Dokumen ini membahas teknik untuk menerapkan dan mengotomatiskan continuous integration (CI), continuous delivery (CD), dan continuous training (CT) untuk sistem machine learning (ML). Dokumen ini terutama berlaku untuk sistem AI prediktif.
Data science dan ML menjadi kemampuan inti untuk memecahkan masalah dunia nyata yang kompleks, mengubah industri, dan memberikan nilai di semua domain. Saat ini, bahan-bahan untuk menerapkan ML yang efektif tersedia untuk Anda:
- Set data besar
- Resource compute on demand yang murah
- Akselerator khusus untuk ML di berbagai platform cloud
- Kemajuan pesat di berbagai bidang penelitian ML (seperti computer vision, natural language understanding, AI generatif, dan sistem AI rekomendasi).
Oleh karena itu, banyak bisnis yang berinvestasi pada tim data science dan kemampuan ML untuk mengembangkan model prediktif yang dapat memberikan nilai bisnis kepada pengguna mereka.
Dokumen ini ditujukan untuk data scientist dan engineer ML yang ingin menerapkan prinsip DevOps ke sistem ML (MLOps). MLOps adalah budaya dan praktik rekayasa ML yang bertujuan menyatukan pengembangan sistem ML (Dev) dan operasi sistem ML (Ops). Dengan mempraktikkan MLOps, berarti Anda mengadvokasi otomatisasi dan pemantauan di semua langkah konstruksi sistem ML, termasuk integrasi, pengujian, rilis, deployment, dan pengelolaan infrastruktur.
Data scientist dapat menerapkan dan melatih model ML dengan performa prediktif pada set data holdout offline, dengan mempertimbangkan data pelatihan yang relevan untuk kasus penggunaan mereka. Namun, tantangan sebenarnya bukanlah mem-build model ML, melainkan membangun sistem ML terintegrasi dan terus mengoperasikannya dalam produksi. Dengan sejarah panjangnya layanan ML produksi di Google, kita telah mempelajari bahwa mungkin ada banyak perangkap dalam mengoperasikan sistem berbasis ML dalam produksi. Beberapa perangkap ini dirangkum dalam Machine Learning: Kartu Kredit dengan Bunga Tinggi untuk Utang Teknis.
Seperti yang ditunjukkan dalam diagram berikut, hanya sebagian kecil sistem ML dunia nyata yang terdiri dari kode ML. Elemen di sekitarnya yang diperlukan sangat luas dan kompleks.
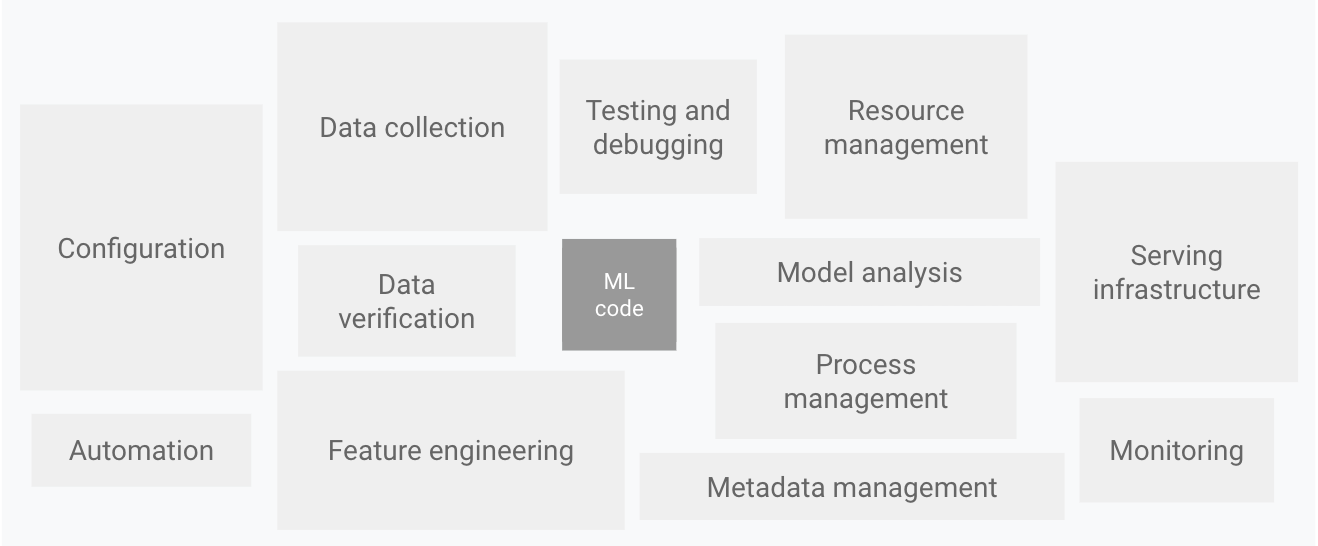
Gambar 1. Elemen untuk sistem ML. Diadaptasi dari Utang Teknis Tersembunyi dalam Sistem Machine Learning.
