Dokumen ini menjelaskan cara mengukur performa sistem inferensi TensorFlow yang Anda buat di Men-deploy sistem inferensi TensorFlow yang skalabel. Tutorial ini juga menunjukkan cara menerapkan penyesuaian parameter untuk meningkatkan throughput sistem.
Deployment didasarkan pada arsitektur referensi yang dijelaskan dalam Sistem inferensi TensorFlow yang skalabel.
Seri ini ditujukan bagi developer yang sudah memahami Google Kubernetes Engine dan framework machine learning (ML), termasuk TensorFlow dan TensorRT.
Dokumen ini tidak dimaksudkan untuk memberikan data performa sistem tertentu. Sebagai gantinya, tutorial ini menawarkan panduan umum tentang proses pengukuran performa. Metrik performa yang Anda lihat, seperti untuk Total Permintaan per Detik (RPS) dan Waktu Respons (ms), akan bervariasi bergantung pada model yang dilatih, versi software, dan konfigurasi hardware yang Anda gunakan.
Arsitektur
Untuk ringkasan arsitektur sistem inferensi TensorFlow, lihat Sistem inferensi TensorFlow yang skalabel.
Tujuan
- Menentukan tujuan dan metrik performa
- Mengukur performa dasar pengukuran
- Melakukan pengoptimalan grafik
- Mengukur konversi FP16
- Mengukur kuantisasi INT8
- Menyesuaikan jumlah instance
Biaya
Untuk mengetahui detail tentang biaya yang terkait dengan deployment, lihat Biaya.
Setelah menyelesaikan tugas yang dijelaskan dalam dokumen ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, lihat Pembersihan.
Sebelum memulai
Pastikan Anda telah menyelesaikan langkah-langkah dalam Men-deploy sistem inferensi TensorFlow yang skalabel.
Dalam dokumen ini, Anda akan menggunakan alat berikut:
- Terminal SSH dari instance kerja yang Anda siapkan di Membuat lingkungan kerja.
- Dasbor Grafana yang Anda siapkan di Men-deploy server pemantauan dengan Prometheus dan Grafana.
- Konsol Locust yang Anda siapkan dalam Men-deploy alat pengujian beban.
Menetapkan direktori
Di konsol Google Cloud, buka Compute Engine > VM instances.
Anda akan melihat instance
working-vmyang Anda buat.Untuk membuka konsol terminal instance, klik SSH.
Di terminal SSH, setel direktori saat ini ke subdirektori
client:cd $HOME/gke-tensorflow-inference-system-tutorial/clientDalam dokumen ini, Anda akan menjalankan semua perintah dari direktori ini.
Menentukan tujuan performa
Saat mengukur performa sistem inferensi, Anda harus menentukan tujuan performa dan metrik performa yang sesuai dengan kasus penggunaan sistem. Untuk tujuan demonstrasi, dokumen ini menggunakan tujuan performa sebagai berikut:
- Setidaknya 95% permintaan menerima respons dalam waktu 100 md.
- Total throughput, yang diwakili oleh permintaan per detik (RPS), meningkat tanpa mengganggu tujuan sebelumnya.
Dengan asumsi ini, Anda mengukur dan meningkatkan throughput model ResNet-50 berikut dengan pengoptimalan yang berbeda. Saat klien mengirim permintaan inferensi, klien akan menentukan model menggunakan nama model dalam tabel ini.
| Nama model | Pengoptimalan |
|---|---|
original |
Model asli (tanpa pengoptimalan dengan TF-TRT) |
tftrt_fp32 |
Pengoptimalan grafik (batch size: 64, grup instance: 1) |
tftrt_fp16 |
Konversi ke FP16 selain pengoptimalan grafik (ukuran batch: 64, grup instance: 1) |
tftrt_int8 |
Kuantisasi dengan INT8 selain pengoptimalan grafik (ukuran batch: 64, grup instance: 1) |
tftrt_int8_bs16_count4 |
Kuantisasi dengan INT8 selain pengoptimalan grafik (ukuran batch: 16, grup instance: 4) |
Mengukur performa dasar pengukuran
Anda memulai dengan menggunakan TF-TRT sebagai dasar pengukuran untuk mengukur performa model asli yang tidak dioptimalkan. Anda membandingkan performa model lain dengan model aslinya untuk mengevaluasi peningkatan performa secara kuantitatif. Saat Anda men-deploy Locust, aplikasi tersebut sudah dikonfigurasi untuk mengirim permintaan untuk model asli.
