Looker reduce la carga en su base de datos y mejora el rendimiento mediante el uso de resultados en caché de consultas anteriores cuando está disponible y lo permite su política de almacenamiento en caché. Además, puede crear consultas complejas como tablas derivadas persistentes (PDT), que almacenan sus resultados para simplificar las consultas posteriores.
Los grupos de datos son muy útiles para coordinar la programación de ETL (extracción, transformación y carga) de tu base de datos con la política de almacenamiento en caché y el programa de recompilación de PDT. Puedes usar un grupo de datos a fin de especificar el activador de recompilación para PDT en función de cuándo se agregan datos nuevos a tu base de datos. En el mismo grupo de datos, puedes especificar una antigüedad máxima de la caché para que las consultas de Explorar funcionen como un sistema a prueba de errores en caso de que, por algún motivo, no se active la recompilación de PDT. De esa manera, el modo de falla de un grupo de datos será consultar la base de datos en lugar de entregar datos obsoletos de la caché de Looker.
Como alternativa, puedes usar un grupo de datos para separar el activador de recompilación de PDT de la antigüedad máxima de la caché. Esto puede ser útil si tienes un objeto Explorar basado en datos que se actualiza con mucha frecuencia y que se une a un PDT que se vuelve a compilar con menos frecuencia. En este caso, es recomendable que la caché de consultas se restablezca con mayor frecuencia que si se volviera a compilar el PDT.
Para obtener detalles sobre el almacenamiento en caché de las consultas, revisa la sección Cómo Looker usa las consultas almacenadas en caché en esta página de documentación.
Define un grupo de datos
Un grupo de datos se define con el parámetro datagroup, ya sea en un archivo de modelo o en su propio archivo LookML. Puede definir varios grupos de datos si desea diferentes políticas de almacenamiento en caché y recompilación de PDT para diferentes exploraciones o PDT en su proyecto.
El parámetro datagroup puede tener los siguientes subparámetros:
label: Especifica una etiqueta opcional para el grupo de datos.description: especifica una descripción opcional del grupo de datos que se puede usar para explicar el propósito y el mecanismo del grupo de datos.max_cache_age: Especifica una string que define un período. Cuando la antigüedad de la caché de una consulta supera el período, Looker la invalida. La próxima vez que se emita la consulta, Looker la enviará a la base de datos para obtener resultados actualizados.interval_trigger: Especifica un programa para activar el grupo de datos, como"24 hours".
Consulta la página de documentación de datagroup para obtener más información sobre estos parámetros.
Como mínimo, un grupo de datos debe tener los parámetros max_cache_age, sql_trigger o interval_trigger.
Un grupo de datos no puede tener los parámetros
sql_triggeryinterval_trigger. Si defines un grupo de datos con ambos parámetros, el grupo de datos usará el valorinterval_triggery omitirá el valorsql_trigger, ya que el parámetrosql_triggerrequiere que Looker use recursos de base de datos cuando consulte la base de datos.
Este es un ejemplo de un grupo de datos que tiene un sql_trigger configurado para volver a compilar el PDT todos los días. Además, max_cache_age se configura para borrar la caché de consultas cada dos horas, en caso de que Explorar explore una una unión con PDT a otros datos que se actualicen con más frecuencia que una vez al día.
datagroup: customers_datagroup {
sql_trigger: SELECT DATE(NOW());;
max_cache_age: "2 hours"
}
Una vez que defina el grupo de datos, podrá asignarlo a Explorar y PDT:
- Para asignar el grupo de datos a un PDT, usa el parámetro
datagroup_triggeren el parámetroderived_table. Consulta la sección Usa un grupo de datos a fin de especificar un activador de recompilación para PDT en esta página a fin de obtener un ejemplo. - Para asignar el grupo de datos a Explorar, usa el parámetro
persist_witha nivel del modelo o al nivel Explorar. Si desea ver un ejemplo, consulte la sección Cómo usar un grupo de datos para especificar el restablecimiento de la caché de consultas para Explorar en esta página.
Usa un grupo de datos a fin de especificar un activador de recompilación para PDT
Para definir un activador de recompilación de PDT mediante grupos de datos, crea un parámetro datagroup con los subparámetros sql_trigger o interval_trigger. Luego, asigna el grupo de datos a PDT individuales con el subparámetro datagroup_trigger en la definición derived_table de PDT. Si usas datagroup_trigger para tu PDT, no necesitas especificar ninguna otra estrategia de persistencia para la tabla derivada. Si especificas varias estrategias de persistencia para un PDT, recibirás una advertencia en el IDE de Looker y solo se usará datagroup_trigger.
