通过预测功能,分析师可以快速向新的或现有的“探索”查询添加数据预测,以帮助用户预测和监控特定的数据点。可以将预测的探索结果和可视化内容添加到信息中心并另存为外观。您还可以在嵌入式 Looker 内容中创建和查看预测结果和可视化内容。
如果您拥有创建预测的权限,则可以预测数据。
预测结果的显示方式和显示方式
预测功能使用“探索”数据表格中的数据结果来计算未来的数据点。预测结果仅包括“探索”查询的显示结果;任何因行数限制而未显示的结果均不包括在内。如需详细了解用于计算预测结果的算法,请参阅本页面中的 ARIMA 算法部分。
预测结果显示为现有“探索”可视化图表的延续,且受配置的可视化设置的约束。预测数据点与非预测数据点的不同之处体现在以下几个方面:

- 在受支持的笛卡尔图表中,预测数据点与非预测数据点之间的差异是,以较浅的阴影或虚线呈现。
- 在支持的文字和表格图表类型中,预测数据点会以斜体显示,并标有星号。
当您将光标悬停在预测的数据点上时,系统在显示的提示中也会明确指明预测的数据:
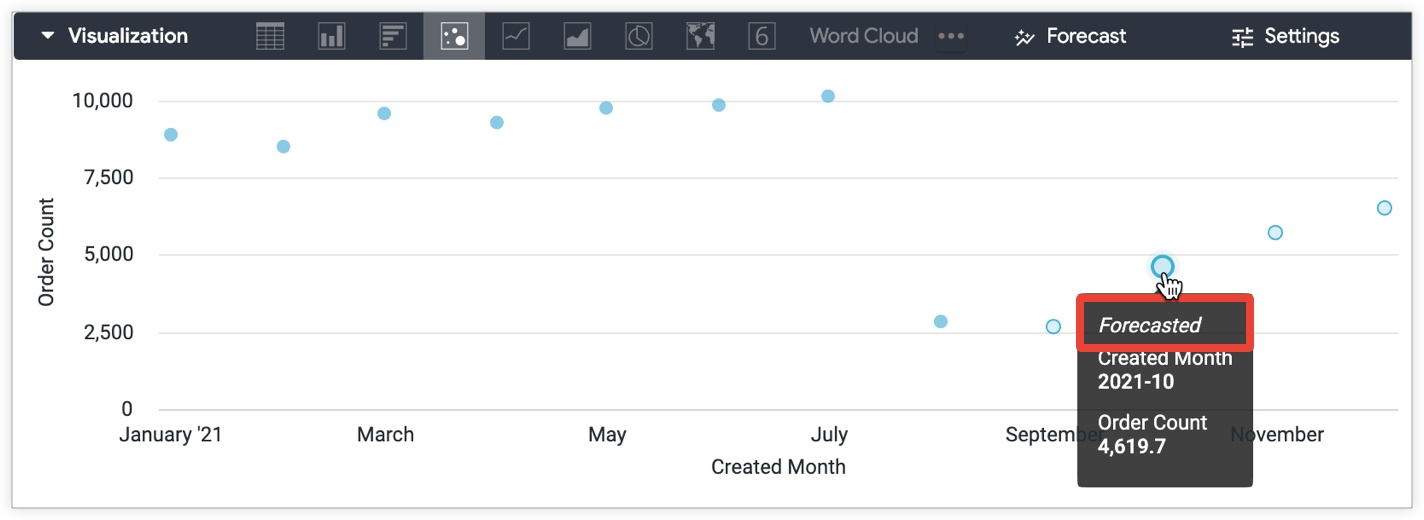
只有特定类型的可视化图表支持预测数据,如下一部分所述。
ARIMA 算法
预测利用自动回归综合移动平均 (ARIMA) 算法来创建与输入的数据最相符的等式。为了找到数据的最佳匹配,Looker 会使用一组初始变量运行 ARIMA,创建初始变量的变体列表,然后使用这些变体再次运行 ARIMA。如有任何变体创建了更适合输入数据的等式,Looker 会将这些变体用作新的初始变量,然后创建其他变体,然后对其进行评估。Looker 不断重复此过程,直到确定最佳变量,或者直到所有选项或分配的计算时间都用尽为止。
此过程可以视为一种遗传算法,数百代的个体之间各有 1 到 10 个子代(基于父代的变量变体),最好的后代能够继续创造“更好”的世代。Looker 在遗传算法方法中使用许多 ARIMA 调用的方式称为 AutoARIMA。
如需详细了解 AutoARIMA,请参阅 pmdarima 用户指南中的 auto_arima 使用提示部分。虽然这不是 Looker 运行 AutoARIMA 所用的库,但 pmdarima 能够最好地解释该过程以及使用的不同变量。
