Questo documento illustra le tecniche per l'implementazione e l'automazione dell'integrazione continua (CI), della distribuzione continua (CD) e dell'addestramento continuo (CT) per i sistemi di machine learning (ML). Questo documento si applica principalmente ai sistemi di AI predittiva.
La data science e l'ML stanno diventando competenze fondamentali per risolvere problemi complessi del mondo reale, trasformare interi settori e generare valore in tutti i domini. Al momento, gli ingredienti per applicare il machine learning in modo efficace sono a tua disposizione:
- Set di dati di grandi dimensioni
- Risorse di computing on demand economiche
- Acceleratori specializzati per il ML su varie piattaforme cloud
- Rapid progressi in diversi campi di ricerca ML (come visione artificiale, comprensione del linguaggio naturale, AI generativa e sistemi di AI per i suggerimenti).
Pertanto, molte aziende stanno investendo nei propri team di data science e nelle proprie funzionalità di ML per sviluppare modelli predittivi in grado di offrire valore aziendale ai propri utenti.
Questo documento è rivolto a data scientist e ML engineer che vogliono applicare i principi di DevOps ai sistemi di machine learning (MLOps). MLOps è una cultura e una pratica di ingegneria ML che mira a unificare lo sviluppo di sistemi ML (Dev) e il funzionamento di sistemi ML (Ops). Mettere in pratica le MLOps significa promuovere l'automazione e il monitoraggio di tutte le fasi di creazione del sistema ML, tra cui integrazione, test, rilascio, deployment e gestione dell'infrastruttura.
I data scientist possono implementare e addestrare un modello ML con prestazioni predittive su un set di dati di holdout offline, dati dati di addestramento pertinenti per il loro caso d'uso. Tuttavia, la vera sfida non è la creazione di un modello ML, ma la creazione di un sistema ML integrato e il suo funzionamento continuo in produzione. Grazie alla lunga storia dei servizi ML di produzione in Google, abbiamo imparato che possono esserci molti problemi nel funzionamento dei sistemi basati su ML in produzione. Alcuni di questi problemi sono riassunti in Machine Learning: The High Interest Credit Card of Technical Debt.
Come mostrato nel seguente diagramma, solo una piccola parte di un sistema di ML reale è composta dal codice ML. Gli elementi circostanti richiesti sono vasti e complessi.
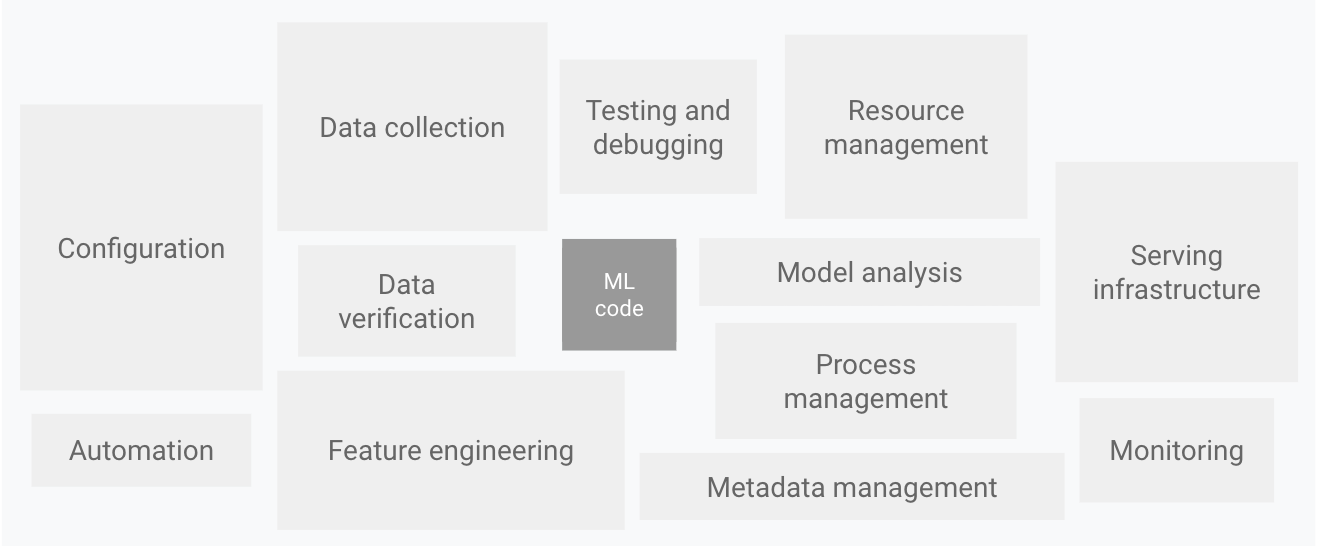
Figura 1. Elementi per i sistemi ML. Adattato da Hidden Technical Debt in Machine Learning Systems.
