이 문서에서는 연구자, 데이터 과학자, 비즈니스 분석가에게 BigQuery에서 Fast Healthcare Interoperability Resources(FHIR) 데이터를 분석할 수 있는 프로세스와 고려사항을 설명합니다.
특히 이 문서에서는 Cloud Healthcare API의 FHIR 스토어에서 내보내는 환자 리소스 데이터에 중점을 둡니다. 또한 FHIR 스키마 데이터가 관계형 형식으로 작동하는 방식을 보여주는 일련의 쿼리를 살펴보고 뷰를 통해 재사용할 수 있도록 이러한 쿼리에 액세스하는 방법을 설명합니다.
FHIR 데이터 분석에 BigQuery 사용
Cloud Healthcare API의 FHIR 관련 API는 단일 FHIR 리소스 또는 FHIR 리소스 모음 수준에서 FHIR 데이터와 실시간으로 트랜잭션 상호작용을 할 수 있도록 설계되었습니다. 그러나 FHIR API는 분석 사용 사례 용으로 설계되지 않았습니다. 이러한 사용 사례의 경우 FHIR API에서 BigQuery로 데이터를 내보내는 것이 좋습니다. BigQuery는 방대한 양의 데이터를 소급적으로 또는 잠재적으로 분석할 수 있는 확장 가능한 서버리스 데이터 웨어하우스입니다.
또한 BigQuery는 ANSI:2011 SQL을 준수하므로 데이터 과학자와 비즈니스 분석가가 일반적으로 사용하는 도구(예: Tableau, Looker 또는 Vertex AI Workbench)를 통해 데이터에 액세스할 수 있습니다.
Vertex AI Workbench와 같은 일부 애플리케이션에서는 기본 제공 클라이언트(예: BigQuery용 Python 클라이언트 라이브러리)를 통해 액세스할 수 있습니다. 이러한 경우 애플리케이션에 반환되는 데이터는 기본 제공 언어 데이터 구조를 통해 사용할 수 있습니다.
BigQuery 액세스
Google Cloud 콘솔의 BigQuery 웹 UI와 다음 도구를 사용하여 BigQuery에 액세스할 수 있습니다.
- BigQuery 명령줄 도구
- BigQuery REST API 또는 클라이언트 라이브러리
- ODBC 및 JDBC 드라이버
이러한 도구를 사용하여 BigQuery를 거의 모든 애플리케이션에 통합할 수 있습니다.
FHIR 데이터 구조 작업
기본 제공 FHIR 표준 데이터 구조는 복잡하며 FHIR 리소스 전체에 중첩되고 삽입된 FHIR 데이터 유형이 있습니다. 이러한 삽입 가능한 FHIR 데이터 유형을 복합 데이터 유형이라고 합니다.
관계형 데이터베이스에서는 배열과 구조를 복잡한 데이터 유형이라고도 합니다. 기본 제공 FHIR 표준 데이터 구조는 문서 중심 시스템에서 XML 또는 JSON 파일로 직렬화되어 잘 작동하지만 관계형 데이터베이스로 번역할 경우 구조가 작업하는 데 까다로울 수 있습니다.
다음 스크린샷에서는 기본 제공 FHIR 표준 데이터 구조의 복잡한 특성을 보여주는 FHIR patient resource 데이터 유형을 부분적으로 보여줍니다.
