Questo documento descrive come implementare un meccanismo di esportazione per eseguire lo streaming dei log dalle risorse Google Cloud a Splunk. Si presume che tu abbia già letto la corrispondente architettura di riferimento per questo caso d'uso.
Queste istruzioni sono rivolte agli amministratori di operazioni e sicurezza che vogliono eseguire lo streaming dei log da Google Cloud a Splunk. Devi conoscere Splunk e Splunk HTTP Event Collector (HEC) per utilizzare queste istruzioni per operazioni IT o casi d'uso di sicurezza. Sebbene non sia obbligatorio, è utile conoscere le pipeline di Dataflow, Pub/Sub, Cloud Logging, Identity and Access Management e Cloud Storage per questo deployment.
Per automatizzare i passaggi di deployment in questa architettura di riferimento utilizzando Infrastructure as Code (IaC), consulta il repository GitHub terraform-splunk-log-export.
Architettura
Il seguente diagramma mostra l'architettura di riferimento e dimostra come i dati dei log passano da Google Cloud a Splunk.

Come mostrato nel diagramma, Cloud Logging raccoglie i log in un sink di log a livello di organizzazione e li invia a Pub/Sub. Il servizio Pub/Sub crea un singolo argomento e una sottoscrizione per i log e li inoltra alla pipeline Dataflow principale. La pipeline Dataflow principale è una pipeline di elaborazione di flussi di dati da Pub/Sub a Splunk che estrae i log dalla sottoscrizione Pub/Sub e li invia a Splunk. Parallela alla pipeline Dataflow principale, la pipeline Dataflow secondaria è una pipeline di streaming Pub/Sub a Pub/Sub per riprodurre i messaggi in caso di mancata consegna. Al termine della procedura, Splunk Enterprise o la piattaforma Splunk Cloud agisce come endpoint HEC e riceve i log per ulteriori analisi. Per maggiori dettagli, consulta la sezione Architettura dell'architettura di riferimento.
Per eseguire il deployment di questa architettura di riferimento, svolgi le seguenti attività:
- Eseguire le attività di configurazione.
- Crea un sink di log aggregato in un progetto dedicato.
- Crea un argomento messaggi non recapitabili.
- Configura un endpoint HEC di Splunk.
- Configura la capacità della pipeline Dataflow.
- Esporta i log in Splunk.
- Trasforma i log o gli eventi in-flight utilizzando le funzioni definite dall'utente (UDF) all'interno della pipeline Splunk Dataflow.
- Gestisci gli errori di importazione per evitare la perdita di dati a causa di potenziali errori di configurazione o problemi di rete temporanei.
Prima di iniziare
Completa i seguenti passaggi per configurare un ambiente per la tua architettura di riferimento da Google Cloud a Splunk:
- Avvia un progetto, abilita la fatturazione e attiva le API.
- Concedi i ruoli IAM.
- Configura l'ambiente.
- Configura una rete sicura.
Apri un progetto, abilita la fatturazione e attiva le API
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Monitoring API, Secret Manager, Compute Engine, Pub/Sub, and Dataflow APIs.
Concedi ruoli IAM
Nella console Google Cloud, assicurati di disporre delle seguenti autorizzazioni di Identity and Access Management (IAM) per le risorse dell'organizzazione e del progetto. Per ulteriori informazioni, consulta Concessione, modifica e revoca dell'accesso alle risorse.
| Autorizzazioni | Ruoli predefiniti | Risorsa |
|---|---|---|
|
|
Organizzazione |
|
|
Progetto |
|
|
Progetto |
Se i ruoli IAM predefiniti non includono autorizzazioni sufficienti per svolgere le tue funzioni, crea un ruolo personalizzato. Un ruolo personalizzato ti offre l'accesso di cui hai bisogno e ti aiuta a seguire il principio del privilegio minimo.
Configura l'ambiente
In the Google Cloud console, activate Cloud Shell.
Imposta il progetto per la sessione Cloud Shell attiva:
gcloud config set project PROJECT_ID
Sostituisci
PROJECT_IDcon l'ID progetto.
Configurare una rete sicura
In questo passaggio, configuri la rete sicura prima di elaborare ed esportare i log in Splunk Enterprise.
Crea una rete VPC e una subnet:
gcloud compute networks create NETWORK_NAME --subnet-mode=custom gcloud compute networks subnets create SUBNET_NAME \ --network=NETWORK_NAME \ --region=REGION \ --range=192.168.1.0/24
Sostituisci quanto segue:
NETWORK_NAME: il nome della reteSUBNET_NAME: il nome della subnetREGION: la regione che vuoi utilizzare per questa rete
Crea una regola firewall per consentire alle macchine virtuali (VM) dei worker di Dataflow di comunicare tra loro:
gcloud compute firewall-rules create allow-internal-dataflow \ --network=NETWORK_NAME \ --action=allow \ --direction=ingress \ --target-tags=dataflow \ --source-tags=dataflow \ --priority=0 \ --rules=tcp:12345-12346
Questa regola consente il traffico interno tra le VM Dataflow che utilizzano le porte TCP 12345-12346. Inoltre, il servizio Dataflow imposta il tag
dataflow.Crea un gateway Cloud NAT:
gcloud compute routers create nat-router \ --network=NETWORK_NAME \ --region=REGION gcloud compute routers nats create nat-config \ --router=nat-router \ --nat-custom-subnet-ip-ranges=SUBNET_NAME \ --auto-allocate-nat-external-ips \ --region=REGION
Abilita l'accesso privato Google sulla subnet:
gcloud compute networks subnets update SUBNET_NAME \ --enable-private-ip-google-access \ --region=REGION
Crea un sink di log
In questa sezione crei l'emissario di sink di log a livello di organizzazione e la relativa destinazione Pub/Sub, insieme alle autorizzazioni necessarie.