Diagram sebelumnya menampilkan komponen sistem berikut:
- Konfigurasi
- Otomatisasi
- Pengumpulan data
- Verifikasi data
- Pengujian dan proses debug
- Pengelolaan resource
- Analisis model
- Pengelolaan proses dan metadata
- Infrastruktur penayangan
- Pemantauan
Untuk mengembangkan dan mengoperasikan sistem kompleks seperti ini, Anda dapat menerapkan prinsip DevOps ke sistem ML (MLOps). Dokumen ini mencakup konsep yang perlu dipertimbangkan ketika menyiapkan lingkungan MLOps untuk praktik data science, seperti CI, CD, dan CT di ML.
Topik-topik berikut dibahas:
- DevOps dibandingkan dengan MLOps
- Langkah-langkah untuk mengembangkan model ML
- Tingkat kesiapan MLOps
- MLOps untuk AI generatif
DevOps dibandingkan dengan MLOps
DevOps adalah praktik populer dalam mengembangkan dan mengoperasikan sistem software berskala besar. Praktik ini memberikan sejumlah manfaat, seperti mempersingkat siklus pengembangan, meningkatkan kecepatan deployment, dan rilis yang dapat diandalkan. Untuk mencapai manfaat ini, Anda memperkenalkan dua konsep dalam pengembangan sistem software:
Sistem ML adalah sistem software, jadi praktik serupa berlaku untuk membantu menjamin bahwa Anda dapat membangun dan mengoperasikan sistem ML dengan andal dalam skala besar.
Namun, sistem ML berbeda dari sistem software lainnya dalam hal berikut:
Keterampilan tim: Dalam project ML, tim biasanya terdiri dari ilmuwan data atau peneliti ML, yang berfokus pada analisis data eksploratif, model pengembangan, dan eksperimen. Anggota ini mungkin bukan software engineer berpengalaman yang dapat membangun layanan kelas produksi.
Pengembangan: ML bersifat eksperimental. Anda harus mencoba berbagai fitur, algoritma, teknik pemodelan, dan konfigurasi parameter untuk menemukan solusi yang paling cocok untuk masalah secepat mungkin. Tantangannya adalah melacak apa yang berhasil dan apa yang tidak, serta mempertahankan reproduktifitas sambil memaksimalkan penggunaan kembali kode.
Pengujian: Pengujian sistem ML lebih kompleks daripada pengujian sistem software lainnya. Selain pengujian unit dan integrasi standar, Anda memerlukan validasi data, evaluasi kualitas model terlatih, dan validasi model.
Deployment: Dalam sistem ML, deployment tidak sesederhana men-deploy model ML yang dilatih offline seperti layanan prediksi. Sistem ML dapat mengharuskan Anda men-deploy pipeline multi-langkah untuk melatih ulang dan men-deploy model secara otomatis. Pipeline ini menambah kompleksitas dan mengharuskan Anda mengotomatiskan langkah-langkah yang dilakukan secara manual sebelum deployment oleh data scientist untuk melatih dan memvalidasi model baru.
Produksi: Model ML dapat menurunkan performa, tidak hanya karena coding yang kurang optimal, tetapi juga karena profil data yang terus berkembang. Dengan kata lain, model dapat mengalami lebih banyak kerusakan dibandingkan sistem software konvensional, dan Anda perlu mempertimbangkan degradasi ini. Oleh karena itu, Anda perlu melacak statistik ringkasan data dan memantau performa online model Anda untuk mengirim notifikasi atau melakukan roll back saat nilai menyimpang dari ekspektasi Anda.
ML dan sistem software lainnya serupa dalam integrasi berkelanjutan kontrol sumber, pengujian unit, pengujian integrasi, dan pengiriman berkelanjutan modul software atau paket. Namun, dalam ML, ada beberapa perbedaan penting:
- CI tidak lagi hanya berfungsi untuk menguji serta memvalidasi kode dan komponen, tetapi juga menguji dan memvalidasi data, skema data, dan model.
- CD bukan lagi tentang satu paket software atau layanan, melainkan sebuah sistem (pipeline pelatihan ML) yang seharusnya otomatis men-deploy layanan lain (layanan prediksi model).
- CT adalah properti baru dan unik untuk sistem ML, yang berkaitan dengan pelatihan ulang dan penyaluran model secara otomatis.
