What is Microservices Architecture?
Microservices architecture (often shortened to microservices) refers to an architectural style for developing applications. Microservices allow a large application to be separated into smaller independent parts, with each part having its own realm of responsibility. To serve a single user request, a microservices-based application can call on many internal microservices to compose its response.
Containers are a well-suited microservices architecture example, since they let you focus on developing the services without worrying about the dependencies. Modern cloud-native applications are usually built as microservices using containers.
Learn how Google Kubernetes Engine can help you create microservices-based applications using containers.
Ready to get started? New customers get $300 in free credits to spend on Google Cloud.
Microservices architecture defined
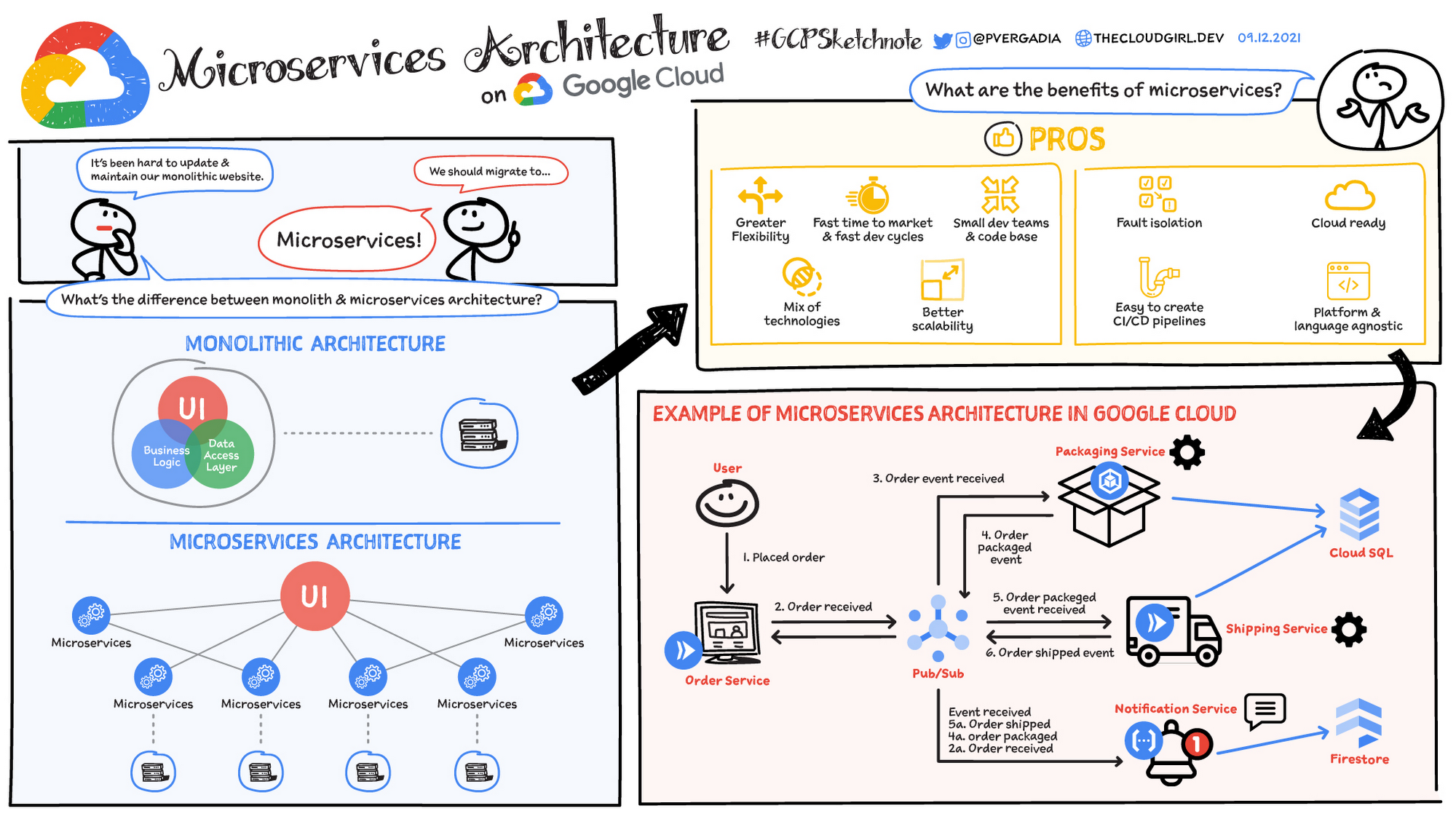
A microservices architecture is a type of application architecture where the application is developed as a collection of services. It provides the framework to develop, deploy, and maintain microservices architecture diagrams and services independently.