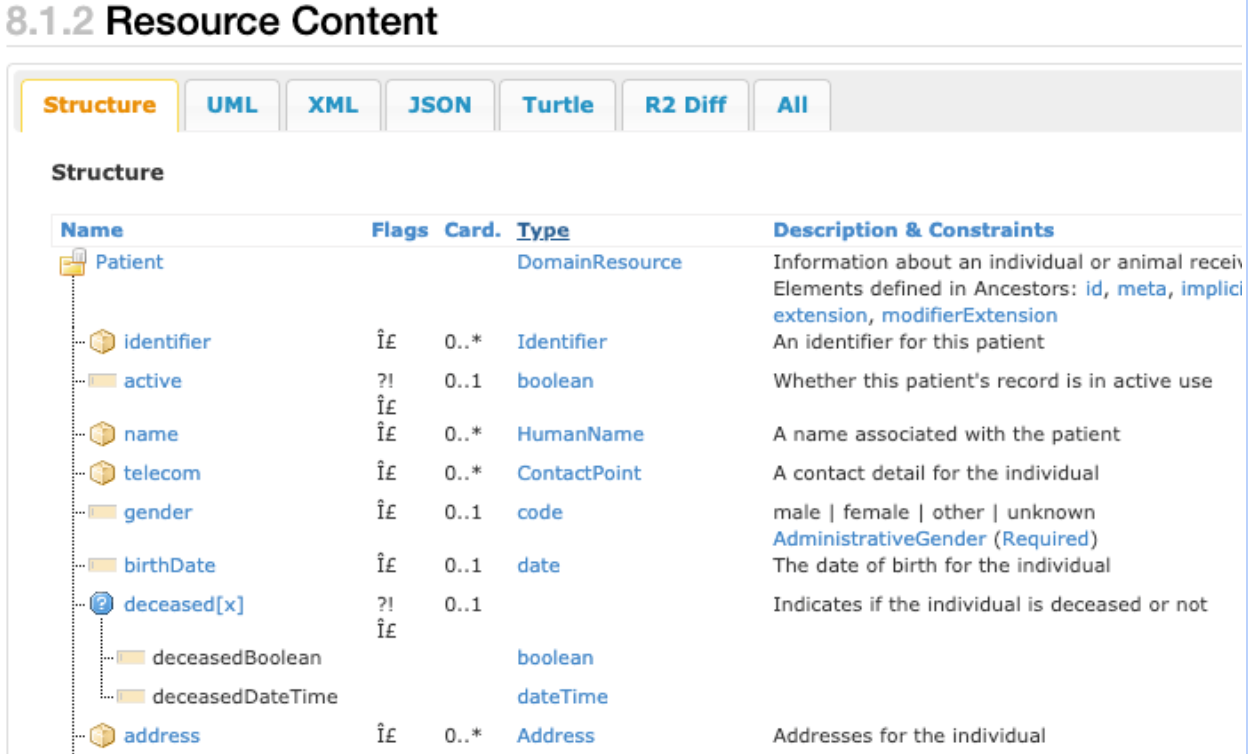
앞의 스크린샷은 FHIR patient
resource 데이터 유형의 기본 구성 요소를 보여줍니다. 예를 들어 카디널리티 열(표에 Card.로 표시됨)은 항목이 0개, 1개 또는 2개 이상 있을 수 있는 여러 항목을 보여줍니다. 유형 열에는 식별자, HumanName, Address 데이터 유형을 보여줍니다. 이러한 데이터 유형은 patient
resource 데이터 유형을 구성하는 복잡한 데이터 유형의 예시입니다. 이러한 각 행은 구조의 배열로 여러 번 기록될 수 있습니다.
배열 및 구조 사용
BigQuery는 배열과 FHIR 리소스에 표시되는 중첩되고 반복되는 데이터 구조인 STRUCT 데이터 유형을 지원하므로 FHIR에서 BigQuery로 데이터를 변환할 수 있습니다.
BigQuery에서 배열은 데이터 유형이 동일한 값 0개 이상으로 구성된 순서가 지정된 목록입니다. 간단한 데이터 유형(예: INT64 데이터 유형)과 복잡한 데이터 유형(예: STRUCT 데이터 유형)의 배열을 생성할 수 있습니다. 현재 배열의 배열은 지원되지 않으므로 ARRAY 데이터 유형은 예외입니다. BigQuery에서 구조체 배열은 반복 가능한 레코드로 표시됩니다.
BigQuery UI 또는 JSON 스키마 파일에서 중첩 데이터 또는 중첩되고 반복되는 데이터를 지정할 수 있습니다. 중첩 열 또는 중첩되고 반복되는 열을 지정하려면 RECORD (STRUCT) 데이터 유형을 사용합니다.
Cloud Healthcare API는 BigQuery에서 FHIR 스키마의 SQL을 지원합니다. 이 분석 스키마는 ExportResources() 메서드의 기본 스키마이며 FHIR 커뮤니티에서 지원됩니다.
