Nestas instruções, mostramos como exportar dados de um aplicativo SAP ou do banco de dados subjacente para o BigQuery usando o SAP Data Services (DS).
O banco de dados pode ser o SAP HANA ou qualquer outro banco de dados compatível com a SAP.
No exemplo neste guia, exportamos tabelas de banco de dados SQL Anywhere, mas é possível usá-las para configurar a exportação de outros tipos de objetos do aplicativo SAP e da camada de banco de dados para o BigQuery.
Use a exportação de dados para fazer backup dos dados da SAP ou consolidar os dados dos sistemas SAP com dados de consumidores de outros sistemas no BigQuery, em que é possível extrair insights do machine learning e da análise de dados em escala de petabytes.
As instruções destinam-se a administradores de sistemas SAP que tenham experiência básica com a configuração do SAP Basis, SAP DS e Google Cloud.
Arquitetura

O SAP Data Services recupera os dados do aplicativo SAP ou do banco de dados subjacente, transforma os dados em compatibilidade com o formato do BigQuery e inicia o job de carregamento que move os dados para o BigQuery. Após a conclusão do job de carregamento, os dados estarão disponíveis no BigQuery para análise.
A exportação é um snapshot dos dados no sistema de origem no momento da exportação. Você controla quando o SAP Data Services inicia uma exportação. Todos os dados atuais na tabela de destino do BigQuery são substituídos pelos dados exportados. Após a conclusão da exportação, os dados no BigQuery não são sincronizados com os dados no sistema de origem.
Nesse cenário, o sistema de origem e os serviços de dados da SAP podem ser executados dentro ou fora do Google Cloud.
Componentes principais da solução
Os componentes a seguir são necessários para exportar dados de um aplicativo SAP ou de um banco de dados para o BigQuery usando o SAP Data Services:
| Componente | Versões exigidas | Observações |
|---|---|---|
| Pilha do servidor de aplicativos da SAP | Qualquer sistema SAP baseado em ABAP que comece com R/3 4.6C | Neste guia, o servidor de aplicativos e o servidor de banco de dados são chamados coletivamente de sistema de origem, mesmo que estejam em execução em máquinas diferentes. Definir usuário RFC com autorização apropriada Opcional: definir espaço de tabela separado para tabelas de registro |
| Sistema de banco de dados (DB, na sigla em inglês) | Qualquer versão de banco de dados listada como compatível com a Matriz de disponibilidade do produto (PAM, na sigla em inglês) da SAP , sujeita a restrições da pilha SAP NetWeaver listada na PAM. | |
| SAP Data Services | SAP Data Services 4.2 SP1 ou posterior | |
| BigQuery | N/A |
Custos
O BigQuery é um componente faturável Google Cloud .
Use a Calculadora de preços para gerar uma estimativa de custo com base no uso previsto.
Pré-requisitos
Nestas instruções, presumimos que o sistema de aplicativos SAP, o servidor de banco de dados e o SAP Data Services já estão instalados e configurados para operação normal.
Verifique com a SAP se a configuração planejada está em conformidade com os requisitos de licenciamento da SAP. Os requisitos podem variar dependendo se você está exportando dados de um sistema de aplicativos SAP ou de um banco de dados subjacente.
Configurar um projeto do Google Cloud em Google Cloud
Para usar o BigQuery, você precisa de um projeto Google Cloud .
Criar um Google Cloud projeto
Acesse o console Google Cloud e inscreva-se, seguindo as etapas no assistente de configuração.
Ao lado do logotipo Google Cloud no canto superior esquerdo, clique no menu suspenso e selecione NOVO PROJETO.
Dê um nome ao projeto e clique em Criar.
Após a criação do projeto (uma notificação é exibida no canto superior direito), atualize a página.
Ativar APIs
Ative a API BigQuery:
Criar uma conta de serviço
A conta de serviço (especificamente o arquivo de chave) é usada para autenticar o SAP DS no BigQuery. Você usa o arquivo de chave mais tarde ao criar o armazenamento de dados de destino.
No console Google Cloud , acesse a página Contas de serviço.
Selecionar o projeto Google Cloud .
Clique em Criar conta de serviço.
Insira um Nome de conta de serviço.
Clique em Criar e continuar.
