このドキュメントでは、Google Cloud に実装した、傾向モデリングを実行するパイプラインの例について説明します。このドキュメントは、機械学習モデルを作成してデプロイするデータ エンジニア、機械学習エンジニア、マーケティング サイエンス チームを対象としています。このドキュメントは、ML のコンセプトを理解し、 Google Cloud、BigQuery、Vertex AI Pipelines、Python、Jupyter ノートブックに慣れていることを前提としています。また、Google アナリティクス 4 と BigQuery の未加工エクスポート機能について理解していることも前提としています。
このドキュメントで扱うパイプラインでは、Google アナリティクスのサンプルデータを使用します。BigQuery ML と XGBoost を使用して複数のモデルを構築するこのパイプラインを、Vertex AI Pipelines を使用して実行します。このドキュメントでは、モデルをトレーニング、評価、デプロイするプロセスについて説明します。また、プロセス全体を自動化する方法についても説明します。
このパイプラインの完全なコードは、GitHub リポジトリの Jupyter ノートブックにあります。
傾向モデリングとは
傾向モデリングは、消費者がとる可能性がある行動を予測します。傾向モデリングの例としては、商品を購入する可能性があるユーザー、サービスに登録する可能性があるユーザー、さらには離脱してブランドのアクティブな顧客ではなくなるユーザーを予測する場合が挙げられます。
傾向モデルでは、消費者がそのアクションを行う可能性を表す 0~1 のスコアが消費者ごとに出力されます。組織が傾向モデリングを行う主な要因の 1 つは、自社データをさらに活用する必要があることです。マーケティングのユースケースの場合、最適な傾向モデルには、オンラインとオフラインの両方のソースからのシグナル(サイト分析や CRM データなど)が含まれます。
このデモでは、BigQuery 内にある GA4 のサンプルデータを使用します。実際のユースケースでは、追加のオフライン シグナルの使用の検討が必要になる場合があります。
MLOps が ML パイプラインを簡素化する仕組み
大半の ML モデルは本番環境で使用されません。モデルの結果からは分析情報が生成されます。多くの場合、データ サイエンス チームがモデルを完成させると、ML エンジニアリング チームやソフトウェア エンジニアリング チームが Flask や FastAPI などのフレームワークを使用して本番環境用のコードでモデルをラップします。通常、このプロセスでは新しいフレームワークでモデルを構築する必要が生じます。これは、データの再変換が必要になることを意味します。この作業には数週間から数か月かかることがあり、そのため、多くのモデルが本番環境に実装できません。
ML プロジェクトから価値を得るうえで、機械学習オペレーション(MLOps)が重要になっており、MLOps はデータ サイエンス組織の進化しつつあるスキルセットになっています。この価値の理解をサポートするため、 Google Cloudでは、MLOps の概要を提供する MLOps のプラクティショナー ガイドを公開しています。
MLOps の原則と Google Cloudを用いることで、手動プロセスの複雑さを大きく軽減する自動プロセスを使用して、モデルをエンドポイントに push できます。このドキュメントで説明するツールとプロセスでは、モデルを本番環境に導入する際に役立つパイプラインをエンドツーエンドで所有するためのアプローチについて説明しています。前述のプラクティショナー ガイド ドキュメントには、業種横断型ソリューションと、MLOps と Google Cloudを使用してできることの概要が記載されています。
Vertex AI Pipelines とは
Vertex AI Pipelines では、Kubeflow Pipelines SDK または TensorFlow Extended(TFX)を使用して構築されたパイプラインを実行できます。Vertex AI を使用せずに、こうしたオープンソース フレームワークのいずれかを大規模に実行するには、独自の Kubernetes クラスタを設定してメンテナンスする必要があります。Vertex AI Pipelines は、この課題に対処するものです。これはマネージド サービスであるため、必要に応じてスケールアップまたはスケールダウンし、常時メンテナンスする必要はありません。
Vertex AI Pipelines プロセスの各ステップは、入力や出力をアーティファクトという形で生成できる、それぞれに独立したコンテナからなります。たとえば、プロセスのステップでデータセットがビルドされる場合、そのステップの出力はデータセット アーティファクトです。このデータセット アーティファクトを、次のステップの入力として使用できます。各コンポーネントは個別のコンテナであるため、パイプラインの各コンポーネントに関する情報(ベースイメージの名前や依存関係のリストなど)を提供する必要があります。
パイプラインのビルドプロセス