Il diagramma precedente mostra i seguenti componenti del sistema:
- Configurazione
- Automazione
- Raccolta dei dati
- Verifica dei dati
- Test e debug
- Gestione delle risorse
- Analisi dei modelli
- Gestione dei processi e dei metadati
- Infrastruttura di pubblicazione
- Monitoraggio
Per sviluppare e gestire sistemi complessi come questi, puoi applicare i principi DevOps ai sistemi ML (MLOps). Questo documento illustra i concetti da considerare quando configuri un ambiente MLOps per le tue pratiche di data science, come CI, CD e CT in ML.
Vengono trattati i seguenti argomenti:
- DevOps e MLOps
- Passaggi per lo sviluppo di modelli ML
- Livelli di maturità di MLOps
- MLOps per l'AI generativa
DevOps e MLOps
DevOps è una pratica popolare nello sviluppo e nel funzionamento di sistemi software su larga scala. Questa pratica offre vantaggi come l'accorciamento dei cicli di sviluppo, l'aumento della velocità di deployment e rilasci affidabili. Per ottenere questi vantaggi, introduci due concetti nello sviluppo del sistema software:
Un sistema ML è un sistema software, quindi si applicano pratiche simili per garantire di poter creare e gestire in modo affidabile sistemi ML su larga scala.
Tuttavia, i sistemi di ML differiscono dagli altri sistemi software per i seguenti motivi:
Competenze del team: in un progetto di ML, il team di solito include data scientist o ricercatori di ML, che si concentrano su analisi esplorativa dei dati, sviluppo di modelli e sperimentazione. Questi membri potrebbero non essere ingegneri software esperti in grado di creare servizi di livello di produzione.
Sviluppo: l'ML è sperimentale. Devi provare diverse funzionalità, algoritmi, tecniche di modellazione e configurazioni dei parametri per trovare ciò che funziona meglio per il problema nel più breve tempo possibile. La sfida consiste nel monitorare ciò che ha funzionato e ciò che non ha funzionato, nonché nel mantenere la riproducibilità massimizzando il riutilizzo del codice.
Test: il test di un sistema ML è più complesso rispetto al test di altri sistemi software. Oltre ai tipici test unitari e di integrazione, devi eseguire la convalida dei dati, la valutazione della qualità del modello addestrato e la convalida del modello.
Deployment: nei sistemi ML, il deployment non è semplice come il deployment di un modello ML addestrato offline come servizio di previsione. I sistemi ML possono richiedere di eseguire il deployment di una pipeline in più passaggi per eseguire automaticamente il retraining e il deployment dei modelli. Questa pipeline aggiunge complessità e richiede di automatizzare i passaggi che vengono eseguiti manualmente prima del deployment dai data scientist per addestrare e convalidare nuovi modelli.
Produzione: i modelli ML possono avere prestazioni ridotte non solo a causa di una codifica non ottimale, ma anche a causa di profili di dati in continua evoluzione. In altre parole, i modelli possono deteriorarsi in più modi rispetto ai sistemi software convenzionali e devi tenere conto di questo deterioramento. Pertanto, devi monitorare le statistiche riepilogative dei tuoi dati e il rendimento online del tuo modello per inviare notifiche o eseguire il rollback quando i valori si discostano dalle tue aspettative.
L'ML e altri sistemi software sono simili per l'integrazione continua del controllo del codice sorgente, i test unitari, i test di integrazione e la distribuzione continua del modulo software o del pacchetto. Tuttavia, nell'ML esistono alcune differenze significative:
- CI continua non riguarda più solo il test e la convalida di codice e componenti, ma anche il test e la convalida di dati, schemi di dati e modelli.
- La CD non riguarda più un singolo pacchetto software o un servizio, ma un sistema (una pipeline di addestramento ML) che deve eseguire automaticamente il deployment di un altro servizio (servizio di previsione del modello).
- CT è una nuova proprietà, unica per i sistemi ML, che si occupa di riaddestrare e pubblicare automaticamente i modelli.
La sezione seguente descrive i passaggi tipici per l'addestramento e la valutazione di un modello ML da utilizzare come servizio di previsione.