In Cloud Shell, crea un argomento Pub/Sub e la relativa sottoscrizione come nuova destinazione di destinazione dei sink di log:
gcloud pubsub topics create INPUT_TOPIC_NAME gcloud pubsub subscriptions create \ --topic INPUT_TOPIC_NAME INPUT_SUBSCRIPTION_NAME
Sostituisci quanto segue:
INPUT_TOPIC_NAME: il nome dell'argomento Pub/Sub da utilizzare come destinazione del sink di logINPUT_SUBSCRIPTION_NAME: il nome dell'abbonamento Pub/Sub alla destinazione di destinazione dei sink di log
Crea lo sink di log dell'organizzazione:
gcloud logging sinks create ORGANIZATION_SINK_NAME \ pubsub.googleapis.com/projects/PROJECT_ID/topics/INPUT_TOPIC_NAME \ --organization=ORGANIZATION_ID \ --include-children \ --log-filter='NOT logName:projects/PROJECT_ID/logs/dataflow.googleapis.com'
Sostituisci quanto segue:
ORGANIZATION_SINK_NAME: il nome della destinazione nell'organizzazioneORGANIZATION_ID: l'ID della tua organizzazione
Il comando è costituito dai seguenti flag:
- Il flag
--organizationspecifica che si tratta di un sink di log a livello di organizzazione. - Il flag
--include-childrenè obbligatorio e garantisce che la sink di log a livello di organizzazione includa tutti i log di tutte le sottocartelle e tutti i progetti. - Il flag
--log-filterspecifica i log da instradare. In questo esempio, escludi i log delle operazioni di Dataflow specificamente per il progettoPROJECT_ID, perché la pipeline Dataflow di esportazione dei log genera più log durante l'elaborazione degli stessi. Il filtro impedisce alla pipeline di esportare i propri log, evitando un ciclo potenzialmente esponenziale. L'output include un account di servizio sotto forma dio#####-####@gcp-sa-logging.iam.gserviceaccount.com.
Concedi il ruolo IAM Publisher Pub/Sub all'account del servizio di sink di log nell'argomento Pub/Sub
INPUT_TOPIC_NAME. Questo ruolo consente all'account di servizio del sink di log di pubblicare messaggi nell'argomento.gcloud pubsub topics add-iam-policy-binding INPUT_TOPIC_NAME \ --member=serviceAccount:LOG_SINK_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/pubsub.publisher
Sostituisci
LOG_SINK_SERVICE_ACCOUNTcon il nome dell'account di servizio per il tuo sink di log.
Creare un argomento messaggi non recapitabili
Per evitare potenziali perdite di dati che si verificano quando la consegna di un messaggio non va a buon fine, devi creare un argomento per la posta in arrivo Pub/Sub e la sottoscrizione corrispondente. Il messaggio con errore viene archiviato nell'argomento per i messaggi inutilizzati finché un operatore o un esperto di affidabilità del sito non può esaminare e correggere l'errore. Per ulteriori informazioni, consulta la sezione Riproduci i messaggi non riusciti dell'architettura di riferimento.
In Cloud Shell, crea un argomento e una sottoscrizione Pub/Sub per la posta in arrivo per evitare la perdita di dati archiviando i messaggi non recapitabili:
gcloud pubsub topics create DEAD_LETTER_TOPIC_NAME gcloud pubsub subscriptions create --topic DEAD_LETTER_TOPIC_NAME DEAD_LETTER_SUBSCRIPTION_NAME
Sostituisci quanto segue:
DEAD_LETTER_TOPIC_NAME: il nome dell'argomento Pub/Sub che sarà l'argomento messaggi non recapitabiliDEAD_LETTER_SUBSCRIPTION_NAME: il nome dell'abbonamento Pub/Sub per l&#argomento messaggi non recapitabili
Configurare un endpoint HEC di Splunk
Nelle procedure che seguono, configuri un endpoint HEC di Splunk e memorizzi il token HEC appena creato come secret in Secret Manager. Quando esegui il deployment della pipeline Splunk Dataflow, devi fornire sia l'URL dell'endpoint sia il token.
Configurare l'HEC di Splunk
- Se non hai ancora un endpoint HEC di Splunk, consulta la documentazione di Splunk per scoprire come configurare un HEC di Splunk. Splunk HEC viene eseguito sul servizio Splunk Cloud Platform o sulla tua istanza Splunk Enterprise. Mantieni disattivata l'opzione di conferma dell'indice HEC di Splunk, poiché non è supportata da Splunk Dataflow.
