Dokumen ini menjelaskan cara memindahkan tugas Apache Spark ke Dataproc. Dokumen ini ditujukan untuk engineer dan arsitek big data. Panduan ini mencakup topik seperti pertimbangan untuk migrasi, persiapan, migrasi tugas, dan pengelolaan.
Ringkasan
Jika Anda ingin memindahkan beban kerja Apache Spark dari lingkungan lokal ke Google Cloud, sebaiknya gunakan Dataproc untuk menjalankan cluster Apache Spark/Apache Hadoop. Dataproc adalah layanan yang dikelola sepenuhnya dan didukung sepenuhnya yang ditawarkan oleh Google Cloud. Hal ini memungkinkan Anda memisahkan penyimpanan dan komputasi, yang membantu Anda mengelola biaya dan lebih fleksibel dalam menskalakan beban kerja.
Jika lingkungan Hadoop terkelola tidak sesuai dengan kebutuhan Anda, Anda juga dapat menggunakan penyiapan lain, seperti menjalankan Spark di Google Kubernetes Engine (GKE), atau menyewa virtual machine di Compute Engine dan menyiapkan sendiri cluster Hadoop atau Spark. Namun, pertimbangkan bahwa opsi selain menggunakan Dataproc dikelola sendiri dan hanya memiliki dukungan komunitas.
Merencanakan migrasi Anda
Ada banyak perbedaan antara menjalankan tugas Spark di lokal dan menjalankan tugas Spark di cluster Dataproc atau Hadoop di Compute Engine. Anda harus memeriksa workload dengan cermat dan bersiap untuk migrasi. Di bagian ini, kami menguraikan pertimbangan yang harus dipertimbangkan, dan persiapan yang harus dilakukan sebelum Anda memigrasikan tugas Spark.
Mengidentifikasi jenis pekerjaan dan cluster rencana
Ada tiga jenis workload Spark, seperti yang dijelaskan di bagian ini.
Tugas batch terjadwal secara rutin
Tugas batch terjadwal secara berkala mencakup kasus penggunaan seperti ETL harian atau per jam, atau pipeline untuk melatih model machine learning dengan Spark ML. Untuk kasus ini, sebaiknya buat cluster untuk setiap beban kerja batch, lalu hapus cluster setelah tugas selesai. Anda memiliki fleksibilitas untuk mengonfigurasi cluster, karena Anda dapat menyesuaikan konfigurasi untuk setiap workload secara terpisah. Cluster Dataproc ditagih dalam peningkatan blok satu detik setelah menit pertama, sehingga pendekatan ini juga hemat biaya, karena Anda dapat memberi label cluster. Untuk mengetahui informasi selengkapnya, lihat halaman Harga Dataproc.
Anda dapat menerapkan tugas batch dengan template alur kerja atau dengan mengikuti langkah-langkah berikut:
Buat cluster dan tunggu hingga cluster dibuat. (Anda dapat memantau apakah cluster telah dibuat menggunakan panggilan API atau perintah gcloud.) Jika Anda menjalankan tugas di cluster Dataproc khusus, sebaiknya nonaktifkan alokasi dinamis dan layanan shuffle eksternal. Perintah
gcloudberikut menunjukkan properti konfigurasi Spark yang diberikan saat Anda membuat cluster Dataproc:dataproc clusters create ... \ --properties 'spark:spark.dynamicAllocation.enabled=false,spark:spark.shuffle.service.enabled=false,spark.executor.instances=10000'Kirimkan tugas Anda ke cluster. (Anda dapat memantau status tugas menggunakan panggilan API atau perintah gcloud.) Contoh:
jobId=$(gcloud --quiet dataproc jobs submit pyspark \ --async \ --format='value(reference.jobId)' \ --cluster $clusterName \ --region global \ gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py) gcloud dataproc jobs describe $jobId \ --region=global \ --format='value(status.state)'Hapus cluster setelah tugas dieksekusi menggunakan panggilan API atau perintah gcloud.
Tugas streaming
Untuk tugas streaming, Anda harus membuat cluster Dataproc yang berjalan lama dan mengonfigurasi cluster tersebut agar berjalan dalam mode ketersediaan tinggi. Sebaiknya jangan gunakan preemptible VM untuk kasus ini.
Workload ad hoc atau interaktif yang dikirimkan oleh pengguna
Contoh beban kerja ad hoc dapat mencakup pengguna yang menulis kueri atau menjalankan tugas analisis pada siang hari.
Untuk kasus ini, Anda harus memutuskan apakah cluster perlu dijalankan dalam mode ketersediaan tinggi, apakah Anda ingin menggunakan VM yang dapat di-preempt, dan cara Anda akan mengelola akses ke cluster. Anda dapat menjadwalkan pembuatan dan penghentian cluster (misalnya, jika Anda tidak pernah memerlukan cluster pada malam hari atau akhir pekan), dan Anda dapat menerapkan penskalaan ke atas dan ke bawah sesuai jadwal.
