Questo documento descrive come spostare i job Apache Spark in Dataproc. Il documento è destinato ai big data engineer e architect e sviluppatori. Tratta argomenti quali considerazioni per la migrazione, preparazione, migrazione e gestione dei job.
Panoramica
Quando vuoi spostare i carichi di lavoro Apache Spark da un ambiente on-premise a Google Cloud, ti consigliamo di utilizzare Dataproc per eseguire cluster Apache Spark/Apache Hadoop. Dataproc è un servizio completamente gestito e supportato offerto da Google Cloud. Ti consente di separare lo spazio di archiviazione e l'elaborazione, il che ti aiuta a gestire i costi e ad essere più flessibile nel scalare i carichi di lavoro.
Se un ambiente Hadoop gestito non soddisfa le tue esigenze, puoi anche usare una configurazione diversa, ad esempio l'esecuzione di Spark Google Kubernetes Engine (GKE) o noleggiare macchine virtuali su Compute Engine e configurare un servizio Hadoop o Spark raggrupparsi. Tuttavia, tieni presente che le opzioni diverse dall'utilizzo Dataproc sono autogestiti e offrono assistenza solo dalla community.
Pianificazione della migrazione
Esistono molte differenze tra l'esecuzione di job Spark on-premise e l'esecuzione Job Spark su cluster Dataproc o Hadoop su in Compute Engine. È importante esaminare attentamente il carico di lavoro per prepararti alla migrazione. In questa sezione illustreremo le considerazioni da tenere presenti e i preparativi da seguire prima di eseguire la migrazione dei job Spark.
Identifica i tipi di job e pianifica i cluster
Esistono tre tipi di carichi di lavoro Spark, come descritto in questa sezione.
Job batch pianificati regolarmente
I job batch pianificati regolarmente includono casi d'uso come ETL giornalieri o orari o pipeline per l'addestramento di modelli di machine learning con Spark ML. In questi casi, consigliamo di creare un cluster per ogni carico di lavoro batch per eliminare il cluster al termine del job. Hai la flessibilità di configurare il cluster, perché puoi regolare la configurazione per ogni carico di lavoro separatamente. I cluster Dataproc vengono fatturati in incrementi di un secondo dopo il primo minuto, quindi questo approccio anche economicamente convenienti, perché etichetta nei cluster. Per ulteriori informazioni, consulta Prezzi di Dataproc .
Puoi implementare i job batch con modelli di flusso di lavoro o seguendo questi passaggi:
Crea un cluster e attendi che venga creato. Puoi monitorare se il cluster è stato creato utilizzando una chiamata API o un comando gcloud. Se esegui il job su un cluster Dataproc dedicato, potrebbe essere utile disattivare l'allocazione dinamica e il servizio di ordinamento esterno. Il seguente comando
gcloudmostra le proprietà di configurazione di Spark fornite quando crei il cluster Dataproc:dataproc clusters create ... \ --properties 'spark:spark.dynamicAllocation.enabled=false,spark:spark.shuffle.service.enabled=false,spark.executor.instances=10000'Invia il tuo job nel cluster. Puoi monitorare lo stato del job utilizzando un Chiamata API o un comando gcloud. Ad esempio:
jobId=$(gcloud --quiet dataproc jobs submit pyspark \ --async \ --format='value(reference.jobId)' \ --cluster $clusterName \ --region global \ gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py) gcloud dataproc jobs describe $jobId \ --region=global \ --format='value(status.state)'Elimina il cluster dopo l'esecuzione del job utilizzando una chiamata API o un comando gcloud.
Job in modalità flusso
Per i job in streaming, devi creare un cluster Dataproc di lunga durata e configurarlo in modalità ad alta disponibilità. Per questo caso, non consigliamo di utilizzare VM preemptibili.
Carichi di lavoro ad hoc o interattivi inviati dagli utenti
Tra gli esempi di carichi di lavoro ad hoc rientrano gli utenti che scrivono query o eseguono analitici durante il giorno.
In questi casi, devi decidere se il cluster deve essere eseguito disponibilità elevata, se vuoi utilizzare VM prerilasciabili e potrai gestire l'accesso al cluster. Puoi pianificare la creazione del cluster (ad esempio, se non hai mai bisogno del cluster durante la notte nei fine settimana) e puoi implementare scalabilità in base alla pianificazione.