- In Splunk, dopo aver creato un token HEC di Splunk, copia il valore del token.
- In Cloud Shell, salva il valore del token HEC di Splunk in un file temporaneo chiamato
splunk-hec-token-plaintext.txt.
Memorizza il token HEC di Splunk in Secret Manager
In questo passaggio, crei un secret e una singola versione del secret sottostante in cui memorizzare il valore del token HEC di Splunk.
In Cloud Shell, crea un segreto contenente il token HEC di Splunk:
gcloud secrets create hec-token \ --replication-policy="automatic"
Per ulteriori informazioni sui criteri di replica per i secret, consulta Scegliere un criterio di replica.
Aggiungi il token come versione del secret utilizzando i contenuti del file
splunk-hec-token-plaintext.txt:gcloud secrets versions add hec-token \ --data-file="./splunk-hec-token-plaintext.txt"
Elimina il file
splunk-hec-token-plaintext.txt, poiché non è più necessario.
Configura la capacità della pipeline Dataflow
La tabella seguente riassume le best practice generali consigliate per la configurazione delle impostazioni della capacità della pipeline Dataflow:
| Impostazione | Best practice generale |
|---|---|
|
Imposta la dimensione della macchina di riferimento |
|
Imposta il numero massimo di worker necessari per gestire il picco EPS previsto in base ai tuoi calcoli |
Parametro |
Imposta su 2 x vCPU/worker x il numero massimo di worker per massimizzare il numero di connessioni parallele HEC di Splunk |
|
Impostato su 10-50 eventi/richiesta per i log, a condizione che il ritardo massimo di buffering di due secondi sia accettabile |
Ricorda di utilizzare i tuoi valori e calcoli univoci quando esegui il deployment di questa architettura di riferimento nel tuo ambiente.
Imposta i valori per il tipo di macchina e il numero di macchine. Per calcolare i valori appropriati per il tuo ambiente cloud, consulta le sezioni Tipo di macchina e Numero di macchine dell'architettura di riferimento.
DATAFLOW_MACHINE_TYPE DATAFLOW_MACHINE_COUNT
Imposta i valori per il parallelismo e il conteggio batch di Dataflow. Per calcolare i valori appropriati per il tuo ambiente cloud, consulta le sezioni Parallelis e Conteggio batch dell'architettura di riferimento.
JOB_PARALLELISM JOB_BATCH_COUNT
Per ulteriori informazioni su come calcolare i parametri di capacità della pipeline Dataflow, consulta la sezione Considerazioni di progettazione per l'ottimizzazione di prestazioni e costi dell'architettura di riferimento.
Esportare i log utilizzando la pipeline Dataflow
In questa sezione esegui il deployment della pipeline Dataflow con i seguenti passaggi:
- Crea un bucket Cloud Storage e un account di servizio worker Dataflow.
- Concedi i ruoli e l'accesso all'account di servizio del worker Dataflow.
- Esegui il deployment della pipeline Dataflow.
- Visualizza i log in Splunk.
La pipeline invia i messaggi di log di Google Cloud all'HEC di Splunk.
Crea un bucket Cloud Storage e un account di servizio worker Dataflow
In Cloud Shell, crea un nuovo bucket Cloud Storage con un'impostazione di accesso uniforme a livello di bucket:
gcloud storage buckets create gs://PROJECT_ID-dataflow/ --uniform-bucket-level-access
Il bucket Cloud Storage che hai appena creato è il luogo in cui il job Dataflow gestisce i file temporanei.
In Cloud Shell, crea un account di servizio per i worker Dataflow:
gcloud iam service-accounts create WORKER_SERVICE_ACCOUNT \ --description="Worker service account to run Splunk Dataflow jobs" \ --display-name="Splunk Dataflow Worker SA"
Sostituisci
WORKER_SERVICE_ACCOUNTcon il nome che vuoi utilizzare per l'account di servizio worker Dataflow.
Concedi i ruoli e l'accesso all'account di servizio worker Dataflow
In questa sezione, concedi i ruoli richiesti all'account di servizio worker Dataflow come mostrato nella tabella seguente.