Mengidentifikasi sumber data dan dependensi
Setiap tugas memiliki dependensi sendiri (misalnya, sumber data yang diperlukan), dan tim lain di perusahaan Anda mungkin bergantung pada hasil tugas Anda. Oleh karena itu, Anda harus mengidentifikasi semua dependensi, lalu membuat rencana migrasi yang menyertakan prosedur untuk hal berikut:
Migrasi langkah demi langkah semua sumber data Anda ke Google Cloud. Pada awalnya, sebaiknya buat salinan sumber data di Google Cloud agar Anda memilikinya di dua tempat.
Migrasi tugas demi tugas dari workload Spark Anda ke Google Cloud segera setelah sumber data yang sesuai dimigrasikan. Seperti data, pada suatu saat Anda mungkin memiliki dua beban kerja yang berjalan secara paralel baik di lingkungan lama maupun di Google Cloud.
Migrasi workload lain yang bergantung pada output workload Spark Anda. Atau, Anda dapat mereplikasi output kembali ke lingkungan awal.
Penonaktifan tugas Spark di lingkungan lama setelah semua tim dependen telah mengonfirmasi bahwa mereka tidak lagi memerlukan tugas tersebut.
Memilih opsi penyimpanan
Ada dua opsi penyimpanan yang dapat digunakan dengan cluster Dataproc: Anda dapat menyimpan semua data di Cloud Storage, atau Anda dapat menggunakan disk lokal atau disk persisten dengan pekerja cluster. Pilihan yang tepat bergantung pada karakter tugas Anda.
Membandingkan Cloud Storage dan HDFS
Setiap node cluster Dataproc memiliki konektor Cloud Storage yang diinstal di dalamnya. Secara default, konektor diinstal di bagian
/usr/lib/hadoop/lib. Konektor ini mengimplementasikan antarmuka
FileSystem
Hadoop dan membuat Cloud Storage kompatibel dengan HDFS.
Karena Cloud Storage adalah sistem penyimpanan objek besar biner (BLOB),
konektor mengemulasikan direktori sesuai dengan nama objek. Anda dapat
mengakses data menggunakan awalan gs://, bukan awalan hdfs://.
Konektor Cloud Storage biasanya tidak memerlukan penyesuaian apa pun. Namun, jika perlu melakukan perubahan, Anda dapat mengikuti petunjuk untuk mengonfigurasi konektor. Daftar lengkap kunci konfigurasi juga tersedia.
Cloud Storage adalah opsi yang baik jika:
- Data Anda dalam format ORC, Parquet, Avro, atau format lainnya akan digunakan oleh cluster atau tugas yang berbeda, dan Anda memerlukan persistensi data jika cluster dihentikan.
- Anda memerlukan throughput tinggi dan data Anda disimpan dalam file yang lebih besar dari 128 MB.
- Anda memerlukan ketahanan lintas zona untuk data Anda.
- Anda memerlukan data yang sangat tersedia—misalnya, Anda ingin menghilangkan NameNode HDFS sebagai titik tunggal kegagalan.
Penyimpanan HDFS lokal adalah opsi yang baik jika:
- Tugas Anda memerlukan banyak operasi metadata—misalnya, Anda memiliki ribuan partisi dan direktori, dan setiap ukuran file relatif kecil.
- Anda sering mengubah data HDFS atau mengganti nama direktori. (Objek Cloud Storage bersifat immutable, sehingga mengganti nama direktori adalah operasi yang mahal karena terdiri dari menyalin semua objek ke kunci baru dan menghapusnya setelah itu.)
- Anda sangat sering menggunakan operasi append pada file HDFS.
Anda memiliki beban kerja yang melibatkan I/O berat. Misalnya, Anda memiliki banyak penulisan yang dipartisi, seperti berikut:
spark.read().write.partitionBy(...).parquet("gs://")Anda memiliki beban kerja I/O yang sangat sensitif terhadap latensi. Misalnya, Anda memerlukan latensi milidetik satu digit per operasi penyimpanan.
Secara umum, sebaiknya gunakan Cloud Storage sebagai sumber data awal dan akhir dalam pipeline big data. Misalnya, jika alur kerja berisi lima tugas Spark secara berurutan, tugas pertama akan mengambil data awal dari Cloud Storage, lalu menulis data shuffle dan output tugas perantara ke HDFS. Tugas Spark akhir menulis hasilnya ke Cloud Storage.
