이 문서에서는 Google Cloud 리소스에서 Splunk로 로그를 스트리밍하도록 내보내기 메커니즘을 배포하는 방법을 설명합니다. 이 사용 사례에 해당하는 참조 아키텍처를 이미 읽었다고 가정합니다.
이 안내는 Google Cloud에서 Splunk로 로그를 스트리밍하려는 작업 관리자와 보안 관리자를 대상으로 합니다. IT 운영 또는 보안 사용 사례에 대한 다음 안내를 사용할 때는 Splunk 및 Splunk HTTP 이벤트 수집기(HEC)에 익숙해야 합니다. 필수는 아니지만 Dataflow 파이프라인, Pub/Sub, Cloud Logging, Identity and Access Management, Cloud Storage에 익숙한 것이 이 배포에 유용합니다.
코드형 인프라(IaC)를 사용하여 이 참조 아키텍처의 배포 단계를 자동화하려면 terraform-splunk-log-export GitHub 저장소를 참조하세요.
아키텍처
다음 다이어그램에서는 참조 아키텍처를 보여주고 Google Cloud에서 Splunk로 로그 데이터가 어떻게 전송되는지 보여줍니다.

다이어그램에서 볼 수 있듯이 Cloud Logging은 로그를 조직 수준의 로그 싱크로 수집하고 Pub/Sub으로 전송합니다. Pub/Sub 서비스는 로그에 대한 단일 주제와 구독을 만들고 로그를 기본 Dataflow 파이프라인으로 전달합니다. 기본 Dataflow 파이프라인은 Pub/Sub 구독에서 로그를 가져와 Splunk에 전송하는 Pub/Sub to Splunk 스트리밍 파이프라인입니다. 기본 Dataflow 파이프라인과 동시에 보조 Dataflow 파이프라인은 전송이 실패하면 메시지를 재생하는 Pub/Sub to Pub/Sub 스트리밍 파이프라인입니다. 프로세스가 끝나면 Splunk Enterprise 또는 Splunk Cloud Platform이 HEC 엔드포인트로 작동하고 추가 분석을 위해 로그를 수신합니다. 자세한 내용은 참조 아키텍처의 아키텍처 섹션을 참조하세요.
이 참조 아키텍처를 배포하려면 다음 태스크를 수행합니다.
- 설정 태스크를 수행합니다.
- 전용 프로젝트에서 집계 로그 싱크를 만듭니다.
- 데드 레터 주제를 만듭니다.
- Splunk HEC 엔드포인트를 설정합니다.
- Dataflow 파이프라인 용량을 구성합니다.
- 로그를 Splunk로 내보냅니다.
- Splunk Dataflow 파이프라인 내에서 사용자 정의 함수(UDF)를 사용하여 진행 중에 로그 또는 이벤트를 변환합니다.
- 전송 실패를 처리하여 잠재적인 구성 오류 또는 일시적인 네트워크 문제로 인한 데이터 손실을 방지합니다.
시작하기 전에
다음 단계를 완료하여 Google Cloud to Splunk 참조 아키텍처의 환경을 설정합니다.
프로젝트 불러오기, 결제 사용 설정, API 활성화
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
IAM 역할 부여
Google Cloud 콘솔에서 조직 및 프로젝트 리소스에 대한 다음 Identity and Access Management(IAM) 권한이 있는지 확인합니다. 자세한 내용은 리소스에 대한 액세스 권한 부여, 변경, 취소를 참조하세요.
| 권한 | 사전 정의된 역할 | 리소스 |
|---|---|---|
|
|
조직 |
|
|
프로젝트 |
|
|
프로젝트 |
사전 정의된 IAM 역할에 작업을 수행할 수 있는 권한이 부족하면 커스텀 역할을 만듭니다. 커스텀 역할은 필요한 액세스 권한을 제공하며 최소 권한의 원칙을 따르는 데 도움이 됩니다.
환경 설정하기
In the Google Cloud console, activate Cloud Shell.
활성 Cloud Shell 세션의 프로젝트를 설정합니다.
gcloud config set project PROJECT_ID
PROJECT_ID를 프로젝트 ID로 바꿉니다.
보안 네트워킹 설정
이 단계에서는 로그를 Splunk Enterprise로 처리하고 내보내기 전에 보안 네트워킹을 설정합니다.
VPC 네트워크와 서브넷을 만듭니다.
gcloud compute networks create NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets create SUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24
다음을 바꿉니다.