Identifica le dipendenze e le origini dati
Ogni job ha le proprie dipendenze (ad esempio le origini dati di cui ha bisogno) e altri team della tua azienda potrebbero dipendere dall'esito dei tuoi job. Pertanto, devi identificare tutte le dipendenze e creare un piano di migrazione che includa procedure per quanto segue:
Migrazione passo passo di tutte le origini dati a in Google Cloud. All'inizio, è utile eseguire il mirroring dell'origine dati in Google Cloud in modo da averla in due posizioni.
Migrazione job per job dei carichi di lavoro Spark in Google Cloud il prima possibile quando è stata eseguita la migrazione delle origini dati corrispondenti. Come per i dati, a un certo punto potresti avere due carichi di lavoro in esecuzione in parallelo sia nel vecchio ambiente sia in Google Cloud.
Migrazione di altri carichi di lavoro che dipendono dall'output di Spark carichi di lavoro con scale out impegnativi. Oppure potresti semplicemente replicare l'output nella fase iniziale completamente gestito di Google Cloud.
Arresto dei job Spark nel vecchio ambiente dopo che tutti i team dipendenti hanno confermato di non aver più bisogno dei lavori.
Scegliere le opzioni di archiviazione
Esistono due opzioni di archiviazione da utilizzare con i cluster Dataproc: puoi archiviare tutti i dati in Cloud Storage oppure utilizzare dischi locali o dischi permanenti con i worker del cluster. La scelta corretta dipende dalla natura dei tuoi job.
Confronto tra Cloud Storage e HDFS
Su ogni nodo di un cluster Dataproc è installato un connettore Cloud Storage. Per impostazione predefinita, il connettore è installato
/usr/lib/hadoop/lib. Il connettore implementa lo strumento Hadoop
FileSystem
e rende Cloud Storage compatibile con HDFS.
Poiché Cloud Storage è un sistema di archiviazione di oggetti binari di grandi dimensioni (BLOB),
il connettore emula le directory in base al nome dell'oggetto. Puoi accedere ai tuoi dati utilizzando il prefisso gs:// anziché hdfs://.
Il connettore Cloud Storage in genere non richiede personalizzazione. Tuttavia, se devi apportare modifiche, puoi seguire le istruzioni per configurazione del connettore. È disponibile anche un elenco completo delle chiavi di configurazione available.
Cloud Storage è una buona opzione se:
- I dati in ORC, Parquet, Avro o in qualsiasi altro formato verranno utilizzati da diversi cluster o job e hai bisogno della persistenza dei dati se il cluster termina.
- È necessaria una velocità effettiva elevata e i dati vengono archiviati in file di dimensioni superiori a 128 MB.
- Per i tuoi dati è necessaria la durabilità tra zone.
- I dati devono essere altamente disponibili, ad esempio, vuoi eliminare NameNode HDFS come singolo punto di errore.
Lo spazio di archiviazione locale HDFS è una buona opzione se:
- I tuoi job richiedono molte operazioni sui metadati, ad esempio devi migliaia di partizioni e directory e le dimensioni di ogni file sono relativamente piccole.
- Modifichi frequentemente i dati HDFS o rinomini le directory. Gli oggetti Cloud Storage sono immutabili, quindi rinominare una directory è un'operazione costosa perché consiste nel copiare tutti gli oggetti in una nuova chiave ed eliminarli successivamente.
- Utilizzi molto l'operazione di aggiunta sui file HDFS.
Hai carichi di lavoro che comportano I/O pesanti. Ad esempio, hai molte scritture partizionate, come quelle riportate di seguito:
spark.read().write.partitionBy(...).parquet("gs://")Hai carichi di lavoro di I/O particolarmente sensibili alla latenza. Ad esempio, è necessaria una latenza di millisecondi a singola cifra per operazione di archiviazione.
In generale, consigliamo di utilizzare Cloud Storage come origine dati iniziale e finale in una pipeline di big data. Ad esempio, se un flusso di lavoro contiene Job Spark in serie. Il primo job recupera i dati iniziali da Cloud Storage e scrive i dati dello shuffling e l'output intermedio del job a HDFS. Il job Spark finale scrive i risultati in Cloud Storage.
Regolare le dimensioni dello spazio di archiviazione
L'uso di Dataproc con Cloud Storage consente di ridurre i requisiti di disco e risparmiare sui costi posizionando i dati lì anziché l'HDFS. Se mantieni i tuoi dati su Cloud Storage e non li archivi sull'HDFS locale, puoi utilizzare dischi più piccoli per il tuo cluster. Rendendo un cluster veramente on demand, puoi anche separare archiviazione e computing, che consente di ridurre significativamente i costi.