Menyesuaikan ukuran penyimpanan
Menggunakan Dataproc dengan Cloud Storage memungkinkan Anda mengurangi persyaratan disk dan menghemat biaya dengan menempatkan data di sana, bukan di HDFS. Jika menyimpan data di Cloud Storage dan tidak menyimpannya di HDFS lokal, Anda dapat menggunakan disk yang lebih kecil untuk cluster. Dengan membuat cluster benar-benar sesuai permintaan, Anda juga dapat memisahkan penyimpanan dan komputasi, seperti yang disebutkan sebelumnya, yang membantu Anda mengurangi biaya secara signifikan.
Meskipun Anda menyimpan semua data di Cloud Storage, cluster Dataproc memerlukan HDFS untuk operasi tertentu seperti menyimpan file kontrol dan pemulihan, atau menggabungkan log. Alat ini juga memerlukan ruang disk lokal non-HDFS untuk shuffling. Anda dapat mengurangi ukuran disk per pekerja jika tidak menggunakan HDFS lokal secara intensif.
Berikut beberapa opsi untuk menyesuaikan ukuran HDFS lokal:
- Kurangi total ukuran HDFS lokal dengan mengurangi ukuran persistent disk utama untuk master dan pekerja. Disk persisten utama juga berisi volume booting dan library sistem, jadi alokasikan setidaknya 100 GB.
- Meningkatkan total ukuran HDFS lokal dengan meningkatkan ukuran persistent disk utama untuk pekerja. Pertimbangkan opsi ini dengan cermat— jarang ada workload yang mendapatkan performa yang lebih baik dengan menggunakan HDFS dengan persistent disk standar dibandingkan dengan menggunakan Cloud Storage atau HDFS lokal dengan SSD.
- Pasang hingga delapan SSD (masing-masing 375 GB) ke setiap pekerja dan gunakan disk ini untuk HDFS. Ini adalah opsi yang baik jika Anda perlu menggunakan HDFS untuk beban kerja yang intensif I/O dan Anda memerlukan latensi milidetik satu digit. Pastikan Anda menggunakan jenis mesin yang memiliki CPU dan memori yang memadai di pekerja untuk mendukung disk ini.
- Gunakan SSD persistent disk (PD-SSD) untuk master atau pekerja sebagai disk utama.
Mengakses Dataproc
Mengakses Dataproc atau Hadoop di Compute Engine berbeda dengan mengakses cluster lokal. Anda perlu menentukan setelan keamanan dan opsi akses jaringan.
Jaringan
Semua instance VM cluster Dataproc memerlukan jaringan internal satu sama lain, dan memerlukan port UDP, TCP, dan ICMP yang terbuka. Anda dapat mengizinkan akses ke cluster Dataproc dari alamat IP eksternal menggunakan konfigurasi jaringan default atau menggunakan jaringan VPC. Cluster Dataproc Anda akan memiliki akses jaringan ke semua layanan Google Cloud (bucket Cloud Storage, API, dan sebagainya) di opsi jaringan apa pun yang Anda gunakan. Untuk mengizinkan akses jaringan ke atau dari resource lokal, pilih konfigurasi jaringan VPC dan siapkan aturan firewall yang sesuai. Untuk mengetahui detailnya, lihat panduan Konfigurasi Jaringan Cluster Dataproc dan bagian Mengakses YARN di bawah.
Pengelolaan akses dan identitas
Selain akses jaringan, cluster Dataproc Anda memerlukan izin untuk mengakses resource. Misalnya, untuk menulis data ke bucket Cloud Storage, cluster Dataproc Anda harus memiliki akses tulis ke bucket. Anda menetapkan akses menggunakan peran. Pindai kode Spark Anda dan temukan semua resource non-Dataproc yang diperlukan kode dan berikan peran yang benar ke akun layanan cluster. Selain itu, pastikan pengguna yang akan membuat template cluster, tugas, operasi, dan alur kerja memiliki izin yang tepat.
Untuk mengetahui detail selengkapnya dan praktik terbaik, lihat dokumentasi IAM.
Memverifikasi Spark dan dependensi library lainnya
Bandingkan versi Spark dan versi library lainnya dengan daftar versi Dataproc resmi dan cari library yang belum tersedia. Sebaiknya gunakan versi Spark yang didukung secara resmi oleh Dataproc.
Jika perlu menambahkan library, Anda dapat melakukan hal berikut:
- Buat image kustom cluster Dataproc.
- Buat skrip inisialisasi di Cloud Storage untuk cluster Anda. Anda dapat menggunakan skrip inisialisasi untuk menginstal dependensi tambahan, menyalin biner, dan sebagainya.
- Kompilasi ulang kode Java atau Scala dan paketkan semua dependensi tambahan yang bukan bagian dari distribusi dasar sebagai "fat jar" menggunakan Gradle, Maven, Sbt, atau alat lainnya.