Bagian berikut membahas langkah-langkah umum untuk melatih dan mengevaluasi model ML agar berfungsi sebagai layanan prediksi.
Langkah-langkah data science untuk ML
Di project ML apa pun, setelah Anda menentukan kasus penggunaan bisnis dan menetapkan kriteria keberhasilan, proses pengiriman model ML ke produksi melibatkan langkah-langkah berikut. Langkah-langkah ini dapat diselesaikan secara manual atau dapat diselesaikan dengan pipeline otomatis.
- Ekstraksi data: Anda memilih dan mengintegrasikan data yang relevan dari berbagai sumber data untuk tugas ML.
- Analisis data: Anda melakukan
analisis data eksploratif (EDA)
untuk memahami data yang tersedia untuk membangun model ML. Proses
ini menghasilkan hal berikut:
- Memahami skema data dan karakteristik yang diharapkan oleh model.
- Mengidentifikasi persiapan data dan rekayasa fitur yang diperlukan untuk model.
- Persiapan data: Data disiapkan untuk tugas ML. Persiapan ini melibatkan pembersihan data, yaitu membagi data menjadi set pelatihan, validasi, dan pengujian. Anda juga akan menerapkan transformasi data dan rekayasa fitur pada model yang menyelesaikan tugas target. Output langkah ini adalah pemisahan data dalam format yang sudah disiapkan.
- Pelatihan model: Data scientist menerapkan berbagai algoritma dengan data yang telah disiapkan untuk melatih berbagai model ML. Selain itu, Anda tunduk pada algoritma yang diimplementasikan pada penyesuaian hyperparameter untuk mendapatkan model ML dengan performa terbaik. Output langkah ini adalah model yang telah dilatih.
- Evaluasi model: Model dievaluasi pada set pengujian holdout untuk mengevaluasi kualitas model. Output langkah ini adalah sekumpulan metrik untuk menilai kualitas model.
- Validasi model: Model dipastikan memadai untuk deployment—bahwa performa prediktifnya lebih baik daripada dasar pengukuran tertentu.
- Penayangan model: Model yang divalidasi di-deploy ke
lingkungan target untuk memberikan prediksi. Deployment ini bisa berupa salah satu dari
hal berikut:
- Microservice dengan REST API untuk menyajikan prediksi online.
- Model yang disematkan ke edge atau perangkat seluler.
- Bagian dari sistem prediksi batch.
- Pemantauan model: Performa prediktif model dipantau untuk berpotensi memanggil iterasi baru dalam proses ML.
Tingkat otomatisasi langkah-langkah ini menentukan kematangan proses ML, yang mencerminkan kecepatan pelatihan model baru dengan mempertimbangkan data baru atau melatih model baru dengan implementasi baru. Bagian berikut menjelaskan tiga level MLOps, mulai dari tingkat yang paling umum, yang tidak melibatkan otomatisasi, hingga mengotomatiskan pipeline ML dan CI/CD.
MLOps level 0: Proses manual
Banyak tim memiliki data scientist dan peneliti ML yang dapat membuat model canggih, tetapi proses pembuatan dan deployment model ML sepenuhnya dilakukan secara manual. Ini dianggap sebagai tingkat kematangan dasar, atau tingkat 0. Diagram berikut menunjukkan alur kerja proses ini.

Gambar 2. Langkah-langkah ML manual untuk menayangkan model sebagai layanan prediksi.
Karakteristik
Daftar berikut menyoroti karakteristik proses MLOps level 0, seperti yang ditunjukkan pada Gambar 2:
Proses manual, berbasis skrip, dan interaktif: Setiap langkah dilakukan secara manual, termasuk analisis data, persiapan data, pelatihan model, dan validasi. Diperlukan eksekusi manual di setiap langkah, dan transisi manual dari satu langkah ke langkah lainnya. Proses ini biasanya didorong oleh kode eksperimental yang ditulis dan dieksekusi secara interaktif di notebook oleh data scientist, hingga model yang dapat dikerjakan diproduksi.
Pemutusan antara ML dan operasi: Proses ini memisahkan data scientist yang membuat model dan engineer yang melayani model sebagai layanan prediksi. Data scientist menyerahkan model terlatih sebagai artefak kepada tim engineer untuk di-deploy di infrastruktur API mereka. Handoff ini dapat mencakup penempatan model yang dilatih di lokasi penyimpanan, memeriksa objek model ke dalam repositori kode, atau menguploadnya ke registry model. Kemudian, engineer yang men-deploy model tersebut perlu menyediakan fitur yang diperlukan dalam produksi untuk penayangan berlatensi rendah, yang dapat menyebabkan kemiringan penayangan pelatihan.