Anche se archivi tutti i tuoi dati in Cloud Storage, Il cluster Dataproc richiede HDFS per determinate operazioni come per archiviare file di controllo e recupero o aggregare i log. Ha bisogno anche di contenuti non HDFS spazio su disco locale per lo shuffling. Puoi ridurre le dimensioni del disco per worker se non utilizzano in modo eccessivo l'HDFS locale.
Ecco alcune opzioni per regolare la dimensione dell'HDFS locale:
- Riduci le dimensioni totali dell'HDFS locale diminuendo la dimensione dischi permanenti primari per il master e i worker. Il disco permanente primario contiene anche il volume di avvio e le librerie di sistema, quindi alloca almeno 100 GB.
- Aumenta la dimensione totale dell'HDFS locale aumentando la dimensione disco permanente primario per i worker. Valuta attentamente questa opzione: è raro avere carichi di lavoro che ottengono prestazioni migliori grazie a HDFS con i dischi permanenti standard rispetto all'uso su Cloud Storage o HDFS locale con SSD.
- Collega fino a otto SSD (da 375 GB ciascuno) a ciascun worker e utilizza questi dischi per l'HDFS. Questa è una buona opzione se devi utilizzare l'HDFS per carichi di lavoro ad uso intensivo di I/O e hai bisogno di una latenza in millisecondi a singola cifra. Assicurati di utilizzare un tipo di macchina con CPU e memoria sufficienti sul worker per supportare questi dischi.
- Utilizzare SSD a disco permanente (DP-SSD) per il master o i worker come disco primario.
Accedi a Dataproc
L'accesso a Dataproc o Hadoop su Compute Engine rispetto all'accesso a un cluster on-premise. Devi determinare le impostazioni di sicurezza e le opzioni di accesso alla rete.
Networking
Tutte le istanze VM di un cluster Dataproc richiedono una rete interna tra di loro e richiedono porte UDP, TCP e ICMP aperte. Puoi consentire l'accesso al cluster Dataproc dall'esterno gli indirizzi IP utilizzando la configurazione di rete predefinita o un rete VPC. Il cluster Dataproc avrà accesso alla rete di tutti i servizi Google Cloud (bucket Cloud Storage, API e così via) in qualsiasi opzione di rete utilizzata. Per consentire l'accesso alla rete da o verso le risorse on-premise, scegli una configurazione della rete VPC e configura le regole firewall appropriate. Per maggiori dettagli, consulta la guida sulla configurazione di rete del cluster Dataproc e la sezione Accedere a YARN di seguito.
Gestione di identità e accessi
Oltre all'accesso alla rete, il cluster Dataproc ha bisogno le autorizzazioni di accesso alle risorse. Ad esempio, per scrivere dati in un nel bucket Cloud Storage, il cluster Dataproc deve avere accesso in scrittura al bucket. Stabilisci l'accesso utilizzando ruoli. Analizza il codice Spark e trova tutte le istanze non Dataproc necessarie al codice e concedere i ruoli corretti all'agente del cluster account di servizio. Inoltre, assicurati che gli utenti che creeranno cluster, job, operazioni e modelli di flusso di lavoro dispongano delle autorizzazioni giuste.
Per ulteriori dettagli e best practice, consulta la documentazione di IAM.
Verificare le dipendenze di Spark e di altre librerie
Confronta la tua versione di Spark e le versioni di altre librerie con l'elenco delle versioni di Dataproc ufficiale e cerca eventuali librerie non ancora disponibili. Ti consigliamo di utilizzare le versioni di Spark supportate ufficialmente da Dataproc.
Se devi aggiungere librerie, puoi procedere nel seguente modo:
- Crea un immagine personalizzata di un cluster Dataproc.
- Crea script di inizializzazione in Cloud Storage per il tuo cluster. Puoi utilizzare gli script di inizializzazione per installare dipendenze aggiuntive, copiare i binari e così via.
- Ricompila il tuo codice Java o Scala e crea pacchetti di tutte le dipendenze aggiuntive che non fanno parte della distribuzione base come "vasetto di grasso" mediante Gradle, Maven, Sbt o un altro strumento.
Regolare le dimensioni del cluster Dataproc
In qualsiasi configurazione di cluster, on-premise o nel cloud, il cluster è fondamentale per le prestazioni dei job Spark. Un job Spark senza risorse sufficienti sarà lento o non funzionerà, soprattutto se non ha abbastanza esecutori la memoria. Per consigli su cosa considerare per determinare le dimensioni di un cluster Hadoop, consulta la sezione Dimensionamento del cluster della guida alla migrazione di Hadoop.