NETWORK_NAME: 네트워크 이름SUBNET_NAME: 서브넷 이름REGION: 이 네트워크에 사용할 리전
Dataflow 작업자 가상 머신(VM)이 서로 통신할 수 있도록 방화벽 규칙을 만듭니다.
gcloud compute firewall-rules create allow-internal-dataflow \ --network=NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346
이 규칙은 TCP 포트 12345~12346을 사용하는 Dataflow VM 간에 내부 트래픽을 허용합니다. 또한 Dataflow 서비스는
dataflow태그를 설정합니다.Cloud NAT 게이트웨이를 만듭니다.
gcloud compute routers create nat-router \ --network=NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION
서브넷에서 비공개 Google 액세스를 사용 설정합니다.
gcloud compute networks subnets update SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
로그 싱크 만들기
이 섹션에서는 필요한 권한과 함께 조직 전체 로그 싱크와 해당 싱크의 Pub/Sub 대상을 만듭니다.
Cloud Shell에서 Pub/Sub 주제와 관련 구독을 새 로그 싱크 대상으로 만듭니다.
gcloud pubsub topics create INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topic INPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME
다음을 바꿉니다.
INPUT_TOPIC_NAME: 로그 싱크 대상으로 사용할 Pub/Sub 주제의 이름INPUT_SUBSCRIPTION_NAME: 로그 싱크 대상에 대한 Pub/Sub 구독의 이름
조직 로그 싱크를 만듭니다.
gcloud logging sinks create ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID/topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID/logs/dataflow.googleapis.com'
다음을 바꿉니다.
ORGANIZATION_SINK_NAME: 조직 이름ORGANIZATION_ID: 조직 ID입니다.
이 명령어는 다음 플래그로 구성됩니다.
--organization플래그는 조직 수준의 로그 싱크임을 지정합니다.--include-children플래그는 필수이며 조직 수준의 로그 싱크에 모든 하위 폴더와 프로젝트의 모든 로그가 포함되도록 합니다.--log-filter플래그는 라우팅할 로그를 지정합니다. 이 예시에서 로그 내보내기 Dataflow 파이프라인은 로그를 처리할 때 자체적으로 더 많은 로그를 생성하므로 특별히PROJECT_ID프로젝트에 대한 Dataflow 작업 로그를 제외합니다. 이 필터를 사용하면 파이프라인에서 자체 로그를 내보내지 않으며 잠재적인 지수 주기를 방지할 수 있습니다. 출력에는o#####-####@gcp-sa-logging.iam.gserviceaccount.com형식의 서비스 계정이 포함됩니다.
Pub/Sub 주제
INPUT_TOPIC_NAME의 로그 싱크 서비스 계정에 Pub/Sub 게시자 IAM 역할을 부여합니다. 이 역할을 사용하면 로그 싱크 서비스 계정에서 메시지를 주제에 게시할 수 있습니다.gcloud pubsub topics add-iam-policy-binding INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/pubsub.publisher
LOG_SINK_SERVICE_ACCOUNT를 로그 싱크의 서비스 계정 이름으로 바꿉니다.
데드 레터 주제 만들기
메시지를 전송할 수 없을 때 발생하는 잠재적인 데이터 손실을 방지하려면 Pub/Sub 데드 레터 주제 및 해당 구독을 만들어야 합니다. 실패한 메시지는 운영자 또는 사이트 안정성 엔지니어가 실패를 조사하고 수정할 때까지 데드 레터 주제에 저장됩니다. 자세한 내용은 참조 아키텍처의 실패한 메시지 재생 섹션을 참조하세요.
Cloud Shell에서 Pub/Sub 데드 레터 주제와 구독을 만들어 전송할 수 없는 메시지를 저장하면 데이터 손실이 방지됩니다.
gcloud pubsub topics create DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topic DEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME
다음을 바꿉니다.
DEAD_LETTER_TOPIC_NAME: 데드 레터 주제가 될 Pub/Sub 주제의 이름DEAD_LETTER_SUBSCRIPTION_NAME: 데드 레터 주제의 Pub/Sub 구독 이름
Splunk HEC 엔드포인트 설정
다음 절차에서는 Splunk HEC 엔드포인트를 설정하고 새로 만든 HEC 토큰을 Secret Manager에 보안 비밀로 저장합니다. Splunk Dataflow 파이프라인을 배포할 때 엔드포인트 URL과 토큰을 모두 제공해야 합니다.
Splunk HEC 구성
- 아직 Splunk HEC 엔드포인트가 없으면 Splunk 문서를 참조하여 Splunk HEC를 구성하는 방법을 알아보세요. Splunk HEC는 Splunk Cloud Platform 서비스 또는 자체 Splunk Enterprise 인스턴스에서 실행됩니다.
- Splunk에서 Splunk HEC 토큰을 만든 후 토큰 값을 복사합니다.
- Cloud Shell에서 Splunk HEC 토큰 값을
splunk-hec-token-plaintext.txt임시 파일에 저장합니다.
Secret Manager에 Splunk HEC 토큰 저장
이 단계에서는 Splunk HEC 토큰 값을 저장할 보안 비밀과 단일 기본 보안 비밀 버전을 만듭니다.
