Questo documento descrive come misurare le prestazioni di TensorFlow di inferenza che hai creato Esegui il deployment di un sistema di inferenza TensorFlow scalabile. Mostra inoltre come applicare l'ottimizzazione dei parametri per migliorare la velocità effettiva del sistema.
Il deployment si basa sull'architettura di riferimento descritta in Sistema di inferenza TensorFlow scalabile.
Questa serie è rivolta agli sviluppatori che hanno familiarità con Google Kubernetes Engine e con i framework di machine learning (ML), tra cui TensorFlow e TensorRT.
Questo documento non è allo scopo di fornire i dati sulle prestazioni di un particolare sistema. Invece, offre indicazioni generali sul processo di misurazione delle prestazioni. Le metriche sul rendimento che vedi, ad esempio per le richieste totali al secondo (RPS) e i tempi di risposta (ms), variano in base al modello addestrato, alle versioni software e alle configurazioni hardware che utilizzi.
Architettura
Per una panoramica dell'architettura del sistema di inferenza di TensorFlow, consulta Sistema di inferenza TensorFlow scalabile.
Obiettivi
- Definisci l'obiettivo di rendimento e le metriche
- Misurare il rendimento di riferimento
- Ottimizza il grafico
- Misurare la conversione FP16
- Misura la quantizzazione di INT8
- Modifica il numero di istanze
Costi
Per informazioni dettagliate sui costi associati al deployment, consulta Costi.
Una volta completate le attività descritte in questo documento, puoi evitare la fatturazione continua eliminando le risorse che hai creato. Per ulteriori informazioni, consulta la pagina Pulizia.
Prima di iniziare
Assicurati di aver già completato i passaggi descritti in Eseguire il deployment di un sistema di inferenza TensorFlow scalabile.
In questo documento vengono utilizzati i seguenti strumenti:
- Un terminale SSH dell'istanza di lavoro che hai preparato in Creare un ambiente di lavoro.
- La Grafana che hai preparato nella Esegui il deployment dei server di monitoraggio con Prometheus e Grafana.
- La console Locust che hai preparato in Eseguire il deployment di uno strumento di test di carico.
Imposta la directory
Nella console Google Cloud, vai a Compute Engine > Istanze VM.
Vedrai l'istanza
working-vmche hai creato.Per aprire la console del terminale dell'istanza, fai clic su SSH.
Nel terminale SSH, imposta la directory corrente sulla sottodirectory
client:cd $HOME/gke-tensorflow-inference-system-tutorial/clientIn questo documento vengono eseguiti tutti i comandi da questa directory.
Definisci l'obiettivo di rendimento
Quando misuri le prestazioni dei sistemi di inferenza, devi definire l'obiettivo di rendimento e le metriche di prestazioni appropriate in base all'uso caso del sistema. A scopo dimostrativo, il presente documento utilizza le seguenti informazioni: obiettivi di rendimento:
- Almeno il 95% delle richieste riceve risposte entro 100 ms.
- La velocità effettiva totale, rappresentata dalle richieste al secondo (RPS), migliora senza interrompere il l'obiettivo precedente.
Utilizzando queste ipotesi, misuri e migliori la velocità effettiva del seguente ResNet-50 di grandi dimensioni con ottimizzazioni diverse. Quando un client invia richieste di inferenza, specifica il modello usando il nome del modello in questa tabella.
| Nome modello | Ottimizzazione |
|---|---|
original |
Modello originale (nessuna ottimizzazione con TF-TRT) |
tftrt_fp32 |
Ottimizzazione del grafico (dimensione del batch: 64, gruppi di istanze: 1) |
tftrt_fp16 |
Conversione in FP16 oltre all'ottimizzazione del grafico (dimensione batch: 64, gruppi di istanze: 1) |
tftrt_int8 |
Quantizzazione con INT8 oltre all'ottimizzazione del grafico (dimensione batch: 64, gruppi di istanze: 1) |
tftrt_int8_bs16_count4 |
Quantizzazione con INT8 oltre all'ottimizzazione del grafico (dimensione batch: 16, gruppi di istanze: 4) |
Misurare il rendimento di base
Inizia utilizzando TF-TRT come linea di base per misurare le prestazioni del modello originale non ottimizzato. Confronti le prestazioni di altri modelli con dell'originale per valutare quantitativamente il miglioramento del rendimento. Quando hai eseguito il deployment di Locust, era già configurato per inviare richieste per modello originale.