Le sezioni seguenti descrivono alcune opzioni per la dimensione del cluster.
Ottenere la configurazione dei job Spark attuali
Controlla la configurazione dei tuoi job Spark attuali e assicurati che il cluster Dataproc sia abbastanza grande. Se ti sposti da un file condiviso in più cluster Dataproc (uno per ogni batch) carico di lavoro), osservare la configurazione YARN di ogni applicazione capire quanti esecutori sono necessari, il numero di CPU per esecutore e memoria totale degli esecutori. Se nel tuo cluster on-premise sono configurate code YARN, scopri quali job condividono le risorse di ogni coda e identifica i colli di bottiglia. Questa migrazione è un'opportunità per rimuovere eventuali limitazioni delle risorse che potresti avere avuto nel tuo cluster on-premise.
Scegliere i tipi di macchine e le opzioni di disco
Scegli il numero e il tipo di VM in base alle esigenze del tuo carico di lavoro. Se hai deciso di utilizzare HDFS locale per lo stoccaggio, assicurati che le VM abbiano il tipo e le dimensioni del disco corretti. Non dimenticare di includere le risorse necessarie dei programmi per i conducenti nel tuo calcolo.
Ogni VM ha un limite di traffico in uscita della rete di 2 Gbps per vCPU. La scrittura su dischi permanenti o su unità SSD permanenti viene conteggiata ai fini di questo limite, pertanto una VM con un numero molto ridotto di vCPU potrebbe essere limitata dal limite quando scrive su questi dischi. Questo è probabile che si verifichi nella fase di smistamento, quando Spark scrive i dati di smistamento su disco e li sposta sulla rete tra gli executor. I dischi permanenti richiedono almeno 2 vCPU per raggiungere il numero massimo di scrittura e gli SSD permanenti richiedono 4 vCPU. Tieni presente che questi valori minimi non tengono conto del traffico, ad esempio la comunicazione tra le VM. Inoltre, le dimensioni di ogni disco influiscono sulle sue prestazioni di picco.
La configurazione che scegli avrà un impatto sui costi di un cluster Dataproc. I prezzi di Dataproc si aggiungono al prezzo per istanza di Compute Engine per ogni VM altre risorse Google Cloud. Per ulteriori informazioni e per utilizzare il Calcolatore prezzi di Google Cloud per ottenere una stima dei costi, consulta la pagina dei prezzi di Dataproc.
Benchmarking del rendimento e ottimizzazione
Al termine della fase di migrazione dei job, ma prima di interrompere l'esecuzione dei carichi di lavoro Spark nel cluster on-premise, esegui il benchmark dei job Spark e valuta eventuali ottimizzazioni. Ricorda che puoi ridimensiona nel cluster se la configurazione non è ottimale.
Scalabilità automatica di Dataproc Serverless per Spark
Utilizza Dataproc Serverless per eseguire carichi di lavoro Spark senza eseguire il provisioning e la gestione del tuo cluster. Specifica i parametri del carico di lavoro e poi invialo al servizio Dataproc Serverless. Il servizio eseguirà il carico di lavoro su un'infrastruttura di computing gestita, con scalabilità automatica delle risorse in base alle esigenze. Gli addebiti di Dataproc Serverless si applicano solo al momento dell'esecuzione del carico di lavoro.
Esecuzione della migrazione
Questa sezione illustra la migrazione dei dati, la modifica del codice del job e la modifica del modo durante l'esecuzione dei job.
Migrazione dei dati
Prima di eseguire qualsiasi job Spark nel cluster Dataproc, è necessario per eseguire la migrazione dei dati in Google Cloud. Per ulteriori informazioni, consulta Guida alla migrazione dei dati.
Esegui la migrazione del codice Spark
Dopo aver pianificato la migrazione a Dataproc e aver spostato eventuali
le origini dati richieste, puoi eseguire la migrazione del codice del job. Se non ci sono differenze
nelle versioni Spark tra i due cluster e se vuoi archiviare i dati
Cloud Storage anziché HDFS locale, devi solo modificare il prefisso
di tutti i percorsi di file HDFS da hdfs:// a gs://.
Se utilizzi versioni diverse di Spark, consulta le note di rilascio di Spark, confronta le due versioni e adatta il codice Spark di conseguenza.