Aquí tienes un ejemplo de una definición de PDT que usa el grupo de datos customers_datagroup. Esta definición también agrega varios índices, tanto en customer_id como en first_order_date. Para obtener más información sobre la definición de PDT, consulta la página de documentación Tablas derivadas en Looker.
view: customer_order_facts {
derived_table: {
sql: ... ;;
datagroup_trigger: customers_datagroup
indexes: ["customer_id", "first_order_date"]
}
}
Si tiene PDT en cascada, PDT que dependen de otros PDT, tenga cuidado de no especificar políticas de almacenamiento en caché de grupos de datos incompatibles.
En el caso de las conexiones que tienen atributos de usuario para especificar los parámetros de conexión, debes crear una conexión independiente con los campos de anulación de PDT si deseas realizar alguna de las siguientes acciones:
• Usar PDT en tu modelo
• Usar un grupo de datos a fin de definir un activador de recompilación de PDT
Sin las anulaciones de PDT, puedes usar un grupo de datos conmax_cache_agea fin de definir la política de almacenamiento en caché para Explorar
Consulta la página de documentación Tablas derivadas en Looker para obtener más información sobre cómo funcionan los grupos de datos con los PDT.
Usa un grupo de datos a fin de especificar el restablecimiento de la caché de consultas para Explorar
Cuando se activa un grupo de datos, el regenerador de Looker vuelve a compilar los PDT que usan ese grupo de datos como estrategia de persistencia. Una vez que se vuelvan a compilar los PDT del grupo de datos, Looker borrará la caché de las exploraciones que usen los PDT recompilados del grupo de datos. Puedes agregar el parámetro max_cache_age a la definición de tu grupo de datos si deseas personalizar un programa de restablecimiento de caché de consultas para el grupo de datos. El parámetro max_cache_age te permite borrar la caché de consultas según un programa específico, además del restablecimiento automático de la caché de consultas que realiza Looker cuando se vuelven a compilar los PDT del grupo de datos.
Para definir una política de almacenamiento en caché de consultas con grupos de datos, crea un parámetro datagroup con el subparámetro max_cache_age.
A fin de especificar un grupo de datos que se usará para restablecer la caché de consultas en Explorar, use el parámetro persist_with:
- Para asignar el grupo de datos como predeterminado para todas las exploraciones en un modelo, usa el parámetro
persist_witha nivel del modelo (en un archivo de modelo). - Para asignar el grupo de datos a Exploraciones individuales, usa el parámetro
persist_withen un parámetroexplore.
En los siguientes ejemplos, se muestra un grupo de datos llamado orders_datagroup que se define en un archivo de modelo. El grupo de datos tiene un parámetro sql_trigger, que especifica que la consulta select max(id) from my_tablename se usará para detectar un ETL. Incluso si ese ETL no sucede durante un tiempo, el max_cache_age del grupo de datos especifica que los datos almacenados en caché se usarán solo durante un máximo de 24 horas.
El parámetro persist_with del modelo apunta a la política de almacenamiento en caché orders_datagroup, lo que significa que esta será la política de almacenamiento en caché predeterminada para todas las exploraciones del modelo. Sin embargo, no queremos usar la política de almacenamiento en caché predeterminada del modelo para las exploraciones customer_facts y customer_background, por lo que podemos agregar el parámetro persist_with a fin de especificar una política de almacenamiento en caché diferente para estas dos exploraciones. Las exploraciones orders y orders_facts no tienen un parámetro persist_with, por lo que usarán la política de almacenamiento en caché predeterminada del modelo: orders_datagroup.
datagroup: orders_datagroup {
sql_trigger: SELECT max(id) FROM my_tablename ;;
max_cache_age: "24 hours"
}
datagroup: customers_datagroup {
sql_trigger: SELECT max(id) FROM my_other_tablename ;;
}
persist_with: orders_datagroup
explore: orders { ... }
explore: order_facts { ... }
explore: customer_facts {
persist_with: customers_datagroup
...
}
explore: customer_background {
persist_with: customers_datagroup
...