Iterasi rilis yang jarang: Proses ini mengasumsikan bahwa tim data science Anda mengelola beberapa model yang tidak sering berubah, baik mengubah implementasi model maupun melatih ulang model dengan data baru. Versi model baru hanya di-deploy beberapa kali per tahun.
Tidak ada CI: Karena hanya ada sedikit perubahan implementasi yang diasumsikan, CI akan diabaikan. Biasanya, menguji kode adalah bagian dari notebook atau eksekusi skrip. Skrip dan notebook yang menerapkan langkah-langkah eksperimen dikontrol dari sumbernya, dan menghasilkan artefak seperti model terlatih, metrik evaluasi, dan visualisasi.
Tidak ada CD: Karena deployment versi model tidak sering dilakukan, CD tidak dipertimbangkan.
Deployment mengacu pada layanan prediksi: Proses ini hanya berkaitan dengan men-deploy model terlatih sebagai layanan prediksi (misalnya, microservice dengan REST API), bukan men-deploy seluruh sistem ML.
Kurangnya pemantauan performa yang aktif: Proses ini tidak melacak atau mencatat prediksi dan tindakan model, yang diperlukan untuk mendeteksi penurunan performa model dan penyimpangan perilaku model lainnya.
Tim engineer mungkin memiliki penyiapan yang kompleks untuk konfigurasi, pengujian, dan deployment API, termasuk keamanan, regresi, serta pengujian beban dan canary. Selain itu, deployment produksi versi baru dari model ML biasanya dilakukan melalui pengujian A/B atau eksperimen online sebelum model dipromosikan untuk menyalurkan semua traffic permintaan prediksi.
Tantangan
MLOps level 0 umum terjadi di banyak bisnis yang mulai menerapkan ML ke kasus penggunaan mereka. Proses manual berbasis ilmuwan data ini mungkin cukup ketika model jarang diubah atau dilatih. Dalam praktiknya, model sering kali rusak ketika di-deploy di dunia nyata. Model gagal beradaptasi dengan perubahan dinamika lingkungan, atau perubahan dalam data yang menjelaskan lingkungan. Untuk informasi selengkapnya, lihat Alasan Model Machine Learning Mengalami Error dan Pembakaran dalam Produksi.
Untuk mengatasi tantangan ini dan mempertahankan akurasi model dalam produksi, Anda perlu melakukan hal berikut:
Pantau kualitas model secara aktif dalam produksi: Dengan pemantauan, Anda dapat mendeteksi penurunan performa dan keusangan model. Hal ini berfungsi sebagai tanda untuk iterasi eksperimen baru dan pelatihan ulang (manual) model pada data baru.
Sering melatih ulang model produksi: Untuk menangkap pola yang berkembang dan baru, Anda perlu melatih ulang model dengan data terbaru. Misalnya, jika aplikasi Anda merekomendasikan produk mode menggunakan ML, rekomendasinya harus beradaptasi dengan tren dan produk terbaru.
Terus bereksperimen dengan implementasi baru untuk menghasilkan model: Untuk memanfaatkan ide dan kemajuan teknologi terbaru, Anda harus mencoba implementasi baru seperti rekayasa fitur, arsitektur model, dan hyperparameter. Misalnya, jika Anda menggunakan computer vision dalam deteksi wajah, pola wajah akan bersifat permanen, tetapi teknik baru yang lebih baik dapat meningkatkan akurasi deteksi.
Untuk mengatasi tantangan pada proses manual ini, praktik MLOps untuk CI/CD CT akan sangat membantu. Dengan men-deploy pipeline pelatihan ML, Anda dapat mengaktifkan CT, dan menyiapkan sistem CI/CD untuk menguji, membangun, serta men-deploy implementasi baru pipeline ML dengan cepat. Fitur ini dibahas secara lebih mendetail di bagian berikutnya.
MLOps level 1: Otomatisasi pipeline ML
Tujuan level 1 adalah melakukan pelatihan berkelanjutan pada model dengan mengotomatiskan pipeline ML; hal ini memungkinkan Anda mencapai continuous delivery atas layanan prediksi model. Untuk mengotomatiskan proses penggunaan data baru untuk melatih ulang model dalam produksi, Anda perlu memperkenalkan langkah validasi model dan data otomatis ke pipeline, serta pemicu pipeline dan pengelolaan metadata.
Gambar berikut adalah representasi skematis pipeline ML otomatis untuk CT.

Gambar 3. Otomatisasi pipeline ML untuk CT.