| Ruolo | Percorso | Finalità |
|---|---|---|
| Dataflow Admin |
|
Consenti all'account di servizio di agire come amministratore di Dataflow. |
| Dataflow Worker |
|
Consenti all'account di servizio di agire come worker Dataflow. |
| Storage Object Admin |
|
Abilitare l'account di servizio per accedere al bucket Cloud Storage utilizzato da Dataflow per i file temporanei. |
| Pub/Sub Publisher |
|
Consenti all'account di servizio di pubblicare i messaggi non riusciti nell'argomento messaggi non recapitabili Pub/Sub. |
| Pub/Sub Subscriber |
|
Consenti all'account di servizio di accedere all'abbonamento inserito. |
| Pub/Sub Viewer |
|
Consenti all'account di servizio di visualizzare l'abbonamento. |
| Secret Manager Secret Accessor |
|
Consenti all'account di servizio di accedere al secret contenente il token HEC di Splunk. |
In Cloud Shell, concedi all'account di servizio worker Dataflow i ruoli Dataflow Admin e Dataflow Worker di cui questo account ha bisogno per eseguire operazioni e attività di amministrazione dei job Dataflow:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/dataflow.worker"
Concedi all'account di servizio del worker Dataflow l'accesso per visualizzare e utilizzare i messaggi dall'abbonamento di input Pub/Sub:
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.subscriber"
gcloud pubsub subscriptions add-iam-policy-binding INPUT_SUBSCRIPTION_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.viewer"
Concedi all'account di servizio del worker Dataflow l'accesso per pubblicare eventuali messaggi non riusciti nell'argomento non elaborato Pub/Sub:
gcloud pubsub topics add-iam-policy-binding DEAD_LETTER_TOPIC_NAME \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/pubsub.publisher"
Concedi all'account di servizio worker Dataflow l'accesso al secret del token HEC di Splunk in Secret Manager:
gcloud secrets add-iam-policy-binding hec-token \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/secretmanager.secretAccessor"
Concedi all'account di servizio worker Dataflow l'accesso in lettura e scrittura al bucket Cloud Storage da utilizzare dal job Dataflow per l'organizzazione dei file temporanei:
gcloud storage buckets add-iam-policy-binding gs://PROJECT_ID-dataflow/ \ --member="serviceAccount:WORKER_SERVICE_ACCOUNT@PROJECT_ID.iam.gserviceaccount.com" --role=”roles/storage.objectAdmin”
Esegui il deployment della pipeline Dataflow
In Cloud Shell, imposta la seguente variabile di ambiente per l'URL HEC di Splunk:
export SPLUNK_HEC_URL=SPLUNK_HEC_URL
Sostituisci la variabile
SPLUNK_HEC_URLutilizzando il moduloprotocol://host[:port], dove:protocolèhttpohttps.hostè il nome di dominio completo (FQDN) o l'indirizzo IP dell'istanza HEC di Splunk o, se hai più istanze HEC, il bilanciatore del carico HTTP(S) (o basato su DNS) associato.portè il numero di porta HEC. È facoltativo e dipende dalla configurazione dell'endpoint HEC di Splunk.
Un esempio di input dell'URL HEC di Splunk valido è
https://splunk-hec.example.com:8088. Se invii dati a HEC sulla piattaforma Splunk Cloud, consulta Inviare dati a HEC su Splunk Cloud per determinare le partihosteportsopra indicate dell'URL HEC di Splunk specifico.L'URL HEC di Splunk non deve includere il percorso dell'endpoint HEC, ad esempio
/services/collector. Al momento, il modello Dataflow Pub/Sub-Splunk supporta solo l'endpoint/services/collectorper gli eventi in formato JSON e aggiunge automaticamente questo percorso all'input dell'URL HEC di Splunk. Per approfondire l'endpoint HEC, consulta la documentazione di Splunk relativa all'endpoint services/collector.Esegui il deployment della pipeline Dataflow utilizzando il modello Dataflow da Pub/Sub a Splunk:
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --staging-location=gs://PROJECT_ID-dataflow/temp/ \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://splk-public/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
Sostituisci
JOB_NAMEcon il formato del nomepubsub-to-splunk-date+"%Y%m%d-%H%M%S"I parametri facoltativi
javascriptTextTransformGcsPathejavascriptTextTransformFunctionNamespecificano una funzione UDF di esempio disponibile pubblicamente:gs://splk-public/js/dataflow_udf_messages_replay.js. La UDF di esempio include esempi di codice per la logica di decodifica e trasformazione degli eventi che utilizzi per riprodurre i caricamenti non riusciti. Per ulteriori informazioni sulle funzioni UDF, consulta Trasformare gli eventi in transito con le funzioni UDF.Al termine del job della pipeline, individua il nuovo ID job nell'output, copialo e salvalo. Inserisci questo ID job in un passaggio successivo.
Visualizzare i log in Splunk
Sono necessari alcuni minuti per eseguire il provisioning dei worker della pipeline Dataflow e per prepararli a inviare i log a Splunk HEC. Puoi verificare che i log vengano ricevuti e indicizzati correttamente nell'interfaccia di ricerca della piattaforma Splunk Enterprise o Splunk Cloud. Per visualizzare il numero di log per tipo di risorsa monitorata:
In Splunk, apri Ricerca e reporting di Splunk.