Menyesuaikan ukuran cluster Dataproc
Dalam konfigurasi cluster apa pun, baik di lokal maupun di cloud, ukuran cluster sangat penting untuk performa tugas Spark. Tugas Spark tanpa resource yang memadai akan berjalan lambat atau gagal, terutama jika tidak memiliki memori eksekutor yang memadai. Untuk mendapatkan saran tentang hal-hal yang perlu dipertimbangkan saat menentukan ukuran cluster Hadoop, lihat bagian menentukan ukuran cluster dalam panduan migrasi Hadoop.
Bagian berikut menjelaskan beberapa opsi untuk menentukan ukuran cluster.
Mendapatkan konfigurasi tugas Spark saat ini
Lihat cara tugas Spark Anda saat ini dikonfigurasi dan pastikan bahwa cluster Dataproc cukup besar. Jika Anda berpindah dari cluster bersama ke beberapa cluster Dataproc (satu untuk setiap beban kerja batch), lihat konfigurasi YARN untuk setiap aplikasi sehingga Anda memahami jumlah eksekutor yang diperlukan, jumlah CPU per eksekutor, dan total memori eksekutor. Jika cluster on-premise Anda telah menyiapkan antrean YARN, lihat tugas mana yang berbagi resource setiap antrean dan identifikasi bottleneck. Migrasi ini adalah peluang untuk menghapus batasan resource yang mungkin Anda miliki di cluster on-premise.
Memilih jenis mesin dan opsi disk
Pilih jumlah dan jenis VM agar sesuai dengan kebutuhan beban kerja Anda. Jika Anda telah memutuskan untuk menggunakan HDFS lokal untuk penyimpanan, pastikan VM memiliki jenis dan ukuran disk yang tepat. Jangan lupa untuk menyertakan kebutuhan resource program driver dalam penghitungan Anda.
Setiap VM memiliki batas traffic keluar jaringan 2 Gbps per vCPU. Operasi tulis ke persistent disk atau SSD persisten dihitung dalam batas ini, sehingga VM dengan jumlah vCPU yang sangat rendah dapat dibatasi oleh batas saat VM tersebut menulis ke disk ini. Hal ini kemungkinan terjadi pada fase shuffle, saat Spark menulis data shuffle ke disk dan memindahkan data shuffle melalui jaringan di antara eksekutor. Persistent disk memerlukan minimal 2 vCPU untuk mencapai performa tulis maksimum dan SSD persisten memerlukan 4 vCPU. Perhatikan bahwa nilai minimum ini tidak mempertimbangkan traffic seperti komunikasi antar-VM. Selain itu, ukuran setiap disk memengaruhi performa puncak-nya.
Konfigurasi yang Anda pilih akan memengaruhi biaya cluster Dataproc Anda. Harga Dataproc merupakan tambahan untuk harga per instance Compute Engine untuk setiap VM dan resource Google Cloud lainnya. Untuk informasi selengkapnya, dan untuk menggunakan kalkulator harga Google Cloud untuk mendapatkan estimasi biaya, lihat halaman harga Dataproc.
Melakukan benchmark performa dan mengoptimalkan
Setelah menyelesaikan fase migrasi tugas, tetapi sebelum berhenti menjalankan workload Spark di cluster on-premise, lakukan benchmark pada tugas Spark dan pertimbangkan pengoptimalan apa pun. Ingat bahwa Anda dapat mengubah ukuran cluster jika konfigurasi tidak optimal.
Penskalaan otomatis Dataproc Serverless untuk Spark
Gunakan Dataproc Serverless untuk menjalankan workload Spark tanpa menyediakan dan mengelola cluster Anda sendiri. Tentukan parameter beban kerja, lalu kirimkan beban kerja ke layanan Dataproc Serverless. Layanan akan menjalankan beban kerja pada infrastruktur komputasi terkelola, serta melakukan penskalaan otomatis resource sesuai kebutuhan. Biaya Dataproc Serverless hanya berlaku saat workload dijalankan.
Melakukan migrasi
Bagian ini membahas migrasi data, mengubah kode tugas, dan mengubah cara tugas dijalankan.
Migrasikan data
Sebelum menjalankan tugas Spark di cluster Dataproc, Anda perlu memigrasikan data ke Google Cloud. Untuk informasi selengkapnya, lihat Panduan Migrasi Data.
Memigrasikan kode Spark
Setelah merencanakan migrasi ke Dataproc dan memindahkan
sumber data yang diperlukan, Anda dapat memigrasikan kode tugas. Jika tidak ada perbedaan
versi Spark antara kedua cluster, dan jika Anda ingin menyimpan data di
Cloud Storage, bukan HDFS lokal, Anda hanya perlu mengubah awalan
semua jalur file HDFS dari hdfs:// menjadi gs://.