Puoi copiare i file jar per le applicazioni Spark al bucket Cloud Storage collegato al cluster Dataproc o a una cartella HDFS. La sezione successiva illustra le opzioni disponibili per l'esecuzione dei job Spark.
Se decidi di utilizzare modelli di flusso di lavoro, ti consigliamo di testare separatamente ogni job Spark che prevedi di aggiungere. Poi puoi eseguire un test finale del modello per assicurarti il flusso di lavoro del modello sia corretto (non mancano job upstream, gli output vengono archiviati nelle posizioni corrette e così via).
Esegui job
Puoi eseguire i job Spark nei seguenti modi:
Usa il seguente comando
gcloud:gcloud dataproc jobs submit [COMMAND]
dove:
[COMMAND]èspark,pysparkospark-sqlPuoi impostare le proprietà Spark con l'opzione
--properties. Per maggiori informazioni informazioni, consulta documentazione per questo comando.Utilizzando la stessa procedura utilizzata prima di eseguire la migrazione del job a Dataproc. Il cluster Dataproc deve essere accessibile dall'on-premise e devi utilizzare la stessa configurazione.
Utilizzando Cloud Composer. Puoi crea un ambiente (un server Apache Airflow gestito), definisci più job Spark come Flusso di lavoro DAG, ed eseguire l'intero flusso di lavoro.
Per maggiori dettagli, consulta la guida su come inviare un lavoro.
Gestione dei job dopo la migrazione
Dopo aver spostato i job Spark in Google Cloud, è importante gestirli utilizzando gli strumenti e i meccanismi forniti da Google Cloud. In questa sezione vengono descritti il logging, il monitoraggio, l'accesso ai cluster, il ridimensionamento dei cluster e l'ottimizzazione dei job.
Utilizza il logging e il monitoraggio delle prestazioni
In Google Cloud puoi utilizzare Cloud Logging e Cloud Monitoring per visualizzare e personalizzare i log e per monitorare job e risorse.
Il modo migliore per individuare l'errore che ha causato un errore di job Spark è esaminare l'output del driver e i log generati dagli esecutori Spark.
Puoi recuperare l'output del programma del driver utilizzando la console Google Cloud oppure
utilizzando un comando gcloud. L'output viene inoltre archiviato nel
bucket Cloud Storage del cluster Dataproc. Per ulteriori dettagli, consulta la sezione sull'output del driver dei job nella documentazione di Dataproc.
Tutti gli altri log si trovano in file diversi all'interno delle macchine del
in un cluster Kubernetes. È possibile visualizzare i log per ciascun container dalla UI web dell'app Spark (o dal server di cronologia al termine del programma) nella scheda Esecutori. Devi esaminare tutti i container Spark per visualizzare tutti i log. Se scrivi log o stampi su stdout o stderr nel codice dell'applicazione, i log vengono salvati nel reindirizzamento di stdout o stderr.
In un cluster Dataproc, YARN è configurato per raccogliere tutti questi log per impostazione predefinita e sono disponibili in Cloud Logging. Cloud Logging fornisce una visualizzazione consolidata e concisa di tutti i log in modo da non dover perdere tempo a sfogliare i log del container per trovare gli errori.
La figura seguente mostra la pagina Cloud Logging nella nella console Google Cloud. Puoi visualizzare tutti i log dal tuo cluster Dataproc selezionando il nome del cluster nel menu del selettore. Non dimenticare di espandere la durata temporale nel selettore dell'intervallo di tempo.