このドキュメントの例では、Juptyer ノートブックを使用してパイプライン コンポーネントを作成します。これらのコンポーネントのコンパイル、実行、自動化にも、Juptyer ノートブックを使用します。前述のように、ノートブックは GitHub リポジトリにあります。
ノートブック コードを実行するには、Vertex AI Workbench ユーザー管理ノートブック インスタンスを使用できます。この場合、認証が自動的に処理されます。Vertex AI Workbench では、ノートブックを使用してマシンの作成、ノートブックの作成、Git への接続を行うことができます(Vertex AI Workbench には他にも多くの機能がありますが、このドキュメントでは取り上げません)。
パイプラインの実行が完了すると、Vertex AI Pipelines で次のような図が生成されます。
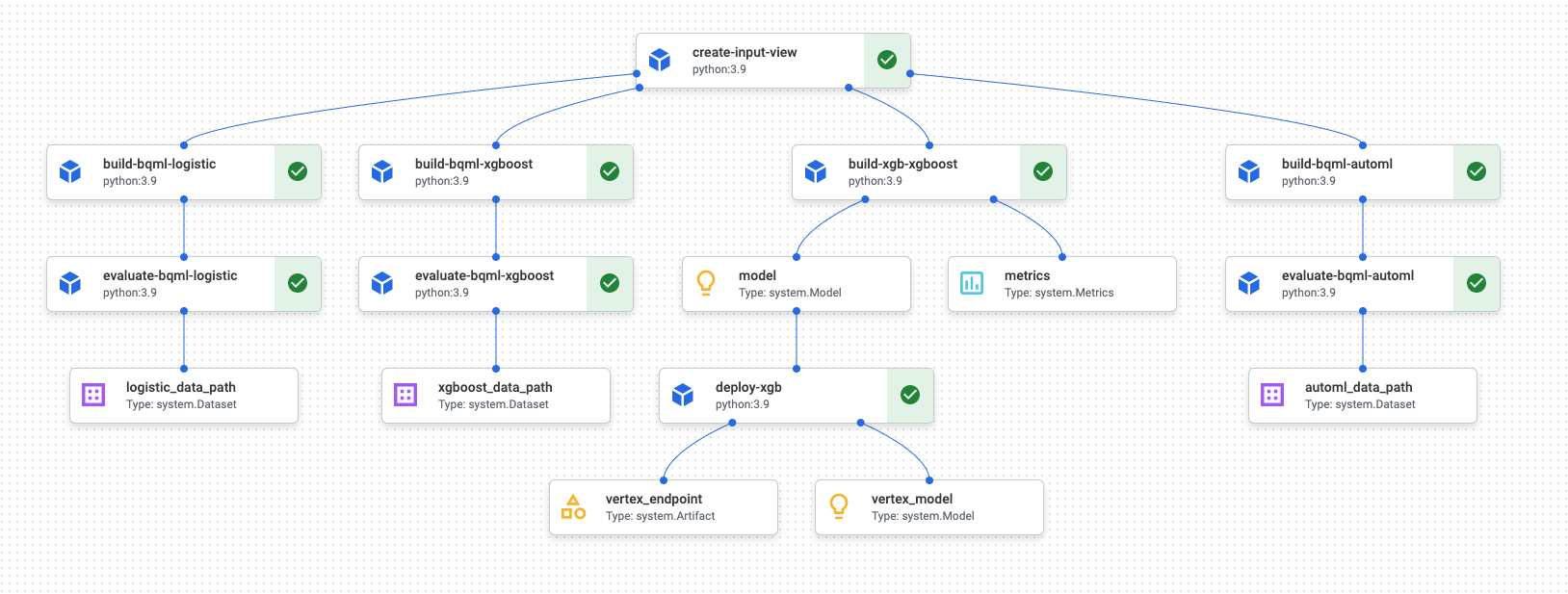
上の図は有向非巡回グラフ(DAG)です。DAG の作成と確認は、データまたは ML パイプラインを理解するための中心的なステップです。DAG の主な属性は、コンポーネントは一方向(この場合は上から下)に流れ、サイクルは発生しないという点です。つまり、親コンポーネントは、子コンポーネントに依存しません。コンポーネントには、並行して発生するものもあれば、依存関係があるため連続して発生するものもあります。
各コンポーネントの緑色のチェックマークは、コードが正常に実行されたことを示します。エラーが発生した場合は、赤色の感嘆符が表示されます。図の各コンポーネントをクリックすると、ジョブの詳細が表示されます。
DAG 図は、ドキュメントのこのセクションに含まれ、パイプラインによって構築される各コンポーネントのブループリントとして機能します。次のリストでは、各コンポーネントについて説明します。
DAG 図に示すように、パイプライン全体では、次のステップを実行します。
create-input-view: このコンポーネントは BigQuery ビューを作成します。このコンポーネントは、Cloud Storage バケットから SQL をコピーし、指定されたパラメータ値を入力します。この BigQuery ビューは、パイプラインでその後にあるすべてのモデルに使用される入力データセットです。build-bqml-logistic: パイプラインは、BigQuery ML を使用してロジスティック回帰モデルを作成します。このコンポーネントが完了すると、新しいモデルを BigQuery コンソールに表示できます。このモデル オブジェクトを使用して、モデルのパフォーマンスを表示できます。また、後で予測も作成できます。evaluate-bqml-logistic: パイプラインはこのコンポーネントを使用して、ロジスティック回帰の適合率 / 再現率曲線(DAG 図ではlogistic_data_path)を作成します。このアーティファクトは、Cloud Storage バケットに保存されます。build-bqml-xgboost: このコンポーネントは、BigQuery ML を使用して XGBoost モデルを作成します。このコンポーネントが完了すると、BigQuery コンソールに新しいモデル オブジェクト(system.Model)を表示できます。このオブジェクトは、モデルのパフォーマンスを確認し、後で予測を行うために使用できます。evaluate-bqml-xgboost: この要素は、XGBoost モデルの適合率 / 再現率曲線(xgboost_data_path)を作成します。このアーティファクトは、Cloud Storage バケットに保存されます。build-xgb-xgboost: パイプラインは、XGBoost モデルを作成します。このコンポーネントでは、モデルの異なる作成方法を確認できるように、BigQuery ML ではなく Python を使用します。このコンポーネントが完了すると、モデル オブジェクトとパフォーマンス指標が Cloud Storage バケットに保存されます。deploy-xgb: このコンポーネントは、XGBoost モデルをデプロイします。バッチ予測またはオンライン予測を許可するエンドポイントを作成します。エンドポイントは、Vertex AI コンソール ページの [モデル] タブで確認できます。エンドポイントはトラフィックに合わせて自動スケーリングします。build-bqml-automl: パイプラインは、BigQuery ML を使用して AutoML モデルを作成します。このコンポーネントが完了すると、新しいモデル オブジェクトを BigQuery コンソールに表示できます。このオブジェクトは、モデルのパフォーマンスを確認し、後で予測を行うために使用できます。evaluate-bqml-automl: パイプラインは、AutoML モデルの精度 / 再現率曲線を作成します。このアーティファクトは、Cloud Storage バケットに保存されます。