Jika Anda menggunakan versi Spark yang berbeda, lihat catatan rilis Spark, bandingkan kedua versi, dan sesuaikan kode Spark Anda.
Anda dapat menyalin file jar untuk aplikasi Spark ke bucket Cloud Storage yang terikat dengan cluster Dataproc atau ke folder HDFS. Bagian berikut menjelaskan opsi yang tersedia untuk menjalankan tugas Spark.
Jika Anda memutuskan untuk menggunakan template alur kerja, sebaiknya uji setiap tugas Spark yang Anda rencanakan untuk ditambahkan secara terpisah. Kemudian, Anda dapat menjalankan pengujian akhir template untuk memastikan alur kerja template sudah benar (tidak ada tugas upstream yang hilang, output disimpan di lokasi yang tepat, dan sebagainya).
Menjalankan tugas
Anda dapat menjalankan tugas Spark dengan cara berikut:
Dengan menggunakan perintah
gcloudberikut:gcloud dataproc jobs submit [COMMAND]
dengan:
[COMMAND]adalahspark,pyspark, atauspark-sqlAnda dapat menetapkan properti Spark dengan opsi
--properties. Untuk informasi selengkapnya, lihat dokumentasi untuk perintah ini.Dengan menggunakan proses yang sama dengan yang Anda gunakan sebelum memigrasikan tugas ke Dataproc. Cluster Dataproc harus dapat diakses dari lokal, dan Anda harus menggunakan konfigurasi yang sama.
Dengan menggunakan Cloud Composer. Anda dapat membuat lingkungan (server Apache Airflow terkelola), menentukan beberapa tugas Spark sebagai alur kerja DAG, lalu menjalankan seluruh alur kerja.
Untuk mengetahui detail selengkapnya, lihat panduan Mengirimkan Tugas.
Mengelola tugas setelah migrasi
Setelah Anda memindahkan tugas Spark ke Google Cloud, penting untuk mengelola tugas ini menggunakan alat dan mekanisme yang disediakan oleh Google Cloud. Di bagian ini, kita akan membahas logging, pemantauan, mengakses cluster, menskalakan cluster, dan mengoptimalkan tugas.
Menggunakan logging dan pemantauan performa
Di Google Cloud, Anda dapat menggunakan Cloud Logging dan Cloud Monitoring untuk melihat dan menyesuaikan log, serta memantau tugas dan resource.
Cara terbaik untuk menemukan error yang menyebabkan kegagalan tugas Spark adalah dengan melihat output driver dan log yang dihasilkan oleh eksekutor Spark.
Anda dapat mengambil output program driver menggunakan konsol Google Cloud atau dengan menggunakan perintah gcloud. Output juga disimpan di bucket Cloud Storage dari cluster Dataproc. Untuk mengetahui detail selengkapnya, lihat bagian tentang output driver tugas dalam dokumentasi Dataproc.
Semua log lainnya berada di file yang berbeda di dalam mesin
cluster. Anda dapat melihat log untuk setiap penampung dari UI web aplikasi Spark (atau dari Server Histori setelah program berakhir) di tab eksekutor. Anda
perlu menjelajahi setiap penampung Spark untuk melihat setiap log. Jika Anda menulis log
atau mencetak ke stdout atau stderr dalam kode aplikasi, log akan disimpan dalam
pengalihan stdout atau stderr.
Di cluster Dataproc, YARN dikonfigurasi untuk mengumpulkan semua log ini secara default, dan log tersebut tersedia di Cloud Logging. Cloud Logging memberikan tampilan gabungan dan ringkas dari semua log sehingga Anda tidak perlu menghabiskan waktu untuk menjelajahi log penampung guna menemukan error.
Gambar berikut menunjukkan halaman Cloud Logging di konsol Google Cloud. Anda dapat melihat semua log dari cluster Dataproc dengan memilih nama cluster di menu pemilih. Jangan lupa untuk meluaskan durasi waktu di pemilih rentang waktu.