Passaggi di data science per l'ML
In qualsiasi progetto di ML, dopo aver definito il caso d'uso aziendale e stabilito i criteri di successo, il processo di invio di un modello di ML in produzione prevede le seguenti fasi. Queste fasi possono essere completate manualmente o mediante una pipeline automatica.
- Estrazione dei dati: selezioni e integri i dati pertinenti da varie origini dati per l'attività di ML.
- Analisi dei dati: esegui l'analisi esplorativa dei dati (EDA) per comprendere i dati disponibili per la creazione del modello ML. Questa
procedura porta a quanto segue:
- Comprendere lo schema e le caratteristiche dei dati previsti dal modello.
- Identificare la preparazione dei dati e il feature engineering necessari per il modello.
- Preparazione dei dati: i dati vengono preparati per l'attività di ML. Questa preparazione prevede la pulizia dei dati, in cui i dati vengono suddivisi in set di addestramento, convalida e test. Applichi anche trasformazioni dei dati e feature engineering al modello che risolve l'attività target. L'output di questo passaggio sono le divisioni dei dati nel formato preparato.
- Addestramento del modello: il data scientist implementa diversi algoritmi con i dati preparati per addestrare vari modelli ML. Inoltre, sottoponi gli algoritmi implementati all'ottimizzazione degli iperparametri per ottenere il modello ML con le migliori prestazioni. L'output di questo passaggio è un modello addestrato.
- Valutazione del modello: il modello viene valutato su un set di test di holdout per valutare la qualità del modello. L'output di questo passaggio è un insieme di metriche per valutare la qualità del modello.
- Convalida del modello: è stato confermato che il modello è adeguato per l'implementazione, ovvero che il suo rendimento predittivo è migliore di una determinata base di riferimento.
- Servizio del modello: il modello convalidato viene implementato in un
ambiente di destinazione per fornire previsioni. Questo deployment può essere uno dei
seguenti:
- Microservizi con un'API REST per fornire previsioni online.
- Un modello incorporato in un dispositivo edge o mobile.
- Parte di un sistema di previsione batch.
- Monitoraggio del modello: le prestazioni predittive del modello vengono monitorate per richiamare potenzialmente una nuova iterazione nel processo ML.
Il livello di automazione di questi passaggi definisce la maturità del processo ML, che riflette la velocità di addestramento di nuovi modelli in base a nuovi dati o di addestramento di nuovi modelli in base a nuove implementazioni. Le sezioni seguenti descrivono tre livelli di MLOps, a partire dal livello più comune, che non prevede automazione, fino all'automazione delle pipeline ML e CI/CD.
Livello 0 di MLOps: procedura manuale
Molti team hanno data scientist e ricercatori di ML che possono creare modelli all'avanguardia, ma la procedura per creare ed eseguire il deployment di modelli di ML è completamente manuale. Questo è considerato il livello di maturità base o livello 0. Il seguente diagramma mostra il flusso di lavoro di questo processo.

Figura 2. Passaggi ML manuali per pubblicare il modello come servizio di previsione.
Caratteristiche
Il seguente elenco evidenzia le caratteristiche del processo MLOps di livello 0, come mostrato nella Figura 2:
Processo manuale, basato su script e interattivo: ogni passaggio è manuale, inclusi analisi dei dati, preparazione dei dati, addestramento e convalida del modello. Richiede l'esecuzione manuale di ogni passaggio e la transizione manuale da un passaggio all'altro. Questo processo è in genere guidato da codice sperimentale scritto ed eseguito in modo interattivo nei notebook dai data scientist, finché non viene prodotto un modello funzionante.
Disconnessione tra ML e operazioni: il processo separa i data scientist che creano il modello e gli ingegneri che lo pubblicano come servizio di previsione. I data scientist consegnano un modello addestrato come artefatto al team di ingegneria per il deployment nella propria infrastruttura API. Questo trasferimento può includere l'inserimento del modello addestrato in una posizione di archiviazione, l'archiviazione dell'oggetto modello in un repository di codice o il caricamento in un registro dei modelli. Poi, gli ingegneri che eseguono il deployment del modello devono rendere disponibili le funzionalità richieste in produzione per la distribuzione a bassa latenza, il che può portare a distorsioni tra addestramento e distribuzione.
Iterazioni di rilascio poco frequenti: il processo presuppone che il tuo team di data science gestisca alcuni modelli che non cambiano spesso, modificando l'implementazione del modello o eseguendo il retraining del modello con nuovi dati. Il deployment di una nuova versione del modello viene eseguito solo un paio di volte all'anno.