Apri la console Locust che hai preparato in Eseguire il deployment di uno strumento di test di carico.
Verifica che il numero di client (indicati come schiavi) sia 10.
Se il numero è inferiore a 10, i client sono ancora in fase di avvio. In questo caso, attendi qualche minuto finché non diventi 10.
Misura il rendimento:
- Nel campo Numero di utenti da simulare, inserisci
3000. - Nel campo Percentuale di tratteggio, inserisci
5. - Per aumentare il numero di utilizzi simulati di 5 al secondo fino a raggiungere i 3000, fai clic su Avvia lo swarming.
- Nel campo Numero di utenti da simulare, inserisci
Fai clic su Grafici.
I grafici mostrano i risultati del rendimento. Tieni presente che, anche se il valore delle richieste totali al secondo aumenta in modo lineare, il valore Tempi di risposta (ms) aumenta di conseguenza.
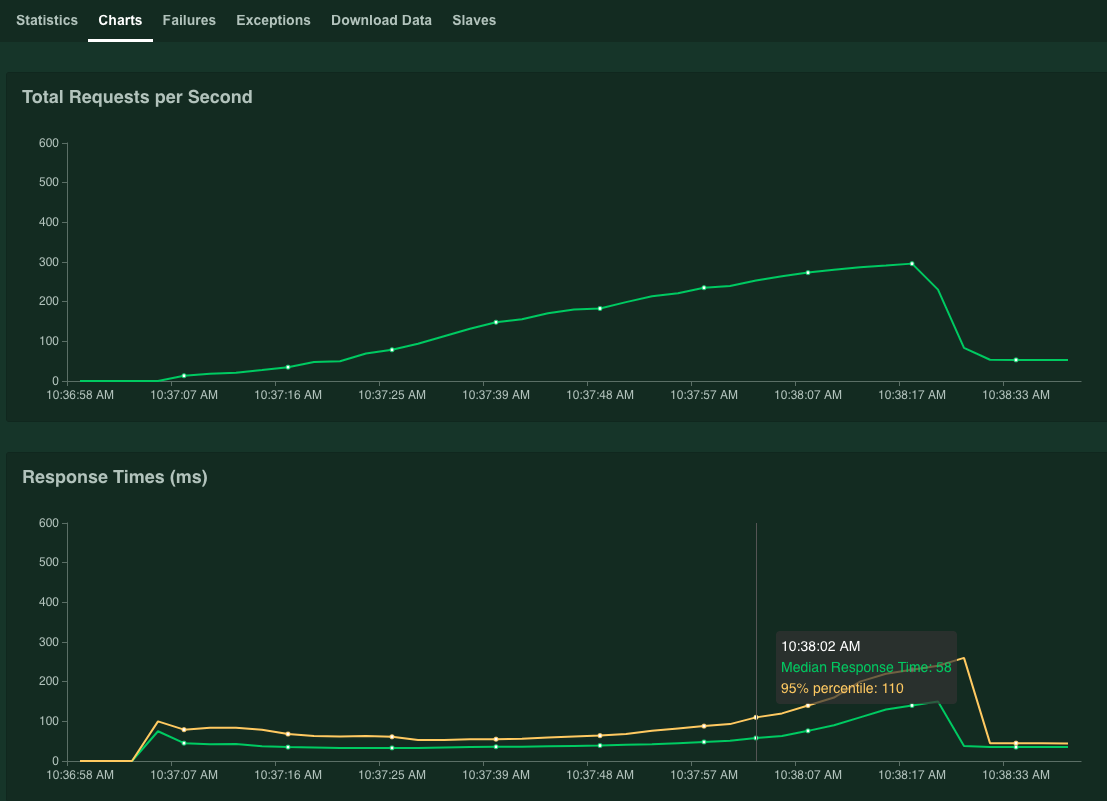
Quando il 95% percentile di tempi di risposta supera 100 ms, fai clic Interrompi per arrestare la simulazione.