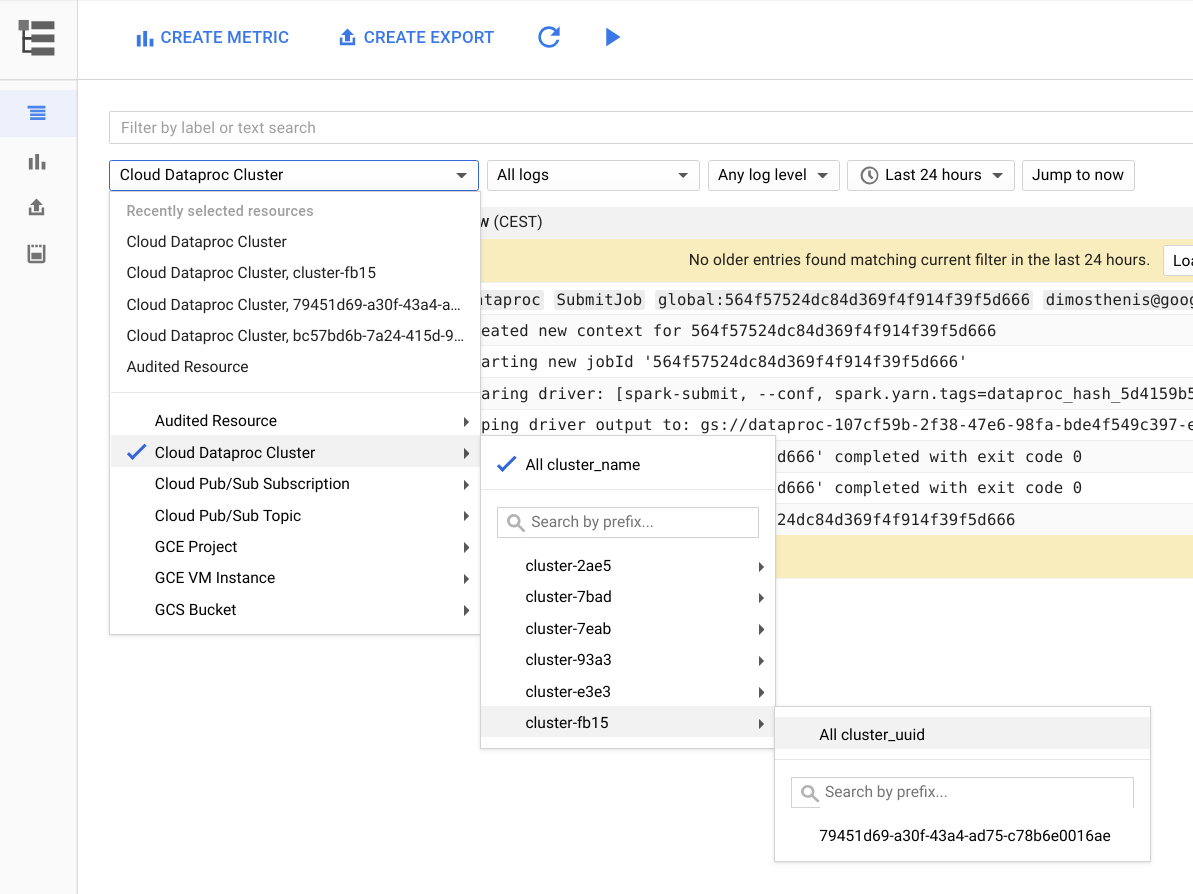
Anda bisa mendapatkan log dari aplikasi Spark dengan memfilter berdasarkan ID-nya. Anda dapat mendapatkan ID aplikasi dari output driver.
Membuat dan menggunakan label
Untuk menemukan log lebih cepat, Anda dapat membuat dan menggunakan label Anda sendiri untuk setiap cluster atau untuk setiap tugas Dataproc. Misalnya, Anda dapat
membuat label dengan kunci env dan nilai exploration, lalu menggunakannya untuk
tugas eksplorasi data. Kemudian, Anda bisa mendapatkan log untuk semua pembuatan tugas eksplorasi dengan memfilter menggunakan label:env:exploration di Cloud Logging.
Perhatikan bahwa filter ini tidak akan menampilkan semua log untuk tugas ini, hanya log pembuatan resource.
Menetapkan level log
Anda dapat
menetapkan level log driver
menggunakan perintah gcloud berikut:
gcloud dataproc jobs submit hadoop --driver-log-levels
Anda menetapkan level log untuk seluruh aplikasi dari konteks Spark. Contoh:
spark.sparkContext.setLogLevel("DEBUG")Memantau tugas
Cloud Monitoring dapat memantau CPU, disk, penggunaan jaringan, dan resource YARN cluster. Anda dapat membuat dasbor kustom untuk mendapatkan diagram terbaru untuk metrik ini dan metrik lainnya. Dataproc berjalan di atas Compute Engine. Jika ingin memvisualisasikan penggunaan CPU, I/O disk, atau metrik jaringan dalam diagram, Anda harus memilih instance VM Compute Engine sebagai jenis resource, lalu memfilter menurut nama cluster. Diagram berikut menunjukkan contoh output.