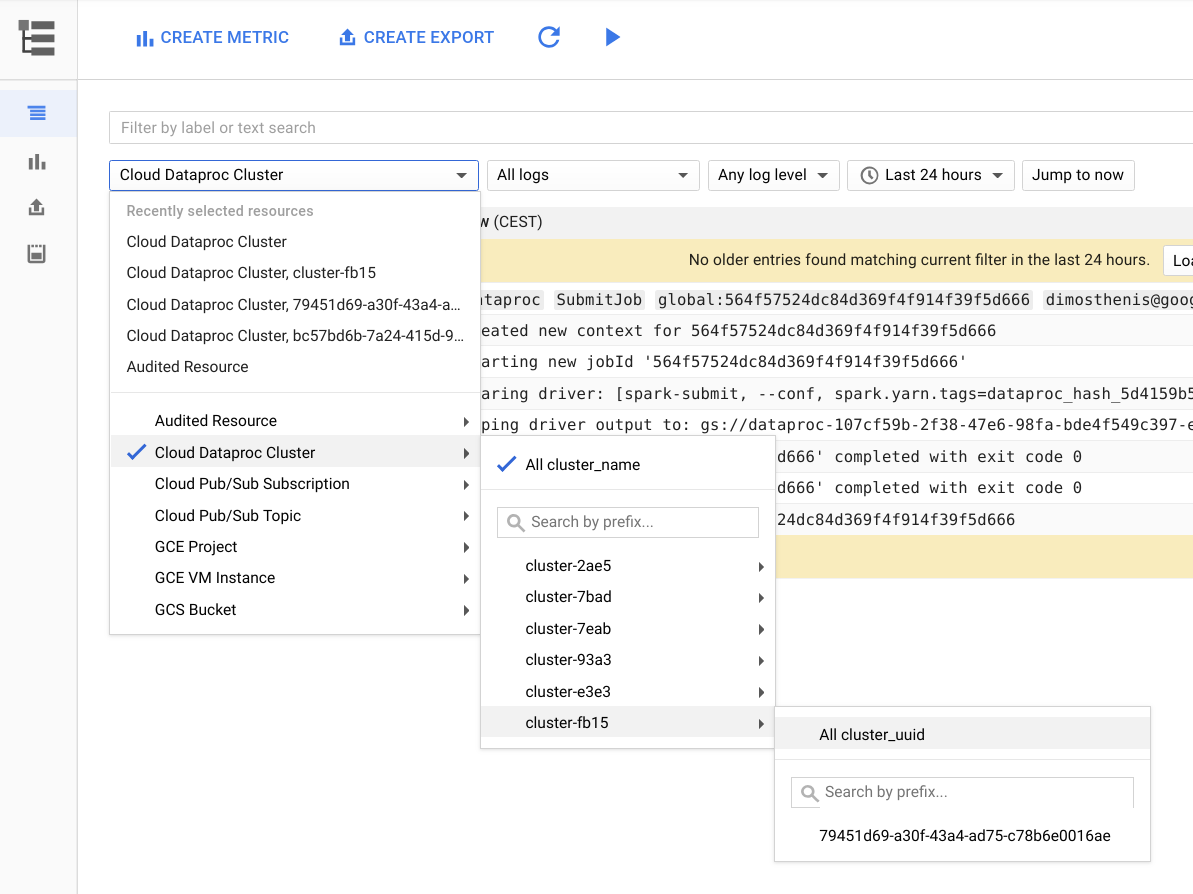
Puoi ottenere i log da un'applicazione Spark filtrandoli in base al relativo ID. Puoi ottenere l'ID applicazione dall'output del driver.
Creare e utilizzare le etichette
Per trovare più velocemente i log, puoi creare e utilizzare i tuoi
etichette
per ogni cluster o per ogni job Dataproc. Ad esempio, puoi
crea un'etichetta con la chiave env e il valore exploration e utilizzala per
il tuo job di esplorazione dei dati. Puoi quindi ottenere i log per tutti i job di esplorazione
creazioni filtrando con label:env:exploration in Cloud Logging.
Tieni presente che questo filtro non restituirà tutti i log per questo job, ma solo la risorsa
log di creazione.
Imposta il livello di log
Puoi
impostare il livello di log del driver
utilizzando il seguente comando gcloud:
gcloud dataproc jobs submit hadoop --driver-log-levels
Imposta il livello di log per il resto dell'applicazione dal contesto Spark. Ad esempio:
spark.sparkContext.setLogLevel("DEBUG")Monitora i job
Cloud Monitoring può monitorare CPU, disco, utilizzo della rete e risorse YARN del cluster. Puoi creare una dashboard personalizzata per ottenere grafici aggiornati per queste e altre metriche. Dataproc viene eseguito su Compute Engine. Se vuoi visualizzare l'utilizzo della CPU, l'I/O del disco metriche di networking in un grafico, devi selezionare una VM istanza come tipo di risorsa, quindi filtra per nome del cluster. Le seguenti mostra un esempio dell'output.