Na lista Selecionar um papel, escolha BigQuery > Editor de dados do BigQuery.
Clique em Adicionar outro papel.
Na lista Selecionar um papel, escolha BigQuery > Usuário de jobs do BigQuery.
Clique em Continuar.
Conceda aos outros usuários acesso à conta de serviço, conforme adequado.
Clique em Concluído.
Na página Contas de serviço no Google Cloud console, clique no endereço de e-mail da conta de serviço que você acabou de criar.
No nome da conta de serviço, clique na guia Chaves.
Clique no menu suspenso Adicionar chave e selecione Criar nova chave.
Certifique-se de que o tipo de chave JSON esteja especificado.
Clique em Criar.
Salve o arquivo de chave baixado automaticamente em local seguro.
Como configurar a exportação de sistemas SAP para o BigQuery
A configuração dessa solução inclui as seguintes etapas gerais:
- Como configurar o SAP Data Services
- Como criar o fluxo de dados entre o SAP Data Services e o BigQuery
Configuração do SAP Data Services
Criar projeto de serviços de dados
- Abra o aplicativo SAP Data Services Designer.
- Acesse Project > New > Project.
- Especifique um nome no campo Project name.
- Clique em Create. Seu projeto aparece no Project Explorer à esquerda.
Criar um armazenamento de dados de origem
É possível usar um sistema de aplicativos SAP ou seu banco de dados subjacente como seu armazenamento de dados de origem para o SAP Data Services. Os tipos de objetos de dados que podem ser exportados são diferentes, dependendo se você está usando um sistema de aplicativos SAP ou um banco de dados como seu armazenamento de dados.
Se você usar um sistema de aplicativos SAP como armazenamento de dados, será possível exportar os seguintes objetos:
- tabelas
- visualizações
- hierarquias
- ODP
- BAPI (funções)
- IDocs

Se você usar um banco de dados subjacente como sua conexão de armazenamento de dados, será possível exportar objetos como estes:
- tabelas
- visualizações
- procedimentos armazenados
- outros objetos de dados

As configurações do armazenamento de dados para sistemas de aplicativos e bancos de dados SAP são descritas nas seções a seguir. Independentemente do tipo de conexão de armazenamento de dados ou objeto de dados, o procedimento para importar e usar os objetos em um fluxo de dados do SAP Data Services é quase idêntico.
Configuração de conexão de camada de aplicativo SAP
Estas etapas criam uma conexão com o aplicativo SAP e adicionam os objetos de dados ao nó de armazenamento de dados aplicável na biblioteca de objetos do Designer.
- Abra o aplicativo SAP Data Services Designer.
- Abra o projeto SAP Data Services no Project Explorer.
- Acesse Project > New > Datastore.
- Preencha o campo Datastore Name. Por exemplo, ECC_DS.
- No campo Datastore type, selecione SAP Applications.
- No campo Application server name, forneça o nome da instância do servidor de aplicativos SAP.
- Especifique as credenciais de acesso do servidor de aplicativos SAP.
- Clique em OK.
Configuração da conexão da camada de banco de dados SAP
SAP HANA
Estas etapas criam uma conexão com o banco de dados SAP HANA e adicionam as tabelas de dados ao nó de armazenamento de dados aplicável na biblioteca de objetos do Designer.
- Abra o aplicativo SAP Data Services Designer.
- Abra o projeto SAP Data Services no Project Explorer.
- Acesse Project > New > Datastore.
- Preencha o campo Datastore Name, por exemplo, HANA_DS.
- No campo Datastore type, selecione a opção Database.
- No campo Database type, selecione a opção SAP HANA.
- No campo Database version, selecione a versão do banco de dados.
- Preencha os campos Database server name, Port number e as credenciais de acesso.
- Clique em OK.
Outros bancos de dados compatíveis
Com estas etapas, você cria uma conexão com o SQL Anywhere e adiciona as tabelas de dados ao nó do armazenamento de dados aplicável na biblioteca de objetos do Designer.
As etapas para a criação de conexão com outros bancos de dados compatíveis são quase idênticas.
- Abra o aplicativo SAP Data Services Designer.
- Abra o projeto SAP Data Services no Project Explorer.
- Acesse Project > New > Datastore.