このプロセスでは、BigQuery ML モデルはエンドポイントに push されません。これは、BigQuery のモデル オブジェクトから直接予測を生成できるためです。BigQuery ML とソリューションの他のライブラリのどちらを使用するかを決める際は、予測を生成する方法を検討してください。毎日のバッチ予測がニーズを満たしている場合は、BigQuery 環境に留まることでワークフローを簡素化できます。ただしリアルタイム予測が必要な場合や、シナリオに別のライブラリにある機能が必要な場合は、このドキュメントの手順に沿って保存されているモデルをエンドポイントに push してください。
費用
このドキュメントでは、Google Cloud の次の課金対象のコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
このシナリオの Jupyter ノートブック
パイプラインを作成および構築するタスクは、GitHub リポジトリにある Jupyter ノートブックに組み込まれています。
タスクを実施するには、ノートブックを入手し、ノートブック内のコードセルを順番に実行します。このドキュメントで説明するフローでは、Vertex AI Workbench でノートブックを実行していることを前提としています。
Vertex AI Workbench 環境を開く
まず、GitHub リポジトリのクローンを Vertex AI Workbench 環境に作成します。
- Google Cloud コンソールで、ノートブックを作成するプロジェクトを選択します。
[Vertex AI Workbench] ページに移動します。
[ユーザー管理のノートブック] タブで、[新しいノートブック] をクリックします。
ノートブック タイプのリストで、Python 3 ノートブックを選択します。
[New notebook] ダイアログで [Advanced Options] をクリックし、[Machine type] で、使用するマシンタイプを選択します。不明な場合は、[n1-standard-1 (1 cVPU, 3.75 GB RAM)] を選択します。
[作成] をクリックします。
ノートブック環境が作成されるまでに少し時間がかかります。
ノートブックが作成されたら、ノートブックを選択し、[JupyterLab を開く] をクリックします。
ブラウザで JupyterLab 環境が開きます。
ターミナルタブを起動するには、[ファイル] > [新規] > [ランチャー] の順に選択します。
[Launcher] タブの [Terminal] アイコンをクリックします。
ターミナルで、
mlops-on-gcpGitHub リポジトリのクローンを作成します。git clone https://github.com/GoogleCloudPlatform/cloud-for-marketing/
コマンドが終了すると、ファイル ブラウザに
cloud-for-marketingフォルダが表示されます。
ノートブック設定を構成する
ノートブックは、実行する前に、それを構成する必要があります。ノートブックには、パイプライン アーティファクトを格納する Cloud Storage バケットが必要なため、まずそのバケットを作成します。
- ノートブックがパイプライン アーティファクトを保存できる Cloud Storage バケットを作成します。バケットの名前は、グローバルに一意にする必要があります。
cloud-for-marketing/marketing-analytics/predicting/kfp_pipeline/フォルダで、Propensity_Pipeline.ipynbノートブックを開きます。- ノートブックで、
PROJECT_ID変数の値を、パイプラインを実行する Google Cloud プロジェクトの ID に設定します。 BUCKET_NAME変数の値を、作成したバケットの名前に設定します。
このドキュメントの残りの部分では、パイプラインの仕組みを理解するために重要なコード スニペットについて説明します。完全な実装については、GitHub リポジトリをご覧ください。
BigQuery ビューを作成する
パイプラインの最初のステップでは、各モデルを構築するために使用する入力データを生成します。この Vertex AI Pipelines コンポーネントは、BigQuery ビューを生成します。ビューの作成プロセスを簡素化するために、一部の SQL はすでに生成されて、テキスト ファイルで GitHub に保存されています。
各コンポーネントのコードは、Vertex AI Pipelines コンポーネント クラスを修飾(属性を使用して親クラスまたは関数を変更)してから、create_input_view 関数(パイプラインのステップのうちの一つ)を定義します。
この関数にはいくつかの入力値が必要です。現在、これらの値の一部は、コード内にハードコードされています(開始日と終了日など)。パイプラインを自動化する際には、適切な値を使用するようにコードを変更するか(たとえば、日付には CURRENT_DATE 関数を使用)、これらの値をハードコードするのではなく、パラメータとして受け取るようにコンポーネントを更新することが可能です。また、ga_data_ref の値を GA4 テーブルの名前に変更し、conversion 変数の値を実際の変換に合わせて設定する必要があります(この例では、一般公開されている GA4 のサンプルデータを使用します)。