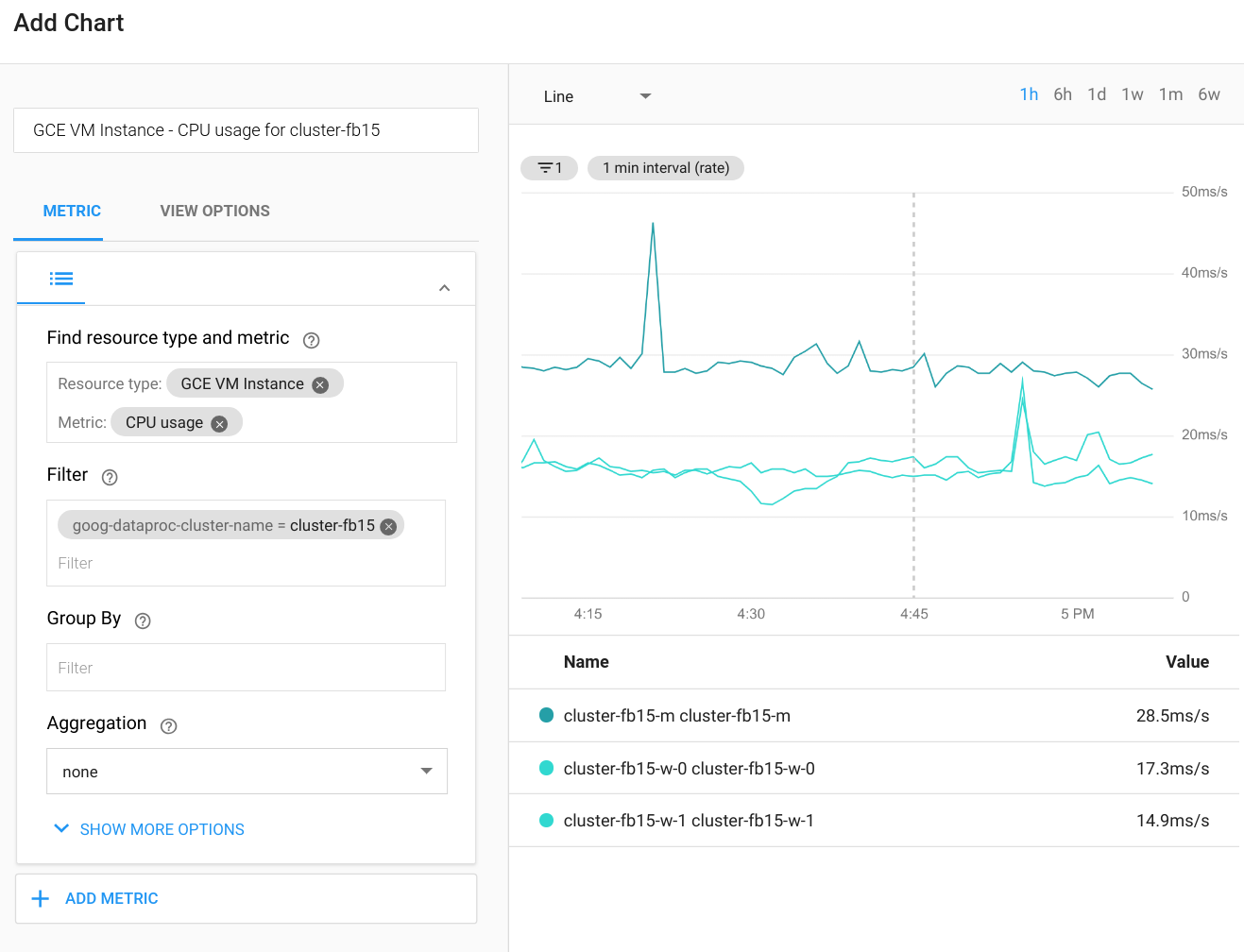
Per visualizzare le metriche per query, job, fasi o attività Spark, connettiti a Spark dell'applicazione. La sezione seguente spiega come eseguire questa operazione. Per informazioni dettagliate su come creare metriche personalizzate, consulta la guida Metriche personalizzate dell'agente.
Accedere a YARN
Puoi accedere all'interfaccia web del gestore di risorse YARN dall'esterno della un cluster Dataproc mediante la configurazione Tunnel SSH. È preferibile usare un modello leggero proxy SOCKS invece del port forwarding locale, perché navigare nell'interfaccia web è più facile in questo modo.
I seguenti URL sono utili per l'accesso YARN:
Gestore delle risorse YARN:
http://[MASTER_HOST_NAME]:8088Server di cronologia Spark:
http://[MASTER_HOST_NAME]:18080
Se il cluster Dataproc ha solo indirizzi IP interni, puoi connetterti tramite una connessione VPN o un bastion host. Per ulteriori informazioni, vedi Scegli un'opzione di connessione per le VM solo interne.
