本说明介绍了如何设置解决方案,以使用 SAP Landscape Transformation (LT) Replication Server 和 SAP Data Services (DS) 将数据从 SAP 应用(例如 SAP S/4HANA 或 SAP Business Suite)复制到 BigQuery。
您可以使用数据复制功能以近乎实时的方式备份 SAP 数据,或将 SAP 系统中的数据与 BigQuery 中其他系统的使用方数据进行整合,以从机器学习和 PB 级数据分析中获得数据洞见。
本说明适用于对 SAP Basis、SAP LT Replication Server、SAP DS、 Google Cloud的配置具有基本经验的 SAP 系统管理员。
架构

SAP LT Replication Server 可以充当 SAP NetWeaver Operational Data Provisioning Framework (ODP) 的数据提供方。SAP LT Replication Server 从连接的 SAP 系统接收数据,并将其存储在 SAP LT Replication Server 系统的操作性增量队列 (ODQ) 的 ODP 框架中。因此,SAP LT Replication Server 本身也充当了 SAP LT Replication Server 配置的目标。ODP 框架会将数据作为与源系统表对应的 ODP 对象来提供。
ODP 框架支持各种目标 SAP 应用(称为订阅者)的提取和复制场景。订阅者从增量队列中检索数据以进一步处理。
订阅者通过 ODP 上下文从数据源请求数据后,系统会立即复制数据。多个订阅者可以使用同一 ODQ 作为来源。
SAP LT Replication Server 会利用 SAP Data Services 4.2 SP1 或更高版本的更改数据捕获 (CDC) 支持,其中包括适用于所有源表的实时数据预配和增量功能。
下图说明了系统中的数据流:
- SAP 应用更新源系统中的数据。
- SAP LT Replication Server 复制数据更改并将数据存储在操作性增量队列中。
- SAP DS 是操作性增量队列的订阅者,会定期轮询该队列以检查是否存在数据更改情况。
- SAP DS 从增量队列检索数据,然后将数据转换为与 BigQuery 格式兼容的格式,最后启动将数据移动到 BigQuery 的加载作业。
- BigQuery 可以提供这些数据,供您分析使用。
在此场景中,SAP 源系统、SAP LT Replication Server 和 SAP Data Services 可以在 Google Cloud上运行,也可以在其之外运行。如需查看 SAP 提供的详细信息,请参阅使用 SAP Landscape Transformation Replication Server 实时配置操作性数据。

核心解决方案组件
您必须使用以下组件,才能使用 SAP Landscape Transformation Replication Server 和 SAP Data Services 将数据从 SAP 应用复制到 BigQuery:
| 组件 | 所需版本 | 备注 |
|---|---|---|
| SAP 应用服务器栈 | 从 R/3 4.6C SAP_Basis 开始的 任何基于 ABAP 的 SAP 系统(最低要求):
|
在本指南中,应用服务器和数据库服务器统称为源系统,即使它们在不同的机器上运行也是如此。 定义具有适当授权的 RFC 用户 可选:定义用于日志记录表的单独表空间 |
| 数据库 (DB) 系统 | SAP 产品可用性矩阵 (PAM) 中列出的任何受支持的 DB 版本,受 PAM 中列出的 SAP NetWeaver 栈的任何限制约束。请参阅 service.sap.com/pam 上的内容。 | |
| 操作系统 | SAP PAM 中列出的任何受支持的操作系统版本,受 PAM 中列出的 SAP NetWeaver 栈的任何限制约束。请参阅 service.sap.com/pam 上的内容。 | |
| SAP Data Migration Server (DMIS) | DMIS:
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 或更高版本 | 需要与源系统建立 RFC 连接。 SAP LT Replication Server 系统的容量在很大程度上取决于 ODQ 中存储的数据量和计划保留期限。 |
| SAP Data Services | SAP Data Services 4.2 SP1 或更高版本 | |
| BigQuery | 不适用 |
费用
BigQuery 是 Google Cloud 的收费组件。
请使用价格计算器根据您的预计使用情况来估算费用。
前提条件
本文的说明假定 SAP 应用服务器、数据库服务器、SAP LT Replication Server 和 SAP Data Services 已安装并进行了配置,可以正常运行。
您需要先有一个 Google Cloud项目才能使用 BigQuery。
在 Google Cloud中设置 Google Cloud 项目
您需要启用 BigQuery API;此外,如果您尚未创建Google Cloud 项目,还需要创建一个。
创建 Google Cloud 项目
前往 Google Cloud 控制台并注册,逐步完成设置向导。
在左上角的 Google Cloud 徽标旁边,点击下拉菜单并选择创建项目。
为项目命名,然后点击创建。
创建项目(右上角会显示一条通知)后,刷新页面。
启用 API
启用 BigQuery API:
启用对 Google Cloud API 的专用访问权限
对于在 Google Cloud外运行的 SAP 工作负载,在与 Google Cloud建立网络连接后,您需要启用对 Google Cloud API 的专用访问权限。
如需了解详情,请参阅服务的专用 Google 访问通道选项。
创建服务账号
该服务账号(具体说来是其密钥文件)用于向 BigQuery 验证 SAP DS 身份。您稍后在创建目标数据存储区时会使用该密钥文件。
在 Google Cloud 控制台中,打开服务账号页面。
选择您的 Google Cloud 项目。
点击创建服务账号。
输入服务账号名称。
点击创建并继续。
在选择角色列表中,选择 BigQuery > BigQuery Data Editor。
点击添加其他角色。
在选择角色列表中,选择 BigQuery > BigQuery Job User。
点击继续。
根据具体情况授予其他用户访问服务账号的权限。
点击完成。
在 Google Cloud 控制台中的服务账号页面上,点击您刚创建的服务账号的邮箱。
在服务账号名称下,点击密钥标签页。
点击添加密钥下拉菜单,然后选择创建新密钥。
确保指定了 JSON 密钥类型。
点击创建。
将自动下载的密钥文件保存到安全的位置。
配置 SAP 应用和 BigQuery 之间的复制
配置此解决方案包括以下高级步骤:
- 配置 SAP LT Replication Server
- 配置 SAP Data Services
- 创建 SAP Data Services 和 BigQuery 之间的数据流
SAP Landscape Transformation Replication Server 配置
以下步骤会将 SAP LT Replication Server 配置为操作性数据预配框架中的提供方,并创建操作性增量队列。在此配置中,SAP LT Replication Server 会使用基于触发器的复制功能,将数据从源 SAP 系统复制到增量队列中的表。作为 ODP 框架中的订阅者运行的 SAP Data Services 会从增量队列中检索数据,对数据进行转换,然后将数据加载到 BigQuery 中。
配置操作性增量队列 (ODQ)
- 在 SAP LT Replication Server 中,使用事务
SM59为作为数据源的 SAP 应用系统创建 RFC 目标。 - 在 SAP LT Replication Server 中,使用事务
LTRC创建配置。在该配置中,定义 SAP LT Replication Server 的来源和目标。使用 ODP 进行数据传输的目标是 SAP LT Replication Server 本身。- 如需指定来源,请输入要用作数据源的 SAP 应用系统的 RFC 目标。
- 如需指定目标,请执行以下操作:
- 对于 RFC 连接,请输入 NONE。