create-input-view コンポーネントのコードを以下に示します。
@component( # this component builds a BigQuery view, which will be the underlying source for model packages_to_install=["google-cloud-bigquery", "google-cloud-storage"], base_image="python:3.9", output_component_file="output_component/create_input_view.yaml", ) def create_input_view(view_name: str, data_set_id: str, project_id: str, bucket_name: str, blob_path: str ): from google.cloud import bigquery from google.cloud import storage client = bigquery.Client(project=project_id) dataset = client.dataset(data_set_id) table_ref = dataset.table(view_name) ga_data_ref = 'bigquery-public-data.google_analytics_sample.ga_sessions_*' conversion = "hits.page.pageTitle like '%Shopping Cart%'" start_date = '20170101' end_date = '20170131' def get_sql(bucket_name, blob_path): from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.get_blob(blob_path) content = blob.download_as_string() return content def if_tbl_exists(client, table_ref): ... else: content = get_sql() content = str(content, 'utf-8') create_base_feature_set_query = content. format(start_date = start_date, end_date = end_date, ga_data_ref = ga_data_ref, conversion = conversion) shared_dataset_ref = client.dataset(data_set_id) base_feature_set_view_ref = shared_dataset_ref.table(view_name) base_feature_set_view = bigquery.Table(base_feature_set_view_ref) base_feature_set_view.view_query = create_base_feature_set_query.format(project_id) base_feature_set_view = client.create_table(base_feature_set_view)
BigQuery ML モデルを構築する
ビューを作成したら、build_bqml_logistic という名前のコンポーネントを実行して、BigQuery ML モデルを構築します。ノートブックのこのブロックは、コア コンポーネントです。最初のブロックで作成したトレーニング ビューを使用して、BigQuery ML モデルを構築します。この例では、ノートブックでロジスティック回帰を使用しています。
モデルタイプと使用可能なハイパーパラメータについては、BigQuery ML のリファレンス ドキュメントをご覧ください。
このコンポーネントのコードを以下に示します。
@component( # this component builds a logistic regression with BigQuery ML packages_to_install=["google-cloud-bigquery"], base_image="python:3.9", output_component_file="output_component/create_bqml_model_logistic.yaml" ) def build_bqml_logistic(project_id: str, data_set_id: str, model_name: str, training_view: str ): from google.cloud import bigquery client = bigquery.Client(project=project_id) model_name = f"{project_id}.