- Preencha o campo Name, por exemplo, SQL_ANYWHERE_DS.
- No campo Datastore type, selecione a opção Database.
- No campo Database type, selecione a opção SQL Anywhere.
- No campo Database version, selecione a versão do banco de dados.
- Preencha os campos Database server name, Database name e as credenciais de acesso.
- Clique em OK.
O novo armazenamento de dados aparece na guia Datastore na biblioteca de objetos locais do Designer.
Criar um armazenamento de dados de destino
Estas etapas criam um repositório de dados do BigQuery que usa a conta de serviço criada anteriormente na seção Criar uma conta de serviço. Com a conta de serviço, o SAP Data Services pode acessar o BigQuery com segurança.
Para mais informações, consulte Receber o e-mail da sua conta de serviço do Google e Receber um arquivo de chave privada da conta de serviço do Google na documentação do SAP Data Services.
- Abra o aplicativo SAP Data Services Designer.
- Abra o projeto SAP Data Services no Project Explorer.
- Acesse Project > New > Datastore.
- Preencha o campo Name. Por exemplo, BQ_DS.
- No campo Datastore type, selecione Google BigQuery.
- A opção Web Service URL é exibida. O software preenche automaticamente a opção com o URL padrão do serviço da Web do BigQuery.
- Selecione Advanced.
- Conclua as opções avançadas com base nas descrições de opções do armazenamento de dados para o BigQuery na documentação do SAP Data Services.
- Clique em OK.
O novo armazenamento de dados aparece na guia Datastore na biblioteca de objetos locais do Designer.
Configurar o fluxo de dados entre o SAP Data Services e o BigQuery
Para configurar o fluxo de dados, você precisa criar o job em lote, o fluxo de dados do carregador do BigQuery e importar as tabelas de origem e do BigQuery para o SAP Data Services como metadados externos.
Criar o job em lote
- Abra o aplicativo SAP Data Services Designer.
- Abra o projeto SAP Data Services no Project Explorer.
- Acesse Project > New > Batch Job.
- Preencha o campo Name. Por exemplo, JOB_SQL_ANYWHERE_BQ.
- Clique em OK.
Criar lógica de fluxo de dados
Importar tabela de origem
Com estas etapas, você importa a tabela do banco de dados do armazenamento de dados de origem e a disponibilizam no SAP Data Services.
- Abra o aplicativo SAP Data Services Designer.
- Expanda o armazenamento de dados de origem no Project Explorer.
- Selecione a opção External Metadata na parte superior do painel direito. A lista de nós com tabelas disponíveis e/ou outros objetos é exibida.
- Selecione a tabela a ser importada da lista.
- Clique com o botão direito do mouse e selecione a opção Import.
- A tabela importada agora está disponível na biblioteca de objetos no nó de armazenamento de dados de origem.
Criar fluxo de dados
- Selecione o job em lote no Project Explorer.
- Clique com o botão direito do mouse em um espaço de trabalho vazio no painel direito e selecione a opção Add New > Dataflow.
- Clique com o botão direito do mouse no ícone do fluxo de dados e selecione Rename.
- Altere o nome para DF_SQL_ANYWHERE_BQ.
Abra o espaço de trabalho do fluxo de dados clicando duas vezes no ícone do fluxo de dados.
Importar e conectar o fluxo de dados aos objetos do armazenamento de dados de origem
- Expanda o armazenamento de dados de origem no Project Explorer.
- No armazenamento de dados, arraste e solte a tabela de origem no espaço de trabalho do fluxo de dados. Escolha a opção Make Source ao arrastar a tabela para o espaço de trabalho. Nestas instruções, o armazenamento de dados é denominado SQL_ANYWHERE_DS. O nome do seu armazenamento de dados pode ser diferente.
- Arraste Query transform do nó Platform na guia Transforms da biblioteca de objetos para o fluxo de dados.
- Conecte a tabela de origem no espaço de trabalho à transformação de consulta.