- 对于 RFC 通信,请选择 ODQ Replication Scenario。使用此方案时,请指定系统通过使用操作性数据预配基础架构和操作性增量队列来传输数据。
- 指定队列别名。
队列别名在 SAP Data Services 中用于数据源 ODP 上下文设置。
SAP Data Services 配置
创建数据服务项目
- 打开 SAP Data Services Designer 应用。
- 转到 File > New > Project。
- 在 Project name 字段中指定一个名称。
- 在 Data Services Repository 中,选择您的数据服务代码库。
- 点击完成。您的项目会显示在左侧的 Project Explorer 中。
SAP Data Services 会连接到源系统以收集元数据,然后连接到 SAP Replication Server 代理以检索配置和更改数据。
创建源数据存储区
以下步骤将创建与 SAP LT Replication Server 的连接,并将数据表添加到 Designer 对象库中的适用数据存储区节点。
如需将 SAP LT Replication Server 与 SAP Data Services 搭配使用,您必须将数据存储区连接到 ODP 基础架构,从而将 SAP Data Services 连接到 ODP 中的正确操作性增量队列。
- 打开 SAP Data Services Designer 应用。
- 在 Project Explorer 中右键点击您的 SAP Data Services 项目名称。
- 选择 New > Datastore。
- 填写 Datastore Name。例如,DS_SLT。
- 在 Datastore type 字段中,选择 SAP Applications。
- 在 Application server name 字段中,提供 SAP LT Replication Server 的实例名称。
- 指定 SAP LT Replication Server 访问凭据。
- 打开 Advanced 标签页。
- 在 ODP Context 中,输入 SLT~ALIAS,其中 ALIAS 是您在配置操作性增量队列 (ODQ) 中指定的队列别名。
- 点击确定。
新数据存储区会显示在 Designer 的本地对象库的 Datastore 标签页中。
创建目标数据存储区
以下步骤将创建一个 BigQuery 数据存储区,该数据存储区会使用您之前在创建服务账号部分中创建的服务账号。该服务账号可让 SAP Data Services 安全地访问 BigQuery。
如需了解详情,请参阅 SAP Data Services 文档中的获取 Google 服务账号电子邮件地址 (Obtain your Google service account email) 和获取 Google 服务账号私钥文件 (Obtain a Google service account private key file)。
- 打开 SAP Data Services Designer 应用。
- 在 Project Explorer 中右键点击您的 SAP Data Services 项目名称。
- 选择 New > Datastore。
- 填写 Name 字段。例如,BQ_DS。
- 点击 Next。
- 在 Datastore type 字段中,选择 Google BigQuery。
- 系统会显示 Web Service URL 选项。该软件会自动使用默认的 BigQuery Web 服务网址完成该选项。
- 选择 Advanced。
- 根据 SAP Data Services 文档中针对 BigQuery 的数据存储区选项说明 (Datastore option descriptions) 完成“Advanced”选项。
- 点击确定。
新数据存储区会显示在 Designer 本地对象库的 Datastore 标签页中。
为复制导入源 ODP 对象
以下步骤将从源数据存储区导入初始加载和增量加载的 ODP 对象,并使其在 SAP Data Services 中可用。
- 打开 SAP Data Services Designer 应用。
- 在 Project Explorer 中展开复制负载的源数据存储区。