Esegui la ricerca
index=[MY_INDEX] | stats count by resource.typedove l'indiceMY_INDEXè configurato per il token HEC di Splunk: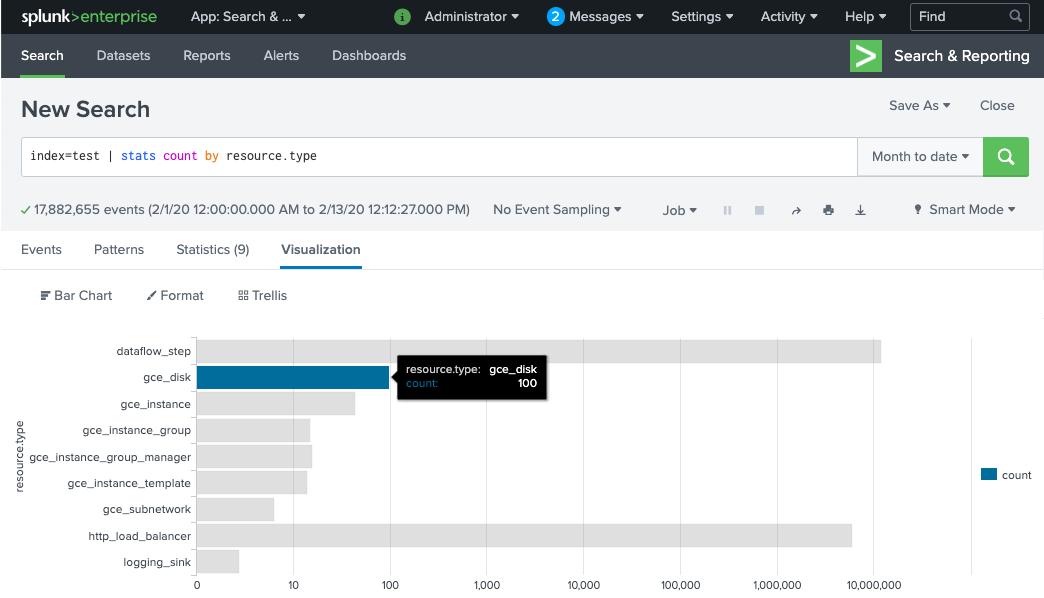
Se non vedi eventi, consulta Gestire gli errori di importazione.
Trasforma gli eventi in-flight con le UDF
Il modello Dataflow Pub/Sub to Splunk supporta una UDF JavaScript per la trasformazione di eventi personalizzati, ad esempio l'aggiunta di nuovi campi o l'impostazione dei metadati HEC di Splunk in base agli eventi. La pipeline di cui hai eseguito il deployment utilizza questa UDF di esempio.
In questa sezione, modifichi prima la funzione UDF di esempio per aggiungere un nuovo campo evento. Questo nuovo campo specifica il valore dell'abbonamento Pub/Sub di origine come informazioni contestuali aggiuntive. Poi, aggiorna la pipeline Dataflow con la UDF modificata.
Modifica la UDF di esempio
In Cloud Shell, scarica il file JavaScript contenente la funzione UDF di esempio:
wget https://storage.googleapis.com/splk-public/js/dataflow_udf_messages_replay.js
Nell'editor di testo che preferisci, apri il file JavaScript, individua il campo
event.inputSubscription, rimuovi il commento dalla riga e sostituiscisplunk-dataflow-pipelineconINPUT_SUBSCRIPTION_NAME:event.inputSubscription = "INPUT_SUBSCRIPTION_NAME";
Salva il file.
Carica il file nel bucket Cloud Storage:
gcloud storage cp ./dataflow_udf_messages_replay.js gs://PROJECT_ID-dataflow/js/
Aggiorna la pipeline Dataflow con la nuova UDF
In Cloud Shell, interrompi la pipeline utilizzando l'opzione Svuota per assicurarti che i log già estratti da Pub/Sub non vadano persi:
gcloud dataflow jobs drain JOB_ID --region=REGION
Esegui il job della pipeline Dataflow con la UDF aggiornata.
gcloud beta dataflow jobs run JOB_NAME \ --gcs-location=gs://dataflow-templates/latest/Cloud_PubSub_to_Splunk \ --worker-machine-type=DATAFLOW_MACHINE_TYPE \ --max-workers=DATAFLOW_MACHINE_COUNT \ --region=REGION \ --network=NETWORK_NAME \ --subnetwork=regions/REGION/subnetworks/SUBNET_NAME \ --disable-public-ips \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/INPUT_SUBSCRIPTION_NAME,\ outputDeadletterTopic=projects/PROJECT_ID/topics/DEAD_LETTER_TOPIC_NAME,\ url=SPLUNK_HEC_URL,\ tokenSource=SECRET_MANAGER, \ tokenSecretId=projects/PROJECT_ID/secrets/hec-token/versions/1, \ batchCount=JOB_BATCH_COUNT,\ parallelism=JOB_PARALLELISM,\ javascriptTextTransformGcsPath=gs://PROJECT_ID-dataflow/js/dataflow_udf_messages_replay.js,\ javascriptTextTransformFunctionName=process
Sostituisci
JOB_NAMEcon il formato del nomepubsub-to-splunk-date+"%Y%m%d-%H%M%S"
Gestire gli errori di recapito
Gli errori di importazione possono verificarsi a causa di errori nell'elaborazione degli eventi o nella connessione all'HEC di Splunk. In questa sezione viene introdotto un errore di importazione per dimostrare il flusso di lavoro di gestione degli errori. Inoltre, scoprirai come visualizzare e attivare il nuovo invio dei messaggi non riusciti a Splunk.