支持的可视化类型
其他可视化类型(包括自定义可视化图表)目前无法呈现预测数据。
探索用于预测的查询要求
要创建预测,探索必须满足以下要求:
注意事项
在创建新的“探索”查询以进行预测或向现有“探索”查询添加预测时,请考虑以下额外条件:
- 数据透视 - 可以对数据透视探索执行预测,只要满足上述要求即可。
- 行总计和小计 - 行总计和小计不包含预测值;我们不建议在预测中使用小计或行总计,因为这样可能会产生意外的数字。
- 包含不完整时间范围的过滤条件 - 为准确进行预测,当探索包含不完整时间范围的数据时,只能将预测与探索过滤条件中的完整时间范围逻辑结合使用。例如,如果用户在“探索”功能中仅显示过去三个月的数据,但探索了某个月份的数据,则“探索”功能会包含当前不完整月份的数据。预测结果会将不完整的数据纳入计算,并显示更不可靠的结果。但是,如果“探索”包含不完整的时间范围(例如,“探索”包含当月的不完整数据),请使用“过去 3 个完整月份”等过滤逻辑(而非“过去 3 个月”),以确保更准确地进行预测。
- 表格计算 - 基于一项或多项预测指标的表格计算将自动纳入到预测范围内。
- 行数上限 - 了解行数上限如何应用于整个数据表(包括预测行)。
如需更多提示和问题排查资源,请参阅本页面上的常见问题和须知事项部分。
通常,数据集越多,行数越短,预测长度也越短,预测结果越准确。
“预测”菜单选项
您可以使用预测菜单(位于“探索”可视化标签页上)中的选项来自定义预测数据。预测菜单包含以下选项:
选择字段
选择字段下拉菜单会显示“探索”查询中可用于预测的指标或自定义衡量指标。最多可选择 5 种衡量方式或自定义衡量方式。
时长
长度选项用于指明要预测数据值的行数或时长。系统会根据“探索”查询中的时间范围维度自动填充预测时长区间。
通常,数据集越多,行越多,预测长度越短,预测结果越准确。
预测区间
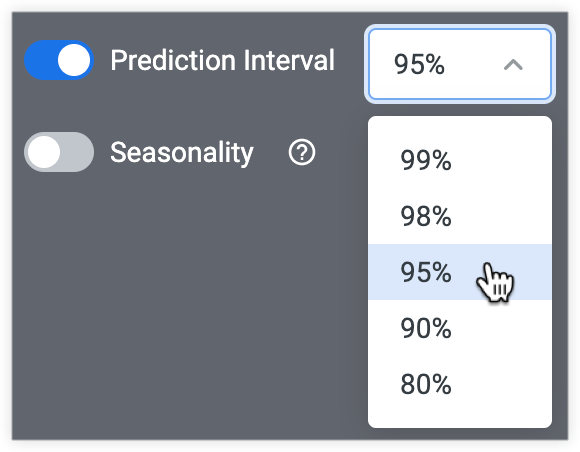