- 在右侧面板的上面部分中选择 External Metadata 选项。系统会显示包含可用表和 ODP 对象的节点列表。
- 点击 ODP 对象节点以检索可用 ODP 对象列表。该列表可能需要很长时间才能显示出来。
- 点击 Search 按钮。
- 在该对话框的 Look in 菜单和 Object type 菜单中,分别选择 External data 和 ODP object。
- 在“Search”对话框中,选择搜索条件以过滤源 ODP 对象列表。
- 从该列表中选择要导入的 ODP 对象。
- 点击鼠标右键,然后选择 Import 选项。
- 填写 Name of Consumer。
- 填写 Name of project。
- 在 Extraction mode 中选择 Changed-data capture (CDC) 选项。
- 点击导入。此时,系统会开始将 ODP 对象导入 Data Services。现在,DS_SLT 节点下的对象库中提供了 ODP 对象。
如需了解详情,请参阅 SAP Data Services 文档中的导入 ODP 源元数据 (Importing ODP source metadata)。
创建架构文件
以下步骤将在 SAP Data Services 中创建一个数据流,以生成反映源表结构的架构文件。稍后,您将使用该架构文件创建 BigQuery 表。
该架构可确保 BigQuery 加载器数据流成功填充新的 BigQuery 表。
创建数据流
- 打开 SAP Data Services Designer 应用。
- 在 Project Explorer 中右键点击您的 SAP Data Services 项目名称。
- 选择 Project > New > Data flow。
- 填写 Name 字段。例如,DF_BQ。
- 点击 Finish。
刷新对象库
- 在 Project Explorer 中右键点击初始加载的源数据存储区,然后选择 Refresh Object Library 选项。这样会更新您可以在数据流中使用的数据源数据库表的列表。
构建数据流
- 通过将源表拖放到数据流工作区并在看到提示时选择 Import as Source 来构建数据流。
- 在对象库的 Transforms 标签页中,将 XML_Map transform 从 Platform 节点 i 拖动到数据流上,然后在看到提示时选择 Batch Load 选项。
- 将工作区中的所有源表连接到 XML 映射转换。
- 打开 XML Map transform,然后根据您要在 BigQuery 表中添加的数据完成输入和输出架构部分。
- 右键点击 Schema Out 列中的 XML_Map 节点,然后从下拉菜单中选择 Generate Google BigQuery Schema。
- 输入架构的名称和位置。
- 点击保存。
- 在 Project Explorer 中右键点击数据流,然后选择 Remove。
SAP Data Services 会生成一个具有 .json 文件扩展名的架构文件。
创建 BigQuery 表
对于初始加载和增量加载,您需要在Google Cloud 上的 BigQuery 数据集中创建表。您可以使用在 SAP Data Services 中创建的架构来创建表。
初始加载表用于整个源数据集的初始复制。增量加载表用于初始加载后发生的源数据集更改的复制。这些表基于您在上一步中生成的架构。增量加载表包含一个额外的时间戳字段,用于标识每次增量加载的时间。
为初始加载创建 BigQuery 表
以下步骤将在 BigQuery 数据集中创建初始加载表。
- 在 Google Cloud 控制台中访问您的 Google Cloud 项目。
- 选择 BigQuery。
- 点击相应的数据集。
- 点击创建表。
- 输入表名称。例如,BQ_INIT_LOAD。
- 在架构下,切换设置以启用以文本形式修改模式。
- 在 BigQuery 中设置新表的架构,方法是复制并粘贴您在创建架构文件中创建的架构文件的内容。
- 点击创建表。
为增量加载创建 BigQuery 表
以下步骤将为 BigQuery 数据集的增量加载创建表。
- 在 Google Cloud 控制台中访问您的 Google Cloud 项目。
- 选择 BigQuery。