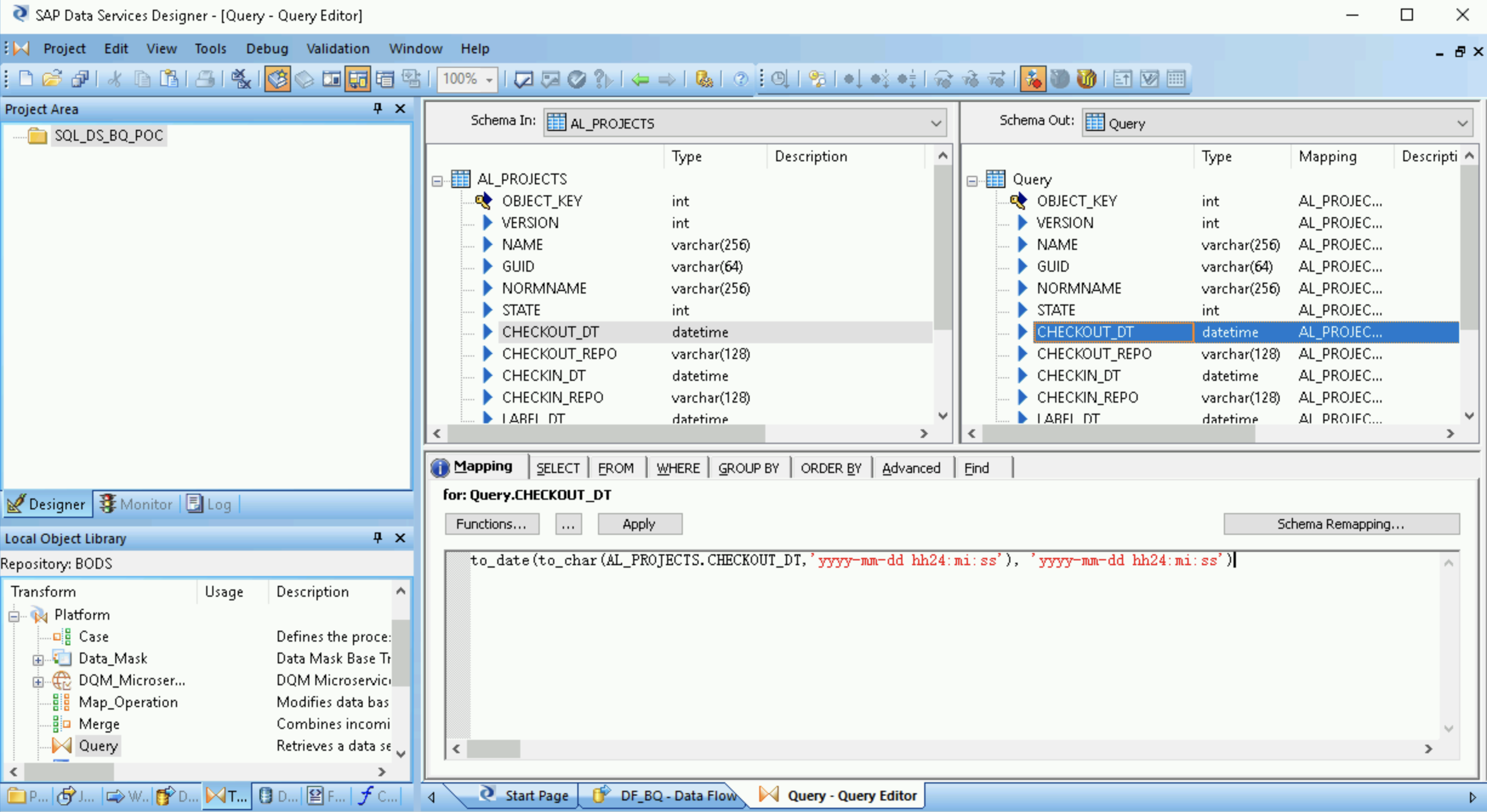
- Clique duas vezes em Query transform.
Selecione todos os campos da tabela em Schema In à esquerda e arraste-os para Schema Out à direita.
- Selecione o campo de data e hora na lista Schema Out à direita.
- Selecione a guia Mapping abaixo das listas de esquema.
Substitua o nome do campo pela função a seguir:
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
Em que FIELDNAME é o nome do campo selecionado.