{data_set_id}.{model_name}" training_set = f"{project_id}.{data_set_id}.{training_view}" build_model_query_bqml_logistic = ''' CREATE OR REPLACE MODEL `{model_name}` OPTIONS(model_type='logistic_reg' , INPUT_LABEL_COLS = ['label'] , L1_REG = 1 , DATA_SPLIT_METHOD = 'RANDOM' , DATA_SPLIT_EVAL_FRACTION = 0.20 ) AS SELECT * EXCEPT (fullVisitorId, label), CASE WHEN label is null then 0 ELSE label end as label FROM `{training_set}` '''.format(model_name = model_name, training_set = training_set) job_config = bigquery.QueryJobConfig() client.query(build_model_query_bqml_logistic, job_config=job_config)
BigQuery ML ではなく XGBoost を使用する
前のセクションで説明したコンポーネントは、BigQuery ML を使用しています。ノートブックの次のセクションでは、BigQuery ML を使用するのではなく Python で直接 XGBoost を使用する方法について説明します。
build_bqml_xgboost という名前のコンポーネントを実行して、グリッド検索を使用して標準の XGBoost 分類モデルを実行するコンポーネントを構築します。その後、作成した Cloud Storage バケットに、モデルをアーティファクトとして保存します。この関数では、出力アーティファクトの追加パラメータ(metrics と model)がサポートされています。Vertex AI Pipelines には、これらのパラメータが必要です。
@component( # this component builds an xgboost classifier with xgboost packages_to_install=["google-cloud-bigquery", "xgboost", "pandas", "sklearn", "joblib", "pyarrow"], base_image="python:3.9", output_component_file="output_component/create_xgb_model_xgboost.yaml" ) def build_xgb_xgboost(project_id: str, data_set_id: str, training_view: str, metrics: Output[Metrics], model: Output[Model] ): ... data_set = f"{project_id}.{data_set_id}.{training_view}" build_df_for_xgboost = ''' SELECT * FROM `{data_set}` '''.format(data_set = data_set) ... xgb_model = XGBClassifier(n_estimators=50, objective='binary:hinge', silent=True, nthread=1, eval_metric="auc") random_search = RandomizedSearchCV(xgb_model, param_distributions=params, n_iter=param_comb, scoring='precision', n_jobs=4, cv=skf.split(X_train,y_train), verbose=3, random_state=1001 ) random_search.fit(X_train, y_train) xgb_model_best = random_search.best_estimator_ predictions = xgb_model_best.predict(X_test) score = accuracy_score(y_test, predictions) auc = roc_auc_score(y_test, predictions) precision_recall = precision_recall_curve(y_test, predictions) metrics.log_metric("accuracy",(score * 100.0)) metrics.log_metric("framework", "xgboost") metrics.log_metric("dataset_size", len(df)) metrics.log_metric("AUC", auc) dump(xgb_model_best, model.path + ".joblib")
