本页面引用了 derived_table 中的
persist_for参数。
persist_for也可以用作探索的一部分,如persist_for(适用于探索)参数文档页面所述。
persist_for也可用作模型的一部分,如persist_for(适用于模型)参数文档页面所述。
用量
derived_table:{
persist_for: “24 小时”
...
}
}
|
层次结构
persist_for |
默认值
无接受
包含整数,后跟时间范围(秒、分钟或小时)的字符串
|
定义
您可以考虑改用
datagroup和datagroup_trigger(如此页面的缓存所述)。
persist_for 可让您设置在重新生成永久性派生表之前可以使用的最长时间。当用户运行依赖于 persist_for 派生表的查询时,Looker 会根据 persist_for 检查该表的存在时间。如果存在时间超出 persist_for 设置,系统会在运行查询之前重新生成派生表。如果存在时间少于 persist_for 设置,则使用现有的派生表。
PDT 的 persist_for 独立于模型和探索的 persist_for 参数运行。
如果管理员向您授予了 develop 权限,您可以强制派生表,使其在达到 persist_for 个使用时间之前重新生成。运行查询后,从屏幕右上角显示的下拉菜单中选择重建派生表格与运行选项:
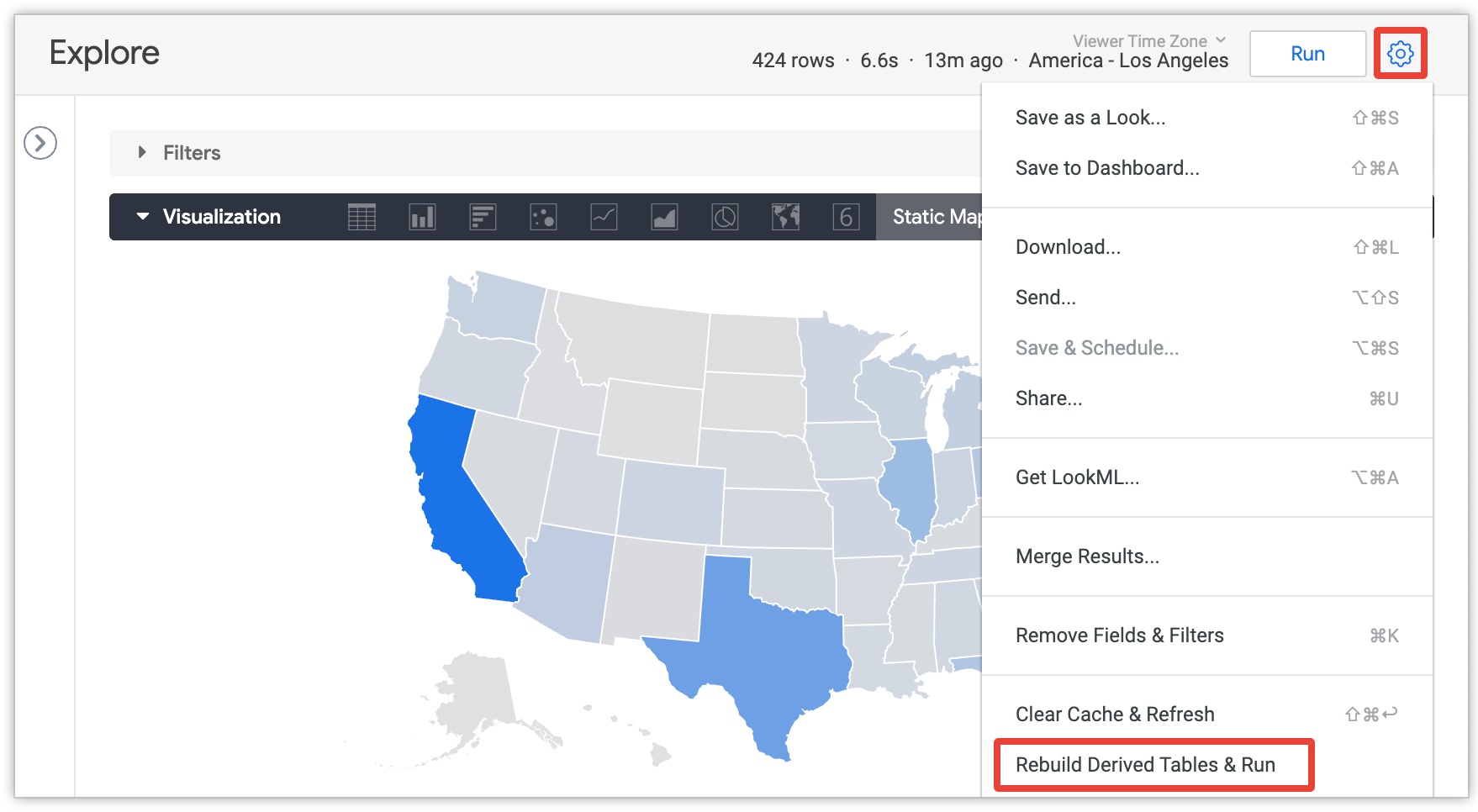
如需详细了解重新构建派生表和运行选项,请参阅 Looker 中的派生表文档页面。
示例
派生派生表(如果其存在时间超过 1 小时)
persist_for: "1 hour"
重新生成派生表(如果其存在时间超过 1.5 小时)
persist_for: "90 minutes"
重新生成派生时间超过 1 天的表格
persist_for: "24 hours"
注意事项
persist_for 要求您启用永久性派生表
除非您在 Looker 实例上为派生表启用了持久化,否则 persist_for 不会产生任何影响。大多数客户在最初配置 Looker 时也会设置永久性派生表。此规则最常见的例外情况是将 Looker 连接到 PostgreSQL 只读热交换副本数据库的客户。
persist_for 在开发模式和生产模式下的工作原理有所不同
在正式版模式下,persist_for 应按预期运行。在开发模式下,即使您将 persist_for 设置为更长的值,所有派生表也会保留最多 24 小时。
如需了解详情,请参阅在 Looker 中派生表文档页面的在开发模式下保留的表部分。
persist_for 的替代方案
persist_for 时间范围到期后,Looker 不会自动重新生成新的派生表。而是会丢弃该表,并在用户下次查询时生成新的派生表。您可以使用 sql_trigger_value 安排自动生成派生表,而无需等待用户查询触发生成派生表。
datagroup 和 max_cache_age 之间的区别
将 datagroup 参数与 datagroup_trigger 参数搭配使用可让您更灵活地触发 PDT 重新构建。不过,max_cache_age 参数只会使缓存失效,不会导致 PDT 过期。如果您希望在从暂存架构中移除 PDT 之前设置最长时间段,请使用 persist_for 及其派生表。