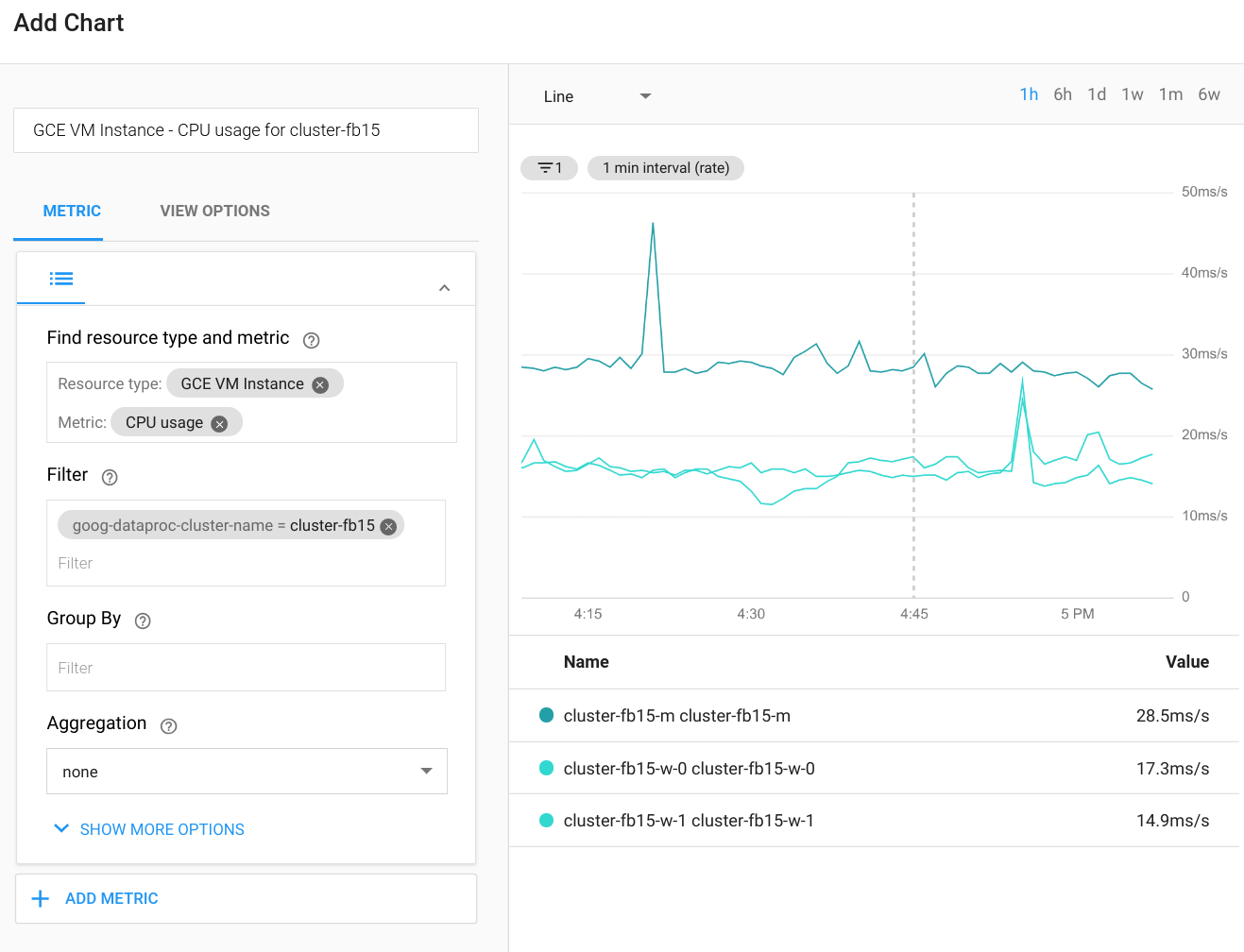
Untuk melihat metrik kueri, tugas, tahap, atau tugas Spark, hubungkan ke UI web aplikasi Spark. Bagian berikutnya akan menjelaskan cara melakukannya. Untuk mengetahui detail tentang cara membuat metrik kustom, lihat panduan Metrik Kustom dari Agen.
Mengakses YARN
Anda dapat mengakses antarmuka web pengelola resource YARN dari luar cluster Dataproc dengan menyiapkan tunnel SSH. Sebaiknya gunakan proxy SOCKS ringan, bukan penerusan port lokal, karena menjelajahi antarmuka web akan lebih mudah.
URL berikut berguna untuk akses YARN:
Pengelola resource YARN:
http://[MASTER_HOST_NAME]:8088Server histori Spark:
http://[MASTER_HOST_NAME]:18080
Jika cluster Dataproc hanya memiliki alamat IP internal, Anda dapat terhubung melalui koneksi VPN atau melalui host bastion. Untuk mengetahui informasi selengkapnya, lihat Memilih opsi koneksi untuk VM khusus internal.
Menskalakan dan mengubah ukuran cluster Dataproc
Cluster Dataproc dapat diskalakan dengan menambah atau mengurangi jumlah pekerja primer atau sekunder (dapat di-preempt) . Dataproc juga mendukung penghentian layanan secara tuntas.