Buka konsol Locust yang Anda siapkan di Men-deploy alat pengujian beban.
Pastikan jumlah klien (disebut sebagai slaves) adalah 10.
Jika angkanya kurang dari 10, klien masih memulai. Dalam kasus ini, tunggu beberapa menit hingga menjadi 10.
Ukur performa:
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
3000. - Di kolom Rasio menetas, masukkan
5. - Untuk meningkatkan jumlah penggunaan yang disimulasikan sebesar 5 per detik hingga mencapai 3.000, klik Start swarming.
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
Klik Diagram.
Grafik menampilkan hasil performa. Perhatikan bahwa meskipun nilai Total Permintaan per Detik meningkat secara linear, nilai Waktu Respons (ms) juga meningkat.
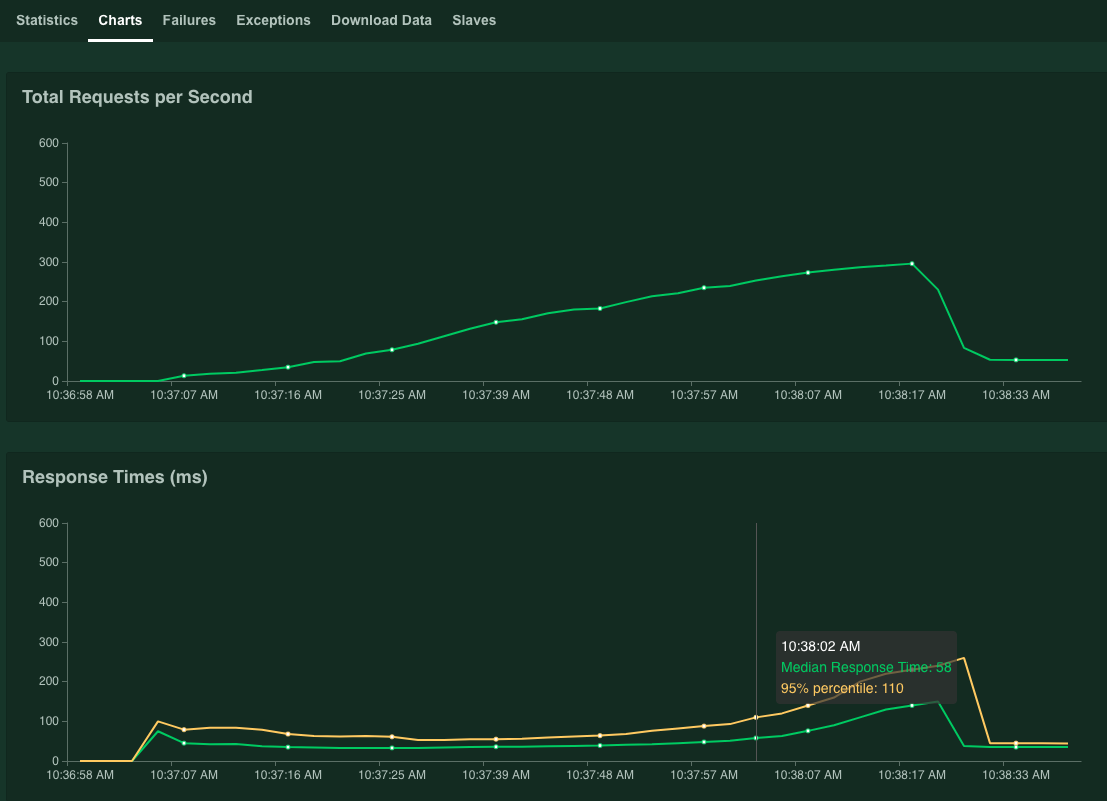
Ketika nilai persentil 95% dari Waktu Respons melebihi 100 milidetik, klik Stop untuk menghentikan simulasi.