Nessun CI: poiché si presuppongono poche modifiche all'implementazione, il CI viene ignorato. In genere, il test del codice fa parte dell'esecuzione di notebook o script. Gli script e i blocchi note che implementano i passaggi dell'esperimento sono controllati dal codice sorgente e producono artefatti come modelli addestrati, metriche di valutazione e visualizzazioni.
Nessuna CD: poiché non vengono eseguiti deployment frequenti delle versioni del modello, la CD non viene presa in considerazione.
Il deployment si riferisce al servizio di previsione: la procedura riguarda solo il deployment del modello addestrato come servizio di previsione (ad esempio, un microservizio con un'API REST), anziché il deployment dell'intero sistema ML.
Mancanza di monitoraggio attivo delle prestazioni: il processo non monitora né registra le previsioni e le azioni del modello, necessarie per rilevare il peggioramento delle prestazioni del modello e altri cambiamenti nel suo comportamento.
Il team di ingegneria potrebbe avere una propria configurazione complessa per la configurazione, il test e il deployment delle API, inclusi test di sicurezza, regressione, carico e canary. Inoltre, il deployment in produzione di una nuova versione di un modello ML di solito viene sottoposto a test A/B o esperimenti online prima che il modello venga promosso per gestire tutto il traffico delle richieste di previsione.
Sfide
Il livello 0 di MLOps è comune in molte aziende che iniziano ad applicare ML ai loro casi d'uso. Questo processo manuale, basato sui data scientist, potrebbe essere sufficiente quando i modelli vengono modificati o addestrati raramente. In pratica, i modelli spesso si rompono quando vengono implementati nel mondo reale. I modelli non riescono ad adattarsi ai cambiamenti nelle dinamiche dell'ambiente o ai cambiamenti nei dati che descrivono l'ambiente. Per saperne di più, consulta Why Machine Learning Models Crash and Burn in Production.
Per affrontare queste sfide e mantenere l'accuratezza del modello in produzione, devi:
Monitora attivamente la qualità del modello in produzione: il monitoraggio ti consente di rilevare il peggioramento delle prestazioni e l'obsolescenza del modello. Funge da spunto per una nuova iterazione di sperimentazione e per il riaddestramento (manuale) del modello su nuovi dati.
Esegui di nuovo l'addestramento dei modelli di produzione di frequente: per acquisire i pattern in evoluzione ed emergenti, devi eseguire di nuovo l'addestramento del modello con i dati più recenti. Ad esempio, se la tua app consiglia prodotti di moda utilizzando ML, i suoi consigli devono adattarsi alle ultime tendenze e ai prodotti.
Sperimenta continuamente nuove implementazioni per produrre il modello: Per sfruttare le idee e i progressi tecnologici più recenti, devi provare nuove implementazioni come l'feature engineering, l'architettura del modello e gli iperparametri. Ad esempio, se utilizzi la computer vision nel riconoscimento facciale, i pattern del volto sono fissi, ma nuove tecniche migliori possono migliorare l'accuratezza del riconoscimento.
Per affrontare le sfide di questo processo manuale, sono utili le pratiche MLOps per CI/CD e CT. Se esegui il deployment di una pipeline di addestramento ML, puoi attivare CT e configurare un sistema CI/CD per testare, creare ed eseguire il deployment rapidamente di nuove implementazioni della pipeline ML. Queste funzionalità sono descritte in modo più dettagliato nelle sezioni successive.
Livello 1 di MLOps: automazione della pipeline ML
L'obiettivo del livello 1 è eseguire l'addestramento continuo del modello automatizzando la pipeline ML, in modo da ottenere la distribuzione continua del servizio di previsione del modello. Per automatizzare il processo di utilizzo di nuovi dati per addestrare nuovamente i modelli in produzione, devi introdurre dati automatizzati e passaggi di convalida dei modelli nella pipeline, nonché trigger della pipeline e gestione dei metadati.
La figura seguente è una rappresentazione schematica di una pipeline di machine learning automatizzata per la classificazione del testo.

Figura 3. Automazione della pipeline ML per l'addestramento continuo.
Caratteristiche
Il seguente elenco evidenzia le caratteristiche della configurazione MLOps di livello 1, come mostrato nella Figura 3:
Esperimento rapido: i passaggi dell'esperimento ML sono orchestrati. La transizione tra i passaggi è automatizzata, il che porta a un'iterazione rapida degli esperimenti e a una migliore preparazione per spostare l'intera pipeline in produzione.
