En este tema, se muestra cómo medir el k-anonimato de un conjunto de datos mediante la protección de datos sensibles y visualizarlo en Looker Studio. Esto permite comprender mejor el riesgo y evaluar las concesiones de utilidad que puedes estar haciendo si ocultas o desidentificas datos.
Si bien el enfoque de este tema es sobre la visualización de la métrica del análisis de riesgos de reidentificación k-anonimato, también puedes visualizar l-diversidad mediante los mismos métodos.
En este tema, suponemos que ya estás familiarizado con el concepto de k-anonimato y su utilidad para evaluar la capacidad de reidentificación de los registros dentro de un conjunto de datos. También será útil estar familiarizado con cómo procesar el k-anonimato con la protección de datos sensibles y con Looker Studio.
Introducción
Las técnicas de desidentificación pueden resultar útiles para resguardar la privacidad de los sujetos mientras se usan o procesan los datos. Sin embargo, ¿cómo saber si un conjunto de datos se desidentificó lo suficiente? ¿Y cómo determinar si la desidentificación generó una pérdida de datos muy grande para el caso de uso? Es decir, ¿cómo se puede comparar el riesgo de desidentificación con la utilidad de los datos para tomar decisiones basadas en estos?
Para resolver estas dudas, resulta útil calcular el valor del k-anonimato de un conjunto de datos, ya que se evalúa la capacidad de reidentificación de sus registros. La protección de datos sensibles contiene una funcionalidad integrada para calcular el valor del k-anonimato de un conjunto de datos según los cuasidentificadores que especifiques. Así se puede evaluar rápidamente si la desidentificación de cierta columna, o combinación de columnas, generará un conjunto de datos más o menos apto para la reidentificación.
Conjunto de datos de ejemplo
A continuación, se presentan las primeras filas de un gran conjunto de datos de ejemplo:
user_id |
age |
title |
score |
|---|---|---|---|
602-61-8588 |
24 |
Biostatistician III |
733 |
771-07-8231 |
46 |
Executive Secretary |
672 |
618-96-2322 |
69 |
Programmer I |
514 |
... |
... |
... |
... |
Para los fines de este instructivo, user_id no se abordará, ya que el enfoque está en los cuasi identificadores. En una situación real, lo ideal sería que se oculte user_id o se le asignen tokens de manera apropiada. La columna score es propiedad de este conjunto de datos y es poco probable que un atacante pueda aprenderla por otros medios, por lo que no la incluirás en el análisis. El enfoque debe centrarse en las columnas age y title, con las que un atacante podría obtener información de un individuo a través de otras fuentes de datos. Estas son las preguntas que se deben responder para este conjunto de datos:
- ¿Qué efecto tendrán ambos cuasi identificadores,
ageytitle, sobre el riesgo de reidentificación general de los datos desidentificados? - ¿Cómo se verá afectado el riesgo si se aplica una transformación de desidentificación?
Debes asegurarte de que la combinación de age y title no se asignará a una cantidad pequeña de usuarios. Por ejemplo, supongamos que hay un solo usuario en el conjunto de datos cuyo título es Programador I y tiene 69 años. Un atacante podría correlacionar esa información con los datos demográficos o con otra información disponible, descubrir quién es la persona y conocer el valor de su puntuación.
Para obtener más información, consulta la sección “ID de entidades y procesamiento de k-anonimato” en el tema conceptual Análisis de riesgos.
Paso 1: calcular k-anonymity en el conjunto de datos
Primero, usa la protección de datos sensibles para calcular el k-anonimato del conjunto de datos enviando el siguiente JSON al recurso DlpJob. Dentro de este JSON, debes configurar el ID de la entidad para la columna user_id, además de identificar ambos cuasiidentificadores como las columnas age y title. También le indicas a la protección de datos sensibles que guarde los resultados en una tabla nueva de BigQuery.
Entrada de JSON:
POST https://dlp.googleapis.com/v2/projects/dlp-demo-2/dlpJobs
{
"riskJob": {
"sourceTable": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "dlp_test_data_kanon"
},
"privacyMetric": {
"kAnonymityConfig": {
"entityId": {
"field": {
"name": "id"
}
},
"quasiIds": [
{
"name": "age"
},
{
"name": "job_title"
}
]
}
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "dlp-demo-2",
"datasetId": "dlp_testing",
"tableId": "test_results"
}
}
}
}
]
}
}
Una vez que se completa el trabajo de k-anonimato, la Protección de datos sensibles envía los resultados del trabajo a una tabla de BigQuery llamada dlp-demo-2.dlp_testing.test_results.
Paso 2: Conecta los resultados a Looker Studio
A continuación, conectarás la tabla de BigQuery que generaste en el Paso 1 a un informe nuevo en Looker Studio.