Scala e ridimensiona i cluster Dataproc
Il cluster Dataproc può essere scalato aumentando o diminuendo il numero di worker principali o secondari (prerilasciabili). Dataproc supporta anche il ritiro graduale.
Il downgrade in Spark è influenzato da una serie di fattori. Prendi in considerazione account:
Sconsigliamo di utilizzare
ExternalShuffleService, soprattutto se esegui periodicamente il ridimensionamento del cluster. Il ribaltamento utilizza i risultati che sono stati scritti sul disco locale del worker dopo l'esecuzione della fase di calcolo, pertanto il nodo non può essere rimosso anche se le risorse di calcolo non vengono più utilizzate.Spark cache in memoria (sia RDD che set di dati) ed esecutori utilizzati dalla cache non viene mai chiusa. Di conseguenza, se un worker viene utilizzato per la memorizzazione nella cache, non può mai essere dismesso con eleganza. Rimuovere con forza i worker influenzare le prestazioni complessive, in quanto i dati memorizzati nella cache andrebbero persi.
L'allocazione dinamica di Spark Streaming è disattivata per impostazione predefinita e la chiave di configurazione che imposta questo comportamento non è documentata. Puoi seguire una discussione sul comportamento dell'allocazione dinamica in un thread sui problemi di Spark. Se utilizzi Spark Streaming o Spark Streaming strutturato, devi: anche disattivare esplicitamente allocazione dinamica come discusso in precedenza Identifica i tipi di job e pianifica i cluster.
In generale, ti consigliamo di evitare di ridurre le dimensioni di un cluster Dataproc se esegui carichi di lavoro batch o in streaming.
Ottimizzazione del rendimento
Questa sezione illustra i modi per migliorare le prestazioni e ridurre i costi dei job Spark in esecuzione.
Gestisci le dimensioni dei file di Cloud Storage
Per ottenere prestazioni ottimali, suddividi i dati in Cloud Storage in file con dimensioni da 128 MB a 1 GB. L'utilizzo di molti file di piccole dimensioni può creare un collo di bottiglia. Se hai molti file di piccole dimensioni, valuta la possibilità di copiarli per l'elaborazione sull'HDFS locale e quindi copiando i risultati.
Passa ai dischi SSD
Se esegui molte operazioni di shuffling o scritture partizionate, passa alle unità SSD per migliorare le prestazioni.
Posiziona le VM nella stessa zona
Per ridurre i costi di networking e migliorare le prestazioni, utilizza la stessa località regionale per i bucket Cloud Storage che utilizzi per i cluster Dataproc.
Per impostazione predefinita, quando utilizzi endpoint Dataproc globali o regionali, le VM del cluster vengono posizionate nella stessa zona (o in un'altra zona della stessa regione con capacità sufficiente) al momento della creazione del cluster. Puoi anche specificare la zona al momento della creazione del cluster.
Utilizzo di VM prerilasciabili
Il cluster Dataproc può utilizzare come worker le istanze di VM prerilasciabili. Ciò si traduce in costi di calcolo all'ora inferiori per e non critici rispetto all'uso di istanze normali. Tuttavia, ci sono alcuni fattori da considerare quando utilizzi le VM prerilasciabili:
- Le VM prerilasciabili non possono essere utilizzate per l'archiviazione HDFS.
- Per impostazione predefinita, le VM prerilasciabili vengono create con dimensioni del disco di avvio più piccole e potresti voler ignorare questa configurazione se esegui carichi di lavoro con un'elevata percentuale di operazioni di smistamento. Per maggiori dettagli, consulta la pagina sulle VM prerilasciabili nella documentazione di Dataproc.
- Non è consigliabile rendere prerilasciabile più della metà dei worker totali.
Se utilizzi VM prerilasciabili, ti consigliamo di modificare il cluster per una maggiore tolleranza agli errori delle attività, in quanto le VM potrebbero meno disponibili. Ad esempio, nella configurazione YARN imposta impostazioni come le seguenti:
yarn.resourcemanager.am.max-attempts mapreduce.map.maxattempts mapreduce.reduce.maxattempts spark.task.maxFailures spark.stage.maxConsecutiveAttempts
Puoi aggiungere o rimuovere facilmente VM preemptibili dal tuo cluster. Per maggiori informazioni i dettagli, vedi VM prerilasciabili.
Passaggi successivi
- Consulta la guida su come eseguire la migrazione dell'infrastruttura Hadoop on-premise a Google Cloud.
- Consulta la nostra descrizione del ciclo di vita di un job Dataproc.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.