CT del modello in produzione: il modello viene addestrato automaticamente in produzione utilizzando dati aggiornati in base ai trigger della pipeline live, che vengono discussi nella sezione successiva.
Simmetria sperimentale-operativa: l'implementazione della pipeline utilizzata nell'ambiente di sviluppo o sperimentazione viene utilizzata nell'ambiente di preproduzione e produzione, un aspetto fondamentale della pratica MLOps per unificare DevOps.
Codice modulare per componenti e pipeline: per costruire pipeline ML, i componenti devono essere riutilizzabili, componibili e potenzialmente condivisibili tra le pipeline ML. Pertanto, anche se il codice EDA può ancora risiedere nei blocchi note, il codice sorgente dei componenti deve essere modularizzato. Inoltre, i componenti devono idealmente essere containerizzati per:
- Disaccoppia l'ambiente di esecuzione dal runtime del codice personalizzato.
- Rendere il codice riproducibile tra gli ambienti di sviluppo e di produzione.
- Isola ogni componente della pipeline. I componenti possono avere la propria versione dell'ambiente di runtime e lingue e librerie diverse.
Distribuzione continua dei modelli: una pipeline ML in produzione distribuisce continuamente servizi di previsione a nuovi modelli addestrati su nuovi dati. Il passaggio di deployment del modello, che pubblica il modello addestrato e convalidato come servizio di previsione per le previsioni online, è automatizzato.
Deployment della pipeline: al livello 0, esegui il deployment di un modello addestrato come servizio di previsione in produzione. Per il livello 1, esegui il deployment di una pipeline di addestramento completa, che viene eseguita automaticamente e in modo ricorrente per fornire il modello addestrato come servizio di previsione.
Componenti aggiuntivi
Questa sezione descrive i componenti che devi aggiungere all'architettura per abilitare l'addestramento continuo di ML.
Convalida dei dati e dei modelli
Quando esegui il deployment della pipeline ML in produzione, uno o più trigger descritti nella sezione Trigger della pipeline ML eseguono automaticamente la pipeline. La pipeline prevede nuovi dati in tempo reale per produrre una nuova versione del modello addestrata sui nuovi dati (come mostrato nella Figura 3). Pertanto, nella pipeline di produzione sono necessari passaggi di convalida dei dati e convalida del modello automatizzati per garantire il seguente comportamento previsto:
Convalida dei dati: questo passaggio è necessario prima dell'addestramento del modello per decidere se riaddestrare il modello o interrompere l'esecuzione della pipeline. Questa decisione viene presa automaticamente se la pipeline ha identificato quanto segue.
- Distorsioni dello schema dei dati: queste distorsioni sono considerate anomalie nei dati di input. Pertanto, i dati di input che non rispettano lo schema previsto vengono ricevuti dai passaggi della pipeline downstream, inclusi i passaggi di elaborazione dei dati e addestramento del modello. In questo caso, devi interrompere la pipeline in modo che il team di data science possa eseguire un'indagine. Il team potrebbe rilasciare una correzione o un aggiornamento della pipeline per gestire queste modifiche allo schema. I problemi dello schema includono la ricezione di funzionalità inaspettate, la mancata ricezione di tutte le funzionalità previste o la ricezione di funzionalità con valori inaspettati.
- Distorsioni dei valori dei dati: queste distorsioni sono cambiamenti significativi nelle proprietà statistiche dei dati, il che significa che i pattern dei dati stanno cambiando ed è necessario attivare un riaddestramento del modello per acquisire questi cambiamenti.
Convalida del modello: questo passaggio viene eseguito dopo l'addestramento del modello con i nuovi dati. Valuti e convalidi il modello prima che venga promosso in produzione. Questo passaggio di convalida del modello offline consiste in quanto segue.
- Produzione di valori delle metriche di valutazione utilizzando il modello addestrato su un set di dati di test per valutare la qualità predittiva del modello.
- Confrontando i valori delle metriche di valutazione prodotti dal modello appena addestrato con il modello attuale, ad esempio il modello di produzione, il modello di base o altri modelli di requisiti aziendali. Prima di promuoverlo per la produzione, assicurati che il nuovo modello offra prestazioni migliori rispetto a quello attuale.
