En este tema, se describe en detalle cómo crear un trabajo de inspección de protección de datos sensibles y cómo programar trabajos de inspección recurrentes mediante la creación de un activador de trabajo. Para obtener una explicación rápida sobre cómo crear un activador de trabajo nuevo con la IU de Sensitive Data Protection, consulta la Guía de inicio rápido: Crea un activador de trabajo de Sensitive Data Protection.
Acerca de los trabajos de inspección y activadores de trabajos
Cuando Sensitive Data Protection realiza un análisis de inspección para identificar datos sensibles, cada análisis se ejecuta como un trabajo. Sensitive Data Protection crea y ejecuta un recurso de trabajo cada vez que le indicas que inspeccione tus repositorios de Google Cloud almacenamiento, incluidos los buckets de Cloud Storage, las tablas de BigQuery, los tipos de Datastore y los datos externos.
Para programar trabajos de análisis de inspección de Sensitive Data Protection, crea activadores de trabajo. Un activador de trabajo automatiza la creación de trabajos de Protección de datos sensibles de forma periódica y también se puede ejecutar a pedido.
Para obtener más información sobre los trabajos y los activadores de trabajo en la Protección de datos sensibles, consulta la página conceptual Activadores de trabajos.
Crea un trabajo de inspección nuevo
Para crear un trabajo de inspección de Sensitive Data Protection nuevo, sigue estos pasos:
Console
En la sección Protección de datos sensibles de la consola de Google Cloud, ve a la página Crear trabajo o activador de trabajo.
Ir a Crear trabajo o activador de trabajo
La página Crear trabajo o activador de trabajo contiene las siguientes secciones:
Elige los datos de entrada
Name
Ingresa un nombre para el trabajo. Puedes usar letras, números y guiones. Asignar un nombre a tu trabajo es opcional. Si no ingresas un nombre, la Protección de datos sensibles le asignará al trabajo un identificador de número único.
Ubicación
En el menú Tipo de almacenamiento, elige el tipo de repositorio que almacena los datos que deseas analizar:
- Cloud Storage: ingresa la URL del bucket que deseas analizar o selecciona Incluir/excluir en el menú Tipo de ubicación y, luego, haz clic en Examinar para navegar al bucket o subcarpeta que deseas analizar. Selecciona la casilla de verificación Analizar carpeta de forma recurrente para analizar el directorio especificado y todos los directorios contenidos. Déjalo sin seleccionar para analizar solo el directorio especificado y nada más.
- BigQuery: ingresa los identificadores del proyecto, el conjunto de datos y la tabla que deseas analizar.
- Datastore: ingresa los identificadores para el proyecto, el espacio de nombres (opcional) y el tipo que deseas analizar.
- Híbrido: Puedes agregar etiquetas obligatorias, opcionales y opciones para controlar datos tabulares. Para obtener más información, consulta Tipos de metadatos que puedes proporcionar.
Muestreo
El muestreo es una forma opcional de ahorrar recursos si tienes una gran cantidad de datos.
En Muestreo, puedes elegir si deseas analizar todos los datos seleccionados o tomar muestras de un porcentaje determinado. El muestreo funciona de manera diferente según el tipo de repositorio de almacenamiento que analices:
- Para BigQuery, puedes muestrear un subconjunto del total de filas seleccionadas, que corresponde al porcentaje de archivos que especificas en el análisis.
- En el caso de Cloud Storage, si algún archivo excede el tamaño especificado en el tamaño máximo de bytes para analizar por archivo, la Protección de datos sensibles lo escanea hasta ese tamaño máximo y luego pasa al siguiente archivo.
Para activar el muestreo, elige una de las siguientes opciones del primer menú:
- Iniciar el muestreo desde la parte superior: Sensitive Data Protection inicia el análisis parcial al comienzo de los datos. Para BigQuery, esto inicia el análisis en la primera fila. En el caso de Cloud Storage, esto inicia el análisis al comienzo de cada archivo y lo detiene una vez que Sensitive Data Protection analiza hasta cualquier tamaño máximo de archivo especificado.
- Iniciar el muestreo desde un punto de inicio aleatorio: Sensitive Data Protection inicia el análisis parcial en una ubicación aleatoria dentro de los datos. Para BigQuery, esto inicia el análisis en una fila aleatoria. Para Cloud Storage, esta configuración solo se aplica a los archivos que superan cualquier tamaño máximo especificado. La Protección de datos sensibles analiza los archivos por debajo del tamaño máximo en su totalidad y los archivos por encima del tamaño máximo hasta el máximo.
Para realizar un análisis parcial, también debes elegir qué porcentaje de los datos deseas analizar. Usa el control deslizante para establecer el porcentaje.
También puedes acotar los archivos o registros para analizarlos por fecha. Para obtener información sobre cómo hacerlo, consulta Programación, más adelante en este tema.
Configuración avanzada
Cuando creas un trabajo para un análisis de depósitos de Cloud Storage o tablas de BigQuery, puedes limitar tu búsqueda si especificas una configuración avanzada. Específicamente, puedes configurar lo siguiente:
- Archivos (solo Cloud Storage): los tipos de archivo que se deben analizar, incluidos los archivos de texto, binarios e imágenes.
- Campos de identificación (solo BigQuery): identificadores de fila únicos dentro de la tabla.
- En el caso de Cloud Storage, si algún archivo excede el tamaño especificado en el tamaño máximo de bytes para analizar por archivo, la Protección de datos sensibles lo escanea hasta ese tamaño máximo y luego pasa al siguiente archivo.
Para activar el muestreo, elige el porcentaje de datos que deseas analizar. Usa el control deslizante para establecer el porcentaje. Luego, elige una de las siguientes opciones del primer menú:
- Iniciar el muestreo desde la parte superior: Sensitive Data Protection inicia el análisis parcial al comienzo de los datos. Para BigQuery, esto inicia el análisis en la primera fila. En el caso de Cloud Storage, esto inicia el análisis al comienzo de cada archivo y lo detiene una vez que la Protección de datos sensibles analiza hasta cualquier tamaño máximo de archivo (ver arriba).
- Iniciar el muestreo desde un punto de inicio aleatorio: Sensitive Data Protection inicia el análisis parcial en una ubicación aleatoria dentro de los datos. Para BigQuery, esto inicia el análisis en una fila aleatoria. Para Cloud Storage, esta configuración solo se aplica a los archivos que superan cualquier tamaño máximo especificado. La Protección de datos sensibles analiza los archivos por debajo del tamaño máximo en su totalidad y los archivos por encima del tamaño máximo hasta el máximo.
Archivos
Para los archivos almacenados en Cloud Storage, puedes especificar los tipos que se incluirán en tu análisis en Archivos.
Puedes elegir entre archivos binarios, de texto, de imagen, CSV, TSV, Microsoft Word, Microsoft Excel, Microsoft PowerPoint, PDF y Apache Avro. Para obtener una lista exhaustiva de las extensiones de archivo que Sensitive Data Protection puede analizar en los buckets de Cloud Storage, consulta FileType.