Within a microservices architecture, each microservice is a single service built to accommodate an application feature and handle discrete tasks. Each microservice communicates with other services through simple interfaces to solve business problems.
Monolithic vs. microservices architecture
Traditional monolithic applications are built as a single, unified unit. All components are tightly coupled, sharing resources and data. This can lead to challenges in scaling, deploying, and maintaining the application, especially as it grows in complexity. In contrast, microservices architecture decomposes an application into a suite of small, independent services. Each microservice is self-contained, with its own code, data, and dependencies. This approach offers several potential advantages:
- Improved scalability: Individual microservices can be scaled independently based on their specific needs
- Increased agility: Microservices can be developed, deployed, and updated independently, enabling faster release cycles
- Enhanced resilience: If one microservice fails, it doesn't necessarily impact the entire application
- Technology diversity: The flexibility of microservices allows teams to use the most suitable technology for each service
Industry examples
Many organizations across various industries have adopted Microservices architecture to address specific business challenges and drive innovation. Here are a few examples:
- E-commerce: Many e-commerce platforms use microservices to manage different aspects of their operations, such as product catalog, shopping cart, order processing, and customer accounts. This helps them to scale individual services based on demand, personalize customer experiences, and rapidly deploy new features.
- Streaming services: Streaming services often rely on microservices to handle tasks such as video encoding, content delivery, user authentication, and recommendation engines. This helps them to deliver high-quality streaming experiences to millions of users simultaneously.
- Financial services: Financial institutions use microservices to manage various aspects of their operations, such as fraud detection, payment processing, and risk management. This allows them to respond quickly to changing market conditions, improve security, and follow regulatory requirements.
What is microservices architecture used for?
Typically, microservices are used to speed up application development. Microservices architectures built using Java are common, especially Spring Boot ones. It’s also common to compare microservices versus service-oriented architecture. Both have the same objective, which is to break up monolithic applications into smaller components, but they have different approaches. Here are some microservices architecture examples:
Website migration
Website migration
A complex website that’s hosted on a monolithic platform can be migrated to a cloud-based and container-based microservices platform.
Media content
Media content
Using microservices architecture, images and video assets can be stored in a scalable object storage system and served directly to web or mobile.
Transactions and invoices
Transactions and invoices
Payment processing and ordering can be separated as independent units of services so payments continue to be accepted if invoicing is not working.
Data processing
Data processing
A microservices platform can extend cloud support for existing modular data processing services.
Related products and services
When you use Google Cloud, you can easily deploy microservices using either the managed container service, Google Kubernetes Engine, or the fully managed serverless offering, Cloud Run.
Depending on the use case, Cloud SQL and other Google Cloud products and services can be readily integrated to support microservices architectures.
 Google Kubernetes EngineSecured and managed Kubernetes service with four-way auto scaling and multi-cluster support.
Google Kubernetes EngineSecured and managed Kubernetes service with four-way auto scaling and multi-cluster support. Cloud RunFully managed compute platform for deploying and scaling containerized applications quickly and securely.
Cloud RunFully managed compute platform for deploying and scaling containerized applications quickly and securely. Cloud SQLFully managed relational database service for MySQL, PostgreSQL, and SQL Server.
Cloud SQLFully managed relational database service for MySQL, PostgreSQL, and SQL Server. AnthosModernize existing applications and build cloud-native apps anywhere to promote agility and cost savings.
AnthosModernize existing applications and build cloud-native apps anywhere to promote agility and cost savings.Solution
Cloud-native application developmentBuild, run, and operate cloud-native apps with Google Cloud. Embrace modern approaches like serverless, microservices, and containers. Quickly code, build, deploy, and manage without compromising security or quality.Solution
Unlocking legacy applications using APIsExtend the life of legacy applications, build modern services, and quickly deliver new experiences with Google’s API management platform as an abstraction layer on top of existing services.
Take the next step
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Need help getting started?
Contact salesWork with a trusted partner
Find a partnerContinue browsing
See all products