- Assicurarsi che le prestazioni del modello siano coerenti in vari segmenti dei dati. Ad esempio, il modello di churn dei clienti appena addestrato potrebbe produrre un'accuratezza predittiva complessivamente migliore rispetto al modello precedente, ma i valori di accuratezza per regione del cliente potrebbero presentare una varianza elevata.
- Assicurati di testare il modello per il deployment, inclusa la compatibilità dell'infrastruttura e la coerenza con l'API del servizio di previsione.
Oltre alla convalida offline del modello, un modello appena sottoposto a deployment viene sottoposto a convalida online del modello, in un deployment canary o in una configurazione di test A/B, prima di fornire la previsione per il traffico online.
Feature Store
Un componente aggiuntivo facoltativo per l'automazione della pipeline ML di livello 1 è un feature store. Un feature store è un repository centralizzato in cui standardizzi la definizione, l'archiviazione e l'accesso alle caratteristiche per l'addestramento e la distribuzione. Un Feature Store deve fornire un'API sia per la distribuzione batch ad alta velocità effettiva sia per la distribuzione in tempo reale a bassa latenza per i valori delle caratteristiche e supportare sia i carichi di lavoro di addestramento che di distribuzione.
L'archivio di caratteristiche aiuta i data scientist a:
- Scopri e riutilizza i set di funzionalità disponibili per le loro entità, invece di ricrearne di uguali o simili.
- Evita di avere funzionalità simili con definizioni diverse mantenendo le funzionalità e i relativi metadati.
- Eroga valori delle caratteristiche aggiornati dall'archivio di caratteristiche.
Evita il disallineamento tra addestramento e distribuzione utilizzando Feature Store come origine dati per la sperimentazione, l'addestramento continuo e la distribuzione online. Questo approccio garantisce che le caratteristiche utilizzate per l'addestramento siano le stesse utilizzate durante la distribuzione:
- Per la sperimentazione, i data scientist possono ottenere un'estrazione offline dallo feature store per eseguire i propri esperimenti.
- Per l'addestramento continuo, la pipeline di addestramento di AutoML può recuperare un batch dei valori delle funzionalità aggiornati del set di dati utilizzati per l'attività di addestramento.
- Per la previsione online, il servizio di previsione può recuperare in batch i valori delle caratteristiche correlati all'entità richiesta, ad esempio le caratteristiche demografiche dei clienti, le caratteristiche dei prodotti e le caratteristiche di aggregazione della sessione corrente.
- Per la previsione online e il recupero delle caratteristiche, il servizio di previsione identifica le caratteristiche pertinenti per un'entità. Ad esempio, se l'entità è un cliente, le funzionalità pertinenti potrebbero includere età, cronologia degli acquisti e comportamento di navigazione. Il servizio raggruppa questi valori delle funzionalità e recupera tutte le funzionalità necessarie per l'entità contemporaneamente, anziché singolarmente. Questo metodo di recupero è utile per l'efficienza, soprattutto quando devi gestire più entità.
Gestione dei metadati
Le informazioni su ogni esecuzione della pipeline ML vengono registrate per facilitare la derivazione di dati e artefatti, la riproducibilità e i confronti. Inoltre, ti aiuta a eseguire il debug di errori e anomalie. Ogni volta che esegui la pipeline, l'archivio dei metadati ML registra i seguenti metadati:
- Le versioni della pipeline e del componente che sono state eseguite.
- La data e l'ora di inizio e di fine e il tempo impiegato dalla pipeline per completare ciascuno dei passaggi.
- L'esecutore della pipeline.
- Gli argomenti dei parametri passati alla pipeline.
- I puntatori agli artefatti generati da ogni passaggio della pipeline, ad esempio la posizione dei dati preparati, le anomalie di convalida, le statistiche calcolate e il vocabolario estratto dalle funzionalità categoriche. Il monitoraggio di questi output intermedi ti aiuta a riprendere la pipeline dall'ultimo passaggio se la pipeline si è interrotta a causa di un passaggio non riuscito, senza dover rieseguire i passaggi già completati.
- Un puntatore al modello addestrato precedente se devi eseguire il rollback a una versione precedente del modello o se devi produrre metriche di valutazione per una versione precedente del modello quando alla pipeline vengono forniti nuovi dati di test durante il passaggio di convalida del modello.
- Le metriche di valutazione del modello prodotte durante il passaggio di valutazione del modello per i set di addestramento e di test. Queste metriche ti aiutano a confrontare le prestazioni di un modello appena addestrato con le prestazioni registrate del modello precedente durante il passaggio di convalida del modello.