Penurunan skala di Spark dipengaruhi oleh sejumlah faktor. Pertimbangkan hal berikut:
Kami tidak merekomendasikan penggunaan
ExternalShuffleService, terutama jika Anda mendownscale cluster secara berkala. Pengacakan menggunakan hasil yang telah ditulis ke disk lokal pekerja setelah fase compute dijalankan, sehingga node tidak dapat dihapus meskipun resource compute tidak digunakan lagi.Spark meng-cache data di memori (baik RDD maupun set data), dan eksekutor yang digunakan untuk menyimpan data ke dalam cache tidak akan pernah keluar. Akibatnya, jika pekerja digunakan untuk menyimpan dalam cache, pekerja tersebut tidak akan pernah dinonaktifkan dengan baik. Menghapus pekerja secara paksa akan memengaruhi performa secara keseluruhan, karena data dalam cache akan hilang.
Spark Streaming memiliki alokasi dinamis yang dinonaktifkan secara default, dan kunci konfigurasi yang menetapkan perilaku ini tidak didokumentasikan. (Anda dapat mengikuti diskusi tentang perilaku alokasi dinamis di thread masalah Spark.) Jika menggunakan Spark Streaming atau Spark Structured Streaming, Anda juga harus menonaktifkan alokasi dinamis secara eksplisit seperti yang telah dibahas sebelumnya di bagian Mengidentifikasi jenis tugas dan merencanakan cluster.
Secara umum, sebaiknya hindari penskalaan ke bawah cluster Dataproc jika Anda menjalankan beban kerja batch atau streaming.
Mengoptimalkan performa
Bagian ini membahas cara mendapatkan performa yang lebih baik dan mengurangi biaya saat menjalankan tugas Spark.
Mengelola ukuran file Cloud Storage
Untuk mendapatkan performa yang optimal, bagi data Anda di Cloud Storage menjadi file dengan ukuran dari 128 MB hingga 1 GB. Menggunakan banyak file kecil dapat menimbulkan kerusakan. Jika Anda memiliki banyak file kecil, pertimbangkan untuk menyalin file untuk diproses ke HDFS lokal, lalu menyalin hasilnya kembali.
Beralih ke disk SSD
Jika Anda melakukan banyak operasi pengurutan ulang atau penulisan partisi, beralihlah ke SSD untuk meningkatkan performa.
Menempatkan VM di zona yang sama
Untuk mengurangi biaya jaringan dan meningkatkan performa, gunakan lokasi regional yang sama untuk bucket Cloud Storage yang Anda gunakan untuk cluster Dataproc.
Secara default, saat Anda menggunakan endpoint Dataproc global atau regional, VM cluster Anda akan ditempatkan ke zona yang sama (atau zona lain di region yang sama yang memiliki kapasitas yang cukup) saat cluster dibuat. Anda juga dapat menentukan zona saat cluster dibuat.
Menggunakan preemptible VM
Cluster Dataproc dapat menggunakan instance preemptible VM sebagai pekerja. Hal ini menghasilkan biaya komputasi per jam yang lebih rendah untuk beban kerja non-kritis Anda daripada menggunakan instance normal. Namun, ada beberapa faktor yang perlu dipertimbangkan saat Anda menggunakan preemptible VM:
- VM preemptible tidak dapat digunakan untuk penyimpanan HDFS.
- Secara default, VM yang dapat dihentikan dibuat dengan ukuran disk booting yang lebih kecil, dan Anda dapat mengganti konfigurasi ini jika menjalankan beban kerja yang banyak melakukan shuffle. Untuk mengetahui detailnya, lihat halaman tentang preemptible VM dalam dokumentasi Dataproc.
- Sebaiknya jangan buat lebih dari setengah total pekerja Anda dapat di-preempt.
Saat Anda menggunakan preemptible VM, sebaiknya sesuaikan konfigurasi cluster agar lebih toleran terhadap kegagalan tugas, karena VM mungkin kurang tersedia. Misalnya, buat setelan seperti berikut dalam konfigurasi YARN:
yarn.resourcemanager.am.max-attempts mapreduce.map.maxattempts mapreduce.reduce.maxattempts spark.task.maxFailures spark.stage.maxConsecutiveAttempts
Anda dapat dengan mudah menambahkan atau menghapus VM yang dapat di-preempt dari cluster. Untuk mengetahui detail selengkapnya, lihat Preemptible VM.
Langkah berikutnya
- Lihat panduan tentang cara memigrasikan infrastruktur Hadoop lokal ke Google Cloud.
- Lihat deskripsi kami tentang Siklus Proses Tugas Dataproc.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.