Abre Looker Studio.
Haz clic en Crear > Informes.
En el panel Agregar datos al informe de Conectar a datos, haz clic en BigQuery. Es posible que debas autorizar a Looker Studio para acceder a tus tablas de BigQuery.
En el selector de columnas, elige Mis proyectos. Luego, elige el proyecto, el conjunto de datos y la tabla. Cuando termines, haz clic en Agregar. Si ves un aviso que indica que agregarás datos a este informe, haz clic en Agregar al informe.
Los resultados del análisis de k-anonimato se agregaron al informe nuevo de Looker Studio. En el siguiente paso, crearemos el gráfico.
Paso 3: Crear el gráfico
Sigue estos pasos para insertar y configurar el gráfico:
- En Looker Studio, si aparece una tabla de valores, selecciónala y presiona Borrar para quitarla.
- En el menú Insertar, haz clic en Gráfico combinado.
- Haz clic y dibuja un rectángulo en el lienzo en el que deseas que aparezca el gráfico.
A continuación, configura los datos del gráfico en la pestaña Datos para que el gráfico muestre el efecto de la variación de los rangos de tamaño y valor de los buckets:
- Para borrar los campos de los siguientes encabezados, apunta a cada campo y haz clic en la X, como se muestra aquí:
- Dimensión del período
- Dimensión
- Métrica
- Orden
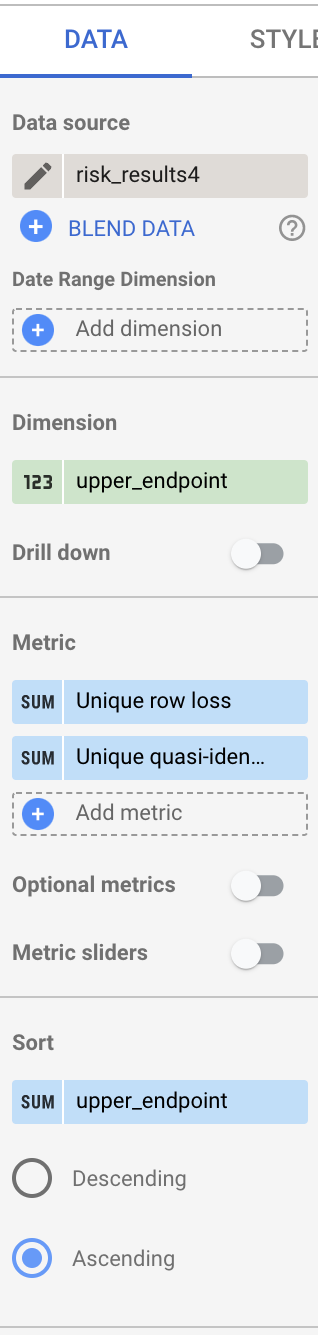
- Con todos los campos borrados, arrastra el campo upper_endpoint de la columna Campos disponibles al encabezado Dimensión.
- Arrastra el campo upper_endpoint al encabezado Orden y, luego, selecciona Ascendente.
- Arrastra los campos bucket_size y bucket_value_count al encabezado Métrica.
- Selecciona el ícono de la izquierda de la métrica bucket_size y aparecerá el ícono Editar
Haz clic en el ícono Editar y, luego, haz lo siguiente:
- En el campo Nombre, escribe
Unique row loss. - En Tipo, selecciona Porcentaje.
- En Cálculo de comparación, elige Porcentaje del total.
- En Cálculo continuo, selecciona Suma continua.
- En el campo Nombre, escribe
- Repite el paso anterior para la métrica bucket_value_count, pero en el campo Nombre, escribe
Unique quasi-identifier combination loss.
Cuando finalices, la columna debe aparecer como se muestra a continuación:
Por último, configura el gráfico a fin de que muestre un gráfico de líneas para cada métrica:
- Haz clic en la pestaña Estilo en el panel de la derecha de la ventana.
- En las series n.º 1 y n.º 2, selecciona Línea.
- Para ver el gráfico final por sí solo, haz clic en el botón Ver en la esquina superior derecha de la ventana.
A continuación, se muestra un gráfico de ejemplo después de completar los pasos anteriores.