}
Si se especifican persist_with y persist_for, recibirás una advertencia de validación y se usará persist_with.
Usa un grupo de datos para activar las entregas programadas
Los grupos de datos también se pueden usar para activar la entrega de un panel, un panel heredado o un diseño. Con esta opción, Looker enviará sus datos cuando se complete el grupo de datos, de modo que el contenido programado esté actualizado.
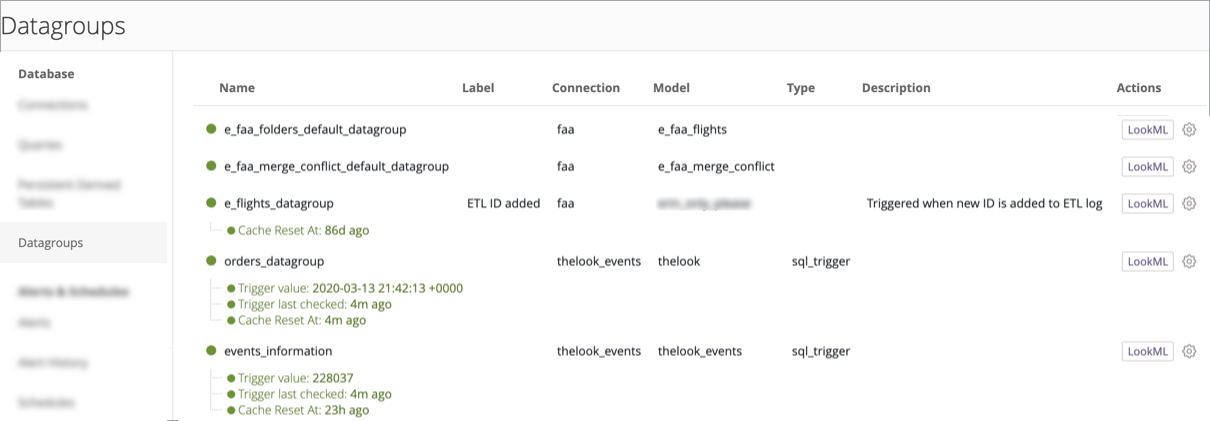
Usar el panel Administrador para grupos de datos
Si tienes la función de administrador de Looker, puedes usar la página Grupos de datos del panel Administrador para ver los grupos de datos existentes. Puede ver la conexión, el modelo y el estado actual de cada grupo de datos y, si se especifica en LookML, una etiqueta y una descripción para cada grupo de datos. También puedes restablecer la caché de un grupo de datos, activar el grupo de datos o navegar al LookML del grupo de datos.
Cómo Looker usa consultas almacenadas en caché
Para las consultas, el mecanismo de almacenamiento en caché en Looker funciona de la siguiente manera:
- Cuando un usuario ejecuta una consulta específica, el resultado de esa consulta se almacena en caché. Los resultados de caché se almacenan en un archivo encriptado en tu instancia de Looker.
Cuando se escribe una consulta nueva, se verifica la caché para ver si la consulta exacta ya se ejecutó. Todos los campos, filtros y parámetros deben ser iguales, incluidas las opciones de configuración, como los límites de filas. Si no se encuentra la consulta, Looker la ejecuta en la base de datos para obtener resultados actualizados (y esos resultados se almacenan en caché).
Los comentarios de contexto no afectan el almacenamiento en caché. Looker agrega un comentario único al comienzo de cada consulta de SQL. Sin embargo, mientras la consulta en SQL sea la misma que en una consulta anterior (sin incluir los comentarios de contexto), Looker usará los resultados almacenados en caché.
Si la consulta se encuentra en la caché, Looker verifica la política de almacenamiento en caché definida en el modelo para ver si la caché aún es válida. De forma predeterminada, Looker invalida los resultados almacenados en caché después de una hora. Puedes usar un parámetro
persist_for(a nivel del modelo o Explorar) o el parámetrodatagroupmás potente para especificar la política de almacenamiento en caché que determina las circunstancias en las que los resultados almacenados en caché no son válidos y deben ignorarse. Un administrador también puede invalidar los resultados almacenados en caché de un grupo de datos.- Si la caché aún es válida, se utilizan esos resultados.
- Si la caché ya no es válida, Looker ejecuta la consulta en la base de datos para obtener resultados actualizados. (Esos nuevos resultados también se almacenan en caché).