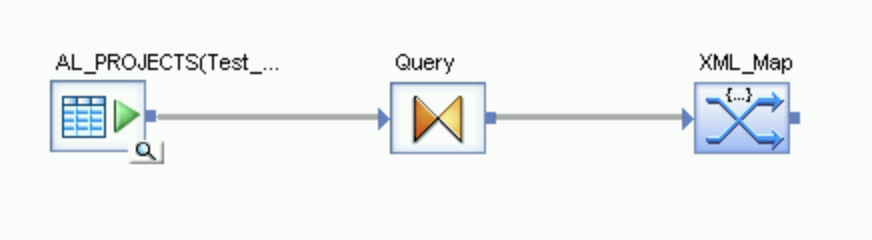
Clique no ícone "Voltar" na barra de ferramentas do aplicativo para voltar ao Editor do fluxo de dados.
No nó Platform na guia Transforms da biblioteca de objetos, arraste uma transformação XML_Map para o fluxo de dados.
Selecione o modo Batch na caixa de diálogo.
Conecte a transformação Query à transformação XML_Map.
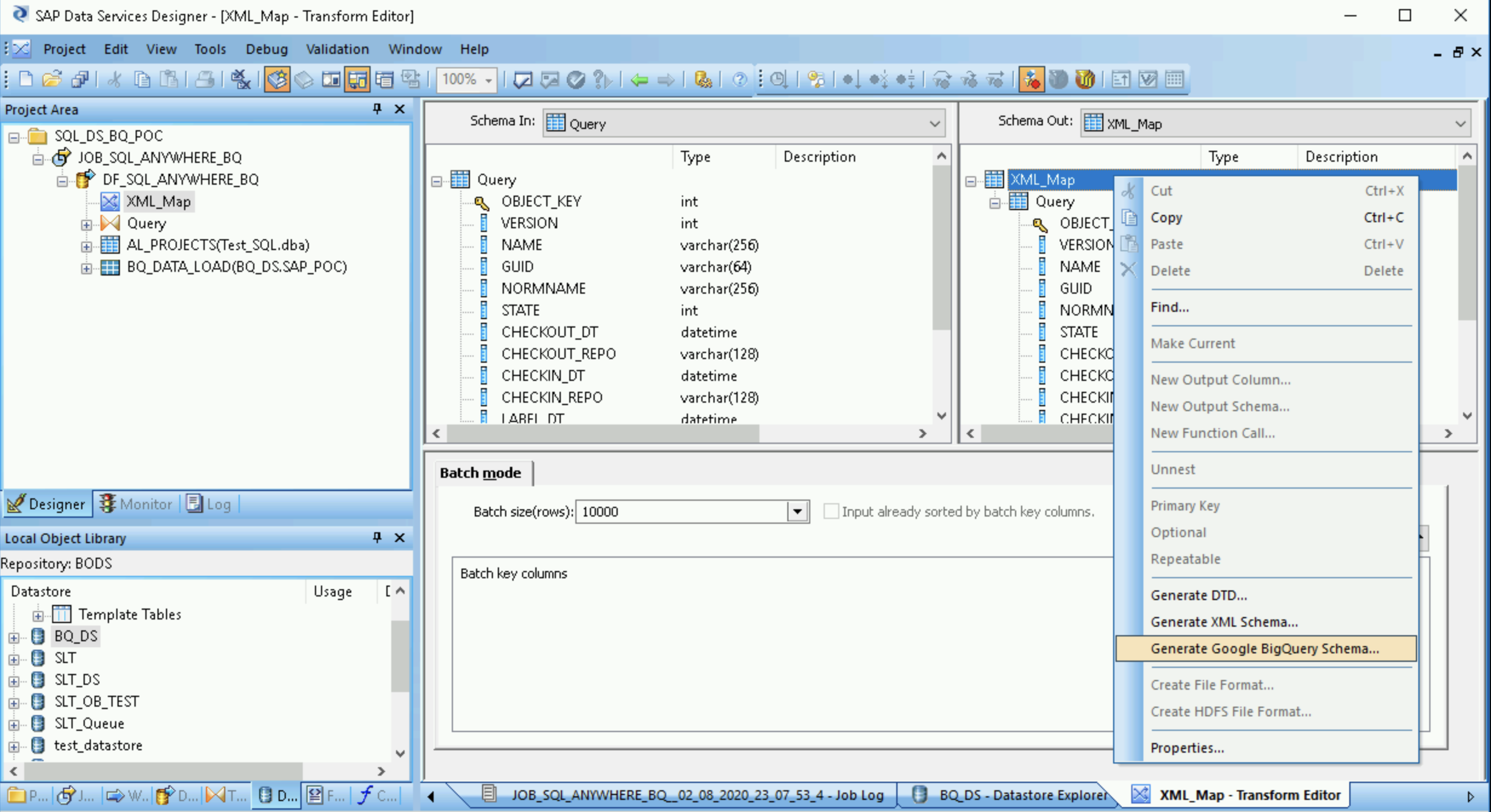
Criar um arquivo de esquema
Estas etapas criam um arquivo de esquema que reflete a estrutura das tabelas de origem. Posteriormente, você usará o arquivo de esquema para criar uma tabela do BigQuery.