BigQuery는 비정규화된 데이터를 지원합니다. 즉, 별표나 눈송이 스키마와 같은 관계형 스키마를 만드는 대신 데이터를 저장할 때 데이터를 비정규화하고 중첩되고 반복되는 열을 사용할 수 있습니다. 중첩되고 반복되는 열은 관계형(정규화된) 스키마를 유지하는 성능에 영향을 주지 않고 데이터 요소 간의 관계를 유지합니다.
UNNEST 연산자를 통한 데이터 액세스
FHIR API의 모든 FHIR 리소스를 데이터 행 하나로 BigQuery에 내보냅니다. 모든 행 내의 배열 또는 구조를 삽입 된 테이블로 생각할 수 있습니다. UNNEST 연산자를 사용하여 배열 또는 구조를 평면화하여 SELECT 절 또는 쿼리의 WHERE 절에서 해당 '테이블'의 데이터에 액세스할 수 있습니다.
UNNEST 연산자는 배열을 가져와 배열의 각 요소에 대한 행이 하나씩 있는 테이블을 반환합니다. 자세한 내용은 표준 SQL의 배열 작업를 참조하세요.
UNNEST 작업은 배열 요소의 순서를 유지하지 않지만 선택적 WITH OFFSET 절을 사용하여 테이블 순서를 변경할 수 있습니다. 이렇게 하면 각 배열 요소의 OFFSET 절이 있는 추가 열이 반환됩니다.
그런 다음 ORDER BY 절을 사용하여 오프셋을 기준으로 행을 정렬할 수 있습니다.
중첩되지 않은 데이터를 조인할 경우 BigQuery는 배열의 각 항목에서 배열의 열을 소스 테이블(FROM 절에서 UNNEST 호출 바로 앞에 있는 테이블)로 참조하는 상관관계의 CROSS JOIN 연산을 사용합니다. 소스 테이블의 각 행에서 UNNEST 작업은 배열을 해당 열에서 배열 요소가 포함된 일련의 행으로 평탄화합니다. 상관 관계가 있는 CROSS JOIN 작업은 이 새 행 집합을 소스 테이블의 단일 행과 조인합니다.
쿼리로 스키마 조사
BigQuery에서 FHIR 데이터를 쿼리하려면 내보내기 프로세스를 통해 생성 된 스키마를 이해해야 합니다. BigQuery를 사용하면 메타데이터를 표시하는 일련의 뷰인 INFORMATION_SCHEMA 기능을 통해 데이터 세트에 있는 모든 테이블의 열 구조를 검사할 수 있습니다. 이 문서의 나머지 부분에서는 데이터 검색을 위해 액세스할 수 있도록 설계된 FHIR 스키마의 SQL을 참조합니다.
다음 샘플 쿼리는 FHIR 스키마의 SQL에서 환자 테이블의 열 세부정보를 살펴봅니다. 쿼리는 FHIR의 Synthea 생성 합성 데이터 공개 데이터 세트를 참조합니다. 이 데이터 세트는 Synthea에서 생성한 100만 개 이상의 합성 환자 기록을 FHIR 형식으로 호스팅합니다.
INFORMATION_SCHEMA.COLUMNS 뷰를 쿼리하면 테이블의 각 열(필드)당 하나의 행이 쿼리 결과에 포함됩니다. 다음 쿼리는 환자 테이블의 모든 열을 반환합니다.
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
다음 쿼리 결과 스크린샷은 identifier 데이터 유형과 STRUCT 데이터 유형이 포함된 데이터 유형 내 배열을 보여줍니다.

BigQuery에서 FHIR 환자 리소스 사용
환자의 의료 기록 번호(MRN)는 FHIR 데이터에 저장된 중요 정보이며 조직의 모든 환자에 대한 임상 및 운영 데이터 시스템 전반에서 사용됩니다. 개별 환자 또는 환자 집합의 데이터에 액세스하려면 MRN을 필터링하거나 반환하거나 둘 다 수행해야 합니다.
다음 샘플 쿼리는 MRN과 모든 환자의 생년월일을 포함하여 내부 FHIR 서버 식별자를 환자 리소스 자체에 반환합니다. 특정 MRN에 쿼리하는 쿼리도 포함되지만 이 예시에서는 주석 처리됩니다.