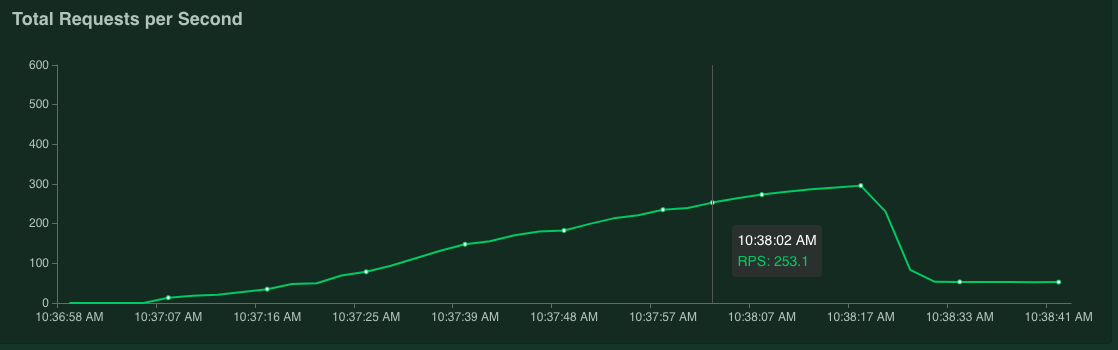
Jika Anda menahan kursor di atas grafik, Anda dapat memeriksa jumlah permintaan per detik yang sesuai dengan saat nilai 95% persentil Waktu Respons melebihi 100 milidetik.
Misalnya, dalam screenshot berikut, jumlah permintaan per detik adalah 253,1.
Sebaiknya Anda ulangi pengukuran ini beberapa kali dan mengambil nilai rata-rata untuk memperhitungkan fluktuasi.
Di terminal SSH, mulai ulang Locust:
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustUntuk mengulangi pengukuran, ulangi prosedur ini.
Mengoptimalkan grafik
Di bagian ini, Anda mengukur performa model tftrt_fp32, yang
dioptimalkan dengan TF-TRT untuk pengoptimalan grafik. Ini adalah pengoptimalan umum
yang kompatibel dengan sebagian besar kartu GPU NVIDIA.
Di terminal SSH, mulai ulang alat pengujian beban:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustResource
configmapmenentukan model sebagaitftrt_fp32.Mulai ulang server Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Tunggu beberapa menit hingga proses server siap.
Periksa status server:
kubectl get podsOutputnya mirip dengan berikut ini, dengan kolom
READYmenampilkan status server:NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sNilai
1/1di kolomREADYmenunjukkan bahwa server siap.Ukur performa:
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
3000. - Di kolom Rasio menetas, masukkan
5. - Untuk meningkatkan jumlah penggunaan yang disimulasikan sebesar 5 per detik hingga mencapai 3.000, klik Start swarming.
Grafik menunjukkan peningkatan performa pengoptimalan grafik TF-TRT.
Misalnya, grafik Anda mungkin menunjukkan bahwa jumlah permintaan per detik kini adalah 381 dengan waktu respons median 59 md.
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
Mengonversi ke FP16
Di bagian ini, Anda mengukur performa model tftrt_fp16, yang
dioptimalkan dengan TF-TRT untuk pengoptimalan grafik dan konversi FP16. Ini adalah
pengoptimalan yang tersedia untuk NVIDIA T4.
Di terminal SSH, mulai ulang alat pengujian beban:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustMulai ulang server Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Tunggu beberapa menit hingga proses server siap.
Ukur performa:
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
3000. - Di kolom Rasio menetas, masukkan
5. - Untuk meningkatkan jumlah penggunaan yang disimulasikan sebesar 5 per detik hingga mencapai 3.000, klik Start swarming.
Grafik menunjukkan peningkatan performa konversi FP16 selain pengoptimalan grafik TF-TRT.
Misalnya, grafik Anda mungkin menunjukkan bahwa jumlah permintaan per detik adalah 1.072,5 dengan waktu respons median 63 md.
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
Mengkuantisasi dengan INT8
Di bagian ini, Anda mengukur performa model tftrt_int8, yang
dioptimalkan dengan TF-TRT untuk pengoptimalan grafik dan kuantisasi INT8. Pengoptimalan
ini tersedia untuk NVIDIA T4.
Di terminal SSH, mulai ulang alat pengujian beban.
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustMulai ulang server Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Tunggu beberapa menit hingga proses server siap.