Attivare i fallimenti di pubblicazione
Per introdurre manualmente un errore di importazione in Splunk, esegui una delle seguenti operazioni:
- Se esegui una singola istanza, arresta il server Splunk per causare errori di connessione.
- Disattiva il token HEC pertinente dalla configurazione di input di Splunk.
Risolvere i problemi relativi ai messaggi non riusciti
Per esaminare un messaggio non riuscito, puoi utilizzare la console Google Cloud:
Nella console Google Cloud, vai alla pagina Abbonamenti Pub/Sub.
Fai clic sull'abbonamento non elaborato che hai creato. Se hai utilizzato l'esempio precedente, il nome dell'abbonamento è:
projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME.Per aprire il visualizzatore dei messaggi, fai clic su Visualizza messaggi.
Per visualizzare i messaggi, fai clic su Pull, assicurandoti di lasciare deselezionata l'opzione Abilita messaggi di conferma.
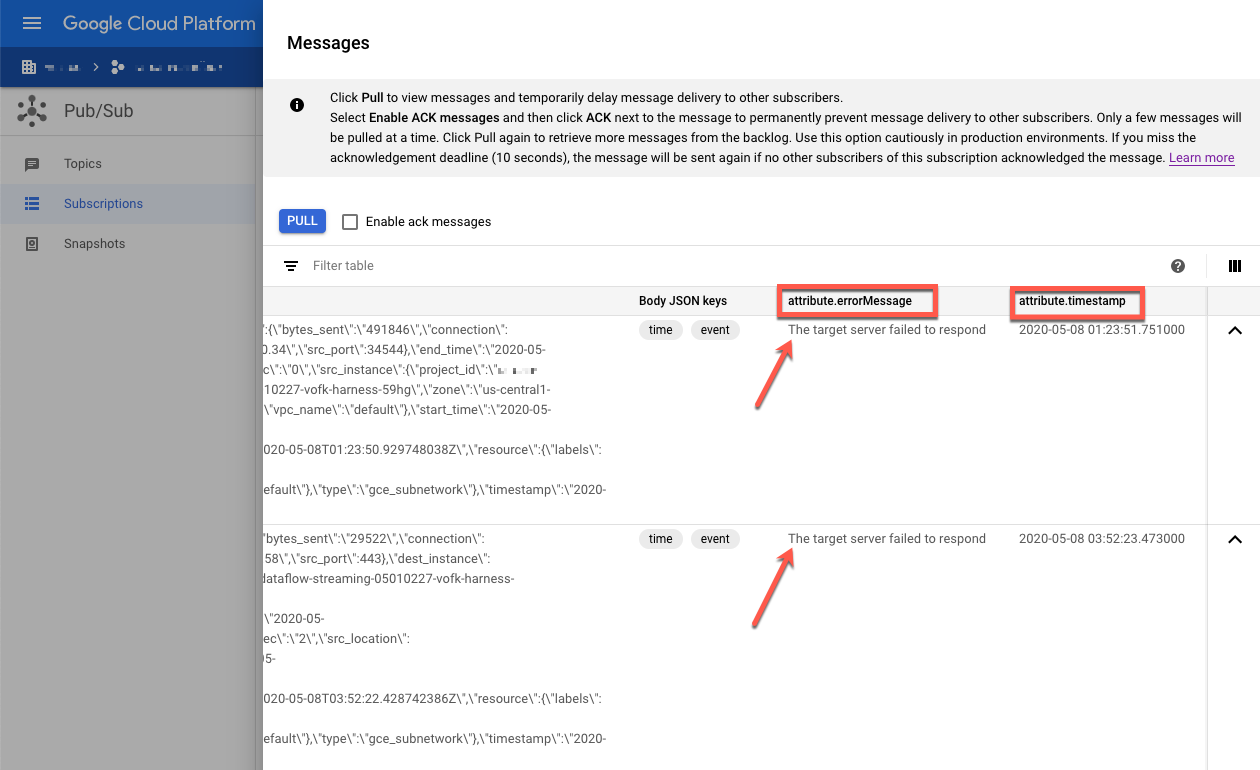
Controlla i messaggi non riusciti. Presta attenzione a quanto segue:
- Il payload dell'evento Splunk nella colonna
Message body. - Il messaggio di errore nella colonna
attribute.errorMessage. - Il timestamp dell'errore nella colonna
attribute.timestamp.
- Il payload dell'evento Splunk nella colonna
Lo screenshot seguente mostra un esempio di messaggio di errore che ricevi se l'endpoint HEC di Splunk è temporaneamente non disponibile o non raggiungibile. Tieni presente che il testo dell'attributo errorMessage è The target server failed to respond.
Il messaggio mostra anche il timestamp associato a ciascun errore. Puoi
utilizzare questo timestamp per risolvere il problema alla radice dell'errore.
Riproduci di nuovo i messaggi non riusciti
In questa sezione, devi riavviare il server Splunk o attivare l'endpoint HEC di Splunk per correggere l'errore di importazione. Puoi quindi riprodurre i messaggi non elaborati.