エンドポイントを構築する
前のセクションの XGBoost モデルを使用して、deploy_xgb という名前のコンポーネントを実行し、エンドポイントを構築します。このコンポーネントは、前の XGBoost モデル アーティファクトを取得し、コンテナを構築してエンドポイントをデプロイします。同時に、エンドポイント URL をアーティファクトとして指定し、表示できるようにします。この手順が完了すると、Vertex AI エンドポイントが作成され、Vertex AI のコンソール ページにエンドポイントが表示されます。
@component( # Deploys xgboost model packages_to_install=["google-cloud-aiplatform", "joblib", "sklearn", "xgboost"], base_image="python:3.9", output_component_file="output_component/xgboost_deploy_component.yaml", ) def deploy_xgb( model: Input[Model], project_id: str, vertex_endpoint: Output[Artifact], vertex_model: Output[Model] ): from google.cloud import aiplatform aiplatform.init(project=project_id) deployed_model = aiplatform.Model.upload( display_name="tai-propensity-test-pipeline", artifact_uri = model.uri.replace("model", ""), serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-4:latest" ) endpoint = deployed_model.deploy(machine_type="n1-standard-4") # Save data to the output params vertex_endpoint.uri = endpoint.resource_name vertex_model.uri = deployed_model.resource_name
パイプラインの定義
パイプラインを定義するには、前に作成したコンポーネントに基づいて各オペレーションを定義します。次に、コンポーネント内で明示的に呼び出されない場合は、パイプライン要素の順序を指定できます。
たとえば、ノートブックで次のコードはパイプラインを定義します。この場合、build_bqml_logistic_op コンポーネントを create_input_view_op コンポーネントの後に実行する必要があります。
@dsl.pipeline( # Default pipeline root. You can override it when submitting the pipeline. pipeline_root=PIPELINE_ROOT, # A name for the pipeline. name="pipeline-test", description='Propensity BigQuery ML Test' ) def pipeline(): create_input_view_op = create_input_view( view_name = VIEW_NAME, data_set_id = DATA_SET_ID, project_id = PROJECT_ID, bucket_name = BUCKET_NAME, blob_path = BLOB_PATH ) build_bqml_logistic_op = build_bqml_logistic( project_id = PROJECT_ID, data_set_id = DATA_SET_ID, model_name = 'bqml_logistic_model', training_view = VIEW_NAME ) # several components have been deleted for brevity build_bqml_logistic_op.after(create_input_view_op) build_bqml_xgboost_op.after(create_input_view_op) build_bqml_automl_op.after(create_input_view_op) build_xgb_xgboost_op.after(create_input_view_op) evaluate_bqml_logistic_op.after(build_bqml_logistic_op) evaluate_bqml_xgboost_op.after(build_bqml_xgboost_op) evaluate_bqml_automl_op.after(build_bqml_automl_op)