- 点击相应的数据集。
- 点击创建表。
- 输入表名称。例如,BQ_DELTA_LOAD。
- 在架构下,切换设置以启用以文本形式修改模式。
- 在 BigQuery 中设置新表的架构,方法是复制并粘贴您在创建架构文件中创建的架构文件的内容。
在架构文件的 JSON 列表的 DI_SEQUENCE_NUMBER 字段定义之前,添加以下 DL_TIMESTAMP 字段定义。此字段会存储每次执行增量加载的时间戳:
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },点击创建表。
设置 SAP Data Services 和 BigQuery 之间的数据流
如需设置数据流,您需要将 BigQuery 表作为外部元数据导入 SAP Data Services,并创建复制作业和 BigQuery 加载器数据流。
导入 BigQuery 表
以下步骤将导入您在上一步中创建的 BigQuery 表,并使其在 SAP Data Services 中可用。
- 在 SAP Data Services Designer 对象库中,打开您之前创建的 BigQuery 数据存储区。
- 在右侧面板的上面部分中,选择 External Metadata。系统会显示您创建的 BigQuery 表。
- 右键点击相应的 BigQuery 表名称,然后选择 Import。
- 此时,系统会开始将选定的表导入 SAP Data Services。现在,目标数据存储区节点下的对象库中提供了该表。
创建复制作业和 BigQuery 加载器数据流
以下步骤将在 SAP Data Services 中创建一个复制作业和数据流,该数据流用于将数据从 SAP LT Replication Server 加载到 BigQuery 表中。
该数据流由两个部分组成。第一个部分执行从源 ODP 对象到 BigQuery 表的初始数据加载,第二个部分启用后续的增量加载。
创建全局变量
为了让复制作业能够确定是执行初始加载还是增量加载,您需要创建一个全局变量以便在数据流逻辑中跟踪加载类型。
- 在 SAP Data Services Designer 应用菜单中,转到 Tools > Variables。
- 右键点击 Global Variables,然后选择 Insert。
- 右键点击变量名称,然后选择 Properties。
- 在变量名称中输入 $INITLOAD。
- 在 Data Type 中,选择 Int。
- 在 Value 字段中输入 0。
- 点击确定。
创建复制作业
- 在 Project Explorer 中右键点击项目名称。
- 选择 New > Batch Job。
- 填写 Name 字段。例如,JOB_SRS_DS_BQ_REPLICATION。
- 点击完成。
为初始加载创建数据流逻辑
创建条件
- 右键点击 Job Name,然后选择 Add New > Conditional 选项。
- 右键点击条件图标,然后选择 Rename。
将名称更改为 InitialOrDelta。

双击条件图标以打开 Conditional Editor。
在 If statement 字段中,输入 $INITLOAD = 1,这会将条件设置为执行初始加载。
右键点击 Then 窗格,然后选择 Add New > Script。
右键点击 Script 图标,然后选择 Rename。
更改名称。例如,本文的说明使用的是 InitialLoadCDCMarker。
双击 Script 图标以打开 Function Editor。
输入
print('Beginning Initial Load');输入
begin_initial_load();
点击应用工具栏中的“Back”图标,以退出 Function Editor。
为初始加载创建数据流
- 右键点击 Then 窗格,然后选择 Add New > Data Flow。
- 为数据流重命名。例如,DF_SRS_DS_InitialLoad。
- 点击 InitialLoadCDCMarker 的连接输出图标,然后将连接线拖动到 DF_SRS_DS_InitialLoad 的输入图标上,从而将 InitialLoadCDCMarker 与 DF_SRS_DS_InitialLoad 连接起来。