Elegir Binario hace que Sensitive Data Protection analice archivos de tipos que no se reconocen.
Campos de identificación
En el caso de las tablas de BigQuery, en el campo Campos de identificación, puedes dirigir a Sensitive Data Protection para que incluya los valores de las columnas de clave principales de la tabla en los resultados. De esta manera, puedes vincular los resultados a las filas de la tabla que los contienen.
Ingresa los nombres de las columnas que identifican de forma única cada fila de la tabla. Si es necesario, usa la notación de puntos para especificar campos anidados. Puedes agregar todos los campos que desees.
También debes activar la acción Guardar en BigQuery para exportar los resultados a BigQuery. Cuando los resultados se exportan a BigQuery, cada uno
contiene los valores respectivos de los campos de identificación. Para obtener más información, consulta identifyingFields.
Configura la detección
En la sección Configura la detección especificas los tipos de datos sensibles que deseas analizar. Completar esta sección es opcional. Si omites esta sección, la Protección de datos sensibles analizará tus datos en busca de un conjunto predeterminado de infotipos.
Plantilla
De manera opcional, puedes usar una plantilla de Protección de datos sensibles para reutilizar la información de configuración que especificaste anteriormente.
Si ya creaste una plantilla que deseas usar, haz clic en el campo Nombre de la plantilla para ver una lista de las plantillas de inspección existentes. Elige o escribe el nombre de la plantilla que deseas usar.
Para obtener más información sobre cómo crear plantillas, consulta Cómo crear plantillas de inspección de Protección de datos sensibles.
Infotipos
Los detectores de Infotipo encuentran datos sensibles de un tipo determinado. Por ejemplo, el detector de Infotipo integrado US_SOCIAL_SECURITY_NUMBER de Protección de datos sensibles encuentra números de seguridad social de EE.UU. Además de los detectores de Infotipo integrados, puedes crear tus propios detectores de Infotipo personalizados.
En Infotipos, elige el detector de Infotipo que corresponda al tipo de datos que deseas analizar. No recomendamos dejar esta sección en blanco. De esta manera, la Protección de datos sensibles analizará tus datos con un conjunto predeterminado de infotipos, que podría incluir infotipos que no necesitas. Para obtener más información sobre cada detector, consulta la referencia del detector de Infotipo.
Para obtener más información sobre cómo administrar infotipos integrados y personalizados en esta sección, consulta Administra infotipos a través de la consola de Google Cloud.
Conjuntos de reglas de inspección
Los conjuntos de reglas de inspección te permiten personalizar los detectores de Infotipos integrados y personalizados con reglas de contexto. Los dos tipos de reglas de inspección son los siguientes:
- Las reglas de exclusión, que ayudan a excluir resultados falsos o no deseados.
- Reglas de palabras clave, que ayudan a detectar resultados adicionales.
Para agregar un conjunto de reglas nuevo, primero especifica uno o más detectores de Infotipo integrados o personalizados en la sección InfoTypes. Estos son los detectores de infoType que tus conjuntos de reglas modificarán. A continuación, sigue estos pasos:
- Haz clic en el campo Elegir infotipos. El infotipo o los infotipos que especificaste anteriormente aparecen debajo del campo en un menú, como se muestra a continuación:
- Elige un infoType del menú y, luego, haz clic en Agregar regla. Aparecerá un menú con las dos opciones Regla de palabra clave y Regla de exclusión.
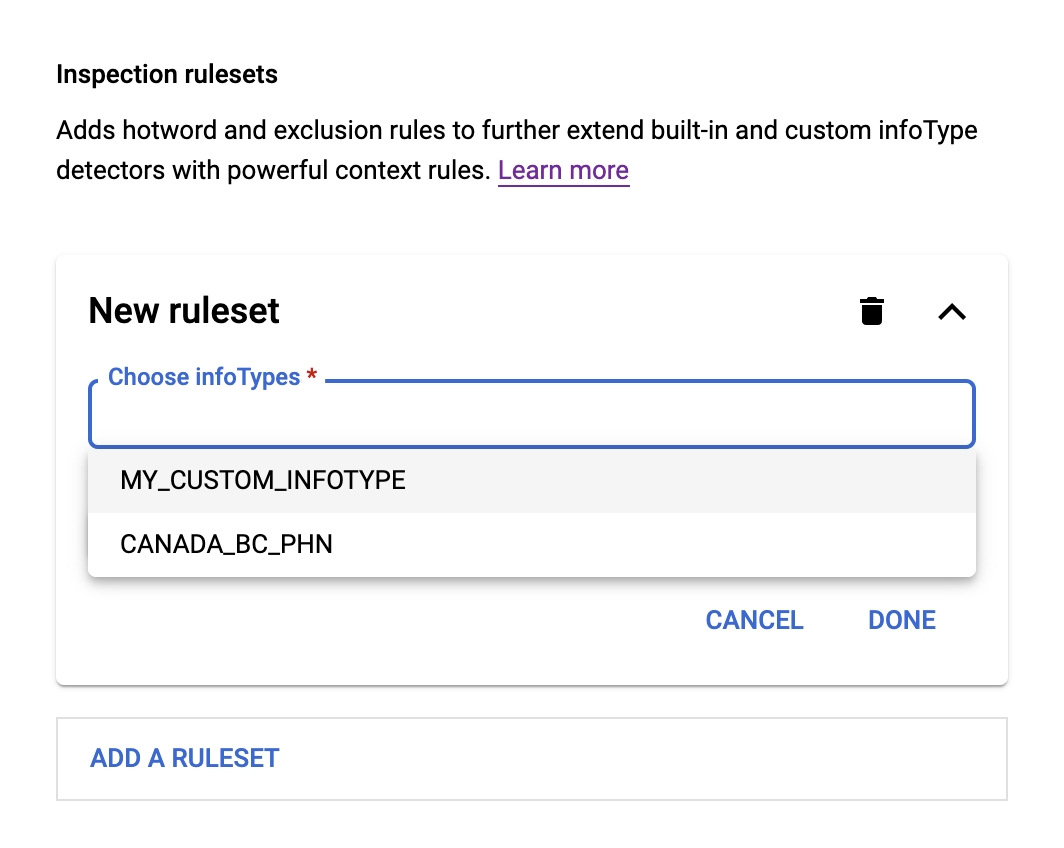
Para las reglas de palabras clave, elige Hotword rules. A continuación, sigue estos pasos:
- En el campo Palabra clave, ingresa una expresión regular que Sensitive Data Protection debería buscar.
- En el menú Hotword proximity, elige si la palabra clave que ingresaste se encuentra antes o después del infoType elegido.
- En Hotword distance from infoType, ingresa la cantidad aproximada de caracteres entre la palabra clave y el infotipo elegido.
- En Ajuste del nivel de confianza, elige si deseas asignar a las coincidencias un nivel fijo de probabilidad o aumentar o disminuir el nivel de probabilidad predeterminado en una cantidad determinada.