O esquema garante que o fluxo de dados do carregador do BigQuery preencha a nova tabela do BigQuery.
- Abra a transformação de mapa XML e preencha as seções de esquema de entrada e saída com base nos dados incluídos na tabela do BigQuery.
- Clique com o botão direito do mouse no nó XML_Map na coluna Schema Out e selecione Generate Google BigQuery Schema no menu suspenso.
- Insira um nome e um local para o esquema.
- Clique em Save.
O SAP Data Services gera um arquivo de esquema com a extensão de arquivo .json.
Criar a tabela do BigQuery
Você precisa criar uma tabela no conjunto de dados do BigQuery noGoogle Cloud para o carregamento de dados. Use o esquema criado no SAP Data Services para criar a tabela.
A tabela é baseada no esquema que você gerou na etapa anterior.
- Acesse seu projeto Google Cloud no console Google Cloud .
- Selecione BigQuery.
- Clique no conjunto de dados relevante.
- Clique em Criar tabela.
- Insira um nome para a tabela. Por exemplo,
BQ_DATA_LOAD. - Em Esquema, ative a opção Editar como texto.
- Defina o esquema da nova tabela no BigQuery copiando e colando o conteúdo do arquivo de esquema que você criou em Criar um arquivo de esquema.
- Clique em Criar tabela.
Importar a tabela do BigQuery
Essas etapas importam a tabela do BigQuery que você criou na etapa anterior e a disponibilizam no SAP Data Services.
- Na biblioteca de objetos do SAP Data Services Designer, clique com o botão direito no armazenamento de dados do BigQuery e selecione a opção Refresh Object Library. Isso atualiza a lista de tabelas de fontes de dados que podem ser usados no seu fluxo de dados.
- Abra o armazenamento de dados do BigQuery.
- Na parte superior do painel direito, selecione External Metadata. A tabela do BigQuery que você criou é exibida.
- Clique com o botão direito do mouse no nome da tabela do BigQuery aplicável e selecione Import.
- A importação da tabela selecionada para o SAP Data Services é iniciada. A tabela agora está disponível na biblioteca de objetos no nó de armazenamento de dados de destino.
Importar e conectar o fluxo de dados aos objetos do armazenamento de dados de destino
- No armazenamento de dados na biblioteca de objetos, arraste a tabela importada do BigQuery para o fluxo de dados. O nome do armazenamento de dados nestas instruções é
BQ_DS. O nome do seu armazenamento de dados pode ser diferente. Conecte a transformação XML_Map à tabela importada do BigQuery.
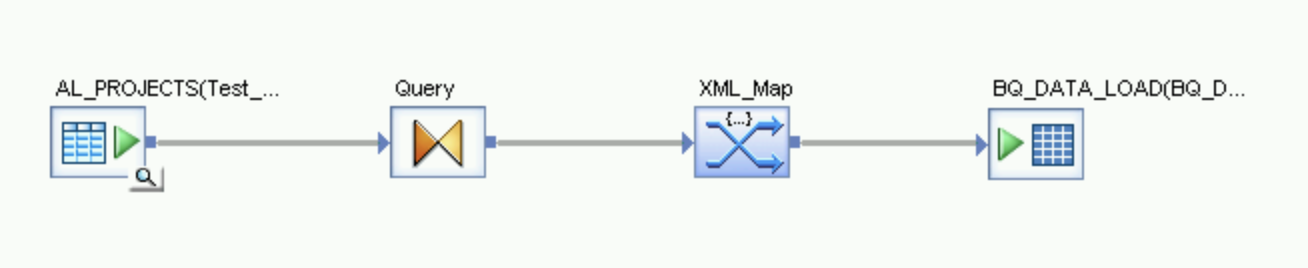
Abra a transformação XML_Map e conclua as seções do esquema de entrada e saída com base nos dados incluídos na tabela do BigQuery.