利用预测区间选项,分析师能够做出一些不确定性,以帮助提高预测准确性。启用后,预测区间选项可让您选择预测数据值的边界。例如,95% 的预测区间表示 95% 的预测衡量值落在预测上限和下限之间。
所选预测区间越大,上限和下限就越大。
季节性变化
借助季节性变化选项,分析师会考虑预测中已知的周期或重复数据趋势,并参考该周期中的行数。例如,如果“探索”数据表格每小时有一行数据,并且每天的数据周期都是循环的,那么季节性趋势就是 24。
使用默认的预测设置时,Looker 会参考“探索”中的日期维度并扫描几个可能的季节性周期,以找到与最终预测结果最相符的结果。例如,使用每小时数据时,Looker 可能会尝试每天、每周和四周的季节性周期。Looker 还会考虑该维度的频率 - 如果某个维度代表的时间段为六小时,那么 Looker 就会知道每天只会有四行内容,因此会相应地调整季节性因素。
对于常见用例,自动选项会检测给定数据集的最佳季节性变化。如果您知道数据集中的特定周期,可以使用自定义选项指定组成预测中单个指标的循环的行数。
为多个衡量指标预测数据值时,您可以为每个衡量指标选择不同的季节性选项(包括无)。季节性变化下拉菜单有以下几个选项:
默认情况下,即使未启用季节性选项,预测功能也会将自动季节性趋势选项应用于预测。
自动
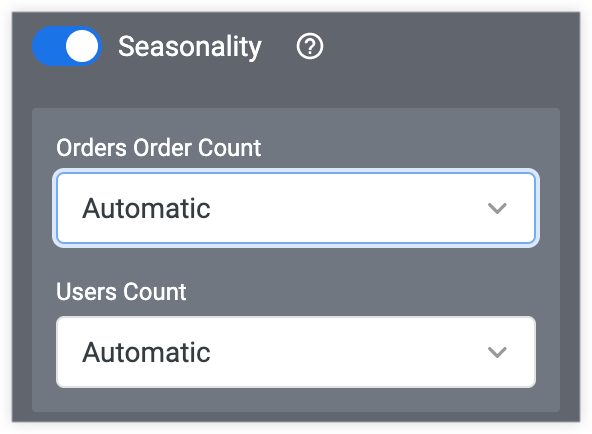
选择自动季节性选项后,Looker 会从多个常见的季节性时段(例如每天、每小时、每月等)中为您的数据选择最佳选项。
自定义

如果您知道数据集中的每个季节或周期构成的具体行数,您可以在时间段字段中指定具体数字。如果您知道数据会在特定的行数内循环,请选择自定义可能会有所帮助。
如果您处理的是周期为数月但更细致的数据(例如,在“探索”中使用日期或周粒度),则周期通常为 4 周或 30 天。
无
季节性变化是预测的强有力组成部分;不过,有时并非建议这样做,具体取决于输入数据。如果数据中没有可预测的循环,则启用季节性因素有时可能会导致不准确的预测,因为算法会尝试查找某种模式,然后尝试在预测结果中应用假模式。这可能会导致预测不够明确。

在为多个衡量指标预测数据值时,如果您希望仅为一个或几个指标启用季节性变化,可以为不启用季节性变化的所有衡量指标选择无。