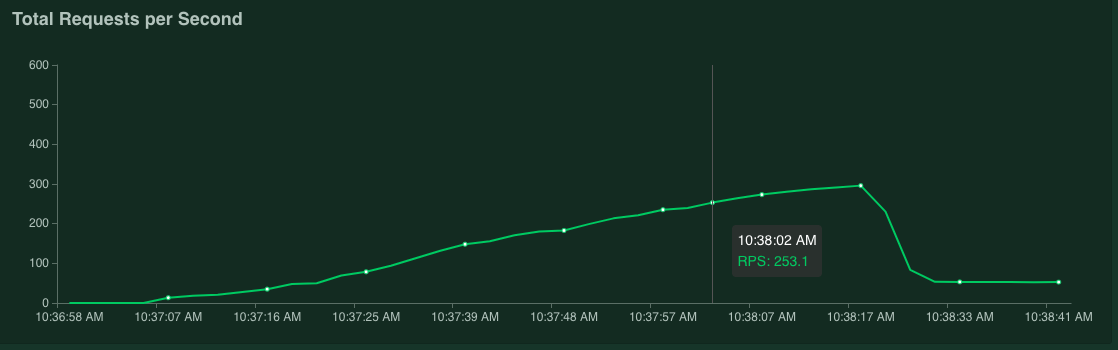
Se tieni il puntatore sopra puoi controllare il numero di richieste al secondo corrispondente a quando il valore del 95% del percentile dei tempi di risposta ha superato i 100 ms.
Ad esempio, nello screenshot seguente, il numero di richieste al secondo è 253,1.
Ti consigliamo di ripetere la misurazione più volte e calcolare una media per tenere conto delle fluttuazioni.
Nel terminale SSH, riavvia Locust:
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustPer ripetere la misurazione, ripeti questa procedura.
Ottimizzare i grafici
In questa sezione misurerai le prestazioni del modello tftrt_fp32, che è
ottimizzate con TF-TRT per l'ottimizzazione del grafico. Questa è un'ottimizzazione comune
compatibile con la maggior parte delle schede GPU NVIDIA.
Nel terminale SSH, riavvia lo strumento di test di carico:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustLa risorsa
configmapspecifica il modello cometftrt_fp32.Riavvia il server Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Attendi qualche minuto finché i processi del server non sono pronti.
Controlla lo stato del server:
kubectl get podsL'output è simile al seguente, in cui la colonna
READYmostra il valore stato del server:NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sIl valore
1/1nella colonnaREADYindica che il server è pronto.Misura il rendimento:
- Nel campo Numero di utenti da simulare, inserisci
3000. - Nel campo Percentuale di tratteggio, inserisci
5. - Per aumentare il numero di utilizzi simulati di 5 al secondo fino a raggiungere i 3000, fai clic su Avvia lo swarming.
I grafici mostrano il miglioramento delle prestazioni dell'ottimizzazione del grafico TF-TRT.
Ad esempio, il grafico potrebbe mostrare che il numero di richieste al secondo è ora di 381 con un tempo di risposta mediano di 59 ms.
- Nel campo Numero di utenti da simulare, inserisci
Converti in FP16
In questa sezione, misuri le prestazioni del modello tftrt_fp16, che è ottimizzato con TF-TRT per l'ottimizzazione del grafo e la conversione FP16. Si tratta di un
per NVIDIA T4.
Nel terminale SSH, riavvia lo strumento di test del carico:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustRiavvia il server Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Attendi qualche minuto fino al completamento dei processi del server.
Misura il rendimento:
- Nel campo Numero di utenti da simulare, inserisci
3000. - Nel campo Percentuale di tratteggio, inserisci
5. - Per aumentare il numero di utilizzi simulati di 5 al secondo fino a raggiungere i 3000, fai clic su Avvia lo swarming.
I grafici mostrano il miglioramento delle prestazioni della conversione FP16 oltre all'ottimizzazione del grafico TF-TRT.
Ad esempio, il grafico potrebbe mostrare che il numero di richieste al secondo è 1072.5 con un tempo di risposta mediano di 63 ms.
- Nel campo Numero di utenti da simulare, inserisci
Quantizzazione con INT8
In questa sezione misurerai le prestazioni del modello tftrt_int8, che è
ottimizzato con TF-TRT per l'ottimizzazione del grafico e la quantizzazione INT8. Questa ottimizzazione è disponibile per NVIDIA T4.
Nel terminale SSH, riavvia lo strumento di test del carico.
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustRiavvia il server Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Attendi qualche minuto fino al completamento dei processi del server.