Cloud Shell에서 Splunk HEC 토큰을 포함할 보안 비밀을 만듭니다.
gcloud secrets create hec-token \ --replication-policy="automatic"
보안 비밀의 복제 정책에 대한 자세한 내용은 복제 정책 선택을 참조하세요.
splunk-hec-token-plaintext.txt파일의 콘텐츠를 사용하여 토큰을 보안 비밀 버전으로 추가합니다.gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
splunk-hec-token-plaintext.txt파일이 더 이상 필요하지 않으므로 이 파일을 삭제합니다.
Dataflow 파이프라인 용량 구성
다음 표에는 Dataflow 파이프라인 용량 설정 구성에 추천되는 일반적인 권장사항이 요약되어 있습니다.
| 설정 | 일반 권장사항 |
|---|---|
|
최대 성능 대비 비용 비율을 위해 기준 머신 크기를 |
|
계산당 예상되는 최대 EPS를 처리하는 데 필요한 최대 작업자 수로 설정 |
|
동시 Splunk HEC 연결 수가 극대화되도록 2 x vCPU/작업자 x 최대 작업자 수로 설정 |
|
최대 버퍼링 지연 2초가 허용되는 경우 로그에 대한 이벤트당 요청을 10~50개로 설정 |
이 참조 아키텍처를 환경에 배포할 때는 고유한 값과 계산을 사용해야 합니다.
머신 유형 및 머신 수의 값을 설정합니다. 클라우드 환경에 적합한 값을 계산하려면 참조 아키텍처의 머신 유형 및 머신 수 섹션을 참조하세요.
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT
Dataflow 동시 로드 및 일괄 수의 값을 설정합니다. 클라우드 환경에 적합한 값을 계산하려면 참조 아키텍처의 동시 로드 및 일괄 계산 섹션을 참조하세요.
JOB_PARALLELISM JOB_BATCH_COUNT
Dataflow 파이프라인 용량 매개변수를 계산하는 방법에 대한 자세한 내용은 이 참조 아키텍처의 성능 및 비용 최적화 설계 고려사항 섹션을 참조하세요.
Dataflow 파이프라인을 사용하여 로그 내보내기
이 섹션에서는 다음 단계에 따라 Dataflow 파이프라인을 배포합니다.
- Cloud Storage 버킷 및 Dataflow 작업자 서비스 계정을 만듭니다.
- Dataflow 작업자 서비스 계정에 역할과 액세스 권한을 부여합니다.
- Dataflow 파이프라인을 배포합니다.
- Splunk에서 로그 보기
파이프라인은 Google Cloud 로그 메시지를 Splunk HEC에 전송합니다.
Cloud Storage 버킷 및 Dataflow 작업자 서비스 계정 만들기
Cloud Shell에서 균일한 버킷 수준 액세스 설정으로 새 Cloud Storage 버킷을 만듭니다.
gsutil mb -b on gs://PROJECT_ID-dataflow/
앞에서 만든 Cloud Storage 버킷에서 Dataflow 작업이 임시 파일을 스테이징합니다.
Cloud Shell에서 Dataflow 작업자의 서비스 계정을 만듭니다.
gcloud iam service-accounts create WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"
WORKER_SERVICE_ACCOUNT를 Dataflow 작업자 서비스 계정에 사용할 이름으로 바꿉니다.
Dataflow 작업자 서비스 계정에 역할 및 액세스 권한 부여
이 섹션에서는 다음 표와 같이 Dataflow 작업자 서비스 계정에 필요한 역할을 부여합니다.
| 역할 | 경로 | 목적 |
|---|---|---|
| Dataflow 관리자 |
|
Dataflow 관리자 역할을 할 서비스 계정을 사용 설정합니다. |
| Dataflow 작업자 |
|
Dataflow 작업자 역할을 할 서비스 계정을 사용 설정합니다. |
| 스토리지 객체 관리자 |
|
Dataflow에서 파일 스테이징에 사용하는 Cloud Storage 버컷에 액세스하도록 서비스 계정을 사용 설정합니다. |
| Pub/Sub 게시자 |
|
Pub/Sub 데드 레터 주제에 실패한 메시지를 게시하도록 서비스 계정을 사용 설정합니다. |
| Pub/Sub 구독자 |
|
입력 구독에 액세스하도록 서비스 계정을 사용 설정합니다. |
| Pub/Sub 뷰어 |
|
구독을 보도록 서비스 계정을 사용 설정합니다. |
| Secret Manager 보안 비밀 접근자 |
|
Splunk HEC 토큰이 포함된 보안 비밀에 액세스하도록 서비스 계정을 사용 설정합니다. |
Cloud Shell에서 Dataflow 작업 및 관리 태스크를 실행하기 위해 이 계정에 필요한 Dataflow 관리자 및 Dataflow 작업자 역할을 Dataflow 작업자 서비스 계정에 부여합니다.