创建预测
只有拥有权限的用户才能创建预测。
要创建预测,请执行以下操作:
确保您的“探索”页面满足预测要求。例如,“探索”查询包含“用户创建的月份”、“用户数”和“订单数”,并且按“用户创建月份”降序排列:

选择“探索”可视化图表标签页中的预测,打开预测菜单。
选择选择字段下拉菜单以选择最多 5 个衡量指标或要预测的自定义衡量指标。
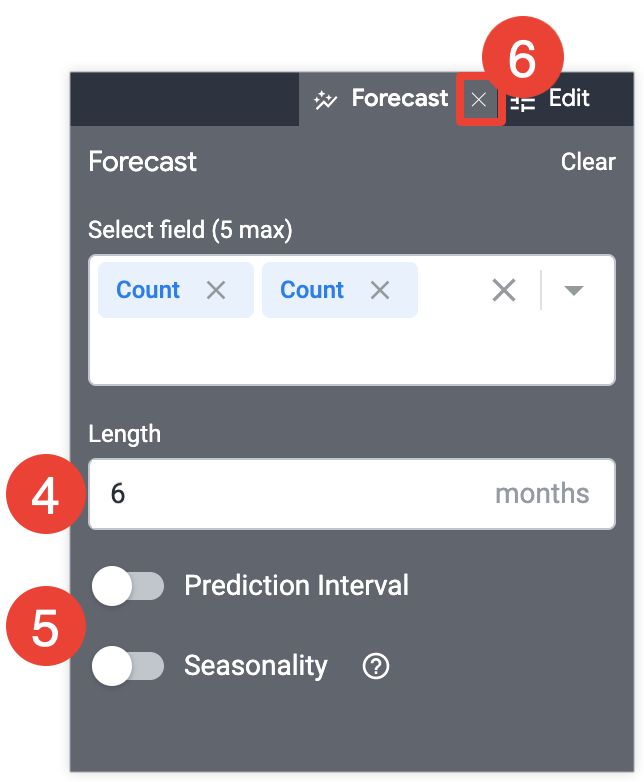
在 Length 字段中,输入您希望预测的未来时长。
在菜单标签页中选择预测旁边的 x,以保存您的设置并退出菜单。
选择运行以重新运行“探索”查询。(在对预测结果进行任何更改后,您必须重新运行“探索”。)
探索结果和可视化图表现在会显示指定时间段内的预测值。示例“探索”现在会显示“用户数”和“订单数”在 2020 年 1 月 1 日至 2020 年 6 月 6 日期间的预测数据:

由于预测的计算取决于数据排序的顺序,因此一旦运行了预测查询,排序便会停用。
修改预测数据
只有拥有权限的用户才能修改预测。
要修改预测,请执行以下操作:
(可选)酌情修改“探索”查询,以添加或移除不同的衡量指标或时间范围字段。确保您的“探索”页面满足预测要求。
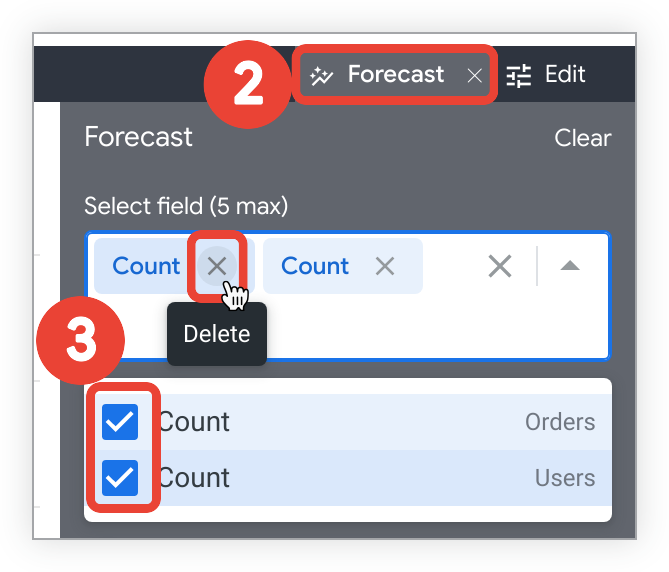
选择“探索”可视化图表标签页中的预测,打开预测菜单。
选择选择字段下拉菜单以更改预测字段。如需移除预测字段,请执行以下操作:
- 在展开的选择字段下拉菜单中,选中预测字段旁边的复选框,从预测中移除这些字段。
- 或者,在收起的选择字段菜单中,选择字段名称旁边的 x。
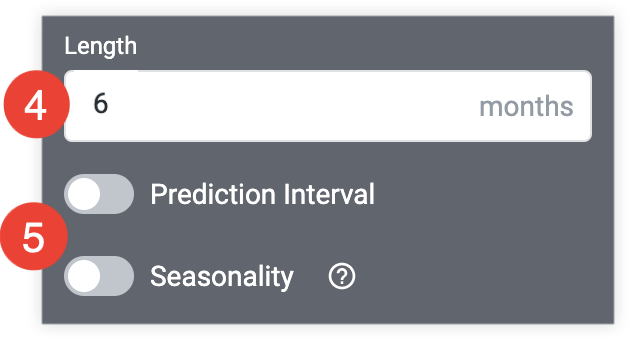
根据需要修改时长字段中未来指定的时长,以进行预测。
选择预测区间或季节性变化开关,以启用每个函数并自定义关联的选项。
- 如果已启用预测间隔或季节性变化,系统就会显示自定义设置。根据需要修改自定义设置,或者选择相应开关以从预测中移除相应函数。
在菜单标签页中选择预测旁边的 x,以保存您的设置并退出菜单。