Karakteristik
Daftar berikut menyoroti karakteristik penyiapan MLOps level 1, seperti yang ditunjukkan pada Gambar 3:
Eksperimen cepat: Langkah-langkah eksperimen ML diatur. Transisi antar-langkah bersifat otomatis, sehingga iterasi eksperimen dapat dilakukan dengan cepat dan kesiapan yang lebih baik untuk memindahkan seluruh pipeline ke produksi.
CT model dalam produksi: Model otomatis dilatih dalam produksi menggunakan data baru berdasarkan pemicu pipeline langsung, yang dibahas di bagian berikutnya.
Simetri operasional eksperimental: Implementasi pipeline yang digunakan di lingkungan pengembangan atau eksperimen digunakan di lingkungan praproduksi dan produksi, yang merupakan aspek utama dari praktik MLOps untuk menyatukan DevOps.
Kode termodulasi untuk komponen dan pipeline: Untuk membuat pipeline ML, komponen harus dapat digunakan kembali, dapat dikomposisi, dan mungkin dapat dibagikan di seluruh pipeline ML. Oleh karena itu, meskipun kode EDA masih dapat berada di notebook, kode sumber untuk komponen harus dimodularisasi. Selain itu, komponen idealnya harus ditempatkan dalam container untuk melakukan hal berikut:
- Pisahkan lingkungan eksekusi dari runtime kode kustom.
- Buat kode yang dapat direproduksi antara lingkungan pengembangan dan produksi.
- Mengisolasi setiap komponen dalam pipeline. Komponen dapat memiliki versi lingkungan runtime-nya sendiri, serta memiliki bahasa dan library yang berbeda.
Continuous delivery untuk model: Pipeline ML dalam produksi secara berkelanjutan memberikan layanan prediksi ke model baru yang dilatih dengan data baru. Langkah deployment model, yang menyalurkan model yang telah dilatih dan divalidasi sebagai layanan prediksi untuk prediksi online, akan dilakukan secara otomatis.
Deployment pipeline: Pada level 0, Anda men-deploy model terlatih sebagai layanan prediksi ke produksi. Untuk level 1, Anda men-deploy seluruh pipeline pelatihan, yang berjalan secara otomatis dan berulang untuk menyalurkan model terlatih sebagai layanan prediksi.
Komponen tambahan
Bagian ini membahas komponen yang perlu Anda tambahkan ke arsitektur untuk mengaktifkan pelatihan berkelanjutan ML.
Validasi data dan model
Saat Anda men-deploy pipeline ML ke produksi, satu atau beberapa pemicu yang dibahas di bagian pemicu pipeline ML otomatis menjalankan pipeline. Pipeline mengharapkan data live baru untuk menghasilkan versi model baru yang dilatih dengan data baru (seperti yang ditunjukkan pada Gambar 3). Oleh karena itu, langkah-langkah validasi data dan validasi model otomatis diperlukan dalam pipeline produksi untuk memastikan perilaku yang diharapkan berikut:
Validasi data: Langkah ini diperlukan sebelum pelatihan model untuk memutuskan apakah Anda harus melatih ulang model atau menghentikan eksekusi pipeline. Keputusan ini dibuat secara otomatis jika hal berikut diidentifikasi oleh pipeline.
- Kemiringan skema data: Kemiringan ini dianggap sebagai anomali dalam data input. Oleh karena itu, data input yang tidak sesuai dengan skema yang diharapkan diterima oleh langkah-langkah pipeline downstream, termasuk langkah-langkah pemrosesan data dan pelatihan model. Dalam kasus ini, Anda harus menghentikan pipeline tersebut agar tim data science dapat menyelidikinya. Tim dapat merilis perbaikan atau update pada pipeline untuk menangani perubahan ini dalam skema. Kemiringan skema mencakup penerimaan fitur yang tidak terduga, tidak menerima semua fitur yang diharapkan, atau menerima fitur dengan nilai yang tidak terduga.
- Nilai data condong: Kemiringan ini adalah perubahan signifikan pada properti statistik data, yang berarti pola data berubah, dan Anda perlu memicu pelatihan ulang model untuk menangkap perubahan tersebut.
Validasi model: Langkah ini terjadi setelah Anda berhasil melatih model yang diberikan data baru. Anda mengevaluasi dan memvalidasi model sebelum dipromosikan ke produksi. Langkah validasi model offline ini terdiri dari hal-hal berikut.
- Membuat nilai metrik evaluasi menggunakan model yang telah dilatih pada set data pengujian untuk menilai kualitas prediktif model.
- Membandingkan nilai metrik evaluasi yang dihasilkan oleh model yang baru Anda latih dengan model saat ini, misalnya, model produksi, model dasar pengukuran, atau model persyaratan bisnis lainnya. Anda memastikan bahwa model baru menghasilkan performa yang lebih baik daripada model saat ini sebelum mempromosikannya ke produksi.