Para las reglas de exclusión, elige Reglas de exclusión. A continuación, sigue estos pasos:
- En el campo Excluir, ingresa una expresión regular (regex) que Sensitive Data Protection deba buscar.
- En el menú Tipo de coincidencia, elige una de las siguientes opciones:
- Coincidencia completa: El hallazgo debe coincidir completamente con la regex.
- Coincidencia parcial: Una subcadena del resultado puede coincidir con la regex.
- Coincidencia inversa: El hallazgo no coincide con la regex.
Puedes agregar reglas de palabras clave o exclusiones adicionales, y conjuntos de reglas para definir mejor los resultados de la búsqueda.
Límite de confianza
Cada vez que Sensitive Data Protection detecta una posible coincidencia con datos sensibles, le asigna un valor de probabilidad en una escala de “Muy improbable” a “Muy probable”. Cuando configuras un valor de probabilidad aquí, le indicas a Sensitive Data Protection que solo haga coincidir los datos que se corresponden con ese valor de probabilidad o uno superior.
El valor predeterminado de “Posible” es suficiente para la mayoría de los propósitos. Si habitualmente obtienes coincidencias demasiado amplias, mueve el control deslizante hacia arriba. Si tienes muy pocas coincidencias, mueve el control deslizante hacia abajo.
Cuando finalices, haz clic en Continuar.
Agregar acciones
En el paso Agrega acciones, selecciona una o más acciones que desees que realice la Protección de datos sensibles después de que se complete el trabajo.
Puedes configurar las siguientes acciones:
Guardar en BigQuery: Guarda los resultados del trabajo de Protección de datos sensibles en una tabla de BigQuery. Antes de ver o analizar los resultados, primero debes asegurarte de que el trabajo se haya completado.
Cada vez que se ejecuta un análisis, Sensitive Data Protection guarda los resultados en la tabla de BigQuery que especifiques. Los resultados exportados contienen detalles sobre la ubicación de cada resultado y la probabilidad de coincidencia. Si deseas que cada resultado incluya la cadena que coincide con el detector de infoType, habilita la opción Incluir cita.
Si no especificas un ID de tabla, BigQuery asigna un nombre predeterminado a una tabla nueva la primera vez que se ejecuta el análisis. Si especificas una tabla existente, Sensitive Data Protection le adjunta los resultados del análisis.
Si no guardas los resultados en BigQuery, los resultados del análisis solo contendrá estadísticas sobre la cantidad y los infotipos de los resultados.
Cuando se escriben datos en una tabla de BigQuery, el uso de cuotas y la facturación se aplican al proyecto que contiene la tabla de destino.
Publicar en Pub/Sub: Publica una notificación que contenga el nombre del trabajo de Protección de datos sensibles como un atributo en un canal de Pub/Sub. Puedes especificar uno o más temas a los que se enviará el mensaje de notificación. Asegúrate de que la cuenta de servicio de Sensitive Data Protection que ejecuta el trabajo de análisis tenga acceso de publicación en el tema.
Publicar en Security Command Center: Publica un resumen de los resultados del trabajo en Security Command Center. Para obtener más información, consulta Cómo enviar resultados de análisis de la Protección de datos sensibles a Security Command Center.
Publicar en Dataplex: Envía los resultados de la tarea a Dataplex,el servicio de administración de metadatos de Google Cloud.
Notificar por correo electrónico: Envía un correo electrónico cuando se complete el trabajo. El correo electrónico se envía a los propietarios del proyecto de IAM y a los Contactos esenciales técnicos.
Publicar en Cloud Monitoring: Envía los resultados de la inspección a Cloud Monitoring en Observabilidad de Google Cloud.
Hacer una copia desidentificada: Desidentifica los resultados de los datos inspeccionados y escribe el contenido desidentificado en un archivo nuevo. Luego, puedes usar la copia desidentificada en tus procesos comerciales, en lugar de los datos que contienen información sensible. Para obtener más información, consulta Cómo crear una copia desidentificada de los datos de Cloud Storage con la Protección de datos sensibles en la consola de Google Cloud.
Para obtener más información, consulta Acciones.
Cuando finalices de seleccionar las acciones, haz clic en Continuar.
Repaso
La sección Revisa contiene un resumen con formato JSON de la configuración del trabajo que acabas de especificar.
Haz clic en Crear para crear el trabajo (si no especificaste un programa) y ejecutar el trabajo una vez. Aparecerá la página de información del trabajo, que contiene el estado y otra información. Si el trabajo se encuentra en ejecución, puedes hacer clic en el botón Cancelar para detenerlo. También puedes borrar el trabajo si haces clic en Borrar.
Para volver a la página principal de Protección de datos sensibles, haz clic en la flecha Atrás en la consola de Google Cloud.
C#
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
PHP
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
REST
Un trabajo se representa en la API de DLP con el recurso DlpJobs. Puedes crear un trabajo nuevo mediante el método projects.dlpJobs.create del recurso DlpJob.
Este JSON de muestra se puede enviar en una solicitud POST al extremo REST de Protección de datos sensibles especificado. En este JSON de ejemplo, se muestra cómo crear un trabajo en Protección de datos sensibles. El trabajo es un análisis de inspección de Datastore.
Para intentar realizar esto con rapidez, puedes usar el Explorador de API que se incorpora a continuación. Ten en cuenta que una solicitud correcta, incluso una creada en el Explorador de API, creará un trabajo. Si quieres obtener información general sobre el uso de JSON para enviar solicitudes a la API de DLP, consulta la Guía de inicio rápido de JSON.
Entrada de JSON:
{
"inspectJob": {
"storageConfig": {
"bigQueryOptions": {
"tableReference": {
"projectId": "bigquery-public-data",
"datasetId": "san_francisco_sfpd_incidents",
"tableId": "sfpd_incidents"
}
},
"timespanConfig": {
"startTime": "2020-01-01T00:00:01Z",
"endTime": "2020-01-31T23:59:59Z",
"timestampField": {
"name": "timestamp"
}
}
},
"inspectConfig": {
"infoTypes": [
{
"name": "PERSON_NAME"
},
{
"name": "STREET_ADDRESS"
}
],
"excludeInfoTypes": false,
"includeQuote": true,
"minLikelihood": "LIKELY"
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "[PROJECT-ID]",
"datasetId": "[DATASET-ID]"
}
}
}
}
]
}
}
Salida de JSON:
El siguiente resultado indica que el trabajo se creó de forma correcta.