이 쿼리에서는 identifier 복합 데이터 유형을 두 번 중첩 해제합니다. 또한 상관 관계가 있는 CROSS JOIN 작업을 사용하여 중첩되지 않은 데이터를 소스 테이블과 조인합니다.
쿼리의 bigquery-public-data.fhir_synthea.patient 테이블은 FHIR의 FHIR 스키마 버전에서 SQL을 BigQuery로 내보내 생성되었습니다.
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
출력은 다음과 비슷합니다.
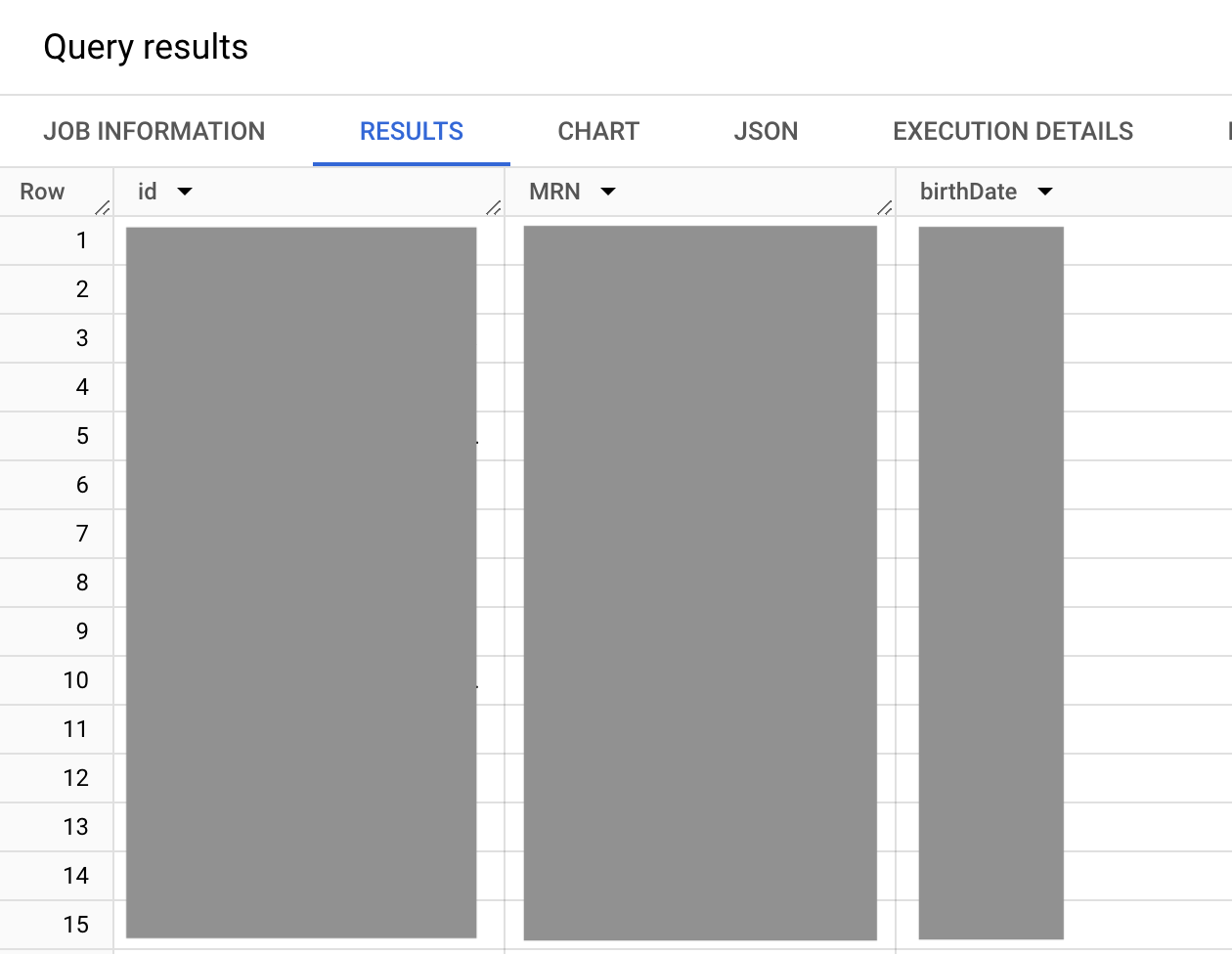
앞의 쿼리에서 identifier.type.coding.code 값 집합은 MRN(MR ID 데이터 유형), 운전면허증(DL ID 데이터 유형), 여권 번호(PPN ID 데이터 유형)과 같은 사용 가능한 ID 데이터 유형을 열거하는 FHIR identifier 값 집합입니다. identifier.type.coding 값 집합이 배열이므로 환자에 나열되는 식별자가 여러 개 있을 수 있습니다. 하지만 이 경우에는 MRN(MR ID 데이터 유형)이 필요합니다.