Trigger di pipeline ML
Puoi automatizzare le pipeline di produzione ML per riaddestrare i modelli con nuovi dati, a seconda del tuo caso d'uso:
- Su richiesta: esecuzione manuale ad hoc della pipeline.
- In base a una pianificazione: i nuovi dati etichettati sono sistematicamente disponibili per il sistema ML su base giornaliera, settimanale o mensile. La frequenza di riaddestramento dipende anche dalla frequenza con cui cambiano i pattern dei dati e dal costo del riaddestramento dei modelli.
- Sulla disponibilità di nuovi dati di addestramento: i nuovi dati non sono disponibili sistematicamente per il sistema ML, ma su base ad hoc quando vengono raccolti e resi disponibili nei database di origine.
- Degrado delle prestazioni del modello: il modello viene riaddestrato quando si verifica un degrado delle prestazioni notevole.
- In caso di modifiche significative nelle distribuzioni dei dati (deviazione del concetto). È difficile valutare il rendimento completo del modello online, ma noti cambiamenti significativi nelle distribuzioni dei dati delle funzionalità che vengono utilizzate per eseguire la previsione. Queste modifiche suggeriscono che il modello è diventato obsoleto e deve essere riaddestrato con dati aggiornati.
Sfide
Supponendo che le nuove implementazioni della pipeline non vengano eseguite di frequente e che tu gestisca solo poche pipeline, in genere testi manualmente la pipeline e i relativi componenti. Inoltre, esegui manualmente il deployment delle nuove implementazioni della pipeline. Inoltre, invii il codice sorgente testato per la pipeline al team IT per il deployment nell'ambiente di destinazione. Questa configurazione è adatta quando esegui il deployment di nuovi modelli basati su nuovi dati, anziché su nuove idee di ML.
Tuttavia, devi provare nuove idee di ML ed eseguire rapidamente il deployment di nuove implementazioni dei componenti ML. Se gestisci molte pipeline ML in produzione, devi configurare CI/CD per automatizzare la creazione, il test e il deployment delle pipeline ML.
Livello 2 di MLOps: automazione della pipeline CI/CD
Per un aggiornamento rapido e affidabile delle pipeline in produzione, hai bisogno di un solido sistema CI/CD automatizzato. Questo sistema CI/CD automatizzato consente ai data scientist di esplorare rapidamente nuove idee riguardanti il processo di feature engineering, l'architettura dei modelli e gli iperparametri. Possono implementare queste idee e creare, testare ed eseguire automaticamente il deployment dei nuovi componenti della pipeline nell'ambiente di destinazione.
Il seguente diagramma mostra l'implementazione della pipeline ML utilizzando CI/CD, che presenta le caratteristiche della configurazione delle pipeline ML automatizzate più le routine CI/CD automatizzate.

Figura 4. Pipeline di machine learning CI/CD automatizzata.
Questa configurazione di MLOps include i seguenti componenti:
- Controllo del codice sorgente
- Testare e creare servizi
- Servizi di deployment
- Registro dei modelli
- Feature Store
- Archivio dei metadati ML
- Orchestratore della pipeline ML
Caratteristiche
Il seguente diagramma mostra le fasi della pipeline di automazione CI/CD ML:

Figura 5. Fasi della pipeline di machine learning CI/CD automatizzata.
La pipeline è costituita dalle seguenti fasi:
Sviluppo e sperimentazione: provi in modo iterativo nuovi algoritmi ML e nuove modellazioni in cui i passaggi dell'esperimento sono coordinati. L'output di questa fase è il codice sorgente dei passaggi della pipeline ML che vengono poi inviati a un repository di origine.
Integrazione continua della pipeline: crei il codice sorgente ed esegui vari test. Gli output di questa fase sono i componenti della pipeline (pacchetti, eseguibili e artefatti) da implementare in una fase successiva.
Distribuzione continua della pipeline: esegui il deployment degli artefatti prodotti dalla fase CI nell'ambiente di destinazione. L'output di questa fase è una pipeline di cui è stato eseguito il deployment con la nuova implementazione del modello.
Attivazione automatica: la pipeline viene eseguita automaticamente in produzione in base a una pianificazione o in risposta a un trigger. L'output di questa fase è un modello addestrato che viene inviato al registro dei modelli.
Distribuzione continua del modello: il modello addestrato viene utilizzato come servizio di previsione. L'output di questa fase è un servizio di previsione del modello di cui è stato eseguito il deployment.