Consulta si una consulta se mostró desde la caché
En una ventana Explorar, puede determinar si una consulta se mostró desde la caché en la esquina superior derecha después de ejecutar una consulta.
Cuando se muestra una consulta desde la caché, se muestra “desde la caché”. De lo contrario, se muestra la cantidad de tiempo para mostrar la consulta.

Obliga a que se generen resultados nuevos a partir de la base de datos
En una ventana Explorar, puedes forzar la recuperación de los resultados nuevos de la base de datos. Selecciona la opción Clear Cache & Refresh del menú de ajustes, que encontrarás en la esquina superior derecha de la pantalla después de ejecutar una consulta (incluidas las de resultados combinados):
![]()
Por lo general, una tabla derivada persistente se regenera en función de la estrategia de persistencia del PDT. Puedes forzar la recompilación de la tabla derivada con anticipación si tu administrador te otorgó el permiso develop y estás viendo una exploración que incluye campos del PDT. Selecciona la opción Rebuild Derived Tables & Run en el menú desplegable de ajustes, que encontrarás en la esquina superior derecha de la pantalla después de ejecutar una consulta:
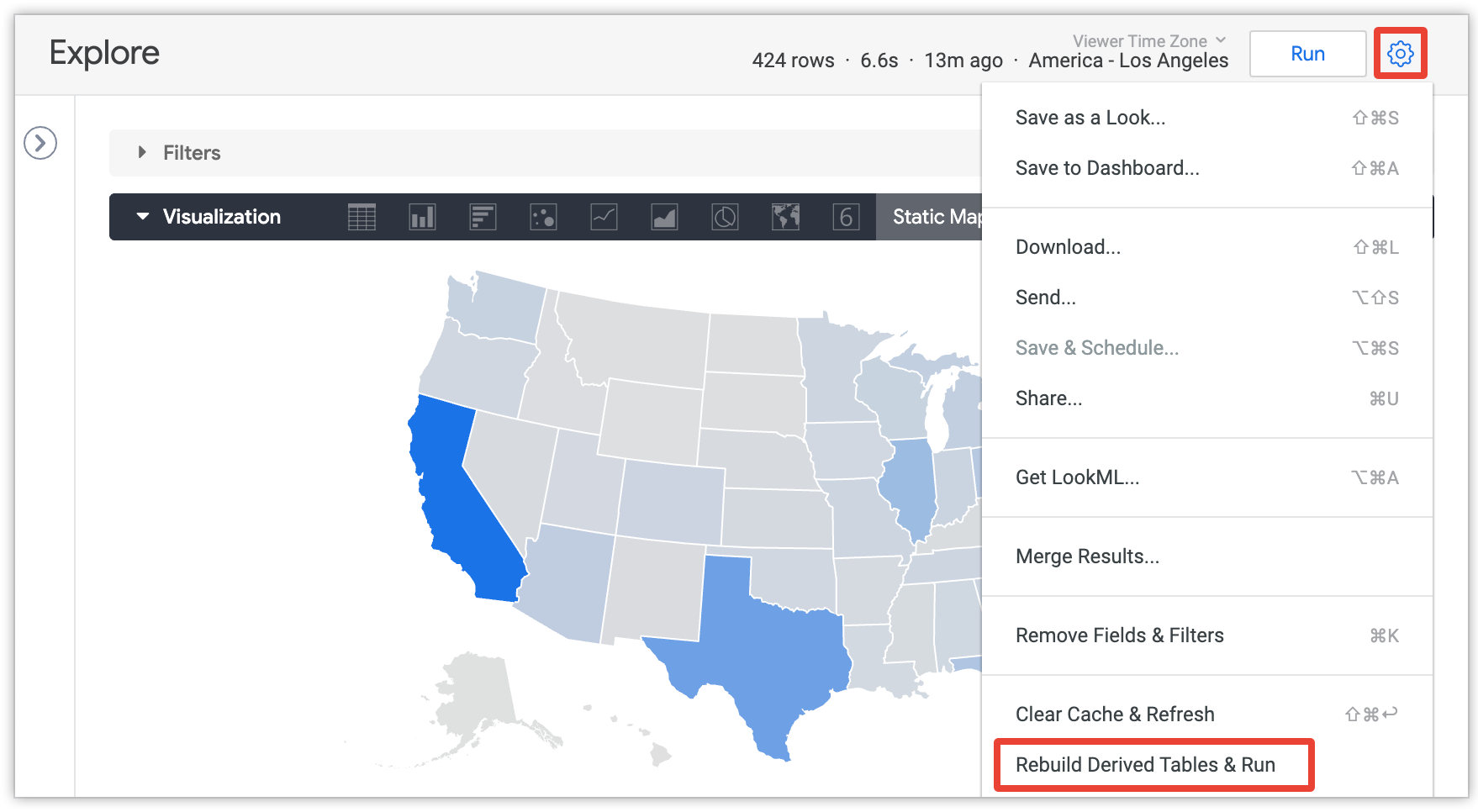
Consulta la página de documentación Tablas derivadas en Looker para obtener más detalles sobre la opción Volver a compilar tablas derivadas y ejecutar.