- 双击 DF_SRS_DS_InitialLoad 数据流。
导入数据流并将其与源数据存储区对象相关联
- 从数据存储区中,将源 ODP 对象拖放到数据流工作区中。在本文的说明中,数据存储区名为 DS_SLT。您的数据存储区名称可能有所不同。
- 将 Query transform 从对象库的 Transforms 标签页的 Platform 节点拖动到数据流上。
双击 ODP 对象,然后在 Source 标签页中将 Initial Load 选项设置为 Yes。

将工作区中的所有源 ODP 对象连接到 Query transform。
双击 Query transform。
选择左侧 Schema In 下的所有表字段,然后将其拖动到右侧的 Schema Out 中。
如需为日期时间字段添加转换函数,请执行以下操作:
- 在右侧的 Schema Out 列表中选择日期时间字段。
- 选择架构列表下方的 Mapping 标签页。
将字段名称替换为以下函数:
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')其中,FIELDNAME 是所选字段的名称。
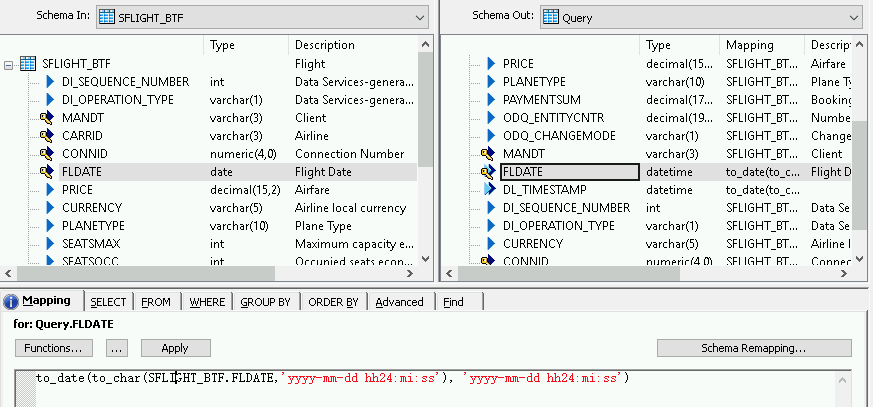
点击应用工具栏中的“Back”图标,以返回到数据流。
导入数据流并将其与目标数据存储区对象相关联
- 从对象库的数据存储区中,将导入的初始加载 BigQuery 表拖动到数据流上。在本文的说明中,该数据存储区的名称为 BQ_DS。您的数据存储区名称可能有所不同。
- 从对象库的 Transforms 标签页的 Platform 节点中,将 XML_Map 转换拖动到数据流上。
- 在对话框中选择 Batch mode。
- 将 Query 转换连接到 XML_Map 转换。
将 XML_Map 转换连接到导入的 BigQuery 表。
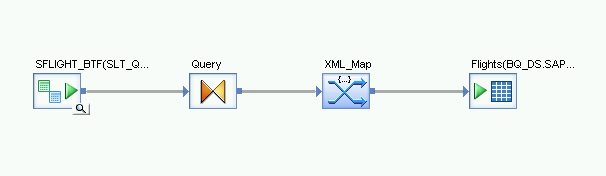
打开 XML_Map 转换,然后根据您要在 BigQuery 表中添加的数据完成输入和输出架构部分。
双击工作区中的 BigQuery 表以将其打开,然后完成 Target 标签页中的选项,如下表所示:
| 选项 | 说明 |
|---|---|
| Make Port | 指定 No(默认值)。 指定 Yes 会将源文件或目标文件设置为嵌入式数据流端口。 |
| Mode | 为初始加载指定 Truncate,这样会将 BigQuery 表中的任何现有记录替换为 SAP Data Services 加载的数据。Truncate 是默认值。 |
| Number of loaders | 指定一个正整数以设置要用于处理的加载器(线程)的数量。默认值为 4。 每个加载器都会在 BigQuery 中启动一个可继续执行的加载作业。您可以指定任意数量的加载器。 如需获得有关如何确定加载器适当数量的帮助,请参阅 SAP 文档,包括:
|
| Maximum failed records per loader | 指定 0 或正整数,以设置在 BigQuery 停止加载记录之前每个加载作业可以失败的最大记录数。默认值为零 (0)。 |
- 点击顶部工具栏中的“Validate”图标。
- 点击应用工具栏中的“Back”图标,以返回到 Conditional Editor。
为增量加载创建数据流
您需要创建数据流以复制初始加载后累积的更改数据捕获记录。
创建条件增量流:
- 双击 InitialOrDelta 条件。
- 右键点击 Else 部分,然后选择 Add New > Script。
- 为脚本重命名。例如,MarkBeginCDCLoad。
- 双击“Script”图标以打开 Function Editor。
输入 print('Beginning Delta Load');

点击应用工具栏中的“Back”图标,以返回到 Conditional Editor。
为增量加载创建数据流
- 在 Conditional Editor 中,点击鼠标右键,然后选择 Add New > Data Flow。
- 为数据流重命名。例如,DF_SRS_DS_DeltaLoad。
- 将 MarkBeginCDCLoad 与 DF_SRS_DS_DeltaLoad 连接起来,如下图所示。
双击 DF_SRS_DS_DeltaLoad 数据流。