Misura il rendimento:
- Nel campo Numero di utenti da simulare, inserisci
3000. - Nel campo Percentuale di tratteggio, inserisci
5. - Per aumentare il numero di utilizzi simulati di 5 al secondo fino a raggiungere i 3000, fai clic su Avvia lo swarming.
I grafici mostrano i risultati del rendimento.
Ad esempio, il grafico potrebbe mostrare che il numero di richieste al secondo è 1085.4 con un tempo di risposta mediano di 32 ms.
In questo esempio, il risultato non è un aumento significativo del rendimento rispetto alla conversione FP16. In teoria, NVIDIA T4 La GPU è in grado di gestire i modelli di quantizzazione INT8 più velocemente dei modelli di conversione FP16. In questo caso, potrebbe esserci un collo di bottiglia diverso dal rendimento della GPU. Puoi confermarlo dai dati sull'utilizzo della GPU nella dashboard di Grafana. Ad esempio, se l'utilizzo è inferiore al 40%, significa che il modello non può utilizzare completamente le prestazioni della GPU.
Come mostrato nella sezione successiva, potresti riuscire ad allentare questo collo di bottiglia aumentando il numero di gruppi di istanze. Ad esempio, aumenta il numero di gruppi di istanze da 1 a 4 e la dimensione del batch diminuirà da 64 a 16. Questo approccio mantiene il numero totale di richieste elaborate su una singola GPU a 64.
- Nel campo Numero di utenti da simulare, inserisci
Modifica il numero di istanze
In questa sezione, misuri le prestazioni del modellotftrt_int8_bs16_count4. Questo modello ha la stessa struttura di tftrt_int8, ma
modificherai la dimensione del batch e il numero di gruppi di istanze come descritto in Quantizzazione con INT8.
Nel terminale SSH, riavvia Locust:
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locustIn questo comando, utilizzi la risorsa
configmapper specificare il modello cometftrt_int8_bs16_count4. Inoltre, aumenta il numero di pod client Locust per generare carichi di lavoro sufficienti per misurare la limitazione delle prestazioni del modello.Riavvia il server Triton:
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1Attendi qualche minuto fino al completamento dei processi del server.
Misura il rendimento:
- Nel campo Numero di utenti da simulare, inserisci
3000. - Nel campo Tasso di schiusa, inserisci
15. Per questo modello potrebbe essere necessario molto tempo per raggiungere il limite di prestazioni se la Frequenza di tratteggio è impostata su5. - aumentare di 5 al secondo il numero di utilizzi simulati fino a raggiungere 3000, fai clic su Inizia lo swarming.
I grafici mostrano i risultati del rendimento.
Ad esempio, il grafico potrebbe mostrare che il numero di richieste al secondo è di 2236,6 con un tempo di risposta mediano di 38 ms.
Modificando il numero di istanze, puoi quasi raddoppiare le richieste al secondo. Nota che l'utilizzo delle GPU è aumentato su Grafana dashboard (ad esempio, l'utilizzo potrebbe raggiungere il 75%).
- Nel campo Numero di utenti da simulare, inserisci
Prestazioni e più nodi
Quando esegui il ridimensionamento con più nodi, misuri il rendimento di un singolo pod. Poiché i processi di inferenza vengono eseguiti in modo indipendente su pod diversi in modo condiviso, possiamo supporre che la velocità effettiva totale in modo lineare con il numero di pod. Questo presupposto si applica purché non siano presenti colli di bottiglia come la larghezza di banda della rete tra i client e i server di inferenza.
Tuttavia, è importante capire in che modo le richieste di inferenza vengono bilanciate tra più server di inferenza. Triton utilizza il protocollo gRPC per stabilire un TCP connessione tra un client e un server. Poiché Triton riutilizza lo standard connessione per l'invio di più richieste di inferenza, richieste da un vengono inviati sempre allo stesso server. Per distribuire le richieste per più server, devi utilizzare più client.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate. di questa serie, puoi eliminare il progetto.
Elimina il progetto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Scopri di più sulla configurazione delle risorse di computing per la previsione.
- Scopri di più su Google Kubernetes Engine (GKE).
- Scopri di più su Cloud Load Balancing.
- Per altre architetture di riferimento, diagrammi e best practice, esplora il Centro architetture cloud.