{
"name": "projects/[PROJECT-ID]/dlpJobs/[JOB-ID]",
"type": "INSPECT_JOB",
"state": "PENDING",
"inspectDetails": {
"requestedOptions": {
"snapshotInspectTemplate": {},
"jobConfig": {
"storageConfig": {
"bigQueryOptions": {
"tableReference": {
"projectId": "bigquery-public-data",
"datasetId": "san_francisco_sfpd_incidents",
"tableId": "sfpd_incidents"
}
},
"timespanConfig": {
"startTime": "2020-01-01T00:00:01Z",
"endTime": "2020-01-31T23:59:59Z",
"timestampField": {
"name": "timestamp"
}
}
},
"inspectConfig": {
"infoTypes": [
{
"name": "PERSON_NAME"
},
{
"name": "STREET_ADDRESS"
}
],
"minLikelihood": "LIKELY",
"limits": {},
"includeQuote": true
},
"actions": [
{
"saveFindings": {
"outputConfig": {
"table": {
"projectId": "[PROJECT-ID]",
"datasetId": "[DATASET-ID]",
"tableId": "[TABLE-ID]"
}
}
}
}
]
}
},
"result": {}
},
"createTime": "2020-07-10T07:26:33.643Z"
}
Crea un activador de trabajo nuevo
Para crear un nuevo activador de trabajo de protección de datos sensibles, sigue estos pasos:
Console
En la sección Protección de datos sensibles de la consola de Google Cloud, ve a la página Crear trabajo o activador de trabajo.
Ir a Crear trabajo o activador de trabajo
La página Crear trabajo o activador de trabajo contiene las siguientes secciones:
Elige los datos de entrada
Name
Ingresa un nombre para el activador de trabajo. Puedes usar letras, números y guiones. Asignar un nombre al activador de trabajo es opcional. Si no ingresas un nombre, la Protección de datos sensibles le dará un identificador de número único al activador de trabajo.
Ubicación
En el menú Tipo de almacenamiento, elige el tipo de repositorio que almacena los datos que deseas analizar:
- Cloud Storage: ingresa la URL del bucket que deseas analizar o selecciona Incluir/excluir en el menú Tipo de ubicación y, luego, haz clic en Examinar para navegar al bucket o subcarpeta que deseas analizar. Selecciona la casilla de verificación Analizar carpeta de forma recurrente para analizar el directorio especificado y todos los directorios contenidos. Déjalo sin seleccionar para analizar solo el directorio especificado y nada más.
- BigQuery: ingresa los identificadores del proyecto, el conjunto de datos y la tabla que deseas analizar.
- Datastore: ingresa los identificadores para el proyecto, el espacio de nombres (opcional) y el tipo que deseas analizar.
Muestreo
El muestreo es una forma opcional de ahorrar recursos si tienes una gran cantidad de datos.
En Muestreo, puedes elegir si deseas analizar todos los datos seleccionados o tomar muestras de un porcentaje determinado. El muestreo funciona de manera diferente según el tipo de repositorio de almacenamiento que analices:
- Para BigQuery, puedes muestrear un subconjunto del total de filas seleccionadas, que corresponde al porcentaje de archivos que especificas en el análisis.
- En el caso de Cloud Storage, si algún archivo excede el tamaño especificado en el tamaño máximo de bytes para analizar por archivo, la Protección de datos sensibles lo escanea hasta ese tamaño máximo y luego pasa al siguiente archivo.
Para activar el muestreo, elige una de las siguientes opciones del primer menú:
- Iniciar el muestreo desde la parte superior: Sensitive Data Protection inicia el análisis parcial al comienzo de los datos. Para BigQuery, esto inicia el análisis en la primera fila. En el caso de Cloud Storage, esto inicia el análisis al comienzo de cada archivo y lo detiene una vez que la Protección de datos sensibles analiza hasta cualquier tamaño máximo de archivo (ver arriba).
- Iniciar el muestreo desde un punto de inicio aleatorio: Sensitive Data Protection inicia el análisis parcial en una ubicación aleatoria dentro de los datos. Para BigQuery, esto inicia el análisis en una fila aleatoria. Para Cloud Storage, esta configuración solo se aplica a los archivos que superan cualquier tamaño máximo especificado. La Protección de datos sensibles analiza los archivos por debajo del tamaño máximo en su totalidad y los archivos por encima del tamaño máximo hasta el máximo.
Para realizar un análisis parcial, también debes elegir qué porcentaje de los datos deseas analizar. Usa el control deslizante para establecer el porcentaje.
Configuración avanzada
Cuando creas un trabajo de activador para un análisis de depósitos de Cloud Storage o tablas de BigQuery, puedes limitar la búsqueda si especificas una configuración avanzada. Específicamente, puedes configurar lo siguiente:
- Archivos (solo Cloud Storage): los tipos de archivo que se deben analizar, incluidos los archivos de texto, binarios e imágenes.
- Campos de identificación (solo BigQuery): identificadores de fila únicos dentro de la tabla.
- En el caso de Cloud Storage, si algún archivo excede el tamaño especificado en el tamaño máximo de bytes para analizar por archivo, la Protección de datos sensibles lo escanea hasta ese tamaño máximo y luego pasa al siguiente archivo.
Para activar el muestreo, elige el porcentaje de datos que deseas analizar. Usa el control deslizante para establecer el porcentaje. Luego, elige una de las siguientes opciones del primer menú:
- Iniciar el muestreo desde la parte superior: Sensitive Data Protection inicia el análisis parcial al comienzo de los datos. Para BigQuery, esto inicia el análisis en la primera fila. En el caso de Cloud Storage, esto inicia el análisis al comienzo de cada archivo y lo detiene una vez que la Protección de datos sensibles analiza hasta cualquier tamaño máximo de archivo (ver arriba).
- Iniciar el muestreo desde un punto de inicio aleatorio: Sensitive Data Protection inicia el análisis parcial en una ubicación aleatoria dentro de los datos. Para BigQuery, esto inicia el análisis en una fila aleatoria. Para Cloud Storage, esta configuración solo se aplica a los archivos que superan cualquier tamaño máximo especificado. La Protección de datos sensibles analiza los archivos por debajo del tamaño máximo en su totalidad y los archivos por encima del tamaño máximo hasta el máximo.
Archivos
Para los archivos almacenados en Cloud Storage, puedes especificar los tipos que se incluirán en tu análisis en Archivos.
Puedes elegir entre archivos binarios, de texto, de imagen, de Microsoft Word, Microsoft Excel, Microsoft PowerPoint, PDF y Apache Avro. Para obtener una lista exhaustiva de las extensiones de archivo que Sensitive Data Protection puede analizar en los buckets de Cloud Storage, consulta FileType.
Elegir Binario hace que Sensitive Data Protection analice archivos de tipos que no se reconocen.
Campos de identificación
En el caso de las tablas de BigQuery, en el campo Campos de identificación, puedes dirigir a Sensitive Data Protection para que incluya los valores de las columnas de clave principales de la tabla en los resultados. De esta manera, puedes vincular los resultados a las filas de la tabla que los contienen.
Ingresa los nombres de las columnas que identifican de forma única cada fila de la tabla. Si es necesario, usa la notación de puntos para especificar campos anidados. Puedes agregar todos los campos que desees.
También debes activar la acción Guardar en BigQuery para exportar los resultados a BigQuery. Cuando los resultados se exportan a BigQuery, cada uno
contiene los valores respectivos de los campos de identificación. Para obtener más información, consulta identifyingFields.