In Splunk, utilizza uno dei seguenti metodi per ripristinare la connessione a Google Cloud:
- Se hai interrotto il server Splunk, riavvialo.
- Se hai disattivato l'endpoint HEC di Splunk nella sezione Attivare gli errori di invio, verifica che l'endpoint HEC di Splunk sia ora operativo.
In Cloud Shell, acquisisci uno snapshot dell'abbonamento non elaborato prima di rielaborare i messaggi in questo abbonamento. Lo snapshot impedisce la perdita di messaggi in caso di errore di configurazione imprevisto.
gcloud pubsub snapshots create SNAPSHOT_NAME \ --subscription=DEAD_LETTER_SUBSCRIPTION_NAME
Sostituisci
SNAPSHOT_NAMEcon un nome che ti aiuti a identificare lo snapshot, ad esempiodead-letter-snapshot-date+"%Y%m%d-%H%M%S.Utilizza il modello Dataflow Pub/Sub to Splunk per creare una pipeline Pub/Sub to Pub/Sub. La pipeline utilizza un altro job Dataflow per trasferire i messaggi dalla sottoscrizione non elaborata all'argomento di input.
DATAFLOW_INPUT_TOPIC="INPUT_TOPIC_NAME" DATAFLOW_DEADLETTER_SUB="DEAD_LETTER_SUBSCRIPTION_NAME" JOB_NAME=splunk-dataflow-replay-date +"%Y%m%d-%H%M%S" gcloud dataflow jobs run JOB_NAME \ --gcs-location= gs://dataflow-templates/latest/Cloud_PubSub_to_Cloud_PubSub \ --worker-machine-type=n2-standard-2 \ --max-workers=1 \ --region=REGION \ --parameters \ inputSubscription=projects/PROJECT_ID/subscriptions/DEAD_LETTER_SUBSCRIPTION_NAME,\ outputTopic=projects/PROJECT_ID/topics/INPUT_TOPIC_NAME
Copia l'ID job Dataflow dall'output comando e salvalo per utilizzarlo in un secondo momento. Inserisci questo ID job come
REPLAY_JOB_IDquando svuoti il job Dataflow.Nella console Google Cloud, vai alla pagina Abbonamenti Pub/Sub.
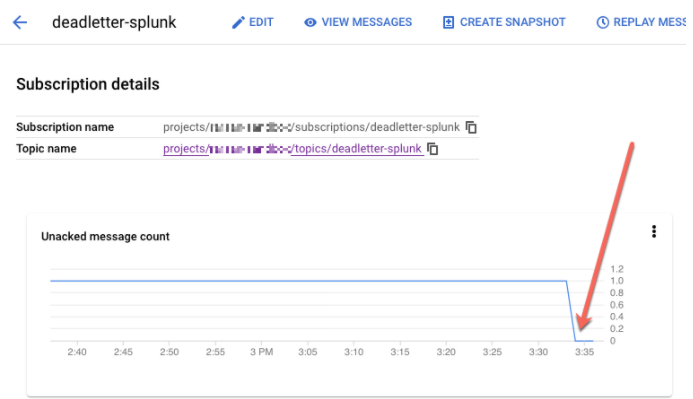
Seleziona l'abbonamento non elaborato. Verifica che il grafico Conteggio messaggi non confermati sia pari a 0, come mostrato nello screenshot seguente.
In Cloud Shell, svuota il job Dataflow che hai creato:
gcloud dataflow jobs drain REPLAY_JOB_ID --region=REGION
Sostituisci
REPLAY_JOB_IDcon l'ID job Dataflow che hai salvato in precedenza.
Quando i messaggi vengono trasferiti nuovamente all'argomento di input originale, la pipeline di Dataflow principale recupera automaticamente i messaggi non riusciti e li recapita a Splunk.
Confermare i messaggi in Splunk
Per verificare che i messaggi siano stati inviati di nuovo, in Splunk apri Splunk Search & Reporting.
Esegui una ricerca per
delivery_attempts > 1. Si tratta di un campo speciale che la UDF di esempio aggiunge a ogni evento per monitorare il numero di tentativi di invio. Assicurati di espandere l'intervallo di tempo di ricerca in modo da includere gli eventi che potrebbero essere stati registrati in passato, perché il timestamp dell'evento corrisponde all'ora originale di creazione, non all'ora di indicizzazione.
Nello screenshot seguente, i due messaggi che inizialmente non sono riusciti ora sono stati recapitati e indicizzati correttamente in Splunk con il timestamp corretto.