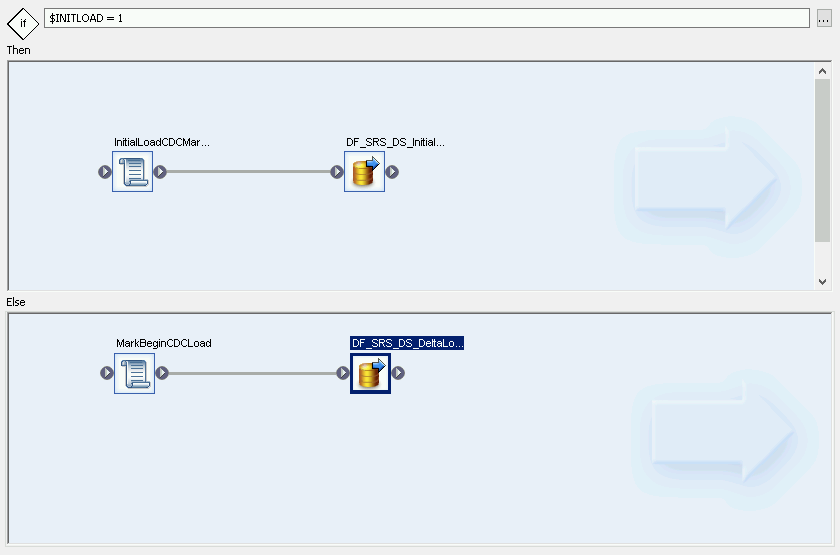
导入数据流并将其与源数据存储区对象相关联
- 将源 ODP 对象从数据存储区拖放到数据流工作区中。在本文的说明中,该数据存储区使用名称 DS_SLT。您的数据存储区名称可能有所不同。
- 从对象库的 Transforms 标签页的 Platform 节点中,将 Query 转换拖动到数据流上。
- 双击 ODP 对象,然后在 Source 标签页中将 Initial Load 选项设置为 No。
- 将工作区中的所有源 ODP 对象连接到 Query 转换。
- 双击 Query 转换。
- 选择左侧“Schema In”列表中的所有表字段,然后将其拖动到右侧的“Schema Out”列表中。
为增量加载启用时间戳
通过以下步骤,SAP Data Services 可以在增量加载表的字段中自动记录每次执行增量加载的时间戳。
- 在右侧的“Schema Out”窗格中右键点击 Query 节点。
- 选择 New Output Column。
- 在 Name 中输入 DL_TIMESTAMP。
- 在 Data type 中选择 datetime。
- 点击确定。
- 点击新创建的 DL_TIMESTAMP 字段。
- 转到下面的 Mapping 标签页。
输入以下函数:
- to_date(to_char(sysdate(),'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
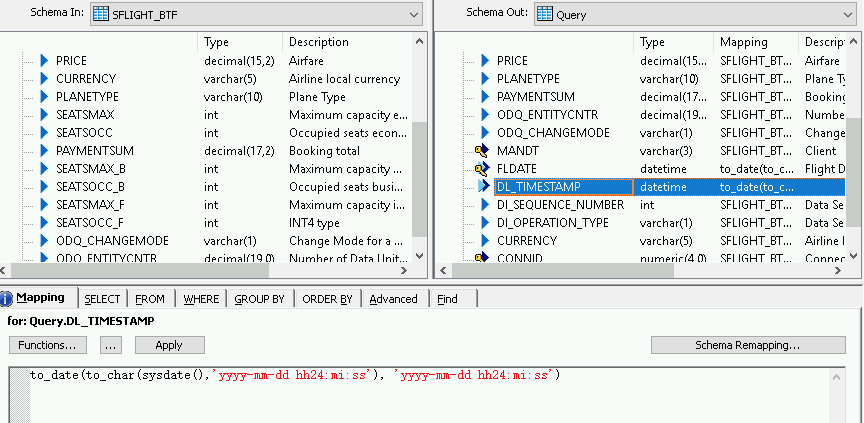
导入数据流并将其与目标数据存储区对象相关联
- 从对象库的数据存储区中,将导入的增量加载 BigQuery 表拖动到数据流工作区中(放在 XML_Map 转换后面)。本文的说明使用示例数据存储区名称 BQ_DS。您的数据存储区名称可能有所不同。
- 从对象库的 Transforms 标签页的 Platform 节点中,将 XML_Map 转换拖动到数据流上。
- 将 Query 转换连接到 XML_Map 转换。
将 XML_Map 转换连接到导入的 BigQuery 表。
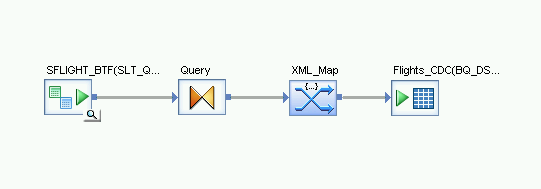
打开 XML_Map 转换,然后根据您要在 BigQuery 表中添加的数据完成输入和输出架构部分。
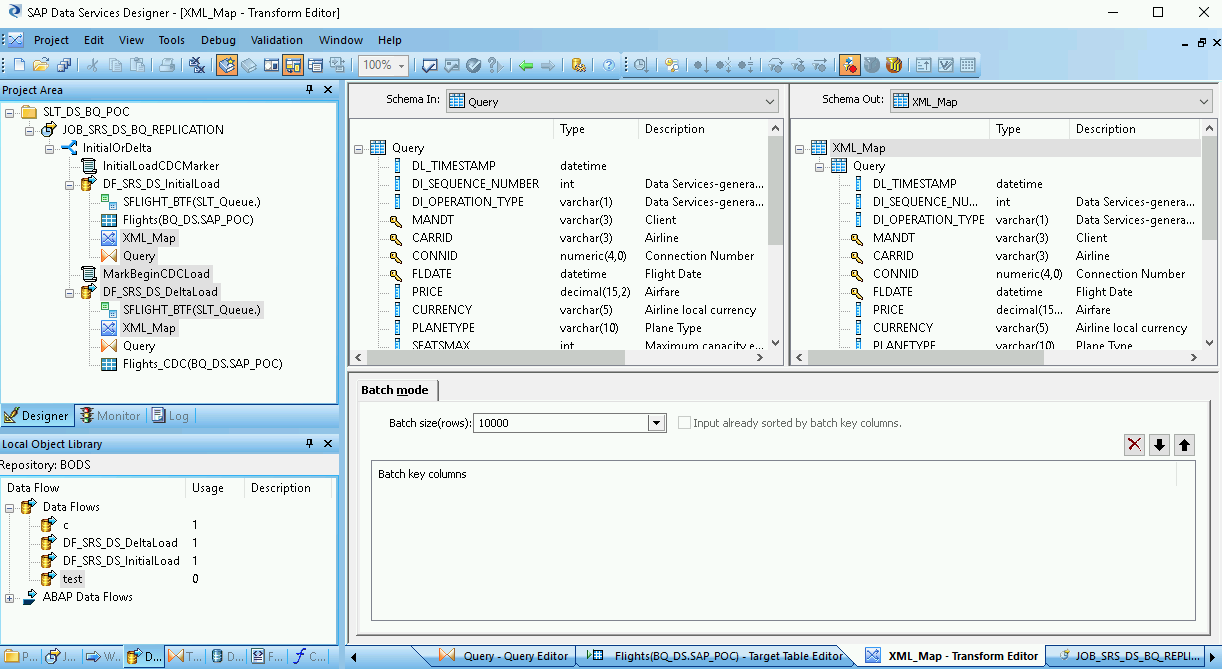
双击工作区中的 BigQuery 表以将其打开,然后根据以下说明完成 Target 标签页中的选项:
| 选项 | 说明 |
|---|---|
| Make Port | 指定 No(默认值)。 指定 Yes 会将源文件或目标文件设置为嵌入式数据流端口。 |
| Mode | 为增量加载指定 Append,这样,系统在从 SAP Data Services 加载新记录时会保留 BigQuery 表中的现有记录。 |
| Number of loaders | 指定一个正整数以设置要用于处理的加载器(线程)的数量。 每个加载器都会在 BigQuery 中启动一个可继续执行的加载作业。您可以指定任意数量的加载器。通常,增量加载比初始加载需要更少的加载器。 如需获得有关如何确定加载器适当数量的帮助,请参阅 SAP 文档,包括:
|
| Maximum failed records per loader | 指定 0 或正整数,以设置在 BigQuery 停止加载记录之前每个加载作业可以失败的最大记录数。默认值为零 (0)。 |
- 点击顶部工具栏中的“Validate”图标。
- 点击应用工具栏中的“Back”图标,以返回到 Conditional Editor。
将数据加载到 BigQuery 中
初始加载和增量加载的步骤类似。对于每种加载,您都需要在 SAP Data Services 中启动复制作业并执行数据流,以便将数据从 SAP LT Replication Server 加载到 BigQuery 中。这两个加载过程之间的一个重要区别在于 $INITLOAD 全局变量的值。对于初始加载,$INITLOAD 必须设置为 1。对于增量加载,$INITLOAD 必须为 0。
执行初始加载