- Memastikan bahwa performa model konsisten pada berbagai segmen data. Misalnya, model churn pelanggan yang baru dilatih mungkin menghasilkan akurasi prediktif yang lebih baik secara keseluruhan dibandingkan dengan model sebelumnya, tetapi nilai akurasi per region pelanggan mungkin memiliki variasi yang besar.
- Pastikan Anda menguji model untuk deployment, termasuk kompatibilitas infrastruktur dan konsistensi dengan API layanan prediksi.
Selain validasi model offline, model yang baru di-deploy mengalami validasi model online—dalam deployment canary atau penyiapan pengujian A/B—sebelum model menyalurkan prediksi untuk traffic online.
Feature Store
Komponen tambahan opsional untuk otomatisasi pipeline ML level 1 adalah feature store. Penyimpanan fitur adalah repositori terpusat tempat Anda menstandarkan definisi, penyimpanan, dan akses fitur untuk pelatihan dan penayangan. Penyimpanan fitur harus menyediakan API untuk layanan batch dengan throughput tinggi dan layanan real-time latensi rendah untuk nilai fitur, serta untuk mendukung beban kerja pelatihan dan penyaluran.
Penyimpanan fitur membantu data scientist melakukan hal berikut:
- Menemukan dan menggunakan kembali set fitur yang tersedia untuk entity mereka, bukan membuat ulang set fitur yang sama atau serupa.
- Hindari memiliki fitur serupa yang memiliki definisi berbeda dengan mempertahankan fitur dan metadata yang terkait.
- Tayangkan nilai fitur terbaru dari feature store.
Hindari ketidakseimbangan penayangan pelatihan dengan menggunakan feature store sebagai sumber data untuk eksperimen, pelatihan berkelanjutan, dan penayangan online. Pendekatan ini memastikan bahwa fitur yang digunakan untuk pelatihan sama dengan yang digunakan selama penayangan:
- Untuk eksperimen, data scientist dapat memperoleh ekstrak offline dari feature store untuk menjalankan eksperimen mereka.
- Untuk pelatihan berkelanjutan, pipeline pelatihan ML otomatis dapat mengambil batch nilai fitur terbaru dari set data yang digunakan untuk tugas pelatihan.
- Untuk prediksi online, layanan prediksi dapat mengambil batch nilai fitur yang terkait dengan entity yang diminta, seperti fitur demografi pelanggan, fitur produk, dan fitur agregasi sesi saat ini.
- Untuk prediksi online dan pengambilan fitur, layanan prediksi mengidentifikasi fitur yang relevan untuk suatu entity. Misalnya, jika entitasnya adalah pelanggan, fitur yang relevan dapat mencakup usia, histori pembelian, dan perilaku penjelajahan. Layanan ini mengelompokkan nilai fitur ini dan mengambil semua fitur yang diperlukan untuk entity sekaligus, bukan satu per satu. Metode pengambilan ini membantu meningkatkan efisiensi, terutama saat Anda perlu mengelola beberapa entitas.
Pengelolaan metadata
Informasi tentang setiap eksekusi pipeline ML dicatat untuk membantu silsilah, reproduksi, dan perbandingan data dan artefak. Alat ini juga membantu Anda melakukan debug error dan anomali. Setiap kali Anda jalankan pipeline, metadata ML akan mencatat metadata berikut:
- Versi pipeline dan komponen yang dijalankan.
- Tanggal mulai dan akhir, waktu, serta waktu yang diperlukan pipeline untuk menyelesaikan setiap langkah.
- Pelaksana pipeline.
- Argumen parameter yang diteruskan ke pipeline.
- Pointer ke artefak yang dihasilkan oleh setiap langkah pipeline, seperti lokasi data yang sudah disiapkan, anomali validasi, statistik yang dihitung, dan kosakata yang diekstrak dari fitur kategoris. Dengan melacak output perantara ini, Anda dapat melanjutkan pipeline dari langkah terbaru jika pipeline dihentikan karena langkah yang gagal, tanpa harus menjalankan kembali langkah-langkah yang telah selesai.
- Pointer ke model terlatih sebelumnya jika Anda perlu melakukan roll back ke versi model sebelumnya atau jika Anda perlu menghasilkan metrik evaluasi untuk versi model sebelumnya ketika pipeline diberi data pengujian baru selama langkah validasi model.
- Metrik evaluasi model yang dihasilkan selama langkah evaluasi model untuk set pelatihan dan pengujian. Metrik ini membantu Anda membandingkan performa model yang baru dilatih dengan performa yang tercatat dari model sebelumnya selama langkah validasi model.