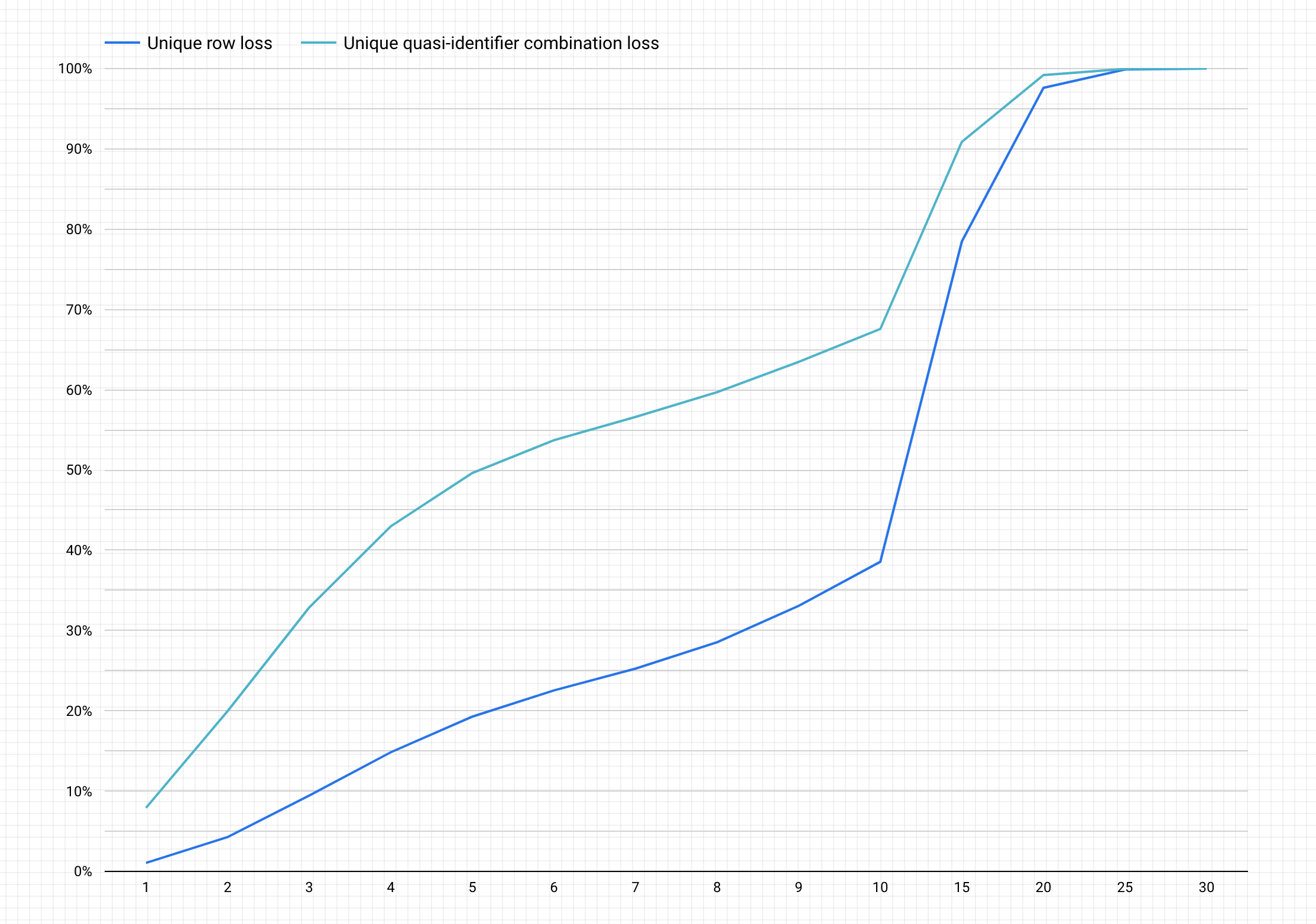
Interpretación del gráfico
El gráfico generado representa, en el eje y, el porcentaje potencial de pérdida de datos para filas únicas y combinaciones de cuasiidentificadores únicos para lograr, en el eje x, un valor de k-anonimato.
Los valores k-anonimato más altos indican menos riesgos de reidentificación. Sin embargo, para alcanzar valores de k-anonimato más altos, debes quitar los porcentajes más altos de las filas totales y las combinaciones únicas del cuasi identificador únicas, lo que podría disminuir la utilidad de los datos.
Afortunadamente, descartar datos no es la única opción para reducir el riesgo de reidentificación. Con otras técnicas de desidentificación, se puede establecer un mejor equilibrio entre la pérdida y la utilidad. Por ejemplo, a fin de abordar el tipo de pérdida de datos asociado con valores de k-anonimato más altos y este conjunto de datos, podrías agrupar las edades o los cargos para reducir la unicidad de las combinaciones de edad y cargo. Es decir, puedes agrupar las edades en rangos de 20-25, 25-30, 30-35 y así sucesivamente. Si quieres obtener más información para realizar este proceso, consulta Generalización y agrupamiento y Desidentificación de datos sensibles en contenidos de texto.