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.worker"
Dataflow 작업자 서비스 계정에 Pub/Sub 입력 구독에서 메시지를 보고 사용할 수 있는 액세스 권한을 부여합니다.
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber"
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.viewer"
Dataflow 작업자 서비스 계정에 실패한 메시지를 Pub/Sub 처리되지 않은 주제에 게시할 수 있는 액세스 권한을 부여합니다.
gcloud pubsub topics add-iam-policy-binding DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.publisher"
Dataflow 작업자 서비스 계정에 Secret Manager의 Splunk HEC 토큰 보안 비밀에 대한 액세스 권한을 부여합니다.
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/secretmanager.secretAccessor"
Dataflow 작업자 서비스 계정에 Dataflow 작업에서 파일 스테이징에 사용할 Cloud Storage 버킷에 대한 읽기 및 쓰기 액세스 권한을 부여합니다.
gcloud storage buckets add-iam-policy-binding gs://PROJECT_ID-dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" --role=”roles/storage.objectAdmin”
Dataflow 파이프라인 배포
Cloud Shell에서 Splunk HEC URL의 다음 환경 변수를 설정합니다.
export SPLUNK_HEC_URL=SPLUNK_HEC_URL
protocol://host[:port] 양식을 사용하여SPLUNK_HEC_URL변수를 바꿉니다. 각 항목의 의미는 다음과 같습니다.protocol는http또는https입니다.host는 정규화된 도메인 이름(FQDN)이거나 Splunk HEC 인스턴스 또는 연결된 HTTP(S)(또는 DNS 기반) 부하 분산기(HEC 인스턴스가 여러 개 있는 경우)의 IP 주소입니다.port는 HEC 포트 번호입니다. 이는 선택사항이며 Splunk HEC 엔드포인트 구성에 따라 다릅니다.
유효한 Splunk HEC URL 입력 예시는
https://splunk-hec.example.com:8088입니다. 데이터를 Splunk Cloud Platform의 HEC로 전송하는 경우 Splunk Cloud의 HEC에 데이터 전송을 참조하여 특정 Splunk HEC URL의 위host및port부분을 확인합니다.Splunk HEC URL에 HEC 엔드포인트 경로가 포함되어서는 안 됩니다(예:
/services/collector). Pub/Sub to Splunk Dataflow 템플릿은 현재 JSON 형식의 이벤트에/services/collector엔드포인트만 지원하고 해당 경로를 Splunk HEC URL 입력에 자동으로 추가합니다. HEC 엔드포인트에 대한 자세한 내용은 서비스/수집기 엔드포인트의 Splunk 문서를 참조하세요.Pub/Sub to Splunk Dataflow 템플릿을 사용하여 Dataflow 파이프라인을 배포합니다.
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID-dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
JOB_NAME을pubsub-to-splunk-date+"%Y%m%d-%H%M%S"이름 형식으로 바꿉니다.선택적 매개변수
javascriptTextTransformGcsPath및javascriptTextTransformFunctionName은 공개적으로 사용 가능한 샘플 UDF(gs://splk-public/js/dataflow_udf_messages_replay.js)를 지정합니다. 샘플 UDF에는 실패한 전송을 재생하는 데 사용하는 이벤트 변환 및 디코딩 로직의 코드 예시가 포함되어 있습니다. UDF에 대한 자세한 내용은 UDF를 사용하여 진행 중인 이벤트 변환을 참조하세요.파이프라인 작업이 완료되면 출력에서 새 작업 ID를 찾아 작업 ID를 복사하고 저장합니다. 이 작업 ID를 이후 단계에서 입력합니다.
Splunk에서 로그 보기
Dataflow 파이프라인 작업자가 프로비저닝되어 Splunk HEC에 로그를 전송할 준비를 완료하는 데 몇 분 정도 걸립니다. Splunk Enterprise 또는 Splunk Cloud Platform 검색 인터페이스에서 로그가 올바르게 수신되었고 색인이 생성되었는지 확인할 수 있습니다. 모니터링 리소스 유형별 로그 수를 확인하려면 다음 안내를 따르세요.
Splunk에서 Splunk Search & Reporting(Splunk 검색 및 보고)을 엽니다.