Monitoraggio: raccogli statistiche sul rendimento del modello in base ai dati in tempo reale. L'output di questa fase è un trigger per eseguire la pipeline o per eseguire un nuovo ciclo di esperimenti.
Il passaggio di analisi dei dati è ancora un processo manuale per i data scientist prima che la pipeline inizi una nuova iterazione dell'esperimento. Anche il passaggio di analisi del modello è un processo manuale.
Integrazione continua
In questa configurazione, la pipeline e i relativi componenti vengono creati, testati e pacchettizzati quando viene eseguito il commit o il push del nuovo codice nel repository del codice sorgente. Oltre a creare pacchetti, immagini container ed eseguibili, la procedura CI può includere i seguenti test:
Test delle unità della logica di feature engineering.
Test unitari dei diversi metodi implementati nel modello. Ad esempio, hai una funzione che accetta una colonna di dati categorici e codifichi la funzione come caratteristica one-hot.
Verifica che l'addestramento del modello converga (ovvero che la perdita del modello diminuisca con le iterazioni e che si adatti eccessivamente a pochi record di esempio).
Verifica che l'addestramento del modello non produca valori NaN a causa della divisione per zero o della manipolazione di valori piccoli o grandi.
Test che verifica che ogni componente della pipeline produca gli artefatti previsti.
Test dell'integrazione tra i componenti della pipeline.
Distribuzione continua
A questo livello, il sistema fornisce continuamente nuove implementazioni della pipeline all'ambiente di destinazione, che a sua volta fornisce servizi di previsione del modello appena addestrato. Per una distribuzione continua rapida e affidabile di pipeline e modelli, devi considerare quanto segue:
Verifica della compatibilità del modello con l'infrastruttura di destinazione prima di eseguire il deployment del modello. Ad esempio, devi verificare che i pacchetti richiesti dal modello siano installati nell'ambiente di gestione e che le risorse di memoria, di calcolo e dell'acceleratore richieste siano disponibili.
Test del servizio di previsione chiamando l'API del servizio con gli input previsti e assicurandoti di ricevere la risposta che ti aspetti. Questo test di solito rileva i problemi che potrebbero verificarsi quando aggiorni la versione del modello e prevede un input diverso.
Test delle prestazioni del servizio di previsione, che prevede il test di carico del servizio per acquisire metriche come le query al secondo (QPS) e la latenza del modello.
Convalida dei dati per il riaddestramento o la previsione batch.
Verificare che i modelli soddisfino i target di rendimento predittivo prima di essere implementati.
Deployment automatizzato in un ambiente di test, ad esempio un deployment attivato dall'invio di codice al ramo di sviluppo.
Deployment semiautomatico in un ambiente di pre-produzione, ad esempio, un deployment attivato dall'unione del codice al ramo principale dopo che i revisori approvano le modifiche.
Deployment manuale in un ambiente di produzione dopo diverse esecuzioni riuscite della pipeline nell'ambiente di pre-produzione.
In sintesi, l'implementazione dell'ML in un ambiente di produzione non significa solo eseguire il deployment del modello come API per la previsione. Significa invece eseguire il deployment di una pipeline ML in grado di automatizzare il riaddestramento e il deployment di nuovi modelli. La configurazione di un sistema CI/CD consente di testare ed eseguire il deployment automaticamente delle nuove implementazioni della pipeline. Questo sistema ti consente di far fronte ai rapidi cambiamenti dei dati e dell'ambiente aziendale. Non è necessario spostare immediatamente tutti i processi da un livello all'altro. Puoi implementare gradualmente queste pratiche per migliorare l'automazione dello sviluppo e della produzione del tuo sistema ML.
Passaggi successivi
- Scopri di più sull'architettura per MLOps utilizzando TensorFlow Extended, Vertex AI Pipelines e Cloud Build.
- Scopri di più sulla Guida alle operazioni di machine learning (MLOps) per i professionisti.
- Guarda il video Best Practices for MLOps on Google Cloud (Cloud Next '19) su YouTube.
- Per una panoramica dei principi e dei consigli architetturali specifici per i workload di AI e ML in Google Cloud, consulta la prospettiva AI e ML nel Well-Architected Framework.
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.
Collaboratori
Autori:
- Jarek Kazmierczak | Solutions Architect
- Khalid Salama | Staff Software Engineer, Machine Learning
- Valentin Huerta | AI Engineer
Altro collaboratore: Sunil Kumar Jang Bahadur | Customer Engineer