQ_TABLE구성 테이블에 레코드로 저장되고 변경한 사람, 변경 시간, 변경 위치 필드가 자동으로 채워집니다.표시 필드를 클릭합니다.
새 테이블 속성 레코드가 필드 매핑 입력 패널 다음에 표시됩니다.
기본 필드 매핑 맞춤설정
소스 SAP 테이블에 타임스탬프 필드 또는 부울이 포함되었으면 대상 BigQuery 테이블에서 데이터 유형을 정확하게 반영하기 위해 기본 데이터 유형 매핑을 변경합니다.
또한 기타 데이터 유형 및 대상 필드에 사용되는 이름을 변경할 수 있습니다.
SAP GUI에서 직접 기본 매핑을 수정할 수도 있고, 다른 사용자가 SAP LT Replication Server에 액세스하지 않고도 값을 수정할 수 있도록 기본 매핑을 스프레드시트 또는 텍스트 파일로 내보낼 수도 있습니다.
기본 필드 매핑과 변경 가능한 항목에 대한 자세한 내용은 필드 매핑을 참조하세요.
대상 BigQuery 필드의 기본 매핑을 맞춤설정하려면 다음 안내를 따르세요.
/GOOG/SLT_SETTINGS트랜잭션의 BigQuery 설정 유지보수 - 필드 페이지에서 현재 구성 중인 대량 전송의 기본 필드 매핑을 표시합니다.필요에 따라 외부 데이터 요소 열에서 기본 대상 데이터 유형을 수정합니다. 특히 다음 데이터 유형의 대상 데이터 유형을 변경합니다.
- 타임스탬프. 기본 대상 데이터 유형을
NUMERIC에서TIMESTAMP또는TIMESTAMP (LONG)로 변경합니다. - 부울. 기본 대상 데이터 유형을
STRING에서BOOLEAN으로 변경합니다. - 16진수. 기본 대상 데이터 유형을
STRING에서BYTES로 변경합니다.
기본 데이터 유형 매핑을 수정하려면 다음 안내를 따르세요.
- 수정해야 하는 필드 행에서 외부 데이터 요소 필드를 클릭합니다.
- 데이터 유형 대화상자에서 필요한 BigQuery 데이터 유형을 선택합니다.
- 변경사항을 확인한 후 저장을 클릭합니다.
- 타임스탬프. 기본 대상 데이터 유형을
BigQuery 설정 유지보수 페이지에서 커스텀 이름 플래그를 지정한 경우 필요에 따라 임시 필드 이름 열에서 기본 대상 필드 이름을 수정합니다.
값을 지정하면 외부 필드 이름 열에 표시된 기본 이름이 재정의됩니다.
필요에 따라 필드 설명 열에서 기본 대상 필드 설명을 수정합니다.
필드 맵을 외부에서 수정하도록 내보낼 수도 있습니다. 자세한 내용은 CSV 파일에서 BigQuery 필드 맵 수정을 참조하세요.
모든 변경이 완료되고 외부에서 수정된 값이 모두 업로드된 후 설정 활성 여부 플래그 체크박스가 선택되었는지 확인합니다. 설정 활성 여부 플래그를 선택하지 않으면 SAP용 BigQuery 커넥터가 기본값을 사용하여 대상 테이블을 만듭니다.
저장을 클릭합니다.
변경사항이
/GOOG/BQ_FIELD구성 테이블에 저장되고 변경한 사람, 변경 시간, 변경 위치 필드가 자동으로 채워집니다.
복제 테스트
데이터 프로비저닝을 시작해서 복제 구성을 테스트합니다.
SAP GUI에서 SAP LT Replication Server Cockpit(트랜잭션
LTRC)을 엽니다.테스트하려는 테이블 복제에 대한 대량 전송 구성을 클릭합니다.
데이터 프로비저닝을 클릭합니다.
데이터 프로비저닝 패널에서 데이터 프로비저닝을 시작합니다.
- 소스 테이블의 이름을 입력합니다.
- 테스트하려는 데이터 프로비저닝 유형에 대한 라디오 버튼을 클릭합니다. 예를 들면 로드 시작을 클릭합니다.
실행 아이콘을 클릭합니다. 데이터 전송이 시작되고 진행 상태가 객체 파티션 나누기 화면에 표시됩니다.
테이블이 BigQuery에 없으면 SAP용 BigQuery 커넥터가 이전에
/GOOG/SLT_SETTINGS트랜잭션으로 정의된 테이블 및 필드 속성으로부터 빌드하는 스키마로부터 테이블을 만듭니다.테이블의 초기 로드에 걸리는 시간 길이는 테이블 및 해당 레코드 크기에 따라 달라집니다.
메시지가
LTRC트랜잭션의 SAP LT Replication Server 애플리케이션 로그 섹션에 기록됩니다.