パイプラインをコンパイルして実行する
これでパイプラインをコンパイルして実行できるようになりました。
キャッシュを有効にするため、ノートブックの次のコードでは enable_caching 値を true に設定します。キャッシュ保存が有効になっている場合、コンポーネントが正常に完了する前の実行は再実行されません。このフラグは、特にパイプラインのテストの際に役立ちます。キャッシュが有効になっていると、実行が高速になり、使用するリソースの量は少なくなります。
compiler.Compiler().compile( pipeline_func=pipeline, package_path="pipeline.json" ) TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S") run = pipeline_jobs.PipelineJob( display_name="test-pipeine", template_path="pipeline.json", job_id="test-{0}".format(TIMESTAMP), enable_caching=True ) run.run()
パイプラインを自動化する
この段階で、最初のパイプラインが起動されました。このジョブのステータスは、コンソールの [Vertex AI Pipelines] ページで確認できます。各コンテナがビルドおよび実行されることを確認できます。このセクションでは、特定のコンポーネントのエラーをクリックして、そのエラーを追跡することもできます。
パイプラインをスケジュールするには、Cloud Run functions を構築し、cron ジョブに似たスケジューラを使用します。
ノートブックの最後のセクションのコードは、次のコード スニペットに示すように、パイプラインが 1 日に 1 回実行されるようにスケジュールします。
from kfp.v2.google.client import AIPlatformClient api_client = AIPlatformClient(project_id=PROJECT_ID, region='us-central1' ) api_client.create_schedule_from_job_spec( job_spec_path='pipeline.json', schedule='0 * * * *', enable_caching=False )
完成したパイプラインを本番環境で使用する
完成したパイプラインは次のタスクを実行しました。
- 入力データセットが作成されました。
- BigQuery ML と Python の XGBoost の両方を使用して複数のモデルをトレーニングする。
- モデルの結果を分析しました。
- XGBoost モデルをデプロイする。
また、Cloud Run functions と Cloud Scheduler を使用して毎日実行し、パイプラインを自動化しました。
ノートブックに定義されているパイプラインは、さまざまなモデルの作成方法を示すために作られています。現在パイプラインは本番環境シナリオで構築されているため、パイプラインは実行しません。しかし、このパイプラインをガイドとして使用し、ニーズに合わせてコンポーネントを変更できます。たとえば、特徴作成プロセスを編集して、データの活用、期間の変更、別モデルの構築を行えます。また、ご利用の本番環境の要件に最適なモデルも選択します。
パイプラインを本番環境で使用できるようになると、追加のタスクを実装できます。たとえば、支持者 / チャレンジャー モデルを実装できます。この場合、新しいモデルが作成され、新しいモデル(チャレンジャー)と既存のモデル(支持者)の両方が毎日スコア付けされます。新しいモデルのパフォーマンスが、現在のモデルのパフォーマンスよりも優れている場合にのみ、本番環境に入れます。システムの進行状況をモニタリングするために、毎日のモデル パフォーマンスの記録を保存し、パフォーマンスの傾向を可視化することもできます。
クリーンアップ
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- MLOps を使用して本番環境対応の ML システムを作成する方法については、MLOps の実践ガイドをご覧ください。
- Vertex AI の詳細を確認する。Vertex AI のドキュメントをご覧ください。
- Kubeflow Pipelines の概要を確認する。KFP のドキュメントをご覧ください。
- TensorFlow Extended の概要を確認する。TFX ユーザーガイドをご覧ください。
- Google Cloudの AI ワークロードと ML ワークロードに固有のアーキテクチャ原則と推奨事項の概要については、アーキテクチャ フレームワークの AI と ML の視点をご覧ください。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
寄稿者
著者: Tai Conley | Cloud カスタマー エンジニア
その他の協力者: Lars Ahlfors | Cloud カスタマー エンジニア