Configura la detección
En la sección Configura la detección especificas los tipos de datos sensibles que deseas analizar. Completar esta sección es opcional. Si omites esta sección, la Protección de datos sensibles analizará tus datos en busca de un conjunto predeterminado de infotipos.
Plantilla
De manera opcional, puedes usar una plantilla de Protección de datos sensibles para reutilizar la información de configuración que especificaste anteriormente.
Si ya creaste una plantilla que deseas usar, haz clic en el campo Nombre de la plantilla para ver una lista de las plantillas de inspección existentes. Elige o escribe el nombre de la plantilla que deseas usar.
Para obtener más información sobre cómo crear plantillas, consulta Cómo crear plantillas de inspección de Protección de datos sensibles.
Infotipos
Los detectores de Infotipo encuentran datos sensibles de un tipo determinado. Por ejemplo, el detector de Infotipo integrado US_SOCIAL_SECURITY_NUMBER de Protección de datos sensibles encuentra números de seguridad social de EE.UU. Además de los detectores de Infotipo incorporados, puedes crear tus propios detectores de Infotipo personalizados.
En Infotipos, elige el detector de Infotipo que corresponda al tipo de datos que deseas analizar. También puedes dejar este campo en blanco para buscar todos los Infotipos predeterminados. Para obtener más información sobre cada detector, consulta la referencia del detector de Infotipo.
También puedes agregar detectores de Infotipo personalizados en la sección Infotipos personalizados y personalizar los detectores de Infotipos integrados y personalizados en la sección Conjuntos de reglas de inspección.
Infotipos personalizados
Conjuntos de reglas de inspección
Los conjuntos de reglas de inspección te permiten personalizar los detectores de Infotipos integrados y personalizados con reglas de contexto. Los dos tipos de reglas de inspección son los siguientes:
- Las reglas de exclusión, que ayudan a excluir resultados falsos o no deseados.
- Reglas de palabras clave, que ayudan a detectar resultados adicionales.
Para agregar un conjunto de reglas nuevo, primero especifica uno o más detectores de Infotipo integrados o personalizados en la sección InfoTypes. Estos son los detectores de infoType que tus conjuntos de reglas modificarán. A continuación, sigue estos pasos:
- Haz clic en el campo Elegir infotipos. El infotipo o los infotipos que especificaste anteriormente aparecen debajo del campo en un menú, como se muestra a continuación:
- Elige un infoType del menú y, luego, haz clic en Agregar regla. Aparecerá un menú con las dos opciones Regla de palabra clave y Regla de exclusión.
Para las reglas de palabras clave, elige Hotword rules. A continuación, sigue estos pasos:
- En el campo Palabra clave, ingresa una expresión regular que Sensitive Data Protection debería buscar.
- En el menú Hotword proximity, elige si la palabra clave que ingresaste se encuentra antes o después del infoType elegido.
- En Hotword distance from infoType, ingresa la cantidad aproximada de caracteres entre la palabra clave y el infotipo elegido.
- En Ajuste del nivel de confianza, elige si deseas asignar a las coincidencias un nivel fijo de probabilidad o aumentar o disminuir el nivel de probabilidad predeterminado en una cantidad determinada.
Para las reglas de exclusión, elige Reglas de exclusión. A continuación, sigue estos pasos:
- En el campo Excluir, ingresa una expresión regular (regex) que Sensitive Data Protection deba buscar.
- En el menú Tipo de coincidencia, elige una de las siguientes opciones:
- Coincidencia completa: El hallazgo debe coincidir completamente con la regex.
- Coincidencia parcial: Una subcadena del resultado puede coincidir con la regex.
- Coincidencia inversa: El hallazgo no coincide con la regex.
Puedes agregar reglas de palabras clave o exclusiones adicionales, y conjuntos de reglas para definir mejor los resultados de la búsqueda.
Límite de confianza
Cada vez que Sensitive Data Protection detecta una posible coincidencia con datos sensibles, le asigna un valor de probabilidad en una escala de “Muy improbable” a “Muy probable”. Cuando configuras un valor de probabilidad aquí, le indicas a Sensitive Data Protection que solo haga coincidir los datos que se corresponden con ese valor de probabilidad o uno superior.
El valor predeterminado de “Posible” es suficiente para la mayoría de los propósitos. Si habitualmente obtienes coincidencias demasiado amplias, mueve el control deslizante hacia arriba. Si tienes muy pocas coincidencias, mueve el control deslizante hacia abajo.
Cuando finalices, haz clic en Continuar.
Agregar acciones
En el paso Agrega acciones, selecciona una o más acciones que desees que realice la Protección de datos sensibles después de que se complete el trabajo.
Puedes configurar las siguientes acciones:
Guardar en BigQuery: Guarda los resultados del trabajo de Protección de datos sensibles en una tabla de BigQuery. Antes de ver o analizar los resultados, primero debes asegurarte de que el trabajo se haya completado.
Cada vez que se ejecuta un análisis, Sensitive Data Protection guarda los resultados en la tabla de BigQuery que especifiques. Los resultados exportados contienen detalles sobre la ubicación de cada resultado y la probabilidad de coincidencia. Si deseas que cada resultado incluya la cadena que coincide con el detector de infoType, habilita la opción Incluir cita.
Si no especificas un ID de tabla, BigQuery asigna un nombre predeterminado a una tabla nueva la primera vez que se ejecuta el análisis. Si especificas una tabla existente, Sensitive Data Protection le adjunta los resultados del análisis.
Si no guardas los resultados en BigQuery, los resultados del análisis solo contendrá estadísticas sobre la cantidad y los infotipos de los resultados.
Cuando se escriben datos en una tabla de BigQuery, el uso de cuotas y la facturación se aplican al proyecto que contiene la tabla de destino.
Publicar en Pub/Sub: Publica una notificación que contenga el nombre del trabajo de Protección de datos sensibles como un atributo en un canal de Pub/Sub. Puedes especificar uno o más temas a los que se enviará el mensaje de notificación. Asegúrate de que la cuenta de servicio de Sensitive Data Protection que ejecuta el trabajo de análisis tenga acceso de publicación en el tema.
Publicar en Security Command Center: Publica un resumen de los resultados del trabajo en Security Command Center. Para obtener más información, consulta Cómo enviar resultados de análisis de la Protección de datos sensibles a Security Command Center.
Publicar en Dataplex: Envía los resultados de la tarea a Dataplex,el servicio de administración de metadatos de Google Cloud.
Notificar por correo electrónico: Envía un correo electrónico cuando se complete el trabajo. El correo electrónico se envía a los propietarios del proyecto de IAM y a los Contactos esenciales técnicos.
Publicar en Cloud Monitoring: Envía los resultados de la inspección a Cloud Monitoring en Observabilidad de Google Cloud.
Hacer una copia desidentificada: Desidentifica los resultados de los datos inspeccionados y escribe el contenido desidentificado en un archivo nuevo. Luego, puedes usar la copia desidentificada en tus procesos comerciales, en lugar de los datos que contienen información sensible. Para obtener más información, consulta Cómo crear una copia desidentificada de los datos de Cloud Storage con la Protección de datos sensibles en la consola de Google Cloud.