Pemicu pipeline ML
Anda dapat mengotomatiskan pipeline produksi ML untuk melatih ulang model dengan data baru, bergantung pada kasus penggunaan Anda:
- Sesuai permintaan: Eksekusi manual ad-hoc pada pipeline.
- Sesuai jadwal: Data baru yang berlabel tersedia secara sistematis untuk sistem ML ML setiap hari, mingguan, atau bulanan. Frekuensi pelatihan ulang juga bergantung pada seberapa sering pola data berubah dan seberapa mahal biaya untuk melatih ulang model Anda.
- Ketersediaan data pelatihan baru: Data baru tidak tersedia secara sistematis untuk sistem ML, melainkan tersedia secara ad hoc saat data baru dikumpulkan dan tersedia di database sumber.
- Pada penurunan performa model: Model dilatih ulang saat ada penurunan performa yang terlihat.
- Pada perubahan signifikan dalam distribusi data (penyimpangan konsep). Sulit untuk menilai performa lengkap model online, tetapi Anda melihat perubahan signifikan pada distribusi data dari fitur yang digunakan untuk melakukan prediksi. Perubahan ini menunjukkan bahwa model Anda sudah usang, dan perlu dilatih ulang dengan data baru.
Tantangan
Dengan asumsi bahwa implementasi baru pipeline tidak sering di-deploy dan Anda hanya mengelola beberapa pipeline, Anda biasanya menguji pipeline dan komponennya secara manual. Selain itu, Anda juga dapat men-deploy implementasi pipeline baru secara manual. Anda juga mengirimkan kode sumber yang telah diuji untuk pipeline kepada tim IT guna di-deploy ke lingkungan target. Penyiapan ini cocok ketika Anda men-deploy model baru berdasarkan data baru, bukan berdasarkan ide ML baru.
Namun, Anda perlu mencoba ide ML baru dan men-deploy implementasi baru komponen ML dengan cepat. Jika mengelola banyak pipeline ML dalam produksi, Anda memerlukan penyiapan CI/CD untuk mengotomatiskan build, pengujian, dan deployment pipeline ML.
MLOps level 2: Otomatisasi pipeline CI/CD
Untuk update pipeline yang cepat dan andal dalam produksi, Anda memerlukan sistem CI/CD otomatis yang tangguh. Sistem CI/CD otomatis ini memungkinkan ilmuwan data Anda dengan cepat mempelajari ide-ide baru seputar rekayasa fitur, arsitektur model, dan hyperparameter. Mereka dapat menerapkan ide ini dan secara otomatis membangun, menguji, serta men-deploy komponen pipeline baru ke lingkungan target.
Diagram berikut menunjukkan implementasi pipeline ML menggunakan CI/CD, yang memiliki karakteristik penyiapan pipeline ML otomatis ditambah rutinitas CI/CD otomatis.

Gambar 4. CI/CD dan pipeline ML otomatis.
Penyiapan MLOps ini mencakup komponen berikut:
- Kontrol sumber
- Menguji dan membangun layanan
- Layanan deployment
- Registry model
- Feature store
- Store metadata ML
- Orkestrasi pipeline ML
Karakteristik
Diagram berikut menunjukkan tahapan pipeline otomatisasi CI/CD ML:

Gambar 5. Tahapan pipeline ML otomatis CI/CD.
Pipeline terdiri atas tahap-tahap berikut:
Pengembangan dan eksperimen: Anda secara berulang mencoba algoritma ML baru dan pemodelan baru tempat langkah-langkah eksperimen diatur. Output tahap ini adalah kode sumber dari langkah-langkah pipeline ML yang kemudian dikirim ke repositori sumber.
Continuous integration pipeline: Anda membangun kode sumber dan menjalankan berbagai pengujian. Output tahap ini adalah komponen pipeline (paket, file yang dapat dieksekusi, dan artefak) yang akan di-deploy di tahap berikutnya.
Continuous delivery pipeline: Anda men-deploy artefak yang dihasilkan oleh tahap CI ke lingkungan target. Output tahap ini adalah pipeline yang di-deploy dengan implementasi model baru.
Pemicuan otomatis: Pipeline dijalankan secara otomatis dalam produksi berdasarkan jadwal atau sebagai respons terhadap pemicu. Output tahap ini adalah model terlatih yang dikirim ke registry model.
Model continuous delivery: Anda menayangkan model terlatih sebagai layanan prediksi untuk prediksi. Output tahap ini adalah layanan prediksi model yang di-deploy.
Pemantauan: Anda mengumpulkan statistik tentang performa model berdasarkan data live. Output tahap ini adalah pemicu untuk menjalankan pipeline atau menjalankan siklus eksperimen baru.