MY_INDEX색인이 Splunk HEC 토큰에 대해 구성된index=[MY_INDEX] | stats count by resource.type검색을 실행합니다.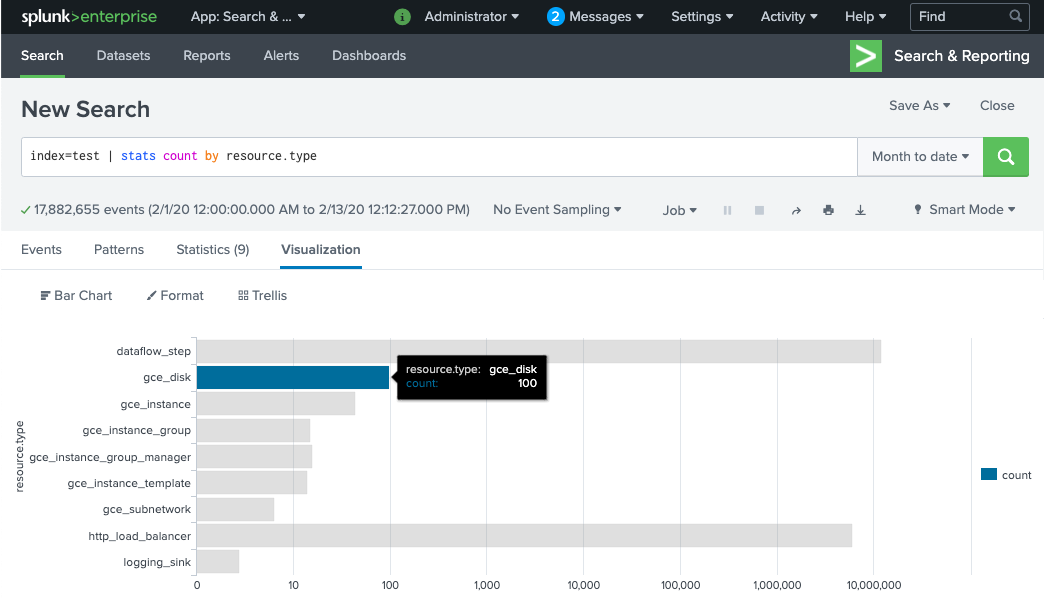
이벤트가 표시되지 않으면 전송 실패 처리를 참조하세요.
UDF를 사용하여 진행 중인 이벤트 변환
Pub/Sub to Splunk Dataflow 템플릿은 새 필드 추가 또는 이벤트별로 Splunk HEC 메타데이터 설정과 같은 커스텀 이벤트 변환을 위한 자바스크립트 UDF를 지원합니다. 배포한 파이프라인에서 이 샘플 UDF를 사용합니다.
이 섹션에서는 먼저 샘플 UDF 함수를 수정하여 새 이벤트 필드를 추가합니다. 이 새로운 필드는 발신 Pub/Sub 구독의 값을 추가 컨텍스트 정보로 지정합니다. 그런 다음 수정된 UDF로 Dataflow 파이프라인을 업데이트합니다.
샘플 UDF 수정
Cloud Shell에서 샘플 UDF 함수가 포함된 자바스크립트 파일을 다운로드합니다.
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
원하는 텍스트 편집기에서 자바스크립트 파일을 열고
event.inputSubscription필드를 찾은 후 해당 줄의 주석 처리를 삭제하고splunk-dataflow-pipeline을INPUT_SUBSCRIPTION_NAME으로 바꿉니다.event.inputSubscription = "INPUT_SUBSCRIPTION_NAME";
파일을 저장합니다.
파일을 Cloud Storage 버킷에 업로드합니다.
gsutil cp ./dataflow_udf_messages_replay.js gs://PROJECT_ID-dataflow/js/
새 UDF로 Dataflow 파이프라인 업데이트
Cloud Shell에서 Pub/Sub에서 이미 가져온 로그가 손실되지 않도록 드레이닝 옵션을 사용하여 파이프라인을 중지합니다.
gcloud dataflow jobs drain JOB_ID --region=REGION
업데이트된 UDF를 사용하여 Dataflow 파이프라인 작업을 실행합니다.
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://PROJECT_ID-dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
JOB_NAME을pubsub-to-splunk-date+"%Y%m%d-%H%M%S"이름 형식으로 바꿉니다.
전송 실패 처리
이벤트 처리 또는 Splunk HEC 연결 중의 오류로 인해 전송 실패가 발생할 수 있습니다. 이 섹션에서는 전송 실패를 도입하여 오류 처리 워크플로를 보여줍니다. 또한 실패한 메시지 Splunk로 다시 전송을 보고 트리거하는 방법도 알아봅니다.
전송 실패 트리거
Splunk에 전송 실패를 수동으로 도입하려면 다음 중 하나를 수행합니다.
- 단일 인스턴스를 실행하는 경우 Splunk 서버를 중지하여 연결 오류를 유발합니다.
- Splunk 입력 구성에서 관련 HEC 토큰을 중지합니다.
실패한 메시지 문제 해결
Google Cloud 콘솔을 사용하여 실패한 메시지를 조사할 수 있습니다.
Google Cloud 콘솔에서 Pub/Sub 구독 페이지로 이동합니다.