환자 테이블을 다른 테이블과 조인
환자 테이블 쿼리를 빌드하면 환잔 테이블을 조건 테이블과 같은 이 데이터 세트의 다른 테이블과 조인할 수 있습니다. 조건 테이블은 환자 진단이 기록되는 위치입니다.
다음 샘플 쿼리는 의료 조건이 고혈압인 모든 항목을 검색합니다.
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
출력은 다음과 비슷합니다.
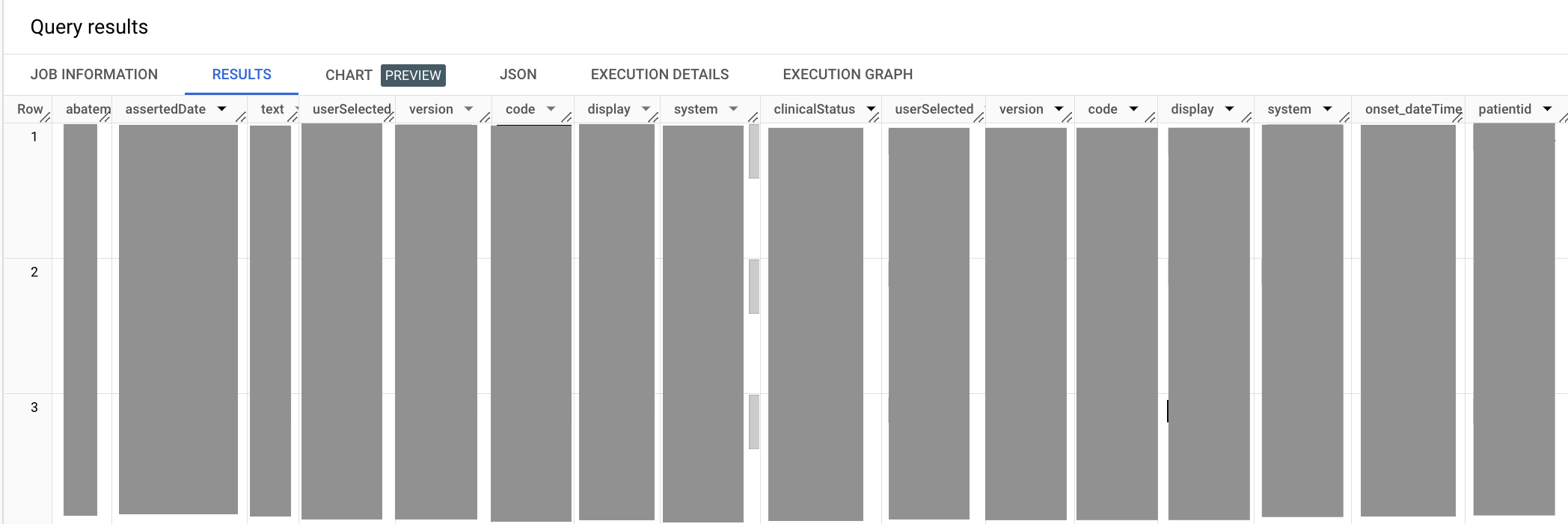
앞의 쿼리에서 UNNEST 메서드를 재사용하여 code.coding 필드를 평면화합니다. SELECT 문의 abatement.dateTime 및 onset.dateTime 코드 요소는 모두 dateTime로 끝나므로 SELECT 문의 출력에 모호한 열 이름이 생깁니다. Hypertension 코드를 선택하는 경우 코드 출처의 용어 시스템(이 경우 SNOMED CT 임상 용어 시스템)도 선언해야 합니다.