복제 검사
다음 방법을 사용해서 복제를 검사할 수 있습니다.
- SAP LT Replication Server에서 다음을 수행합니다.
- 데이터 프로비저닝 화면에서 복제를 모니터링합니다.
- 애플리케이션 로그 화면에서 오류 메시지를 확인합니다.
- BigQuery의 테이블 정보 탭에서 다음을 수행합니다.
- 스키마 탭에서 스키마가 올바른지 확인합니다.
- 미리보기 탭에서 삽입된 행의 미리보기를 확인합니다.
- 세부정보 탭에서 삽입된 행 수, 테이블 크기, 기타 정보를 확인합니다.
- BigQuery 테이블을 구성할 때 추가 필드 플래그 체크박스를 선택한 경우
/GOOG/REPLIC_VALID커스텀 트랜잭션을 입력하여 복제 검증 도구를 실행합니다.
SAP LT Replication Server에서 복제 확인
LTRC 트랜잭션을 사용해서 시작된 초기 로드 또는 복제 작업의 진행 상태와 오류 메시지를 확인합니다.
로드 통계 탭에서 로드 상태를 확인하고 SAP LT Replication Server의 데이터 전송 모니터 탭에서 작업 진행 상태를 확인할 수 있습니다.
LTRC 트랜잭션의 애플리케이션 로그 화면에서 BigQuery, SAP용 BigQuery 커넥터, SAP LT Replication Server에서 반환되는 모든 메시지를 확인할 수 있습니다.
SAP LT Replication Server에서 SAP용 BigQuery 커넥터로 생성된 메시지는 /GOOG/SLT 프리픽스로 시작합니다. BigQuery API에서 반환된 메시지는 /GOOG/MSG 프리픽스로 시작합니다.
SAP LT Replication Server에서 반환된 메시지는 /GOOG/ 프리픽스로 시작하지 않습니다.
BigQuery에서 복제 확인
Google Cloud 콘솔에서 테이블이 생성되었고 BigQuery가 데이터를 테이블에 삽입하고 있는지 확인합니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 섹션의 검색 필드에 대상 BigQuery 테이블 이름을 입력한 후
Enter를 누릅니다.테이블 정보는 페이지 오른쪽에 있는 콘텐츠 창의 탭 아래에 표시됩니다.
테이블 정보 섹션에서 다음 제목을 클릭하여 테이블 및 행 삽입을 확인합니다.
- 미리보기에는 BigQuery 테이블에 삽입된 행 및 필드가 표시됩니다.
- 스키마에는 필드 이름 및 데이터 유형이 표시됩니다.
- 세부정보에는 테이블 크기, 총 행 수, 기타 세부정보가 표시됩니다.
복제 검사 도구 실행
BigQuery 테이블을 구성할 때 추가 필드 플래그를 선택한 경우 복제 검증 도구를 사용하여 BigQuery 테이블의 레코드 수를 Replication Server 통계 또는 소스 테이블의 레코드 수와 비교하는 보고서를 생성할 수 있습니다.
복제 검사 도구를 실행하려면 다음 안내를 따르세요.
SAP GUI에서
/n에 이어/GOOG/REPLIC_VALID트랜잭션을 입력합니다./n/GOOG/REPLIC_VALID
처리 옵션 섹션에서 검사 실행 라디오 버튼을 클릭합니다.
선택 옵션 섹션에서 다음 사양을 입력합니다.
- GCP 파트너 식별자 필드의 드롭다운 메뉴에서 BigQuery를 선택합니다.
- 검사 유형 필드의 드롭다운 메뉴에서 생성할 보고서 유형을 선택합니다.
- 초기 로드 수
- 복제 수
- 현재 개수
- 날짜 확인 필드가 표시되면 수가 필요한 날짜를 지정합니다.
- 대량 전송 키 필드에 대량 전송 구성 이름을 입력합니다.
실행 아이콘을 클릭하여 복제 검사 도구를 실행합니다.
검사 확인이 완료되면 처리 옵션 섹션에서 보고서 표시 라디오 버튼을 클릭하고 실행 아이콘을 클릭하여 보고서를 표시합니다.
자세한 내용은 복제 검증 도구를 참조하세요.
문제 해결
SAP용 BigQuery 커넥터를 사용해서 SAP와 BigQuery 사이에 로드 또는 복제를 구성하고 실행할 때 발생할 수 있는 문제의 진단 및 해결에 대한 자세한 내용은 SAP용 BigQuery 커넥터 문제 해결 가이드를 참조하세요.
지원 받기
복제 및 SAP용 BigQuery 커넥터 관련 문제 해결에 도움이 필요하면 모든 사용 가능한 진단 정보를 수집하고 Cloud Customer Care에 문의하세요. Customer Care 문의 정보는 Google Cloud에서 SAP 지원 받기를 참고하세요.