选择运行以重新运行“探索”查询。(对预测数据进行任何更改后,必须重新运行“探索”。)
“探索”结果和可视化图表现在会显示修改后的预测数据。由于预测的计算取决于数据排序的顺序,因此一旦运行了预测查询,排序便会停用。
移除预测
只有拥有权限的用户才能移除预测数据。
要从探索中移除预测数据,请执行以下操作:
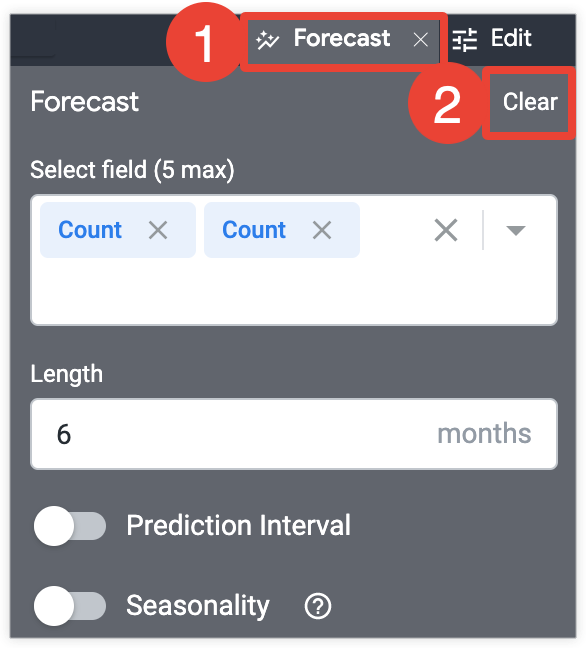
- 选择“探索”可视化图表标签页中的预测,打开预测菜单。
- 选择清除。
系统会自动重新运行查询以生成未应用预测的结果。
常见问题和须知事项
准确度如何?
预测的准确性取决于输入数据。Looker 的 AutoARIMA 实现可以做出极为准确的预测,从而成功合并输入数据中的许多细微差别。还有一些情况是该算法在输入数据中被奇怪的模式捕获,并在预测中强调它们。确保提供足够的数据且数据尽可能准确,以便充分利用预测功能。
无法生成预测结果
无法进行预测是有正当理由的。这通常与输入数据量过少或请求的预测长度过大有关。上述任一因素均无具体限制,并且在一定长度的预测中,没有所需输入数据的精确比率。输入数据越分散且不可预测,AutoARIMA 算法就越难找到匹配项。生成预测的最有效方式是增加干净的输入数据量,确保季节性设置正确无误,并将预测长度缩短为仅需要的值。使用预测区间选项时,选择较低的时间间隔可能会有所帮助。
清理输入数据可能包括:
- 去除没有数据的时间段的前导或尾随行
- 通过选择较大的日期维度来减少数据集中的噪声
- 更改对预测结果没有帮助的过滤条件离群值
查询结果没有预测结果,我收到了一个模糊错误
应该不会发生这种情况。如果是,请尝试从预测配置中移除一个或多个指标,然后重新添加。
预测结果已经显示,但明显有误或没有帮助
在这种情况下,最佳的做法是添加更多输入数据,尽可能进行清理,并可能设置自定义的季节性变化(如果您知道数据的特定周期),或者选择 None 以完全停用季节性选项。
清理输入数据可能涉及以下任务:
- 去除没有数据的时间段的前导或尾随行
- 通过选择较大的日期维度来减少数据集中的噪声
- 更改对预测结果没有帮助的过滤条件离群值