Langkah analisis data masih merupakan proses manual bagi data scientist sebelum pipeline memulai iterasi baru eksperimen. Langkah analisis model juga merupakan proses manual.
Continuous integration
Dalam penyiapan ini, pipeline dan komponennya dibagun, diuji, dan dikemas saat kode baru di-commit atau dikirim ke repositori kode sumber. Selain membangun paket, image container, dan file yang dapat dieksekusi, proses CI dapat menyertakan pengujian berikut:
Pengujian unit logika rekayasa fitur Anda.
Melakukan pengujian unit berbagai metode yang diimplementasikan dalam model Anda. Misalnya, Anda memiliki fungsi yang menerima kolom data kategoris dan mengenkode fungsi sebagai fitur one-hot.
Pengujian bahwa pelatihan model Anda konvergensi (yaitu, hilangnya model Anda turun melalui iterasi dan overfits pada beberapa record sampel).
Menguji bahwa pelatihan model Anda tidak menghasilkan nilai NaN karena membagi dengan nol atau memanipulasi nilai kecil atau besar.
Menguji bahwa setiap komponen dalam pipeline menghasilkan artefak yang diharapkan.
Menguji integrasi antarkomponen pipeline.
Continuous delivery
Pada level ini, sistem Anda terus memberikan implementasi pipeline baru ke lingkungan target, yang kemudian memberikan layanan prediksi dari model yang baru dilatih. Untuk pipeline dan model continuous delivery yang cepat dan andal, Anda harus mempertimbangkan hal-hal berikut:
Memverifikasi kompatibilitas model dengan infrastruktur target sebelum men-deploy model. Misalnya, Anda perlu memverifikasi bahwa paket yang diperlukan oleh model diinstal di lingkungan penayangan, dan bahwa resource memori, komputasi, dan akselerator yang diperlukan tersedia.
Menguji layanan prediksi dengan memanggil API layanan beserta input yang diharapkan, dan memastikan Anda mendapatkan respons yang diharapkan. Pengujian ini biasanya menangkap masalah yang mungkin terjadi saat Anda mengupdate versi model dan mengharapkan input yang berbeda.
Menguji performa layanan prediksi, yang melibatkan pengujian beban layanan untuk merekam metrik seperti kueri per detik (QPS) dan latensi model.
Memvalidasi data baik untuk pelatihan ulang atau prediksi batch.
Memverifikasi bahwa model memenuhi target performa prediktif sebelum di-deploy.
Deployment otomatis ke lingkungan pengujian, misalnya deployment yang dipicu dengan mengirim kode ke cabang pengembangan.
Deployment semi-otomatis ke lingkungan pra-produksi, misalnya, deployment yang dipicu dengan menggabungkan kode ke cabang utama setelah peninjau menyetujui perubahan.
Deployment manual ke lingkungan produksi setelah beberapa kali berhasil menjalankan pipeline di lingkungan praproduksi.
Singkatnya, mengimplementasikan ML di lingkungan produksi tidak hanya berarti men-deploy model Anda sebagai API untuk prediksi. Sebaliknya, ini berarti men-deploy pipeline ML yang dapat mengotomatiskan pelatihan ulang dan deployment model baru. Dengan menyiapkan sistem CI/CD, Anda dapat menguji dan men-deploy implementasi pipeline baru secara otomatis. Sistem ini memungkinkan Anda mengatasi perubahan cepat pada data dan lingkungan bisnis. Anda tidak perlu segera memindahkan semua proses dari satu tingkat ke tingkat lainnya. Anda dapat menerapkan praktik ini secara bertahap untuk membantu meningkatkan otomatisasi pengembangan dan produksi sistem ML.
Langkah berikutnya
- Pelajari lebih lanjut Arsitektur untuk MLOps menggunakan TensorFlow Extended, Vertex AI Pipelines, dan Cloud Build.
- Pelajari Panduan Praktisi untuk Operasi Machine Learning (MLOps).
- Tonton Praktik Terbaik MLOps di Google Cloud (Cloud Next '19) di YouTube.
- Untuk mengetahui ringkasan prinsip dan rekomendasi arsitektur khusus untuk workload AI dan ML di Google Cloud, lihat perspektif AI dan ML dalam Well-Architected Framework.
- Untuk mengetahui lebih banyak tentang arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.
Kontributor
Penulis:
- Jarek Kazmierczak | Solutions Architect
- Khalid Salama | Staff Software Engineer, Machine Learning
- Valentin Huerta | AI Engineer
Kontributor lain: Sunil Kumar Jang Bahadur | Customer Engineer