Para obtener más información, consulta Acciones.
Cuando finalices de seleccionar las acciones, haz clic en Continuar.
Programa
En la sección Programación, tienes las siguientes dos opciones:
- Especificar intervalo de tiempo: se limitan los archivos o las filas para analizar por fecha. Haz clic en Hora de inicio para especificar la marca de tiempo del archivo más antigua que se debe incluir. Deja este valor en blanco para especificar todos los archivos. Haz clic en Hora de finalización para especificar la marca de tiempo del archivo más reciente. Deja este valor en blanco para no especificar un límite de marca de tiempo superior.
Crear un activador para ejecutar el trabajo de forma periódica: Esta opción convierte el trabajo en un activador de trabajo que se ejecuta de forma periódica. Si no especificas un programa, debes crear un solo trabajo que se inicie de inmediato y se ejecute una vez. Para crear un activador de trabajo que se ejecute con regularidad, debes configurar esta opción.
El valor predeterminado también es el valor mínimo: 24 horas. El valor máximo es de 60 días.
Si deseas que la Protección de datos sensibles analice solo archivos o filas nuevos, selecciona Limitar análisis solo a contenido nuevo. Para la inspección de BigQuery, solo se incluyen en el análisis las filas que tengan al menos tres horas de antigüedad. Consulta el problema conocido relacionado con esta operación.
Revisar
La sección Revisa contiene un resumen con formato JSON de la configuración del trabajo que acabas de especificar.
Haz clic en Crear para crear el activador de trabajo (si especificaste un programa). Aparecerá la página de información del activador de trabajo, que contiene el estado y otra información. Si el trabajo se encuentra en ejecución, puedes hacer clic en el botón Cancelar para detenerlo. También puedes borrar el activador de trabajo si haces clic en Borrar.
Para volver a la página principal de Protección de datos sensibles, haz clic en la flecha Atrás en la consola de Google Cloud.
C#
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
PHP
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
REST
Un recurso de trabajo se representa en la API de DLP con el recurso JobTrigger. Puedes crear un activador de trabajo nuevo mediante el método projects.jobTriggers.create del recurso JobTrigger.
Este JSON de muestra se puede enviar en una solicitud POST al extremo REST de Protección de datos sensibles especificado. En este JSON de ejemplo, se muestra cómo crear un activador de trabajo en la Protección de datos sensibles. El trabajo que iniciará este activador es un análisis de inspección de Datastore. El activador de trabajo que se crea se ejecuta cada 86,400 segundos (o 24 horas).
Para intentar realizar esto con rapidez, puedes usar el Explorador de API que se incorpora a continuación. Ten en cuenta que una solicitud correcta, incluso una creada en el Explorador de API, creará un activador de trabajo programado nuevo. Si quieres obtener información general sobre el uso de JSON para enviar solicitudes a la API de DLP, consulta la Guía de inicio rápido de JSON.
Entrada de JSON:
{
"jobTrigger":{
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"status":"HEALTHY",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"kind":{
"name":"Example-Kind"
},
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"excludeInfoTypes":false,
"includeQuote":true,
"minLikelihood":"LIKELY"
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
}
}
}
Resultado de JSON:
En el resultado siguiente, se indica que el activador de trabajo se creó de manera correcta.
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
},
"kind":{
"name":"Example-Kind"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2018-11-30T01:52:41.171857Z",
"updateTime":"2018-11-30T01:52:41.171857Z",
"status":"HEALTHY"
}
Enumera todos los trabajos
Para enumerar todos los trabajos del proyecto actual, sigue estos pasos:
Console
En la consola de Google Cloud, ve a la página Protección de datos sensibles.
Haz clic en la pestaña Inspección y, luego, en la subpestaña Inspeccionar trabajos.
La consola muestra una lista de todos los trabajos del proyecto actual, incluidos sus identificadores de trabajo, el estado, la hora de creación y la hora de finalización. Para obtener más información sobre cualquier trabajo, incluido un resumen de sus resultados, haz clic en su identificador.
C#
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
PHP
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
REST
El recurso DlpJob tiene un método projects.dlpJobs.list con el que puedes enumerar todos los trabajos.
Para enumerar todos los trabajos definidos actualmente en tu proyecto, envía una solicitud GET al extremo dlpJobs, como se muestra aquí:
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs?key={YOUR_API_KEY}
En el siguiente resultado de JSON, se enumera uno de los trabajos que se muestran. Ten en cuenta que la estructura del trabajo refleja la del recurso DlpJob.
Salida de JSON:
{
"jobs":[
{
"name":"projects/[PROJECT-ID]/dlpJobs/i-5270277269264714623",
"type":"INSPECT_JOB",
"state":"DONE",
"inspectDetails":{
"requestedOptions":{
"snapshotInspectTemplate":{
},
"jobConfig":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"[CLOUD-STORAGE-URL]"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"startTime":"2019-09-08T22:43:16.623Z",
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_SOCIAL_SECURITY_NUMBER"
},
{
"name":"CANADA_SOCIAL_INSURANCE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT-ID]",
"datasetId":"[DATASET-ID]",
"tableId":"[TABLE-ID]"
}
}
}
}
]
}
},
"result":{
...
}
},
"createTime":"2019-09-09T22:43:16.918Z",
"startTime":"2019-09-09T22:43:16.918Z",
"endTime":"2019-09-09T22:43:53.091Z",
"jobTriggerName":"projects/[PROJECT-ID]/jobTriggers/sample-trigger2"
},
...
Para intentar realizar esto con rapidez, puedes usar el Explorador de API que se incorpora a continuación. Si quieres obtener información general sobre el uso de JSON para enviar solicitudes a la API de DLP, consulta la guía de inicio rápido de JSON.
Enumera todos los activadores de trabajo
Para enumerar todos los activadores de trabajo del proyecto actual, sigue estos pasos:
Console
En la consola de Google Cloud, ve a la página Protección de datos sensibles.
Ir a Protección de datos sensibles
En la pestaña Inspección, en la subpestaña Activadores de trabajo, la consola muestra una lista de todos los activadores de trabajo del proyecto actual.
C#
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
PHP
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
REST
El recurso JobTrigger tiene un método projects.jobTriggers.list con el que puedes enumerar todos los activadores de trabajo.
Para enumerar todos los activadores de trabajo definidos actualmente en tu proyecto, envía una solicitud GET al extremo jobTriggers, como se muestra a continuación:
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/jobTriggers?key={YOUR_API_KEY}
En la siguiente salida de JSON, se muestra el activador de trabajo que se creó en la sección anterior. Ten en cuenta que la estructura del activador de trabajo refleja la del recurso JobTrigger.