만든 처리되지 않은 구독을 클릭합니다. 앞의 예시를 사용한 경우 구독 이름은
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME입니다.메시지 뷰어를 열려면 메시지 보기를 클릭합니다.
메시지를 보려면 확인 메시지 사용 설정을 비워둔 채 가져오기를 클릭합니다.
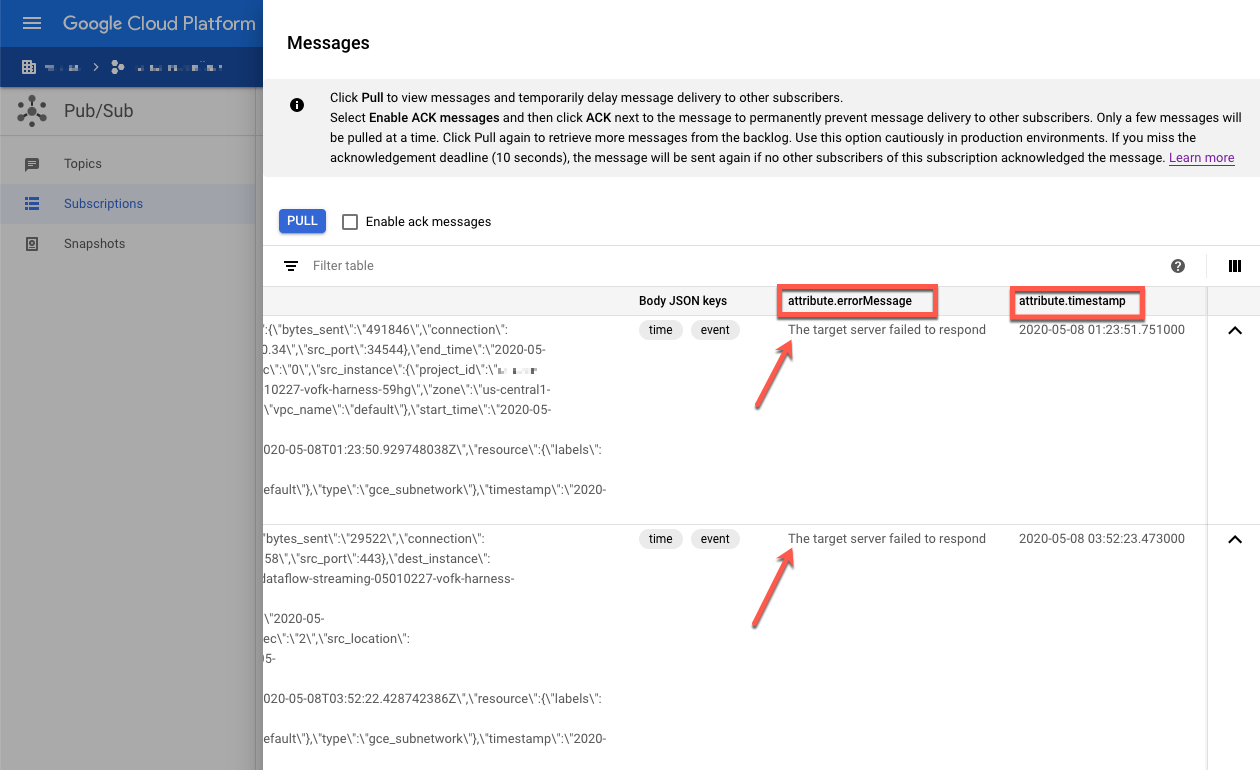
실패한 메시지를 검사합니다. 다음 사항에 유의하세요.
Message body열 아래의 Splunk 이벤트 페이로드attribute.errorMessage열 아래의 오류 메시지attribute.timestamp열 아래의 오류 타임스탬프
다음 스크린샷에서는 Splunk HEC 엔드포인트가 일시적으로 중단되거나 연결할 수 없을 때 표시되는 실패 메시지의 예시를 보여줍니다. errorMessage 속성의 텍스트는 The target server failed to respond로 표시됩니다.
또한 이 메시지에서는 각 실패와 관련된 타임스탬프를 보여줍니다. 이 타임스탬프를 사용하여 실패 근본 원인을 해결할 수 있습니다.
실패한 메시지 재생
이 섹션에서는 Splunk 서버를 다시 시작하거나 Splunk HEC 엔드포인트를 사용 설정하여 전송 오류를 수정해야 합니다. 그러면 처리되지 않은 메시지를 재생할 수 있습니다.
Splunk에서 다음 방법 중 하나를 사용하여 Google Cloud에 대한 연결을 복원합니다.
- Splunk 서버를 중지한 경우 서버를 다시 시작합니다.