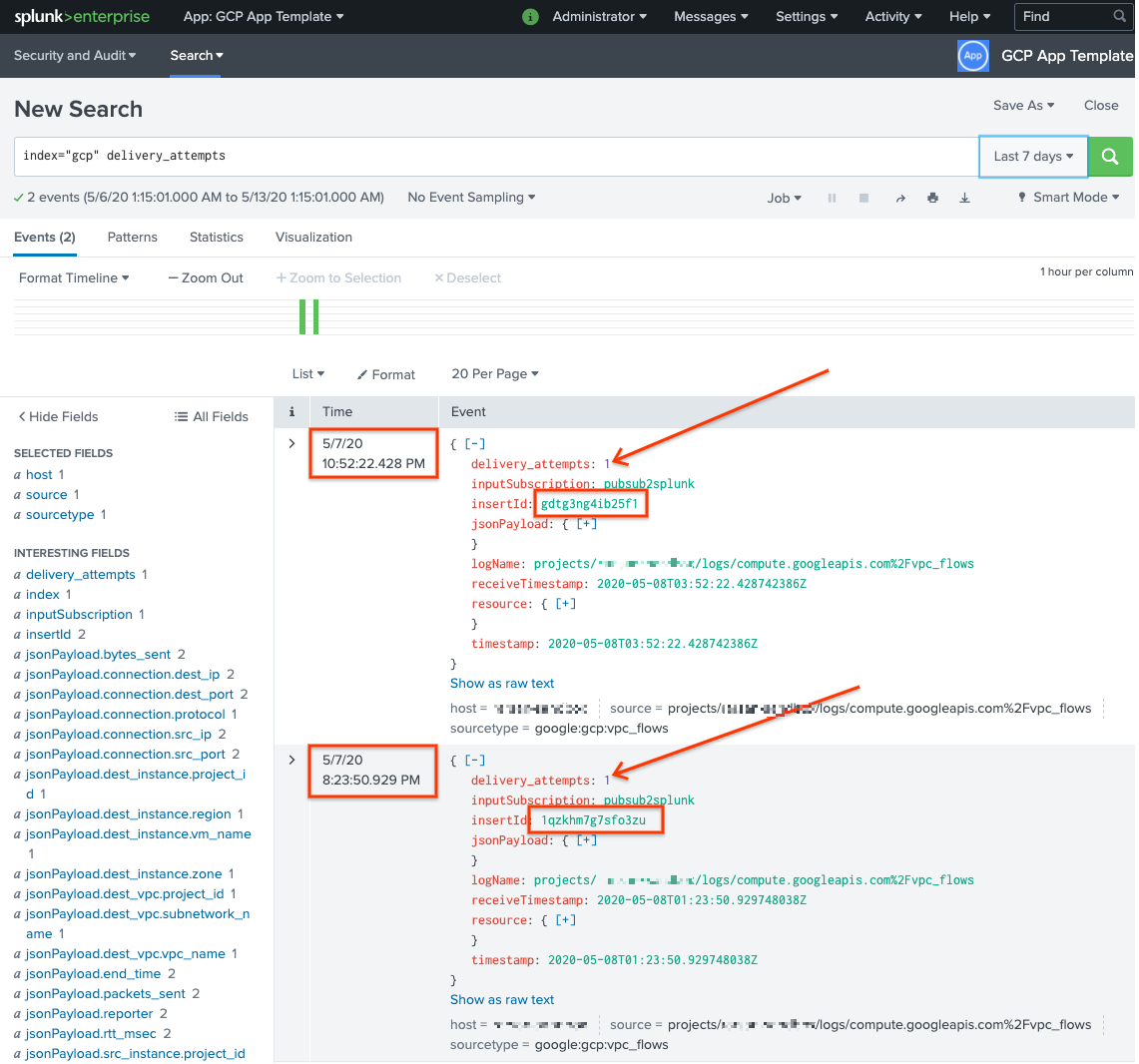
Tieni presente che il valore del campo insertId corrisponde a quello visualizzato nei messaggi di errore quando visualizzi l'abbonamento non elaborato.
Il campo insertId è un identificatore univoco assegnato da Cloud Logging alla
voce di log originale. insertId viene visualizzato anche nel corpo del messaggio Pub/Sub.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questa architettura di riferimento, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina l'emissario a livello di organizzazione
- Utilizza il seguente comando per eliminare il sink di log a livello di organizzazione:
gcloud logging sinks delete ORGANIZATION_SINK_NAME --organization=ORGANIZATION_ID
Elimina il progetto
Dopo aver eliminato il sink di log, puoi procedere con l'eliminazione delle risorse create per ricevere ed esportare i log. Il modo più semplice è eliminare il progetto che hai creato per l'architettura di riferimento.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Per un elenco completo dei parametri del modello Pub/Sub to Splunk Dataflow, consulta la documentazione di Pub/Sub to Splunk Dataflow.
- Per i modelli Terraform corrispondenti che ti aiutano a eseguire il deployment di questa architettura di riferimento, consulta il repository GitHub di
terraform-splunk-log-export. Include una dashboard di Cloud Monitoring predefinita per monitorare la pipeline Splunk Dataflow. - Per ulteriori dettagli sulle metriche personalizzate e sul logging di Splunk Dataflow per aiutarti a monitorare e risolvere i problemi delle pipeline di Splunk Dataflow, consulta questo blog Nuove funzionalità di osservabilità per le pipeline di streaming di Splunk Dataflow.
- Per altre architetture di riferimento, diagrammi e best practice, visita il Cloud Architecture Center.