Salida de JSON:
{
"jobTriggers":[
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"displayName":"JobTrigger1",
"description":"Starts an inspection of a Datastore kind",
"inspectJob":{
"storageConfig":{
"datastoreOptions":{
"partitionId":{
"projectId":"[PROJECT_ID]",
"namespaceId":"[NAMESPACE_ID]"
},
"kind":{
"name":"Example-Kind"
}
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"PHONE_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
},
"includeQuote":true
},
"actions":[
{
"saveFindings":{
"outputConfig":{
"table":{
"projectId":"[PROJECT_ID]",
"datasetId":"[BIGQUERY_DATASET_NAME]",
"tableId":"[BIGQUERY_TABLE_NAME]"
}
}
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2018-11-30T01:52:41.171857Z",
"updateTime":"2018-11-30T01:52:41.171857Z",
"status":"HEALTHY"
},
...
],
"nextPageToken":"KkwKCQjivJ2UpPreAgo_Kj1wcm9qZWN0cy92ZWx2ZXR5LXN0dWR5LTE5NjEwMS9qb2JUcmlnZ2Vycy8xNTA5NzEyOTczMDI0MDc1NzY0"
}
Para intentar realizar esto con rapidez, puedes usar el Explorador de API que se incorpora a continuación. Si quieres obtener información general sobre el uso de JSON para enviar solicitudes a la API de DLP, consulta la guía de inicio rápido de JSON.
Borra un trabajo
Para borrar un trabajo de tu proyecto, que incluye sus resultados, haz lo siguiente. Cualquier resultado guardado externamente (como en BigQuery) no se ve afectado por esta operación.
Console
En la consola de Google Cloud, ve a la página Protección de datos sensibles.
Haz clic en la pestaña Inspección y, luego, en la subpestaña Inspeccionar trabajos. Google Cloud Console muestra una lista de todos los trabajos para el proyecto actual.
En la columna Actions (Acciones) para el activador de trabajo que deseas borrar, haz clic en el menú Más acciones (que se muestra como tres puntos ordenados verticalmente) y, luego, haz clic en Delete (Borrar).
De forma alternativa, en la lista de trabajos, haz clic en el identificador del trabajo que deseas borrar. En la página de detalles del trabajo, haz clic en Borrar.
C#
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
PHP
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
REST
Para borrar un trabajo del proyecto actual, envía una solicitud DELETE al extremo dlpJobs, como se muestra aquí. Reemplaza el campo [JOB-IDENTIFIER] con el identificador del trabajo, que comienza con i-.
URL:
DELETE https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs/[JOB-IDENTIFIER]?key={YOUR_API_KEY}
Si la solicitud se realizó correctamente, la API de DLP mostrará una respuesta exitosa. Para verificar que el trabajo se borró correctamente, enumera todos los trabajos.
Para intentar realizar esto con rapidez, puedes usar el Explorador de API que se incorpora a continuación. Si quieres obtener información general sobre el uso de JSON para enviar solicitudes a la API de DLP, consulta la guía de inicio rápido de JSON.
Borra un activador de trabajo
Console
En la consola de Google Cloud, ve a la página Protección de datos sensibles.
Ir a Protección de datos sensibles
En la pestaña Inspección, en la subpestaña Activadores de trabajo, Console muestra una lista de todos los activadores de trabajo para el proyecto actual.
En la columna Actions (Acciones) para el activador de trabajo que deseas borrar, haz clic en el menú Más acciones (que se muestra como tres puntos ordenados verticalmente) y, luego, haz clic en Delete (Borrar).
Como alternativa, en la lista de activadores de trabajo, haz clic en el nombre del activador de trabajo que deseas borrar. En la página de detalles del activador de trabajo, haz clic en Delete (Borrar).
C#
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
PHP
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
REST
Para borrar un activador de trabajo del proyecto actual, envía una solicitud DELETE al extremo jobTriggers, como se muestra aquí. Reemplaza el campo [JOB-TRIGGER-NAME] con el nombre del activador del trabajo.
URL:
DELETE https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/jobTriggers/[JOB-TRIGGER-NAME]?key={YOUR_API_KEY}
Si la solicitud se realizó correctamente, la API de DLP mostrará una respuesta exitosa. Para verificar si se borró el activador de trabajo de manera correcta, enumera todos los activadores de trabajo.
Para intentar realizar esto con rapidez, puedes usar el Explorador de API que se incorpora a continuación. Si quieres obtener información general sobre el uso de JSON para enviar solicitudes a la API de DLP, consulta la guía de inicio rápido de JSON.
Obtener un trabajo
Para obtener un trabajo de tu proyecto, que incluye sus resultados, haz lo siguiente. Cualquier resultado guardado externamente (como en BigQuery) no se ve afectado por esta operación.
C#
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
PHP
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
REST
Para obtener un trabajo del proyecto actual, envía una solicitud GET al extremo dlpJobs, como se muestra aquí. Reemplaza el campo [JOB-IDENTIFIER] con el identificador del trabajo, que comienza con i-.
URL:
GET https://dlp.googleapis.com/v2/projects/[PROJECT-ID]/dlpJobs/[JOB-IDENTIFIER]?key={YOUR_API_KEY}
Si la solicitud tuvo éxito, la API de DLP mostrará una respuesta exitosa.
Para intentar realizar esto con rapidez, puedes usar el Explorador de API que se incorpora a continuación. Si quieres obtener información general sobre el uso de JSON para enviar solicitudes a la API de DLP, consulta la guía de inicio rápido de JSON.
Cómo forzar la ejecución inmediata de un activador de trabajo
Después de crear un activador de trabajo, puedes forzar una ejecución inmediata del activador para probarlo activándolo. Para ello, ejecuta el siguiente comando:
curl --request POST \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "X-Goog-User-Project: PROJECT_ID" \
'https://dlp.googleapis.com/v2/JOB_TRIGGER_NAME:activate'
Reemplaza lo siguiente:
- PROJECT_ID: El ID del Google Cloud proyecto para facturar los cargos de acceso asociados con la solicitud.
- JOB_TRIGGER_NAME: Es el nombre completo del recurso del activador de trabajos, por ejemplo,
projects/my-project/locations/global/jobTriggers/123456789.
Actualiza un activador de trabajo existente
Además de crear, enumerar y borrar activadores de trabajo, también puedes actualizar un activador de trabajo existente. Para cambiar la configuración de un activador de trabajo existente, sigue estos pasos:
Console
En la consola de Google Cloud, ve a la página Protección de datos sensibles.
Haz clic en la pestaña Inspección y, luego, en la subpestaña Activadores de trabajos.
La consola muestra una lista de todos los activadores de trabajo para el proyecto actual.
En la columna Acciones para el activador de trabajo que deseas borrar, haz clic en Más more_vert, y luego haz clic en Ver detalles.
En la página de detalles del activador de trabajo, haz clic en Edit (Editar).
En la página del activador de edición, puedes cambiar la ubicación de los datos de entrada; detalles de detección, como plantillas, Infotipos o probabilidades; las acciones posteriores al análisis y la programación del activador de trabajo. Cuando finalices de realizar cambios, haz clic en Guardar.
C#
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
PHP
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de Protección de datos sensibles, consulta Bibliotecas cliente de Protección de datos sensibles.