¿Cuánto tiempo se almacenan los datos en la caché?
Para especificar la cantidad de tiempo antes de que los resultados almacenados en caché dejen de ser válidos, usa el parámetro persist_for (para un modelo o para Explorar) o el parámetro max_cache_age (para un grupo de datos). Estos son los diferentes comportamientos que se muestran en el cronograma, según si caducó la hora de persist_for o max_cache_age:
- Antes de que venza el tiempo de
persist_foromax_cache_age: Si se vuelve a ejecutar la consulta, Looker extrae datos de la caché. - Cuando vence el tiempo de
persist_foromax_cache_age, Looker borra los datos de la caché, a menos que hayas habilitado la función de Paneles de control instantáneos Looker Labs. - Una vez transcurrido el tiempo de
persist_foromax_cache_age, si se vuelve a ejecutar la consulta, Looker extrae los datos de la base de datos directamente y restablece el temporizador depersist_foromax_cache_age.
Un punto clave aquí es que los datos se borran de la caché cuando caducan las horas persist_for o max_cache_age, siempre que la función de paneles instantáneos de Looker Labs esté inhabilitada. (La función Paneles instantáneos requiere el almacenamiento en caché para cargar los resultados almacenados en caché de inmediato en un panel). Si habilitas los Paneles instantáneos, los datos permanecerán en la caché durante 30 días o hasta que se alcancen los límites de almacenamiento en caché. Si la caché alcanza el límite de almacenamiento, los datos se expulsan según un algoritmo de uso reciente (LRU), sin ninguna garantía de que los datos con temporizadores persist_for o max_cache_age vencidos se borren de una vez.
Minimiza el tiempo que los datos pasan en la caché
Looker requiere la caché de disco para los procesos internos, por lo que los datos siempre se escribirán en la caché, incluso si estableces los parámetros persist_for y max_cache_age en 0. Una vez que se escriban en la caché, los datos se marcarán para su eliminación, pero podrían permanecer hasta 10 minutos en el disco.
Sin embargo, todos los datos de clientes que aparecen en la caché de disco están encriptados por el Estándar de encriptación avanzada (AES), y puede minimizar la cantidad de tiempo que estos se almacenan en la caché si realiza los siguientes cambios:
- Inhabilita la función Looker Labs de los paneles instantáneos, que requiere que Looker almacene datos en caché.
- En cualquier parámetro
persist_for(para un modelo o Explorar) omax_cache_age(para un grupo de datos), establece el valor en 0. Para las instancias de Looker con los paneles instantáneos desactivados, Looker borra la caché cuando vence el tiempo depersist_foro cuando los datos alcanzan elmax_cache_ageespecificado en su grupo de datos. (Esto no es necesario para el parámetropersist_forde las tablas derivadas persistentes, ya que las tablas derivadas persistentes se escriben en la base de datos y no en la caché). - Establece el parámetro
suggest_persist_foren una cantidad de tiempo pequeña. El valorsuggest_persist_forespecifica por cuánto tiempo Looker debe conservar las sugerencias de filtros en la caché. Las sugerencias de filtro se basan en una consulta de los valores del campo que se filtra. Estos resultados de consulta se guardan en la caché para que Looker pueda proporcionar sugerencias rápidamente a medida que el usuario escribe en el campo de texto de filtro. El valor predeterminado es almacenar en caché las sugerencias de filtros durante 6 horas. Para minimizar la cantidad de tiempo que tus datos están en la caché, establece el valorsuggest_persist_foren un valor más bajo, como 5 minutos.