Ukur performa:
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
3000. - Di kolom Rasio menetas, masukkan
5. - Untuk meningkatkan jumlah penggunaan yang disimulasikan sebesar 5 per detik hingga mencapai 3.000, klik Start swarming.
Grafik menampilkan hasil performa.
Misalnya, grafik Anda mungkin menunjukkan bahwa jumlah permintaan per detik adalah 1.085,4 dengan waktu respons median 32 md.
Dalam contoh ini, hasilnya bukan peningkatan performa yang signifikan jika dibandingkan dengan konversi FP16. Secara teori, GPU NVIDIA T4 dapat menangani model kuantisasi INT8 lebih cepat daripada model konversi FP16. Dalam kasus ini, mungkin ada bottleneck selain performa GPU. Anda dapat mengonfirmasinya dari data penggunaan GPU di dasbor Grafana. Misalnya, jika pemakaian kurang dari 40%, artinya model tidak dapat sepenuhnya menggunakan performa GPU.
Seperti yang ditunjukkan pada bagian berikutnya, Anda mungkin dapat mengatasi bottleneck ini dengan meningkatkan jumlah grup instance. Misalnya, tambah jumlah grup instance dari 1 menjadi 4, dan kurangi ukuran batch dari 64 menjadi 16. Pendekatan ini mempertahankan jumlah total permintaan yang diproses pada satu GPU sebesar 64.
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
Menyesuaikan jumlah instance
Di bagian ini, Anda mengukur performa model tftrt_int8_bs16_count4. Model ini memiliki struktur yang sama dengan tftrt_int8, tetapi Anda mengubah ukuran batch dan jumlah grup instance seperti yang dijelaskan dalam Melakukan kuantisasi dengan INT8.
Di terminal SSH, mulai ulang Locust:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locustDalam perintah ini, Anda menggunakan resource
configmapuntuk menentukan model sebagaitftrt_int8_bs16_count4. Anda juga meningkatkan jumlah Pod klien Locust untuk menghasilkan beban kerja yang cukup untuk mengukur batasan performa model.Mulai ulang server Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Tunggu beberapa menit hingga proses server siap.
Ukur performa:
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
3000. - Di kolom Rasio menetas, masukkan
15. Untuk model ini, mungkin perlu waktu lama untuk mencapai batas performa jika Laju hatch ditetapkan ke5. - Untuk meningkatkan jumlah penggunaan yang disimulasikan sebesar 5 per detik hingga mencapai 3.000, klik Start swarming.
Grafik menampilkan hasil performa.
Misalnya, grafik Anda mungkin menunjukkan bahwa jumlah permintaan per detik adalah 2236,6 dengan waktu respons median 38 md.
Dengan menyesuaikan jumlah instance, Anda hampir menggandakan permintaan per detik. Perhatikan bahwa penggunaan GPU telah meningkat di dasbor Grafana (misalnya, penggunaan mungkin mencapai 75%).
- Di kolom Jumlah pengguna yang akan disimulasikan, masukkan
Performa dan beberapa node
Saat melakukan penskalaan dengan beberapa node, Anda mengukur performa satu Pod. Karena proses inferensi dijalankan secara independen di berbagai Pod yang berbeda dengan cara apa pun, Anda dapat berasumsi bahwa total throughput akan diskalakan secara linear dengan jumlah Pod. Asumsi ini berlaku selama tidak ada bottleneck seperti bandwidth jaringan antara klien dan server inferensi.
Namun, penting untuk memahami bagaimana permintaan inferensi diseimbangkan di antara beberapa server inferensi. Triton menggunakan protokol gRPC untuk membuat koneksi TCP antara klien dan server. Karena Triton menggunakan kembali koneksi yang sudah ada untuk mengirim beberapa permintaan inferensi, permintaan dari satu klien akan selalu dikirim ke server yang sama. Untuk mendistribusikan permintaan ke beberapa server, Anda harus menggunakan beberapa klien.
Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam seri ini, Anda dapat menghapus project.
Menghapus project
- Di konsol Google Cloud, buka halaman Manage resource.
- Pada daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
Langkah selanjutnya
- Pelajari cara mengonfigurasi resource komputasi untuk prediksi.
- Pelajari Google Kubernetes Engine (GKE) lebih lanjut.
- Pelajari Cloud Load Balancing lebih lanjut.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.