- 트리거 전송 실패 섹션에서 Splunk HEC 엔드포인트를 사용 중지한 경우 Splunk HEC 엔드포인트가 현재 작동하는지 확인합니다.
Cloud Shell에서 이 구독의 메시지를 다시 처리하기 전에 처리되지 않은 구독의 스냅샷을 만듭니다. 스냅샷은 예기치 않은 구성 오류가 발생할 경우의 메시지 손실을 방지합니다.
gcloud pubsub snapshots create SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME
SNAPSHOT_NAME을 스냅샷을 식별하는 데 도움이 되는 이름(예:dead-letter-snapshot-date+"%Y%m%d-%H%M%S)으로 바꿉니다.Pub/Sub to Splunk Dataflow 템플릿을 사용하여 Pub/Sub to Pub/Sub 파이프라인을 만듭니다. 파이프라인은 다른 Dataflow 작업을 사용하여 메시지를 처리되지 않은 구독에서 다시 입력 주제로 전송합니다.
DATAFLOW_INPUT_TOPIC="INPUT_TOPIC_NAME" DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME" JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs run JOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n1-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME,\ outputTopic=projects/PROJECT_ID/topics/INPUT_TOPIC_NAME
명령어 결과에서 Dataflow 작업 ID를 복사하고 나중에 사용할 수 있도록 저장합니다. Dataflow 작업을 드레이닝할 때 이 작업 ID를
REPLAY_JOB_ID로 입력합니다.Google Cloud 콘솔에서 Pub/Sub 구독 페이지로 이동합니다.
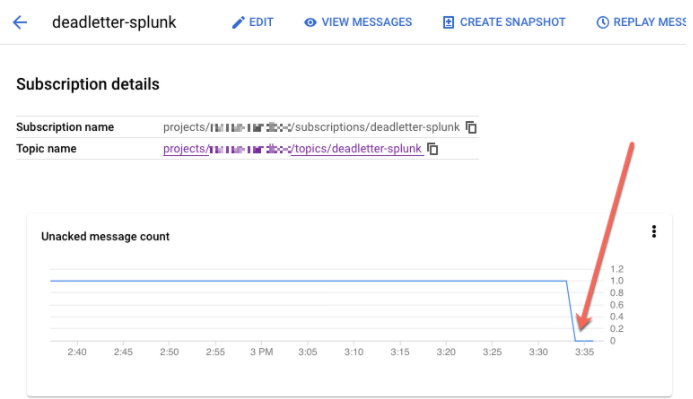
처리되지 않은 구독을 선택합니다. 다음 스크린샷과 같이 미확인 메시지 수 그래프가 0인지 확인합니다.
Cloud Shell에서 만든 Dataflow 작업을 드레이닝합니다.
gcloud dataflow jobs drain REPLAY_JOB_ID --region=REGION
REPLAY_JOB_ID를 이전에 저장한 Dataflow 작업 ID로 바꿉니다.
메시지가 원래 입력 주제로 다시 전송되면 기본 Dataflow 파이프라인이 실패한 메시지를 자동으로 선택하여 Splunk에 다시 전송합니다.
Splunk에서 메시지 확인
메시지가 다시 전송되었는지 확인하려면 Splunk에서 Splunk Search & Reporting(Splunk 검색 및 보고)을 엽니다.
delivery_attempts > 1에 대해 검색을 실행합니다. 이는 샘플 UDF가 전송 시도 횟수를 추적하기 위해 각 이벤트에 추가하는 특수 필드입니다. 이벤트 타임스탬프는 색인 생성 시간이 아닌 원래 생성 시간이므로 이전에 발생했을 수 있는 이벤트가 포함되도록 검색 시간 범위를 확장해야 합니다.
다음 스크린샷에서는 원래 실패한 메시지 두 개가 이제 올바른 타임스탬프와 함께 Splunk에 성공적으로 전송되었으며 색인이 생성되었습니다.