Para autenticarte en la Protección de datos sensibles, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
REST
Usa el método projects.jobTriggers.patch para enviar valores JobTrigger nuevos a la API de DLP y actualizar esos valores dentro de un activador de trabajo especificado.
Por ejemplo, considera el siguiente activador de trabajo simple. Este JSON representa el activador del trabajo y se mostró después de enviar una solicitud GET al extremo del activador de trabajo del proyecto actual.
Salida de JSON:
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"inspectJob":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://dlptesting/*"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_SOCIAL_SECURITY_NUMBER"
}
],
"minLikelihood":"POSSIBLE",
"limits":{
}
},
"actions":[
{
"jobNotificationEmails":{
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2019-03-06T21:19:45.774841Z",
"updateTime":"2019-03-06T21:19:45.774841Z",
"status":"HEALTHY"
}
El siguiente JSON, cuando se envía con una solicitud PATCH al extremo especificado, actualiza el activador de trabajo determinado con un nuevo Infotipo para analizar, así como una nueva probabilidad mínima. Ten en cuenta que también debes especificar el atributo updateMask y que su valor está en formato FieldMask.
Entrada de JSON:
PATCH https://dlp.googleapis.com/v2/projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]?key={YOUR_API_KEY}
{
"jobTrigger":{
"inspectJob":{
"inspectConfig":{
"infoTypes":[
{
"name":"US_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER"
}
],
"minLikelihood":"LIKELY"
}
}
},
"updateMask":"inspectJob(inspectConfig(infoTypes,minLikelihood))"
}
Después de enviar este JSON a la URL especificada, muestra lo siguiente, que representa el activador de trabajo actualizado. Ten en cuenta que los valores de Infotipo y probabilidad originales se reemplazaron por los nuevos.
Salida de JSON:
{
"name":"projects/[PROJECT_ID]/jobTriggers/[JOB_TRIGGER_NAME]",
"inspectJob":{
"storageConfig":{
"cloudStorageOptions":{
"fileSet":{
"url":"gs://dlptesting/*"
},
"fileTypes":[
"FILE_TYPE_UNSPECIFIED"
],
"filesLimitPercent":100
},
"timespanConfig":{
"enableAutoPopulationOfTimespanConfig":true
}
},
"inspectConfig":{
"infoTypes":[
{
"name":"US_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBER"
}
],
"minLikelihood":"LIKELY",
"limits":{
}
},
"actions":[
{
"jobNotificationEmails":{
}
}
]
},
"triggers":[
{
"schedule":{
"recurrencePeriodDuration":"86400s"
}
}
],
"createTime":"2019-03-06T21:19:45.774841Z",
"updateTime":"2019-03-06T21:27:01.650183Z",
"lastRunTime":"1970-01-01T00:00:00Z",
"status":"HEALTHY"
}
Para intentar realizar esto con rapidez, puedes usar el Explorador de API que se incorpora a continuación. Si quieres obtener información general sobre el uso de JSON para enviar solicitudes a la API de DLP, consulta la guía de inicio rápido de JSON.
Latencia del trabajo
No hay objetivos de nivel de servicio (SLO) garantizados para las tareas ni los activadores de tareas. La latencia se ve afectada por varios factores, como la cantidad de datos que se analizarán, el repositorio de almacenamiento que se analiza, el tipo y la cantidad de infotipos que se buscan, la región en la que se procesa la tarea y los recursos de procesamiento disponibles en esa región. Por lo tanto, la latencia de los trabajos de inspección no se puede determinar con anticipación.
Para ayudar a reducir la latencia del trabajo, puedes probar con las siguientes opciones:
- Si el muestreo está disponible para tu trabajo o activador de trabajo, habilítalo.
Evita habilitar infoTypes que no necesites. Si bien lo siguiente es útil en ciertas situaciones, estos infoTypes pueden hacer que las solicitudes se ejecuten mucho más lentamente que las que no los incluyen:
PERSON_NAMEFEMALE_NAMEMALE_NAMEFIRST_NAMELAST_NAMEDATE_OF_BIRTHLOCATIONSTREET_ADDRESSORGANIZATION_NAME
Especifica siempre los Infotipos de forma explícita. No uses una lista de Infotipos vacía.
Si es posible, usa una región de procesamiento diferente.
Si aún tienes problemas de latencia con las tareas después de probar estas técnicas, considera usar solicitudes content.inspect o content.deidentify en lugar de tareas. Estos métodos se incluyen en el Acuerdo de Nivel de Servicio. Para obtener más información, consulta el Acuerdo de nivel de servicio de Protección de datos sensibles.
Limita el análisis solo al contenido nuevo
Puedes configurar el activador de trabajo para que establezca automáticamente la fecha del período de los archivos almacenados en Cloud Storage o BigQuery. Cuando configuras el objeto TimespanConfig para que se complete automáticamente, la Protección de datos sensibles solo analiza los datos que se agregaron o modificaron desde la última ejecución del activador:
...
timespan_config {
enable_auto_population_of_timespan_config: true
}
...
Para la inspección de BigQuery, solo se incluyen en el análisis las filas que tengan al menos tres horas de antigüedad. Consulta el problema conocido relacionado con esta operación.
Activa trabajos en la carga de archivos
Además de la compatibilidad con activadores de trabajo, que está integrada en la Protección de datos sensibles,Google Cloud también tiene una variedad de otros componentes que puedes usar para integrar o activar trabajos de Protección de datos sensibles. Por ejemplo, puedes usar funciones de Cloud Run para activar un análisis de Protección de datos sensibles cada vez que se suba un archivo a Cloud Storage.
Para obtener información sobre cómo configurar esta operación, consulta Cómo automatizar la clasificación de datos subidos a Cloud Storage.
Trabajos exitosos sin datos inspeccionados
Un trabajo se puede completar correctamente incluso si no se analizaron datos. Los siguientes ejemplos de situaciones pueden causar que esto suceda:
- La tarea está configurada para inspeccionar un recurso de datos específico, como un archivo, que existe, pero está vacío.
- El trabajo está configurado para inspeccionar un recurso de datos que no existe o que ya no existe.
- La tarea está configurada para inspeccionar un bucket de Cloud Storage que está vacío.
- El trabajo está configurado para inspeccionar un bucket, y el análisis recursivo está inhabilitado. En el nivel superior, el bucket solo contiene carpetas que, a su vez, contienen los archivos.
- La tarea está configurada para inspeccionar solo un tipo de archivo específico en un bucket, pero el bucket no tiene ningún archivo de ese tipo.
- La tarea está configurada para inspeccionar solo el contenido nuevo, pero no hubo actualizaciones después de la última vez que se ejecutó.
En la consola de Google Cloud, en la página Detalles del trabajo, el campo Bytes analizados especifica cuántos datos inspeccionó el trabajo. En la API de DLP, el campo processedBytes especifica cuántos datos se inspeccionaron.
¿Qué sigue?
- Obtén más información para crear una copia desidentificada de los datos en el almacenamiento.