Clique duas vezes na tabela do BigQuery no espaço de trabalho para abri-la e concluir as opções na guia Target, conforme indicado na tabela a seguir:
Opção Descrição Make Port Especifique No, que é o padrão.
Ao especificar Yes, você transforma um arquivo de origem ou de destino em uma porta de fluxo de dados incorporada.Mode Especifique Truncate para o carregamento inicial, que substitui todos os registros atuais na tabela do BigQuery pelos dados carregados pelo SAP Data Services. Truncate é o padrão. Number of loaders Especifique um número inteiro positivo para definir o número de carregadores (linhas de execução) a serem usados para processamento. O padrão é 4.
Cada carregador inicia um job de carregamento recuperável no BigQuery. É possível especificar qualquer número de carregadores.
Para saber como determinar um número adequado de carregadores, consulte a documentação da SAP, incluindo:
Maximum failed records per loader Especifique 0 ou um número inteiro positivo para definir o número máximo de registros que podem falhar por job de carregamento antes que o BigQuery pare de carregar registros. O padrão é zero (0). Clique no ícone "Validate" na barra de ferramentas superior.
Clique no ícone "Back" na barra de ferramentas do aplicativo para retornar ao Editor do fluxo de dados.
Como carregar os dados no BigQuery
Estas etapas iniciam o job de replicação e executam o fluxo de dados no SAP Data Services para carregar os dados do sistema de origem para o BigQuery.
Quando você executa a carga, todos os dados no conjunto de dados de origem são replicados para a tabela de destino do BigQuery que está conectada ao fluxo de dados de carga. Todos os dados na tabela de destino são substituídos.
- No SAP Data Services Designer, abra o Project Explorer.
- Clique com o botão direito do mouse no nome do job de replicação e selecione Execute.
- Clique em OK.
- O processo de carregamento é iniciado e as mensagens de depuração começam a aparecer no registro do SAP Data Services. Os dados são carregados na tabela que você criou no BigQuery para carregamentos iniciais. O nome da tabela de carregamento nestas instruções é
BQ_DATA_LOAD. O nome da tabela pode ser diferente. - Para conferir se o carregamento foi concluído, acesse o console Google Cloud e abra o conjunto de dados do BigQuery que contém a tabela. Se os dados ainda estiverem sendo carregados, a mensagem "Carregando" vai aparecer ao lado do nome da tabela.
Após o carregamento, os dados estarão prontos para processamento no BigQuery.
Como programar carregamentos
É possível programar um job de carregamento para ser executado em intervalos regulares usando o console de gerenciamento do SAP Data Services.
- Abra o aplicativo console de gerenciamento do SAP Data Services.
- Clique em Administrator.
- Expanda o nó Batch na árvore de menus à esquerda.
- Clique no nome do repositório do SAP Data Services.
- Clique na guia Batch Job Configuration.
- Clique em Add Schedule.
- Preencha o nome da Schedule.
- Marque Active.
- Na seção Select scheduled time for executing the jobs, especifique a frequência da execução da carga delta.
- Importante: Google Cloud limita o número de jobs de carregamento do BigQuery que podem ser executados em um dia. Certifique-se de que sua programação não exceda o limite, que não pode ser aumentado. Para mais informações sobre o limite de jobs de carregamento do BigQuery, consulte Cotas e limites na documentação do BigQuery.
Clique em Aplicar.
A seguir
Consulte e analise dados replicados no BigQuery. Para mais informações sobre consultas, veja:
- Visão geral da consulta de dados do BigQuery na documentação do BigQuery.
Para algumas ideias sobre como configurar uma solução para replicação quase em tempo real de aplicativos SAP para o BigQuery usando o SAP Landscape Transformation Replication Server e o SAP Data Services, consulte:
Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.