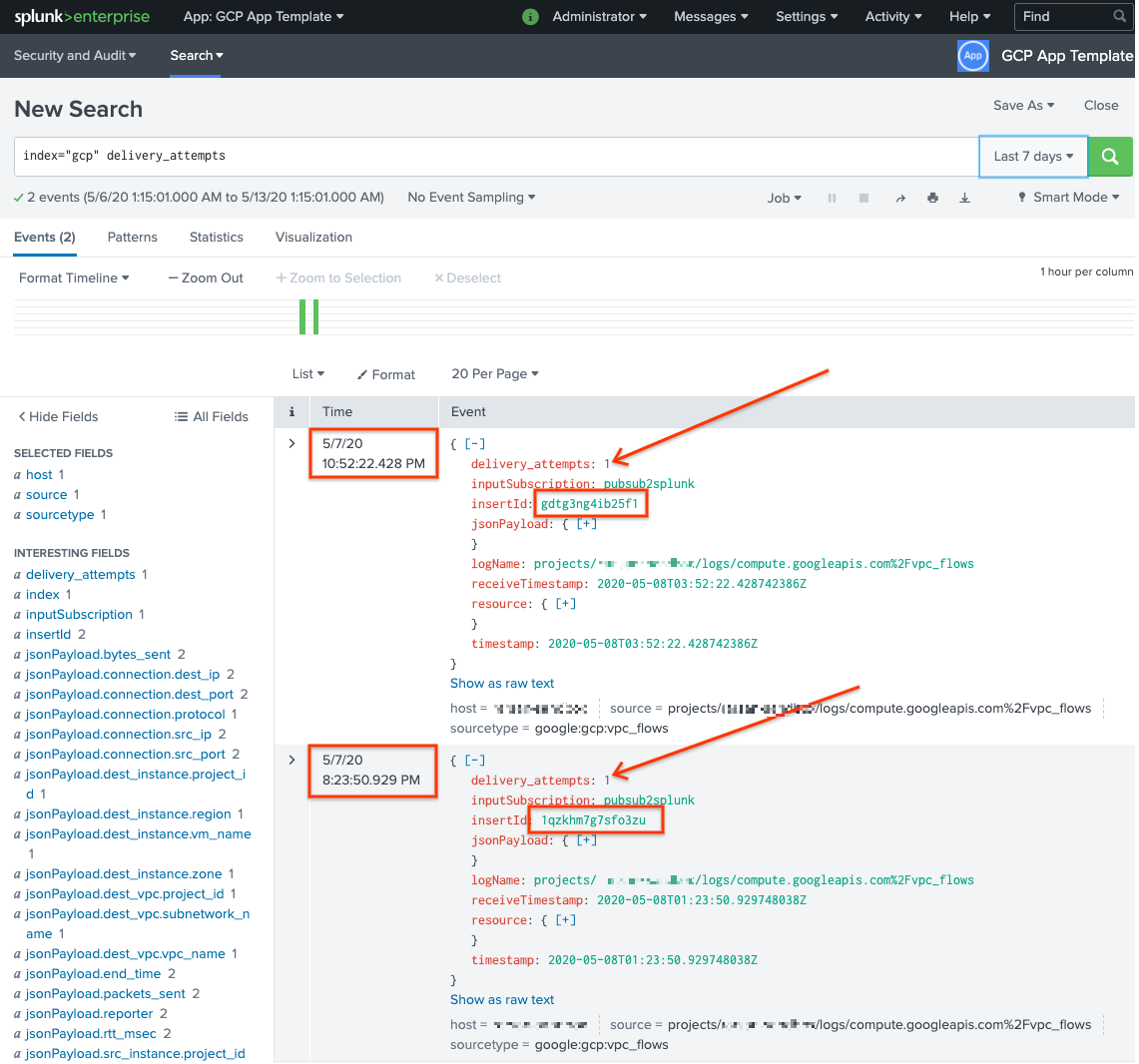
insertId 필드 값은 처리되지 않은 구독을 볼 때 실패한 메시지에 표시되는 값과 동일합니다.
insertId 필드는 Cloud Logging이 원래 로그 항목에 할당하는 고유 식별자입니다. insertId는 Pub/Sub 메시지 본문에도 표시됩니다.
삭제
이 참조 아키텍처에서 사용된 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
조직 수준 싱크 삭제
- 다음 명령어를 사용하여 조직 수준의 로그 싱크를 삭제합니다.
gcloud logging sinks delete ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
프로젝트 삭제
로그 싱크를 삭제하면 로그를 수신하고 내보내기 위해 만든 리소스 삭제를 계속 진행할 수 있습니다. 가장 쉬운 방법은 참조 아키텍처를 위해 만든 프로젝트를 삭제하는 것입니다.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- Pub/Sub to Splunk Dataflow 템플릿 매개변수의 전체 목록은 Pub/Sub to Splunk Dataflow 문서를 참조하세요.
- 이 참조 아키텍처를 배포하는 데 도움이 되는 해당 Terraform 템플릿은
terraform-splunk-log-exportGitHub 저장소를 참조하세요. 여기에는 Splunk Dataflow 파이프라인을 모니터링할 수 있도록 사전 빌드된 Cloud Monitoring 대시보드가 포함됩니다. - Splunk Dataflow 파이프라인을 모니터링하고 문제를 해결하는 데 도움이 되는 Splunk Dataflow 커스텀 측정항목과 로깅에 대한 자세한 내용은 Splunk Dataflow 스트리밍 파이프라인을 위한 새로운 관측 가능성 기능 블로그를 참조하세요.
- 그 밖의 참조 아키텍처, 다이어그램, 튜토리얼, 권장사항을 알아보려면 클라우드 아키텍처 센터를 확인하세요.