执行初始加载时,源数据集中的所有数据都会复制到目标 BigQuery 表,该表连接到初始加载数据流。目标表中的任何数据都会被覆盖。
- 在 SAP Data Services Designer 中,打开 Project Explorer。
- 右键点击复制作业名称,然后选择 Execute。系统会显示一个对话框。
- 在该对话框中,前往全局变量标签页,然后将
$INITLOAD的值更改为 1,这样初始加载就会首先运行。 - 点击确定。此时,加载过程会启动,而调试消息也开始出现在 SAP Data Services 日志中。数据将加载到您在 BigQuery 中为初始加载创建的表中。在本文的说明中,初始加载表的名称为 BQ_INIT_LOAD。您的表名称可能有所不同。
- 如需查看加载是否已完成,请前往 Google Cloud 控制台,然后打开包含该表的 BigQuery 数据集。如果数据仍在加载,则表名称旁边会显示“正在加载”。
加载完成后,即可在 BigQuery 中处理数据。
从此时开始,源表中的所有更改都会记录在 SAP LT Replication Server 增量队列中。如需将数据从增量队列加载到 BigQuery,请执行增量加载作业。
执行增量加载
执行增量加载时,只有自上次加载以来在源数据集中发生的更改会复制到目标 BigQuery 表,该表连接到增量加载数据流。
- 右键点击作业名称,然后选择 Execute。
- 点击确定。此时,加载过程会启动,而调试消息也开始出现在 SAP Data Services 日志中。数据将加载到您在 BigQuery 中为增量加载创建的表中。在本文的说明中,增量加载表的名称为 BQ_DELTA_LOAD。您的表名称可能有所不同。
- 如需查看加载是否已完成,请前往 Google Cloud 控制台,然后打开包含该表的 BigQuery 数据集。如果数据仍在加载,则表名称旁边会显示“正在加载”。
- 加载完成后,即可在 BigQuery 中处理数据。
为了跟踪源数据的更改情况,SAP LT Replication Server 会在 DI_SEQUENCE_NUMBER 列中记录更改数据操作的顺序,并且在 DI_OPERATION_TYPE 列中记录更改数据操作的类型(D 表示“删除”、U 表示“更新”、I 表示“插入”)。SAP LT Replication Server 将数据存储在增量队列表的列中,系统会将数据从这些列复制到 BigQuery。
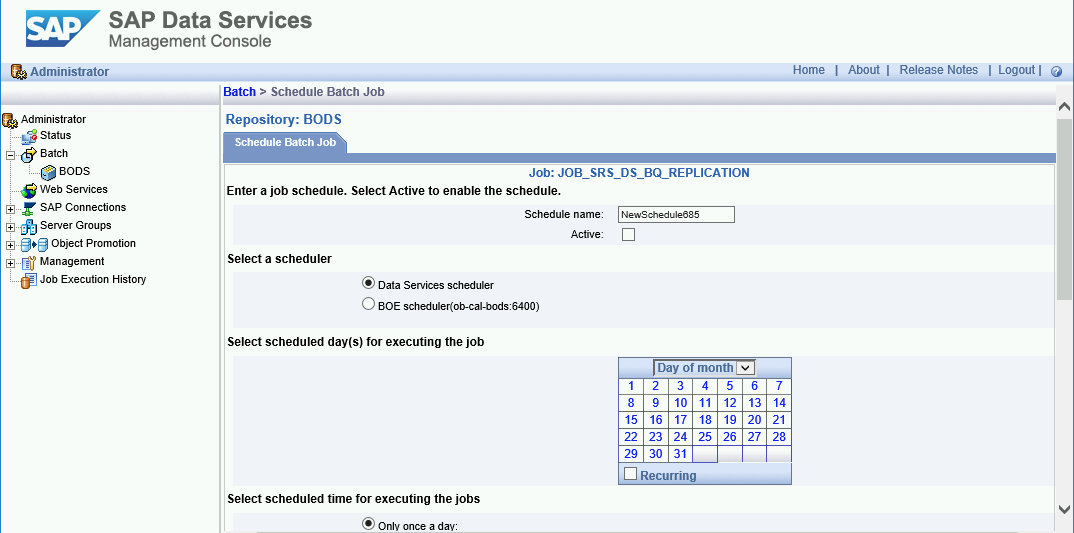
安排增量加载
您可以使用 SAP Data Services Management Console 安排增量加载作业定期运行。
- 打开 SAP Data Services Management Console 应用。
- 点击 Administrator。
- 展开左侧菜单树中的 Batch 节点。
- 点击您的 SAP Data Services 代码库的名称。
- 点击 Batch Job Configuration 标签页。
- 点击 Add Schedule。
- 填写 Schedule name。
- 选中 Active。
- 在 Select scheduled time for executing the jobs 部分中,指定增量加载的执行频率。
- 重要提示: Google Cloud 会限制您一天中可以运行的 BigQuery 加载作业的数量。请确保您安排的数量不会超过限制;该限制所对应的数量无法增加。如需详细了解 BigQuery 加载作业的限制,请参阅 BigQuery 文档中的配额和限制。
- 展开 Global Variables,然后检查 $INITLOAD 是否设置为 0。
- 点击 Apply。
后续步骤
在 BigQuery 中查询和分析复制的数据。
如需详细了解查询,请参阅以下内容:
- BigQuery 文档中的查询 BigQuery 数据概览。
如需了解如何在 BigQuery 中大规模合并初始加载数据和增量加载数据,请参阅以下内容:
- 在 BigQuery 中执行大规模变更解决方案(可在 Google Cloud 博客中找到)。
- BigQuery 文档中的数据操纵语言。
探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud 架构中心。