마지막 단계로 subject.patientid 키를 사용하여 조건 테이블을 환자 테이블과 조인합니다. 이 키는 FHIR 서버 내에서 환자 리소스 자체의 식별자를 가리킵니다.
쿼리 통합
다음 샘플 쿼리에서는 이전 두 섹션의 쿼리를 사용하고 간단한 계산을 수행하면서 WITH 절을 사용하여 조인합니다.
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
출력은 다음과 비슷합니다.
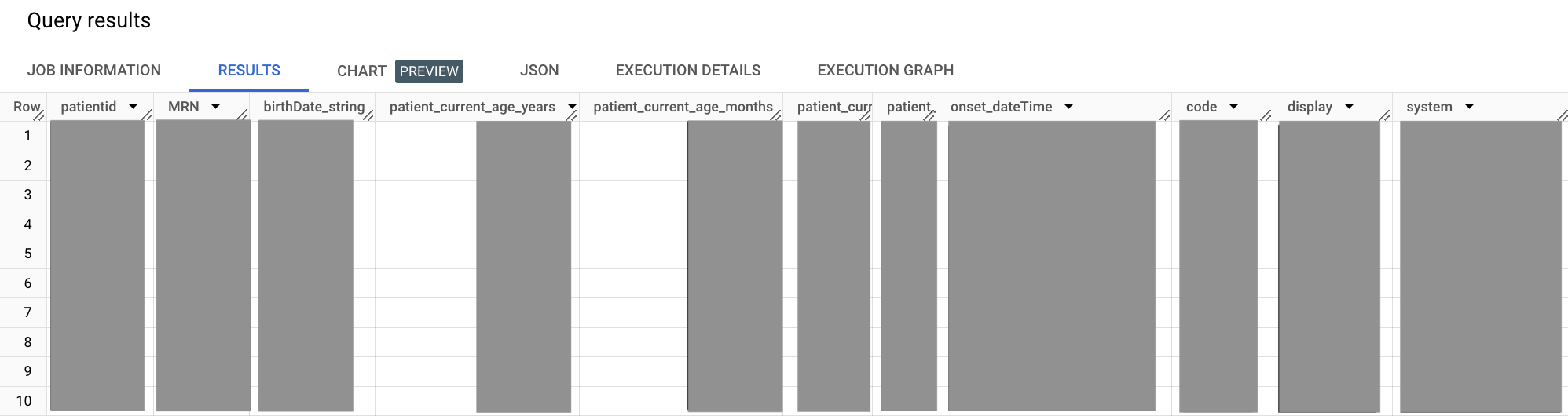
앞의 샘플 쿼리에서 WITH 절을 사용하면 하위 쿼리를 자체 정의한 세그먼트로 격리할 수 있습니다. 이 방식은 가독성을 높일 수 있으므로 쿼리가 커질수록 더욱 중요해집니다. 이 쿼리에서는 환자 및 조건에 대한 하위 쿼리를 자체 WITH 세그먼트로 격리한 후 기본 SELECT 세그먼트에 조인합니다.
원시 데이터에 계산을 적용할 수도 있습니다. 다음 샘플 코드인 SELECT 문은 발병한 환자 연령을 계산하는 방법을 보여줍니다.
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
앞의 코드 샘플에 표시된 대로 제공된 dateTime 문자열인 condition.onset_dateTime에서 여러 작업을 수행할 수 있습니다. 먼저 문자열의 날짜 구성요소를 SUBSTR 값으로 선택합니다. 그런 다음 CAST 구문을 사용하여 문자열을 DATE 데이터 유형으로 변환합니다. 또한 patient.birthDate 필드를 DATE 필드로 변환합니다.
마지막으로 DATE_DIFF 함수를 사용하여 두 날짜 간의 차이를 계산합니다.
다음 단계
- BigQuery 및 AI Platform Notebooks를 사용하여 임상 데이터 분석
- Jupyter 메모장에서 BigQuery 데이터 시각화
- Cloud Healthcare API 보안
- BigQuery 액세스 제어
- Google Cloud Marketplace의 의료 및 생명과학 솔루션
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보기